

-
摘要: 为了解决交通高峰时段城市区域路网过大的交通需求引起的路网通行效率下降以及区域内部交通流分布的异质性产生的道路资源浪费等问题.本文提出了基于区域路网固有属性宏观基本图(Macroscopic fundamental diagram,MFD)的过饱和区域控制优化模型,建立了边界控制信号和内部控制信号目标函数的双层规划优化,进一步设计了基于BP(Back propagation)神经网络的自适应动态规划(Adaptive dynamic programming,ADP)模型,对建立的双层规划区域交通信号进行求解,实例仿真结果验证了本文方法的有效性.通过本文的研究分析,对城市区域交通的需求管控、拥堵政策制定等城市区域交通管理具有一定的指导意义.Abstract: In order to solve traffic efficiency reduction of road network, which is caused by overlarge traffic demand of urban regions at peak hours, and resource waste of roads due to the heterogeneity of traffic distribution, this paper proposes an optimization model of control for oversaturated area based on inherent attributes macroscopic fundamental diagram (MFD) of regional road network, and builds up the bi-level programming optimization of objective function for boundary and internal signal control. Furthermore, an adaptive dynamic programming (ADP) model based on back propagation (BP) neural network is employed to solve the regional signal control of bi-level programming. Simulation results verify the validity of this method. The investigation of this paper has certain guidance for urban traffic management such as control and management of traffic demand, formulation of congestion policy, etc.1) 本文责任编委 董海荣
-
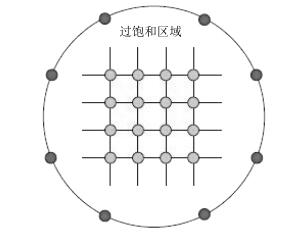
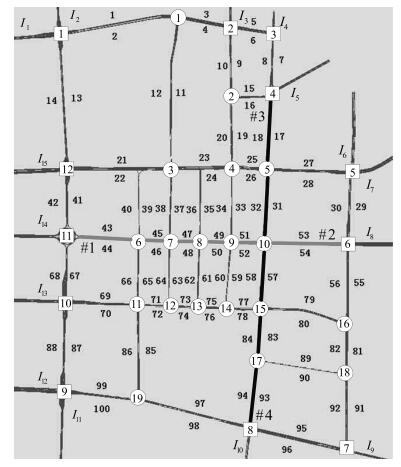
图 1 过饱和区域边界及内部交叉口示意图
Fig. 1 Boundary of oversaturated area and internal intersection diagram
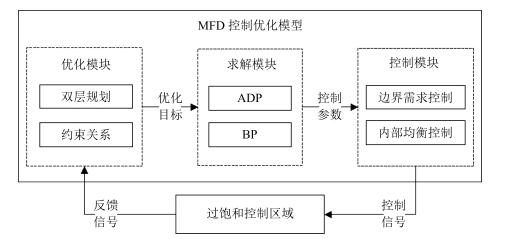
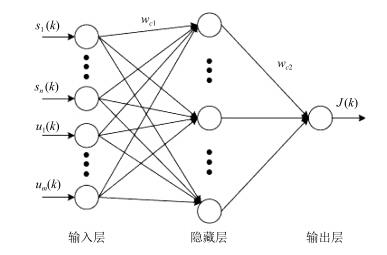
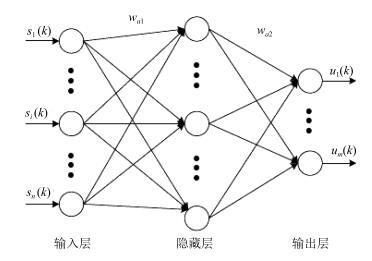
图 2 过饱和区域信号控制优化模型框架
Fig. 2 Frame of oversaturated area traffic signal optimization control model
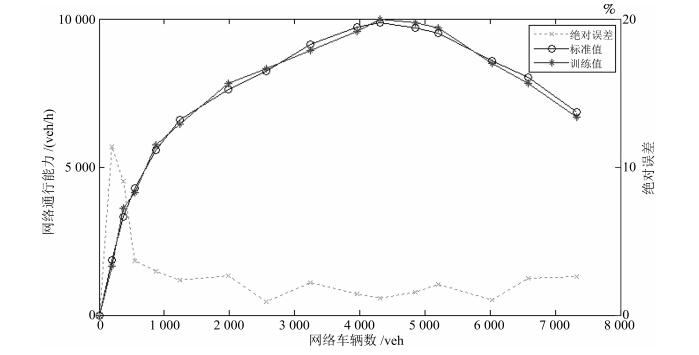
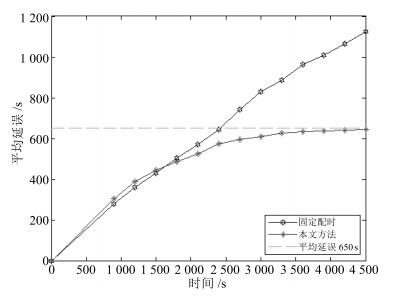
图 8 ADP模型训练值与标准值对比及误差
Fig. 8 Comparison and deviation between training value and standard value of ADP model
-
[1] Papageorgiou M, Diakaki C, Dinopoulou V, Kotsialos A, Wang Y B. Review of road traffic control strategies. Proceedings of the IEEE, 2003, 91 (12):2043-2067 doi: 10.1109/JPROC.2003.819610 [2] 高云峰, 胡华, 韩皓, 杨晓光.城市道路交叉口群信号协调控制多目标优化与仿真.中国公路学报, 2012, 25 (6):129-135 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGGL201206024.htmGao Yun-Feng, Hu Hua, Han Hao, Yang Xiao-Guang. Multi-objective optimization and simulation for urban road intersection group traffic signal control. China Journal of Highway and Transport, 2012, 25 (6):129-135 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGGL201206024.htm [3] Girianna M, Benekohal R F. Dynamic signal coordination for networks with oversaturated intersections. Transportation Research Record:Journal of the Transportation Research Board, 2002, 1811:122-130 doi: 10.3141/1811-15 [4] Aboudolas K, Papageorgiou M, Kouvelas A, Kosmatopoulos E. A rolling-horizon quadratic-programming approach to the signal control problem in large-scale congested urban road networks. Transportation Research Part C:Emerging Technologies, 2010, 18 (5):680-694 doi: 10.1016/j.trc.2009.06.003 [5] 张勇, 白玉, 杨晓光.城市道路交通网络死锁控制策.中国公路学报, 2010, 23 (6):96-102 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGGL201006016.htmZhang Yong, Bai Yu, Yang Xiao-Guang. Strategy of traffic gridlock control for urban road network. China Journal of Highway and Transport, 2010, 23 (6):96-102 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGGL201006016.htm [6] 王浩, 吴翱翔, 杨晓光.过饱和条件下信号交叉口协调控制可靠性优化.公路交通科技, 2012, 29 (11):86-91 doi: 10.3969/j.issn.1002-0268.2012.11.016Wang Hao, Wu Ao-Xiang, Yang Xiao-Guang. Reliability optimization of signalized intersection coordinated control under oversaturated condition. Journal of Highway and Transportation Research and Development, 2012, 29 (11):86-91 doi: 10.3969/j.issn.1002-0268.2012.11.016 [7] Xin W P, Chang J, Muthuswamy S, Talas M, Prassas E. Multiregime adaptive signal control for congested urban roadway networks. Transportation Research Record:Journal of the Transportation Research Board, 2013, 2356:44-52 doi: 10.3141/2356-06 [8] Jang K, Kim H, Jang I G. Traffic signal optimization for oversaturated urban networks:queue growth equalization. IEEE Transactions on Intelligent Transportation Systems, 2015, 16 (4):2121-2128 doi: 10.1109/TITS.2015.2398896 [9] 邵海鹏, 伍速锋, 李宙峰.诱导条件下的路网交通过饱和预防性控制.长安大学学报(自然科学版), 2014, 34 (5):129-137, 174 http://www.cnki.com.cn/Article/CJFDTOTAL-XAGL201405021.htmShao Hai-Peng, Wu Su-Feng, Li Zhou-Feng. Preventive signal control for over-saturated road network under traffic guidance. Journal of Chang'an University (Natural Science Edition), 2014, 34 (5):129-137, 174 http://www.cnki.com.cn/Article/CJFDTOTAL-XAGL201405021.htm [10] 李轶舜, 徐建闽, 王琳虹.过饱和交通网络的多层边界主动控制方法.华南理工大学学报(自然科学版), 2012, 40 (7):27-32 http://www.cnki.com.cn/Article/CJFDTOTAL-HNLG201207007.htmLi Yi-Shun, Xu Jian-Min, Wang Lin-Hong. Active multi-layer perimeter control strategy of oversaturated traffic networks. Journal of South China University of Technology (Natural Science Edition, 2012, 40 (7):27-32 http://www.cnki.com.cn/Article/CJFDTOTAL-HNLG201207007.htm [11] 陈娟, 胡庆松.城市过饱和路网的非均匀自适应相容优化控制.信息与控制, 2012, 41 (5):637-643 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK201205016.htmChen Juan, Hu Qing-Song. Non-even adaptive compatible optimization control for urban oversaturated traffic network. Information and Control, 2012, 41 (5):637-643 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK201205016.htm [12] Li Y S, Xu J M, Shen L. A perimeter control strategy for oversaturated network preventing queue spillback. Procedia-Social and Behavioral Sciences, 2012, 43:418-427 doi: 10.1016/j.sbspro.2012.04.115 [13] Medina J C, Benekohal R F. Reinforcement learning agents for traffic signal control in oversaturated networks. In:Proceedings of the 1st Congress of Transportation and Development Institute. Chicago IL:American Society of Civil Engineers, USA, 2011. 132-141 [14] Putha R, Quadrifoglio L, Zechman E. Comparing ant colony optimization and genetic algorithm approaches for solving traffic signal coordination under oversaturation conditions. Computer-aided Civil and Infrastructure Engineering, 2012, 27 (1):14-28 doi: 10.1111/mice.2012.27.issue-1 [15] Geroliminis N, Daganzo C F. Existence of urban-scale macroscopic fundamental diagrams:some experimental findings. Transportation Research Part B:Methodological, 2008, 42 (9):759-770 doi: 10.1016/j.trb.2008.02.002 [16] 赵靖, 马万经, 汪涛, 廖大彬.基于宏观基本图的相邻子区协调控制方法.交通运输系统工程与信息, 2015, 16 (1):78-84 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201601013.htmZhao Jing, Ma Wan-Jing, Wang Tao, Liao Da-Bin. Coordinated perimeter flow control for two subareas with macroscopic fundamental diagrams. Journal of Transportation Systems Engineering and Information Technology, 2015, 16 (1):78-84 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201601013.htm [17] Yan F, Tian F L, Shi Z K. Effects of iterative learning based signal control strategies on macroscopic fundamental diagrams of urban road networks. International Journal of Modern Physics C, 2016, 27 (4):1650045 doi: 10.1142/S0129183116500455 [18] 杜怡曼, 贾宇涵, 吴建平, 许明, 杨森炎.基于交通环境容量的区域交通动态调控模型.交通运输系统工程与信息, 2015, 15 (2):36-41 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201502006.htmDu Yi-Man, Jia Yu-Han, Wu Jian-Ping, Xu Ming, Yang Sen-Yan. Dynamic traffic control model based on traffic environment capacity. Journal of Transportation Systems Engineering and Information Technology, 2015, 15 (2):36-41 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201502006.htm [19] 岳园圆, 于雷, 朱琳, 宋国华, 陈旭梅.基于速度里程分布的快速路宏观交通状态评价模型.交通运输系统工程与信息, 2014, 14 (4):85-92 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201404013.htmYue Yuan-Yuan, Yu Lei, Zhu Lin, Song Guo-Hua, Chen Xu-Mei. Macroscopic model for evaluating traffic conditions on the expressway based on speed-special VKT distributions. Journal of Transportation Systems Engineering and Information Technology, 2014, 14 (4):85-92 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201404013.htm [20] 林晓辉.基于MFD的路网周边交通控制策略与仿真.中外公路, 2014, 34ć(4):353-356 http://www.cnki.com.cn/Article/CJFDTOTAL-GWGL201404086.htmLin Xiao-Hui. Road network perimeter control strategy and simulation based on MFD. Journal of China and Foreign Highway, 2014, 34 (4):353-356 http://www.cnki.com.cn/Article/CJFDTOTAL-GWGL201404086.htm [21] Gayah V V, Gao X Y, Nagle A S. On the impacts of locally adaptive signal control on urban network stability and the macroscopic fundamental diagram. Transportation Research Part B:Methodological, 2014, 70:255-268 doi: 10.1016/j.trb.2014.09.010 [22] 许菲菲, 何兆成, 沙志仁.交通管理措施对路网宏观基本图的影响分析.交通运输系统工程与信息, 2013, 13 (2):185-190 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201302029.htmXu Fei-Fei, He Zhao-Cheng, Sha Zhi-Ren. Impacts of traffic management measures on urban network microscopic fundamental diagram. Journal of Transportation Systems Engineering and Information Technology, 2013, 13 (2):185-190 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201302029.htm [23] 唐少虎, 刘小明, 陈兆盟.基于视频数据的交叉口状态判别及排队长度估计.道路交通与安全, 2015, 15 (1):58-64 http://www.cnki.com.cn/Article/CJFDTOTAL-DLJA201501011.htmTang Shao-Hu, Liu Xiao-Ming, Chen Zhao-Meng. State discriminant and queue length estimation of an intersection based on video data. Road Traffic & Safety, 2015, 15 (1):58-64 http://www.cnki.com.cn/Article/CJFDTOTAL-DLJA201501011.htm [24] Cassidy M J, Jang K, Daganzo C F. Macroscopic fundamental diagrams for freeway networks:theory and observation. In:Proceedings of the 2011 Transportation Research Record:Journal of the Transportation Research Board. Washington, DC:Transportation Research Board, USA, 2011. 8-15 [25] 马旭辉, 李岱, 何忠贺.城市交通网络一致性控制算法及仿真研究.公路, 2014, 60 (4):189-193 http://www.cnki.com.cn/Article/CJFDTOTAL-GLGL201504039.htmMa Xu-Hui, Li Dai, He Zhong-He. Study on urban traffic network consistency control algorithm and simulation. Highway, 2014, 60 (4):189-193 http://www.cnki.com.cn/Article/CJFDTOTAL-GLGL201504039.htm [26] 王力, 李岱, 何忠贺, 马旭辉.基于多智能体分群同步的城市路网交通控制.控制理论与应用, 2014, 31 (11):1448-1456 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201411002.htmWang Li, Li Dai, He Zhong-He, Ma Xu-Hui. Urban traffic network control based on cluster consensus of multi-agent systems. Control Theory and Application, 2014, 31 (11):1448-1456 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201411002.htm [27] Werbos P J. Using ADP to understand and replicate brain intelligence:the next level design. In:Proceedings of the 2007 IEEE International Symposium on Approximate Dynamic Programming and Reinforcement Learning. Honolulu, USA:IEEE, 2007. 209-216 [28] Powell W B. Approximate Dynamic Programming:Solving the Curses of Dimensionality. New York:John Wiley and Sons, 2007. [29] 张化光, 张欣, 罗艳红, 杨珺.自适应动态规划综述.自动化学报, 2013, 39 (4):303-311 http://www.aas.net.cn/CN/abstract/abstract17916.shtmlZhang Hua-Guang, Zhang Xin, Luo Yan-Hong, Yang Jun. An overview of research on adaptive dynamic programming. Acta Automatica Sinica, 2013, 39 (4):303-311 http://www.aas.net.cn/CN/abstract/abstract17916.shtml [30] Liu W X, Venayagamoorthy G K, Wunsch Ⅱ D C. A heuristic-dynamic-programming-based power system stabilizer for a turbogenerator in a single-machine power system. IEEE Transactions on Industry Applications, 2005, 41 (5):1377-1385 doi: 10.1109/TIA.2005.853386 [31] 赵冬斌, 刘德荣, 易建强.基于自适应动态规划的城市交通信号优化控制方法综述.自动化学报, 2009, 35 (6):676-681 http://www.aas.net.cn/CN/abstract/abstract13331.shtmlZhao Dong-Bin, Liu De-Rong, Yi Jian-Qiang. An overview on the adaptive dynamic programming based urban city traffic signal optimal control. Acta Automatica Sinica, 2009, 35 (6):676-681 http://www.aas.net.cn/CN/abstract/abstract13331.shtml [32] Balakrishnan S N, Biega V. Adaptive-critic-based neural networks for aircraft optimal control. Journal of Guidance, Control, and Dynamics, 1996, 19 (4):893-898 doi: 10.2514/3.21715 [33] Liu D R, Zhang Y, Zhang H G. A self-learning call admission control scheme for CDMA cellular networks. IEEE Transactions on Neural Networks, 2005, 16 (5):1219-1228 doi: 10.1109/TNN.2005.853408 [34] Bazzan A L C. A distributed approach for coordination of traffic signal agents. Autonomous Agents and Multi-Agent Systems, 2005, 10 (1):131-164 doi: 10.1007/s10458-004-6975-9 [35] Ferrari S, Stengel R F. Online adaptive critic flight control. Journal of Guidance, Control, and Dynamics, 2004, 27 (5):777-786 doi: 10.2514/1.12597 [36] 王澄, 刘德荣, 魏庆来, 赵冬斌, 夏振超.带有储能设备的智能电网电能迭代自适应动态规划最优控制.自动化学报, 2014, 40 (9):1984-1990 http://www.aas.net.cn/CN/abstract/abstract18469.shtmlWang Cheng, Liu De-Rong, Wei Qing-Lai, Zhao Dong-Bin, Xia Zhen-Chao. Iterative adaptive dynamic programming approach to power optimal control for smart grid with energy storage devices. Acta Automatica Sinica, 2014, 40 (9):1984-1990 http://www.aas.net.cn/CN/abstract/abstract18469.shtml [37] 唐少虎, 刘小明.基于IAGSO算法的VISSIM模型校正研究与实现.交通运输系统工程与信息, 2014, 14 (5):74-80 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201405011.htmTang Shao-Hu, Liu Xiao-Ming. VISSIM model calibration based on IAGSO algorithm. Journal of Transportation Systems Engineering and Information Technology, 2014, 14 (5):74-80 http://www.cnki.com.cn/Article/CJFDTOTAL-YSXT201405011.htm -

 下载:
下载:

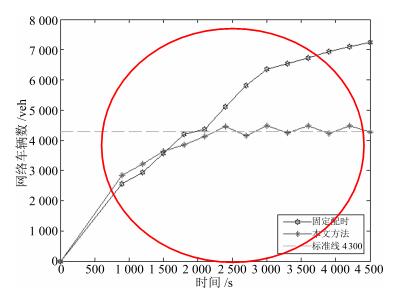
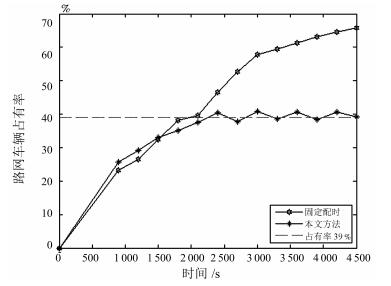

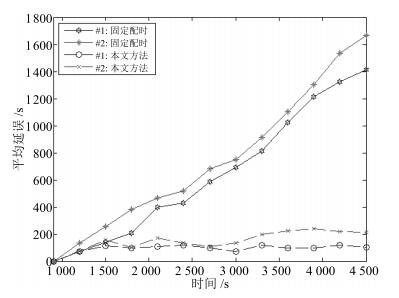
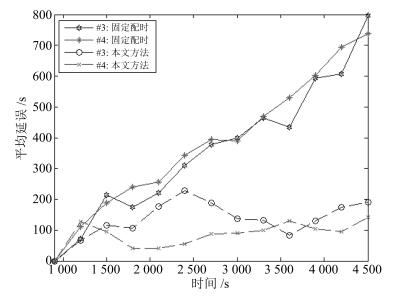

图(16)
计量
- 文章访问数: 3709
- HTML全文浏览量: 488
- PDF下载量: 807
- 被引次数: 0
