

-
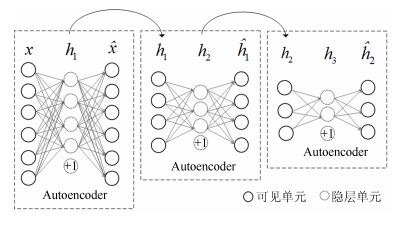
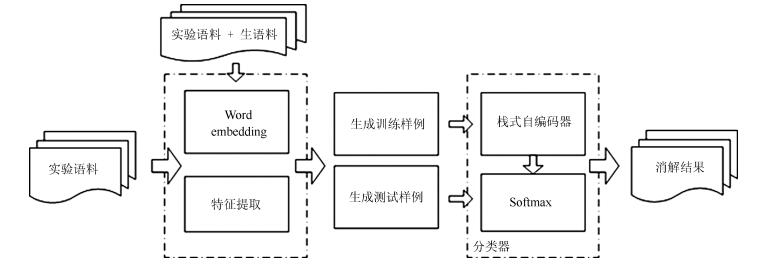
摘要: 针对维吾尔语名词短语指代现象,提出了一种利用栈式自编码深度学习算法进行基于语义特征的指代消解方法.通过对维吾尔语名词短语指称性的研究,提取出利于消解任务的13项特征.为提高特征对文本语义的表达,在特征集中引入富含词汇语义及上下文位置关系的Word embedding.利用深度学习机制无监督的提取隐含的深层语义特征,训练Softmax分类器进而完成指代消解任务.该方法在维吾尔语指代消解任务中的准确率为74.5%,召回率为70.6%,F值为72.4%.实验结果证明,深度学习模型较浅层的支持向量机更合适于本文的指代消解任务,对Word embedding特征项的引入,有效地提高了指代消解模型的性能.
-
关键词:
- 深度学习 /
- 栈式自编码神经网络 /
- 指代消解 /
- Word embedding /
- 维吾尔语
Abstract: Aimed at the reference phenomena of Uyghur noun phrases, a method using stacked autoencoder model to achieve coreference resolution based on semantic characteristics is presented. Through the study of noun phrases referentiality, we pick up beneficial 13 features for coreference resolution tasks. In order to improve the expression of features for semantic text, Word embedding is added into feature sets, which makes feature sets contain lexical semantic information and context positional relationship. A deep learning algorithm is proposed for unsupervised detection of implicit semantic information, and also introduced is a softmax classifier to decide whether the two markables actually corefer. Experiments show that precision rate, recall rate and F value of coreference resolution reach 74.5%, 70.6% and 72.4%, respectively, which demonstrates that the proposed method on coreference resolution of Uyghur noun phrase and introduction of Word embedding to feature sets are able to improve the performance of coreference resolution system.-
Key words:
- Deep learning /
- stacked autoencoder /
- coreference resolution /
- word embedding /
- Uyghur
1) 本文责任编委 张民 -
表 1 指示词库
Table 1 The demonstrative thesaurus
指人指物 指性质 指数量 指地点 





, 








$\cdots$ $\cdots$ $\cdots$ $\cdots$  下载: 导出CSV
下载: 导出CSV
表 2 维吾尔语名词短语指代消解训练和测试样例
Table 2 Training or testing sample format for Uyghur noun phrases
先行语 照应语 样例值(13个特征值+ 50维先行语、照应语Word embedding) 是否指代 

0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0 0.133, $-$0.053, 0.114, $\cdots$, $-$0.108
0.177, $-$0.008, 0.127, $\cdots$, $-$0.055是 

0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0 0.076, 0.099, 0.019, $\cdots$, $-$0.069
0.177, $-$0.008, 0.127, $\cdots$, $-$0.055否 

0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0 0.060, $-$0.135, 0.277, $\cdots$, $-$0.042
0.177, $-$0.008, 0.127, $\cdots$, $-$0.055否
下载: 导出CSV
表 3 SAE模型最优参数
Table 3 Optimal parameters of SAE
参数 $\rho$ $\beta$ $\lambda$ maxIter 值 0.1 3 3E$-$3 800
下载: 导出CSV
表 4 基于SAE模型的有效性验证
Table 4 The validation of SAE effectiveness
模型 $P$ (%) $R$ (%) $F$ (%) SAE$^1$ 61.775 73.319 67.054 SAE$^2$ 66.064 71.256 68.562 SAE$^3$ 66.134 71.995 68.940 SAE$^4$ 68.695 71.743 70.186 SVM 66.727 70.115 68.379
下载: 导出CSV
表 5 特征集对结果的影响
Table 5 The influence of introducing features sets
特征项 $P$ (%) $R$ (%) $F$ (%) AnProperNoun 46.079 0.856 1.681 CaProperNoun 66.159 0.713 1.411 AnDefiniteNP 75.897 1.102 2.172 CaDefiniteNP 59.932 4.579 8.508 AnDemonstrativeNP 65.432 8.409 14.903 CaDemonstrativeNP 57.092 9.112 15.716 AnPossessionNP 60.411 26.912 37.222 CaPossessionNP 44.439 38.403 41.201 AnPossessionNP 48.231 51.082 49.616 CaPossessionNP 45.831 70.334 55.498 PropertyFit 64.470 51.108 57.017 SinglePluralFit 58.631 80.205 67.742 FullMatch 68.695 71.743 70.186
下载: 导出CSV
表 6 Word embedding的引入对实验的影响
Table 6 The influence of introducing word embedding
模型 $P$ (%) $R$ (%) $F$ (%) SAE$^1$ 60.915 74.569 67.054 SAE$^1$ + WE 64.382 70.103 67.121 SAE$^2$ 66.064 71.256 68.562 SAE$^2+$ WE 66.571 71.419 68.910 SAE$^3$ 66.134 71.995 68.940 SAE$^3$ + WE 68.215 72.375 70.233 SAE$^4$ 68.695 71.743 70.186 SAE$^4$+ WE 72.352 69.743 71.024
下载: 导出CSV
表 7 Word embedding维度对实验的影响
Table 7 The influence of adjusting word embedding dimension

SAE$^4$ + WE SVM + WE $P$ (%) $R$ (%) $F$ (%) $P$ (%) $R$ (%) $F$ (%) 10 72.4 69.7 71.0 67.0 70.3 68.6 50 73.9 69.8 71.8 70.5 69.8 70.1 100 74.5 70.6 72.4 69.9 69.9 69.9 150 75.8 68.4 71.9 69.0 70.4 69.7 200 77.0 67.0 71.9 68.2 70.9 69.4
下载: 导出CSV
-
[1] Zelenko D, Aone C, Tibbetts J. Coreference resolution for information extraction. In:Proceedings of the 2004 ACL Workshop on Reference Resolution and its Applications. Barcelona, Spain:ACL, 2004. 9-16 [2] Soon W M, Ng H T, Lim D C Y. A machine learning approach to coreference resolution of noun phrases. Computational Linguistics, 2001, 27(4):521-544 doi: 10.1162/089120101753342653 [3] Bergsma S, Lin D K. Bootstrapping path-based pronoun resolution. In:Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics. Sydney:Association for Computational Linguistics, 2006. 33-40 [4] Ng V. Semantic class induction and coreference resolution. In:Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics. Prague, Czech Republic:ACL, 2007. 536-543 [5] Bengtson E, Roth D. Understanding the value of features for coreference resolution. In:Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. Honolulu:Association for Computational Linguistics, 2008. 294-303 [6] 周俊生, 黄书剑, 陈家骏, 曲维光.一种基于图划分的无监督汉语指代消解算法.中文信息学报, 2007, 21(2):77-82 http://d.wanfangdata.com.cn/Periodical/zwxxxb200702012Zhou Jun-Sheng, Huang Shu-Jian, Chen Jia-Jun, Qu Wei-Guang. A new graph clustering algorithm for Chinese noun phrase coreference resolution. Journal of Chinese Information Processing, 2007, 21(2):77-82 http://d.wanfangdata.com.cn/Periodical/zwxxxb200702012 [7] 王海东, 胡乃全, 孔芳, 周国栋.指代消解中语义角色特征的研究.中文信息学报, 2009, 23(1):23-29 http://d.wanfangdata.com.cn/Periodical/zwxxxb200901004Wang Hai-Dong, Hu Nai-Quan, Kong Fang, Zhou Guo-Dong. Research on semantic role information in anaphora resolution. Journal of Chinese Information Processing, 2009, 23(1):23-29 http://d.wanfangdata.com.cn/Periodical/zwxxxb200901004 [8] 孔芳, 周国栋.基于树核函数的中英文代词消解.软件学报, 2012, 23(5):1085-1099 http://d.wanfangdata.com.cn/Periodical/rjxb201205005Kong Fang, Zhou Guo-Dong. Pronoun resolution in English and Chinese languages based on tree kernel. Journal of Software, 2012, 23(5):1085-1099 http://d.wanfangdata.com.cn/Periodical/rjxb201205005 [9] 奚雪峰, 周国栋.基于Deep Learning的代词指代消解.北京大学学报(自然科学版), 2014, 50(1):100-110 http://d.wanfangdata.com.cn/Periodical/bjdxxb201401015Xi Xue-Feng, Zhou Guo-Dong. Pronoun resolution based on deep learning. Acta Scientiarum Naturalium Universitatis Pekinensis, 2014, 50(1):100-110 http://d.wanfangdata.com.cn/Periodical/bjdxxb201401015 [10] Mikolov T, Sutskever I, Chen K, Corrado G S, Dean J. Distributed representations of words and phrases and their compositionality. In:Proceedings of the 2013 Advances in Neural Information Processing Systems 26. Lake Tahoe, Nevada, USA:Curran Associates, Inc., 2013. 3111-3119 [11] Kim Y. Convolutional neural networks for sentence classification. In:Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar:Association for Computational Linguistics, 2014. 746-1751 [12] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. In:Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA, 2011. 315-323 [13] Glorot X, Bordes A, Bengio Y. Domain adaptation for large-scale sentiment classification:a deep learning approach. In:Proceedings of the 28th International Conference on Machine Learning. Bellevue, Washington, USA:Omnipress, 2011. 513-520 [14] Lu S X, Chen Z B, Xu B. Learning new semi-supervised deep auto-encoder features for statistical machine translation. In:Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore, Maryland, USA:ACL, 2014. 122-132 [15] 王厚峰, 梅铮.鲁棒性的汉语人称代词消解.软件学报, 2005, 16(5):700-707 http://d.wanfangdata.com.cn/Periodical/rjxb200505008Wang Hou-Feng, Mei Zheng. Robust pronominal resolution within Chinese text. Journal of Software, 2005, 16(5):700-707 http://d.wanfangdata.com.cn/Periodical/rjxb200505008 [16] 帕提古力·麦麦提. 基于向心理论的维吾尔语语篇回指研究[博士学位论文], 中央民族大学, 中国, 2010Patgul·Mamat. Uyghur Discourse Anaphora based on Centering Theory[Ph.D. dissertation], Minzu University of China, China, 2010 [17] 贺宇, 潘达, 付国宏.基于自动编码特征的汉语解释性意见句识别.北京大学学报(自然科学版), 2015, 51(2):235-240 http://d.wanfangdata.com.cn/Periodical/bjdxxb201502006He Yu, Pan Da, Fu Guo-Hong. Chinese explanatory opinionated sentence recognition based on auto-Encoding features. Acta Scientiarum Naturalium Universitatis Pekinensis, 2015, 51(2):235-240 http://d.wanfangdata.com.cn/Periodical/bjdxxb201502006 -

 下载:
下载:

计量
- 文章访问数: 2108
- HTML全文浏览量: 418
- PDF下载量: 561
- 被引次数: 0
