

Conditional Random Forests for Spontaneous Smile Detection in Unconstrained Environment
-
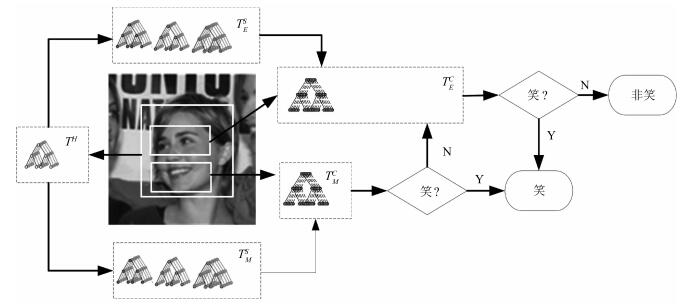
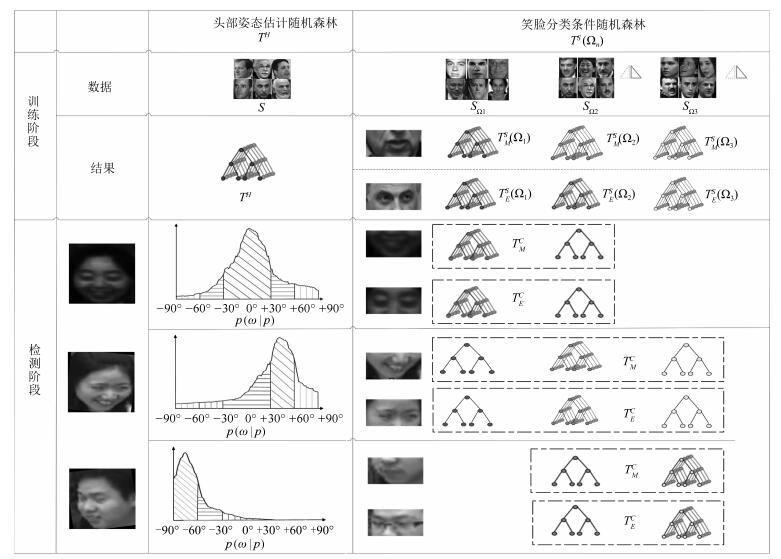
摘要: 为减少非约束环境下头部姿态多样性对笑脸检测带来的不利影响,提出一种基于条件随机森林(Conditional random forests,CRF)的笑脸检测方法.首先,以头部姿态作为隐含条件划分数据空间,构建基于条件随机森林的笑脸分类器;其次,以K-Means聚类方法确定条件随机森林分类器的分类边界;最后,分别从嘴巴区域和眉眼区域采集图像子块训练两组条件随机森林构成层级式结构进行笑脸检测.本文的笑脸检测方法在GENKI-4K、LFW和自备课堂场景(CCNU-Classroom)数据集上分别取得了91.14%,90.73%和85.17%的正确率,优于现有基于支持向量机、AdaBoost和随机森林的笑脸检测方法.Abstract: To reduce the negative influence of smile detection due to head pose diversity in unconstrained environment, a conditional random forests (CRF) based approach is proposed to detect spontaneous smile. First, the conditional random forests based approach is presented to learn the relations between image patches and the smile/non-smile features conditional to head poses. Image patches from different eye and mouth regions are separately trained for two different conditional random forests. Then, a two-layer smile/non-smile classifier based on the two conditional random forests is constructed. Furthermore, a K-means based voting method is introduced to improve the discrimination capability of the classifier. Experiments are carried out with spontaneous facial expression datasets including GENKI-4K, LFW and CCNU-Classroom, and the proposed approach reaches 91.14%, 90.73% and 85.17% accuracy rates, respectively, on these datasets. The proposed approach outperforms the SVM-based, AdaBoost-based and random forest based methods.1) 本文责任编委 黄庆明
-
表 1 本文方法与文献[15-16]在GENKI-4K数据集上的比较
Table 1 The proposed approach compared with [15-16] on GENKI-4K dataset
 下载: 导出CSV
下载: 导出CSV
表 2 头部姿态估计在LFW和CCNU-Classroom数据集上的准确率(%)
Table 2 Accuracies of head pose estimation on LFW and CCNU-Classroom datasets (%)
头部姿态 LFW CCNU-Classroom 正脸 87.88 86.41 微侧 80.00 81.60 侧脸 83.73 83.33 混合 82.72 83.41
下载: 导出CSV
表 3 不同笑脸检测算法在LFW和CCNU-Classroom数据集上的准确率(%)
Table 3 Comparisons of accuracies of different smile detection algorithms on LFW and CCNU-Classroom datasets (%)
LFW LFW CCNU-Classroom 正脸 微侧 侧脸 混合 正脸 微侧 侧脸 混合 本文 92.86 90.67 89.04 90.73 88.89 86.96 79.66 85.17 SVM 85.63 77.00 81.85 83.25 77.56 74.51 68.53 73.52 RF 78.00 77.14 85.99 81.74 78.89 79.85 59.17 72.38 AdaBoost 75.00 72.35 68.54 71.96 70.00 65.56 61.24 66.27
下载: 导出CSV
表 4 不同图像子块采样方式在LFW数据集上的笑脸检测准确率(%)
Table 4 Accuracies of smile detection with different image sub-regions on LFW dataset (%)
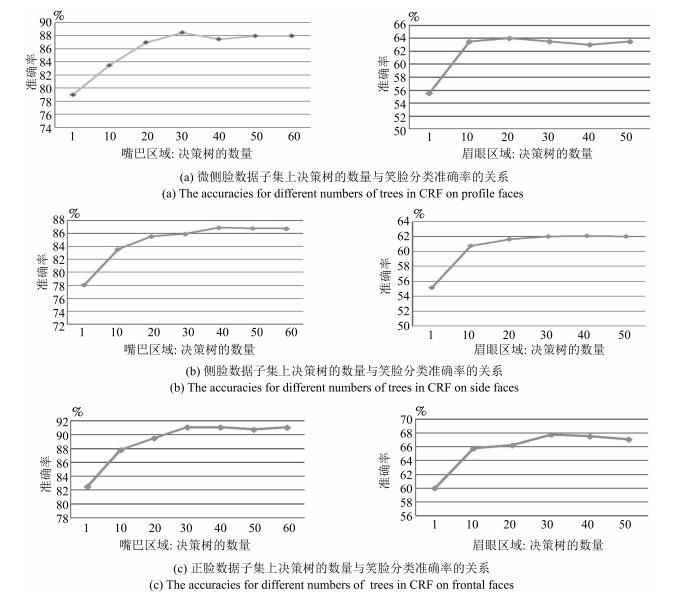
头部姿态 整个人脸 嘴巴区域 眉眼区域 嘴巴十眉眼 正脸 78.00 91.08 67.74 95.09 微侧 75.50 88.50 64.50 90.05 侧脸 72.08 86.86 62.08 86.86 混合 74.79 88.71 64.59 90.47
下载: 导出CSV
表 5 不同嘴巴和眉眼区域定位方法的笑脸检测准确率(%)
Table 5 Accuracies of smile detection using different approaches to locate eyes and mouth regions (%)
方法 正脸 微侧 侧脸 混合 几何关系粗略定位 95.09 90.05 86.86 90.47 人脸特征点精确定位 95.79 91.00 88.74 91.37
下载: 导出CSV
表 6 使用不同决策边界方法对应的笑脸检测准确率(%)
Table 6 Accuracies of smile detection using different decision boundary methods (%)
LFW CCNU-Classroom 头部姿态 K-Means 高斯 决策桩 K-Means 高斯 决策桩 正脸 95.09 90.78 52.91 88.89 87.78 75.56 微测 90.50 88.50 80.00 86.96 85.04 71.43 侧脸 86.86 85.23 74.22 79.66 77.94 61.90 混合 90.81 88.17 69.04 85.17 83.59 69.63
下载: 导出CSV
-
[1] Sénéchal T, Turcot J, el Kaliouby R. Smile or smirk? Automatic detection of spontaneous asymmetric smiles to understand viewer experience. In: Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). Shanghai, China: IEEE, 2013. 1-8 [2] Chen J Y, Luo N, Liu Y Y, Liu L Y, Zhang K, Kolodziej J. A hybrid intelligence-aided approach to affect-sensitive e-learning. Computing, 2016, 98(1-2):215-233 doi: 10.1007/s00607-014-0430-9 [3] Shah R, Kwatra V. All smiles: automatic photo enhancement by facial expression analysis. In: Proceedings of the 9th European Conference on Visual Media Production (CVMP). London, UK: ACM, 2012. 1-10 [4] Whitehill J, Littlewort G, Fasel I, Bartlett M, Movellan J. Toward practical smile detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(11):2106-2111 doi: 10.1109/TPAMI.2009.42 [5] Sariyanidi E, Gunes H, Cavallaro A. Automatic analysis of facial affect:a survey of registration, representation, and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(6):1113-1133 doi: 10.1109/TPAMI.2014.2366127 [6] 孙晓, 潘汀, 任福继.基于ROI-KNN卷积神经网络的面部表情识别.自动化学报, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtmlSun Xiao, Pan Ting, Ren Fu-Ji. Facial expression recognition using ROI-KNN deep convolutional neural networks. Acta Automatica Sinica, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtml [7] Tong Y, Chen J X, Ji Q. A unified probabilistic framework for spontaneous facial action modeling and understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(2):258-273 doi: 10.1109/TPAMI.2008.293 [8] Vick S J, Waller B M, Parr L A, Pasqualini M C S, Bard K. A cross-species comparison of facial morphology and movement in humans and chimpanzees using the facial action coding system (FACS). Journal of Nonverbal Behavior, 2007, 31(1):1-20 doi: 10.1007/s10919-006-0017-z [9] Valstar M, Pantic M. Fully automatic recognition of the temporal phases of facial actions. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2012, 42(1):28-43 doi: 10.1109/TSMCB.2011.2163710 [10] 解仑, 卢亚楠, 姜波, 孙铁, 王志良.基于人脸运动单元及表情关系模型的自动表情识别.北京理工大学学报, 2016, 36(2):163-169 http://www.cnki.com.cn/Article/CJFDTotal-BJLG201602011.htmXie Lun, Lu Ya-Nan, Jiang Bo, Sun Tie, Wang Zhi-Liang. Expression automatic recognition based on facial action units and expression relationship model. Transactions of Beijing Institute of Technology, 2016, 36(2):163-169 http://www.cnki.com.cn/Article/CJFDTotal-BJLG201602011.htm [11] 王磊, 邹北骥, 彭小宁.针对表情动作单元跟踪的隧道隐变量法.自动化学报, 2009, 35(2):198-201 http://www.aas.net.cn/CN/abstract/abstract18060.shtmlWang Lei, Zou Bei-Ji, Peng Xiao-Ning. Tunneled latent variables method for facial action unit tracking. Acta Automatica Sinica, 2009, 35(2):198-201 http://www.aas.net.cn/CN/abstract/abstract18060.shtml [12] Yang P, Liu Q S, Metaxas D N. Exploring facial expressions with compositional features. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, CA, USA: IEEE, 2010. 2638-2644 [13] Walecki R, Rudovic O, Pavlovic V, Pantic M. Variable-state latent conditional random fields for facial expression recognition and action unit detection. In: Proceedings of the 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). Ljubljana, Slovenia: IEEE, 2015. 1-8 [14] Shimada K, Matsukawa T, Noguchi Y, Kurita T. Appearance-based smile intensity estimation by cascaded support vector machines. In: Proceedings of the 2010 Revised Selected Papers, Part I Asian Conference on Computer Vision (ACCV). Queenstown, New Zealand: Springer, 2010. 277-286 [15] Shan C F. Smile detection by boosting pixel differences. IEEE Transactions on Image Processing, 2012, 21(1):431-436 doi: 10.1109/TIP.2011.2161587 [16] An L, Yang S F, Bhanu B. Efficient smile detection by extreme learning machine. Neurocomputing, 2015, 149:354-363 doi: 10.1016/j.neucom.2014.04.072 [17] Huang G B, Zhou H M, Ding X J, Zhang R. Extreme learning machine for regression and multiclass classification. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2012, 42(2):513-529 doi: 10.1109/TSMCB.2011.2168604 [18] Gao Y, Liu H, Wu P P, Wang C. A new descriptor of gradients self-similarity for smile detection in unconstrained scenarios. Neurocomputing, 2016, 174:1077-1086 doi: 10.1016/j.neucom.2015.10.022 [19] Liu H, Gao Y, Wu P. Smile detection in unconstrained scenarios using self-similarity of gradients features. In: Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP). Paris, France: IEEE, 2014. 1455-1459 [20] El Meguid M K A, Levine M D. Fully automated recognition of spontaneous facial expressions in videos using random forest classifiers. IEEE Transactions on Affective Computing, 2014, 5(2):141-154 doi: 10.1109/TAFFC.2014.2317711 [21] 刘帅师, 田彦涛, 万川.基于Gabor多方向特征融合与分块直方图的人脸表情识别方法.自动化学报, 2011, 37(12):1455-1463 http://www.aas.net.cn/CN/abstract/abstract17643.shtmlLiu Shuai-Shi, Tian Yan-Tao, Wan Chuan. Facial expression recognition method based on gabor multi-orientation features fusion and block histogram. Acta Automatica Sinica, 2011, 37(12):1455-1463 http://www.aas.net.cn/CN/abstract/abstract17643.shtml [22] Dapogny A, Bailly K, Dubuisson S. Pairwise conditional random forests for facial expression recognition. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, USA: IEEE, 2015, 3783-3791 [23] Yin L J, Wei X Z, Sun Y, Wang J, Rosato M J. A 3D facial expression database for facial behavior research. In: Proceedings of the 7th IEEE International Conference on Automatic Face and Gesture Recognition. Southampton, Britain: IEEE, 2006. 211-216 [24] Huang G B, Mattar M, Berg T, Learned-Miller E. Labeled faces in the wild:a database for studying face recognition in unconstrained environments. Technical Report, University of Massachusetts, USA, 2007. [25] Breiman L. Random forests. Machine Learning, 2001, 45(1):5-32 doi: 10.1023/A:1010933404324 [26] Liu Y Y, Chen J Y, Su Z M, Luo Z Z, Luo N, Liu L Y, Zhang K. Robust head pose estimation using Dirichlet-tree distribution enhanced random forests. Neurocomputing, 2015, 173:42-53 https://www.sciencedirect.com/science/article/pii/S0925231215010413 [27] Sun M, Kohli P, Shotton J. Conditional regression forests for human pose estimation. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA: IEEE, 2012. 3394-3401 [28] Dantone M, Gall J, Fanelli G, Van Gool L. Real-time facial feature detection using conditional regression forests. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA, 2012. 2578-2585 [29] Du S Y, Zheng N N, You Q B, Wu Y, Yuan M J, Wu J J. Rotated Haar-Like features for face detection with in-plane rotation. In: Proceedings of the 12th International Conference, Virtual Systems and Multimedia (VSMM). Xi'an, China: Springer, 2006. 128-137 [30] Du S Y, Liu J, Liu Y H, Zhang X T, Xue J R. Precise glasses detection algorithm for face with in-plane rotation. Multimedia Systems, 2017, 23(3):293-302 doi: 10.1007/s00530-015-0483-4 [31] Wayne I, Langley P. Induction of one-level decision trees. In: Proceedings of the 9th International Workshop on Machine Learning. San Francisco, CA, USA: Morgan Kaufmann, 1992. 233-240 [32] Viola P, Jones M J. Robust real-time face detection. International Journal of Computer Vision, 2004, 57(2):137-154 doi: 10.1023/B:VISI.0000013087.49260.fb [33] Chang C C, Lin C J. Training v-support vector classifiers:theory and algorithms. Neural Computation, 2001, 13(9):2119-2147 doi: 10.1162/089976601750399335 -

 下载:
下载:


计量
- 文章访问数: 2339
- HTML全文浏览量: 290
- PDF下载量: 816
- 被引次数: 0
