

A Multi-layer Relation Graph Model for Extracting Opinion Targets and Opinion Words
-
摘要: 中文评价对象与评价词抽取是文本倾向性分析的重要问题.如何利用评价对象与评价词之间的语法、共现等关系设计模型是提高抽取精度的关键.本文提出了一种基于多层关系图模型的中文评价对象与评价词抽取方法.该方法首先利用词对齐模型抽取评价对象与评价词搭配;然后,考虑评价对象与评价词的依存句法关系、评价对象内部的共现关系和评价词内部的共现关系,建立多层情感关系图,接着利用随机游走方法计算候选评价对象与评价词的置信度;最后,选取置信度高的候选评价对象与评价词作为输出.实验结果表明,与现有的方法相比,本文所提出的方法不仅对评价对象和评价词的抽取精度均有显著提升,而且具有良好的鲁棒性.Abstract: Mining opinion targets and opinion words is a fundamental task for the Chinese online media to mine opinion and analyze sentiment. The key to enhancing the effectiveness of opinion target and opinion word is to integrate syntactic relations and co-occurrence relations between opinion target and opinion word into the mining model. A novel approach based on a multi-layer relation graph model is proposed to extract opinion targets and opinion words from Chinese social media. First, the word alignment model is employed to extract the candidates of opinion target and opinion word candidates. Second, a multi-layer relation graph is constructed by the syntactic inter-relations between opinion target and opinion word, the co-occurrence intra-relations among opinion targets, and the co-occurrence intra-relations among opinion words. Third, a random-walk algorithm is adopted to calculate the confidence of each opinion target candidate and opinion word candidate. Finally, opinion targets and opinion words are extracted according to their confidence values. Experimental results show that the presented method can not only achieve significant improvement over previous methods, but also have good robustness.
-
Key words:
- Sentiment analysis /
- opinion mining /
- dependency syntactic parsing /
- random walk
-
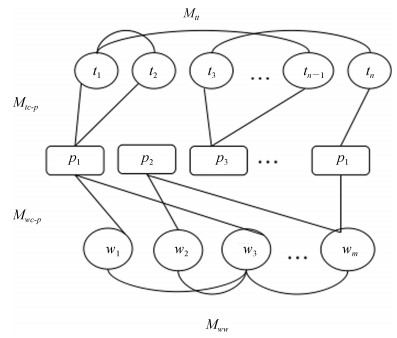
图 3 评价对象、句法模式和评价词的多层关系图
Fig. 3 The multi-layer relation graph on opinion target, syntactic pattern and opinion word
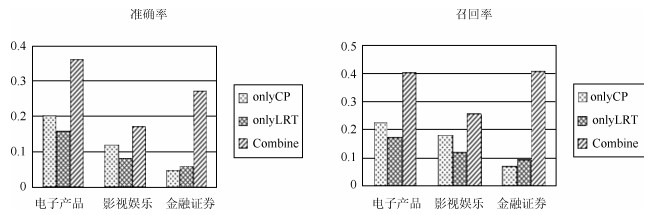
图 6 不同 $\alpha$ , $\beta$ 的评价对象抽取结果
Fig. 6 Different results of opinion targets extraction according to $\alpha$ , $\beta$

图 7 不同 $\alpha$ , $\beta$ 的评价词抽取结果
Fig. 7 Different results of opinion words extraction according to $\alpha$ , $\beta$
表 1 语料库中候选项的统计信息
Table 1 The statistics of candidate terms in the corpus
${T_i}$ $\sim{T_i}$ ${T_j}$ ${K_1}({T_i},{T_j})$ ${K_2}(\sim{T_i},{T_j})$ $\sim{T_j}$ ${K_3}({T_i},\sim{T_j})$ ${K_4}(\sim{T_i},\sim{T_j})$  下载: 导出CSV
下载: 导出CSV
表 2 语料统计表
Table 2 The description of dataset
领域 句子总数 评价对象数 评价词数 电子产品 15 051 3 593 5 068 影视娱乐 7 915 997 1 344 金融证券 6 382 534 605
下载: 导出CSV
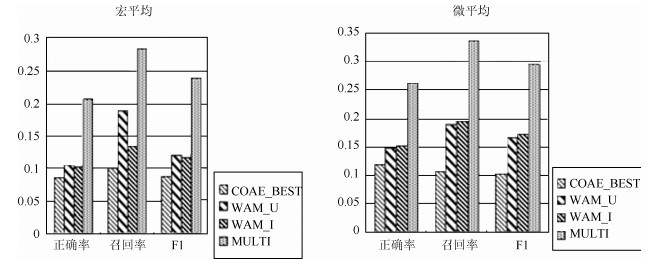
表 3 评价对象抽取的对比实验结果
Table 3 The results of our method VS baseline on opinion
领域 方法 Precision Recall ${\rm{F1\_measure}}$ 电子产品 ${\rm{COAE}}\_{\rm{BEST}}$ 0.223 0.160 0.186 LIU 0.199 0.221 0.209 ${\rm{WAM\_U}}$ 0.338 0.376 0.356 ${\rm{WAM\_I}}$ 0.346 0.385 0.364 MULTI 0.365 0.406 0.384 影视娱乐 ${\rm{COAE}}\_{\rm{BEST}}$ 0.203 0.053 0.078 LIU 0.102 0.154 0.123 ${\rm{WAM\_U}}$ 0.173 0.261 0.208 ${\rm{WAM\_I}}$ 0.185 0.279 0.223 MULTI 0.171 0.258 0.206 金融证券 ${\rm{COAE}}\_{\rm{BEST}}$ 0.090 0.045 0.045 LIU 0.210 0.315 0.252 ${\rm{WAM\_U}}$ 0.120 0.180 0.144 ${\rm{WAM\_I}}$ 0.183 0.273 0.219 MULTI 0.275 0.412 0.330
下载: 导出CSV
表 4 评价词抽取的对比实验结果
Table 4 The results of our method VS baseline on opinion word
领域 方法 Precision Recall ${\rm{F1\_measure}}$ 电子产品 ${\rm{COAE}}\_{\rm{BEST}}$ 0.218 0.113 0.126 ${\rm{WAM\_U}}$ 0.187 0.221 0.203 ${\rm{WAM\_I}}$ 0.197 0.233 0.214 MULTI 0.326 0.386 0.353 影视娱乐 ${\rm{COAE}}\_{\rm{BEST}}$ 0.130 0.096 0.064 ${\rm{WAM\_U}}$ 0.081 0.120 0.096 ${\rm{WAM\_I}}$ 0.076 0.113 0.091 MULTI 0.118 0.176 0.141 金融证券 ${\rm{COAE}}\_{\rm{BEST}}$ 0.044 0.121 0.049 ${\rm{WAM\_U}}$ 0.048 0.079 0.060 ${\rm{WAM\_I}}$ 0.035 0.058 0.044 MULTI 0.175 0.289 0.218
下载: 导出CSV
-
[1] 黄萱菁, 赵军.中文文本情感倾向性分析.中国计算机学会通讯, 2008, 4(2): 39-47Huang Xuan-Jing, Zhao Jun. Chinese text sentiment orientation analysis. Communications of the CCF, 2008, 4(2): 39-47 [2] Zhuang L, Jing F, Zhu X Y. Movie review mining and summarization. In: Proceedings of the 15th ACM International Conference on Information and Knowledge Management. Arlington, Virginia, USA: ACM, 2006. 43-50 [3] Wang B, Wang H F. Bootstrapping both product features and opinion words from Chinese customer reviews with cross-inducing. In: Proceedings of the 3rd International Joint Conference on Natural Language Processing. Hyderabad, India, 2008. 289-295 [4] Kim S M, Hovy E. Identifying opinion holders for question answering in opinion texts. In: Proceedings of AAAI-05 Workshop on Question Answering in Restricted Domains. Pennsylvania, USA: AAAI, 2005. 1367-1373 [5] Jin W, Ho H H, Srihari R K. OpinionMiner: a novel machine learning system for web opinion mining and extraction. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Paris, France: ACM, 2009. 1195-1204 [6] Wu Y B, Zhang Q, Huang X J, Wu L D. Phrase dependency parsing for opinion mining. In: Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics, 2009. 1533-1541 [7] Jakob N, Gurevych I. Extracting opinion targets in a single-and cross-domain setting with conditional random fields. In: Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Vancouver, British Columbia, Canada: Association for Computational Linguistics, 2010. 1035-1045 [8] Hu M Q, Liu B. Mining and summarizing customer reviews. In: Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Seattle, USA: ACM, 2004. 168-177 [9] Qiu G, Liu B, Bu J J, Chen C. Opinion word expansion and target extraction through double propagation. Computational Linguistics, 2011, 37(1): 9-27 doi: 10.1162/coli_a_00034 [10] Xu L H, Liu K, Lai S W, Chen Y B, Zhao J. Mining opinion words and opinion targets in a two-stage framework. In: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: ACL, 2013. 1764-1773 [11] Liu K, Xu L H, Zhao J. Syntactic patterns versus word alignment: extracting opinion targets from online reviews. In: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: ACL, 2013. 1754-1763 [12] Liu K, Xu L H, Zhao J. Opinion target extraction using word-based translation model. In: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Jeju Island, South Korea: Association for Computational Linguistics, 2012. 1346-1356 [13] 陈兴俊, 魏晶晶, 廖祥文, 简思远, 陈国龙.基于词对齐模型的中文评价对象与评价词抽取.山东大学学报 (理学版), 2016, 51(1): 58-64, 70 http://www.cnki.com.cn/Article/CJFDTOTAL-SDDX201601008.htmChen Xing-Jun, Wei Jing-Jing, Liao Xiang-Wen, Jian Si-Yuan, Chen Guo-Long. Extraction of opinion targets and opinion words from Chinese sentences based on word alignment model. Journal of Shandong University (Natural Science), 2016, 51(1): 58-64, 70 http://www.cnki.com.cn/Article/CJFDTOTAL-SDDX201601008.htm [14] Zhou X J, Wan X J, Xiao J G. Cross-language opinion target extraction in review texts. In: Proceedings of the 12th IEEE International Conference on Data Mining. Brussels, Belgium: IEEE, 2012. 1200-1205 [15] Li S S, Wang R Y, Zhou G D. Opinion target extraction using a shallow semantic parsing framework. In: Proceedings of the 26th AAAI Conference on Artificial Intelligence. Toronto, Canada: AAAI, 2012. 1671-1677 [16] Huang H, Liu Q T, Huang T. Appraisal expression recognition based on generalized mutual information. Journal of Computers, 2013, 8(7): 1715-1721 https://www.researchgate.net/publication/272798717_Appraisal_Expression_Recognition_Based_on_Generalized_Mutual_Information [17] 赵妍妍, 秦兵, 车万翔, 刘挺.基于句法路径的情感评价单元识别.软件学报, 2011, 22(5): 887-898 doi: 10.3724/SP.J.1001.2011.03767Zhao Yan-Yan, Qin Bing, Che Wan-Xiang, Liu Ting. Appraisal expression recognition based on syntactic path. Journal of Software, 2011, 22(5): 887-898 doi: 10.3724/SP.J.1001.2011.03767 [18] Li F T, Pan S J, Jin O, Yang Q, Zhu X Y. Cross-domain co-extraction of sentiment and topic lexicons. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Jeju Island, South Korea: Association for Computational Linguistics, 2012. 410-419 [19] Brown P F, Della Pietra V J, Della Pietra S A, Mercer R L. The mathematics of statistical machine translation: parameter estimation. Computational Linguistics, 1993, 19(2): 263-311 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.13.8919 [20] 舒万里. 中文领域本体学习中概念和关系抽取的研究[硕士学位论文], 重庆大学, 中国, 2012Shu Wan-Li. Research on Concept and Relation Extraction of Chinese Domain Ontology [Master dissertation], Chongqing University, China, 2012 -

 下载:
下载:



计量
- 文章访问数: 2989
- HTML全文浏览量: 293
- PDF下载量: 798
- 被引次数: 0
