

-
摘要: 细粒度图像分类问题是计算机视觉领域一项极具挑战的研究课题,其目标是对子类进行识别,如区分不同种类的鸟.由于子类别间细微的类间差异和较大的类内差异,传统的分类算法不得不依赖于大量的人工标注信息.近年来,随着深度学习的发展,深度卷积神经网络为细粒度图像分类带来了新的机遇.大量基于深度卷积特征算法的提出,促进了该领域的快速发展.本文首先从该问题的定义以及研究意义出发,介绍了细粒度图像分类算法的发展现状.之后,从强监督与弱监督两个角度对比分析了不同算法之间的差异,并比较了这些算法在常用数据集上的性能表现.最后,我们对这些算法进行了总结,并讨论了该领域未来可能的研究方向及其面临的挑战.Abstract: Fine-grained image categorization is a challenging task in the field of computer vision, which aims to classify sub-categories, such as different species of birds. Due to the low inter-class but high intra-class variations, traditional categorization algorithms have to depend on a large amount of annotation information. Recently, with the advances of deep learning, deep convolutional neural networks have provided a new opportunity for fine-grained image recognition. Numerous deep convolutional feature-based algorithms have been proposed, which have advanced the development of fine-grained image research. In this paper, starting from its definition, we give a brief introduction to some recent developments in fine-grained image categorization. After that, we analyze different algorithms from the strongly supervised to and weakly supervised ones, and compare their performances on some popular datasets. Finally, we provide a brief summary of these methods as well as the potential future research direction and major challenges.
-
传统辨识方法可以分为时域法[1]和频域法[2]两大类,系统的数学模型可分为连续时间模型和离散时间模型两大类.从频域方法辨识研究文献来看,主要集中在离散形式的状态空间方程[3],而连续时间模型的研究大多采用传递函数辨识法[2],状态空间模型的辨识研究得相对较少. 对离散时间状态空间模型,常采用子空间模型辨识方法(Subspace model identification,SMI)[4],该方法属于一种非参数方法,多用于过程系统建模[5]、 系统模态分析[6]、机翼颤振检测[7]等. SMI 的典型算法有3种: Verhaegen等提出的MOESP (Multivariable output error state space)[8-10],Van Overschee等提出的N4SID (Numerical algorithm for subspace state space system identification)[11] 以及Larimore提出的CVA (Canonical variate analysis)[12].
描述多输入多输出(Multiple-input multiple-output,MIMO)线性系统的模型有多种,相比其他模型,状态空间模型是对系统动态的物理模型描述,其参数具有实际的物理意义,便于工程人员理解与分析. 对控制系统设计人员而言,辨识的参数通常为系统稳定性导数和控制偏导数,正好对应着状态方程中的状态转移阵和输入控制阵. 以飞行器为例,其稳定和控制导数实际上是飞机几何参数(如翼展、弦长等)、气动参数(如升力线斜率和控制面效率)、惯量参数(如质量、惯性矩等)的函数[13].因此,状态空间模型对飞行器建模而言更具实用性.
由机理法建模得到的系统模型通常为连续时间模型,如微分方程、状态空间方程或传递函数. 在实践中,利用输入输出数据辨识系统的连续时间模型是建模的重要需求之一,包括控制设计及故障诊断等. 并且,这些模型可以方便地转换成离散模型.在频率变换域中辨识连续时间状态空间模型,是近年来发展的一种重要的系统辨识方法.Klein[14]提出了频域极大似然方法用于飞行器参数辨识.Morelli[15]对频域方法进一步发展,通过递推方式进行频域变换,使得频域方法可以用于在线辨识.Tischler[16]采用线性调频Z变换获取系统的频域响应,并推出了CIFER频域辨识软件.
本文以飞行器为例,研究一类MIMO系统的连续时间状态空间模型参数辨识问题. 首先,建立飞行器的状态空间结构模型;针对系统状态可观测、状态微分项无法直接获取的问题,基于离散傅里叶变换,在频率变换域中研究了估计模型参数的最小二乘算法;针对多变量系统,推导出矩阵参数形式的频域多元线性回归模型,实现了子系统分解和整体最小二乘估计算法,设计了正交多正弦(Orthogonal multi-sine)激励信号,并进行了仿真实验与分析.
1. 多变量系统的连续状态空间模型
线性状态空间模型的连续形式可表示为
\begin{align}\left\{ \begin{gathered} {\dot{\pmb x}}(t) = A{\pmb{x}}(t) + B{\pmb{u}}(t) + {\pmb{w}}(t) \\ {\pmb{y}}(t) = C{\pmb{x}}(t) + D{\pmb{u}}(t) + {\pmb{v}}(t) \\\end{gathered} \right.\end{align}
(1) 其中, ${\pmb{x}}(t)\in{{\bf {R}}^n}$ 为状态向量, ${\pmb{u}}(t)\in{{\bf {R}}^r}$ 为输入向量, ${\pmb{y}}(t)\in{{\bf{R}}^m}$ 为输出向量,过程噪声 ${\pmb{w}}(t)\in{{\bf{R}}^n}$ 和观测噪声 ${\pmb{v}}(t)\in{{\bf{R}}^m}$ 均为平稳的零均值白噪声, $\mathit{A}$ , $\mathit{B}$ , $\mathit{C}$ , $\mathit{D}$ 为相应维数的未知参数矩阵.下面分两种情形讨论.
1.1 系统状态不可观测
在很多实际系统中,其状态量无法直接观测. 对式(1) 应用拉普拉斯变换,可得系统的输出与系统参数阵的关系为
\begin{align}\begin{gathered} Y(s) = [C{(sI - A)^{ - 1}}B + D]U(s) +\hfill \\ \quad \quad \quad C{(sI - A)^{ - 1}}W(s) + V(s) \\\end{gathered}\end{align}
(2) 可见,输出与系统参数矩阵是非线性关系,对状态空间模型的辨识是非常困难的. 这属于已知输入、输出,估计系统阶次及参数矩阵的辨识问题. 近年来,将子空间方法用于连续系统状态空间模型的辨识问题得到研究人员的持续关注[17-20],其主要困难在于输入和输出量的高阶微分计算方法.
1.2 系统状态可观测
当系统状态可观测时,对状态空间模型参数的辨识就是线性回归问题,只要获得统计意义上足够多的输入及状态数据,就可以用最小二乘(Least-squares,LS)、极大似然(Maximum likelihood,ML)等传统辨识算法获得系统的模型及参数. 但是,对于连续状态空间方程的左端项而言,即状态量的微分通常无法直接观测,若采用数值微分等方法会引入额外的噪声及延迟,导致辨识精度显著降低.
对飞行器等一类运动体,可以采用机理方法推导出满足控制系统设计的数学模型结构,且由于位置/速度、角度/角速度等传感器技术较为成熟,再加上卡尔曼滤波器等信号处理技术,获得较为准确的状态数据并不困难,甚至某些模型参数也可精确地获取,此时的系统辨识就成为已知模型结构以及部分参数情况下的参数估计问题,这是典型的灰箱(Grey-box)建模方法.
2. 基于离散傅里叶变换的频域最小二乘方法
采用傅里叶变换回归(Fourier transform regression)辨识方法可以很好地解决状态空间方程左端项无法获取的难题,且对信号噪声有很强的处理能力. 下面对其原理进行简要介绍.
2.1 离散傅里叶变换
设采样时间为 $T$ ,信号的离散采样序列为 ${\pmb{x}}~(kT)$ $(k=0,1,2,cdots,N-1) $ ,离散傅里叶变换(Discrete Fourier transform,DFT)定义[2]为
\begin{align}X(i) = \sum\limits_{k = 0}^{N - 1} {{\pmb{x}}(kT){{\rm e}^{ - {\rm j}2\pi \frac {ik}{N}}}} ,~~~i=0,1,cdots,N-1\end{align}
(3) 实际中,进行DFT分析的有效频率带宽受到Nyquist频率限制,即不能超过 $1/(2T)$ Hz. 记DFT计算的频谱点数为 $M \leq N/2$ ,各点的频率为
\begin{align}\pmb{\omega}(i) = 2\pi\frac{i}{NT},\quad i=0,1,cdots,M-1\end{align}
(4) 需要注意的是,不同于信号处理领域中的频谱分析,在控制系统的频域分析中,可以人为选定一段感兴趣的频带. 换言之,式(4) 中的 ${\pmb{\omega}}$ 不一定从零频率开始(用以去除直流分量),同样也不一定高至Nyquist频率(用以去除高频噪声).取DFT计算的频点数为 $M$ ,式(3) 改写为
\begin{align}X({\rm j}{\pmb{\omega }}) = \sum\limits_{k = 0}^{N - 1}{{\pmb{x}}(kT){{\rm e}^{ -{\rm j}{\pmb{\omega }}kT}}}\end{align}
(5) 对应地,信号的微分状态量 $\dot{\pmb x}(kT)$ 的频域变换为
\begin{align}\dot X({\rm j}{\pmb{\omega }}) = \sum\limits_{k = 0}^{N - 1}\dot{\pmb x}(kT){\rm e}^{ - {\rm j}{\pmb\omega }kT}\end{align}
(6) 不难得出,在频域中信号的微分与原信号存在关系
\begin{align}\dot X({\rm j}{\pmb{\omega }}) = {\rm j}{\pmb{\omega }}X({\rm j}{\pmb{\omega }})\end{align}
(7) 对式(1) 所示的时域状态空间方程进行DFT得:
\begin{align}\left\{ \begin{gathered} {\rm j}{\pmb{\omega }}X({\rm j}{\pmb{\omega }}) = AX({\rm j}{\pmb{\omega }}) + BU({\rm j}{\pmb{\omega }}) + W({\rm j}{\pmb{\omega }}) \\ Y({\rm j}{\pmb{\omega }}) = CX({\rm j}{\pmb{\omega }}) + DU({\rm j}{\pmb{\omega }}) + V({\rm j}{\pmb{\omega }}) \\\end{gathered} \right.\end{align}
(8) 式中, $X({\rm j}{\pmb{\omega }})\in{{\bf {C}}^{n × M}}$ , $Y({\rm j}{\pmb{\omega }})\in{{\bf {C}}^{m × M}}$ , $U({\rm j}{\pmb{\omega }})\in{{\bf {C}}^{r × M}}$ , $W({\rm j}{\pmb{\omega }})\in{{\bf {C}}^{n × M}}$ , $V({\rm j}{\pmb{\omega }})\in{{\bf {C}}^{m × M}}$ 分别为时域序列 ${\pmb{x}}(kT)$ , ${\pmb{y}}~(kT)$ , ${\pmb{u}}(kT)$ , ${\pmb{w}}(kT)$ , ${\pmb{v}}(kT)~(k=0,1,\cdots,N-1) $ 应用如式(5) 的DFT计算得到的复矩阵.
2.2 单变量系统频域最小二乘参数估计
首先考虑单变量系统的最小二乘辨识模型 $z(t)={{\pmb{\varphi}}^{\text{T}}}(t){\pmb{\theta}}+v(t)$ . 其中, $z(t)\in\bf{R}$ 为系统输出, ${\pmb{\varphi}}(t)={[{\varphi _1}(t),{\varphi _2}(t),\cdots,{\varphi_K}(t)]^{\text{T}}}\in{{\bf{R}}^K}$ 是由系统输入输出数据构成的信息向量, $v(t)\in\bf{R}$ 为随机干扰噪声, ${\pmb{\theta }}={[{\theta_1},\;{\theta _2},\;\cdots,\;{\theta _K}]^{\text{T}}}\in{{\bf{R}}^K}$ 是待辨识参数向量[21].将式(1) 中的每一行方程视为一个单变量子系统,经DFT得到的频域最小二乘模型为
\begin{align}{\tilde{\pmb z}} = {\tilde {\pmb \Phi}}{\pmb{\theta }} +{\tilde{\pmb \nu }}\end{align}
(9) 其中, ${\tilde{\pmb \Phi}}\in{{\bf {C}}^{M×(n+r)}}$ 是由状态 $\pmb{x}$ 和输入 $\pmb{u}$ 组成的扩张状态经DFT计算得到的复变量矩阵; ${\pmb{\theta }}\in{{\bf {R}}^{(n+r)}}$ 为待辨识参数向量; ${\tilde{\pmb z}}\in{{\bf {C}}^{M × 1}}$ 为时域观测变量的傅里叶变换,当观测量为状态的微分时, ${\tilde{\pmb z}}$ 可以采用式(7) 间接求取; ${\tilde{\pmb \nu }}\in{{\bf {C}}^{M× 1}}$ 为频域噪声残差序列. 值得注意的是,为与时域向量区分开来,频域向量符号顶部均加上了波浪线标志.
关于DFT计算的频点数 $M$ 的选取,当 $M <(n+r)$ 时,由式(9) 无法求得待辨识参数; $M=(n+r)$ 时,式(9) 可以直接解析求解,但由于 ${\tilde{\pmb\nu}}$ 的存在,这样求得的参数精度很差; 当 $M\gg(n+r)$ 时,就能应用回归分析方法求得统计意义上的最优参数估计结果,典型的有最大似然方法、最小二乘方法等[22].
下面介绍频域最小二乘估计算法.
与时域对应,在不考虑频率变换中的频谱泄露情况下,频域最小二乘代价函数定义为
\begin{align}J({\pmb{\theta }}) = \frac{1}{2}{({ \tilde {\pmb z}} - \tilde{\pmb\Phi }{\pmb{\theta }})^{\rm H}}({\tilde{\pmb z}} - \tilde{\pmb \Phi}{\pmb{\theta }})\end{align}
(10) 式中, ${(\cdot)^{\rm H}}$ 表示复共轭转置(Hermitian transpose)运算.
考察式(9) 不难发现,除未知参数 ${\pmb{\theta }}$ 为实数外,其余均为复数向量或矩阵. 应用最小二乘估计理论,可以得到三种最小二乘估计算式.
1) LS-Re估计算式
将式(9) 写成等价形式如下:
\begin{align}\left[{\begin{array}{*{20}{c}} {\operatorname{Re} ({\tilde{\pmb z}})} \\ {\operatorname{Im} ({\tilde{\pmb z}})}\end{array}} \right] = \left[{\begin{array}{*{20}{c}} {\operatorname{Re} (\tilde { \pmb\Phi })} \\ {\operatorname{Im}(\tilde{\pmb \Phi })}\end{array}} \right]{\pmb{\theta }} + \left[{\begin{array}{*{20}{c}} {\operatorname{Re} ({\tilde{\pmb \nu }})} \\ {\operatorname{Im}({\tilde{\pmb \nu }})}\end{array}} \right]\end{align}
(11) 式中,Re ${(\cdot)}$ 、Im ${(\cdot)}$ 分别表示提取变量的实部、虚部.仅考虑复向量/矩阵的实部所形成的方程,根据最小二乘估计理论,参数估计为
\begin{align}{\hat{\pmb \theta }} = {\left[{\operatorname{Re} {{(\tilde{\pmb\Phi })}^{\text{T}}}\operatorname{Re} (\tilde{\pmb \Phi })}\right]^{ - 1}}\operatorname{Re} {(\tilde {\pmb\Phi})^{\text{T}}}\operatorname{Re} ({\tilde{\pmb z}})\end{align}
(12) 2) LS-Im估计算式
同理,若仅考虑复向量/矩阵的虚部,参数最小二乘估计为
\begin{align}{\hat{ \pmb\theta }} = {\left[{\operatorname{Im} {{(\tilde{\pmb\Phi })}^{\text{T}}}\operatorname{Im} (\tilde{\pmb \Phi })}\right]^{ - 1}}\operatorname{Im} {(\tilde{\pmb \Phi})^{\text{T}}}\operatorname{Im} ({\tilde{\pmb z}})\end{align}
(13) 3) LS-EAM估计算式
Morelli[15]给出的复数域最小二乘参数估计为
\begin{align}{\hat{\pmb \theta }} = {\left[{\operatorname{Re} ({\tilde{\pmb \Phi}^{\rm H}}\tilde {\pmb\Phi })} \right]^{ - 1}}\operatorname{Re}({\tilde{\pmb \Phi }^{\rm H}}{\tilde{\pmb z}})\end{align}
(14) 参数估计的协方差矩阵为
\begin{align}{\text{cov}}({\hat {\pmb\theta }}) := \rm E[({\hat {\pmb\theta }} -{\pmb{\theta }}){({\hat {\pmb\theta }} - {\pmb{\theta}})^{\text{T}}}] = {\sigma ^2}{\left[{\operatorname{Re} ({{\tilde{\pmb \Phi}}^{\rm H}}\tilde {\pmb \Phi })} \right]^{ - 1}}\end{align}
(15) 式中,误差协方差 ${\sigma ^2}$ 即噪声方差未知,但可以通过拟合残差 $s$ 进行估计:
\begin{align}{\sigma ^2} \doteq {s^2} = \frac{1}{{M -{n_\mathrm{p}}}}({\tilde{\pmb z}} - \tilde{\pmb \Phi} \hat{\pmb\theta })^{\rm H}(\tilde{\pmb z} -\tilde {\pmb\Phi} \hat{\pmb\theta })\end{align}
(16) 式中, $n_ \mathrm{p}=n+r$ 为 $\pmb{\theta}$ 向量的参数个数.
3. 连续状态空间模型的参数辨识频域方法
3.1 多元复数域线性回归模型
由式(8) 可看出,状态空间模型变换至频率域后,将得到一组复数域方程组,方程总数为 $M(n+m)$ .该方程组可视为对式(8) 中的状态、输入及输出进行了 $M$ 次观测得到的,且这 $M$ 次观测是在频域中进行的. 以其中的状态方程为例,将DFT计算的状态 $X$ 和输入 $U$ 、未知参数矩阵 $A$ 和 $B$ 分别进行组合,得到:
\begin{align}& {\tilde{\pmb \Phi}}_{\rm E} = [X^{\rm T}\quad U^{\rm T}] \notag\\& {{\pmb\theta}_{\rm E}}\;\; = \left[{\begin{array}{*{20}{lll}} A^{\rm T} \\ B^{\rm T} \end{array}} \right] \notag\\& {\tilde{\pmb z}}_{\rm E}\;\; = {\rm j}{\pmb\omega}X^{\rm T} \notag\\& {\tilde{\pmb v}}_{\rm E}\;\; = {W^{\rm T}}\end{align}
(17) 其中, $\tilde {\pmb\Phi} _{{\rm E}}\in{{\bf {C}}^{M ×(n + r)}}$ , ${{\pmb{\theta }}_{{\rm E}}}\in{{\bf {R}}^{(n + r)× n}}$ , ${{\tilde{\pmb z}}_{{\rm E}}}\in{{\bf {C}}^{M × n}}$ , ${{\tilde{\pmb v}}_{{\rm E}}}\in{{\bf {C}}^{M × n}}$ ,下标E代表扩展(Extended),于是,将式(8) 中的状态方程改写成式(9) 的形式可得:
\begin{align}{{\tilde {\pmb z}}_{{\rm E}}} = {\tilde {\pmb \Phi} _{{\rm E}}}{{{\pmb \theta}}_{{\rm E}}} + {{\tilde {\pmb\nu }}_{{\rm E}}}\end{align}
(18) 这是关于未知参数的矩阵参数形式的多元线性回归方程,待辨识参数个数为 ${n^2} + nr$ . 类似地,对式(8) 中输出方程的已知量和未知参数进行分别组合,也能得到形如式(18) 的回归方程,其待辨识参数个数为 $mn + mr$ . 式(18) 所示的多元线性回归模型可采用子系统分解的单变量最小二乘方法或整体最小二乘方法估计未知参数矩阵.
3.2 子系统分解最小二乘参数估计
面对称飞行器的状态空间模型通常分为纵向和横侧向两个通道:
\begin{align}\begin{gathered} \left[{\begin{array}{*{20}{c}} \begin{gathered} {\dot V} \\ {\dot \alpha } \\\end{gathered} \\ \begin{gathered} {\dot q} \\ {{\dot \theta }_{\rm s}} \\\end{gathered}\end{array}} \right]\!\!\! =\!\!\!\left[{\begin{array}{*{20}{c}} {{X_V}}&{{X_\alpha }}&{{X_q}}&{ - g\cos {\gamma _ \circ }} \\ {{Z_V}}&{{Z_\alpha }}&{1 + {Z_q}}&{\dfrac{{ - g\sin {\gamma _{_ \circ }}}}{{{V_ \circ }}}} \\ {{M_V}}&{{M_\alpha }}&{{M_q}}&0 \\ 0&0&1&0\end{array}} \right]\!\!\!\left[{\begin{array}{*{20}{c}} V \\ \alpha \\ q \\ {{\theta _{\rm s}}}\end{array}} \right]\!\!\! +\hfill \\ \quad \quad \quad \quad \quad {\left[{\begin{array}{*{20}{c}} {{X_{{\delta _{{\rm e}}}}}}&{{Z_{{\delta _{{\rm e}}}}}}&{{M_{{\delta _{{\rm e}}}}}}&0\end{array}} \right]^{\text{T}}}{\delta _{{\rm e}}} \\ \left[{\begin{array}{*{20}{c}} \begin{gathered} {\dot \beta } \\ {\dot p} \\\end{gathered} \\ \begin{gathered} {\dot r} \\ {\dot \phi } \\\end{gathered}\end{array}} \right] = \left[\begin{array}{*{20}{c}} {{Y_\beta }}&{{Y_p}}&{{Y_r} - 1}&\dfrac{g}{V_ \circ } \\ {{L_\beta }}&{{L_p}}&{{L_r}}&0 \\ {{N_\beta }}&{{N_p}}&{{N_r}}&0 \\ 0&1&0&0\end{array} \right]\left[{\begin{array}{*{20}{c}} \begin{gathered} \beta \\ p \\\end{gathered} \\ \begin{gathered} r \\ \phi \\\end{gathered}\end{array}} \right] + \\ \quad \quad \quad \quad \quad {\left[{\begin{array}{*{20}{c}} 0&{{L_{{\delta _{{\rm a}}}}}}&{{N_{{\delta _{{\rm a}}}}}}&0 \\ {{Y_{{\delta _{{\rm r}}}}}}&{{L_{{\delta _{{\rm r}}}}}}&{{N_{{\delta _{{\rm r}}}}}}&0\end{array}} \right]^{\text{T}}}\left[{\begin{array}{*{20}{c}} {{\delta _{{\rm a}}}} \\ {{\delta _{{\rm r}}}}\end{array}} \right] \\\end{gathered}\end{align}
(19) 其中,系统的状态为 $V,\alpha,q,\theta_ {\rm s},\beta,p,r,\phi$ ,输入为 ${\delta} _{{\rm e}},\delta _{{\rm a}},{\delta _{{\rm r}}}$ ,变量及参数定义可参见文献[23].
式(19) 所描述的飞行器动力学模型共有44个参数,若将1和0视为已知参数,则未知参数有29 个.
为实现矩阵参数形式多元线性回归模型的参数估计,首先介绍基于子系统分解的最小二乘方法. 以纵向通道为例,将所有状态及输入数据通过DFT变换,并加以组合得:
$\tilde {\pmb{\Phi}} = \left[{\begin{array}{*{20}{c}} {{\tilde{\pmb V}}(1) }&{{\tilde{\pmb \alpha }}(1) }&{{\tilde{\pmb q}}(1) }&{{{{\tilde {\pmb\theta }}}_{{\rm s}}} (1) } & {{{{\tilde{\pmb \delta }}}_{{\rm e}}}(1) } \\ {{\tilde{\pmb V}}(2) }&{{\tilde {\pmb\alpha }}(2) }&{{\tilde{\pmb q}}(2) }&{{{{\tilde{\pmb \theta }}}_{{\rm s}}}(2) } & {{{{\tilde {\pmb\delta }}}_{{\rm e}}}(2) } \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ {{\tilde{\pmb V}}(M)}&{{\tilde {\pmb\alpha }}(M)}&{{\tilde {\pmb q}}(M)}& {{{{\tilde {\pmb\theta }}}_{{\rm s}}}(M)} & {{{{\tilde {\pmb\delta }}}_{{\rm e}}}(M)}\end{array}} \right]$
其中, ${\tilde{\pmb V}}(\cdot)$ , ${\tilde {\pmb\alpha }}(\cdot)$ , ${\tilde{\pmb q}}(\cdot)$ , ${{\tilde {\pmb\theta }}_{{\rm s}}}(\cdot)$ , ${{\tilde {\pmb\delta }}_{{\rm e}}}(\cdot)$ 分别为对应状态时域数据向量经DFT所得到的频域复向量,括号中数字表示DFT定义式(3) 中的频点标号 $(1,2,cdots,M)$ .
由于单变量最小二乘辨识模型中的待辨识参数一般为向量,因此,按纵向通道的状态方程逐行列出未知参数 ${\pmb{\theta }}$ 如下
${{\pmb{\theta }}^{\text{T}}} = \left[{\begin{array}{*{20}{c}} {{{\pmb{\theta }}_1}} \\ {{{\pmb{\theta }}_2}} \\ {{{\pmb{\theta }}_3}} \\ {{{\pmb{\theta }}_4}}\end{array}} \right] = \left[{\begin{array}{*{20}{c}} {{A_{11}}}&{{A_{12}}}&{{A_{13}}}&{{A_{14}}} & {{B_{11}}} \\ {{A_{21}}}&{{A_{22}}}&{{A_{23}}}&{{A_{24}}} & {{B_{21}}} \\ {{A_{31}}}&{{A_{32}}}&{{A_{33}}}&{{A_{34}}} & {{B_{31}}} \\ {{A_{41}}}&{{A_{42}}}&{{A_{43}}}&{{A_{44}}} & {{B_{41}}}\end{array}} \right]$
其中, ${A_{ij}},{B_{ik}}$ 表示未知参数阵 $A$ , $B$ 的各元素, ${{{\pmb{\theta }}_i}}$ 表示第 $i$ 行子状态方程中的所有待估计参数.
限于篇幅,仅列出纵向通道的第3个子动态 $q$ ,对应第3个参数向量 ${{{\pmb{\theta }}_3}}$ 的频域最小二乘模型为
\begin{align}{{\tilde{\pmb z}}_3} = \left[{\begin{array}{*{20}{c}} {\rm j}{\pmb{\omega }}(1) {\tilde {\pmb q}}(1) \\ {\rm j}{\pmb{\omega }}(2) {\tilde {\pmb q}}(2) \\ \vdots \\ {\rm j}{\pmb{\omega }}(M){\tilde {\pmb q}}(M)\end{array}} \right] = \tilde{ \pmb \Phi} \left[{\begin{array}{*{20}{c}} {{A_{31}}} \\ {{A_{32}}} \\ {{A_{33}}} \\ {{A_{34}}} \\ {{B_{31}}}\end{array}} \right]\end{align}
(20) 对其他子系统及对应的参数向量,所采用的 $\tilde{\pmb\Phi}$ 为同一矩阵. 这样,基于待辨识参数逐行分解,得到了 $n=4$ 个子系统的单变量最小二乘辨识模型,采用如式(12)~(14) 所示的任意一种最小二乘算法,每个子系统模型可估计出 $n+r=5$ 个参数,最终得到全部的参数辨识结果.
子系统方法的优点在于: 信息阵的维数不高、 计算量小;对于已知的参数可以不用估计,即信息阵的维数可以进一步降低,从而提高辨识效率.
3.3 整体最小二乘参数估计
由式(20) 所示的子系统分解最小二乘辨识方法,是单变量系统辨识方法在多变量系统上的扩展. 实际上,还可以采用整体最小二乘估计算法求解,下面介绍两种常用的算法.
第一种算法的具体思路是: 参照单变量最小二乘的基本模型,将式(19) 的各子系统辨识模型进行合并,使未知参数矩阵 $\pmb{\theta}$ 串行化转变成参数向量. 也可以说,将式(18) 所示的多元回归模型进行向量化变换 ${\text{Vec}}(\cdot)$ [24],即
\begin{align}{\text{Vec(}}{\tilde{\pmb z}_{\rm E}}{\text{)}} = ({I_n} \otimes{\tilde {\pmb\Phi} _{{\rm E}}}){\text{Vec(}}{{{\pmb \theta}}_{{\rm E}}}) + {\text{Vec(}}{{\tilde {\pmb\nu }}_{{\rm E}}})\end{align}
(21) 其中
${\text{Vec(}}{{{\tilde {\pmb z}}}_{{\rm E}}}{\text{)}} := {{\tilde {\pmb z}}_{\text{total}}}= \left[\begin{gathered} {{{\tilde {\pmb z}}}_1} \\ {{{\tilde {\pmb z}}}_2} \\ \vdots \\ {{{\tilde {\pmb z}}}_n} \\\end{gathered} \right],{\text{Vec(}}{{{\pmb\theta }}_{{\rm E}}}) := {{{\pmb\theta }}_{{\text{total}}}}=\left[\begin{gathered} {{ {\pmb\theta}}_1} \\ {{ {\pmb \theta}}_2} \\ \vdots \\ {{{\pmb\theta }}_n} \\\end{gathered} \right]$${I_n} \otimes {\tilde {\pmb \Phi }_{{\rm E}}} = {I_n} \otimes \tilde {\pmb \Phi} :={\tilde {\pmb \Phi }_{{\text{total}}}} = \left[{\begin{array}{*{20}{c}} {\tilde{\pmb \Phi }}&0&0&0 \\ 0&{\tilde {\pmb\Phi }}&0&0 \\ 0&0& \ddots &0 \\ 0&0&0&{\tilde{\pmb\Phi}}\end{array}} \right]$
${I_n}$ 为 $n$ 阶单位阵, $ \otimes $ 为张量积符号, ${{\tilde{\pmb z}}_{{\text{total}}}}\in{{\bf {C}}^{Mn × 1}}$ , ${{\pmb{\theta}}_{{\text{total}}}}\in{{\bf {R}}^{n(n + r) × 1}}$ , $ \tilde{\pmb\Phi} _{{\text{total}}}\in{{\bf {C}}^{Mn × n(n + r)}}$ .值得注意的是, ${\tilde {\pmb \Phi} _{{\rm E}}}$ 与 $ \tilde{\pmb\Phi}$ 为同一矩阵.
从最小二乘计算式(12) ~(14) 可以看出,最小二乘估计计算量主要在于信息阵的求逆. 由于 $ \tilde{\pmb\Phi}$ 的列向量可能存在近似的线性关系,且在系统激励不充分、多输入信号存在相关性或者DFT计算频点过少时,信息阵 ${\tilde {\pmb \Phi} ^{\rm H}}{\tilde {\pmb\Phi}}$ 会出现病态,从而导致最小二乘估计的计算精度不高且稳定性差. 为了处理矩阵病态问题,本文采用奇异值分解(Singular value decomposition,SVD)方法.对式(21) 所示的整体最小二乘模型,其信息阵为
\begin{align}{\tilde {\pmb\Phi}}^{\rm H}_{{\text{total}}}{ \tilde {\pmb\Phi}_{{\text{total}}}} = \left[{\begin{array}{*{15}{c}} {{{\tilde{\pmb \Phi} }}^{\rm H}{\tilde {\pmb \Phi}} }&0&0&0 \\ 0&{{{\tilde {\pmb \Phi}}}^{\rm H}{\tilde {\pmb\Phi}}}&0&0 \\ 0&0& \ddots &0 \\ 0&0&0&{ {\tilde{\pmb \Phi }}^{\rm H} \tilde{\pmb \Phi }}\end{array}} \right]\end{align}
(22) 该矩阵是由 $n$ 个单变量最小二乘模型的信息阵 $ \tilde {\pmb\Phi }^{\rm H} \tilde{\pmb \Phi} $ 组成的对角方块阵,因此有:
\begin{align}&{(\tilde {\pmb \Phi }^{\rm H}_{{\text{total}}}{{\tilde {\pmb \Phi}}_{{\text{total}}}})^{ - 1}} =\notag\\ &\quad \left[{\begin{array}{*{10}{c}} {{{({\tilde {\pmb \Phi }}^{\rm H}\tilde {\pmb \Phi} )}^{ - 1}}}&0&0&0 \\ 0&{{{({\tilde {\pmb \Phi }}^{\rm H}\tilde {\pmb \Phi} )}^{ - 1}}}&0&0 \\ 0&0& \ddots &0 \\ 0&0&0&{{{({\tilde {\pmb \Phi }}^{\rm H}\tilde {\pmb \Phi} )}^{ - 1}}}\end{array}} \right]\end{align}
(23) 可见,采用这种整体估计算法,会导致辨识模型的阶次大幅增加,但由于矩阵 ${\tilde {\pmb \Phi} _{{\text{total}}}}$ 的特殊形式,使得有关信息阵的计算复杂度没有大幅增加,并且可以一次得到全部参数的估计. 因此,在对算法实时性没有专门要求的场合,这种算法较为常用,易于被工程人员理解和接受[25].
第二种算法就是将单变量最小二乘向多变量情形直接扩展,即式(14) 也能直接用于多元线性回归模型的参数估计.这样所有参数的最小二乘估计可以一次性求得.
3.4 正交多正弦激励信号设计
激励信号是施加在系统平衡状态输入量上的扰动,其设计目的是使被辨识对象激发出与待辨识参数相关的运动模态,提供辨识所需的足够的信息量. 多变量系统的输入往往不止一个,通常将各个输入分开激励,这样做效率很低,且状态转移矩阵并非简单的对角阵,在参数结构未知的情况下无法解耦.这样,当同时施加多个激励信号时,将无法得到准确的辨识结果.
多正弦信号是指由多个谐波正弦信号叠加而成的信号,由于其频谱分布是离散的,因此可以避免DFT中的频谱泄露. 对多输入系统,多正弦信号可以较好地实现单次激励获取整个系统的频率响应,每个通道的多正弦输入信号在离散的频谱上相互错开,频谱特性为
\begin{align}\left\{ \begin{gathered} {{U_p}({n_{{\rm u}}}(k-1) +p)\ne0,\quad k=1,2,\cdots,F,}\\ \qquad \quad p=1,2,\cdots,n_{\rm u} \\ {{U_p}({n_{{\rm u}}}(k-1) +r)=0,\quad r=1,2,\cdots,{n_{{\rm u}}},} \\ \qquad \quad r \ne p\hfill \\\end{gathered} \right.\end{align}
(24) 其中, $F$ 为单个多正弦信号谐波数, $n_{\rm u}$ 为系统输入个数, $p,r$ 为谐波间隔控制参数.
满足式(24) 的多正弦信号组合称为正交多正弦信号,由于各输入信号在频域中正交,因而可以方便地进行多通道同时激励而不会互相干扰,这将大大缩短辨识激励实验时间. 文献[26]证明,组成多正弦信号的不同频率的谐波信号在时域中也是互不相关的.
多正弦信号的设计在于频谱、相位的选择与优化,频谱需要根据被辨识对象的带宽进行设计,相位优化的目的在于降低多正弦信号的峰值因数.但相位优化问题至今无解析解,一般采用随机分布法、Schroeder公式法或搜索优化方法[27].本文采用的Schroeder公式法最适合产生等幅度谱的信号,且生成多正弦信号非常简便. 以 $n_{\rm u}=3$ , $F=10$ 为例,生成的3个互不相关的多正弦信号频谱及对应的时域信号分别如图 1和图 2所示.
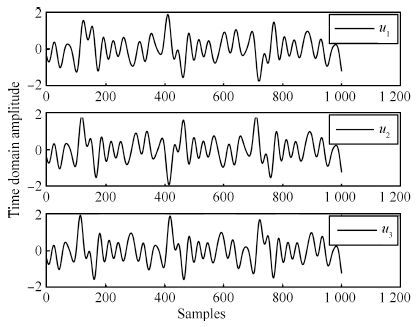 图 2 正交多正弦信号的时间历程(采样点数= 1000)Fig. 2 Plots of orthogonal multi-sine signals (Samples =1000)
图 2 正交多正弦信号的时间历程(采样点数= 1000)Fig. 2 Plots of orthogonal multi-sine signals (Samples =1000)在实际中,激励信号是经由执行机构施加到被辨识系统上的,当执行机构与系统间存在线性或非线性相关性时,式(24) 的信号就不满足正交激励的条件. 此外,闭环反馈也会带来输入输出相关性,正交多正弦信号在这两种条件下不再适用.
4. 实验分析
4.1 单输入多输出系统频域最小二乘辨识
考虑F-16飞机纵向通道模型参数为[28]
\begin{align} & {{{A}}_{{\text{lon}}}} =\notag\\ & \quad \left[{\begin{array}{*{10}{c}} 0.0171 & -3.6619 & -1.0969 & -32.1740 \\ -0.0003 & -0.7534 & 0.9279 & 0 \\ 0 & -4.3115 & -1.2657 & 0 \\ 0 & 0 & 1 & 0\end{array}} \right]{\text{ }} \notag\\ & {{{B}}_{{\text{lon}}}} = {\left[{\begin{array}{*{10}{c}} 9.9927 & -0.1595 & -13.9671& 0\end{array}} \right]^{\text{T}}}\end{align}
(25) 输入及状态定义见式(19) .
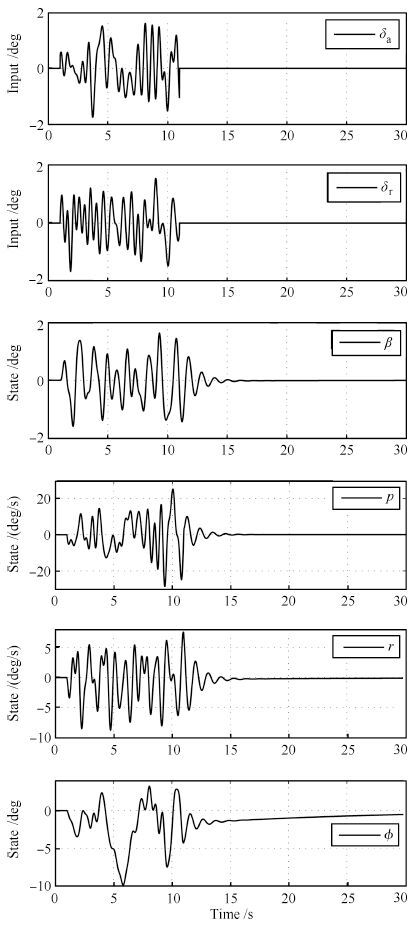
在二重阶跃(Doublet)信号激励下,系统的输入及状态响应曲线如图 3所示.
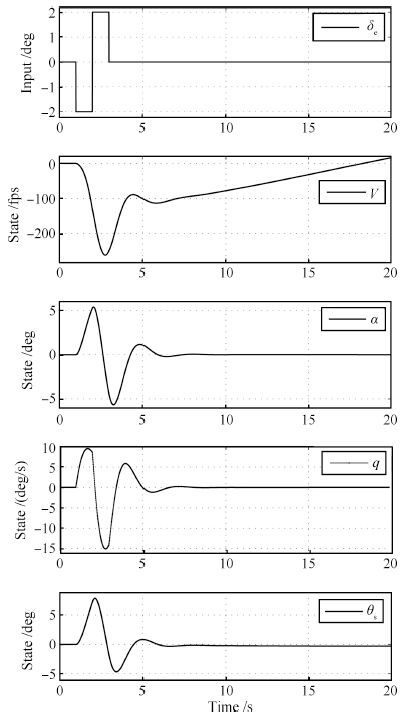 图 3 F-16飞机纵向通道输入及响应时间历程Fig. 3 Plots of input and response of F-16 aircraft longitudinal channel
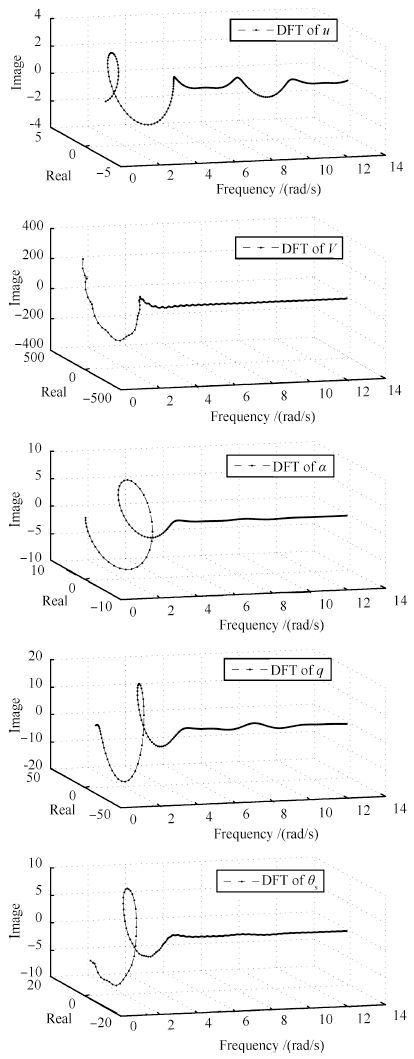
图 3 F-16飞机纵向通道输入及响应时间历程Fig. 3 Plots of input and response of F-16 aircraft longitudinal channel系统的输入及各状态经DFT变换至复数域后,如图 4所示. 其中,DFT的频带根据飞行器的特性选为[0.1,2.2]Hz,频率分辨率0.01Hz,即频点数为211个.
对DFT得到的数据分别采用式(12) ~(14) 所示的三种频域最小二乘算法,得到的参数估计结果如表 1所示.
表 1 不同频域最小二乘算法的结果比较Table 1 Comparison of results with different frequency domain least-square algorithmsLS algorithm ${\hat{A}_{{\text{lon}}}}$ $\hat{B}_{{\rm{lon}}}$ LS_Re -0.0161 -3.8292 -1.0548 -32.0137 10.1047 -0.0003 -0.7514 0.9272 -0.0020 -0.1613 -0.0004 -4.1575 -1.3190 -0.1572 -14.1069 0.0009 -0.0693 1.0046 0.0579 0.0139 LS_Im -0.0175 -3.7048 -1.0633 -32.1205 10.0944 -0.0002 -0.7543 0.9274 0.0005 -0.1609 0.0026 -4.3783 -1.3070 0.0307 -14.0746 0.0019 -0.1118 1.0048 0.0929 0.0298 LS_EAM -0.0165 -3.7773 -1.0591 -32.0588 10.1050 -0.0002 -0.7523 0.9273 -0.0012 -0.1613 0.0002 -4.2252 -1.3142 -0.0985 -14.1047 0.0010 -0.0655 1.0036 0.0544 0.0161 考虑到实际中的真实参数是未知的,因此利用式(15) 的误差协方差阵估计值获得参数绝对误差的估计值:
\begin{align} \hat{\pmb\delta} _{\text{abs}} = \sqrt {{\rm diag}\{{\rm cov}(\hat{\pmb\theta})\}}\end{align}
(26) 其中,diag $\{\cdot\}$ 表示提取矩阵的对角元素.与其他估计方法不同的是,最小二乘方法的优点在于可以给出参数的误差,因而更具实用价值.图 5给出了式(25) 模型的20个参数估计误差及其置信区间,其中原点表示参数辨识的结果与真值间的误差,而竖线则表示该误差的99% 置信区间. 为指示清晰,三种最小二乘方法的结果在每个参数附近位置略微错开.
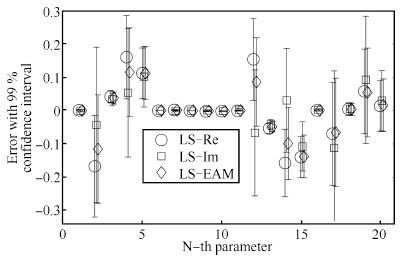 图 5 单输入系统参数辨识结果的误差及其置信区间Fig. 5 Error and confidence interval of identification results for a single-input system
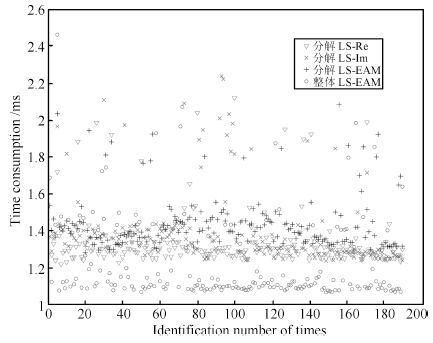
图 5 单输入系统参数辨识结果的误差及其置信区间Fig. 5 Error and confidence interval of identification results for a single-input system图 6给出了不同算法的计算时间对比,采用了式(12) $\sim$ (14) 的三种频域最小二乘算式,并分别以分解和整体最小二乘的方式进行计算,基于同样条件和模型,每种算法仿真190次,计算机采用的处理器为Intel i5 CPU 1.7GHz.
结合表 1、图 5和图 6可看出,三种频域最小二乘算法给出的结果精度及计算效率基本相当,由于整体LS-EAM算法采用了直接计算而非函数调用,因此耗时略少,但总的来说与子系统分解辨识方法的计算效率相当. 当参数为实数时,可采用任一算法; 当参数为复数时,如系统模型包含延迟环节,则只能采用LS-EAM算法.
4.2 多输入多输出系统最小二乘辨识
以无人机侧向通道模型为例,参数矩阵为[29]
\begin{align} {{{A}}_{{\text{lat}}}} =& \left[{\begin{array}{*{10}{c}} -0.0187 & 0.0399 & -1.1989 & 0.2366 \\ -99.2236 & -13.1772 & 3.2226 & 0 \\ 23.0595 & -0.4875 & -1.9818 & 0 \\ 0 & 1 & 0 & 0\end{array}} \right]{\text{ }} \notag\\ {{{B}}_{{\text{lat}}}} =& {\left[{\begin{array}{*{10}{c}} 0.0490 & -184.2693 & -5.0177 & 0 \\ -0.4602 & 32.1348 & -28.0895 & 0\end{array}} \right]^{\text{T}}}\end{align}
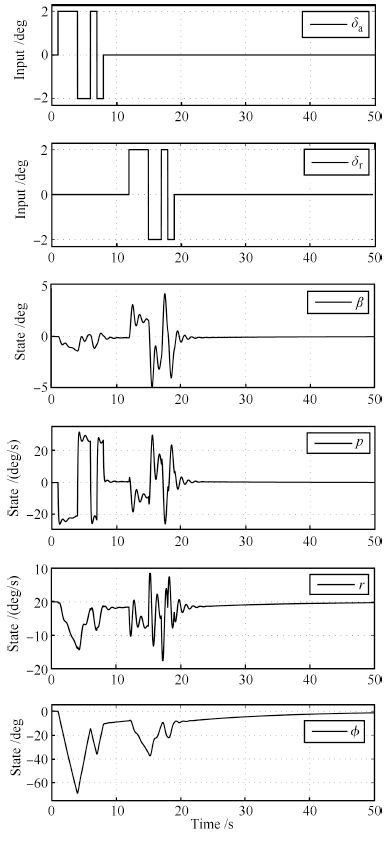
(27) 为实现多输入机动解相关激励,设计两路频率涵盖 $[0.1,2.2]$ Hz的正交多正弦信号,为避免频点重叠,这里分别选为 $87$ 、 $43$ ,激励时长的选取则保证所有谐波不少于1个整周期,此处设为10s.作为对比,选择3-2-1-1信号对系统的两个输入通道进行分时激励,采取分时激励的原因在于实现输入对状态响应的解耦;否则,无法辨识出多输入控制矩阵 ${B_{{\text{lat}}}}$ 的全部参数.两种激励方式的信号及响应分别如图 7和图 8 所示.
对两种激励条件所得的数据进行频域辨识,DFT的分析频点数仍取均匀分布的211个频点,频域最小二乘采用LS-EAM子系统分解辨识算法,得到的参数与真值间的误差对比如图 9所示. 由于部分参数真值为0,不便于比较相对误差,因此图 9中的误差均为绝对误差,竖线表示该误差的99 $\%$ 置信区间; $x$ 轴坐标为参数的序号,按参数扩张矩阵 $[A_{\text{lat}}\;\;B_{\text{lat}}]$ 行优先索引,这样,每个子图分别对应系统模型中的每一个子系统的参数辨识结果.
对比图 7~9可以看到,正交多正弦信号同时激励与多输入信号分时激励所得到的辨识结果精度相当,但前者在辨识时间上具有明显优势,特别是当输入量较多时,这种优势就更为明显.
 图 9 MIMO 系统参数辨识结果的误差及置信区间Fig. 9 Error and con¯dence interval of identi¯cation results for a MIMO system
图 9 MIMO 系统参数辨识结果的误差及置信区间Fig. 9 Error and con¯dence interval of identi¯cation results for a MIMO system5. 结论
1) 将时域信号的微分问题转化为频域中的简单乘法计算,避免了微分求解的困难.
2) 在频率变换域,连续时间系统状态空间模型的参数估计可以采用与时域类似的方法,包括最小二乘、子空间辨识等方法,本文则着重研究了频域最小二乘的三种求解算法.
3) 单变量最小二乘方法可以方便地推广到多变量系统,子系统分解方法与整体最小二乘方法均能得到准确的参数估计结果.
4) 对MIMO这类典型的多变量系统,采用多输入解相关激励技术,以正交多正弦信号同时对系统所有通道进行激励,大大提高了辨识效率.
-


图 2 细粒度图像数据库示意图(所有图像均取自不同类别)
Fig. 2 Illustration of fine-grained datasets (the images are sampled from different categories)
表 1 CUB200-2011[1]数据库上的算法性能比较(其中BBox指标注框信息(Bounding Box), Parts指局部区域信息)
Table 1 Performance of different algorithms in CUB200-2011[1] (where BBox refers to bounding box, Parts means part annotations)
算法 BBox
(训练)Parts
(训练)BBox
(测试)Parts
(测试)简要描述 准确率(%) CUB[1] √ √ SIFT + BoW + SVM 10.3 CUB[1] √ √ √ √ SIFT + BoW + SVM 17.3 [2mm] POOF[26] √ √ √ POOF + SVM 56.8 POOF[26] √ √ √ √ POOF + SVM 73.3 Alignment[31] √ √ Fisher + SVM 62.7 Symbiotic[30] √ √ Fisher + SVM 61 [2mm] DeCAF[25] √ √ Alex-Net + Logistic Regression 61 Part R-CNN[43] √ √ Alex-Net + Fine-Tune + SVM 73.9 Pose Normalized CNN[48] √ √ Alex-Net + Fine-Tune + SVM 75.7 Pose Normalized CNN[48] √ √ √ √ Alex-Net + Fine-Tune + SVM 85.4 [2mm] Two-level Attention[56] Alex-Net 69.7 Two-level Attention[56] VGG16-Net 77.9 Zhang et al.[12] VGG16-Net + Fine-Tune + SVM 79.3 Constellations[58] VGG19-Net + Fine-Tune + Flip + SVM 81 Bilinear CNN[13] VGG19-Net/VGG-M + Flip 84.1 Spatial Transformer Net[55] Inception[62] + Flip 84.1  下载: 导出CSV
下载: 导出CSV
-
[1] Wah C, Branson S, Welinder P, Perona P, Belongie S. The Caltech-UCSD Birds-200-2011 Dataset, Technical Report CNS-TR-2011-001, California Institute of Technology, Pasadena, CA, USA, 2011 [2] Bosch A, Zisserman A, Muñoz X. Scene classification using a hybrid generative/discriminative approach. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(4):712-727 doi: 10.1109/TPAMI.2007.70716 [3] Wu J X, Rehg J M. CENTRIST:a visual descriptor for scene categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8):1489-1501 doi: 10.1109/TPAMI.2010.224 [4] Gehler P, Nowozin S. On feature combination for multiclass object classification. In:Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 221-228 [5] Jarrett K, Kavukcuoglu K, Ranzato M, LeCun Y. What is the best multi-stage architecture for object recognition? In:Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 2146-2153 [6] Wright J, Yang A Y, Ganesh A, Sastry S S, Ma Y. Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2):210-227 doi: 10.1109/TPAMI.2008.79 [7] 李晓莉, 达飞鹏.基于排除算法的快速三维人脸识别方法.自动化学报, 2010, 36(1):153-158 http://www.aas.net.cn/CN/abstract/abstract13642.shtmlLi Xiao-Li, Da Fei-Peng. A rapid method for 3D face recognition based on rejection algorithm. Acta Automatica Sinica, 2010, 36(1):153-158 http://www.aas.net.cn/CN/abstract/abstract13642.shtml [8] Khosla A, Jayadevaprakash N, Yao B P, Li F F. Novel dataset for fine-grained image categorization. In:Proceedings of the 1st Workshop on Fine-Grained Visual Categorization (FGVC), IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Springs, USA:IEEE, 2011. [9] Nilsback M E, Zisserman A. Automated flower classification over a large number of classes. In:Proceedings of the 6th Indian Conference on Computer Vision, Graphics & Image Processing. Bhubaneswar, India:IEEE, 2008. 722-729 [10] Krause J, Stark M, Deng J, Li F F. 3D object representations for fine-grained categorization. In:Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops (ICCVW). Sydney, Australia:IEEE, 2013. 554-561 [11] Maji S, Rahtu E, Kannala J, Blaschko M, Vedaldi A. Fine-grained visual classification of aircraft[Online], available:https://arxiv.org/abs/1306.5151, June 21, 2013 [12] Zhang Y, Wei X S, Wu J X, Cai J F, Lu J B, Nguyen V A, Do M N. Weakly supervised fine-grained categorization with part-based image representation. IEEE Transactions on Image Processing, 2016, 25(4):1713-1725 doi: 10.1109/TIP.2016.2531289 [13] Lin T Y, RoyChowdhury A, Maji S. Bilinear CNN models for fine-grained visual recognition. In:Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV). Santiago, Chile:IEEE, 2015. 1449-1457 [14] 张琳波, 王春恒, 肖柏华, 邵允学.基于Bag-of-phrases的图像表示方法.自动化学报, 2012, 38(1):46-54 http://www.aas.net.cn/CN/abstract/abstract17634.shtmlZhang Lin-Bo, Wang Chun-Heng, Xiao Bai-Hua, Shao Yun-Xue. Image representation using bag-of-phrases. Acta Automatica Sinica, 2012, 38(1):46-54 http://www.aas.net.cn/CN/abstract/abstract17634.shtml [15] 余旺盛, 田孝华, 侯志强.基于区域边缘统计的图像特征描述新方法.计算机学报, 2014, 37(6):1398-1410 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201406018.htmYu Wang-Sheng, Tian Xiao-Hua, Hou Zhi-Qiang. A new image feature descriptor based on region edge statistical. Chinese Journal of Computers, 2014, 37(6):1398-1410 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201406018.htm [16] 颜雪军, 赵春霞, 袁夏. 2DPCA-SIFT:一种有效的局部特征描述方法.自动化学报, 2014, 40(4):675-682 http://www.aas.net.cn/CN/abstract/abstract18333.shtmlYan Xue-Jun, Zhao Chun-Xia, Yuan Xia. 2DPCA-SIFT:an efficient local feature descriptor. Acta Automatica Sinica, 2014, 40(4):675-682 http://www.aas.net.cn/CN/abstract/abstract18333.shtml [17] Lowe D G. Object recognition from local scale-invariant features. In:Proceedings of the 7th IEEE International Conference on Computer Vision. Kerkyra, Greece:IEEE, 1999. 1150-1157 [18] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In:Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, USA:IEEE, 2005. 886-893 [19] Jégou H, Douze M, Schmid C, Pérez P. Aggregating local descriptors into a compact image representation. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, USA:IEEE, 2010. 3304-3311 [20] Perronnin F, Dance C. Fisher kernels on visual vocabularies for image categorization. In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, USA:IEEE, 2007. 1-8 [21] Sánchez J, Perronnin F, Mensink T, Verbeek J. Image classification with the Fisher vector:theory and practice. International Journal of Computer Vision, 2013, 105(3):222-245 doi: 10.1007/s11263-013-0636-x [22] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In:Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA:MIT Press, 2012. 1097-1105 [23] 高莹莹, 朱维彬.深层神经网络中间层可见化建模.自动化学报, 2015, 41(9):1627-1637 http://www.aas.net.cn/CN/abstract/abstract18736.shtmlGao Ying-Ying, Zhu Wei-Bin. Deep neural networks with visible intermediate layers. Acta Automatica Sinica, 2015, 41(9):1627-1637 http://www.aas.net.cn/CN/abstract/abstract18736.shtml [24] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553):436-444 doi: 10.1038/nature14539 [25] Donahue J, Jia Y Q, Vinyals O, Hoffman J, Zhang N, Tzeng E, Darrell T. DeCAF:a deep convolutional activation feature for generic visual recognition. In:Proceedings of the 31st International Conference on Machine Learning. Beijing, China:ACM, 2014. 647-655 [26] Berg T, Belhumeur P N. POOF:part-based one-vs.-one features for fine-grained categorization, face verification, and attribute estimation. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Portland, USA:IEEE, 2013. 955-962 [27] Perronnin F, Sánchez J, Mensink T. Improving the fisher kernel for large-scale image classification. In:Proceedings of the 11th European Conference on Computer Vision. Berlin Heidelberg, Germany:Springer, 2010. 143-156 [28] Bo L, Ren X, Fox D. Kernel descriptors for visual recognition. In:Proceedings of the 24th Annual Conference on Neural Information Processing Systems. Vancouver, Canada:MIT Press, 2010. 244-252 [29] Branson S, Van Horn G, Wah C, Perona P, Belongie S. The ignorant led by the blind:a hybrid human-machine vision system for fine-grained categorization. International Journal of Computer Vision, 2014, 108(1-2):3-29 doi: 10.1007/s11263-014-0698-4 [30] Chai Y N, Lempitsky V, Zisserman A. Symbiotic segmentation and part localization for fine-grained categorization. In:Proceedings of the 14th IEEE International Conference on Computer Vision (ICCV). Sydney, Australia:IEEE, 2013. 321-328 [31] Gavves E, Fernando B, Snoek C G M, Smeulders A W M, Tuytelaars T. Fine-grained categorization by alignments. In:Proceedings of the 14th IEEE International Conference on Computer Vision (ICCV). Sydney, Australia:IEEE, 2013. 1713-1720 [32] Yao B P, Bradski G, Li F F. A codebook-free and annotation-free approach for fine-grained image categorization. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, USA:IEEE, 2012. 3466-3473 [33] Yang S L, Bo L F, Wang J, Shapiro L. Unsupervised template learning for fine-grained object recognition. In:Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, USA:MIT Press, 2012. 3122-3130 [34] Branson S, Wah C, Schroff F, Babenko B, Welinder P, Perona P, Belongie S. Visual recognition with humans in the loop. In:Proceedings of the 11th European Conference on Computer Vision. Berlin Heidelberg, Germany:Springer, 2010. 438-451 [35] Wah C, Branson S, Perona P, Belongie S. Multiclass recognition and part localization with humans in the loop. In:Proceedings of the 13th IEEE International Conference on Computer Vision (ICCV). Barcelona, Spain:IEEE, 2011. 2524-2531 [36] LeCun Y, Boser B, Denker J S, Henderson D, Howard R E, Hubbard W, Jackel L D. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989, 1(4):541-551 doi: 10.1162/neco.1989.1.4.541 [37] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11):2278-2324 doi: 10.1109/5.726791 [38] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer, 2014. 818-833 [39] Gong Y C, Wang L W, Guo R Q, Lazebnik S. Multi-scale orderless pooling of deep convolutional activation features. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer, 2014. 392-407 [40] Cimpoi M, Maji S, Vedaldi A. Deep filter banks for texture recognition and segmentation. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA:IEEE, 2015. 3828-3836 [41] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[Online], available:https://arxiv.org/abs/1409.1556, April 10, 2015 [42] Welinder P, Branson S, Mita T, Wah C, Schroff F, Belongie S, Perona P. Caltech-UCSD Birds 200, Technical Report CNS-TR-2010-001, California Institute of Technology, Pasadena, CA, USA, 2010 [43] Zhang N, Donahue J, Girshick R, Darrell T. Part-based R-CNNs for fine-grained category detection. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer, 2014. 834-849 [44] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, USA:IEEE, 2014. 580-587 [45] Viola P, Jones M J. Robust real-time face detection. International Journal of Computer Vision, 2004, 57(2):137-154 doi: 10.1023/B:VISI.0000013087.49260.fb [46] Wu J X, Liu N N, Geyer C, Rehg M J. C^4:a real-time object detection framework. IEEE Transactions on Image Processing, 2013, 22(10):4096-4107 doi: 10.1109/TIP.2013.2270111 [47] Uijlings J R R, van de Sande K E A, Gevers T, Smeulders A W M. Selective search for object recognition. International Journal of Computer Vision, 2013, 104(2):154-171 doi: 10.1007/s11263-013-0620-5 [48] Branson S, Van Horn G, Belongie S, Perona P. Bird species categorization using pose normalized deep convolutional nets[Online], available:https://arxiv.org/abs/1406.2952, June 11, 2014 [49] Branson S, Beijbom O, Belongie S. Efficient large-scale structured learning. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Portland, USA:IEEE, 2013. 1806-1813 [50] Krause J, Jin H L, Yang J C, Li F F. Fine-grained recognition without part annotations. In:Proceedings of the 15th IEEE International Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA:IEEE, 2015. 5546-5555 [51] Guillaumin M, Küttel D, Ferrari V. Imagenet auto-annotation with segmentation propagation. International Journal of Computer Vision, 2014, 110(3):328-348 doi: 10.1007/s11263-014-0713-9 [52] Kuettel D, Guillaumin M, Ferrari V. Segmentation propagation in imagenet. In:Proceedings of the 12th European Conference on Computer Vision. Berlin Heidelberg, Germany:Springer, 2012. 459-473 [53] Lin D, Shen X Y, Lu C W, Jia J Y. Deep LAC:deep localization, alignment and classification for fine-grained recognition. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA:IEEE, 2015. 1666-1674 [54] Xu Z, Huang S L, Zhang Y, Tao D C. Augmenting strong supervision using web data for fine-grained categorization. In:Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV). Santiago, Chile:IEEE, 2015. 2524-2532 [55] Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K. Spatial transformer networks. In:Proceedings of the 29th Annual Conference on Neural Information Processing Systems. Montreal, Canada:MIT Press, 2015. 2017-2025 [56] Xiao T J, Xu Y C, Yang K Y, Zhang J X, Peng Y X, Zhang Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA:IEEE, 2015. 842-850 [57] Zhang Y, Wu J X, Cai J F. Compact representation for image classification:to choose or to compress. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, USA:IEEE, 2014. 907-914 [58] Simon M, Rodner E. Neural activation constellations:unsupervised part model discovery with convolutional networks. In:Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV). Santiago, Chile:IEEE, 2015. 1143-1151 [59] Simon M, Rodner E, Denzler J. Part detector discovery in deep convolutional neural networks. In:Proceedings of the 12th Asian Conference on Computer Vision. Singapore:Springer, 2014. 162-177 [60] Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks:visualising image classification models and saliency maps[Online], available:https://arxiv.org/abs/1312.6034, April 19, 2014 [61] Wang D Q, Shen Z Q, Shao J, Zhang W, Xue X Y, Zhang Z. Multiple granularity descriptors for fine-grained categorization. In:Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV). Santiago, Chile:IEEE, 2015. 2399-2406 [62] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA:IEEE, 2015. 1-9 [63] Hall D, Perona P. Fine-grained classification of pedestrians in video:benchmark and state of the art. In:Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA:IEEE, 2015. 5482-5491 [64] Liu Y, Zhang D S, Lu G J, Ma W Y. A survey of content-based image retrieval with high-level semantics. Pattern Recognition, 2007, 40(1):262-282 doi: 10.1016/j.patcog.2006.04.045 [65] Datta R, Joshi D, Li J, Wang J Z. Image retrieval:ideas, influences, and trends of the new age. ACM Computing Surveys, 2008, 40(2):Article No.5 http://dl.acm.org/citation.cfm?id=1348248 [66] Felzenszwalb P F, Girshick R B, McAllester D, Ramanan D. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9):1627-1645 doi: 10.1109/TPAMI.2009.167 [67] Wei X S, Luo J H, Wu J X. Selective convolutional descriptor aggregation for fine-grained image retrieval. IEEE Transactions on Image Processing, 2017, 26(6):2868-2881 doi: 10.1109/TIP.2017.2688133 [68] Xie L X, Wang J D, Zhang B, Tian Q. Fine-grained image search. IEEE Transactions on Multimedia, 2015, 17(5):636-647 doi: 10.1109/TMM.2015.2408566 -

 下载:
下载:

计量
- 文章访问数: 6788
- HTML全文浏览量: 1276
- PDF下载量: 2990
- 被引次数: 0
