

Multiple Feature Extraction Based on Ensemble Empirical Mode Decomposition for Motor Imagery EEG Recognition Tasks
-
摘要: 人的脑电信号(Electroencephalogram,EEG)复杂且具有非线性及非平稳性的特点使其不易分析处理,其识别效果也依赖于数据集的不同,而表现不稳定.本文中应用的总体经验模态分解(Ensemble empirical mode decomposition,EEMD)是一种具有强自适应性的信号处理方法,其在时频域展现的良好分辨率特别适合脑电识别任务处理.本文提出利用EEMD分解后得到的较具影响能力的固有模态函数(Intrinsic mode functions,IMFs),利用希尔伯特变换提取边际谱(Marginal spectrum,MS)及瞬时能谱(Instantaneous energy spectrum,IES)时频特征,同时通过加窗的方法提取非线性动力学特征近似熵特征,利用线性判别分类器(Linear discriminant analysis,LDA)作为分类器,实验结果得出,对于被试S2和被试S3可达到识别率分别为79.60%和87.77%,实验中9名被试的平均识别率为82.74%,得到平均识别率也高于近期使用相同数据集文献的其他方法.Abstract: EEG signals are complicated as well as nonlinear and non-stationary, which make them hard to analyze. Recognition result is dependent on the datasets selected, and is not stable. The ensemble empirical mode decomposition (EEMD) as a kind of adaptive signal processing method is used for motor imagery recognition tasks because of its good decomposition resolution. An efficient EEMD-based feature extraction scheme is presented, which combines the Hilbert marginal spectrum (MS) and instantaneous energy spectrum (IES) features with window-added EEMD-based approximate entropy (ApEn) features. The impactful factors of IMFs and frequency bands are selected for the features as well. A linear discriminant analysis (LDA) classifier is designed for classifyication. The method is tested on nine subjects. The result shows that the proposed feature combination is competitive in recognition rate with other methods on the same dataset. The maximal classification accuracy for S2 and S3 can reach 79.60% and 87.77%, respectively. The mean accuracy of nine subjects is 82.74%. The average recognition rate obtained is superior to other methods on the same datasets.
-
在很多机器学习的回归或者分类问题中, 训练样本通常可以划分为很多子集, 不同的子集需要用不同的模型和不同的特征来进行描述, 这时为了构建输入输出之间的关系, 需要建立很复杂的预测函数. 分而治之的方法因为可以把一个复杂的问题分解成多个相对简单的子问题而成为了处理复杂机器学习问题的一种常用方法. 决策树算法是最常用的一种分而治之方法. 决策树模型的每个分支递归的选择一个特征将输入该节点的样本空间划分成不同区域, 然后在叶子节点上用不同的节点值来对不同区域的样本进行预测. 决策树模型的一个缺陷是每次划分只依据单一的特征, 忽略了特征之间的联系. 另外决策树模型也难以建模输入输出之间的局部的线性关系. 当根据领域知识输入输出关系更适合用线性模型来描述时, 强行用决策树模型建模的话需要大量样本构建复杂的树结构.
与决策树模型将每个输入样本都划分到不同的节点、每个训练样本只由一个叶子节点负责预测不同, 混合专家模型将概率方法引入到样本空间分割和子预测模型建模中. 混合专家模型通过门函数来计算样本属于不同子类的概率, 并且对不同的子类估计一个称为专家模型的输入输出的概率模型. 混合专家模型通过门函数和多个专家模型的组合来建模输入输出之间复杂的概率关系 [1]. 和决策树模型一样, 混合专家模型也是一种将预测问题分而治之的方法. 相比于决策树模型使用硬的判决条件对输入空间进行分割, 使用概率模型的混合专家模型可以认为是一种软分割的方法 [2]. 混合专家模型使用的门函数决定了每个样本由不同专家预测的概率, 也相当于对于每个样本分配了一组将子模型组合时的权值, 之后用计算得到的概率权值把不同的专家模型的预测结果组合起来 [3].
混合专家模型中的门函数和专家模型的选取有较大的自由, 通常使用简单的线性模型来构建专家模型以建模输入输出之间局部的线性关系 [1, 4-5]. 另外也常使用高斯过程来构建非线性的专家模型 [6-7]. 混合专家通常使用多类分类的softmax函数作为门函数来计算每个样本由不同专家进行预测的概率 [5, 8]. 文献 [4] 使用了多层的门函数, 构建一个类似于决策树的多层混合专家模型.
近年来,随着各种特征选择方法的发展, 学者们将特征选择与混合专家模型进行了结合, 从而将混合专家模型推广到了处理高维数据上. 文献 [9] 将$L_1$惩罚加入到高斯混合模型训练的EM算法中以诱导稀疏的高斯模型均值. 文献 [8, 10] 沿着将$L_1$正则和EM算法结合的思路, 提出利用$L_1$ 正则方法来使得混合专家模型的门函数和专家模型都只使用部分稀疏特征. $L_1$范数正则的稀疏化方法需要设置适当的正则系数, 这些$L_1$正则和EM结合的方法通常都使用交叉检验的算法来估计正则系数. 为了减小交叉检验的计算量, 文献 [8, 10] 中所有的专家模型和门函数都使用统一的正则系数. 然而在实际中不同的专家模型可能需要使用的特征和特征数目都不相同, 这种统一的正则惩罚可能会降低模型的泛化性能. 另外由于训练混合模型时使用的EM算法不能保证每次都收敛到全局的最优解, 只能够得到局部的极大值点, 收敛得到的最终结果受到迭代初始值的影响, 因此交叉检验的性能差异并不能完全确定是否是由于使用了不同的正则化系数而导致的. 上面的这些原因导致了使用$L_1$范数正则对混合专家模型进行特征选择在实践中使用的困难.
稀疏贝叶斯方法是另外一种常用的特征选择的方法. 稀疏贝叶斯方法不像$L_1$范数正则一样可以归结到的一个凸优化问题而能够保证收敛到全局最优值, 它是一种概率的方法并且只能保证收敛到局部极值点 [11-12]. 稀疏贝叶斯方法的主要优点在于不需要预设一个正则参数, 避免了繁杂的参数选择问题. 对于混合专家模型而言, 由于训练多个模型混合就无法保证收敛到全局的最优, 并且模型本身也是从概率角度进行描述的, 因此用稀释贝叶斯方法来进行模型特征选择更加自然并且计算也更加简便. 文献 [5] 使用了稀疏贝叶斯方法来选择混合的高斯专家模型的特征, 但是其门函数使用的softmax 函数难以使用合适的先验分布, 使得后验分布具有容易计算的解析形式, 因此他们的方法只能选择专家模型特征而不能选择门函数的特征. 本文将probit模型 [13]引入到混合专家模型的门函数建模中, 用全贝叶斯方法建立了一种稀疏的混合专家模型, 这种模型能够自动地确定不同的专家模型和门函数使用的特征并且不依赖于人为的设置的参数, 因此新提出的模型适用于分析高维的输入数据. 文献 [14] 提出了一种贝叶斯混合专家模型方法. 本文与其主要区别在于本文的模型更注重于高维数据的特征选择. 为了进行特征选择, 本文提出的模型使用了不同的先验分布和门函数. 本文提出的这种全贝叶斯的混合专家模型的框架也很容易使用其他的先验分布来进行推广, 以提取具有其他性质的专家模型或者门函数.
本文主要是为了解决不同条件下的光谱数据多元校正问题. 在光谱数据分析中, 很多时候整个光谱数据集中的样本是在不同的条件下搜集的. 如果我们能够确定光谱数据的来源, 就可以对不同的来源的高维光谱数据分别建立回归模型. 但当数据来源不确定时候, 如果单纯只是将不同来源的数据放在一起用统一的线性模型估计的话可能会产生较大的误差, 特别是部分环境中的样本点很小的时候 [15]. 在光谱分析中为了分析来自不同来源的数据以及将一种环境中建立好的模型运用到另外不同的环境中人们提出了很多特殊的光谱校正迁移的算法 [16]. 为了避免线性模型在建模数据来源复杂时预测精度下降的问题, 很多非线性方法如支持向量机等也都被引入到了光谱多元校正中 [17-21]. 但是这样的模型忽视了在同一个环境中光谱数据和预测值通常是具有线性关系的. 因此本文将混合专家模型引入到光谱数据分析之中, 混合专家模型能够把搜集于不同环境中的光谱数据首先用门函数来进行分类, 然后划分到不同的专家模型进行预测, 更加符合光谱分析中非线性产生的根源.
近年来为了分析来自不同来源的但是相互之间具有内在联系的数据, 多任务学习(Multi-task learning)的方法得到了人们广泛关注 [22-29]. 多任务学习的方法能够提取多个相关的机器学习任务之间的内在联系. 即使在单个学习任务的训练样本不足的时候, 多任务学习的方法也可以利用任务之间的关联来对每个学习任务建立泛化性能较好的模型 [22]. 多任务学习研究的是在给定多个学习任务后同时学习多个学习任务, 对于每个数据样本都要有一个任务标签来判断是属于哪一个任务. 而有时我们并不清楚搜集到的数据具体属于哪个任务, 不能给这些数据一些明确的任务标签, 本文主要研究的是在不能够给定数据来源标签的情况下同时对数据进行划分和对划分后的数据建模.
本文内容安排如下: 在第1节回顾了混合专家模型的基本形式, 并且提出了新的稀疏混合专家模型. 第2节基于变分推断方法给出了稀疏混合专家模型的训练算法, 以及对新样本的预测算法. 第3节将我们提出的新的模型在一个人工数据集和3个真实的多种来源的光谱数据集中进行了实验, 展示了新的方法的预测性能. 最后第4节对全文进行了总结.
1. 稀疏混合专家模型
在本节中我们首先简要回顾经典的混合专家模型(Mixture of experts, ME), 之后介绍本文的主要贡献: 结合稀疏贝叶斯方法以及probit模型对经典的混合专家模型进行扩展后的使用贝叶斯方法选择稀疏特征的新的稀疏混合专家模型(Sparse mixture of experts, SME).
1.1 混合专家模型
考虑监督学习中的回归问题, 设有N个训练样本对 $({x}_i, {y_i}), \;i = 1, 2, \cdots, N$, 分别表示输入${x}$和输出y, 其中$x\in {{R}^{p}},y\in \mathbf{R}$. 学习目标是根据N个训练样本寻找一个回归函数 $f( x)$, 当有新的输入时回归函数可以对输出进行预测. 从概率的观点来看, 如果可以得到给定输入时输出y的概率分布$P(y| x)$, 就可以用分布的均值作为回归的预测输出:
$f( x) = {\rm E}(y| x) $
(1) 输入输出之间的条件概率有时比较复杂, 难以用单个的概率模型来描述, 混合专家模型采用多个局部的混合密度来估计输入输出之间的条件概率分布.
设有K个局部的概率模型, 混合专家模型将条件分布$P(y| x)$分解为
$P(y| x) = \sum\limits_{k = 1}^K {{\pi _k}( x){P_k}(y| x)} $
(2) ME模型假设输入输出的条件概率是多个局部概率密度的加权混合, 其中局部的概率密度函数${P_k}(y| x)$称为ME模型中的专家, 混合系数${\pi _k}( x)$称为门函数. 混合专家模型可以认为是一种概率上的决策树模型: 其采用概率的门函数来计算各个输入更适合用哪个专家预测. 决策树模型采用硬的分割规则来分割输入空间. 相对于一般的概率混合模型, 如高斯混合模型. 混合专家模型假设混合模型的加权系数与输入$ x$有关, 而概率混合模型中混合系数认为是常数.
ME常采用多元logit模型来定义门函数:
${\pi _k}( x) = \frac{{\exp ({ r}^{\rm T}_k x)}}{{\sum\limits_{j = 1}^K {\exp ({ r}^{\rm T}_j x)} }} $
(3) 其中${ r_i} \in {\textbf{R}^p}, i \in \{ 1, 2, \cdots, K\} $表示门函数的参数.
在回归问题中, 常用线性高斯模型来构建专家模型:
${P_k}(y| x) = {\rm N}(y|{ w}^{\rm T}_k x, {\alpha ^{ -1}}) $
(4) ${\rm N}(y|{ w}^{\rm T}_k x, {\alpha ^{ -1}})$表示高斯分布:
${\left( {\frac{\alpha }{{2\pi }}} \right)^{\frac{1}{2}}}\exp \left( { -\frac{\alpha }{2}{{(y -{ w}^{\rm T}_k x)}^{\rm T}}(y -{ w}^{\rm T}_k x)} \right) $
(5) ${ w_i} \in {\textbf{R}^p}, i \in \{ 1, 2, \cdots, K\} $表示K个线性高斯模型的系数, $\alpha $表示K个专家模型共有的精度参数. 混合专家模型的预测输出可以表示为
$f( x) = {\rm E}(P(y| x)) = \sum\limits_{i = 1}^K {{\pi _k}( x)\left( {{ w}^{\rm T}_k x} \right)} $
(6) 上面的混合专家模型也可以引入潜在的二元指示变量$ z = ({z_1}, {z_2}, \cdots, {z_k}) \in {\{ 0, 1\} ^K}$, 然后边缘化潜在变量$ z$得到. $ z$满足如下条件: 其中一个元素${z_i} = 1$, 其他所有元素为$0$. $ z$指示选中了K个专家中的哪一个专家. 利用指示变量$ z$混合专家模型可以表示为
$P(y| x) = \sum\limits_{ z} {P( z| x)P(y| z, x)} $
(7) 其中:
$P({z_i} = 1| x) = {\pi _k}( x) $
(8) $P(y| z, x) = \prod\limits_{k = 1}^K {{\rm N}{{(y|{ w_k}^{\rm T} x, {\alpha ^{ -1}})}^{{z_k}}}} $
(9) 如果有N个样本$({ x_i}, {y_i})$, 需要N个潜在变量${z_i}$.
采用不同的门函数和专家模型, 可以得到不同的混合专家模型. 如对于分类问题, 可采用逻辑回归模型作为专家模型来进行构建混合专家分类模型. 文献 [4] 使用混合专家分类模型作为门函数得到了一种分层的混合专家模型.
1.2 稀疏混合专家模型
当输入数据的维数大于训练样本数时, 拟合线性的高斯模型以及线性的多元分类模型都会出现过拟合问题, 因此传统的混合专家模型不适合处理高维的输入数据. 而由于高维的输入特征中通常只有部分的特征与输出有关, 对输入的特征进行提取是一种常用的分析高维数据的方法. 本文将稀疏贝叶斯方法和probit模型与混合专家模型结合起来, 提出一种能够自动提取输入特征的稀疏混合专家模型.
我们采用全贝叶斯的稀疏的线性回归模型作为专家模型:
$P(y|z, W, \alpha , x)=\prod\limits_{k=1}^{K}{\text{N}{{(y|w_{k}^{\text{T}}x, {{\alpha }_{k}}^{-1})}^{{{z}_{k}}}}}$
(10) $ (W|A)=\prod\limits_{k=1}^{K}{\text{N}({{w}_{k}}|0, {{A}_{k}}^{-1})}$
(11) ${A_k} = {\rm{diag}}\{ {a_{k1}}, {a_{k2}}, \cdots , {a_{kp}}\} $
(12) $P(A) = {\rm{ }}\prod\limits_{k = 1}^K {P({A_k}) = \prod\limits_{k = 1}^K {\prod\limits_{i = 1}^p {P({a_{ki}})} } } = \prod\limits_{k = 1}^K {\prod\limits_{i = 1}^p {{\rm{Gam}}\left( {{a_{ki}}|a, b} \right)} } $
(13) $P( {\alpha} ) = \prod\limits_{i = 1}^K {P({\alpha _k}) = \prod\limits_{i = 1}^K {{\rm{Gam}}\left( {{\alpha _k}|a, b} \right)} } $
(14) 其中$ z$表示$\{ {z_k}\} $, A表示$\{ {A_k}\} $, ${\alpha} $表示$\{ {\alpha _k}\} $, $k = 1, 2, \cdots, K$. 另外有:
${\rm{Gam}}\left( {\lambda |a, b} \right) = \frac{1}{{\Gamma (a)}}{b^a}{\lambda ^{a -1}}\exp ( -b\lambda ) $
(15) 上面的模型中采用高斯先验来建模专家模型中的预测系数${ w_k}$, 对于不同专家模型的不同特征对应的预测系数${w_{ki}}$, 设置了不同的先验精度${a_{ki}}$. 如果在训练过程中${a_{ki}}$趋于无穷, 则相应的专家模型中可以去掉对应的第i个特征 [11]. 上面的全贝叶斯模型设精度服从共轭的Gamma先验分布, 先验分布的超参数是事先设置的小的常数. 与常用的多元混合模型专家模型不同, 本文使用多元probit模型来构建门函数. probit模型常用到贝叶斯分类问题中以避免贝叶斯分类时logistic模型无法得到解析的 后验形式而需要近似的问题 [12, 30]. 对于一个K类分类问题, probit模型假设存在一个K维的潜在变量$ v \in {\bf{R}}^K$, 其采用如下的规则确定分类结果:
${z_k} = 1, \;{若}\;{v_k} = \mathop {\max }\limits_{1 \le i \le K} \{ {v_i}\} $
(16) 通过建模潜在变量$ v$与输入之间的关系来构建分类模型.
我们采用如下的贝叶斯probit门函数模型:
$P( z| v) = \prod\limits_{k = 1}^K {\delta {{({v_k} > {v_j} \wedge {z_k} = 1, \forall j \ne k)}^{{z_k}}}} $
(17) 其中$\delta $为0-1指示函数, 记${0^0} = 1$,
$P( v|R, x) = \prod\limits_{k = 1}^K {{\rm N}({v_k}|{ r_k}^{\rm T} x, 1)} $
(18) $P(R|C) = \prod\limits_{k = 1}^K {\rm N}({ r_k}|0, {C_k}^{ -1}) $
(19) ${C_k} = {\rm{diag}}\{{c_{k1}}, \cdots, {c_{kp}}\} $
(20) $P(C) = \prod\limits_{k = 1}^K {\prod\limits_{i = 1}^p {{\mathop{\rm Gam}\nolimits} } \left( {{c_{ki}}|a, b} \right)} $
(21) $ v$表示$\{{v_k}\} $, R表示$\{ { r_k}\} $, C表示$\{ {C_k}\} $, $k = 1, 2, \cdots, K$. 这里用线性高斯模型来建模隐藏变量$ v$与输入$ x$之间的关系, 由于只需要利用隐藏变量$ v$ 来进行分类, $ v$的量级并不重要, 因此固定线性高斯模型的方差为1. ${ r_k}$是门函数的线性分类系数. 同样根据稀疏贝叶斯的思想, 如果在模型训练过程中${c_{ki}}$趋于无穷, 则相应的关于第k 类的门函数中可以去掉对应的第i个特征. 做了上述的模型假设后, 我们的SME模型的全概率分布可以写成
$\begin{align} &P(y,v,z,R,W,\alpha ,A,C|x)= \\ &P(y|z,\alpha ,W,x)P(W|A)P(A)P(\alpha )\times \\ &P(z|v)P(v|R,x)P(R|C)P(C) \\ \end{align}$
(22) 设有N个训练样本, 可以用图 1所示的概率图模型来表示上述的概率关系.
本文将文献 [12] 提出的稀疏probit分类方法引入到混合专家模型中对门函数进行建模. 相比于文献 [14] 中贝叶斯的混合专家模型, 本文提出的SME模型中每个专家的线性高斯模型的系数的先验分布具有不同的精度, 这样SME模型的训练过程中能够根据这些精度的后验分布自动地选取特征. SME模型中使用probit模型作为门函数, 可以直接处理多类的贝叶斯分类问题, 而文献 [14] 需要对logistic回归中的sigmoid函数进行近似, 并且需要构建一个复杂的树结构以使用两类分类方法来对多类进行分类. 文献 [8] 采用了$L_1$范数正则化的方法来获得稀疏的专家模型系数和门函数模型系数, 但文献 [8] 中所有的专家模型和门函数都使用了同样的正则化参数, 这样的限制可能会使得有些专家模型或者门函数模型使用了过多的特征而出现过拟合, 而有些模型的正则化参数太大而出现欠拟合. 如果对不同的专家使用不同的正则化系数, 文献 [8] 中的方法将会有太多的正则参数需要事先确定, 确定参数的计算量过大. 文献 [5] 和本文一样使用了稀疏贝叶斯的线性模型作为专家模型. 两者的混合专家模型的门函数使用的是多元logit模型, 当把稀疏贝叶斯的思想用到多元logit模型时, 需要在每步迭代中计算$Kp \times Kp$的Hessian矩阵以及其逆矩阵, 计算量过大. 文献 [5] 的模型无法对门函数进行特征选择, 当输入特征的维度很高时, 可能不能得到合适的门函数.
2. 变分推断以及预测
本节先通过变分推断(Variational inference) 的方法推导出上面提出的SME模型的训练方法, 之后给出当出现新样本时输出的预测方法.
对于经典的混合专家模型, 我们常利用潜在变量$ z$以及EM (Expectation-maximization)算法来极大化似然函数以得到混合专家模型的系数. 而对于这里提出的全贝叶斯的SME模型, 为了能够对新样本做出预测, 需要首先估计给定训练样本后模型参数的后验分布, 之后利用参数的后验分布来计算新样本的输出的分布. 下面通过变分推断方法来估计模型的各个随机变量的后验分布.
给定了N个训练样本, 当新样本${ x_{\rm new}}$出现时, 新样本的预测输出分布为
$P({y_{{\rm{new}}}}|{x_{{\rm{new}}}}, X, Y) = \int {P({y_{{\rm{new}}}}|{x_{{\rm{new}}}}, \theta )P(\theta |X, Y){\rm{d}}\theta } $
(23) 这里记:
$X={{[{{x}_{1}}, {{x}_{2}}, \cdots , {{x}_{N}}]}^{\text{T}}}$
(24) $Y={{[{{y}_{1}}, {{y}_{2}}, \cdots , {{y}_{N}}]}^{\text{T}}}$
(25) $\theta$代表所有模型中未观测的隐藏变量,
$\theta = \{ C, R, V, Z, {\alpha} , W, A\} $
(26) 记:
$Z={{[{{z}_{1}}, {{z}_{2}}, \cdots , {{z}_{N}}]}^{\text{T}}}$
(27) $V={{[{{v}_{1}}, {{v}_{2}}, \cdots , {{v}_{N}}]}^{\text{T}}}$
(28) 式(23)中\(P({y_{\rm new}}|{ x_{\rm new}}, \theta )\)可以根据假设的概率模型直接写出, 因此训练任务即是估计\(P(\theta |X, Y)\).
用概率分布$q(\theta )$, 来估计后验概率$P(\theta |X, Y)$. 将测量样本的$\log$边缘概率分解为
$\label{logMag} L( Y|X) = L(q) + KL(q||P) $
(29) 其中$L(q)$定义为
$\label{logMag1} L(q) = \int {q(\theta )\ln \left\{ {\frac{{P( Y, \theta |X)}}{{q(\theta )}}} \right\}{\rm d}\theta } $
(30) $KL(q||P)$定义为
$KL(q||P) = -\int {q(\theta )\ln \left\{ {\frac{{P(\theta |X, Y)}}{{q(\theta )}}} \right\}{\rm d}\theta } $
(31) 即\(P(\theta |X, Y)\)与$q(\theta )$之间的K-L散度. 根据K-L散度的性质, 当$q(\theta ) = P(\theta |X, Y)$时, \(KL(q||P) = 0\), 但是在上面的概率模型中, $P(\theta |X, Y)$难以直接计算. 变分推断方法对$q(\theta )$的形式做出一些限定之后通过极小化\(KL(q||P)\)来用$q(\theta )$近似$P(\theta |X, Y)$. 在式(29)中, \(L( Y|X)\)为常数, 因此可以通过极大化$L(q) = \int {q(\theta )\ln \left\{ {\frac{{P( Y, \theta |X)}}{{q(\theta )}}} \right\}{\rm d}\theta }$来极小化\(KL(q||P)\). 根据平均场近似理论, 我们采用如下形式的$q(\theta )$来近似后验概率:
$\label{qast} q(\theta ) = q(Z, V)q({\alpha} )q(W)q(R)q(C)q(A) $
(32) 将式(32)代入到式(30), 用变分法来极大化$L(q)$, 可以得到
$\label{logqast} \begin{aligned} \ln {q^*}({\theta _j}) &= {{\rm E}_{i \ne j}}[\ln P(Y, \theta |X)] + \rm{const}= \& \int {\ln P(Y, \theta |X)\prod\limits_{i \ne j} {{q_i}} {\rm d}{\theta _i}} + {\rm{const}} \end{aligned} $
(33) 这里$\theta_i$, $\theta_j$代表式(32)中的因子项, 如$C, A$等. 根据式(33)可以得到一系列的关于每个因子分布的方程, 式(32)中的每个因子与其他因子的期望有关, 变分推断方法即是初始化每个因子, 然后根据式(33)交替的计算每个因子分布并代替当前因子分布, 一直循环迭代直到收敛. 下面给出专家模型和门函数中每一个因子分布的具体计算方法.
2.1 专家模型的变分推断
专家模型中包含了随机变量 ${\alpha}, W, A$, 根据式(22), ${q^*}(W)$满足:
$\eqalign{ &\ln {q^*}(W) = {{\rm{E}}_{Z, \alpha }}[\ln P(Y|Z, \alpha , W, X) + \ln P(W|A)] + {\rm{const}} = \cr &{{\rm{E}}_{Z, \alpha , {A_k}}}\{ \sum\limits_{k = 1}^K {\sum\limits_{n = 1}^N {{z_{nk}}} } [ - {{{\alpha _k}} \over 2}{(x_n^{\rm{T}}{w_k} - {y_n})^2}] + \sum\limits_{k = 1}^K { - {{w_k^{\rm{T}}{A_k}{w_k}} \over 2}} \} + {\rm{const}} \cr} $
(34) 记${\tilde \alpha _k} = {\rm E}{\alpha _k}, {\tilde A_k} = {\rm E}{A_k}, {\tilde z_{nk}} = {\rm E}{z_{nk}}, {\tilde Z_k} = {\rm{diag}}\{{\tilde z_{1k}}, {\tilde z_{2k}}, \cdots, {\tilde z_{Nk}}\}$. 由式(35)可得
$q(W)=\prod\limits_{k=1}^{K}{\text{N}(}{{w}_{k}}|{{{\tilde{m}}}_{k}}, {{{\tilde{\Sigma }}}_{k}})$
(35) ${{{\tilde{m}}}_{k}}={{\left( {{{\tilde{\alpha }}}_{k}}{{X}^{\text{T}}}{{{\tilde{Z}}}_{k}}X+{{{\tilde{A}}}_{k}} \right)}^{-1}}$
(36) ${{{\tilde{\alpha }}}_{k}}{{X}^{\text{T}}}{{{\tilde{Z}}}_{k}}Y{{{\tilde{\Sigma }}}_{k}}={{\left( {{{\tilde{\alpha }}}_{k}}{{X}^{\text{T}}}{{{\tilde{Z}}}_{k}}X+{{{\tilde{A}}}_{k}} \right)}^{-1}}$
(37) 由于模型中采用了共轭先验, 后验估计$q(W)$同样也为高斯分布, 其期望与协方差矩阵分别为${\tilde { m}_k}$和${\tilde \Sigma _k}$, 与训练样本有关. ${q^*}( \alpha )$满足:
$\eqalign{ &\ln {q^*}(\alpha ) = {{\rm{E}}_{Z, W}}[\ln P(Y|Z, \alpha , W, X) + \ln P(\alpha )] \cr & + {\rm{const}} = {{\rm{E}}_{Z, W}}\{ \sum\limits_{k = 1}^K {\sum\limits_{n = 1}^N {{z_{nk}}} } [{1 \over 2}\ln {\alpha _k} - {{{\alpha _k}} \over 2}{(x_n^{\rm{T}}{w_k} - {y_n})^2}]\} \cr & + \sum\limits_{k = 1}^K {[(a - } 1)\ln {\alpha _k} - b{\alpha _k}] + {\rm{const}} \cr} $
(38) 令: ${N_k} = \sum\limits_{n = 1}^N {{{\tilde z}_{nk}}}$ \begin{equation*} {S_k} = \frac{{{{(X{{\tilde { m}}_k} -Y)}^{\rm T}}{{\tilde Z}_k}(X{{\tilde { m}}_k} -Y) + {\rm{tr}}({X^{\rm T}}{{\tilde Z}_k}X{{\tilde \Sigma }_k})}}{{{N_k}}} \end{equation*} 式(38)可以写成
$\ln {q^*}(\alpha ) = \sum\limits_{k = 1}^K {{{{N_k}} \over 2}\ln {\alpha _k}} - {{{\alpha _k}{N_k}{S_k}} \over 2} + (a - 1)\ln {\alpha _k} - b{\alpha _k} + {\rm{const}}$
(39) 因此根据共轭先验, ${q^*}( \alpha )$同样也为Gamma分布:
${q^*}(\alpha ) = \prod\limits_{k = 1}^K {{\rm{Gam}}(} {\alpha _k}|{{\tilde a}_k}, {{\tilde b}_k}){{\tilde a}_k} = a + {{{N_k}} \over 2}, {{\tilde b}_k} = b + {{{N_k}{S_k}} \over 2}$
(40) 根据Gamma分布的性质有:
${\tilde \alpha _k} = {\rm E}{\alpha _k} = \frac{{{{\tilde a}_k}}}{{{{\tilde b}_k}}} = \frac{{a + {\frac{N_k}{2}}}}{{b + {\frac{N_kS_k}{2}}}} $
(41) 稀疏混合专家模型通过参数A进行特征选择, 由式(22)和式 (33)可以得到:
$\eqalign{ &\ln {q^*}(A) = {{\rm{E}}_W}\ln P(W|A)P(A) + {\rm{const}} = \cr &{{\rm{E}}_W}\sum\limits_{k = 1}^K {\sum\limits_{i = 1}^p {\ln \left[ {\sqrt {{{{a_{ki}}} \over {2\pi }}} \exp \left( { - {{{a_{ki}}{w_{ki}}^2} \over 2}} \right)} \right]} } + \cr &(a - 1)\ln {a_{ki}} - b{a_{ki}} + {\rm{const}} \cr} $
(42) 可以看出${q^*}({a_{ki}})$同样为Gamma分布,
$\eqalign{ &{q^*}(A) = \prod\limits_{k = 1}^K {\prod\limits_{i = 1}^p {{\rm{Gam}}} ({a_{ki}}|{{\tilde a}_{Aki}}} , {{\tilde b}_{Aki}}) \cr &\left\{ {{{\tilde a}_{Aki}}} \right\} = a + {1 \over 2} \cr &\left\{ {{{\tilde b}_{Aki}}} \right\} = b + {{{{\tilde m}_{ki}}^2 + {{\tilde \Sigma }_k}(i)} \over 2} \cr} $
(43) 其中${\tilde \Sigma _k}(i)$是${\tilde \Sigma _k}$的第i个对角元素. 同样根据Gamma分布性质有:
${\rm E}({A_k}) = {\rm{diag}}\left\{\cdots, {\frac{{{\tilde a}_{Aki}}} {{\tilde b}_{Aki}}} , \cdots\right\} $
(44) 2.2 门函数的变分推断
在概率图模型中, 随机变量$V, Z, R, C$属于门函数模型, 其中$q(R), q(C)$的推断和上面的专家模型中$q(W), q(A)$的推断类似:
$\begin{align} &\ln {{q}^{*}}(R)={{\text{E}}_{V,C}}\left[ \ln P(V|R,X)+\ln P(R|C) \right]+\text{const}= \\ &{{\text{E}}_{V,C}}[\sum\limits_{k=1}^{K}{\sum\limits_{n=1}^{N}{-\frac{{{({{x}_{n}}^{\text{T}}{{r}_{k}}-{{v}_{nk}})}^{2}}}{2}}}-\sum\limits_{k=1}^{K}{\frac{{{r}_{k}}^{\text{T}}{{C}_{k}}{{r}_{k}}}{2}}]+\text{const}= \\ &\sum\limits_{k=1}^{K}{[}-\frac{1}{2}{{(X{{r}_{k}}-{{{\tilde{v}}}_{k}})}^{\text{T}}}(X{{r}_{k}}-{{{\tilde{v}}}_{k}})-\frac{{{r}_{k}}^{\text{T}}{{{\tilde{C}}}_{k}}{{r}_{k}}}{2}]+\text{const} \\ \end{align}$
(45) 其中
${{{\tilde{v}}}_{k}}=\text{E}\left[ {{({{v}_{1k}}, \cdots , {{v}_{Nk}})}^{\text{T}}} \right]$
(46) ${{{\tilde{C}}}_{k}}=\text{E}\left[ \text{diag}\{{{c}_{k1}}, \cdots , {{c}_{kp}}\} \right]$
(47) 从式(45)中可以看出R的后验估计同样为高斯分布:
$\begin{aligned} &{q^*}(R) = \prod\limits_{k = 1}^K {{\rm N}({ r_k}|{{\tilde { \mu} }_k}, {{\tilde H}_k}} )\&{{\tilde { \mu} }_k} = {({X^{\rm T}}X + {{\tilde C}_k})^{ -1}}{X^{\rm T}}{{\tilde { v}}_k}\&{{\tilde H}_k} = {({X^{\rm T}}X + {{\tilde C}_k})^{ -1}} \end{aligned} $
(48) ${q^*}(R)$的均值和协方差矩阵分别为 ${\tilde {\mu} _k}$和${\tilde H_k}$. ${q^*}(C)$满足:
$\eqalign{ &\ln {q^*}(C) = {{\rm{E}}_R}\left[ {\ln P(R|C)P(C)} \right] + {\rm{const}} = \cr &{{\rm{E}}_W}\sum\limits_{k = 1}^K {\sum\limits_{i = 1}^p {\ln \left[ {\sqrt {{{{c_{ki}}} \over {2\pi }}} \exp \left( { - {{{c_{ki}}{r_{ki}}^2} \over 2}} \right)} \right]} } + (a - 1)\ln {c_{ki}} - b{c_{ki}} + {\rm{const}} = \cr &\sum\limits_{k = 1}^K {\sum\limits_{i = 1}^p {{1 \over 2}} } \ln {c_{ki}} - {c_{ki}}\left[ {{{\tilde \mu }_{ki}}^2 + {{\tilde H}_k}(i)} \right]2 + (a - 1)\ln {c_{ki}} - b{c_{ki}} + {\rm{const}} \cr} $
(49) 其中${\tilde H_k}(i)$为${\tilde H_k}$的第i个对角元素. 从式(49)可以得出${q^*}(C)$为Gamma分布:
$\eqalign{ &{q^*}(C) = \prod\limits_{k = 1}^K {\prod\limits_{i = 1}^p {{\rm{Gam}}} ({c_{ki}}|{{\tilde a}_{Cki}}} , {{\tilde b}_{Cki}})\left\{ {{{\tilde a}_{Cki}}} \right\} = a + {1 \over 2}\left\{ {{{\tilde b}_{Cki}}} \right\} \cr & = b + {{{{\tilde \mu }_{ki}}^2 + {{\tilde H}_k}(i)} \over 2} \cr} $
(50) ${c_{ki}}$的期望为
${\rm E}{c_{k1}} = \frac{\tilde a_{Cki}}{\tilde b_{Cki}} $
(51) 我们采用了稀疏贝叶斯的方法设专家模型和门函数中关于每个特征的拟合系数的先验分布有着不同的精度, 在模型推断的时候, 大部分精度的后验分布均值即E${a_{k1}}$和E${c_{k1}}$会变得很大, 因此可以剔除很多冗余的特征, 达到特征提取的目的 [11].
$q(Z, V)$的估计相对复杂:
$\begin{align} &\ln {{q}^{*}}(Z, V)={{\text{E}}_{\alpha , W, R}}[\ln P(Y|Z, W, \alpha , X)+ \\ &\ln P(Z|V)P(V|R, X)]+\text{const} \\ \end{align}$
(52) 记:
${{g}_{1}}={{\text{E}}_{\alpha , W, R}}\left[ \ln P(Y|Z, W, \alpha , X) \right]$
(53) ${{g}_{2}}={{\text{E}}_{\alpha , W, R}}\left[ \ln P(Z|V)P(V|R, X) \right]$
(54) 代入上面的分布函数可以计算得到:
${g_1} = \sum\limits_{n = 1}^N {\sum\limits_{k = 1}^K {{z_{nk}}\ln {\rho _{nk}}} } $
(55) $\ln {{\rho }_{nk}}=\frac{1}{2}\text{E}\ln {{\alpha }_{k}}-\frac{1}{2}\ln 2\pi -\frac{1}{2}\text{E}{{\alpha }_{k}}{{({{y}_{n}}-w_{k}^{\text{T}}{{x}_{n}})}^{2}}$
(56) 由Gamma分布的性质可得E$\ln {\alpha _k} = \psi ({\tilde a_k}) -\ln {\tilde b_k}$, $\psi ({\tilde a_k})$为digamma函数, 定义为
$\psi (a) = \frac{{\rm d}}{{{\rm d}a}}\ln \Gamma (a) $
(57) 故:
$\ln {{\rho }_{nk}}=\frac{1}{2}\psi ({{\tilde{a}}_{k}})-\frac{1}{2}\ln {{\tilde{b}}_{k}}-\frac{1}{2}\ln 2\pi -\frac{1}{2}{{\tilde{\alpha }}_{k}}\left[ {{({{y}_{n}}-{{{\tilde{m}}}_{k}}^{\text{T}}{{x}_{n}})}^{2}}+{{x}_{n}}^{\text{T}}{{{\tilde{\Sigma }}}_{k}}{{x}_{n}} \right]$
(58) 根据前面的模型定义:
$\exp \left[ {{g}_{2}}(Z,V) \right]\propto \prod\limits_{n=1}^{N}{\prod\limits_{k=1}^{K}{\text{N}({{v}_{nk}}|{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{n}},1)\delta {{({{v}_{nk}}>{{v}_{nj}},\forall j\ne k)}^{{{z}_{nk}}}}}}$
(59) 结合${g_1}, {g_2}$可以得到:
$\begin{align} &{{q}^{*}}(Z,V)=\prod\limits_{n=1}^{N}{{{q}^{*}}({{z}_{n}},{{v}_{n}})}\propto \prod\limits_{n=1}^{N}{\prod\limits_{k=1}^{K}{\text{N}}}({{v}_{nk}}|{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{n}},1)\times \\ &\delta {{({{v}_{nk}}>{{v}_{nj}},\forall j\ne k)}^{{{z}_{nk}}}}{{\rho }_{nk}}^{{{z}_{nk}}} \\ \end{align}$
(60) 记归一化常数为${\tilde L_n} = \int {{q^*}({ z_n}, { v_n})} {\rm d}{ z_n}{\rm d}{ v_n}$, 这样有:
${{q}^{*}}(Z,V)=\prod\limits_{n=1}^{N}{\frac{1}{{{{\tilde{L}}}_{n}}}}\times \prod\limits_{k=1}^{K}{\text{N}({{v}_{nk}}|{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{n}},1)\delta {{({{v}_{nk}}>{{v}_{nj}},\forall j\ne k)}^{{{z}_{nk}}}}{{\rho }_{nk}}^{{{z}_{nk}}}}$
(61) 对式(61)进行积分可以得到:
$\begin{align} &{{{\tilde{L}}}_{n}}=\sum\limits_{k=1}^{K}{\int_{-\infty }^{+\infty }{{{\rho }_{nk}}}}\delta ({{v}_{nk}}>{{v}_{nj}}\wedge {{z}_{nk}}=1, \forall j\ne k)\times \\ &\text{N}({{v}_{nk}}|{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{n}}, 1)\text{d}{{v}_{nk}}\prod\limits_{j\ne k}{\text{N}}({{v}_{nj}}|{{{\tilde{\mu }}}_{j}}^{\text{T}}{{x}_{n}}, 1)\text{d}{{v}_{nj}} \\ \end{align}$
(62) 化简后:
${\tilde L_n} = \sum\limits_{k = 1}^K {{\rho _{nk}}{{\tilde L}_{nk}}} $
(63) 其中:
${\tilde L_{nk}} = {{\rm E}_u}\left\{ {\prod\limits_{j \ne k} {\phi (u -{{\tilde {\mu} }_j}^{\rm T}{ x_n} + {{\tilde {\mu} }_k}^{\rm T}{ x_n})} } \right\} $
(64) 这里u为一个服从标准正态分布的随机变量, $\phi (x)$为probit函数, 定义为
$\phi (x) = \int_{ -\infty }^x {\frac{1}{{\sqrt {2\pi } }}\exp \left( {-\frac{ {\theta ^2}}{2}}\right){\rm d}\theta } $
(65) ${\tilde L_{nk}}$没有解析形式, 但是可以通过一维的数值积分或者随机采样方法计算出来. 根据后验概率估计(61), 我们可以求出前面的估计方程中需要的随机变量$Z, V$的期望E${z_{nk}}, {\rm E}{v_{nk}}$. 我们有:
$\begin{align} &{{{\tilde{z}}}_{nk}}=\text{E}{{z}_{nk}}=\int{{{q}^{*}}({{z}_{nk}}=1\wedge \forall j\ne k,{{z}_{nj}}=0,{{V}_{n}})\text{d}{{v}_{n}}}= \\ &\frac{{{\rho }_{nk}}}{{{{\tilde{L}}}_{n}}}\int_{-\infty }^{+\infty }{\text{N}({{v}_{nk}}|{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{n}},1)}\times \\ &\prod\limits_{j\ne k}{\int_{-\infty }^{{{v}_{nk}}}{\text{N}({{v}_{nj}}|{{{\tilde{\mu }}}_{j}}^{\text{T}}{{x}_{n}},1)}}\text{d}{{v}_{nj}}\text{d}{{v}_{nk}}=\frac{{{\rho }_{nk}}{{{\tilde{L}}}_{nk}}}{{{{\tilde{L}}}_{n}}} \\ \end{align}$
(66) ${ v_n}$的后验分布估计的边缘分布为
${{q}^{*}}({{v}_{n}})=\frac{1}{{{{\tilde{L}}}_{n}}}\sum\limits_{k=1}^{K}{{{\rho }_{nk}}\text{N}({{v}_{nk}}|{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{n}}, 1)\delta ({{v}_{nk}}>{{v}_{nj}}, \forall j\ne k)}$
(67) 可以把E${ v_n}$记成
${\tilde { v}_n} = {\rm E}{ v_n} = \frac{1}{{{{\tilde L}_n}}}\sum\limits_{k = 1}^K {\rho {{\tilde { v}}_n}^{(k)}} $
(68) ${\tilde { v}_n}^{(k)} = {({\tilde v_{n1}}^{(k)}, {\tilde v_{n2}}^{(k)}, \cdots, {\tilde v_{nK}}^{(k)})^{\rm T}} \in {\textbf{R}^K}$, 将式(67)代入到期望计算公式可以得到:
$\begin{align} &{{{\tilde{v}}}_{ni}}^{(k)}={{{\tilde{L}}}_{nk}}{{{\tilde{\mu }}}^{\text{T}}}_{i}{{x}_{n}}-{{\text{E}}_{u}}\times \{\text{N}(u|{{{\tilde{\mu }}}_{i}}^{\text{T}}{{x}_{n}}-{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{n}},1)\times \\ &\prod\limits_{j\ne i,k}{\phi (u-{{{\tilde{\mu }}}_{j}}^{\text{T}}{{x}_{n}}+{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{n}})}\},若i\ne k \\ \end{align}$
(69) ${\tilde v_{nk}}^{(k)} = {\tilde L_{nk}}\left[{{{\tilde {\mu} }^{\rm T}}_k{ x_n} + \sum\limits_{j \ne k} {\left( {{{\tilde {\mu} }^{\rm T}}_j{ x_n} -\frac{1}{{{{\tilde L}_{nk}}}}{{\tilde v}_{nj}}^{(k)}} \right)} } \right] $
(70) 上面的推导给出了模型中的所有隐藏随机变量的后验分布的估计方法, 由于采用了共轭先验假设, 后验估计和先验有着同样的形式, 只需要根据上述的公式交替更新后验估计分布的参数可以得到最优的后验估计. 每次参数更新过程中$L(q) = \int {q(\theta )\ln \left\{ {\frac{{P(Y, \theta |X)}}{{q(\theta )}}} \right\}{\rm d}\theta } $会单调上升, 在每轮对所有随机变量的后验估计进行更新后我们可以计算似然函数值下界$L(q)$的改变量来判断变分推断的迭代是否收敛.
似然函数值下界可以写成
$\begin{align} &L(q)=\int{q}(V, Z, R, W, \alpha , A, C)\times \\ &\ln \frac{P(Y, V, Z, R, W, \alpha , A, C|X)}{q(V, Z, R, W, \alpha , A, C)}\times \\ &\text{d}V\text{d}Z\text{d}R\text{d}W\text{d}\alpha \text{d}A\text{d}C= \\ &\text{E}\ln P(Y|Z, \alpha , W, X)+\text{E}\ln P(W|A)+ \\ &\text{E}\ln P(\alpha )+\text{E}\ln P(Z, V|R, X)+ \\ &\text{E}\ln P(R|C)+\text{E}\ln P(A)+ \\ &\text{E}\ln P(C)-\text{E}\ln q(W)-\text{E}\ln q(\alpha )- \\ &\text{E}\ln q(Z, V)-\text{E}\ln q(R)-\text{E}\ln q(A)-\text{E}\ln q(C) \\ \end{align}$
(71) 代入前面设定的模型的具体分布以及估计出的后验分布就可以得到极大化的似然函数值的下界. 通过计算采用不同专家数时的不同的似然函数值的下界可以选择最优的专家个数. 采用probit模型作为门函数不需要在每步对门函数模型的后验概率进行近似, 而是采用多个独立分布的积利用变分推断来近似整个后验分布. 在上面的变分推断中每次关于门函数的迭代中需要计算k个$P \times P$的矩阵${\tilde H_k}$及其逆, 相比于用logit模型计算1个$KP \times KP$的Hessian矩阵及其逆的计算量要小一点, 前者的计算量为O$(K{P^3})$, 后者为O$({K^3}{P^3})$. 但是采用probit模型每步迭代时需要计算O$({K^2}N)$个一维积分, 当专家数过多时积分的计算量会变得很大.
2.3 变分预测分布
当出现新样本${ x_{\rm new}}$时, 稀疏混合专家模型对输出${y_{\rm new}}$的预测为
$\begin{align} &P({{y}_{\text{new}}}|{{x}_{\text{new}}}, X, Y)=\int{P({{y}_{\text{new}}}|{{x}_{\text{new}}}, \theta )P(\theta |X, Y)\text{d}\theta }= \\ &\sum\limits_{{{z}_{\text{new}}}}{\int{P}}({{y}_{\text{new}}}|{{x}_{\text{new}}}, {{z}_{\text{new}, k}}=1, {{w}_{k}}, {{\alpha }_{k}})\times P({{z}_{\text{new}, k}}=1, {{w}_{k}}, {{\alpha }_{k}}|X, Y)\text{d}{{w}_{k}}\text{d}{{\alpha }_{k}} \\ \end{align}$
(72) 用上面的后验估计来近似$P({z_{{\rm new}, k} }= 1, { w_k}, {\alpha _k}|X, Y)$, 可以得到:
$\begin{align} &P({{y}_{\text{new}}}|{{x}_{\text{new}}}, X, Y)\approx \sum\limits_{{{z}_{\text{new}}}}{P}({{z}_{\text{new}, k}}=1|X, Y)\times \\ &\int{P}({{y}_{\text{new}}}|{{x}_{\text{new}}}, {{z}_{\text{new}, k}}=1, {{w}_{k}}, {{\alpha }_{k}})\times q({{w}_{k}})q({{\alpha }_{k}})\text{d}{{w}_{k}}\text{d}{{\alpha }_{k}} \\ \end{align}$
(73) 其中:
$\begin{align} &\int{P}({{y}_{\text{new}}}|{{x}_{\text{new}}}, {{z}_{\text{new}, k}}=1, \\ &{{w}_{k}}, {{\alpha }_{k}})\times q({{w}_{k}})q({{\alpha }_{k}})\text{d}{{w}_{k}}\text{d}{{\alpha }_{k}}= \\ &\int{\text{N}({{y}_{\text{new}}}|w_{k}^{\text{T}}{{x}_{\text{new}}}, {{\alpha }_{k}}^{-1})}\text{N}({{w}_{k}}|{{{\tilde{m}}}_{k}}, {{{\tilde{\Sigma }}}_{k}})\times \\ &\text{Gam}({{\alpha }_{k}}|{{{\tilde{a}}}_{k}}, {{{\tilde{b}}}_{k}})\text{d}{{w}_{k}}\text{d}{{\alpha }_{k}}=\int{\text{N}({{y}_{\text{new}}}|{{{\tilde{m}}}_{k}}^{\text{T}}{{x}_{\text{new}}}, {{\alpha }_{k}}^{-1}+{{x}_{\text{new}}}^{\text{T}}{{{\tilde{\Sigma }}}_{k}}{{x}_{\text{new}}})} \\ &\times \text{Gam}({{\alpha }_{k}}|{{{\tilde{a}}}_{k}}, {{{\tilde{b}}}_{k}})\text{d}{{\alpha }_{k}}\approx \text{N}({{y}_{\text{new}}}|{{{\tilde{m}}}_{k}}^{\text{T}}{{x}_{\text{new}}}, {{{\tilde{\alpha }}}_{k}}^{-1}+{{x}_{\text{new}}}^{\text{T}}{{{\tilde{\Sigma }}}_{k}}{{x}_{\text{new}}}) \\ \end{align}$
(74) 上式的第3行中的积分没有解析解. 由于后验分布一般比较尖锐, 可以直接用${\alpha _k}$的均值近似在整个空间中对后验分布的积分.
$\begin{align} &P({{z}_{\text{new}, k}}=1|X, Y)=\int{P}({{z}_{\text{new}, k}}=1|{{v}_{\text{new}}})\times \\ &P({{v}_{\text{new}}}|{{x}_{\text{new}}}, R)\times P(R|X, Y)\text{d}R\text{d}{{v}_{\text{new}}}\approx \\ &\int{P}({{z}_{\text{new}, k}}=1|{{v}_{\text{new}}})P({{v}_{\text{new}}}|{{x}_{\text{new}}}, R)\times q(R)\text{d}R\text{d}{{v}_{\text{new}}}= \\ &\int_{{{S}_{k}}}{P({{v}_{\text{new}}}|{{x}_{\text{new}}}, R)q(R)\text{d}R\text{d}{{v}_{\text{new}}}} \\ \end{align}$
(75) 其中${S_k} = \{ ({v_1}, {v_2}, \cdots, {v_k}) \in {\textbf{R}^K}|{v_k} > {v_j}, \forall j \ne k\} $, 由于:
$\begin{align} &\int{P({{v}_{\text{new}}}|{{x}_{\text{new}}}, R)q(R)}\text{d}R= \\ &\int{\prod\limits_{k=1}^{K}{\text{N}({{v}_{\text{new}, k}}|{{r}_{k}}^{\text{T}}{{x}_{\text{new}}}, 1)}}\times \text{N}({{r}_{k}}|{{{\tilde{\mu }}}_{k}}^{\text{T}}, {{{\tilde{H}}}_{k}})\text{d}R= \\ &\prod\limits_{k=1}^{K}{\text{N}({{v}_{\text{new}, k}}|{{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{\text{new}}}, 1+{{x}_{\text{new}}}^{\text{T}}{{{\tilde{H}}}_{k}}{{x}_{\text{new}}})} \\ \end{align}$
(76) 记:
${{{\tilde{t}}}_{\text{new}, k}}={{{\tilde{\mu }}}_{k}}^{\text{T}}{{x}_{\text{new}}}$
(77) ${{\sigma }_{\text{new}, k}}=\sqrt{1+{{x}_{\text{new}}}^{\text{T}}{{{\tilde{H}}}_{k}}{{x}_{\text{new}}}}$
(78) 式(75)等于:
$\eqalign{ &{h_k} = P({z_{{\rm{new}}, k}} = 1|X, Y) = \cr &\int_{{S_k}} {\prod\limits_{k = 1}^K {{\rm{N}}({v_{{\rm{new}}, k}}|{{\tilde \mu }_k}^{\rm{T}}{x_{{\rm{new}}}}, 1 + {x_{{\rm{new}}}}^{\rm{T}}{{\tilde H}_k}{x_{{\rm{new}}}})} {\rm{d}}{v_{{\rm{new}}}}} \cr & = {{\rm{E}}_u}\left\{ {\prod\limits_{j \ne k} {\phi \left( {{{u{\sigma _{{\rm{new}}, k}} + {{\tilde t}_{{\rm{new}}, k}} - {{\tilde t}_{{\rm{new}}, j}}} \over {{\sigma _{{\rm{new}}, j}}}}} \right)} } \right\} \cr} $
(79) u为服从标准正态分布的随机变量. 可以用下面的高斯混合分布来估计新样本输出${y_{{\rm new}}}$的分布:
$P({{y}_{\text{new}}}|{{x}_{\text{new}}},X,Y)\approx \sum\limits_{k=1}^{K}{{{h}_{k}}\text{N}({{y}_{\text{new}}}|{{{\tilde{m}}}_{k}}^{\text{T}}{{x}_{\text{new}}},{{{\tilde{\alpha }}}_{k}}^{-1}+{{x}_{\text{new}}}^{\text{T}}{{{\tilde{\Sigma }}}_{k}}{{x}_{\text{new}}})}$
(80) 输出${y_{{\rm new}}}$的期望为
${\rm E}{y_{{\rm new}}} = \sum\limits_{k = 1}^K {{h_k}{{\tilde { m}}_k}^{\rm T}{ x_{{\rm new}}}} $
(81) 可以将上式作为混合专家模型对输出的预测公式.
3. 实验
本节中我们首先采用人工生成的实验数据来检测新提出的SME模型的函数拟合和特征选择能力, 之后将提出的SME模型运用到了三个真实的光谱数据集中来检验新提出的方法在光谱数据的定量分析中的表现. SME模型将与经典的混合专家模型, 以及几种常用的回归方法包括偏最小二乘(Partial least squares, PLS)、 支持向量机回归(Support vector regression, SVR)、 LASSO (Least absolute shrinkage and selection operator)和岭回归(Ridge regression) 进行了比较. 其中SVR中采用径向基函数(Radial basis function, RBF): $\exp ( -\gamma || v -u|{|^2})$作为核函数. 在真实光谱数据集中, 我们的算法还和使用Bagging方法集成的岭回归方法进行了比较. SME模型中只需要指定一个超参数, 即共轭Gamma先验分布的$a, b$. 与PLS、 SVR以及LAR中的参数不同, 我们通常希望贝叶斯模型中超参数对模型训练的结果的影响尽量小, 因此可以直接指定为一个很小的值$a = {10^{ -3}}, b = {10^{ -5}}$. 使用这样很小的超参数, 可以减少SME模型中先验信息对后验概率分布的影响. 其他模型的参数由5层交叉检验决定. Bagging集成学习方法采用了100次重新抽样. 对于我们提出的这种稀疏混合专家模型, 和文献 [14] 一样, 我们使用了确定性退火(Deterministic annealing) 的策略来减小迭代初值对最终得到的模型的影响, 确定性退火策略的具体实现步骤参照文献[31-32].
3.1 仿真数据
我们生成300个60维的随机输入. 随机输入的生成方式如下: 首先生成300个均值为0、协方差矩阵为$UD{U^{\rm T}}$的60维多元高斯分布随机数, 其中U为60维的随机单位正交矩阵, D为对角矩阵, 其前五个对角元为1, 剩下的为0.01. 之后将这些多元高斯分布随机数的前2维加上平移项, 对前100个数据的前两维加上平移项(1, 1), 中间100个数据加上平移项$(1, -1), $ 最后100个数据加上平移项$(-1, -1).$ 这样这些输入数据可以根据前两维分成3类. 接下来为了生成对应的输出, 我们把这些数据的第3到4维按照之前分成的三堆分别乘上3个随机的系数向量并且加上方差为1的零均值高斯噪声以生成一维输出Y, 其中随机系数向量服从均值为0、标准差为10的正态分布. 通过上面的步骤我们生成了三堆可用通过前两维划分开的, 同时输出只与输入的第3、 4维有关的数据集.
我们根据生成的仿真数据训练多个不同专家数目的SME模型. 为了确定最优的专家个数, 分别计算专家数为$2\sim6$时的$L(q)$, 结果如图 2所示. 从图 2中可以看出当专家数超过3时, 进一步增加专家数模型$L(q)$反而降低, 因此SME模型适合使用3个专家. 图 3和 图 4展示了SME模型中专家模型和门函数的代表拟合系数精度的随机变量A、C的均值. 根据稀疏贝叶斯方法, 矩阵A、C中对应特征的精度值越大, 特征的对应系数就越集中到0. 因此大精度值对应的特征就可以删去, 从图 3和图 4中可以看出SME模型成功的找出了与专家模 型 相 关 的第3、 4维特征, 以及与门函数相关的第1、 2维特征.
最后来检验生成的数据对输出预测效果, 这里采用均方误差值(Root mean square error, RMSE)来作为各种方法的评价标准, 设有n个测试样本RMSE值的定义如下:
${\rm RMSE} = \sqrt {\frac{1}{n}\sum\limits_{i = 1}^n {{{({y_i} -{{\hat y}_i})}^2}} } $
(82) 其中${y_i}$是真实的输出值, 而${\hat y_i}$是预测值, 我们用5层交叉检验的方法来计算预测结果, 每次选取300个样本中的20 %的样本作为测试样本, 剩下的80 %样本作为训练样本. 表 1给出了采用PLS、SVR、 LAR、 经典的混合专家模型(ME)以及我们提出的SME方法的预测误差. 对于这种有大量多余噪声维数同时可以用少量几个线性模型描述的数据集, SME方法取得了最好的预想结果, 预测误差最接近贝叶斯误差1.0. 而线性的PLS、 LASSO、Ridge方法都不能很好地预测这类数据. 由于具有大量的噪声维度, 非线性的SVR方法的预测效果也很差. 表 1显示了经典的混合专家模型无法处理高维数据, 因此在之后对光谱数据的实验中我们只考虑使用SME模型, 不再进行和经典ME模型的比较.
表 1 在人工数据集上的预测结果Table 1 The prediction results in the arti-cial data setMethod RMSECV PLS 5.1617 ± 0.7679 SVR 4.9164 ± 0.5646 LASSO 5.2411 ± 0.4112 Ridge 5.0103 ± 0.5044 ME 10.236 ± 1.5720 SME 1.5130 ± 0.3117 3.2 光谱数据
我们使用三个真实的光谱数据集来展示我们的算法在光谱分析中的应用效果, 这三个数据集都是使用红外光谱来对物质含量或者浓度来进行预测. 第1个数据集是玉米光谱数据集, 数据集下载地址为: http://software.eigenvector.com/Data/Corn/ index.html, 这个数据集包括了240条由三个不同的光谱仪测量的玉米样本的红外光谱以及其对应的蛋白质含量、脂肪含量、 水分含量以及淀粉含量, 我们只进行对水分的预测. 玉米光谱的波长范围为1 100 nm $\sim$ 2 498 nm, 每隔2 nm测量光谱在该波长上的吸收度, 这样玉米数据集的输入样本为240个700维的向量. 而进行预测的输出的水分浓度的范围为9.38 % $\sim$ 10.99 %. 第2个数据集是来自于IDRC Shootout 2002的药品数据集, 这个数据集包含了由两个红外仪器测654个样本得到的1 308条光谱以及对应药品成分含量, 这个数据集的输入为从600 nm $\sim$ 1 898 nm每隔2 nm进行记录的1 308个650维的向量, 预测输出为在152 nm $\sim$ 239 mg范围内的药品有效成分的含量. 第3个数据集是来自于文献 [15] 的温度数据集, 包含了19个水, 乙醇等混合物样本在30 ℃ $\sim$ 70 ℃时测得的95条光谱数据, 我们研究对乙醇的预测. 温度数据集的输入为850 nm $\sim $ 1 049 nm间每隔1 nm测量的95个200维向量, 预测输出为浓度范围为$0 %\sim100$ %的乙醇浓度. 我们首先使用玉米数据集的所有240个样本训练了一个使用3个专家的SME模型. 图 5显示了这个SME模型的专家模型的回归系数的均值, 即式(35)中的W的后验估计$q(W)$的均值${\tilde m_k}, k = 1, 2, 3$. 从图 5中可以看出每个专家模型都只使用了部分的波长, 这显示了SME模型可以实现特征选择的目标.
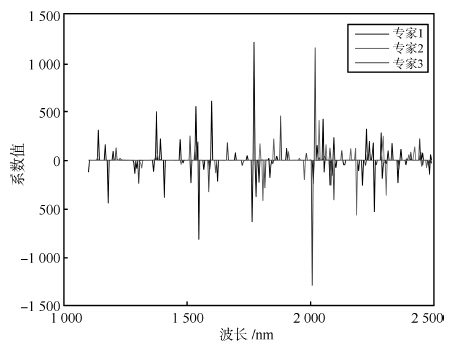 图 5 根据玉米数据集的全部样本训练的三个专家的SME 模型的专家模型回归系数的均值Fig. 5 The means of the coe±cients of the three expert models of SME trained with the corn data set
图 5 根据玉米数据集的全部样本训练的三个专家的SME 模型的专家模型回归系数的均值Fig. 5 The means of the coe±cients of the three expert models of SME trained with the corn data set由于贝叶斯方法不需要进行参数选择, 对于新提出的SME模型, 我们只需要将数据分成训练集和测试集, 用训练集上数据来训练SME模型, 然后用测试集上的数据来检验预测效果. 和PLS、SVR等模型不同, SME模型不需要一个独立的验证集来选择模型参数. 为了充分利用所有的训练样本, 我们直接使用交叉检验误差来评估SME模型在真实光谱数据集上的预测效果. 对于其他需要选择参数的建模方法, 我们给出了使得交叉检验误差最小的模型参数的RMSECV (Root mean square error of cross validation)值. 对于玉米数据集,我们将240个样本用5层交叉检验的方法来划分训练集和验证集. 每次选择192个样本作为训练集, 选择剩下的48个样本作为验证集. 对于药品数据集, 我们和文献 [33] 一样首先去掉了部分异常样本, 之后对剩下的1 208个样本同样进行5层交叉检验来选择部分模型的参数和评价不同模型预测结果. 最后对温度数据集的不同温度下的95个样本计算交叉检验的均方误差. 实验的三个光谱数据集包含了每条光谱的测量仪器或者测量环境信息, 这样我们也可以根据测量仪器或者测量环境的不同, 将浓度预测问题划分成几个子问题, 然后用多任务学习的方法来分别对不同仪器或者不同环境的光谱数据建立预测模型. 我们实验了多任务学习中的${L_{2, 1}}$范数正则的方法以同时对子问题建模和提取模型间的共有稀疏特征 [27, 34]. 三个数据集中不同建模方法的预测误差如表 2 ~4所示.
表 2 玉米光谱数据集的预测结果Table 2 The prediction results in corn data setMethod RMSECV PLS 0.1480±0.0093 SVR 0.1504±0.0084 LASSO 0.1510±0.0114 Ridge 0.1511±0.0083 Bagging-ridge 0.1239±0.0113 SME 0.1124±0.0034 Multi-task 0.1145±0.0094 表 3 温度数据集的预测结果Table 3 The prediction results in temperature data setMethod RMSECV PLS 0.0148±0.0026 SVR 0.0180±0.0019 LASSO 0.0208±0.0031 Ridge 0.0345±0.0013 Bagging-ridge 0.0143±0.0018 SME 0.0106±0.0008 Multi-task 0.0225±0.0032 表 4 药片光谱数据集的预测结果Table 4 The prediction results in pharmaceutical data setMethod RMSECV PLS 0.0148±0.0026 SVR 0.0180±0.0019 LASSO 0.0208±0.0031 Ridge 0.0345±0.0013 Bagging-ridge 0.0143±0.0018 SME 0.0106±0.0008 Multi-task 0.0225±0.0032 从表 2 $\sim$ 4可以看出在三个数据集中, SME方法都取得了最好的预测结果, 这说明对于光谱数据采用混合专家模型方法将几个线性模型组合, 能够得到比单一线性模型更好的结果. 在不知道光谱来源的情况下, SME方法的预测结果甚至还优于知道光谱测量仪器或者测量环境时的共同稀疏特征提取的多任务学习方法(Multi-task). 与多任务学习方法不同, SME方法可以在不明确光谱数据来源的情况下根据输入输出数据自动地对输入样本进行分类, 之后再分别建立模型. 在对光谱数据建模的问题上比多任务学习方法更加灵活: 因为有时可能没有记录光谱的来源. 与非线性的方法相比, SME的预测结果在三个数据集上也优于采用高斯核函数建模的SVR方法. 实验结果说明当不知道光谱数据的来源时, SME方法可以自动地构建适合不同环境中的光谱数据的预测模型, 同时判断模型的适用范围, 相比于单一的模型能够取得更好的预测结果.
集成学习的方法将多个线性模型进行集成后最终得到的还是线性模型. 和集成学习方法(如Boosting、 Bagging方法)不同, SME方法得 到 的模型可以用多个分段的线性模型来建模更加复杂的非线性关系, 也更适合建模不同环境中搜集到的光谱数据. 由于基于决策树的回归方法, 如随机森林(Random forest, RF)、 GDBT (Gradient boosting decision tree)等, 无法建模线性关系, 而理论上光谱数据和预测浓度在很大的一个范围内都满足适当的线性关系, 我们没有实验基于树模型的集成学习方法. 我们将SME方法和采用了Bagging进行集成的岭回归方法进行了比较, 从实验结果中可以看出采用Bagging方法进行集成后的岭回归模型的预测误差比原有的岭回归模型的预测误差在玉米和温度数据集上有很大的降低, 但仍然高于SME方法. 这是因为SME用多个分段线性函数构建预测模型, 更符合光谱预测数据中的非线性产生的根源, 也就能够取得更好的预测结果. 尽管我们在训练模型时采用了确定性退火的策略, 但当专家个数较多时, 混合模型的优化结果将受到初值影响, 因此实验中采用了较小的专家个数. 为了减小初值影响, 同时避免计算过程中产生奇异点, 需要研究如何在混合模型训练时同时对专家进行合并与重新分割. 另一方面, SME模型的计算量随着专家个数的增加而会变得很大, 当专家个数较多时, 每个专家模型的训练样本可能会出现不足, 这些都可能会限制SME模型建立更加复杂的非线性模型和在其他高维的数据分析中的应用. 将混合专家模型和多任务学习方法进行结合可能是解决专家个数较多时训练样本不足的一种途径. 最后将这种SME方法的学习框架扩展到提取其他的专家模型以及门函数的结构也是我们接下来需要进一步研究的目标.
4. 结论
本文利用稀疏贝叶斯方法和probit模型分类方法提出一种新的稀疏的混合专家模型. 这种模型利用了稀疏贝叶斯方法的自动相关判决技术来选择混合专家模型的门函数和专家模型的特征, 并且利用probit模型构建门函数得到了一个全贝叶斯的混合专家模型. 相对于现有混合专家模型中的特征选择方法, 本文提出的方法不需要使用交叉检验来调整模型参数, 避免了使用EM算法收敛到局部极值点时对交叉检验结果的影响. 之后我们将提出的新的模型运用到了多来源的光谱数据的多元校正的建模之中, 本文提出的模型可以为这种多个来源的光谱数据分别建立合适的线性模型, 并判断各个模型所适用的光谱数据. 在几个真实的光谱数据集上的实验结果表明本文提出的模型相对于光谱多元校正常用的支持向量机和偏最小二乘方法在预测精度上有一定的提高.
-

图 2 被试者S3进行左手想象运动(a)和右手想象运动(b)两通道上信号的IMF2平均瞬时能量图
Fig. 2 The averaging Hilbert instantaneous energy spectrum of IMF2 for left (a) and right (b) hand motor imagery over C3, C4 channels of the training trials from subject S3

图 3 被试者S4进行左手想象运动(a)和右手想象运动(b)两通道上信号的IMF2平均边际谱幅值图
Fig. 3 The averaging Hilbert marginal spectrum of IMF2 for left (a) and right (b) hand motor imagery over C3, C4 channels of the training trials from subject S4
表 1 不同被试采用两种特征在两类时段可获得的平均识别率和最高识别率
Table 1 The average and maximal classification accuracy obtained by different features F1 and F1 + F2
被试 特征组合 识别率上升时段 最优时段平均 最优时段最高 平均识别率(%) 识别率(%) 识别率(%) S1 F1 68.39 83.85 88.09 F1+F2 73.38 84.23 88.56 S2 F1 69.60 78.15 79.44 F1+F2 71.14 78.26 79.60 S3 F1 80.04 86.53 87.77 F1+F2 81.16 86.29 87.65 S4 F1 64.82 75.33 77.25 F1+F2 65.41 75.13 77.22 S5 F1 65.60 78.31 81.29 F1+F2 67.70 80.52 82.93 S6 F1 72.37 92.01 94.38 F1+F2 78.50 93.09 94.72 S7 F1 68.37 80.28 81.97 F1+F2 70.56 79.92 81.28 S8 F1 64.62 77.52 79.23 F1+F2 67.67 77.26 79.14 S9 F1 61.74 71.07 72.59 F1+F2 64.15 70.77 72.59  下载: 导出CSV
下载: 导出CSV
表 2 加窗ApEn和时间均值ApEn特征对于不同被试取得的识别率对比
Table 2 The comparasion of window-added ApEn feature and normal ApEn feature on accuracy for each subjects
被试 加窗ApEn (%) 时间均值的ApEn (%) S1 76.14±0.99 64.54±1.38 S2 74.14±0.40 72.86±0.61 S3 84.97±0.86 81.93±0.84 S4 60.02±0.80 59.03±0.42 S5 72.38±1.80 71.17±1.17 S6 84.58±0.28 82.58±0.46 S7 75.80±0.57 80.99±0.40 S8 75.00±0.57 73.88±0.39 S9 67.04±0.47 68.13±0.47
下载: 导出CSV
表 3 对于不同被试者可得到的最大识别率(%)
Table 3 The maximal classification accuracy (%) obtained on different subjects
下载: 导出CSV
表 4 本文方法与BCI竞赛获奖者所取得的最大互信息对比
Table 4 Comparison of maximal mutual information (MI) between our work and BCI competition winners'methods
特征提取方法 最大互信息(MI) Schäfer and Lemm Morlet小波特征 0.61 Narayanad AR功率谱 0.46 Saffari AAR参数模型 0.45 Gao 频段能量特征 0.44 Sadashivaiah 六阶AR参数模型 0.29 本文方法 0.64
下载: 导出CSV
表 5 本文中所用方法的时耗统计
Table 5 The time consumption of the method used in this paper
EEMD过程 瞬时能量特征 边际谱特征 近似熵特征 时耗(s) 1.147 0.001 0.082 2.354
下载: 导出CSV
-
[1] Wolpaw J R, Birbaumer N, Mcfarland D J, Pfurtscheller G, Vaughan T M. Brain-computer interfaces for communication and control. Clinical Neurophysiology, 2002, 113(6): 767-791 doi: 10.1016/S1388-2457(02)00057-3 [2] Birbaumer N. Breaking the silence: Brain-computer interfaces (BCI) for communication and motor control. Psychophysiology, 2006, 43(6): 517-532 doi: 10.1111/psyp.2006.43.issue-6 [3] 高上凯.浅谈脑--机接口的发展现状与挑战.中国生物医学工程学报, 2007, 26(6): 801-803, 809 http://www.cnki.com.cn/Article/CJFDTOTAL-ZSWY200706002.htmGao Shang-Kai. Comments on recent progress and challenges in the study of brain-computer interface. Chinese Journal of Biomedical Engineering, 2007, 26(6): 801-803, 809 http://www.cnki.com.cn/Article/CJFDTOTAL-ZSWY200706002.htm [4] 王行愚, 金晶, 张宇, 王蓓.脑控:基于脑--机接口的人机融合控制.自动化学报, 2013, 39(3): 208-221 http://www.aas.net.cn/CN/abstract/abstract17800.shtmlWang Xing-Yu, Jin Jing, Zhang Yu, Wang Bei. Brain control: Human-computer integration control based on brain-computer interface. Acta Automatica Sinica, 2013, 39(3): 208-221 http://www.aas.net.cn/CN/abstract/abstract17800.shtml [5] Blankertz B, Sannelli C, Halder S, Hammer E M, Kübler A, Müller K R, Curio G, Dickhaus T. Neurophysiological predictor of SMR-based BCI performance. Neuroimage, 2010, 51(4): 1303-1309 doi: 10.1016/j.neuroimage.2010.03.022 [6] Pfurtscheller G, Neuper C. Motor imagery and direct brain-computer communication. Proceedings of the IEEE, 2001, 89(7): 1123-1134 doi: 10.1109/5.939829 [7] Birbaumer N, Ghanayim N, Hinterberger T, Iversen I, Kotchoubey B, Kübler A, Perelmouter J, Taub E, Flor H. A spelling device for the paralysed. Nature, 1999, 398(6725): 297-298 doi: 10.1038/18581 [8] Bayliss J D. Use of the evoked potential P3 component for control in a virtual apartment. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2003, 11(2): 113-116 doi: 10.1109/TNSRE.2003.814438 [9] Hoffmann U, Vesin J M, Ebrahimi T, Diserens K. An efficient P300-based brain-computer interface for disabled subjects. Journal of Neuroscience Methods, 2008, 167(1): 115-125 doi: 10.1016/j.jneumeth.2007.03.005 [10] Lalor E C, Kelly S P, Finucane C, Burke R, Smith R, Reilly R B, McDarby G. Steady-state VEP-based brain-computer interface control in an immersive 3D gaming environment. EURASIP Journal on Applied Signal Processing, 2005, 2005: 3156-3164 doi: 10.1155/ASP.2005.3156 [11] Middendorf M, McMillan G, Calhoun G, Jones K S. Brain-computer interfaces based on the steady-state visual-evoked response. IEEE Transactions on Rehabilitation Engineering, 2000, 8(2): 211-214 doi: 10.1109/86.847819 [12] Hwang H J, Kwon K, Im C H. Neurofeedback-based motor imagery training for brain-computer interface (BCI). Journal of Neuroscience Methods, 2009, 179(1): 150-156 doi: 10.1016/j.jneumeth.2009.01.015 [13] Tam W K, Tong K Y, Meng F, Gao S. A minimal set of electrodes for motor imagery BCI to control an assistive device in chronic stroke subjects: A multi-session study. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2011, 19(6): 617-627 doi: 10.1109/TNSRE.2011.2168542 [14] Pfurtscheller G. Functional brain imaging based on ERD/ERS. Vision Research, 2001, 41(10-11): 1257-1260 doi: 10.1016/S0042-6989(00)00235-2 [15] McFarland D J, Miner L A, Vaughan T M, Wolpaw J R. Mu and Beta Rhythm topographies during motor imagery and actual movements. Brain Topography, 2000, 12(3): 177-86 doi: 10.1023/A:1023437823106 [16] Chen M Y, Fang Y H, Zheng X F. Phase space reconstruction for improving the classification of single trial EEG. Biomedical Signal Processing and Control, 2014, 11: 10-16 doi: 10.1016/j.bspc.2014.02.002 [17] Rodríguez-Bermúdez G, Garcí a-Laencina P J, Roca-González J, Roca-Dorda J. Efficient feature selection and linear discrimination of EEG signals. Neurocomputing, 2013, 115: 161-165 doi: 10.1016/j.neucom.2013.01.001 [18] 孙会文, 伏云发, 熊馨, 杨俊, 刘传伟, 余正涛.基于HHT运动想象脑电模式识别研究.自动化学报, 2015, 41(9): 1686-1692 http://www.aas.net.cn/CN/abstract/abstract18742.shtmlSun Hui-Wen, Fu Yun-Fa, Xiong Xin, Yang Jun, Liu Chuan-Wei, Yu Zheng-Tao. Identification of EEG induced by motor imagery based on Hilbert-Huang transform. Acta Automatica Sinica, 2015, 41(9): 1686-1692 http://www.aas.net.cn/CN/abstract/abstract18742.shtml [19] Hsu W Y. Assembling a multi-feature EEG classifier for left-right motor imagery data using wavelet-based fuzzy approximate entropy for improved accuracy. International Journal of Neural Systems, 2015, 25(8): 1550037 doi: 10.1142/S0129065715500379 [20] Hsu W Y, Sun Y N. EEG-based motor imagery analysis using weighted wavelet transform features. Journal of Neuroscience Methods, 2009, 176(2): 310-318 doi: 10.1016/j.jneumeth.2008.09.014 [21] Wang H X. Optimizing spatial filters for single-trial EEG classification via a discriminant extension to CSP: The Fisher criterion. Medical & Biological Engineering & Computing, 2011, 49(9): 997-1001 https://www.researchgate.net/publication/50852065_Optimizing_spatial_filters_for_single-trial_EEG_classification_via_a_discriminant_extension_to_CSP_The_Fisher_criterion [22] 王金甲, 陈春.分层向量自回归的多通道脑电信号的特征提取研究.自动化学报, 2016, 42(8): 1215-1226 http://www.aas.net.cn/CN/abstract/abstract18911.shtmlWang Jin-Jia, Chen Chun. Multi-channel EEG feature extraction using hierarchical vector autoregression. Acta Automatica Sinica, 2016, 42(8): 1215-1226 http://www.aas.net.cn/CN/abstract/abstract18911.shtml [23] 杨帮华, 章云元, 何亮飞, 李华荣, 王倩.脑机接口中基于ICA-RLS的EOG伪迹自动去除.仪器仪表学报, 2015, 36(3): 668-674 http://www.cnki.com.cn/Article/CJFDTOTAL-YQXB201503024.htmYang Bang-Hua, Zhang Yun-Yuan, He Liang-Fei, Li Hua-Rong, Wang Qian. Removal of EOG artifacts from EEG signals in BCI based on ICA-RLS. Chinese Journal of Scientific Instrument, 2015, 36(3): 668-674 http://www.cnki.com.cn/Article/CJFDTOTAL-YQXB201503024.htm [24] He L H, Hu D, Wan M, Wen Y, von Deneen K M, Zhou M C. Common Bayesian network for classification of EEG-based multiclass motor imagery BCI. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2016, 46(6): 843-854 doi: 10.1109/TSMC.2015.2450680 [25] Yuksel A, Olmez T. A neural network-based optimal spatial filter design method for motor imagery classification. PLoS One, 2015, 10(5): e0125039 doi: 10.1371/journal.pone.0125039 [26] Wu Z H, Huang N E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Advances in Adaptive Data Analysis, 2011, 1(1): 1-41 https://www.researchgate.net/publication/282728306_Ensemble_empirical_mode_decomposition_A_noise-assisted_data_analysis_method [27] Huang N E, Shen Z, Long S R, Wu M C, Shih H H, Zheng Q A, Yen N C, Tung C C, Liu H H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 1998, 454(1971): 903-995 doi: 10.1098/rspa.1998.0193 [28] BCI Competition Ⅱ [Online], available: http://www.bbci.de/competition/ii/, May 5, 2017. [29] BCI Competition Ⅲ [Online], available: http://www.bbci.de/competition/iii/, May 5, 2017. [30] BCI Competition Ⅳ [Online], available: http://www.bbci.de/competition/iv/, May 5, 2017. [31] Pfurtscheller G, Neuper C. Event-related synchronization of mu rhythm in the EEG over the cortical hand area in man. Neuroscience Letters, 1994, 174(1): 93-96 doi: 10.1016/0304-3940(94)90127-9 [32] 罗磊, 黄博妍, 孙金玮, 温良.基于总体平均经验模态分解的主动噪声控制系统研究.自动化学报, 2016, 42(9): 1432-1439 http://www.aas.net.cn/CN/abstract/abstract18931.shtmlLuo Lei, Huang Bo-Yan, Sun Jin-Wei, Wen Liang. A new ANC system based on ensemble empirical mode decomposition. Acta Automatica Sinica, 2016, 42(9): 1432-1439 http://www.aas.net.cn/CN/abstract/abstract18931.shtml [33] Yeh C L, Chang H C, Wu C H, Lee P L. Extraction of single-trial cortical beta oscillatory activities in EEG signals using empirical mode decomposition. Biomedical Engineering Online, 2010, 9: 25 doi: 10.1186/1475-925X-9-25 [34] Pincus S M. Approximate entropy as a measure of system complexity. Proceedings of the National Academy of Sciences of the United States of America, 1991, 88(6): 2297-2301 doi: 10.1073/pnas.88.6.2297 [35] Srinivasan V, Eswaran C, Sriraam N. Approximate entropy-based epileptic EEG detection using artificial neural networks. IEEE Transactions on Information Technology in Biomedicine, 2007, 11(3): 288-295 doi: 10.1109/TITB.2006.884369 [36] Signorini M G, Magenes G, Cerutti S, Arduini D. Linear and nonlinear parameters for the analysis of fetal heart rate signal from cardiotocographic recordings. IEEE Transactions on Biomedical Engineering, 2003, 50(3): 365-374 doi: 10.1109/TBME.2003.808824 [37] Yu H, Yang J. A direct LDA algorithm for high-dimensional data with application to face recognition. Pattern Recognition, 2001, 34(10): 2067-2070 doi: 10.1016/S0031-3203(00)00162-X [38] Hariharan M, Fook C Y, Sindhu R, Ilias B, Yaacob S. A comparative study of wavelet families for classification of wrist motions. Computers & Electrical Engineering, 2012, 38(6): 1798-1807 http://profiles.wizfolio.com/Nazirah/publications/27945/183326/ [39] Schlögl A, Neuper C, Pfurtscheller G. Estimating the mutual information of an EEG-based brain-computer interface. Biomedizinische Technik. Biomedical Engineering, 2002, 47(1-2): 3-8 doi: 10.1515/bmte.2002.47.1-2.3 [40] 李明爱, 崔燕, 杨金福, 郝冬梅.基于HHT和CSSD的多域融合自适应脑电特征提取方法.电子学报, 2013, 41(12): 2479-2486 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201312025.htmLi Ming-Ai, Cui Yan, Yang Jin-Fu, Hao Dong-Mei. An adaptive multi-domain fusion feature extraction with method HHT and CSSD. Acta Electronica Sinica, 2013, 41(12): 2479-2486 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201312025.htm -


 下载:
下载:




计量
- 文章访问数: 2763
- HTML全文浏览量: 409
- PDF下载量: 938
- 被引次数: 0
