

-
摘要: 动量算法理论上可以加速受限玻尔兹曼机(Restricted Boltzmann machine,RBM)网络的训练速度.本文通过对现有动量算法进行仿真研究,发现现有动量算法在受限玻尔兹曼机网络训练中加速效果较差,且在训练后期逐渐失去了加速性能.针对以上问题,本文首先基于Gibbs采样收敛性定理对现有动量算法进行了理论分析,证明了现有动量算法的加速效果是以牺牲网络权值为代价的;然后,本文进一步对网络权值进行研究,发现网络权值中包含大量真实梯度的方向信息,这些方向信息可以用来对网络进行训练;基于此,本文提出了基于网络权值的权值动量算法,最后给出了仿真实验.实验结果表明,本文提出的动量算法具有更好的加速效果,并且在训练后期仍然能够保持较好的加速性能,可以很好地弥补现有动量算法的不足.Abstract: Momentum algorithms can accelerate the training speed of restricted Boltzmann machine theoretically. Through a simulation study on existing momentum algorithms, it is found that existing momentum algorithms for training restricted Boltzmann machine have a poor accelerating effect and they began to lose acceleration performance. In the latter part of training process. Focusing on this problem, firstly, this paper gives a theoretical analysis of the algorithms based on Gibbs sampling convergence theorem. It is proved that the acceleration effect of existing momentum algorithms is at the expense of enlarging network weights. Then, a further investigation on network weights shows that the network weights contain a lot of information of the true gradient direction which can be used to train the network. According to this, a weight momentum algorithm is proposed based on the weight of the network. Finally, simulation results demonstrate that the proposed algorithm has a better acceleration effect and has the accelerating ability even in the end of the training process. Therefore the proposed algorithm can well make up for the weaknesses of existing momentum algorithms.
-
Key words:
- Deep learning /
- restricted Boltzmann machine (RBM) /
- momentum algorithm /
- weight momentum
-
自2006年Hinton等[1]提出第一个深度网络开始, 经过十年的发展, 深度学习已逐渐成为机器学习研究领域的前沿热点.深度置信网络[2]、深度卷积神经网络[3]、深度自动编码机[4]等深度网络也广泛应用于机器学习的各个领域, 如图像识别[5]、语音分析[6]、文本分析[7]、游戏[8-9]、控制[10]、环境保护[11].相对于传统的机器学习网络, 深度网络取得了更好的效果, 极大地推动了技术发展水平(State-of-the-art)[12].尤其在大数据背景下, 针对海量无标签数据的学习, 深度网络具有明显的优势[13].
受限玻尔兹曼机(Restricted Boltzmann machine, RBM)[14]是深度学习领域中的一个重要模型, 也是构成诸多深度网络的基本单元之一.它具有两层结构, 在无监督学习下, 隐层单元可以对输入层单元进行抽象, 提取输入层数据的抽象特征.当多个RBM或RBM与其他基本单元以堆栈的方式构成深度网络时, RBM隐层单元提取到的抽象特征可以作为其他单元的输入, 继续进行特征提取.通过这种方式, 深度网络可以提取到抽象度非常高的数据特征.当采用逐层贪婪(Greedy layer-wise)[2]方法对深度网络进行训练时, 各个基本单元是逐一被训练的.因此, RBM训练的优劣将直接影响整个深度网络的性能.
2002年, Hinton提出了对比散度(Contrastive divergence, CD)算法[15]用以训练RBM网络, 通过一条Gibbs采样链来近似目标梯度, 取得了良好的训练效果, 是目前RBM训练的标准算法.为克服CD算法采样初值较差的缺点, 2008年, Tieleman以CD算法为基础, 提出了持续对比散度(Persistent contrastive divergence, PCD)算法[16], 它以上次采样迭代的采样值作为下次采样迭代的初值继续迭代, 加快了Gibbs采样链的收敛速度.为了加速PCD算法, Tieleman等又于2009年提出了加速持续对比散度(Fast persistent contrastive divergence, FPCD)算法[17], 引入了额外的加速参数提高采样速度.为提高Gibbs采样链的混合率, Desjardins等(2010) [18]、Cho等(2011) [19]、Brakel等(2011) [20]分别提出应用并行回火算法(Parallel tempering, PT)来训练RBM.PT算法在不同温度下并行化多条Gibbs采样链, 不同温度下的Gibbs采样以一定的交换概率进行交换, 相对于一条Gibbs采样链, PT算法具有更高的采样混合率.针对复杂分布, 尤其是多模分布, PT算法的训练效果要明显优于CD算法[21].
动量算法作为梯度加速项可以与以上算法结合加速RBM网络的训练效果.1964年, Polyak[22]提出了经典动量方法(Classical momentum, CM), 它通过一个速度 $v$ 来积累梯度, 在梯度下降算法中可以加快收敛速度, 该算法在整个机器学习领域已经取得了广泛的成功.2010年, Fischer等[23]发现经典动量算法在RBM网络训练中效果较差, 甚至在一些实验中根本无法起到加速效果.2012年, Hinton在文献[24]中推荐使用动量算法来加速RBM网络的训练速度, 但并没有给出相应的实验结果.2013年, Sutskever等[25]为训练深度网络, 提出了基于Nesterov加速梯度算法的Nesterov动量(Nesterov momentum, NM)算法.该算法在一定程度上克服了经典动量算法的不稳定性和方向误差, 在深度自动编码机和深度递归神经网络等深层网络中取得了良好的效果.2015年, Zarea等[26]将该动量算法应用到受限玻尔兹曼机训练中, 从仿真结果来看, 效果并不是很明显.
基于以上描述, 本文将在后续章节分别对下列问题进行研究:第1节, 现有动量算法在训练RBM网络的过程中存在哪些问题; 第2节, 造成这些问题的原因是什么; 第3节, 如何弥补现有动量算法的这些不足; 最后, 第4节, 仿真实验部分给出了具体的仿真结果和详细分析.
1. 背景知识
本节对本文所需背景知识进行简要介绍, 给出了受限玻尔兹曼机模型及其训练算法、传统动量算法的简要描述.
1.1 受限玻尔兹曼机
受限玻尔兹曼机是一个马尔科夫随机场模型[21], 它具有两层结构, 如图 1所示.下层为输入层, 包含 $m$ 个输入单元 $v_i$ , 用来表示输入数据, 每个输入单元包含一个实值偏置量 $a_i$ ; 上层为隐层, 包含 $n$ 个隐层单元 $h_j$ , 表示受限玻尔兹曼机提取到的输入数据的特征, 每个隐层单元包含一个实值偏置 $b_j$ .受限玻尔兹曼机具有层内无连接, 层间全连接的特点.即同层内各节点之间没有连线, 每个节点与相邻层所有节点全连接, 连线上有实值权重矩阵 $w_{ij}$ .这一性质保证了各层之间的条件独立性.
本文研究二值RBM, 即随机变量 $(V, H)$ 取值 $(v, h)\in \left\{ {0, 1}\right\}$ .由二值受限玻尔兹曼机定义的联合分布满足 $Gibbs$ 分布 $P(v, h)=\frac{1}{Z_\theta}{\rm e}^{-E_\theta (v, h)}$ , 其中 $\theta $ 为网络参数 $\theta =\{a_i, b_j, w_{ij} \}$ , $E_\theta (v, h)$ 为网络的能量函数:
$\label{eq1} E_\theta (v, h)=-\sum\limits_{i=1}^n{\sum\limits_{j=1}^m {w_{ij} v_i h_j } -\sum\limits_{i=1}^m {a_i v_i } -\sum\limits_{j=1}^n {b_j h_j } }$
(1) $Z_\theta $ 为配分函数: $Z_\theta =\sum_{v, h} {{\rm e}^{-E_\theta(v, h)}} $ .输入层节点 $v$ 的概率分布 $P(v)$ 为: $P(v)=\frac{1}{Z_\theta}\sum_h {{\rm e}^{-E_\theta (v, h)}}$ .由受限玻尔兹曼机各层之间的条件独立性可知, 当给定输入层数据时, 输出层节点取值满足如下条件概率:
\begin{align} \label{eq2} P(h_k =1\vert v)=\,&\dfrac{1}{1+\exp (-b_j -\sum\limits_{i=1}^n {w_{ij} v_i } )} =\nonumber\\ & {\rm sigmoid}\left(b_j +\sum\limits_{i=1}^n {w_{ij} v_i } \right) \end{align}
(2) 相应地, 当输出层数据确定后, 输入层节点取值的条件概率为
$\begin{align} &P({{v}_{k}}=1|h)=d\frac{1}{1+\exp (-{{a}_{i}}-\sum\limits_{i=1}^{n}{{{w}_{ij}}{{h}_{j}}})}= \\ & \quad \quad \quad \quad \quad \quad \text{sigmoid}\left( {{a}_{i}}+\sum\limits_{i=1}^{n}{{{w}_{ij}}{{h}_{j}}} \right) \\ \end{align}$
(3) 给定一组训练样本 $S=\{v^1, v^2, \cdots, v^n\}$ , 训练RBM意味着调整参数 $\theta$ , 以拟合给定的训练样本, 使得该参数下由相应RBM表示的概率分布尽可能地与训练数据的经验分布相符合.本文应用最大似然估计的方法对网络参数进行估计, 这样, 训练RBM的目标就是最大化网络的似然函数: $L_{\theta, v} =\prod_{i=1}^n {P(v^i)}$ .为简化计算, 将其改写为对数形式: $\ln L_{\theta, v} =\sum_{i=1}^n{\ln P(v^i)} $ .进一步推导对数似然函数的参数梯度
\begin{align}\label{eq4}&\frac{\partial \ln P(v)}{\partial a_i}=-\sum\limits_h {P(h\vert v)}\frac{\partial E(v, h)}{\partial a_i }+\nonumber\\&\qquad\qquad \sum\limits_{v, h} {P(v, h)} \frac{\partial E(v, h)}{\partial a_i } =\nonumber\\&\qquad \qquad v_i-\sum\limits_v {P(v)v_i }\nonumber\\& \frac{\partial \ln P(v)}{\partial b_j }=-\sum\limits_h {P(h\vert v)}\frac{\partial E(v, h)}{\partial b_j}+\nonumber\\&\qquad\qquad\sum\limits_{v, h} {P(v, h)}\frac{\partial E(v, h)}{\partial b_j } =\nonumber\\&\qquad \qquad P(h_i =1\vert v)-\sum\limits_v {P(v)P(h_{i=1} \vert v)} \nonumber\\& \frac{\partial \ln P(v)}{\partial w_{ij} }=-\sum\limits_h {P(h\vert v)}\frac{\partial E(v, h)}{\partial w_{ij}}+\nonumber\\&\qquad\qquad\sum\limits_{v, h} {P(v, h)}\frac{\partial E(v, h)}{\partial w_{ij} }=\nonumber\\&\qquad\qquad P(h_j =1\vert v)v_i-\nonumber\\&\qquad\qquad\sum\limits_v {P(v)P(h_{j=1} \vert v)v_i}\end{align}
(4) 得到对数似然函数的参数梯度后, 可以由梯度上升法求解其最大值.但由于数据分布 $P(v)$ 未知, 且包含配分函数 $Z_\theta$ , 因此, 无法给出梯度的解析解.现有训练算法主要是基于采样的方法, 首先构造以 $P(v)$ 为平稳分布的马尔科夫链, 获得满足 $P(v)$ 分布的样本, 然后通过蒙特卡洛迭代来近似梯度:
\begin{align}\label{eq5} &\nabla a_i =v_i^{(0) } -v_i^{(k)} \nonumber\\& \nabla b_j =P(h_j =1\vert v^{(0) })-P(h_j =1\vert v^{(k)}) \nonumber\\& \nabla w_{ij} =P(h_j =1\vert v^{(0) })v_i^{(0) } -P(h_j =1\vert v^{(k)})v_i^{(k)}\end{align}
(5) 其中, $v_i^{(0) } $ 为样本值, $v_i^{(k)}$ 为通过采样获得的满足 $P(v)$ 分布的样本.
最后, 参数更新方程如下:
\begin{align}\label{eq6} &a_i =a_i +\eta \nabla a_i \nonumber\\& b_i =b_i +\eta \nabla b_i \nonumber\\& w_{ij} =w_{ij} +\eta \nabla w_{ij}\end{align}
(6) 现有RBM训练算法, 包括对比散度(Contrastive divergence, CD)算法、并行回火(PT)算法, 都是以Gibbs采样为基础的, 都是通过多步Gibbs采样获得一定精度的目标样本, 然后分别通过其他后续操作获得最终的目标梯度.CD算法是RBM训练的主流算法, 下面首先给出CD算法[21]:
算法1. Contrastive divergence
Input. $RBM(V_1, \cdots, V_m, H_1, \cdots, H_n )$ , training batch $S$
Output. $w_{ij}, a_j \;{\rm and}\;b_i \;{\rm for}\;i=1, \cdots, n, \quad j=1, \cdots, m$
1: Init $\nabla w_{ij} =\nabla a_j =\nabla b_i =0\;{\rm for}\;i=1, \cdots, n, j=1, \cdots, m$
2: For all the $v\in S$ do
3: $v^{(0) }\leftarrow v$
4: for $t=0, \cdots, k-1$ do
5: for $i=1, \cdots, n$ do sample $h_i^{(t)} \sim p(h_i \vert v^{(t)})$
6: for $j=1, \cdots, m$ do sample $v_j^{(t+1) } \sim p(v_j \vert h^{(t)})$
7: for $i=1, \cdots, n, j=1, \cdots, m$ do
8: $\nabla w_{ij} =p(H_i =1\vert v^{(0) })\cdot v_j ^{(0) }-p(H_i =1\vert v^{(k)})\cdot v_j^{(k)} $
9: $\nabla a_i =v_i^{(0) } -v_i^{(k)} $
10: $\nabla b_j =p(H_j =1\vert v^{(0) })-p(H_j =0\vert v^{(k)})$
11: $w_{ij} =w_{ij} +\eta \nabla w_{ij} $
12: $a_i =a_i +\eta \nabla a_i $
13: $b_j =b_j +\eta \nabla b_j $
14: End for
其中, $a$ 为可见层偏置向量, $b$ 为隐层偏置向量, $w$ 为网络权值矩阵, $\eta $ 为学习率.
1.2 动量算法
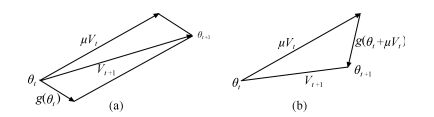
经典动量方法(Classical momentum, CM)[22]如图 2(a)所示, 在梯度下降算法中, 其中 $v$ 为累计速度, $\nabla g(\theta _t)$ 为目标函数在当前点的梯度, 它通过累计速度与当前梯度的差值来调整目标梯度, 从而加快收敛速度.RBM模型是基于梯度上升法进行训练的, 因此经典动量方法在RBM模型下的参数更新公式为式(7), 其中 $\mu$ 为累计速度参数, $\eta $ 为学习率.
$\begin{align} &{{v}_{t+1}}=\mu {{v}_{t}}+\eta \nabla g({{\theta }_{t}}) \\ &{{\theta }_{t+1}}={{\theta }_{t}}+{{v}_{t+1}} \\ \end{align}$
(7) Nesterov动量(Nesterov momentum, NM)[25]如图 2(b)所示.与CM不同的是, NM不是计算目标函数在当前点的梯度, 而是首先由当前时刻的累计速度对目标函数的参数进行调节, 计算 $\theta_t +\mu v_t$ 的梯度, 然后才对目标梯度进行调节, 在RBM模型下的NM参数更新公式如式(8), 其中 $\mu$ 为累计速度参数, $\eta $ 为学习率.
$\begin{align} &{{v}_{t+1}}=\mu {{v}_{t}}+\eta \nabla g({{\theta }_{t}}+\mu {{v}_{t}}) \\ &{{\theta }_{t+1}}={{\theta }_{t}}+{{v}_{t+1}} \\ \end{align}$
(8) 2. 问题描述
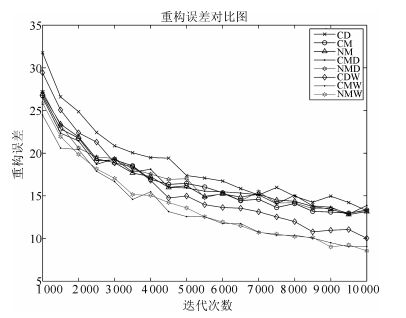
由第5.1节中给出的网络模型和训练策略, 得到CD算法和传统动量算法在MNIST数据集上的训练效果对比图.
其中CD表示原始CD算法, CM表示加入经典动量项的CD算法, NM表示加入Nesterov动量项的CD算法.
图 3和图 4给出了三种算法的仿真对比图, 由仿真结果可以看出, CM算法和NM算法可以加快RBM训练过程的收敛速度, 但仍存在以下问题:
1) 加速效果不明显.如图 3所示, CM算法和NM算法的收敛曲线与CD算法的收敛曲线间隔较小, 考虑每次迭代额外增加的计算量的前提下, 这两种动量方法并没有达到预想的效果.
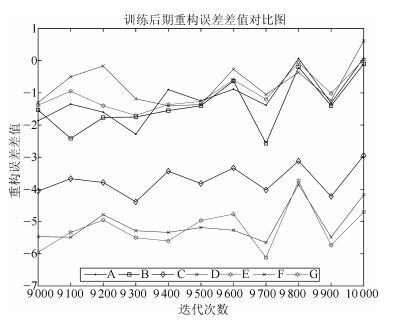
2) 训练后期加速失效.随着迭代的进行, CM算法和NM算法的误差曲线逐渐与CD算法重合.如图 4所示, CM算法与NM算法与CD算法的重构误差的差值逐渐收敛到0, 这说明在训练后期, CM算法和NM算法逐渐失去了加速效果.
3. 问题分析
RBM网络的训练算法都是基于Gibbs采样的, Gibbs采样链的收敛性质, 即采样混合率, 是影响训练算法性能的本质因素.因此, 本节首先基于Gibbs采样收敛性理论对以上算法和问题进行分析.
3.1 基于Gibbs采样收敛性的理论分析
3.1.1 Gibbs采样链收敛性定理
由于在RBM网络中, 可见层偏置向量 $a$ 和隐层偏置向量 $b$ 都是极小值, 相对于网络权值 $w$ 可以忽略不计.因此, 本文在研究网络参数的时候, 只对网络权值 $w$ 进行研究.下面首先给出Gibbs采样收敛性定理:
定理1. RBM网络下, Gibbs采样链的混合率随网络权值量级的增大而逐渐降低[15, 21, 27-28].
证明. RBM网络基于式(2) 和(3) 进行Gibbs迭代, 以此完成参数更新.当网络权值 $w$ 的量级逐渐增大时, 即 $\vert w\vert \to +\infty $ , 可推理出如下结果:
\begin{align} \label{eq9} \left\{ {\begin{array}{l} -b_j -\sum\limits_{i=1}^n {w_{ij} v_i } \to +\infty ~\mbox{或}~{-}\infty \\ -a_i -\sum\limits_{i=1}^n {w_{ij} h_j } \to +\infty~ \mbox{或}~{-}\infty \\ \end{array}} \right. \end{align}
(9) 则对应的隐层节点的取值概率 $P(h_k =1\vert v)$ 和可见层节点的取值概率 $P(v_k =1\vert h)$ 分别为
\begin{align} \label{eq10} \left\{ {\begin{array}{l} P(h_k =1\vert v)\to 0 ~\mbox{或} ~1 \\ P(v_k =1\vert h)\to 0~ \mbox{或} ~1 \\ \end{array}} \right. \end{align}
(10) 当网络权值逐渐增大时, Gibbs采样链的采样概率逐渐趋于0或1.即, 每次采样时, 各点的取值均为0或1, 此时, 采样链的转移算子不再具备随机性(Less randomness[27]).
由文献[27]可知:Gibbs采样链的混合率随着其转移算子随机性的降低而逐渐降低.因此, 当Gibbs采样链的采样概率逐渐趋于0或1时, 采样链的转移算子的随机性逐渐降低, 导致了采样链混合率的逐渐下降.从而证明了当网络权值逐渐增大时, Gibbs采样链的混合率逐渐下降.
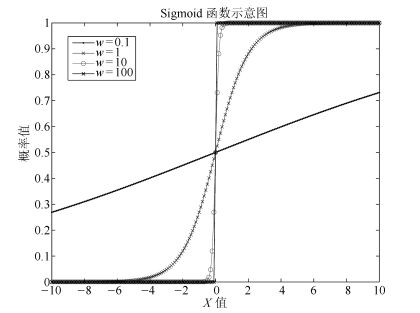
为验证上述推论的合理性, 我们给出了Sigmoid函数在不同权值下的曲线, 如图 5所示.
当网络权值量级逐渐增大时, Sigmoid函数曲线变得越来越陡峭.这时如果对状态进行采样, 大部分采样区域将为0或1, 发生变化的区域, 即可调域(图中曲线部分), 非常小, 由此导致采样前后的状态变化量非常小, 即转移算子的随机性非常小, 从而导致采样混合率降低.当采样前后状态变化量不变时, 转移算子没有随机性, 采样率为0, 此时, 网络将停止优化.
所以, 在RBM网络下, 随着网络权值量级的逐渐增大, Gibbs采样链的混合率逐渐降低.
3.1.2 对第2节中的问题进行分析
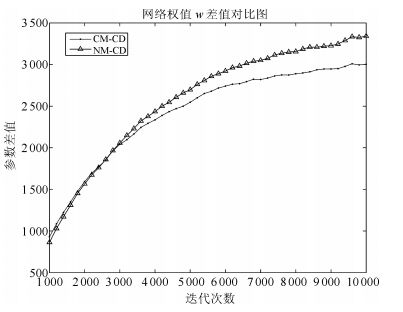
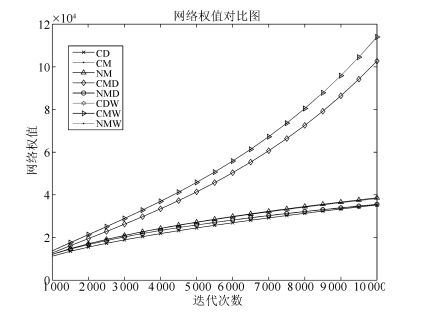
由第1.2节给出的动量公式可以看出, CM算法和NM算法通过速度项对梯度进行累积, 然后对参数梯度进行修正, 即, 除去参数本身的梯度外, CM算法和NM算法还额外引入了一个梯度更新量, 这将加快网络权值的增加速度, 图 6给出了CD算法和CM、NM算法的权值增长曲线对比图.
由图 6可以看出, CM算法和NM算法的权值增长速度明显快于CD算法, 图 7给出的权值差值对比图也说明了这一点.这说明, CM算法和NM算法的加速效果是以增加权值量级为代价的.在迭代训练初期, 由于三者的网络权值都较小, 这时, 虽然CM算法和NM算法的混合率略小于CD算法的混合率, 但由于累计速度 $v$ 的存在, 使得CM算法和NM算法的综合梯度要大于CD算法, 如图 8所示, 从而在前期, CM算法和NM能够起到加速效果.但由于它们之间的梯度差值差别不是很大, 所以加速效果并不是很明显, 即第2节问题1) 中描述的现象.
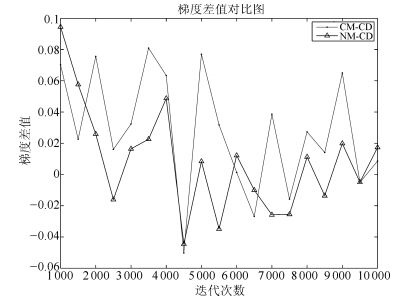
但到了训练后期, CM算法和NM算法训练下的权值明显大于CD算法训练下的权值, 这使得CM算法和NM算法下的采样链混合率急剧下降, 远小于CD算法下的采样链混合率, 这时, 即便存在累计速度 $v$ , 也不能弥补混合率下降带来的梯度劣势, 从而, 使得最终CM算法和NM算法的梯度值接近, 如下图 9中所示, CM算法与NM算法与CD算法的梯度差值在训练后期逐渐降为0, 甚至小于0, 所以到了训练后期, CM算法与NM算法逐渐失去了加速效果, 这就是第2节中问题2) 的原因.
3.2 通过权值衰减项控制网络权值
3.2.1 仿真实验
由于网络权值的量级是影响Gibbs采样链的关键因素, 所以一个很自然的想法是通过控制网络权值的量级来保证采样链的混合率.因此, 本节在原有动量算法的基础上引入了权值衰减项(Weight decay), 研究总体训练效果.首先分别给出CM算法和NM算法与权值衰减项结合后总的梯度更新公式:
\begin{align} \label{eq11} \left\{ {\begin{array}{l} {\rm CMD}\theta _{t+1} =\theta _t +{\rm CM}grad_t -\lambda \theta _t \\ {\rm NMD}\theta _{t+1} =w_t +{\rm NM}grad_t -\lambda \theta _t \\ \end{array}} \right. \end{align}
(11) 其中, $λ$ 为权值衰减项参数, 设为0.00001.以CMD表示CM算法与权值衰减项结合后的算法, CMD $\theta $ 表示CMD算法下的参数值, CM $grad$ 为由CM算法计算得到的更新梯度; 以NMD表示NM算法与权值衰减项结合后的算法, NMD $\theta$ 表示NMD算法下的参数值, NM $grad$ 为由NM算法计算得到的更新梯度.以第5.1节中给出的实验设计为例, 进行仿真实验, 仿真结果如下.
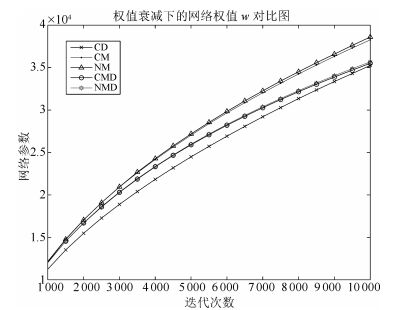
图 10给出了权值衰减下的网络权值对比图, 图 11给出了各动量算法与原始CD算法的网络权值差值对比图.通过以上两图可以看出, 权值衰减项可以有效地控制网络权值的变化, 使其不至于过大, 根据第3.1节给出的定理, 权值衰减项的引入可以一定程度上保证Gibbs采样链的混合率.
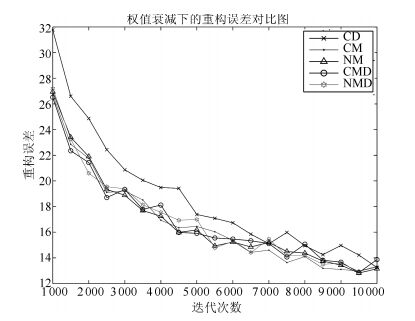
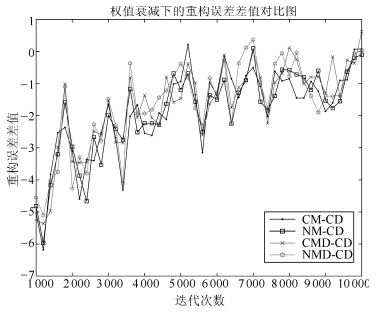
图 12给出了各算法的重构误差对比图, 从图 12中可以看出, CMD算法和NMD算法的训练曲线与CM算法和NM算法的训练曲线几乎重合, 即权值衰减项的引入并没有提高CM算法和NM算法的加速效果; 图 13给出的重构误差差值对比图中, 各差值曲线也几乎重合, 都是逐渐收敛到0, 这说明了在训练后期, CMD算法和NMD算法也会失去加速效果.加入权值衰减项后的动量算法并没有改善原始动量算法的性能, 仍然出现了第2节中描述的问题.
3.2.2 问题解释
由式(11), 可以得到引入权值衰减项后的权值梯度公式:
$\nabla W=\mu {{v}_{t}}+\eta \nabla w-\lambda W$
(12) 其中, $\nabla w$ 为Gibbs采样计算的梯度, $\nabla W$ 为总的梯度.
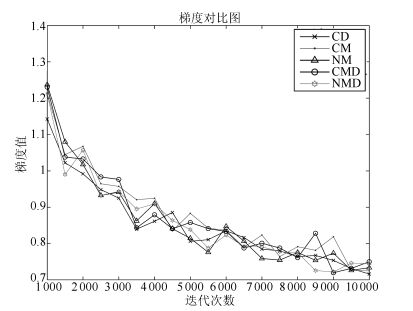
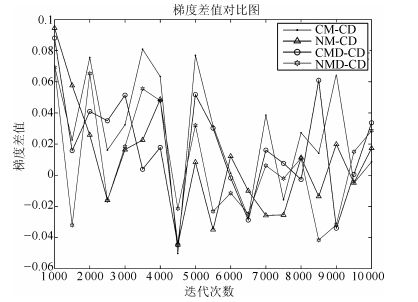
权值衰减项的引入虽然可以控制权值的量级, 保证采样链的混合率, 即提高了 $\nabla w$ 的值, 但由式(12) 可以看出, 权值衰减项的方向与动量的方向相反, 也就是说, 权值衰减项对动量具有一定的抵消作用.由提高混合率带来的加速效果和由方向相反引起的抵消作用相互牵制, 最终导致总的梯度 $\nabla W$ 与仅由动量算法计算的梯度大致相等, 如图 14和15所示, 从而出现了第2节中描述的问题.
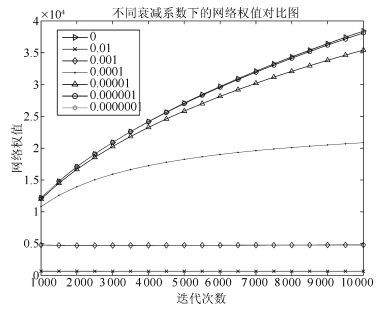
3.2.3 衰减系数对仿真结果的影响
为研究不同衰减系数对训练效果的影响, 本节我们以CMD算法为例, 设计了7组对比实验, 在每组实验中, 衰减系数 $λ$ 分别取不同的值, 仿真结果和相应的 $λ$ 的取值如图 16和17所示.其中当 $λ=0$ 时, 表示没有权值衰减项, 即经典动量算法CM.
图 16给出了不同衰减系数下的重构误差对比图; 图 17给出了不同衰减系数下的网络权值对比图.从图 17中可以看出, 当衰减系数 $λ$ 取较大值时( $λ>0.0001$ ), 衰减项对网络权值的控制较强, 此时网络权值较小, 但相应的重构误差较大, 这说明, 当 $λ$ 取值较大时, 会降低网络的训练效果, 甚至导致网络无法训练; 当 $λ$ 取值较小时( $λ<0.0001$ ), 衰减项对网络权值的控制较弱, 此时网络权值略小于无权值衰减下的网络权值, 对应的重构误差与无权值衰减下的重构误差差别不大; 随着 $λ $ 的继续减小( $λ<0.00001$ ), 权值衰减项逐渐失去了控制作用, 此时网络权值与无权值衰减项下的网络权值几乎相等, 相应的重构误差与无权值衰减项下的网络重构误差几乎相等.从图 17中可以看出, $λ $ 取0.00001(即本文的取值)是较为合适的.
由以上理论分析可知, 现有动量算法以提高权值量级为代价加快训练过程的收敛, 同时这也导致了后期加速性能的失效.通过引入权值衰减项来控制网络权值并不能解决这个问题.
4. 权值动量算法
4.1 网络权值信息
本文以网络权值作为动量项的想法来自于以下基本判断:
迭代训练一段时期后, 网络参数的方向与真实参数方向大致相同, 这时, 如果沿着该方向加大网络参数, 可以一定程度上提高网络训练效果.
下面给出分析证明.
4.1.1 理论分析
定理2. CD算法的估计梯度的方向在大部分时间内与真实梯度的方向是相同的[27].
文献[27]中通过大量的实验分析表明, 在大部分时间内, CD算法的近似梯度与真实梯度的方向是相同的.所以, 我们有理由相信, 经过一段时间的训练调节之后, 网络权值的方向与期望权值的方向大致相同.
4.1.2 实验证明
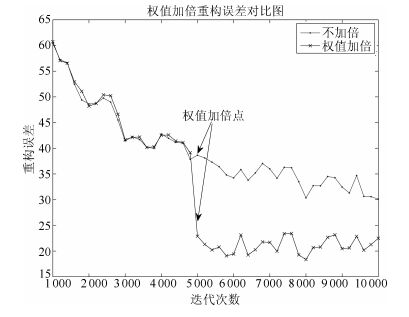
本次试验的网络结构和参数初值与第5.1节中给出的设计一致.本节采用的训练策略是在迭代进行到500次时, 对网络权值进行加倍, 即 $w=w×10$ .实验结果如图 18.
从以上对比结果可以看出, 在迭代次数为500处对网络权值进行加倍可以大幅度地提升训练效果.但加倍后的重构误差值几乎不再变化, 而不加倍的重构误差值则逐渐减小.我们做了大量的仿真实验, 分别在不同的迭代点, 对网络权值 $w$ 分别乘以不同的倍数, 都会出现以上结果:权值加倍后会提高网络训练效果, 但后续训练速度极其缓慢.
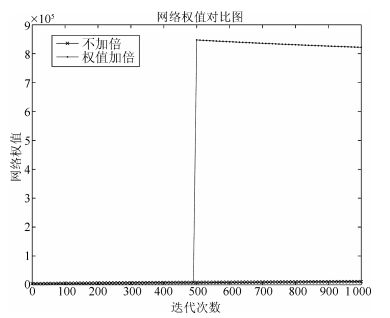
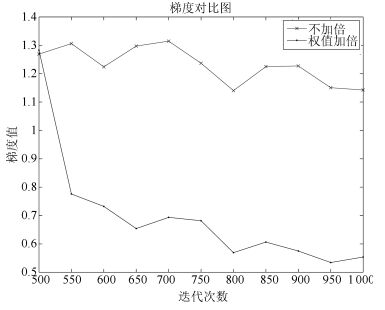
出现以上现象的原因是:当对网络参数进行加倍后, 网络权值急剧增大, 如图 19所示, 根据第3.1节给出的Gibbs采样收敛性定理, 此时, Gibbs采样链的混合率急剧下降, 从而使得网络参数的梯度值急剧下降, 如图 20所示, 最终导致网络训练曲线不再变化.
以上分析表明, 网络权值在网络训练中保留了重要的真实梯度的方向信息.当网络权值增大到采样梯度很小甚至接近于0的时候, 我们可以用权值中保存的梯度方向信息来继续训练网络, 基于此, 本文设计了基于权值动量的RBM加速训练算法.
4.2 权值动量算法
本文设计的动量项为网络权值 $w$ , 该权值动量项可以与原始CD算法结合, 也可以与现有动量算法CM算法和NM算法结合, 在混合率降低时, 提供梯度方向信息, 加速网络训练.下面分别给出权值动量项与上述三种算法结合后的参数更新公式.
权值动量与CD结合后的算法称为CDW, 相应的参数更新公式为
\begin{align} \label{eq13} \left\{ {\begin{array}{l} w_{ij} =w_{ij} +\eta \nabla w_{ij} +\alpha w_{ij} \\ a_i =a_i +\eta \nabla a_i \\ b_j =b_j +\eta \nabla b_j \\ \end{array}} \right. \end{align}
(13) 其中, $\eta $ 为学习率, $\alpha $ 为权值动量系数.
权值动量与CM算法结合后的算法称为CMW, 相应的参数更新公式为
\begin{align} \label{eq14} \left\{ {\begin{array}{l} w_{ij} =w_{ij} +\mu v_{ij}^{cm} +\eta \nabla w_{ij} +\alpha w_{ij} \\ a_i =a_i +\mu v_i^{cm} +\eta \nabla a_i \\ b_j =b_j +\mu v_j^{cm} +\eta \nabla b_j \\ \end{array}} \right. \end{align}
(14) 其中, $v^{cm}$ 为CM算法下的速度, $\mu $ 为速度参数.
权值动量与NM算法结合后的算法称为NMW, 相应的参数更新公式为
\begin{align} \label{eq15} \left\{ {\begin{array}{l} w_{ij} =w_{ij} +\mu v_{ij}^{nm} +\eta \nabla w_{ij} +\alpha w_{ij} \\ a_i =a_i +\mu v_i^{nm} +\eta \nabla a_i \\ b_j =b_j +\mu v_j^{nm} +\eta \nabla b_j \\ \end{array}} \right. \end{align}
(15) 其中, $v^{nm}$ 表示NM算法下的速度, $\mu $ 为速度参数.
5. 仿真实验
为证明算法的有效性和普适性, 本文选取了5个常用的Benchmark标准数据集.分别为MNIST[29]数据集、MNORB数据集、CIFAR-10[30]数据集、CIFAR-100[30]数据集和OLIVETTI_FACE[31]数据集.并在这5个Benchmark标准数据集上进行了测试.
MNIST手写数据集共包含60000个训练样本, 对应 $0 \sim 9$ 十个数字, 每个样本是一幅 $28× 28$ 像素的灰度图.CIFAR-10数据集是Tiny image[32]数据集的一部分, 共包含60000幅 $32×32×3$ 彩色图片.图片分为10类, 每个类由5000幅训练图片和1000幅测试图片组成.CIFAR-100数据集与CIFAR-10数据集类似, 它包含100个类, 每个类对应600幅图片, 其中500幅用于训练, 100幅用于测试.整个数据集共包含60000幅图片.MNORB数据集是NORB[33]数据集的二值化子集, 总共包含19440个数据, 每个数据对应一幅 $32×32$ 的灰度图.OLIVETTI_FACE数据集是贝尔实验室收集的人脸数据库, 用于人脸识别任务.它总共包含400幅图片, 每幅图片为 $64×64$ 的灰度图.
在每个数据集下, 本文分别设计了7组对比实验, 分别将上文给出的7种训练算法进行对比.为避免重复叙述, 本文只在MNIST数据集下给出了详细的仿真实验, 并结合仿真结果, 对本文提出的算法进行了详细地分析, 在其他4个数据集只给出网络结构和参数设定, 以及相应的仿真结果和简要分析.
5.1 MNIST数据集
MNIST数据集内的数据为 $28× 28$ 的灰度图片, 因此, 本文设计的RBM网络模型为 $784×500$ , 输入层有784个节点, 对应灰度图的784个像素点, 隐层有500个节点, 用来提取输入层数据的特征.训练迭代次数为10000次.具体的网络结构如表 1所示.
表 1 网络参数值Table 1 The value of network parameters网络参数 初始值 $a$ zeros $(1, 784) $ $b$ zeros $(1, 500) $ $w$ $0.1\times randn(784,500)$ $\eta $ $0.1$ $\mu $ $0.9 $ 具体的网络参数初始值设定如表 2所示.
表 2 训练参数Table 2 Training parameters算法参数 $\mu $ $\lambda$ $\alpha $ CD 0.9 CM 0.9 NM 0.9 CMD 0.9 0.00001 NMD 0.9 0.00001 CDW 0.9 0.0001 CMW 0.9 0.0001 NMW 0.9 0.0001 5.1.1 训练精度对比分析
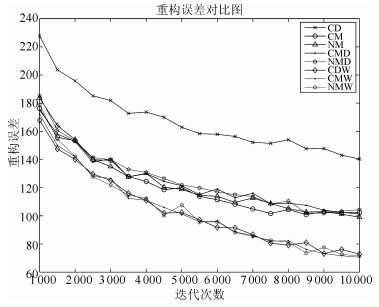
图 21给出了所有算法的训练误差对比图, 其中CDW算法、CMW算法和NMW算法的训练曲线与CD算法的间距较大, 远大于CM算法、NM算法、CMD算法和NMD算法.仿真结果说明本文提出的权值动量算法相对于现有动量算法, 具有更好的加速效果, 且加速效果明显.从而克服了第2节问题1) 中描述的现有动量算法出现的问题.
图 22给出了迭代后期各动量算法与CD算法重构误差的差值对比图, 为画图方便, 作如下记号, 如表 3所示.
表 3 记号示意图Table 3 Sign diagram代号 差值项 A CM-CD B NM-CD C CMW-CD D NMW-CD E CDW-CD F CMW-CD G NMW-CD 由图 22所示, 在迭代末期, CDW算法、CMW算法和NMW算法与CD算法的重构误差差值仍然较大, 而其他算法与CD算法的重构误差差值逐渐增大到0, 甚至大于0.这说明, 其他算法在后期逐渐失去了加速效果, 甚至会产生副作用, 而本文提出的权值动量算法在迭代后期仍然具有良好的加速效果.从而克服了第3节问题2) 中描述的现有动量算法出现的问题.
5.1.2 梯度对比分析
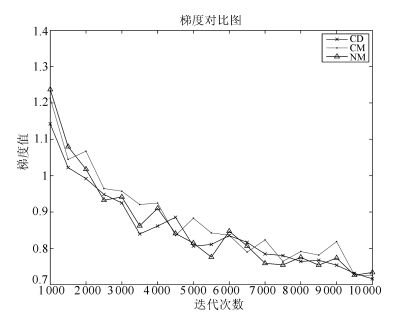
图 23给出了迭代初期各动量算法与CD算法之间的梯度差值对比图.从图 23中可以看出, 在迭代初期, 各动量算法的梯度值基本上都大于CD算法的梯度值, 从而保证了加速效果.
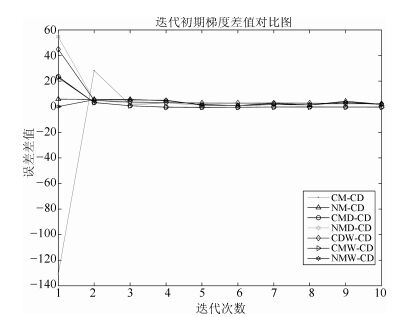 图 23 迭代初期梯度差值对比图Fig. 23 Compassion of the difference of the gradients in initial stages of iteration
图 23 迭代初期梯度差值对比图Fig. 23 Compassion of the difference of the gradients in initial stages of iteration图 24给出了迭代中期各动量算法与CD算法之间的梯度差值, 图 24给出了迭代中期各算法的重构误差对比图, 对比分析这两个图, 可以发现以下两个问题:
 图 24 迭代中期梯度差值对比图Fig. 24 Compassion of the difference of the gradients in mid-term of iteration
图 24 迭代中期梯度差值对比图Fig. 24 Compassion of the difference of the gradients in mid-term of iteration问题1. 图 24中显示, 在迭代中期, CDW算法的梯度远大于其他算法梯度.理论上, 这一时期CDW算法的加速效果要优于其他算法.但图 25给出的迭代中期重构误差图中, CDW算法的重估误差虽然比CD算法的重估误差小, 但却大于其他动量算法, 与图 24中的现象相反.
问题2. 图 23中, CMW算法和NMW算法在中期的梯度值并不突出, 但图 24中显示, 此时这两种算法仍然具有最优的训练效果, 且训练效果要明显好于其他算法.
下面对以上两个问题作出解答:
解答1. 在迭代中期, 由于网络参数的初值为任意选取, 导致在迭代中期, 网络权值 $w$ 的方向并没有完全调节好, 造成其中包含的方向信息不准确, 即一部分分量的方向为真实权值的方向, 另一部分分量的方向并不是真实权值方向.而CDW算法仅仅是以网络权值作为动量项进行加速, 所以此时CDW算法的梯度虽然大, 但只有部分分量的方向是正确的, 而另一部分分量的方向是错误的.方向正确的分量会加速训练效果, 方向错误的分量会削弱训练效果, 这两种效果相互补偿, 从而出现上述问题1) 中的现象.
解答2. 另外两种算法, NMW算法和CMW算法, 因为有累计梯度 $v$ , 包含了正确的梯度信息, 所以, 当权值分量方向正确时, 会进一步加强加速效果, 当权值分量方向错误时, 会补偿一部分削弱效果.所以, 尽管这一时期CMW算法和NMW算法的梯度值没有明显优势, 仍然具有最优的训练效果.
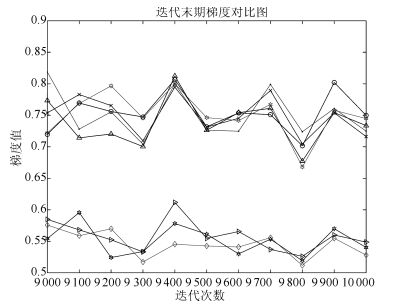
在整个训练过程中, 网络逐渐进入一个较优的局部极大域.这时, 较小的梯度值更有利于网络的微调, 从而使网络更加靠近局部极大点.图 26显示, 在网络靠近局部极大点的过程中, CDW算法、CMW算法和NMW算法的梯度值显著下降, 下降速度要远大于其他算法.在迭代末期, 如图 27所示, CDW算法、CMW算法和NMW算法的梯度值要远小于其他算法, 这说明, 当网络逐渐进入一个较优的局部极大域后, CDW算法、CMW算法和NMW算法相对于其他算法, 具有更好的局部微调能力, 使得网络可以继续收敛.而其他算法由于后期梯度值较大, 网络参数每次更新步长始终较大, 导致网络在局部极大域内发生振荡, 从而很难收敛.
5.1.3 网络权值对比分析
图 28给出了各动量算法的网络权值对比图, 图 29给出了各动量算法与CD算法的动量差值对比图.从以上两图可以看出, 本文提出权值动量算法是以增大网络权值为代价的.按照第4.1节给出的Gibbs采样链收敛性定理, 当权值增大后, Gibbs采样链的混合率将显著下降, 甚至降为0, 此时网络将无法训练.但本文提出的权值动量算法在网络权值急剧增大的情况下仍然能有效地训练网络, 这是因为, 在训练后期, 网络权值增加, 虽然Gibbs采样的混合率显著降低, 但此时, 由于网络已经训练较好, 可以认为已经达到了较好的局部极大域, 此时, 网络权值 $w$ 的方向已经于真实方向几乎相同, 再加上累积的梯度 $v$ 的参与, 完全可以以这两项对网络进行调节, 所以, 训练后期, 虽然网络权值较大, 但网络仍然能够继续训练.
5.1.4 采样效果对比
图 30为最后一幅训练图片的原始图, 图 31~36分别为各训练算法对应的重构图.从以上结果可以看出, 通过权值动量算法训练后的网络重构图, 噪点较少, 重构精度更高, 说明权值动量算法具有更好的加速训练效果.
5.2 MNOB数据集
MNORB数据集内的数据为 $32×32$ 的灰度图, 如图 37所示.本文设计的RBM网络模型为 $1024×800$ , 输入层有1024个节点, 对应灰度图的1024个像素点, 隐层有800个节点, 用来提取输入层数据的特征.训练迭代次数为10000次.网络结构和初始参数如表 4所示.仿真结果如图 38所示.
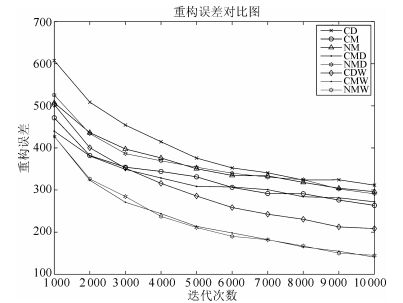
表 4 网络参数值Table 4 The value of network parameters网络参数 初始值 $a$ zeros $(1, 1024) $ $b$ zeros $(1, 800) $ $w$ $0.1\times randn(1024,800)$ $\eta $ $0.01$ $\mu $ $0.9$ 图 38给出了MNOB数据集下各算法重构误差对比图.从图 38中可以看出, CDW算法、CMW算法和NMW算法的训练曲线与CD算法的间距较大, 远大于CM算法、NM算法、CMD算法和NMD算法.仿真结果说明本文提出的权值动量算法相对于现有动量算法, 具有更好的加速效果, 且加速效果明显.
5.3 CIFAR10数据集
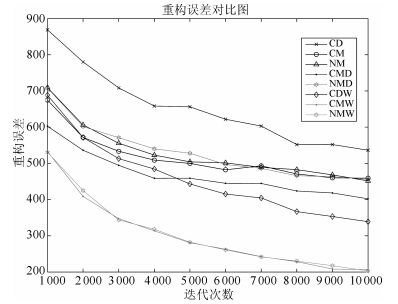
CIFAR-10数据集内的数据为 $32× 32×3$ 的彩色图, 如图 39所示.本文设计的RBM网络模型为 $3072×2000$ , 输入层有3072个节点, 对彩色图的3072个像素点, 隐层有2000个节点, 用来提取输入层数据的特征.训练迭代次数为10000次.网络结构和初始参数设定如表 5所示.仿真结果如图 40所示.
表 5 网络参数值Table 5 The value of network parameters网络参数 初始值 $a$ zeros $(1, 3072) $ $b$ zeros $(1, 2000) $ $w$ $0.1\times randn(3072,2000)$ $\eta $ $0.01$ $\mu $ $0.9$ 图 40给出了CIFAR10数据集下各算法重构误差对比图.从图 40中可以看出, CDW算法、CMW算法和NMW算法的训练曲线与CD算法的间距较大, 远大于CM算法、NM算法、CMD算法和NMD算法.仿真结果说明本文提出的权值动量算法相对于现有动量算法, 具有更好的加速效果, 且加速效果明显.
5.4 CIFAR100数据集
CIFAR-100数据集内的数据为 $32× 32× 3$ 的彩色图, 如图 41所示.本文设计的RBM网络模型为 $3072×2000$ , 输入层有3072个节点, 对彩色图的3072个像素点, 隐层有2000个节点, 用来提取输入层数据的特征.训练迭代次数为10000次.网络结构和初始参数设定如表 6所示.仿真结果如图 42所示.
表 6 网络参数值Table 6 The value of network parameters网络参数 初始值 $a$ zeros $(1, 3072) $ $b$ zeros $(1, 2000) $ $w$ $0.1\times randn(3072,2000)$ $\eta $ $0.01$ $\mu $ $0.9 $ 图 42给出了CIFAR100数据集下各算法重构误差对比图.从图 42中可以看出, CDW算法、CMW算法和NMW算法的训练曲线与CD算法的间距较大, 远大于CM算法、NM算法、CMD算法和NMD算法.在该数据集下, CMW算法和NMW算法加速效果明显, 具有最好的加速效果.仿真结果说明本文提出的权值动量算法相对于现有动量算法, 具有更好的加速效果, 且加速效果明显.
5.5 OLIVETTI_FACE数据集
OLIVETTI_FACE数据集内的数据为 $64×64$ 的灰度图, 如图 43所示.本文设计的RBM网络模型为 $4096×3000$ , 输入层有4096个节点, 对灰度图的4096个像素点, 隐层有3000个节点, 用来提取输入层数据的特征.训练迭代次数为10000次.网络结构和初始参数设置如表 7所示.仿真结果如图 44所示.
表 7 网络参数值Table 7 The value of network parameters网络参数 初始值 $a$ zeros $(1, 4096) $ $b$ zeros $(1, 3000) $ $w$ $0.1\times randn(4096,3000)$ $\eta $ $0.01$ $\mu $ $0.9 $ 图 44给出了CIFAR10数据集下各算法重构误差对比图.从图中可以看出, CDW算法、CMW算法和NMW算法的训练明显好于CM算法、NM算法、CMD算法和NMD算法.仿真结果说明本文提出的权值动量算法相对于现有动量算法, 具有更好的加速效果, 且加速效果明显.
6. 总结
本文针对现有动量算法在受限玻尔兹曼机网络训练中加速效果较差、训练后期加速性能显著降低的问题, 首先, 基于Gibbs采样收敛性定理对现有动量算法进行了理论分析, 证明了现有动量算法的加速效果是以增大网络权值为代价的, 随着网络权值逐渐增大, Gibbs采样链的收敛性逐渐变差, 这也最终导致了现有动量算法在训练后期逐渐失去加速能力; 然后, 本文通过引入权值衰减项来对网络权值进行控制, 并进行了仿真实验, 实验结果表明, 权值衰减项并不能解决现有动量算法存在的问题, 而且权值衰减项的系数非常难以调节.系数较大时, 算法不能有效地训练网络; 系数较小时, 不能起到很好的权值控制作用.于是, 本文接着对网络权值进行研究, 发现网络权值中包含大量真实梯度的方向信息, 这些梯度方向信息可以与现有动量算法结合来加速网络训练, 尤其在训练后期, 当Gibbs采样链几乎无法收敛时, 仍然可以用网络权值中保存的梯度方向信息继续对网络进行训练.基于此, 本文提出了基于网络权值的权值动量算法, 最后分别在MNIST数据集、MNOB数据集、CIFAR10数据集、CIFAR100数据集和FACE数据集上给出了仿真实验.实验结果表明, 相对于传统动量算法, 本文提出的权值动量算法在以上5个数据集上均具有更好的加速效果, 并且在训练后期仍然能够保持较好的加速性能.同时, 5个数据集上的仿真结果表明, 本文提出的动量算法具有一定的普适性.
本文提出的权值动量算法虽然可以很好地弥补现有动量算法的不足, 但仍然是以增大网络权值为代价的.网络权值过大可能会导致网络的泛化性能降低, 如何在保证加速性能的同时保持网络的泛化性能, 仍有待于进一步研究.
-
图 23 迭代初期梯度差值对比图
Fig. 23 Compassion of the difference of the gradients in initial stages of iteration
图 24 迭代中期梯度差值对比图
Fig. 24 Compassion of the difference of the gradients in mid-term of iteration
表 1 网络参数值
Table 1 The value of network parameters
网络参数 初始值 $a$ zeros $(1, 784) $ $b$ zeros $(1, 500) $ $w$ $0.1\times randn(784,500)$ $\eta $ $0.1$ $\mu $ $0.9 $  下载: 导出CSV
下载: 导出CSV
表 2 训练参数
Table 2 Training parameters
算法参数 $\mu $ $\lambda$ $\alpha $ CD 0.9 CM 0.9 NM 0.9 CMD 0.9 0.00001 NMD 0.9 0.00001 CDW 0.9 0.0001 CMW 0.9 0.0001 NMW 0.9 0.0001
下载: 导出CSV
表 3 记号示意图
Table 3 Sign diagram
代号 差值项 A CM-CD B NM-CD C CMW-CD D NMW-CD E CDW-CD F CMW-CD G NMW-CD
下载: 导出CSV
表 4 网络参数值
Table 4 The value of network parameters
网络参数 初始值 $a$ zeros $(1, 1024) $ $b$ zeros $(1, 800) $ $w$ $0.1\times randn(1024,800)$ $\eta $ $0.01$ $\mu $ $0.9$
下载: 导出CSV
表 5 网络参数值
Table 5 The value of network parameters
网络参数 初始值 $a$ zeros $(1, 3072) $ $b$ zeros $(1, 2000) $ $w$ $0.1\times randn(3072,2000)$ $\eta $ $0.01$ $\mu $ $0.9$
下载: 导出CSV
表 6 网络参数值
Table 6 The value of network parameters
网络参数 初始值 $a$ zeros $(1, 3072) $ $b$ zeros $(1, 2000) $ $w$ $0.1\times randn(3072,2000)$ $\eta $ $0.01$ $\mu $ $0.9 $
下载: 导出CSV
表 7 网络参数值
Table 7 The value of network parameters
网络参数 初始值 $a$ zeros $(1, 4096) $ $b$ zeros $(1, 3000) $ $w$ $0.1\times randn(4096,3000)$ $\eta $ $0.01$ $\mu $ $0.9 $
下载: 导出CSV
-
[1] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786):504-507 doi: 10.1126/science.1127647 [2] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527-1554 doi: 10.1162/neco.2006.18.7.1527 [3] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In:Proceedings of Advances in Neural Information Processing Systems 25. Cambridge, MA:MIT Press, 2012. [4] Bengio Y. Learning deep architectures for AI. Foundations and Trends in Machine Learning, 2009, 21(6):1-27 http://www.iro.umontreal.ca/~pift6266/A08/documents/ftml.pdf [5] Deng L, Abdel-Hamid O, Yu D. A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion. In:Proceedings of the 2013 International Conference on Acoustics Speech and Signal Processing (ICASSP). Vancouver, BC, Canada:IEEE, 2013. 6669-6673 [6] Deng L. Design and learning of output representations for speech recognition. In:Neural Information Processing Systems (NIPS) Workshop on Learning Output Representations. Lake Tahoe, USA:NIPS, 2013. [7] Tan C C, Eswaran C. Reconstruction and recognition of face and digit images using autoencoders. Neural Computing and Applications, 2010, 19(7):1069-1079 doi: 10.1007/s00521-010-0378-4 [8] 郭潇逍, 李程, 梅俏竹.深度学习在游戏中的应用.自动化学报, 2016, 42(5):676-684 http://www.aas.net.cn/CN/abstract/abstract18857.shtmlGuo Xiao-Xiao, Li Cheng, Mei Qiao-Zhu. Deep learning applied to games. Acta Automatica Sinica, 2016, 42(5):676-684 http://www.aas.net.cn/CN/abstract/abstract18857.shtml [9] 田渊栋.阿法狗围棋系统的简要分析.自动化学报, 2016, 42(5):671-675 http://www.aas.net.cn/CN/abstract/abstract18856.shtmlTian Yuan-Dong. A simple analysis of AlphaGo. Acta Automatica Sinica, 2016, 42(5):671-675 http://www.aas.net.cn/CN/abstract/abstract18856.shtml [10] 段艳杰, 吕宜生, 张杰, 赵学亮, 王飞跃.深度学习在控制领域的研究现状与展望.自动化学报, 2016, 42(5):643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtmlDuan Yan-Jie, Lv Yi-Sheng, Zhang Jie, Zhao Xue-Liang, Wang Fei-Yue. Deep learning for control:the state of the art and prospects. Acta Automatica Sinica, 2016, 42(5):643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtml [11] 耿杰, 范剑超, 初佳兰, 王洪玉.基于深度协同稀疏编码网络的海洋浮筏SAR图像目标识别.自动化学报, 2016, 42(4):593-604 http://www.aas.net.cn/CN/abstract/abstract18846.shtmlGeng Jie, Fan Jian-Chao, Chu Jia-Lan, Wang Hong-Yu. Research on marine floating raft aquaculture SAR image target recognition based on deep collaborative sparse coding network. Acta Automatica Sinica, 2016, 42(4):593-604 http://www.aas.net.cn/CN/abstract/abstract18846.shtml [12] Deng L, Hinton G, Kingsbury B. New types of deep neural network learning for speech recognition and related applications:an overview. In:Proceedings of the 2013 International Conference on Acoustics, Speech and Signal Processing (ICASSP). Vancouver, BC, Canada:IEEE, 2013. 8599-8603 [13] Erhan D, Courville A, Bengio Y, Vincent P. Why does unsupervised pre-training help deep learning? In:Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS). Chia Laguna Resort, Sardinia, Italy:AISTATS, 2010. 201-208 [14] Smolensky P. Information processing in dynamical systems:foundations of harmony theory. Parallel Distributed Processing:Explorations in the Microstructure of Cognition, vol.1:Foundations. Cambridge:MIT Press, 1986. 194-281 [15] Hinton G E. Training products of experts by minimizing contrastive divergence. Neural Computation, 2002, 14(8):1771-1800 doi: 10.1162/089976602760128018 [16] Tieleman T. Training restricted Boltzmann machines using approximations to the likelihood gradient. In:Proceedings of the 25th International Conference on Machine Learning. New York:ACM, 2008. 1064-1071 [17] Tieleman T, Hinton G. Using fast weights to improve persistent contrastive divergence. In:Proceedings of the 26th International Conference on Machine Learning (ICML). Montreal, Quebec, Canada:ACM, 2009. 1033-1040 [18] Desjardins G, Courville A C, Bengio Y, Vincent P, Dellaleau O. Tempered Markov chain Monte Carlo for training of restricted Boltzmann machines. In:Proceedings of the 13th International Workshop on Artificial Intelligence and Statistics (AISTATS). Chia Laguna Resort, Sardinia, Italy:AISTATS, 2010. 45-152 [19] Cho K, Raiko T, Ilin A. Parallel tempering is efficient for learning restricted Boltzmann machines. In:Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN). Barcelona, Spain:IEEE, 2010. 3246-3253 [20] Brakel P, Dieleman S, Schrauwen B. Training restricted Boltzmann machines with multi-tempering:harnessing parallelization. In:European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN). Belgium:Evere, 2012. 287-292 [21] Fischer A, Igel C. Training restricted Boltzmann machines:an introduction. Pattern Recognition, 2014, 47(1):25-39 doi: 10.1016/j.patcog.2013.05.025 [22] Polyak B T. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 1964, 4(5):1-17 doi: 10.1016/0041-5553(64)90137-5 [23] Fischer A, Igel C. Empirical analysis of the divergence of Gibbs sampling based learning algorithms for restricted Boltzmann machines. Artificial Neural Networks. Berlin Heidelberg:Springer, 2010. 208-217 [24] Hinton G E. A practical guide to training restricted Boltzmann machines. Neural Networks:Tricks of the Trade (Second edition). Berlin Heidelberg:Springer, 2012. 599-619 [25] Sutskever I, Martens J, Dahl G, Hinton G. On the importance of initialization and momentum in deep learning. In:Proceedings of the 30th International Conference on Machine Learning. Atlanta, Georgia, USA:ICML, 2013. 1139-1147 [26] Zarȩba S, Gonczarek A, Tomczak J M, Świątek J. Accelerated learning for restricted Boltzmann machine with momentum term. Progress in Systems Engineering. Switzerland:Springer International Publishing, 2015. 330:187-192 [27] Bengio Y, Delalleau O. Justifying and generalizing contrastive divergence. Neural Computation, 2009, 21(6):1601-1621 doi: 10.1162/neco.2008.11-07-647 [28] Carreira-Perpiñán M Á, Hinton G E. On contrastive divergence learning. In:Proceedings of the 10th International Workshop on Artificial Intelligence and Statistics (AISTATS). Barbados:The Society for Artificial Intelligence and Statistics, 2005. 59-66 [29] Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11):2278-2324 doi: 10.1109/5.726791 [30] Krizhevsky A. Learning multiple layers of features from tiny images[Master dissertation], University of Toronto, Toronto, Canada, 2009. [31] Roweis S. available:http://www.cs.nyu.edu/~roweis/, July 2, 2016. [32] Torralba A, Fergus R, Freeman W T. 80 million tiny images:a large data set for nonparametric object and scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(11):1958-1970 doi: 10.1109/TPAMI.2008.128 [33] LeCun Y, Huang F J, Bottou L. Learning methods for generic object recognition with invariance to pose and lighting. In:Proceedings of the 2004 IEEE Computer Society Conference Computer Vision and Pattern Recognition. Washington, DC, USA:IEEE, 2004. 2(2):Ⅱ-97-104 https://nyuscholars.nyu.edu/en/publications/learning-methods-for-generic-object-recognition-with-invariance-t 期刊类型引用(11)
1. 汪强龙,高晓光,吴必聪,胡子剑,万开方. 受限玻尔兹曼机及其变体研究综述. 系统工程与电子技术. 2024(07): 2323-2345 .  百度学术
百度学术2. 周瑞敏,王瑞尧,司文杰,李志军. 带有改进自适应动量因子的四容水箱DRNN控制系统设计. 工业控制计算机. 2021(01): 19-22 . 百度学术3. 李滨,曾辉. 改进的深度置信网络在电主轴故障诊断中的应用. 机械科学与技术. 2021(07): 1051-1057 . 百度学术4. 魏立新,王恒,孙浩,呼子宇. 基于改进深度信念网络训练的冷轧轧制力预报. 计量学报. 2021(07): 906-912 . 百度学术5. 史加荣,王丹,尚凡华,张鹤于. 随机梯度下降算法研究进展. 自动化学报. 2021(09): 2103-2119 . 本站查看6. 陈红岩,盛伟铭,刘嘉豪,黄翰,朱俊江,赵永佳. 基于TensorFlow架构的Adam-BPNN在红外甲烷传感器系统误差修正的应用. 传感技术学报. 2020(04): 529-536 . 百度学术7. 郭新华,高禹,林玉梅. 基于RT-RBM协同过滤的图书馆个性化推荐系统的研究. 太原师范学院学报(自然科学版). 2020(04): 59-64 . 百度学术8. 沈卉卉,李宏伟. 基于动量方法的受限玻尔兹曼机的一种有效算法. 电子学报. 2019(01): 176-182 . 百度学术9. 沈卉卉,刘国武,付丽华,刘智慧,李宏伟. 一种基于修正动量的RBM算法. 电子学报. 2019(09): 1957-1964 . 百度学术10. 祝志慧,汤勇,洪琪,黄飘,王巧华,马美湖. 基于种蛋图像血线特征和深度置信网络的早期鸡胚雌雄识别. 农业工程学报. 2018(06): 197-203 . 百度学术11. 王春梅. 基于深度置信网络的风电机组主轴承故障诊断方法研究. 自动化仪表. 2018(05): 33-37 . 百度学术其他类型引用(14)
-

 下载:
下载:



















计量
- 文章访问数: 2020
- HTML全文浏览量: 299
- PDF下载量: 841
- 被引次数: 25
