

SWT and Parity Space Based Fault Detection for Linear Discrete Time-varying Systems
-
摘要: 为提高基于等价空间的线性离散时变(Linear discrete time-varying,LDTV)系统故障检测的检测性能,本文提出一种基于平稳小波变换(Stationary wavelet transform,SWT)与等价空间的LDTV系统故障检测方法.通过引入SWT对基于低阶等价关系构造的残差进行多尺度滤波,将残差产生器设计转化为不同尺度下的多目标最优化问题,保证了各尺度下残差对干扰鲁棒性和对故障灵敏性指标的最小化,同时利用SWT快速算法获得一组多尺度残差信号.进一步,对产生的多尺度残差信号进行多分辨率分析,从而实现较宽频率范围内故障信号的检测,有效降低了故障漏报率.最后,通过仿真实验验证了本文方法的有效性.Abstract: This paper deals with fault detection (FD) for linear discrete time-varying (LDTV) systems by combining stationary wavelet transform (SWT) with parity space based method, so as to improve the FD performance. By employing SWT to filter the residual generated with low order parity relation, the design of residual generator can be formulated as multi-objective optimization problem at each scale of SWT, so that minimum ratio criterion of robustness to unknown input and sensitivity to faults are assured, and a bank of multi-scale residuals are obtained by applying the SWT recursive algorithm. Moreover, by analysing the generated residual signals at multiscale, the faults within a broader frequency band can be detected and a lower miss detection rate can be achieved. Finally, a numerical example is given to verify the effectiveness of the proposed approach.
-
-
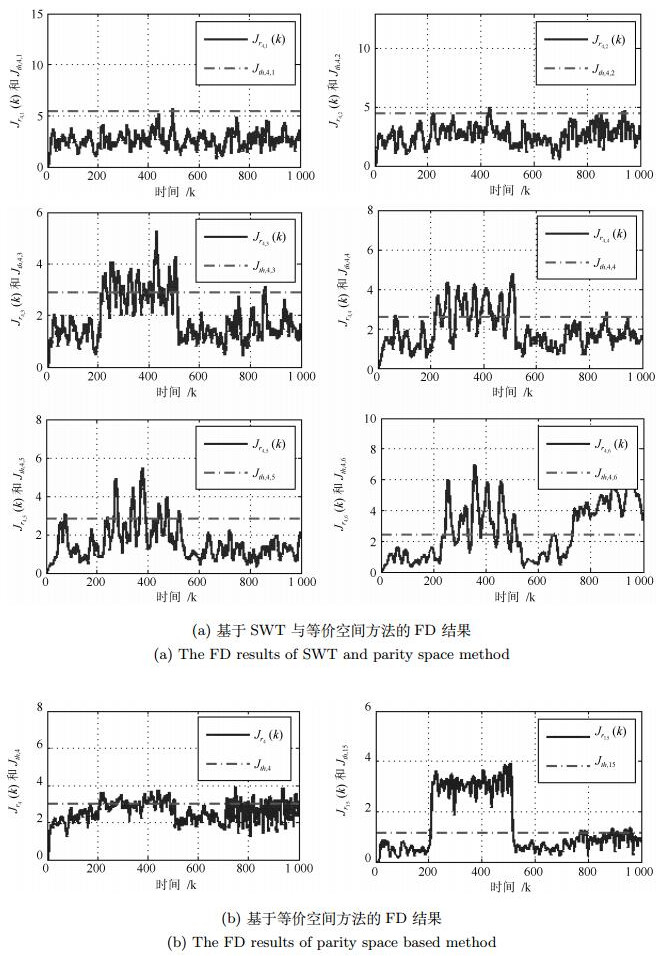
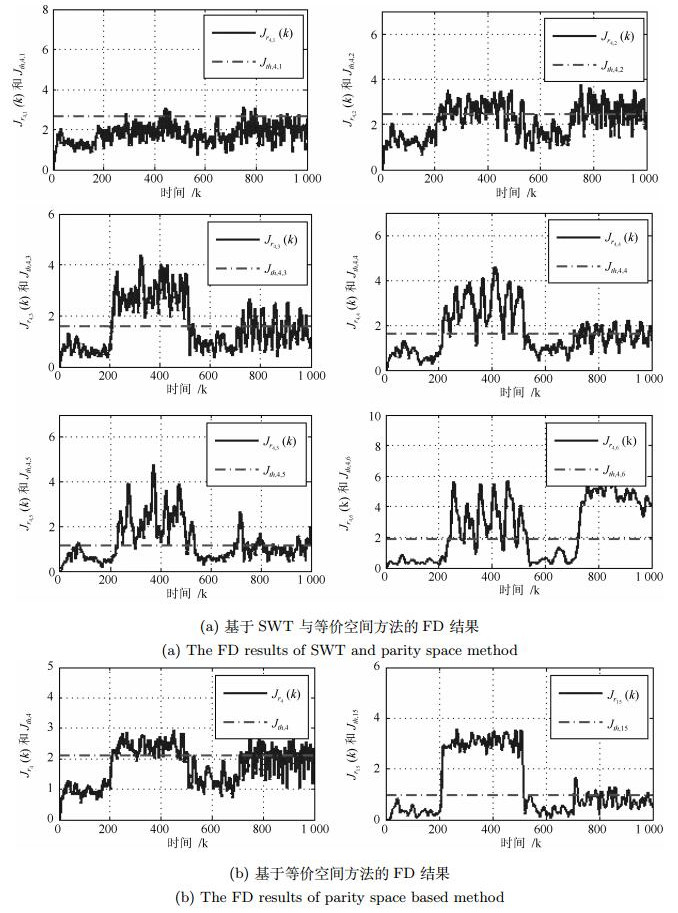
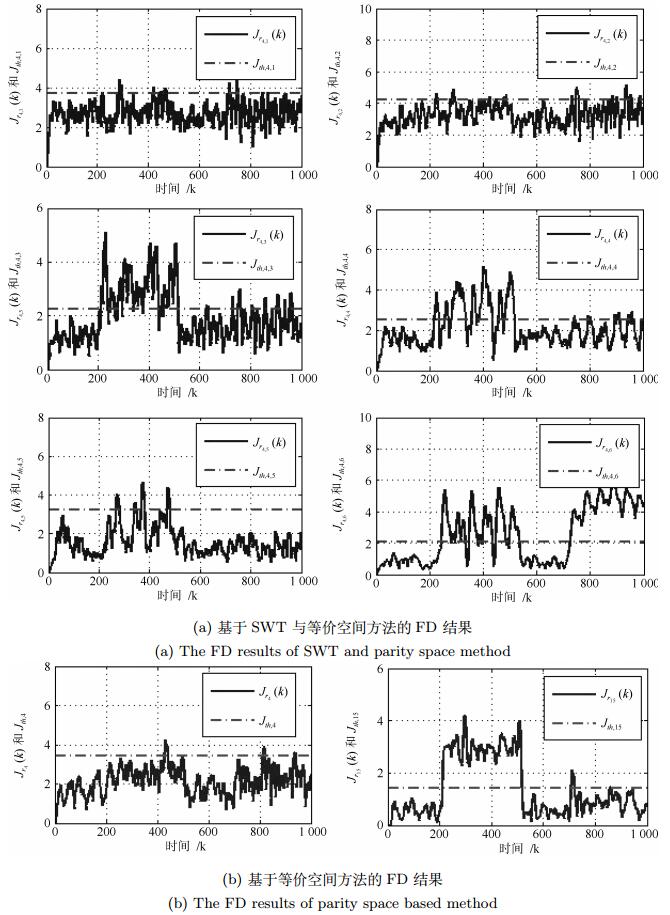
图 3 当$d_1(k)$方差为0.7$^2$时的正弦故障检测结果
Fig. 3 The FD results of sine fault with the variance of $d_1(k)$ rising to $0.7^2$
-
[1] Lan J L, Patton R J. A new strategy for integration of fault estimation within fault-tolerant control. Automatica, 2016, 69:48-59 doi: 10.1016/j.automatica.2016.02.014 [2] Ding S X. Data-driven design of monitoring and diagnosis systems for dynamic processes:a review of subspace technique based schemes and some recent results. Journal of Process Control, 2014, 24:431-449 doi: 10.1016/j.jprocont.2013.08.011 [3] 周东华, 刘洋, 何潇.闭环系统故障诊断技术综述.自动化学报, 2013, 39(11):1933-1943 http://www.aas.net.cn/CN/abstract/abstract18232.shtmlZhou Dong-Hua, Liu Yang, He Xiao. Review on fault diagnosis techniques for closed-loop systems. Acta Automatica Sinica, 2013, 39(11):1933-1943 http://www.aas.net.cn/CN/abstract/abstract18232.shtml [4] Cai J, Ferdowsi H, Sarangapani J. Model-based fault detection, estimation, and prediction for a class of linear distributed parameter systems. Automatica, 2016, 66:122-131 doi: 10.1016/j.automatica.2015.12.028 [5] Ding S. Model-based Fault Diagnosis Techniques (2nd Edition). London:Springer, 2013. [6] 李岳炀, 钟麦英.具有多测量数据包丢失的线性离散时变系统故障检测滤波器设计.自动化学报, 2015, 41(9):1638-1648 http://www.aas.net.cn/CN/abstract/abstract18737.shtmlLi Yue-Yang, Zhong Mai-Ying. Fault detection filter design for linear discrete time-varying systems with multiple packet dropouts. Acta Automatica Sinica, 2015, 41(9):1638-1648 http://www.aas.net.cn/CN/abstract/abstract18737.shtml [7] Li Y Y, Liu S, Wang Z H. Fault detection for linear discrete time-varying systems with intermittent observations and quantization errors. Asian Journal of Control, 2016, 18(1):377-389 doi: 10.1002/asjc.v18.1 [8] Zhong M Y, Zhou D H, Ding S X. On H∞ fault detection filter for linear discrete time-varying systems. IEEE Transactions on Automatic Control, 2010, 55(7):1689-1695 doi: 10.1109/TAC.2010.2046921 [9] Wan Y M, Dong W, Wu H, Ye H. Integrated fault detection system design for linear discrete time-varying systems with bounded power disturbances. International Journal of Robust and Nonlinear Control, 2013, 23(16):1781-1802 http://www.academia.edu/4226910/Integrated_fault_detection_system_design_for_linear_discrete_time-varying_systems_with_bounded_power_disturbances [10] Chandra N H, Sekhar A S. Fault detection in rotor bearing systems using time frequency techniques. Mechanical Systems and Signal Processing, 2016, 73-73:105-133 http://adsabs.harvard.edu/abs/2016MSSP...72..105C [11] Barragan J F, Fontes C H, Embiruçu M. A wavelet-based clustering of multivariate time series using a multiscale SPCA approach. Computers & Industrial Engineering, 2016, 95:144-155 https://www.sciencedirect.com/science/article/pii/S0360835216300560 [12] You D Y, Gao X D, Katayama S. WPD-PCA-based laser welding process monitoring and defects diagnosis by using FNN and SVM. IEEE Transactions on Industrial Electronics, 2015, 62(1):628-638 doi: 10.1109/TIE.2014.2319216 [13] Patton R J, Chen J. Review of parity space approaches to fault diagnosis. IFAC Symposia Series, 1992, 6:65-81 http://www.sciencedirect.com/science/article/pii/S1474667017511246 [14] Zhong M Y, Ding S X, Han Q L, Ding Q. Parity space-based fault estimation for linear discrete time-varying systems. IEEE Transactions on Automatic Control, 2010, 55(7):1726-1731 doi: 10.1109/TAC.2010.2047672 [15] Vento J, Blesa J, Puig V, Sarrate R. Set-membership parity space hybrid system diagnosis. International Journal of Systems Science, 2015, 46(5):790-807 doi: 10.1080/00207721.2014.977978 [16] Zhang Z, Jaimoukha I M. On-line fault detection and isolation for linear discrete-time uncertain systems. Automatica, 2014, 50(2):513-518 doi: 10.1016/j.automatica.2013.11.003 [17] Wang Y L, Gao B Z, Chen H. Data-driven design of parity space-based FDI system for AMT vehicles. IEEE/ASME Transactions on Mechatronics, 2015, 20(1):405-415 doi: 10.1109/TMECH.2014.2329005 [18] Li Z L, Outbib R, Hissel D, Giurgea S. Diagnosis of PEMFC by using data-driven parity space strategy. In:Proceedings of the 2014 European Control Conference (ECC). Strasbourg, France:IEEE, 2014. 1268-1273 http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6862527 [19] Zhang P, Ye H, Ding S X, Wang G Z, Zhou D H. On the relationship between parity space and H2 approaches to fault detection. Systems & Control Letters, 2006, 55(2):94-100 [20] Ye H, Wang G Z, Ding S X. A new parity space approach for fault detection based on stationary wavelet transform. IEEE Transactions on Automatic Control, 2004, 49(2):281-286 doi: 10.1109/TAC.2003.822856 [21] 薛婷, 钟麦英, 李钢.基于小波变换与等价空间的无人机作动器故障检测.控制理论与应用, 2016, 33(9):1193-1199 http://d.wanfangdata.com.cn/Periodical/kzllyyy201609008Xue Ting, Zhong Mai-Ying, Li Gang. Wavelet transform and parity space based actuator fault detection for unmanned aerial vehicle. Control Theory and Application, 2016, 33(9):1193-1199 http://d.wanfangdata.com.cn/Periodical/kzllyyy201609008 [22] Zhang J M, Zhang Y B, Guan Y G. Analysis of time-domain reflectometry combined with wavelet transform for fault detection in aircraft shielded cables. IEEE Sensors Journal, 2016, 16(11):4579-4586 doi: 10.1109/JSEN.2016.2547323 [23] 杜党波, 张伟, 胡昌华, 周志杰, 司小胜, 张建勋.含缺失数据的小波——卡尔曼滤波故障预测方法.自动化学报, 2014, 40(10):2115-2125 http://www.aas.net.cn/CN/abstract/abstract18486.shtmlDu Dang-Bo, Zhang Wei, Hu Chang-Hua, Zhou Zhi-Jie, Si Xiao-Sheng, Zhang Jian-Xun. A failure prognosis method based on wavelet-Kalman filtering with missing data. Acta Automatica Sinica, 2014, 40(10):2115-2125 http://www.aas.net.cn/CN/abstract/abstract18486.shtml [24] Yusuff A A, Jimoh A A, Munda J L. Fault location in transmission lines based on stationary wavelet transform, determinant function feature and support vector regression. Electric Power Systems Research, 2014, 110:73-83 doi: 10.1016/j.epsr.2014.01.002 [25] Zhong M Y, Ding Q, Shi P. Parity space-based fault detection for Markovian jump systems. International Journal of Systems Science, 2009, 40(4):421-428 doi: 10.1080/00207720802556237 [26] Zhong M Y, Song Y, Ding S X. Parity space-based fault detection for linear discrete time-varying systems with unknown input. Automatica, 2015, 59:120-126 doi: 10.1016/j.automatica.2015.06.013 [27] Mallat S G. A Wavelet Tour of Signal Processing:the Sparse Way (3rd Edition). Amsterdam:Elsevier, 2009. [28] Renaud O, Starck J L, Murtagh F. Wavelet-based combined signal filtering and prediction. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2005, 35(6):1241-1251 doi: 10.1109/TSMCB.2005.850182 期刊类型引用(22)
1. 张欣,张雁,张鑫. 基于亮度与彩色纹理统计的无参考图像评价. 信息技术与信息化. 2023(01): 122-129 .  百度学术
百度学术2. 何锦成,韩永成,张闻文,何伟基,陈钱. 基于通道校正卷积的真彩色微光图像增强. 兵工学报. 2023(06): 1643-1654 . 百度学术3. 罗小燕,刘顺,汤文聪,王兴卫. 基于Mask RCNN的矿仓入料口堵塞矿石识别定位研究. 有色金属科学与工程. 2022(01): 101-107 . 百度学术4. 陈健,李诗云,林丽,王猛,李佐勇. 模糊失真图像无参考质量评价综述. 自动化学报. 2022(03): 689-711 . 本站查看5. 段添耀,柯圆圆. 基于多种颜色模型的马赛克瓷砖选色研究. 江汉大学学报(自然科学版). 2022(04): 45-52 . 百度学术6. 来晓. 基于微调优化的深度学习在果蔬识别中的应用. 智能计算机与应用. 2021(04): 117-123 . 百度学术7. 贺杰,王桂梅,刘杰辉,杨立洁. 基于图像处理的皮带机上煤量体积计量. 计量学报. 2020(12): 1516-1520 . 百度学术8. 柴富杰,邓嘉敏,李建森,刘正发. 数码照相颜色数值与物质浓度辨识的数学模型. 数学的实践与认识. 2019(04): 305-311 . 百度学术9. 陈扬,李旦,张建秋. 互补色小波域图像质量盲评价方法. 电子学报. 2019(04): 775-783 . 百度学术10. 侯向宁,刘华春. 基于MSER和SVM以及强种子区域生长的车牌定位. 西安工程大学学报. 2019(02): 180-185 . 百度学术11. 梁长江,吴雪梅,王芳,宋朱军,张富贵. 基于无人机的田间地膜识别算法研究. 浙江农业学报. 2019(06): 1005-1011 . 百度学术12. 刘星星,王烁烁,徐丽明,袁全春,马帅,于畅畅,牛丛,陈晨,袁训腾,曾鉴. 基于OpenCV的动态葡萄干色泽实时识别. 农业工程学报. 2019(23): 177-184 . 百度学术13. 李可,陈洪亮,张生伟,万锦锦. 基于SVM的雾天图像分类技术研究. 电光与控制. 2018(03): 37-41+47 . 百度学术14. 丁丽. 基于粗集理论的车辆状态检测. 电脑知识与技术. 2018(01): 189-190+208 . 百度学术15. 胡晓丽,钟昊,李彤. 基于二值图像连通域的甘蔗螟虫识别计数方法. 桂林电子科技大学学报. 2018(03): 210-214 . 百度学术16. 张宪红,张春蕊. 基于六维前馈神经网络模型的图像增强算法. 山东大学学报(工学版). 2018(04): 10-19 . 百度学术17. 李玉华,李天华,牛子孺,吴彦强,张智龙,侯加林. 基于色饱和度三维几何特征的马铃薯芽眼识别. 农业工程学报. 2018(24): 158-164 . 百度学术18. 郑恩,林靖宇. 基于图像质量约束的无序图像关键帧提取. 计算机工程. 2017(11): 210-215 . 百度学术19. 任荣梓,高航. 基于混沌置乱的分量融合图像加密压缩方法. 计算机技术与发展. 2017(08): 106-109+114 . 百度学术20. 元朴康,况盛坤,王强,田全慧. 基于GRNN的模糊图像盲评价. 包装工程. 2016(13): 195-200 . 百度学术21. 李俊峰,张之祥,沈军民. 基于亮度统计的无参考图像质量评价. 光电子·激光. 2016(10): 1101-1110 . 百度学术22. 万泽慧. 试析网络图像的色彩管理要点. 无线互联科技. 2016(04): 32-34 . 百度学术其他类型引用(51)
-

 下载:
下载:

图(4)
计量
- 文章访问数: 2274
- HTML全文浏览量: 212
- PDF下载量: 680
- 被引次数: 73
