

Research on TV-L1 Optical Flow Model for Image Registration Based on Fractional-order Differentiation
-
摘要: 图像的非刚性配准在计算机视觉和医学图像分析中有着重要的作用.TV-L1(全变分L1范数、Total variation-L1)光流模型是解决非刚性配准问题的有效方法,但TV-L1光流模型的正则项是一阶导数,会导致纹理特征等具有弱导数性质的信息模糊.针对该问题,将G-L(Grünwald-Letnikov)分数阶引入TV-L1光流模型,提出基于G-L分数阶微分的TV-L1光流模型,并应用原始-对偶算法求解该模型.新的模型用G-L分数阶微分代替正则项中的一阶导数,由于分数阶微分比整数阶微分具有更好的细节描述能力,并能有效地、非线性地保留具有弱导数性质的纹理特征,从而提高图像的配准精度.另外,通过实验给出了配准精度与G-L分数阶模板参数之间的关系,从而为模板最佳参数的选取提供了依据.尽管不同类型的图像其最佳参数是不同的,但是其最佳配准阶次一般在1 ~2之间.理论分析和实验结果均表明,提出的新模型能够有效地提高图像配准的精度,适合于包含较多弱纹理和弱边缘信息的医学图像配准,该模型是TV-L1光流模型的重要延伸和推广.Abstract: In computer vision and medical image analysis, non-rigid image registration is a challenging task. TV-L1 (Total variation-L1) optical flow model has been proved to be an effective method in the field of non-rigid image registration. It can solve the problem of fuzzy edge caused by smooth displacement fields of Horn-Schunck, but its first-order derivative in regularization term leads to fuzzy texture information with weak derivative property. Aiming at the problem, this paper introduces G-L (Grünwald-Letnikov) fractional differentiation to TV-L1 optical flow model, and proposes a new TV-L1 optical flow model based on fractional differentiation, and then finds the solution of the model using primal-dual algorithm. In this paper we use Grünwald-Letnikov fractional order differential instead of the first-order derivative in the regularization term for its better ability of detail description than first-order's. Then we purposefully control to retain or inhibit the texture information with weak derivative nature, thus improving the registration accuracy. Experimental results show that the proposed method has a better registration accuracy in registration of texture information with weak derivative, and that it can be considered an important extension and generalization of TV-L1 optical flow modes.1) 本文责任编委 张长水
-
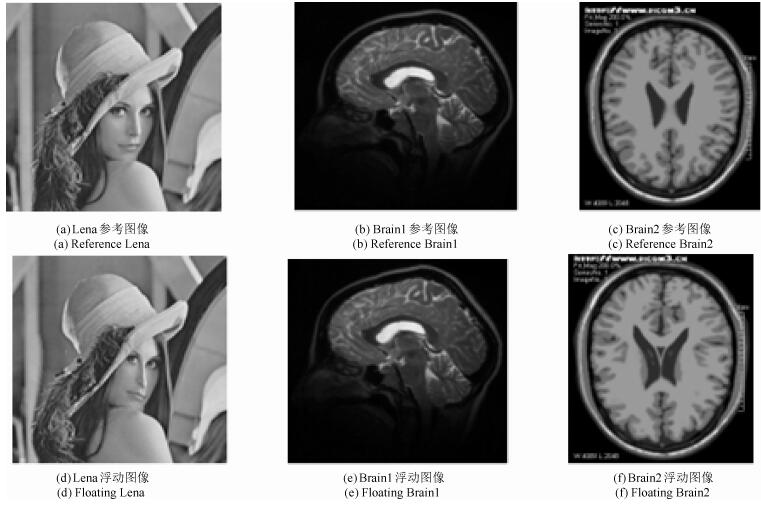
图 4 验图像(其中第一行为参考图像, 第二行为与参考图像对应的浮动图像)
Fig. 4 Experimental images (The first line are reference images, the second line are floating images corresponding to reference images)

图 5 Lena图像实验(第一行为浮动图像和配准后图像, 第二行为差值图像. (a)为浮动图像, (b) $\sim$ (e)为配准后的图像; (b) TV-L$^{1}$方法; (c)本文方法($\alpha=1.2, k=1$); (d)本文方法($\alpha=1.2, k=2$); (e)本文方法($\alpha=1.2, k=3$); (f) $\sim$ (j)分别为第一行图像与参考图像(图 4(a))的差值图像)
Fig. 5 Lena image (The first line is floating image and registered image, the second line is difference image. (a) Floating image, (b) $\sim$ (e) are registered images, (b) TV-L$^{1}$, (c) Our method ($\alpha=1.2, k=1$), (d) Our method ($\alpha=1.2, k=2$), (e) Our method ($\alpha=1.2, k=3$), (f) $\sim$ (j) are difference images)
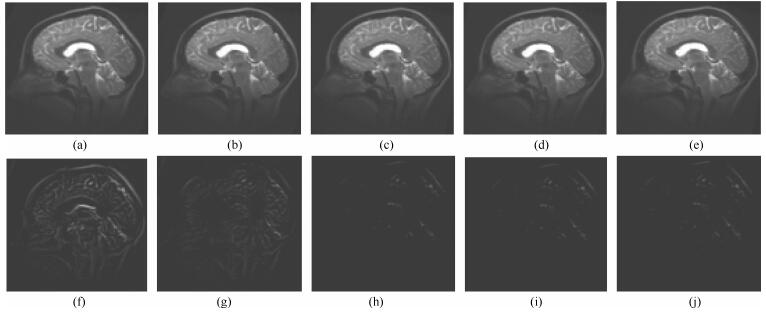
图 7 Brain1图像实验(第一行为浮动图像和配准后图像, 第二行为差值图像. (a)为浮动图像, (b) $\sim$ (e)为配准后的图像; (b) TV-L$^{1}$方法; (c)本文方法($\alpha=1.3, k=1$); (d)本文方法($\alpha=1.3, k=2$); (e)本文方法($\alpha=1.3, k=3$); (f) $\sim$ (j)分别为第一行图像与参考图像(图 4(b))的差值图像)
Fig. 7 Brain1 image (The first line is floating image and registered image, the second line is difference image. (a) Floating image, (b) $\sim$ (e) are registered images, (b) TV-L$^{1}$, (c) Our method ($\alpha=1.3, k=1$), (d) Our method ($\alpha=1.3, k=2$), (e) Our method ($\alpha=1.3, k=3$), (f) $\sim$ (j) are difference images)

图 8 Brain2图像实验(第一行为浮动图像和配准后图像, 第二行为差分图像. (a)为浮动图像, (b) $\sim$ (e)为配准后的图像; (b) TV-L$^{1}$方法; (c)本文方法($\alpha=1.3$, $k=1$); (d)本文方法($\alpha=1.3$, $k=2$); (e)本文方法($\alpha=1.3$, $k=3$); (f) $\sim$ (j)分别为第一行图像与参考图像(图 4(c))的差值图像)
Fig. 8 Brain2 image. The first line is floating image and registered image, the second line is difference image ((a) floating image, (b) $\sim$ (e) are registered images, (b) TV-L$^{1}$, (c) Our method ($\alpha=1.3$, $k=1$), (d) Our method ($\alpha=1.3$, $k=2$), (e) Our method ($\alpha=1.3$, $k=3$), (f) $\sim$ (j) are difference images)
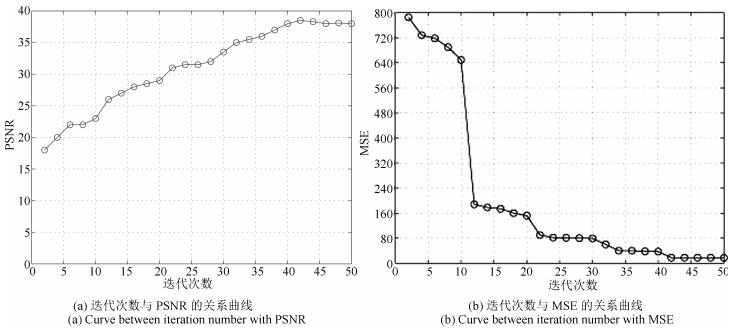
表 1 参考图像和配准图像的均方误差(MSE)
Table 1 Mean square error (MSE) of reference image and registered
输入图片 配准前 TV-L $^{1}$ 本文算法($k$ = 1) 本文算法($k$ = 2) 本文算法($k$ = 3) Lena ($\alpha$ = 1.2) 669.33 14.86 10.36 9.17 11.56 Brain1 ($\alpha$ = 1.3) 295.85 27.51 18.20 15.93 20.22 Brain2 ($\alpha$ = 1.3) 813.77 31.02 11.47 9.95 17.89  下载: 导出CSV
下载: 导出CSV
表 2 峰值信噪比(PSNR)
Table 2 Peak signal to noise ratio (PSNR)
输入图片 配准前 TV-L $^{1}$ 本文算法($k$ = 1) 本文算法($k$ = 2) 本文算法($k$ = 3) Lena ($\alpha$ = 1.2) 19.32 35.55 38.18 38.88 37.50 Brain1 ($\alpha$ = 1.3) 22.78 33.73 35.34 36.17 34.89 Brain2 ($\alpha$ = 1.3) 19.03 31.21 37.73 38.15 35.60
下载: 导出CSV
-
[1] 蒲亦非, 王卫星.数字图像的分数阶微分掩模及其数值运算规则.自动化学报, 2007, 33(11):1128-1135 http://www.aas.net.cn/CN/abstract/abstract13448.shtmlPu Yi-Fei, Wang Wei-Xing. Fractional differential masks of digital image and their numerical implementation algorithms. Acta Automatica Sinica, 2007, 33(11):1128-1135 http://www.aas.net.cn/CN/abstract/abstract13448.shtml [2] 陈青, 刘金平, 唐朝晖, 李建奇, 吴敏.基于分数阶微分的图像边缘细节检测与提取.电子学报, 2013, 41(10):1873-1880 doi: 10.3969/j.issn.0372-2112.2013.10.001Chen Qing, Liu Jin-Ping, Tang Zhao-Hui, Li Jian-Qi, Wu Min. Detection and extraction of image edge curves and detailed features using fractional differentiation. Acta Electronica Sinica, 2013, 41(10):1873-1880 doi: 10.3969/j.issn.0372-2112.2013.10.001 [3] Pu Y F, Siarry P, Zhou J L, Liu Y G, Zhang N, Huang G, Liu Y Z. Fractional partial differential equation denoising models for texture image. Science China Information Sciences, 2014, 57(7):1-19 doi: 10.1007/s11432-014-5112-x [4] Liu J, Chen S C, Tan X Y. Fractional order singular value decomposition representation for face recognition. Pattern Recognition, 2008, 41(1):378-395 doi: 10.1016/j.patcog.2007.03.027 [5] Zhang Y, Pu Y F, Hu J R, Zhou J L. A class of fractional-order variational image inpainting models. Applied Mathematics and Information Sciences, 2012, 6(2):299-306 http://www.researchgate.net/publication/260210952_A_Class_of_Fractional-Order_Variational_Image_Inpainting_Models [6] Ren Z M. Adaptive active contour model driven by fractional order fitting energy. Signal Processing, 2015, 117:138-150 doi: 10.1016/j.sigpro.2015.05.009 [7] 薛鹏, 杨佩, 曹祝楼, 贾大宇, 董恩清.基于平衡系数的Active Demons非刚性配准算法.自动化学报, 2016, 42(9):1389-1400 http://www.aas.net.cn/CN/abstract/abstract18927.shtmlXue Peng, Yang Pei, Cao Zhu-Lou, Jia Da-Yu, Dong En-Qing. Active demons non-rigid registration algorithm based on balance coefficient. Acta Automatica Sinica, 2016, 42(9):1389-1400 http://www.aas.net.cn/CN/abstract/abstract18927.shtml [8] 张桂梅, 曹红洋, 储珺, 曾接贤.基于Nyström低阶近似和谱特征的图像非刚性配准.自动化学报, 2015, 41(2):429-438 http://www.aas.net.cn/CN/abstract/abstract18621.shtmlZhang Gui-Mei, Cao Hong-Yang, Chu Jun, Zeng Jie-Xian. Non-rigid image registration based on low-rank Nyström approximation and spectral feature. Acta Automatica Sinica, 2015, 41(2):429-438 http://www.aas.net.cn/CN/abstract/abstract18621.shtml [9] 闫德勤, 刘彩凤, 刘胜蓝, 刘德山.大形变微分同胚图像配准快速算法.自动化学报, 2015, 41(8):1461-1470 http://www.aas.net.cn/CN/abstract/abstract18720.shtmlYan De-Qin, Liu Cai-Feng, Liu Sheng-Lan, Liu De-Shan. A fast image registration algorithm for diffeomorphic image with large deformation. Acta Automatica Sinica, 2015, 41(8):1461-1470 http://www.aas.net.cn/CN/abstract/abstract18720.shtml [10] Thirion J P. Image matching as a diffusion process:an analogy with Maxwell's demons. Medical Image Analysis, 1998, 2(3):243-260 doi: 10.1016/S1361-8415(98)80022-4 [11] Wang H, Dong L, O'Daniel J, Mohan R, Garden A A, Ang K K, Kuban D A, Bonnen M, Chang J Y, Cheung R. Validation of an accelerated 'demons' algorithm for deformable image registration in radiation therapy. Physics in Medicine and Biology, 2005, 50(12):2887-2905 doi: 10.1088/0031-9155/50/12/011 [12] Palos G, Betrouni N, Coulanges M, Vermandel M, Devlaminck V, Rousseau J. Multimodal matching by maximisation of mutual information and optical flow technique. In:Proceedings of the 26th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (IEMBS). San Francisco, CA, USA:IEEE, 2004. 1679-1682 http://europepmc.org/abstract/MED/17272026 [13] Pock T, Urschler M, Zach C, Beichel R, Bischof H. A duality based algorithm for TV-L1-optical-flow image registration. Medical Image Computing and Computer-Assisted Intervention-MICCAI 2007. Berlin Heidelberg:Springer-Verlag, 2007. 511-518 [14] Pérez J S, Meinhardt-Llopis E, Facciolo G. TV-L1 optical flow estimation. Image Processing on Line, 2013, 3:137-150 doi: 10.5201/ipol [15] Yip S S F, Coroller T P, Sanford N N, Huynh E, Mamon H, Aerts H J W L, Berbeco R I. Use of registration-based contour propagation in texture analysis for esophageal cancer pathologic response prediction. Physics in Medicine and Biology, 2016, 61(2):906-922 doi: 10.1088/0031-9155/61/2/906 [16] Horn B K, Schunck B G. Determining optical flow. In:Technical Symposium East. Washington, D.C., USA:International Society for Optics and Photonics, 1981. 319-331 [17] Rudin L I, Osher S, Fatemi E. Nonlinear total variation based noise removal algorithms. Physica D:Nonlinear Phenomena, 1992, 60(1-4):259-268 doi: 10.1016/0167-2789(92)90242-F [18] Chambolle A, Pock T. A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of Mathematical Imaging and Vision, 2011, 40(1):120-145 doi: 10.1007/s10851-010-0251-1 [19] Cafagna D. Fractional calculus:a mathematical tool from the past for present engineers. IEEE Industrial Electronics Magazine, 2007, 1(2):35-40 doi: 10.1109/MIE.2007.901479 -

 下载:
下载:


计量
- 文章访问数: 2918
- HTML全文浏览量: 403
- PDF下载量: 876
- 被引次数: 0
