

-
摘要: 针对现有背景建模算法难以处理场景非平稳变化的问题,提出一种基于长时间视频序列的背景建模方法.该方法包括训练、检索、更新三个主要步骤.在训练部分,首先将长时间视频分段剪辑并计算对应的背景图,然后通过图像降采样和降维找到背景描述子,并利用聚类算法对背景描述子进行分类,生成背景记忆字典.在检索部分,利用前景像素比例设计非平稳状态判断机制,如果发生非平稳变换,则计算原图描述子与背景字典中描述子之间的距离,距离最近的背景描述子对应的背景图片即为此时背景.在更新部分,利用前景像素比例设计更新判断机制,如果前景比例始终过大,则生成新背景,并更新背景字典以及背景图库.当出现非平稳变化时(如光线突变),本算法能够将背景模型恢复问题转化为背景检索问题,确保背景模型的稳定获得.将该框架与短时空域信息背景模型(以ViBe、MOG为例)融合,重点测试非平稳变化场景下的背景估计和运动目标检测结果.在多个视频序列上的测试结果表明,该框架可有效处理非平稳变化,有效改善目标检测效果,显著降低误检率.Abstract: Considering the difficulties to deal with scene non-stationary variation of proposed background modeling methods, we propose a method for moving targets by exploiting periodic spatial-temporal feature from a long-term video. We use three steps, training, retrieval and updating, to establish a background modeling framework for long-term video sequences. In the training step, we cut hours of video into a number of minute clips and compute the average background to generate a series of background images. After performing resize and dimension reduction on background images, a set of descriptors are obtained for the clustering process, where background descriptors are classified into different clusters and each cluster is represented by a typical background image in the background memory dictionary. In the retrieval step, we use foreground pixel ratio as a criterion to determine sudden change of background. For those scenarios, the current image is converted to a background descriptor and compared to the descriptors stored in retrieval database to find a suitable background frame. If no similar background descriptor is found in the database, a new background image is to be generated and added into our dictionary and background image database. Using this framework, the background modeling problem is converted to a background retrieval problem when non-stationary change happens especially for the indoor scene with quick illumination changes such as light on/off. Combining the popular ViBe or MOG algorithm with our framework, we test a number of long term video sequences and achieve better results in terms of tracking targets and the false detection rate.1) 本文责任编委 桑农
-
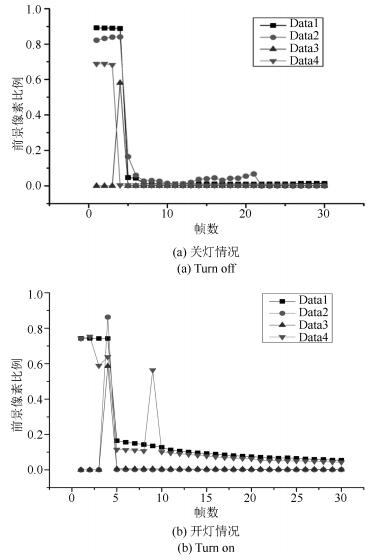
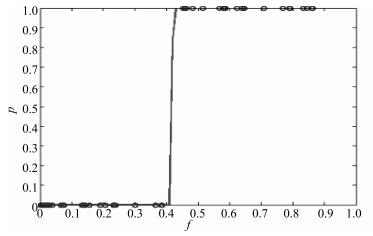
图 10 更新背景字典阈值$T_{u}$的确定
Fig. 10 Determination of threshold $T_{u}$ for updating background dictionary

图 12 运动目标检测效果对比图(ViBe开灯)
Fig. 12 Moving object detection comparison charts (ViBe turns on the lights
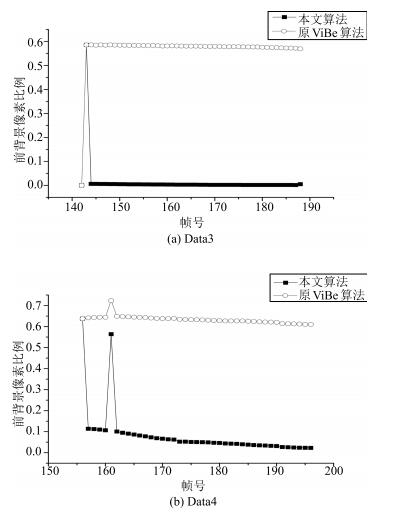
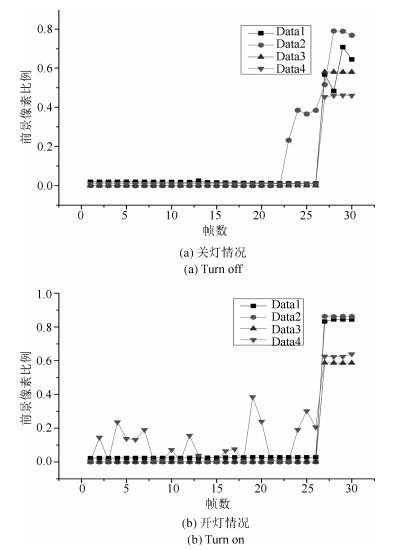
图 14 前景像素比例变化对比图(对应图 12 (c) $\sim$(d))
Fig. 14 Comparison chart of foreground pixel ratio (Corresponding to Fig. 12 (c) $\sim$ (d))

图 11 运动目标检测效果对比图(ViBe关灯)
Fig. 11 Moving object detection comparison charts (ViBe turns off the lights)
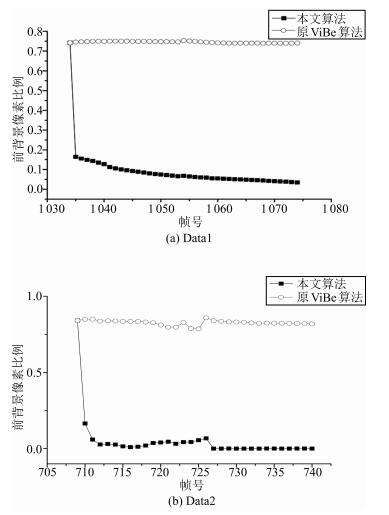
图 13 前景像素比例变化对比图(对应图 11 (a) $\sim$ (b))
Fig. 13 Comparison chart of foreground pixel ratio (Corresponding to Fig. 11 (a) $\sim$ (b))

图 15 运动目标检测效果对比图(MOG关灯)
Fig. 15 Moving object detection comparison charts (MOG turns off the lights)

图 16 运动目标检测效果对比图(MOG开灯)
Fig. 16 Moving object detection comparison charts (MOG turns on the lights)
表 1 算法处理速度(fps)
Table 1 Processing times of algorithm (fps)
算法 Data1 Data2 Data3 Data4 原ViBe算法 25.96 63.79 62.44 14.49 本文算法 25.65 63.13 59.48 14.40  下载: 导出CSV
下载: 导出CSV
-
[1] 储珺, 杨樊, 张桂梅, 汪凌峰.一种分步的融合时空信息的背景建模.自动化学报, 2014, 40(4):731-743 http://www.aas.net.cn/CN/abstract/abstract18339.shtmlChu Jun, Yang Fan, Zhang Gui-Mei, Wang Ling-Feng. A stepwise background subtraction by fusion spatio-temporal information. Acta Automatica Sinica, 2014, 40(4):731-743 http://www.aas.net.cn/CN/abstract/abstract18339.shtml [2] 牛化康, 何小海, 汪晓飞, 张峰, 吴小强.一种改进的ViBe目标检测算法.四川大学学报(工程科学版), 2014, 46(S2):104-108 http://www.cqvip.com/QK/90462X/2014S2/83677672504849528350484957.htmlNiu Hua-Kang, He Xiao-Hai, Wang Xiao-Fei, Zhang Feng, Wu Xiao-Qiang. An improved ViBe object detection algorithm. Journal of Sichuan University (Engineering Science Edition), 2014, 46(S2):104-108 http://www.cqvip.com/QK/90462X/2014S2/83677672504849528350484957.html [3] Wren C R, Azarbayejani A, Darrell T, Pentland A P. Pfinder:real-time tracking of the human body. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(7):780-785 doi: 10.1109/34.598236 [4] Stauffer C, Grimson W E L. Adaptive background mixture models for real-time tracking. In: Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Fort Collins, Co, USA: IEEE, 1999, 2: 252 [5] Wang Y, Loe K F, Wu J K. A dynamic conditional random field model for foreground and shadow segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(2):279-289 doi: 10.1109/TPAMI.2006.25 [6] Kim K, Chalidabhongse T H, Harwood D, Davis L. Background modeling and subtraction by codebook construction. In: Proceedings of the 2004 International Conference on Image Processing. Singapore: IEEE, 2004, 5: 3061-3064 [7] Barnich O, Van Droogenbroeck M. ViBe:a universal background subtraction algorithm for video sequences. IEEE Transactions on Image Processing, 2011, 20(6):1709-1724 doi: 10.1109/TIP.2010.2101613 [8] St-Charles P L, Bilodeau G A, Bergevin R. Subsense:a universal change detection method with local adaptive sensitivity. IEEE Transactions on Image Processing, 2015, 24(1):359-373 doi: 10.1109/TIP.2014.2378053 [9] van der Maaten L J P, Postma E O, van den Herik H J. Dimensionality reduction:a comparative review. Journal of Machine Learning Research, 2007, 10(1):66-71 [10] Huang H C, Chuang Y Y, Chen C S. Affinity aggregation for spectral clustering. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 773-780 [11] Arthur D, Vassilvitskii S. k-means++: the advantages of careful seeding. In: Proceedings of the 18th annual ACM-SIAM Symposium on Discrete Algorithms. Philadelphia, PA, USA: ACM, 2007. 1027-1035 [12] Goyette N, Jodoin P M, Porikli F, Konrad J, Ishwar P. Changedetection. net: a new change detection benchmark dataset. In: Proceedings of the 2012 IEEE Computer Society Conference on Workshop on Computer Vision and Pattern Recognition Workshops. Providence, RI, USA: IEEE, 2012. 1-8 [13] 苏雅茹. 高维数据的维数约简算法研究[博士学位论文], 中国科学技术大学, 中国, 2012Su Ya-Ru. Research on Dimensionality Reduction of High-Dimensional Data[Ph. D. dissertation], University of Science and Technology of China, China, 2012 [14] 蔡晓妍, 戴冠中, 杨黎斌.谱聚类算法综述.计算机科学, 2008, 35(7):14-18 doi: 10.3969/j.issn.1002-137X.2008.07.004Cai Xiao-Yan, Dai Guan-Zhong, Yang Li-Bin. Survey on spectral clustering algorithms. Computer Science, 2008, 35(7):14-18 doi: 10.3969/j.issn.1002-137X.2008.07.004 [15] Zhu X T, Loy C C, Gong S G. Constructing robust affinity graphs for spectral clustering. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 1450-1457 [16] Smiatacz M. Eigenfaces, Fisherfaces, Laplacianfaces, Marginfaces——how to face the face verification task. In: Proceedings of the 8th International Conference on Computer Recognition Systems CORES. Switzerland: Springer, 2013. 187-196 [17] Ng A Y, Jordan M I, Weiss Y. On spectral clustering: analysis and an algorithm. In: Proceedings of Advances in Neural Information Processing Systems 14: Proceedings of the 2001 Conference. Vancouver, British Columbia, Canada: MIT Press, 2001, 14: 849-856 [18] Toyama K, Krumm J, Brumitt B, Meyers B. Wallflower: principles and practice of background maintenance. In: Proceedings of the 7th IEEE International Conference on Computer Vision. Kerkyra, Greece: IEEE, 1991, 1: 255-261 [19] Chen Y T, Chen C S, Huang C R, Huang Y P. Efficient hierarchical method for background subtraction. Pattern Recognition, 2007, 40(10):2706-2715 doi: 10.1016/j.patcog.2006.11.023 -

 下载:
下载:




计量
- 文章访问数: 2484
- HTML全文浏览量: 290
- PDF下载量: 474
- 被引次数: 0
