

-
摘要: 针对网络上出现越来越多的多模态数据,如何在海量数据中检索不同模态的数据成为一个新的挑战.哈希方法把数据映射到Hamming空间,大大降低了计算复杂度,为海量数据的跨模态检索提供了一条有效的路径.然而,大部分现存方法生成的哈希码不包含任何语义信息,从而导致算法性能的下降.为了解决这个问题,本文提出一种基于映射字典学习的跨模态哈希检索算法.首先,利用映射字典学习一个共享语义子空间,在子空间保持数据模态间的相似性.然后,提出一种高效的迭代优化算法得到哈希函数,但是可以证明问题的解并不是唯一的.因此,本文提出通过学习一个正交旋转矩阵最小化量化误差,得到性能更好的哈希函数.最后,在两个公开数据集上的实验结果说明了该算法优于其他现存方法.Abstract: With the sharp increasing of multi-modal data on the internet, retrieving samples with different modalities has become a challenge. hashing methods, which map the data to Hamming space to reduce computational cost, can provide an effective way for large-scale cross-modal retrieval. However, the hashing codes of most existing methods do not contain any semantic information, which degrades the performance. To address this issue, we propose a cross-modal hashing method, termed projective dictionary learning hashing (PDLH) method. Firstly, projective dictionary learning is employed to learn a sharing semantic subspace by preserving the inter-modal similarity. Then an efficient iterative optimal algorithm is proposed to gain hashing functions. However, the solution is not a unique solution, as proven in this paper. To further improve the performance of the proposed method, an orthogonal rotation matrix is learned by minimizing the quantization loss for better hashing functions. Finally, experimental results on two widely used datasets show that the performance of the proposed method is better than those of the existing methods.
-
Key words:
- Cross-modal retrieval /
- hashing /
- project dictionary learning /
- Hamming space
1) 本文责任编委 朱军 -

图 2 码长16 bits在Wiki数据集的PR曲线图
Fig. 2 PR curves on Wiki dataset with the code length fixed to 16 bits

图 3 码长32 bits在Wiki数据集的PR曲线图
Fig. 3 PR curves on Wiki dataset with the code length fixed to 32 bits
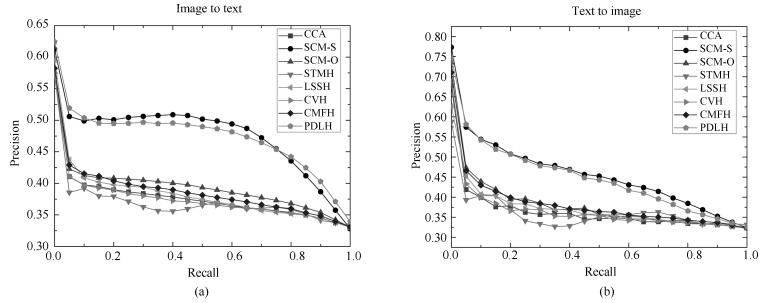
图 4 码长16 bits在NUS-WIDE数据集的PR曲线图
Fig. 4 PR curves on NUS-WIDE dataset with the code length fixed to 16 bits
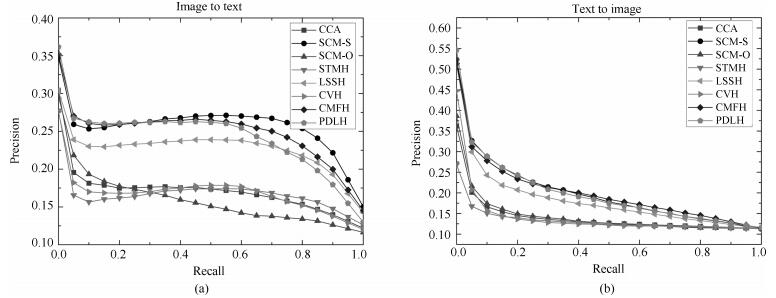
图 5 码长32 bits在NUS-WIDE数据集的PR曲线图
Fig. 5 PR curves on NUS-WIDE dataset with the code length fixed to 32 bits
表 1 图像检索文本和文本检索图像任务在Wiki数据集上的实验结果(MAP@200)
Table 1 MAP@200 results on Wiki dataset for the tasks of using the image to query texts and vice versa
算法 任务 8 16 24 32 任务 8 16 24 32 CCA 0.2047 0.1815 0.1634 0.1694 0.2036 0.1663 0.1527 0.1595 CVH 图 0.2038 0.1951 0.1682 0.1674 文 0.1997 0.1833 0.1703 0.1613 SCM-O 像 0.1907 0.1718 0.1673 0.1704 本 0.1889 0.1669 0.1610 0.1661 SCM-S 检 0.2129 0.2353 0.2337 0.2377 检 0.2037 0.2411 0.2419 0.2507 CMFH 索 0.2185 0.2300 0.2377 0.2420 索 0.2216 0.2333 0.2352 0.2390 LSSH 文 0.1895 0.2084 0.2232 0.2094 图 0.1841 0.2127 0.2308 0.2157 STMH 本 0.1907 0.1926 0.2201 0.2321 像 0.1896 0.2130 0.2260 0.2240 PDLH- 0.2188 0.2175 0.2385 0.2316 0.2217 0.2162 0.2364 0.2325 PDLH 0.2196 0.2301 0.2499 0.2384 0.2225 0.2276 0.2423 0.2430  下载: 导出CSV
下载: 导出CSV
表 2 图像检索文本和文本检索图像任务在NUS-WIDE数据集上的实验结果(MAP@200)
Table 2 MAP results on NUS-WIDE dataset for the tasks of using the image to query texts and vice versa (MAP@200)
算法 任务 8 16 24 32 任务 8 16 24 32 CCA 0.3445 0.3413 0.3465 0.3424 0.3722 0.3620 0.3731 0.3562 CVH 图 0.3395 0.3435 0.3440 0.3357 文 0.3676 0.3706 0.3620 0.3481 SCM-O 像 0.3687 0.3580 0.3567 0.3501 本 0.4205 0.4023 0.3866 0.3977 SCM-S 检 0.4098 0.4443 0.4413 0.4482 检 0.4828 0.5012 0.5067 0.5222 CMFH 索 0.3374 0.3586 0.3778 0.3803 索 0.3843 0.3984 0.4093 0.4120 LSSH 文 0.3465 0.3716 0.3770 0.4073 图 0.3686 0.3736 0.3841 0.4184 STMH 本 0.3723 0.3922 0.4067 0.4156 像 0.3979 0.4114 0.4235 0.4322 PDLH-- 0.4010 0.4423 0.4478 0.4505 0.4362 0.5003 0.5078 0.5128 PDLH 0.4137 0.4456 0.4530 0.4714 0.4530 0.5034 0.5135 0.5172
下载: 导出CSV
表 3 同数量训练样本的训练时间(s)和MAP结果
Table 3 The time costs (s) and MAP results with different sizes of training dataset
训练集 训练时间 文本检索图像 图像检索文本 大小 (s) MAP MAP 10 000 30.25 0.4839 0.4603 20 000 58.75 0.5466 0.4973 50 000 750.77 0.5643 0.5520 10 0000 325.90 0.5719 0.5584 150 000 504.59 0.6028 0.5603
下载: 导出CSV
-
[1] Andoni A, Indyk P. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. In: Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science. Berkeley, USA: IEEE, 2006. 459-468 http://cn.bing.com/academic/profile?id=d697ff3b4000193b22b8e0e0e7ec6c83&encoded=0&v=paper_preview&mkt=zh-cn [2] Kulis B, Kristen G. Kernelized locality-sensitive hashing. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(6):1092-1104 doi: 10.1109/TPAMI.2011.219 [3] 李武军, 周志华.大数据哈希学习:现状与趋势.科学通报, 2015, 60(5-6):485-490 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201612015Li Wu-Jun, Zhou Zhi-Hua. Learning to hash for big data:current status and future trends. Chinese Science Bulletin, 2015, 60(5-6):485-490 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201612015 [4] Weiss Y, Torralba A, Fergus R. Spectral hashing. In: Proceedings of the 22nd Annual Conference on Neural Information Processing Systems. British Columbia, Canada: MIT, 2008. 1753-1760 [5] Liu W, Wang J, Ji R R, Jiang Y G, Chang S F. Supervised hashing with kernels. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, Rhode Island, USA: IEEE, 2012. 2074-2081 doi: 10.1109/CVPR.2012.6247912 [6] Gong Y C, Lazebnik S. Iterative quantization: a procrustean approach to learning binary codes. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado, USA: IEEE, 2011. 817-824 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5995432 [7] Shen F M, Shen C H, Liu W, Shen H T. Supervised discrete hashing. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 37-45 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=7298598 [8] Song J K, Yang Y, Huang Z, Shen H T, Hong R C. Multiple feature hashing for real-time large scale near-duplicate video retrieval. In: Proceedings of the 19th ACM International Conference on Multimedia. New York, USA: ACM, 2011. 423-432 http://dl.acm.org/citation.cfm?id=2072354 [9] Zhang D, Wang F, Si L. Composite hashing with multiple information sources. In: Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. Beijing, China: ACM, 2011. 225-234 http://dl.acm.org/citation.cfm?id=2009950 [10] Xu H, Wang J D, Li Z, Zeng G, Li S P, Yu N H. Complementary hashing for approximate nearest neighbor search. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 1631-1638 http://dl.acm.org/citation.cfm?id=2356416 [11] Bronstein M M, Bronstein A M, Michel F, Paragios N. Data fusion through cross-modality metric learning using similarity-sensitive hashing. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 3594-3601 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5539928 [12] Kumar S, Udupa R. Learning hash functions for cross-view similarity search. In: Proceedings of the 22nd International Joint Conference on Artificial Intelligence. Barcelona, Spain: AAAI, 2011. 1360-1366 http://dl.acm.org/citation.cfm?id=2283623 [13] Ding G G, Guo Y C, Zhou J L. Collective matrix factorization hashing for multimodal data. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 2083-2080 doi: 10.1109/CVPR.2014.267 [14] Zhou J L, Ding G G, Guo Y C. Latent semantic sparse hashing for cross-modal similarity search. In: Proceedings of the 37th ACM SIGIR Conference on Research and Development in Information Retrieval. Gold Coast, Australia: ACM, 2014. 415-424 http://dl.acm.org/citation.cfm?id=2609610 [15] Zhuang Y T, Wang Y F, Wu F, Zhang Y, Lu W M. Supervised coupled dictionary learning with group structures for multi-modal retrieval. In: Proceedings of the 27th AAAI Conference on Artificial Intelligence. Washington, USA: AAAI, 2013. 1070-1076 https://www.researchgate.net/publication/285957475_Supervised_coupled_dictionary_learning_with_group_structures_for_multi-modal_retrieval [16] Zhen Y, Yeung D Y. A probabilistic model for multimodal hash function learning. In: Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Beijing, China: ACM, 2012. 940-948 http://dl.acm.org/citation.cfm?id=2339678 [17] Rafailidis D, Crestani F. Cluster-based joint matrix factorization hashing for cross-modal retrieval. In: Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval. Pisa, Italy: ACM, 2016. 781-784 http://dl.acm.org/citation.cfm?id=2914710 [18] Hotelling H. Relations between two sets of variates. Biometrika, 1936, 28(3-4):321-377 doi: 10.1093/biomet/28.3-4.321 [19] Zhang D Q, Li W J. Large-scale supervised multimodal hashing with semantic correlation maximization. In: Proceedings of the 28th AAAI Conference on Artificial Intelligence. Québec, Canada: AAAI, 2014. 2177-2183 http://dl.acm.org/citation.cfm?id=2892854 [20] 练秋生, 石保顺, 陈书贞.字典学习模型、算法及其应用研究进展.自动化学报, 2015, 41(2):240-260 http://www.aas.net.cn/CN/abstract/abstract18604.shtmlLian Qiu-Sheng, Shi Bao-Shun, Chen Shu-Zhen. Research advances on dictionary learning models, algorithms and applications. Acta Automatica Sinica, 2015, 41(2):240-260 http://www.aas.net.cn/CN/abstract/abstract18604.shtml [21] 陈思宝, 赵令, 罗斌.基于局部保持的核稀疏表示字典学习.自动化学报, 2014, 40(10):2295-2305 http://www.aas.net.cn/CN/abstract/abstract18504.shtmlChen Si-Bao, Zhao Ling, Luo Bin. Locality preserving based kernel dictionary learning for sparse representation. Acta Automatica Sinica, 2014, 40(10):2295-2305 http://www.aas.net.cn/CN/abstract/abstract18504.shtml [22] Yan Y, Yang Y, Shen H Q, Meng D Y, Liu G W, Hauptmann A, Sebe N. Complex event detection via event oriented dictionary learning. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, USA: AAAI, 2015. 3841-3847 http://dl.acm.org/citation.cfm?id=2888249 [23] 黄丹丹, 孙怡.基于判别性局部联合稀疏模型的多任务跟踪.自动化学报, 2016, 42(3):402-415 http://www.aas.net.cn/CN/abstract/abstract18829.shtmlHuang Dan-Dan, Sun Yi. Tracking via multitask discriminative local joint sparse appearance model. Acta Automatica Sinica, 2016, 42(3):402-415 http://www.aas.net.cn/CN/abstract/abstract18829.shtml [24] Sun X X, Nasrabadi N M, Tran T D. Task-driven dictionary learning for hyperspectral image classification with structured sparsity constraints. IEEE Transactions on Geoscience and Remote Sensing, 2015, 53(8):4457-4471 doi: 10.1109/TGRS.2015.2399978 [25] 马名浪, 何小海, 滕奇志, 陈洪刚, 卿粼波.基于自适应稀疏变换的指纹图像压缩.自动化学报, 2016, 42(8):1274-1284 http://www.aas.net.cn/CN/abstract/abstract18916.shtmlMa Ming-Lang, He Xiao-Hai, Teng Qi-Zhi, Chen Hong-Gang, Qing Lin-Bo. Fingerprint image compression algorithm via adaptive sparse transformation. Acta Automatica Sinica, 2016, 42(8):1274-1284 http://www.aas.net.cn/CN/abstract/abstract18916.shtml [26] 郑思龙, 李元祥, 魏宪, 彭希帅.基于字典学习的非线性降维方法.自动化学报, 2016, 42(7):1065-1076 http://www.aas.net.cn/CN/abstract/abstract18897.shtmlZheng Si-Long, Li Yuan-Xiang, Wei Xian, Peng Xi-Shuai. Nonlinear dimensionality reduction based on dictionary learning. Acta Automatica Sinica, 2016, 42(7):1065-1076 http://www.aas.net.cn/CN/abstract/abstract18897.shtml [27] Gu S H, Zhang L, Zuo W M, Feng X C. Projective dictionary pair learning for pattern classification. In: Proceedings of the 2014 Advances in Neural Information Processing Systems. Montréal, Canada: MIT, 2014. 793-801 http://hdl.handle.net/10397/16587 [28] Guo J, Guo Y Q, Kong X W, He R. Discriminative analysis dictionary learning. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI, 2016. 1617-1623 http://aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/11918 [29] Rasiwasia N, Pereira J C, Coviello E, Doyle G, Lanckriet G R G, Levy R, Vasconcelos N. A new approach to cross-modal multimedia retrieval. In: Proceedings of the 18th ACM International Conference on Multimedia. New York, USA: ACM, 2010. 251-260 http://dl.acm.org/citation.cfm?id=1873987 [30] Chua T S, Tang J H, Hong R C, Li H J, Luo Z P, Zheng Y T. NUS-WIDE: a real-world web image database from national university of Singapore. In: Proceedings of the 2009 ACM International Conference on Image and Video Retrieval. Santorini Island, Greece: ACM, 2009. Article No. 48 http://dl.acm.org/citation.cfm?id=1646452 [31] Wang D, Gao X B, Wang X M, He L H. Semantic topic multimodal hashing for cross-media retrieval. In: Proceedings of the 24th International Conference on Artificial Intelligence. Buenos Aires, Argentina: AAAI, 2015. 3890-3896 -

 下载:
下载:

计量
- 文章访问数: 2385
- HTML全文浏览量: 522
- PDF下载量: 748
- 被引次数: 0
