

Research on Multi-hypothesis Residual Reconstruction Algorithm Based on Adaptive Sampling
-
摘要: 为保证遥感视频序列的高质量重构,本文结合视频序列的高时空冗余特点,在基于块的分布式视频压缩感知(Distributed video compressed sensing,DVCS)框架的基础上提出了一种基于自适应采样的多假设预测残差重构模型及基于变采样率的多假设预测残差重构算法.首先对目标帧进行预测,根据各块预测精度的不同自适应地分配采样率;然后用变采样率多假设预测残差重构算法重构出目标帧;最后利用双向运动估计对重构结果进行修正.仿真结果表明该算法能够在降低采样率的同时保证良好的主客观重构质量;相同采样率条件下,重构精度比MC-BCS-SPL算法提高大约7dB,比MH-BCS-SPL算法提高大约1dB.Abstract: To guarantee an adequate quality reconstruction of remote sensing video and to make use of the character of mass information redundancy in video, this paper proposes a kind of adaptive sampling and multi-hypothesis residual reconstruction model and algorithm based on the framework called distributed video compressed sensing (DVCS). Firstly, the current frame is predicted, then sampling rates are adaptively allocated according to the precise degrees of the blocks in the predicted frame. Afterwards, the current frame is reconstructed using the variable sampling rates multi-hypothesis residual reconstruction algorithm. Finally, the reconstructed frame is revised by bilateral motion estimation technic. Simulation shows that the proposed model and algorithm can assure low sampling rate and high reconstruction quality simultaneously, and that the model can offer a PSNR gain of around 7dB higher the MC-BCS-SPL algorithm, and a gain of around 1dB than higher the MH-BCS-SPL algorithm when the sampling rates are same.1) 本文责任编委 杨健
-
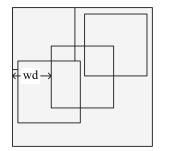
图 1 帧内多假设预测的候选块示意图
Fig. 1 Sketch map of candidates in intraframe multi-hypothesis prediction
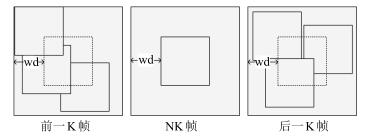
图 2 帧间多假设预测的候选块示意图
Fig. 2 Sketch map of candidates in interframe multi-hypothesis prediction

图 3 本文提出的自适应采样多假设预测残差重构系统的框架
Fig. 3 The multi-hypothesis residual reconstruction framework based on adaptive sampling

图 4 不同算法对foreman序列第30帧图像的恢复效果
Fig. 4 Reconstruction of the 30th frame in the foreman video using different algorithms

图 5 遥感视频序列中第10帧图像的恢复效果
Fig. 5 Reconstruction of the 10th frame in the remote sensing video
表 1 各测试序列在不同C下NK帧的平均重构PSNR (dB)和SSIM
Table 1 Average PSNR (dB) and SSIM of each video with different C
Foreman Stefan Bus Flower PSNR SSIM PSNR SSIM PSNR SSIM PSNR SSIM $C$ = 0.3 35.782 0.927 25.249 0.844 25.576 0.790 14.238 0.635 $C$ = 0.4 36.389 0.933 26.252 0.870 26.638 0.824 14.047 0.647 $C$ = 0.5 36.761 0.937 27.147 0.888 27.449 0.847 14.420 0.655 $C$ = 0.6 36.906 0.939 27.723 0.898 27.923 0.860 14.731 0.672 $C$ = 0.7 36.994 0.940 28.086 0.904 28.234 0.869 15.515 0.684 $C$ = 0.8 37.015 0.942 28.211 0.908 28.533 0.882 17.571 0.708 $C$ = 0.9 36.785 0.941 28.144 0.906 28.467 0.880 23.562 0.768 $C$ = 1.0 36.371 0.941 28.169 0.910 28.417 0.876 16.211 0.700  下载: 导出CSV
下载: 导出CSV
表 2 不同$S{R_a}$和$\Delta SR$下K帧和NK帧的采样率
Table 2 Sampling rates of K frames and NK frames with different $S{R_a}$ and $\Delta SR$
$SR$ $S{R_a} = 0.3$ $S{R_a} = 0.4$ $S{R_a} = 0.5$ $S{R_a} = 0.6$ $\Delta SR = 0$ $S{R_K}$ 0.3 0.4 0.5 0.6 $S{R_{NK}}$ 0.3 0.4 0.5 0.6 $\Delta SR = 0.05$ $S{R_K}$ 0.35 0.45 0.55 0.65 $S{R_{NK}}$ 0.25 0.35 0.45 0.55 $\Delta SR = 0.1$ $S{R_K}$ 0.4 0.5 0.6 0.7 $S{R_{NK}}$ 0.2 0.3 0.4 0.5 $\Delta SR = 0.15$ $S{R_K}$ 0.45 0.55 0.65 0.75 $S{R_{NK}}$ 0.15 0.25 0.35 0.45 $\Delta SR = 0.2$ $S{R_K}$ 0.5 0.6 0.7 0.8 $S{R_{NK}}$ 0.1 0.2 0.3 0.4 $\Delta SR = 0.25$ $S{R_K}$ 0.55 0.65 0.75 0.85 $S{R_{NK}}$ 0.05 0.15 0.25 0.35
下载: 导出CSV
表 3 测试序列在不同$\Delta SR$下的平均重构性能比较: PSNR (dB); SSIM
Table 3 Average reconstruction quality of each video using different $\Delta SR$: PSNR (dB); SSIM
$\Delta SR$ $S{R_a} = 0.3$ $S{R_a} = 0.4$ $S{R_a} = 0.5$ $S{R_a} = 0.6$ Foreman 0 32.123; 0.874 34.655; 0.915 36.562; 0.935 38.700; 0.955 0.05 33.256; 0.897 35.295; 0.924 37.033; 0.941 39.126; 0.959 0.1 33.904; 0.908 35.885; 0.931 37.762; 0.950 39.667; 0.963 0.15 34.317; 0.913 36.393; 0.937 38.322; 0.954 40.341; 0.968 0.2 34.618; 0.918 36.857; 0.942 38.950; 0.959 41.120; 0.973 0.25 34.289; 0.916 37.170; 0.945 39.528; 0.963 41.962; 0.977 Stefan 0 25.020; 0.808 27.296; 0.867 29.304; 0.904 31.930; 0.938 0.05 25.539; 0.830 27.735; 0.882 29.812; 0.916 32.370; 0.946 0.1 25.929; 0.845 28.218; 0.895 30.292; 0.926 33.000; 0.955 0.15 26.216; 0.855 28.662; 0.905 30.873; 0.935 33.681; 0.962 0.2 26.331; 0.857 29.022; 0.913 31.352; 0.942 34.549; 0.968 0.25 26.041; 0.837 29.299; 0.917 31.810; 0.947 35.347; 0.972 Bus 0 25.526; 0.772 27.713; 0.840 29.674; 0.883 31.978; 0.920 0.05 26.029; 0.793 28.069; 0.852 30.114; 0.894 32.446; 0.929 0.1 26.350; 0.806 28.394; 0.862 30.564; 0.905 32.846; 0.937 0.15 26.487; 0.812 28.697; 0.871 30.954; 0.914 33.406; 0.945 0.2 26.354; 0.806 28.939; 0.878 31.322; 0.921 33.940; 0.952 0.25 25.795; 0.777 29.014; 0.880 31.727; 0.9280 34.623; 0.958 Flower 0 18.436; 0.702 19.294; 0.764 20.959; 0.814 28.512; 0.928 0.05 18.748; 0.719 19.440; 0.768 21.040; 0.823 28.832; 0.935 0.1 19.053; 0.730 20.121; 0.783 21.029; 0.826 29.379; 0.945 0.15 19.054; 0.736 20.590; 0.788 21.389; 0.830 30.065; 0.954 0.2 19.056; 0.724 20.982; 0.797 21.832; 0.834 30.899; 0.962 0.25 18.610; 0.695 20.854; 0.795 22.546; 0.843 31.957; 0.970
下载: 导出CSV
4(a) $\Delta SR = 0$时不同测量率下各视频重构算法的性能比较: PSNR (dB); SSIM; T(s)
4(a) Reconstruction performance of each video using different algorithms when $\Delta SR = 0$: PSNR (dB); SSIM; T(s)
$\Delta SR = 0$ $S{R_a}$ MC-BCS-SPL MH-BCS-SPL ASR-MH-BCS-SPL Foreman 0.3 30.417; 0.837; 33.815 32.520; 0.899; 71.347 33.688; 0.904; 229.674 0.4 32.144; 0.875; 31.505 34.448; 0.926; 72.805 36.194; 0.931; 229.834 0.5 33.864; 0.904; 31.852 36.561; 0.946; 73.047 38.341; 0.950; 233.199 0.6 35.846; 0.931; 29.365 38.725; 0.964; 73.274 40.688; 0.966; 233.328 Stefan 0.3 23.729; 0.768; 30.651 25.690; 0.842; 68.406 26.327; 0.850; 222.506 0.4 25.297; 0.823; 31.438 27.876; 0.893; 73.059 28.846; 0.901; 232.134 0.5 26.916; 0.865; 30.276 30.057; 0.927; 73.346 31.422; 0.934; 231.002 0.6 28.738; 0.901; 30.769 32.444; 0.952; 73.597 34.209; 0.957; 234.602 Bus 0.3 23.955; 0.735; 32.855 26.915; 0.837; 71.504 27.117; 0.832; 226.984 0.4 25.379; 0.793; 30.149 29.053; 0.889; 70.539 29.409; 0.888; 224.230 0.5 26.640; 0.833; 29.474 31.094; 0.924; 71.013 31.632; 0.925; 226.318 0.6 28.272; 0.872; 28.700 33.481; 0.953; 72.386 34.253; 0.953; 225.288 Flower 0.3 22.096; 0.805; 35.040 23.362; 0.843; 70.165 23.796; 0.850; 228.090 0.4 23.500; 0.853; 34.598 25.312; 0.895; 73.011 26.063; 0.904; 232.301 0.5 24.931; 0.890; 29.932 27.520; 0.933; 73.209 28.525; 0.940; 234.678 0.6 26.433; 0.918; 31.428 29.996; 0.960; 73.325 31.503; 0.965; 233.758
下载: 导出CSV
4(b) $\Delta SR = 0.25$时不同测量率下各视频重构算法的性能比较: PSNR (dB); SSIM; T(s)
4(b) Reconstruction performance of each video using different algorithms when $\Delta SR = 0.25$: PSNR (dB); SSIM; T(s)
$\Delta SR = 0.25$ $S{R_a}$ MC-BCS-SPL MH-BCS-SPL ASR-MH-BCS-SPL Foreman 0.3 23.204; 0.705; 33.925 33.155; 0.905; 67.849 33.099; 0.902; 219.409 0.4 27.756; 0.805; 33.789 36.164; 0.940; 69.078 36.804; 0.941; 222.530 0.5 29.768; 0.840; 33.654 38.075; 0.954; 69.232 38.860; 0.958; 225.625 0.6 31.127; 0.867; 34.944 40.015; 0.971; 71.942 41.067; 0.972; 225.247 Stefan 0.3 16.972; 0.509; 32.812 23.871; 0.804; 68.001 23.551; 0.786; 225.259 0.4 21.273; 0.739; 31.591 27.558; 0.906; 69.245 28.270; 0.906; 226.554 0.5 23.301; 0.804; 31.600 30.328; 0.943; 71.778 31.310; 0.945; 229.342 0.6 24.802; 0.841; 30.313 32.660; 0.965; 71.874 34.004; 0.968; 227.454 Bus 0.3 17.285; 0.431; 34.425 23.744; 0.723; 67.839 23.264; 0.694; 221.197 0.4 21.071; 0.657; 33.323 26.469; 0.869; 71.593 27.396; 0.871; 225.255 0.5 23.075; 0.755; 31.213 29.383; 0.912; 71.109 30.579; 0.922; 229.852 0.6 24.328; 0.799; 30.213 31.707; 0.951; 70.613 33.331; 0.951; 229.566 Flower 0.3 16.426; 0.602; 35.366 21.073; 0.747; 67.389 20.670; 0.725; 222.119 0.4 20.589; 0.807; 33.905 25.294; 0.897; 68.826 25.441; 0.894; 222.122 0.5 22.241; 0.857; 33.102 28.094; 0.943; 69.513 28.610; 0.946; 225.607 0.6 23.276; 0.881; 33.876 31.266; 0.971; 70.842 32.138; 0.973; 232.007
下载: 导出CSV
表 5 遥感视频在不同算法, 不同采样率下的重构性能: PSNR (dB); SSIM; T(s)
Table 5 Reconstruction performance of the remote sensing video using different algorithms and different sampling rates: PSNR (dB); SSIM; T(s)
$\Delta SR$ $S{R_a}$ MC-BCS-SPL MH-BCS-SPL ASR-MH-BCS-SPL 0 0.3 29.997; 0.907; 71.999 28.497; 0.903; 170.374 30.319; 0.911; 566.243 0.4 32.581; 0.937; 75.129 30.946; 0.934; 170.660 33.020; 0.940; 557.305 0.5 34.795; 0.956; 77.276 31.137; 0.952; 170.849 35.557; 0.959; 556.948 0.6 37.479; 0.972; 74.780 34.517; 0.969; 176.408 37.910; 0.974; 557.896 0.25 0.3 22.910; 0.779; 77.666 30.353; 0.959; 169.677 36.093; 0.965; 556.974 0.4 27.855; 0.901; 79.855 32.148; 0.971; 170.455 38.752; 0.977; 568.386 0.5 30.714; 0.929; 76.857 33.001; 0.979; 170.616 41.318; 0.986; 567.555 0.6 32.499; 0.949; 73.635 35.026; 0.988; 170.555 45.786; 0.993; 556.889
下载: 导出CSV
表 6 三种算法各个环节的时耗和重构性能: T(s); PSNR (dB); SSIM
Table 6 Time and reconstruction quality of three algorithms in every step: T(s)
ASR-MH-BCS-SPL MC-BCS-SPL MH-BCS-SPL ${A_1}$ 67.320; -; - ${C_1}$ 0.005; -; - ${H_1}$ 0.003; -; - ${A_2}$ 68.087; 37.528; 0.948 ${C_2}$ 25.732; 29.425; 0.835 ${H_2}$ 68.411; 36.261; 0.938 ${A_3}$ 16.563; -; - ${C_3}$ 0.230; -; - ${A_4}$ 67.945; 37.543; 0.948 ${C_4}$ 7.369; 29.502; 0.849
下载: 导出CSV
-
[1] Donoho D L. Compressed sensing. IEEE Transactions on Information Theory, 2006, 52(4):1289-1306 doi: 10.1109/TIT.2006.871582 [2] Candes E J, Wakin M B. An introduction to compressive sampling. IEEE Signal Processing Magazine, 2008, 25(2):21-30 doi: 10.1109/MSP.2007.914731 [3] 任越美, 张艳宁, 李映.压缩感知及其图像处理应用研究进展与展望.自动化学报, 2014, 40(8):1563-1575 http://www.aas.net.cn/CN/abstract/abstract18426.shtmlRen Yue-Mei, Zhang Yan-Ning, Li Ying. Advances and perspective on compressed sensing and application on image processing. Acta Automatica Sinica, 2014, 40(8):1563-1575 http://www.aas.net.cn/CN/abstract/abstract18426.shtml [4] 沈燕飞, 李锦涛, 朱珍民, 张勇东, 代锋.基于非局部相似模型的压缩感知图像恢复算法.自动化学报, 2015, 41(2):261-272 http://www.aas.net.cn/CN/abstract/abstract18605.shtmlShen Yan-Fei, Li Jin-Tao, Zhu Zhen-Min, Zhang Yong-Dong, Dai Feng. Image reconstruction algorithm of compressed sensing based on nonlocal similarity model. Acta Automatica Sinica, 2015, 41(2):261-272 http://www.aas.net.cn/CN/abstract/abstract18605.shtml [5] Waters A E, Sankaranarayanan A C, Baraniuk R G. SpaRCS:recovering low-rank and sparse matrices from compressive measurements. In:Proceedings of the 2011 Neural Information Processing Systems (NIPS). Barcelona, Spain:IEEE, 2011. 1089-1097 https://dl.acm.org/citation.cfm?id=2986581 [6] Fowler J E, Mun S, Tramel E W. Multiscale block compressed sensing with smoothed projected landweber reconstruction. In:Proceedings of the 19th European Signal Processing Conference. Barcelona, Spain:IEEE, 2011. 564-568 http://ieeexplore.ieee.org/document/7073994/ [7] Willett R M, Marcia R F, Nichols J M. Compressed sensing for practical optical imaging systems:a tutorial. Optical Engineering, 2011, 50(7):1-13, Article No. 72601 doi: 10.1117/1.3596602.full [8] Thompson D, Harmany Z, Marcia R. Sparse video recovery using linearly constrained gradient projection. In:Proceedings of the 2011 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Prague, Czech Republic:IEEE, 2011. 1329-1332 http://ieeexplore.ieee.org/document/5946657/ [9] Baron D, Duarte M F, Wakin M B, Sarvotham S, Baraniuk R G. Distributed compressive sensing[Online], available:http://www.arxiv.org/abs/0901.3403, February 17, 2016 [10] Zhang B J, Lei Q, Wang W, Mu J S. Distributed video coding of secure compressed sensing. Security and Communication Networks, 2015, 8(14):2416-2419 doi: 10.1002/sec.v8.14 [11] Liu H X, Song B, Tian F, Qin H, Liu X. Optimal-correlation-based reconstruction for distributed compressed video sensing. Journal of Visual Communication and Image Representation, 2015, 31:197-207 doi: 10.1016/j.jvcir.2015.06.020 [12] Chen J, Su K X, Wang W X, Lan C D. Residual distributed compressive video sensing based on double side information. Acta Automatica Sinica, 2014, 40(10):2316-2323 doi: 10.1016/S1874-1029(14)60363-3 [13] Tramel E W, Fowler J E. Video compressed sensing with multihypothesis. In:Proceedings of the 2011 Data Compression Conference (DCC). Snowbird, UT, USA:IEEE, 2011. 193-202 http://ieeexplore.ieee.org/document/5749477/ [14] Chen C, Tramel E W, Fowler J E. Compressed sensing recovery of images and video using multihypothesis predictions. In:Proceedings of Conference Record of the 46th Asilomar Conference on Signals, Systems, and Computers (ASILOMAR). Pracific Grove, CA, USA:IEEE, 2011. 1193-1198 http://ieeexplore.ieee.org/document/6190204/ [15] Warnell G, Reddy D, Chellappa R. Adaptive rate compressive sensing for background subtraction. In:Proceedings of the 2012 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Kyoto, Japan:IEEE, 2012. 1477-1480 http://ieeexplore.ieee.org/document/6288170/ [16] Srinivasarao B K N, Gogineni V C, Mula S, Chakrabarti I. VLSI friendly framework for scalable video coding based on compressed sensing[Online], available:arxiv.org/abs/1602.07453, April 5, 2016 [17] 练秋生, 田天, 陈书贞, 郭伟.基于变采样率的多假设预测分块视频压缩感知.电子与信息学报, 2013, 35(1):203-208 http://www.wenkuxiazai.com/doc/273fe231f242336c1eb95e5c.htmlLian Qiu-Sheng, Tian Tian, Chen Shu-Zhen, Guo Wei. Block compressed sensing of video based on variable sampling rates and multihypothesis predictions. Journal of Electronics and Information Technology, 2013, 35(1):203-208 http://www.wenkuxiazai.com/doc/273fe231f242336c1eb95e5c.html [18] 李如春, 李林, 常丽萍, 基于变采样率压缩感知的视频压缩研究.电子技术应用, 2015, 41(10):147-149, 153 http://www.cqvip.com/QK/90393X/201510/666124609.htmlLi Ru-Chun, Li Lin, Chang Li-Ping. Block compressed sensing of video based on variable sampling rates. Application of Electronic Technique, 2015, 41(10):147-149, 153 http://www.cqvip.com/QK/90393X/201510/666124609.html [19] 左觅文, 常侃, 施静兰, 覃团发.一种自适应采样率视频压缩感知方案.电视技术, 2015, 39(2):66-70 http://edu.wanfangdata.com.cn/Periodical/Detail/dsjs201502019Zuo Mi-Wen, Chang Kan, Shi Jing-Lan, Qin Tuan-Fa. Adaptive rate compressed video sensing scheme. Video Engineering, 2015, 39(2):66-70 http://edu.wanfangdata.com.cn/Periodical/Detail/dsjs201502019 [20] Mun S, Fowler J E. Residual reconstruction for block-based compressed sensing of video. In:Proceedings of the 2011 Data Compression Conference (DCC). Snowbird, UT, USA:IEEE, 2011. 183-192 http://ieeexplore.ieee.org/document/5749476/ [21] Choi B D, Han J W, Kim C S, Ko S J. Motion-compensated frame interpolation using bilateral motion estimation and adaptive overlapped block motion compensation. IEEE Transactions on Circuits and Systems for Video Technology, 2007, 17(4):407-416 doi: 10.1109/TCSVT.2007.893835 -

 下载:
下载:

计量
- 文章访问数: 2303
- HTML全文浏览量: 243
- PDF下载量: 512
- 被引次数: 0
