

-
摘要: 目前,显著性检测已成为国内外计算机视觉领域研究的一个热点,但现有的显著性检测算法大多无法有效检测出位于图像边缘的显著性物体.针对这一问题,本文提出了基于自适应背景模板与空间先验的显著性物体检测方法,共包含三个步骤:第一,根据显著性物体在颜色空间上具有稀有性,获取基于自适应背景模板的显著图.将图像分割为超像素块,提取原图的四周边界作为原始背景区域.利用设计的自适应背景选择策略移除原始背景区域中显著的超像素块,获取自适应背景模板.通过计算每个超像素块与自适应背景模板的相异度获取基于自适应背景模板的显著图.并采用基于K-means的传播机制对获取的显著图进行一致性优化;第二,根据显著性物体在空间分布上具有聚集性,利用基于目标中心优先与背景模板抑制的空间先验方法获得空间先验显著图.第三,将获得的两种显著图进行融合得到最终的显著图.在公开数据集MSRA-1000、SOD、ECSSD和新建复杂数据集CBD上进行实验验证,结果证明本文方法能够准确有效地检测出图像中的显著性物体.Abstract: Due to its effectiveness of identifying salient object while suppressing the background, boundary prior has been widely used in saliency detection recently. However, if the locations of salient regions are near the image border, the existing methods would not be suitable. In order to improve the robustness of saliency detection, we propose an improved saliency detection method using adaptive background template and spatial prior. Firstly, according to the rarity of salient object in the color space, a selection strategy is presented to establish the adaptive background template by removing the potential saliency superpixels from the image border regions, and a saliency map is obtained. A propagation mechanism based on K-means algorithm is designed for maintaining the neighborhood coherence of the above saliency map. Secondly, according to the aggregation of salient object, a new spatial prior is presented to integrate the saliency detection results by aggregating two complementary measures such as image center preference and the background template exclusion. Finally, the final salient map is obtained by fusing the above two salient maps. Quantitative experiments on four available datasets MSRA-1000, SOD, ECSSD and new constructed CBD demonstrate that our method outperforms other state-of-the-art saliency detection approaches.
-
Key words:
- Saliency detection /
- background template /
- propagation mechanism /
- spatial prior
-
-

图 5 针对显著性物体位于图像边缘的图像, 显著图的视觉比较结果
Fig. 5 Visual comparison of previous methods, our method and ground truth for the image whose salient object locates at the border

图 6 显著图的视觉比较结果
Fig. 6 Visual comparison of previous methods, our method and ground truth
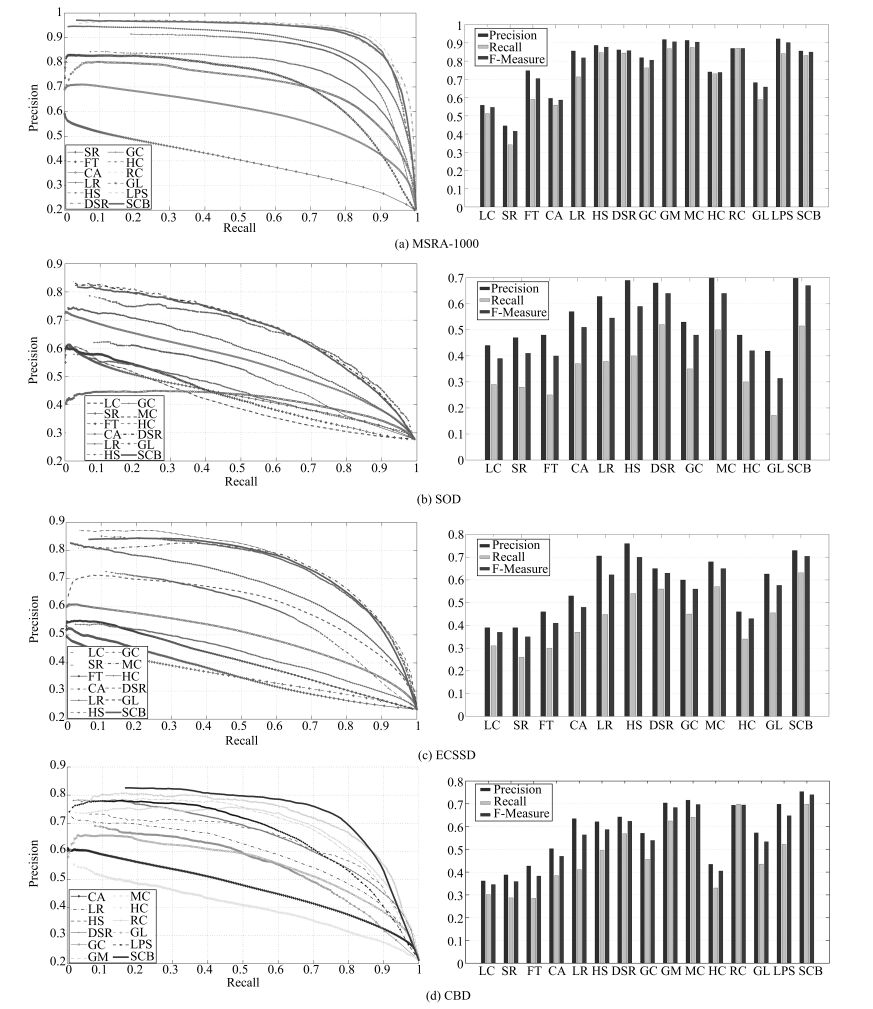
图 7 不同算法的准确率-召回率曲线与F-measure值柱状图
Fig. 7 Quantitative results of the precision/recall curves and F-measure metrics
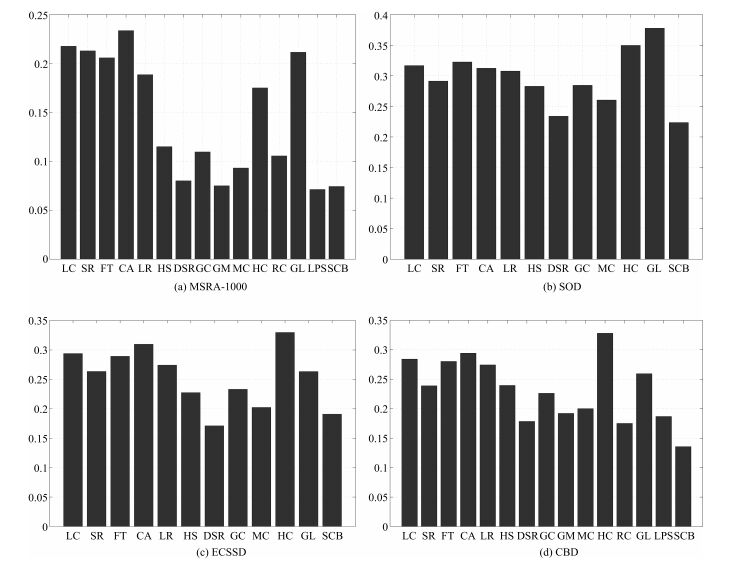
图 8 针对MSRA-1000、SOD、ECSSD与CBD数据集, 不同显著性检测方法的MAE柱状图
Fig. 8 Quantitative results of the MAE value of MSRA-1000, SOD, ECSSD and CBD
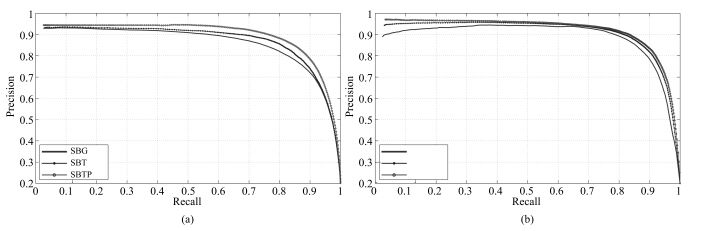
图 9 针对MSRA-1000数据集, 提出的SCB方法各个组成部分的准确率-召回率曲线
Fig. 9 Quantitative results of each component of SCB method in MSRA-1000 dataset

图 10 针对Co-saliency pairs数据集, 基于Web的协同显著图
Fig. 10 The co-saliency map based on web in co-saliency pairs dataset
表 1 平均检测时间对比表
Table 1 The table of contrast result in running times
方法 FT CA LR GC GL HS 编程工具 C++ MATLAB MATLAB C++ MATLAB C++ 时间 0.02 52.58 14.5 0.09 9.42 0.49 方法 GM MC DSR LPS SCB 编程工具 MATLAB MATLAB MATLAB MATLAB MATLAB 时间 0.25 0.14 3.53 2.40 1.12  下载: 导出CSV
下载: 导出CSV
-
[1] 钱生, 陈宗海, 林名强, 张陈斌.基于条件随机场和图像分割的显著性检测.自动化学报, 2015, 41(4):711-724 http://www.aas.net.cn/CN/abstract/abstract18647.shtmlQian Sheng, Chen Zong-Hai, Lin Ming-Qiang, Zhang ChenBin. Saliency detection based on conditional random field and image segmentation. Acta Automatica Sinica, 2015, 41(4):711-724 http://www.aas.net.cn/CN/abstract/abstract18647.shtml [2] Wei Y C, Wen F, Zhu W, Sun J. Geodesic saliency using background priors. In:Proceedings of the 12th European Conference on Computer Vision. Berlin, Germany:Springer, 2012. 29-42 [3] Li X H, Lu H C, Zhang L H. Saliency detection via dense and sparse reconstruction. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 2976-2983 [4] Wang K Z, Lin L, Lu J B, Li C L, Shi K Y. PISA:pixelwise image saliency by aggregating complementary appearance contrast measures with edge-preserving coherence. IEEE Transactions on Image Processing, 2015, 24(10):3019-3033 doi: 10.1109/TIP.2015.2432712 [5] Wang L J, Lu H C, Ruan X, Yang M H. Deep networks for saliency detection via local estimation and global search. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015. 3183-3192 [6] Mauthner T, Possegger H, Waltner G, Bischof H. Encoding based saliency detection for videos and images. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015. 2494-2502 [7] Jain S D, Grauman K. Active image segmentation propagation. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, Nevada, USA:IEEE, 2016. 2864-2873 [8] Yu G, Yuan J S, Liu Z C. Propagative Hough voting for human activity detection and recognition. IEEE Transactions on Circuits and Systems for Video Technology, 2015, 25(1):87-98 doi: 10.1109/TCSVT.2014.2319594 [9] Horbert E, García G M, Frintrop S, Leibe B. Sequencelevel object candidates based on saliency for generic object recognition on mobile systems. In:Proceedings of the 2015 IEEE International Conference on Robotics and Automation. Seattle, Washington, USA:IEEE, 2015. 127-134 [10] Yang X Y, Qian X M, Xue Y. Scalable mobile image retrieval by exploring contextual saliency. IEEE Transactions on Image Processing, 2015, 24(6):1709-1721 doi: 10.1109/TIP.2015.2411433 [11] Lei B Y, Tan E L, Chen S P, Ni D, Wang T F. Saliencydriven image classification method based on histogram mining and image score. Pattern Recognition, 2015, 48(8):2567 -2580 doi: 10.1016/j.patcog.2015.02.004 [12] Cheng M M, Mitra N J, Huang X L, Torr P H S, Hu S M. Global contrast based salient region detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3):569-582 doi: 10.1109/TPAMI.2014.2345401 [13] Yang C, Zhang L H, Lu H C, Ruan X, Yang M H. Saliency detection via graph-based manifold ranking. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 3166-3173 [14] Jiang B W, Zhang L H, Lu H C, Yang C, Yang M H. Saliency detection via absorbing Markov chain. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 1665-1672 [15] Jiang H Z, Wang J D, Yuan Z J, Wu Y, Zheng N N, Li S P. Salient object detection:a discriminative regional feature integration approach. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 2083-2090 [16] Lu H C, Li X H, Zhang L H, Ruan X, Yang M H. Dense and sparse reconstruction error based saliency descriptor. IEEE Transactions on Image Processing, 2016, 25(4):1592-1603 doi: 10.1109/TIP.2016.2524198 [17] Borji A, Sihite D N, Itti L. Salient object detection:a benchmark. In:Proceedings of the 12th European Conference on Computer Vision. Berlin, Germany:Springer, 2012. 414-429 [18] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11):1254-1259 doi: 10.1109/34.730558 [19] Ma Y F, Zhang H J. Contrast-based image attention analysis by using fuzzy growing. In:Proceedings of the 11th ACM International Conference on Multimedia. Berkeley, USA:ACM, 2003. 374-381 [20] Achanta R, Hemami S, Estrada F, Susstrunk S. Frequencytuned salient region detection. In:Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami Beach, USA:IEEE, 2009. 1597-1604 [21] Rahtu E, Kannala J, Salo M, Heikkilä J. Segmenting salient objects from images and videos. In:Proceedings of the 11th European Conference on Computer Vision. Crete, Greece:Springer, 2010. 366-379 [22] Cheng M M, Warrell J, Lin W Y, Zheng S, Vineet V, Crook N. Efficient salient region detection with soft image abstraction. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 1529-1536 [23] Perazzi F, Krähenbühl P, Pritch Y, Hornung A. Saliency filters:contrast based filtering for salient region detection. In:Proceedings of the 2012 IEEE International Conference on Computer Vision and Pattern Recognition. Providence, USA:IEEE, 2012. 733-740 [24] Margolin R, Tal A, Zelnik-Manor L. What makes a patch distinct? In:Proceedings of the 2013 IEEE International Conference on Computer Vision and Pattern Recognition. Sydney, Australia:IEEE, 2013. 1139-1146 [25] Yan Q, Xu L, Shi J P, Jia J Y. Hierarchical saliency detection. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 1155-1162 [26] Shen X H, Wu Y. A unified approach to salient object detection via low rank matrix recovery. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA:IEEE, 2012. 853-860 [27] Zhu W J, Liang S, Wei Y C, Sun J. Saliency optimization from robust background detection. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE, 2014. 2814-2821 [28] Xi T, Fang Y, Lin W, Zhang Y. Improved salient object detection based on background priors. In:Proceedings of the 2015 Pacific Rim Conference on Multimedia. Gwangju, Korea:Springer, 2015. 411-420 [29] Qin Y, Lu H C, Xu Y Q, Wang H. Saliency detection via cellular automata. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015. 110-119 [30] Achanta R, Shaji A, Smith K, Lucchi A, Fua P, Süsstrunk S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11):2274-2282 doi: 10.1109/TPAMI.2012.120 [31] Zhang L, Yang C, Lu H, Xiang R, Yang M H. Ranking saliency. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(9):1892-1904 doi: 10.1109/TPAMI.2016.2609426 [32] Judd T, Ehinger K, Durand F, Torralba A. Learning to predict where humans look. In:Proceedings of the 12th International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 2106-2113 [33] Movahedi V, Elder J H. Design and perceptual validation of performance measures for salient object segmentation. In:Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. San Francisco, CA, USA:IEEE, 2010. 49-56 [34] Alpert S, Galun M, Brandt A, Basri R. Image segmentation by probabilistic bottom-up aggregation and cue integration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(2):315-327 doi: 10.1109/TPAMI.2011.130 [35] Zou W B, Kpalma K, Liu Z, Ronsin J. Segmentation driven low-rank matrix recovery for saliency detection. In:Proceedings of the 24th British Machine Vision Conference. Bristol, UK:IEEE, 2013. 1-13 [36] Li G B, Yu Y Z. Visual saliency based on multiscale deep features. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015. 5455-5463 [37] Zhai Y, Shah M. Visual attention detection in video sequences using spatiotemporal cues. In:Proceedings of the 14th ACM International Conference on Multimedia. New York, USA:ACM, 2006. 815-824 [38] Hou X, Zhang L. Saliency detection:a spectral residual approach. In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, Minnesota, USA:IEEE, 2007. 1-8 [39] Goferman S, Zelnik-Manor L, Tal A. Context-aware saliency detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(10):1915-1926 doi: 10.1109/TPAMI.2011.272 [40] Tong N, Lu H C, Zhang Y, Ruan X. Salient object detection via global and local cues. Pattern Recognition, 2015, 48(10):3258-3267 doi: 10.1016/j.patcog.2014.12.005 [41] Li H Y, Lu H C, Lin Z, Shen X H, Price B. Inner and inter label propagation:salient object detection in the wild. IEEE Transactions on Image Processing, 2015, 24(10):3176-3186 doi: 10.1109/TIP.2015.2440174 [42] 徐威, 唐振民.利用层次先验估计的显著性目标检测.自动化学报, 2015, 41(4):799-812 http://www.aas.net.cn/CN/abstract/abstract18654.shtmlXu Wei, Tang Zhen-Min. Exploiting hierarchical prior estimation for salient object detection. Acta Automatica Sinica, 2015, 41(4):799-812 http://www.aas.net.cn/CN/abstract/abstract18654.shtml [43] 杨赛, 赵春霞, 徐威.一种基于词袋模型的新的显著性目标检测方法.自动化学报, 2016, 42(8):1259-1273 http://www.aas.net.cn/CN/abstract/abstract18915.shtmlYang Sai, Zhao Chun-Xia, Xu Wei. A novel salient object detection method using bag-of-features. Acta Automatica Sinica, 2016, 42(8):1259-1273 http://www.aas.net.cn/CN/abstract/abstract18915.shtml [44] Li H L, Ngan K N. A co-saliency model of image pairs. IEEE Transactions on Image Processing, 2011, 20(12):3365-3375 doi: 10.1109/TIP.2011.2156803 -




计量
- 文章访问数: 2012
- HTML全文浏览量: 238
- PDF下载量: 678
- 被引次数: 0
