

A Generating Approach to Group's Intelligence with Application to Dysphagia's Rehabilitation Treatment after Stroke
-
摘要: 传统的中风后吞咽功能障碍康复治疗方案的制订通常以会诊方式,需要群体专家对所有可能的备选治疗方案进行讨论与决策,增加专家主观疲劳,且缺乏针对群体治疗智慧涌现方法的探讨,基层康复医师难以学习群体专家治疗智慧.基于多属性群决策理论,本文提出了群体智慧定义,给出了基于"专家讨论后的备选方案排序结果——子属性特征"的群体智慧涌现方法以及基于群体智慧的多属性决策方法,使计算机逐步学习群体专家经验并代替专家决策,减轻群体专家疲劳感,并具备针对未知备选方案进行自动决策的能力.针对一类数值实例,对传统多属性决策方法与所提决策方法进行了对比,并将所提方法应用于一类实际中风后吞咽功能障碍康复治疗中,验证了本文所提方法的正确性与可行性.Abstract: Traditional rehabilitation treatment decision-making process of dysphagia after stroke usually involves group experts to discuss all alternatives in consultation frame, suffering the from the experts' subjective fatigue and difficulties to learn the intelligence for primary doctors. Therein, the definition of group intelligence is proposed based on the multi-attribute group decision-making theories. Moreover, "the ranking results after discussion——the characteristic of the subattributes" group intelligence generating methods and the decision-making approaches based on the group intelligence are provided to help learn the group experts' experience and replace the experts, as well as reduce group's subjective fatigue. The proposed decision-making approaches are compared with the well-known multi-attribute decision-making method, meanwhile, real rehabilitation treatment examples of dysphagia after stroke are employed to exemplify applications of the proposed methods.1) 本文责任编委 吕金虎
-
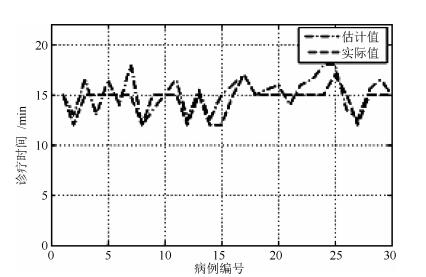
图 9 基于所提决策方法与专家会诊的物理治疗时间对比图
Fig. 9 The physical therapy time comparison chart based on the proposed decision method and expert consultation
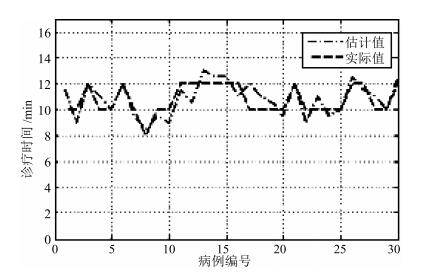
图 10 基于所提决策方法与专家会诊的按摩时间对比图
Fig. 10 The massage time comparison chart based on the proposed decision method and expert consultation
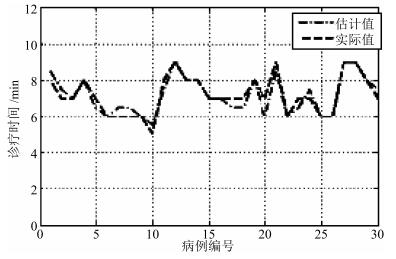
图 11 基于所提决策方法与专家会诊的针灸时间对比图
Fig. 11 The acupuncture time comparison chart based on the proposed decision method and expert consultation
表 1 备选方案集
Table 1 The alternatives
u1 u2 u3 x1 2.3 3.4 0.9 x2 4.9 8.0 1.4 x3 3.2 5.6 1.3 x4 5.0 6.8 1.9 x5 1.4 2.0 1.8  下载: 导出CSV
下载: 导出CSV
表 2 规范阵
Table 2 The standard matrix
u1 u2 u3 S1 0.46 0.42 0.47 S2 0.98 1 0.74 S3 0.64 0.7 0.68 S4 1 0.85 1 S5 0.28 0.25 0.95
下载: 导出CSV
表 4 方案准确率对照表
Table 4 The accuracy comparison of the treatment plan
编号 准确系数 物理治疗 按摩 针灸 平均 1 1.00 0.85 0.94 0.93 2 0.92 0.90 0.93 0.92 3 0.90 1.00 1.00 0.97 4 0.87 0.90 1.00 0.92 5 0.90 1.00 0.93 0.94 6 0.93 1.00 1.00 0.98 7 0.8 0.95 0.92 0.89 8 1 0.94 0.92 0.95 9 0.9 0.95 1 0.95 10 1 0.9 0.9 0.93
下载: 导出CSV
-
[1] Hassan H E, Aboloyoun A I. The value of bedside tests in dysphagia evaluation. Egyptian Journal of Ear, Nose, Throat and Allied Sciences, 2014, 15 (3):197-203 doi: 10.1016/j.ejenta.2014.07.007 [2] Navaneethan U, Eubanks S. Approach to patients with esophageal dysphagia. Surgical Clinics of North America, 2015, 95 (3):483-489 doi: 10.1016/j.suc.2015.02.004 [3] Fields J, Go J T, Schulze K S. Pill properties that cause dysphagia and treatment failure. Current Therapeutic Research, 2015, 77:79-82 doi: 10.1016/j.curtheres.2015.08.002 [4] Huang K L, Liu T Y, Huang Y C, Leong C P, Lin W C, Pong Y P. Functional outcome in acute stroke patients with oropharyngeal dysphagia after swallowing therapy. Journal of Stroke and Cerebrovascular Disease, 2014, 23 (10):2547-2553 doi: 10.1016/j.jstrokecerebrovasdis.2014.05.031 [5] 庄福振, 罗平, 何清, 史忠植.迁移学习研究进展.软件学报, 2015, 26 (1):26-39 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201501003.htmZhuang Fu-Zhen, Luo Ping, He Qing, Shi Zhong-Zhi. Survey on transfer learning research. Journal of Software, 2015, 26 (1):26-39 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201501003.htm [6] 范玉华, 秦世引.基于潜在语义分析的场景分类优化决策方法.计算机辅助设计与图形学学报, 2013, 25 (2):175-182 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201302006.htmFan Yu-Hua, Qin Shi-Yin. Optimizing decision for scene classification based on latent semantic analysis. Journal of Computer-aided Design and Computer Graphics, 2013, 25 (2):175-182 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201302006.htm [7] 杨武夷, 曾智, 张树武, 李和平.基于人脸检测与SIFT的播音员镜头检测.软件学报, 2009, 20 (9):2417-2425 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200909014.htmYang Wu-Yi, Zeng Zhi, Zhang Shu-Wu, Li He-Ping. Anchor shot detection based on face detection and SIFT. Journal of Software, 2009, 20 (9):2417-2425 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200909014.htm [8] 李琳辉, 郭景华, 张明恒, 连静.越野智能车转向及驱动协调控制.控制理论与应用, 2013, 30 (1):80-94 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201301013.htmLi Lin-Hui, Guo Jing-Hua, Zhang Ming-Heng, Lian Jing. Coordinated control of steering and driving in off-road intelligent vehicle. Control Theory and Applications, 2013, 30 (1):80-94 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201301013.htm [9] 李璐, 董秋雷, 赵瑞珍.含缺失成分的矩阵的广义低秩逼近及其在图像处理中的应用.计算机辅助设计与图形学学报, 2015, 27 (11):2065-2076 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201511007.htmLi Lu, Dong Qiu-Lei, Zhao Rui-Zhen. Generalized low-rank approximations of matrices with missing components and its applications in image processing. Journal of Computer-Aided Design and Computer Graphics, 2015, 27 (11):2065-2076 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201511007.htm [10] Yardimci A. Soft computing in medicine. Applied Soft Computing, 2009, 9 (3):1029-1043 doi: 10.1016/j.asoc.2009.02.003 [11] Montani S. Exploring new roles for case-based reasoning in heterogeneous AI systems for medical decision support. Applied Intelligence, 2008, 28 (3):275-285 doi: 10.1007/s10489-007-0046-2 [12] Yan H M, Jiang Y T, Zheng J, Peng C L, Li Q H. A multilayer perceptron-based medical decision support system for heart disease diagnosis. Expert Systems with Applications, 2006, 30 (2):272-281 doi: 10.1016/j.eswa.2005.07.022 [13] Teodorescua H N L, Chelaru M, Kandel A, Tofan I, Irimia M. Fuzzy methods in tremor assessment, prediction, and rehabilitation. Artificial Intelligence in Medicine, 2001, 21 (1-3):107-130 doi: 10.1016/S0933-3657(00)00076-2 [14] Shamsuddin S, Yussof H, Ismail L I, Mohamed S, Hanapiahc F A, Zaharid N I. Humanoid robot NAO interacting with autistic children of moderately impaired intelligence to augment communication skills. Procedia Engineering, 2014, 41:1533-1538 [15] Zahedi Z M, Akbari R, Shokouhifar M, Safaei F, Jalali A. Swarm intelligence based fuzzy routing protocol for clustered wireless sensor networks. Expert Systems with Applications, 2016, 55:313-328 doi: 10.1016/j.eswa.2016.02.016 [16] 何小贤, 朱云龙, 王玫.群体智能中的知识涌现与复杂适应性问题综述研究.信息与控制, 2005, 34 (5):560-566 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK200505010.htmHe Xiao-Xian, Zhu Yun-Long, Wang Mei. Knowledge emergence and complex adaptability in swarm intelligence. Information and Control, 2005, 34 (5):560-566 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK200505010.htm [17] Sabir M M, Ali T. Optimal PID controller design through swarm intelligence algorithms for sun tracking system. Applied Mathematics and Computation, 2016, 274:690-699 doi: 10.1016/j.amc.2015.11.036 [18] Nguyen D, Nguyen L T T, Vo B, Hong T P. A novel method for constrained class association rule mining. Information Sciences, 2015, 320:107-125 doi: 10.1016/j.ins.2015.05.006 [19] Sahoo J, Das A K, Goswami A. An efficient approach for mining association rules from high utility itemsets. Expert Systems with Applications, 2015, 42 (13):5754-5778 doi: 10.1016/j.eswa.2015.02.051 [20] 梁吉业, 冯晨娇, 宋鹏.大数据相关分析综述.计算机学报, 2016, 39(1):1-18 doi: 10.11897/SP.J.1016.2016.00001Liang Ji-Ye, Feng Chen-Jiao, Song Peng. A survey on correlation analysis of big data. Chinese Journal of Computers, 2016, 39 (1):1-18 doi: 10.11897/SP.J.1016.2016.00001 [21] Ventura R, Pinto-Ferreir C. Responding efficiently to relevant stimuli using an affect-based agent architecture. Neurocomputing, 2009, 72 (13-15):2923-2930 doi: 10.1016/j.neucom.2008.09.019 [22] Su C, Li H G. An affective learning agent with Petri-net-based implementation. Applied Intelligence, 2012, 37 (4):569-585 doi: 10.1007/s10489-012-0350-3 [23] Su C, Li H G. A novel interactive preferential evolutionary method for controller tuning in chemical processes. Chinese Journal of Chemical Engineering, 2015, 23 (2):398-411 doi: 10.1016/j.cjche.2014.09.020 [24] Su C, Li H G, Huang J W, Bao X Y. Generating methods for group affective preferences with engineering applications. Arabian Journal for Science and Engineering, 2015, 40 (6):1539-1551 doi: 10.1007/s13369-015-1617-x [25] 于超, 樊治平.指标期望为随机变量情形的多指标决策方法.控制与决策, 2015, 30 (8):1434-1440 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201508015.htmYu Chao, Fan Zhi-Ping. Multiple attribute decision making method with attribute aspirations in the form of random variable. Control and Decision, 2015, 30 (8):1434-1440 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201508015.htm [26] 张小芝, 朱传喜, 朱丽.一种基于变权的动态多属性决策方法.控制与决策, 2014, 29 (3):494-498 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201403018.htmZhang Xiao-Zhi, Zhu Chuan-Xi, Zhu Li. A method of dynamic multi-attribute decision making based on variable weight. Control and Decision, 2014, 29 (3):494-498 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201403018.htm [27] Xu Z S, Yager R R. Dynamic intuitionistic fuzzy multi-attribute decision making. International Journal of Approximate Reasoning, 2008, 48 (1):246-262 doi: 10.1016/j.ijar.2007.08.008 [28] Ohmoto Y, Kataoka M, Nishida T. Extended methods to dynamically estimate emphasizing points for group decision-making and their evaluation. Procedia--Social and Behavioral Sciences, 2013, 97:147-155 doi: 10.1016/j.sbspro.2013.10.215 [29] Meng F Y, Zhang Q. Induced continuous Choquet integral operators and their application to group decision making. Computers and Industrial Engineering, 2014, 68:42-53 doi: 10.1016/j.cie.2013.11.013 [30] 姜艳萍, 樊治平.基于判断矩阵的决策理论与方法.北京:科学出版社, 2008. 74-78Jiang Yan-Ping, Fan Zhi-Ping. The Methods and the Theory of Decision Based on the Judge Matrix. Beijing:China Science Publishing and Media Ltd, 2008. 74-78 [31] 徐泽水.不确定多属性决策方法及应用.北京:清华大学出版社, 2004.Xu Ze-Shui. Uncertain Multiple Attribute Decision Making:Method and Application. Beijing:Tsinghua University Press, 2004. [32] Xia M M, Xu Z S. Interval weight generation approaches for reciprocal relations. Applied Mathematical Modelling, 2014, 38 (3):828-838 doi: 10.1016/j.apm.2013.07.018 [33] 倪延延, 张晋昕.向量自回归模型拟合与预测效果评价.中国卫生统计, 2014, 33 (1):53-56 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGWT201401016.htmNi Yan-Yan, Zhang Jin-Xin. Modeling and forecasting for multivariate time series using a vector autoregression model. Chinese Journal of Health Statistics, 2014, 33 (1):53-56 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGWT201401016.htm -

 下载:
下载:


计量
- 文章访问数: 2297
- HTML全文浏览量: 168
- PDF下载量: 694
- 被引次数: 0
