

A New Method of Anti-interference Matching Under Foreground Constraint for Target Tracking
-
摘要: 传统模型匹配跟踪方法没有充分考虑目标与所处图像的关系,尤其在复杂背景下,发生遮挡时易丢失目标.针对上述问题,提出一种前景约束下的抗干扰匹配(Anti-interference matching under foreground constraint,AMFC)目标跟踪方法.该方法首先选取图像帧序列前m帧进行跟踪训练,将每帧图像基于颜色特征分割成若干超像素块,利用均值聚类组建簇集合,并通过该集合建立判别外观模型;然后,采用EM(Expectation maximization)模型建立约束性前景区域,通过基于LK(Lucas-Kanade)光流法框架下的模型匹配寻找最佳匹配块.为了避免前景区域中相似物体的干扰,提出一种抗干扰匹配的决策判定算法提高匹配的准确率;最后,为了对目标的描述更加准确,提出一种新的在线模型更新算法,当目标发生严重遮挡时,在特征集中加入适当特征补偿,使得更新的外观模型更为准确.实验结果表明,该算法克服了目标形变、目标旋转移动、光照变化、部分遮挡、复杂环境的影响,具有跟踪准确和适应性强的特点.Abstract: The relation between a moving target and its image has not been fully considered in traditional model-matching tracking methods. The tracking drift problem may frequently occur when the target is occluded under a complex background. In this paper, a novel target tracking method, anti-interference matching under foreground constraint (AMFC), is proposed to solve this kind of problem. First, the method selects several initial frames from a vedio sequence for tracking training. Each of these frames is divided into several super-pixel blocks based on its color feature. These super-pixel blocks are combined into cluster sets by a mean shift algorithm to construct a discrimination appearance model. Then, a constrained foreground region is established using the expectation maximization (EM) model and a matching process is conducted based on the Lucas-Kanade (LK) optical flow method in order to select the optimum matching block. A decision-making algorithm is introduced to avoid the interference caused by similar targets in the foreground region, so as to increase the accuracy of the matching process. Moreover, in order to provide a more accurate target representation, an algorithm for appearance model online-updating is proposed. When a severe occlusion occurs, this algorithm can append appropriate feature compensations to the feature sets to improve the accuracy of the appearance model. Experimental results indicate that the proposed approach can provide superior tracking accuracy and adaptability, especially in the context of target deformation, target rotational movements, illumination changes, partial occlusion, and complex background.1) 本文责任编委 桑农
-
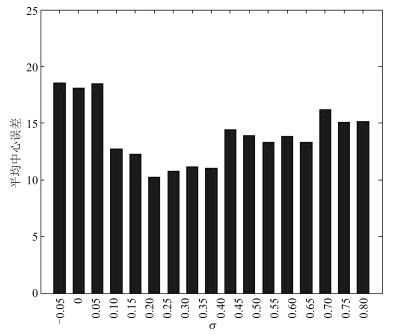
图 3 $\sigma$值与平均中心误差之间的关系
Fig. 3 The relationship between the $\sigma$ value and average center error

图 8 11种跟踪算法在12组图像序列中的跟踪结果
Fig. 8 Tracking results of the 11 algorithms in the 12 image sequences
表 1 实验图像序列信息
Table 1 The information of the test image sequences
图像序列 光照变化 遮挡 形变 复杂背景 旋转 Girl $\surd$ $\surd$ Deer $\surd$ $\surd$ Bird2 $\surd$ $\surd$ Football $\surd$ $\surd$ Lemming $\surd$ $\surd$ $\surd$ $\surd$ Woman $\surd$ $\surd$ Bolt $\surd$ $\surd$ $\surd$ CarDark $\surd$ David1 $\surd$ $\surd$ $\surd$ David2 $\surd$ Singer1 $\surd$ $\surd$ $\surd$ Basketball $\surd$ $\surd$ $\surd$ $\surd$  下载: 导出CSV
下载: 导出CSV
表 2 不同跟踪算法的平均中心误差
Table 2 Average center errors of different tracking algorithms
图像序列 ASLA FRAG SCM VTD L1APG CT OAB TLD LOT SPT AMFC Girl 36.76 24.27 $\mathbf{3.47}$ 8.64 25.51 19.45 4.68 7.66 20.28 4.73 4.76 Deer $\mathbf{6.74}$ 87.64 37.62 7.93 38.76 52.13 16.77 25.34 29.44 28.76 11.92 Bird2 20.12 14.96 11.53 46.24 25.44 37.87 26.16 10.23 47.61 $\mathbf{6.32}$ 6.97 Football 16.62 15.38 9.64 13.57 11.31 17.44 9.28 13.82 7.15 11.27 $\mathbf{6.28}$ Lemming 47.52 112.63 75.43 60.73 142.28 37.82 73.74 32.68 14.48 $\mathbf{9.41}$ 11.39 Woman 76.57 118.28 22.24 107.69 115.57 104.58 30.94 137.47 118.41 23.36 $\mathbf{21.71}$ Bolt 62.42 73.62 9.37 49.17 132.48 38.74 129.56 141.24 17.62 15.23 $\mathbf{8.44}$ CarDark 5.30 6.23 6.32 28.72 $\mathbf{3.44}$ 18.70 39.86 21.36 24.18 21.58 8.35 David1 $\mathbf{3.57}$ 84.41 4.38 48.95 5.76 9.69 31.26 8.92 37.84 23.29 9.36 David2 8.94 67.51 6.72 3.51 $\mathbf{3.23}$ 69.83 36.34 6.73 3.97 8.48 9.21 Singer1 45.62 57.83 17.85 12.53 49.84 31.07 36.27 22.17 16.64 $\mathbf{10.14}$ 10.25 Basketball 106.62 18.42 116.24 9.48 84.47 79.41 37.13 95.46 127.83 12.38 $\mathbf{7.73}$ 平均 36.40 56.77 26.73 33.10 53.17 43.06 39.33 43.59 38.79 14.58 9.70 注:粗体为最优结果.
下载: 导出CSV
表 3 不同跟踪算法的跟踪重叠率
Table 3 Tracking overlap ratio of different tracking algorithms
图像序列 ASLA FRAG SCM VTD L1APG CT OAB TLD LOT SPT AMFC Girl 0.31 0.41 $\mathbf{0.74}$ 0.69 0.39 0.29 0.73 0.56 0.43 0.71 0.73 Deer $\mathbf{0.69}$ 0.11 0.47 0.63 0.45 0.34 0.56 0.41 0.50 0.53 0.61 Bird2 0.66 0.70 0.74 0.41 0.63 0.44 0.58 0.80 0.43 $\mathbf{0.84}$ 0.83 Football 0.61 0.63 0.71 0.65 0.68 0.62 0.68 0.65 0.73 0.69 $\mathbf{0.75}$ Lemming 0.71 0.43 0.53 0.57 0.39 0.74 0.56 0.77 0.83 $\mathbf{0.86}$ 0.86 Woman 0.27 0.14 0.59 0.15 0.15 0.17 0.48 0.12 0.14 0.59 $\mathbf{0.61}$ Bolt 0.53 0.47 0.76 0.55 0.23 0.58 0.20 0.16 0.72 0.73 $\mathbf{0.77}$ CarDark $\mathbf{0.82}$ 0.82 0.81 0.43 $\mathbf{0.82}$ 0.72 0.38 0.46 0.44 0.43 0.79 David1 $\mathbf{0.83}$ 0.23 0.82 0.53 0.80 0.77 0.57 0.79 0.55 0.62 0.76 David2 0.68 0.21 0.69 0.73 $\mathbf{0.74}$ 0.02 0.33 0.69 0.73 0.68 0.64 Singer1 0.58 0.55 0.73 0.74 0.57 0.64 0.63 0.69 0.72 $\mathbf{0.76}$ 0.76 Basketball 0.19 0.63 0.17 0.67 0.25 0.27 0.59 0.21 0.14 0.68 $\mathbf{0.69}$ 平均 0.57 0.45 0.65 0.56 0.51 0.47 0.52 0.53 0.53 0.68 0.73
下载: 导出CSV
表 4 不同跟踪算法的平均运行速度
Table 4 Average running speeds of different tracking algorithms
图像序列 ASLA FRAG SCM VTD L1APG CT OAB TLD LOT SPT AMFC Girl 5.31 6.32 0.65 2.74 1.76 38.21 17.51 26.84 0.79 0.47 3.68 Deer 6.24 4.78 0.97 2.67 1.64 31.63 14.72 27.17 0.83 0.41 3.56 Bird2 5.74 5.43 0.67 2.58 1.49 27.06 9.94 26.58 0.65 0.56 3.09 Football 6.15 5.68 0.61 3.14 1.61 36.73 19.67 26.63 0.93 0.76 3.41 Lemming 6.78 6.27 0.69 2.77 1.75 28.15 10.46 26.70 0.71 0.37 3.39 Woman 8.45 6.41 0.57 2.16 1.53 32.42 11.31 26.32 0.66 0.43 4.37 Bolt 7.04 3.97 0.46 2.21 1.63 27.18 8.66 24.74 0.61 0.29 3.06 CarDark 7.23 4.23 0.48 2.49 1.74 26.79 10.35 25.13 0.59 0.36 2.95 David1 7.84 4.48 0.53 3.47 2.03 34.22 14.75 26.47 0.67 0.54 3.86 David2 5.87 5.25 0.48 2.68 1.44 36.36 16.68 25.89 0.73 0.66 2.97 Singer1 5.31 4.96 0.52 2.91 1.73 28.19 10.43 26.31 0.71 0.43 3.42 Basketball 7.91 6.23 0.89 2.34 2.04 25.81 9.09 24.53 0.62 0.34 2.89
下载: 导出CSV
-
[1] 尹宏鹏, 陈波, 柴毅, 刘兆栋.基于视觉的目标检测与跟踪综述.自动化学报, 2016, 42(10):1466-1489 http://www.aas.net.cn/CN/Y2016/V42/I10/1466Yin Hong-Peng, Chen Bo, Chai Yi, Liu Zhao-Dong. Vision-based object detection and tracking:a review. Acta Automatica Sinica, 2016, 42(10):1466-1489 http://www.aas.net.cn/CN/Y2016/V42/I10/1466 [2] 黄丹丹, 孙怡.基于判别性局部联合稀疏模型的多任务跟踪.自动化学报, 2016, 42(3):402-415 http://www.aas.net.cn/CN/Y2016/V42/I3/402Huang Dan-Dan, Sun Yi. Tracking via multitask discriminative local joint sparse appearance model. Acta Automatica Sinica, 2016, 42(3):402-415 http://www.aas.net.cn/CN/Y2016/V42/I3/402 [3] 徐建强, 陆耀.一种基于加权时空上下文的鲁棒视觉跟踪算法.自动化学报, 2015, 41(11):1901-1912 http://www.aas.net.cn/CN/Y2015/V41/I11/1901Xu Jian-Qiang, Lu Yao. Robust visual tracking via weighted spatio-temporal context learning. Acta Automatica Sinica, 2015, 41(11):1901-1912 http://www.aas.net.cn/CN/Y2015/V41/I11/1901 [4] Yuan X H, Kong L B, Feng D C, Wei Z C. Automatic feature point detection and tracking of human actions in time-of-flight videos. IEEE/CAA Journal of Automatica Sinica, 2017, 4(4):677-685 doi: 10.1109/JAS.2017.7510625 [5] Zoidi O, Tefas A, Pitas I. Visual object tracking based on local steering kernels and color histograms. IEEE Transactions on Circuits and Systems for Video Technology, 2013, 23(5):870-882 doi: 10.1109/TCSVT.2012.2226527 [6] Duffner S, Garcia C. Using discriminative motion context for online visual object tracking. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 26(12):2215-2225 doi: 10.1109/TCSVT.2015.2504739 [7] Wang X C, Tuüretken E, Fleuret F, Fua P. Tracking interacting objects using intertwined flows. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(11):2312-2326 doi: 10.1109/TPAMI.2015.2513406 [8] Khan Z H, Gu I Y H. Nonlinear dynamic model for visual object tracking on Grassmann manifolds with partial occlusion handling. IEEE Transactions on Cybernetics, 2013, 43(6):2005-2019 doi: 10.1109/TSMCB.2013.2237900 [9] 王美华, 梁云, 刘福明, 罗笑南.部件级表观模型的目标跟踪方法.软件学报, 2015, 26(10):2733-2747 http://doi.cnki.net/Resolution/Handler?doi=10.13328/j.cnki.jos.004737Wang Mei-Hua, Liang Yun, Liu Fu-Ming, Luo Xiao-Nan. Object tracking based on component-level appearance model. Journal of Software, 2015, 26(10):2733-2747 http://doi.cnki.net/Resolution/Handler?doi=10.13328/j.cnki.jos.004737 [10] 张焕龙, 胡士强, 杨国胜.基于外观模型学习的视频目标跟踪方法综述.计算机研究与发展, 2015, 52(1):177-190 doi: 10.7544/issn1000-1239.2015.20130995Zhang Huan-Long, Hu Shi-Qiang, Yang Guo-Sheng. Video object tracking based on appearance models learning. Journal of Computer Research and Development, 2015, 52(1):177-190 doi: 10.7544/issn1000-1239.2015.20130995 [11] 施华, 李翠华, 韦凤梅, 王华伟.基于像素可信度和空间位置的运动目标跟踪基于外观模型学习的视频目标跟踪方法综述.计算机研究与发展, 2005, 42(10):1726-1732 http://cdmd.cnki.com.cn/Article/CDMD-10561-1012452907.htmShi Hua, Li Cui-Hua, Wei Feng-Mei, Wang Hua-Wei. Moving object tracking based on location and confidence of pixels. Journal of Computer Research and Development, 2005, 42(10):1726-1732 http://cdmd.cnki.com.cn/Article/CDMD-10561-1012452907.htm [12] Babenko B, Yang M H, Belongie S. Visual tracking with online multiple instance learning. In: Proceedings of the 22nd IEEE International Conference on Computer Vision and Pattern Recognition. Miami, Florida, USA: IEEE, 2009. 983-990 [13] Oron S, Bar-Hillel A, Levi D, Avidan S. Locally orderless tracking. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 1940-1947 [14] 徐如意, 陈靓影.稀疏表示的Lucas-Kanade目标跟踪.中国图象图形学报, 2013, 18(3):283-289 doi: 10.11834/jig.20130306Xu Ru-Yi, Chen Liang-Ying. Lucas-Kanade tracking based on sparse representation. Journal of Image and Graphics, 2013, 18(3):283-289 doi: 10.11834/jig.20130306 [15] Wang S, Lu H C, Yang F, Yang M H. Superpixel tracking. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 1323-1330 [16] Levinshtein A, Stere A, Kutulakos K N, Fleet D J, Dickinson S J, Siddiqi K, et al. Turbopixels:fast superpixels using geometric flows. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12):2290-2297 doi: 10.1109/TPAMI.2009.96 [17] Baker Simon B, Matthews Iain M. Lucas-Kanade 20 years on:a unifying framework. International Journal of Computer Vision, 2004, 56(3):221-255 doi: 10.1023/B:VISI.0000011205.11775.fd [18] 刘万军, 刘大千, 费博雯, 曲海成.基于局部模型匹配的几何活动轮廓跟踪.中国图象图形学报, 2015, 20(5):652-663 doi: 10.11834/jig.20150508Liu Wan-Jun, Liu Da-Qian, Fei Bo-Wen, Qu Hai-Cheng. Geometric active contour tracking based on locally model matching. Journal of Image and Graphics, 2015, 20(5):652-663 doi: 10.11834/jig.20150508 [19] Comaniciu D, Meer P. Mean shift:a robust approach toward feature space analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(45):603-619 [20] Wu Y, Lim J, Yang M H. Online object tracking: a benchmark. In: Proceedings of the 2013 IEEE International Conference on Computer Vision and Pattern Recognition. Oregon, Portland, USA: IEEE, 2013. 2411-2418 [21] Jia X, Lu H C, Yang M H. Visual tracking via adaptive structural local sparse appearance model. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 1822-1829 [22] Adam A, Rivlin E, Shimshoni I. Robust fragments-based tracking using the integral histogram. In: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2006. 798-805 [23] Zhong W, Lu H C, Yang M H. Robust object tracking via sparsity-based collaborative model. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 1838-1845 [24] Kwon J, Lee K M. Visual tracking decomposition. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 1269-1276 [25] Bao C L, Wu Y, Ling H B, Ji H. Real time robust L1 tracker using accelerated proximal gradient approach. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 1830-1837 [26] Zhang K H, Zhang L, Yang M H. Real-time compressive tracking. In: Proceedings of the 2012 European Conference on Computer Vision. Florence, Italy: Springer, 2012. 864-877 [27] Grabner H, Grabner M, Bischof H. Real-time tracking via on-line boosting. In: Proceedings of the 2006 British Machine Vision Conference. Edinburgh, UK: BMVA Press, 2006. 47-56 [28] Kalal Z, Mikolajczyk K, Matas J. Tracking-learning-detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(7):1409-1422 doi: 10.1109/TPAMI.2011.239 [29] 高君宇, 杨小汕, 张天柱, 徐常胜.基于深度学习的鲁棒性视觉跟踪方法.计算机学报, 2016, 39(7):1419-1434 doi: 10.11897/SP.J.1016.2016.01419Gao Jun-Yu, Yang Xiao-Shan, Zhang Tian-Zhu, Xu Chang-Sheng. Robust visual tracking method via deep learning. Chinese Journal of Computers, 2016, 39(7):1419-1434 doi: 10.11897/SP.J.1016.2016.01419 [30] 李庆武, 朱国庆, 周妍, 霍冠英.基于特征在线选择的目标压缩跟踪算法.自动化学报, 2015, 41(11):1961-1970 http://www.aas.net.cn/CN/Y2015/V41/I11/1961Li Qing-Wu, Zhu Guo-Qing, Zhou Yan, Huo Guan-Ying. Object compressive tracking via online feature selection. Acta Automatica Sinica, 2015, 41(11):1961-1970 http://www.aas.net.cn/CN/Y2015/V41/I11/1961 -

 下载:
下载:





计量
- 文章访问数: 2497
- HTML全文浏览量: 261
- PDF下载量: 679
- 被引次数: 0
