

Estimating Spatial Layout of Cluttered Rooms by Using Object Prior and Spatial Constraints
-
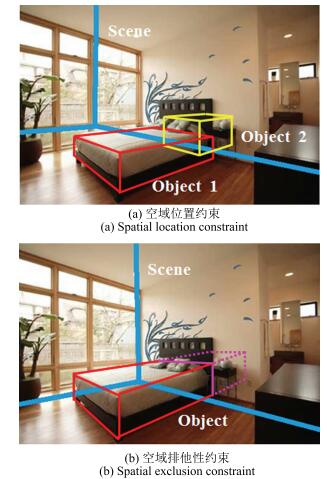
摘要: 对结构化室内场景的空域布局结构进行估计是计算机视觉领域的研究热点之一.然而,对于内部堆放了众多杂乱物体的室内场景,现有的大多数方法容易受到各种物体遮挡的影响而无法对这一类场景的布局结构进行准确推理.为此,本文方法充分考虑了房间和物体之间的几何和语义关联性,参数化地对房间和内部物体的三维体积分别进行描述,并且提出利用多种高层图像语义来获取物体的先验信息.此外,还在此基础上加入了空域排他性和空域位置等多种空域约束,进而在改进室内场景空域布局估计的同时为物体的识别和定位提供关键信息.本文方法不仅具有较低的求解复杂度,而且通过试验表明相比于现有的经典方法在杂乱的室内场景中能够取得更为鲁棒的空域布局推理结果.Abstract: Estimating spatial layout of a structural indoor scene is one of the research hotspots in computer vision. However, most of the current solutions cannot work robustly in a cluttered room due to occlusion of different objects inside. In this paper, a new algorithm which integrates geometric and semantic relations between room and objects is proposed to recover the spatial layout of a cluttered room. This algorithm parametrically represents the 3D volume of both room and objects and uses multiple high-level image semantics to obtain object priors. Furthermore, several spatial constraints such as spatial exclusion and containment are used which simultaneously optimize spatial layout estimation of the room and provide significant information for object recognition and localization. One advantage of the algorithm is its low computational complexity, and experimental results also demonstrate that it can work more robustly in cluttered rooms than several classic algorithms.
-
-

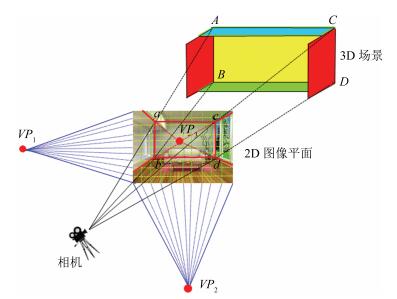
图 5 基于不同高层图像语义的物体位置估计
Fig. 5 Different high-level image semantic based object localization
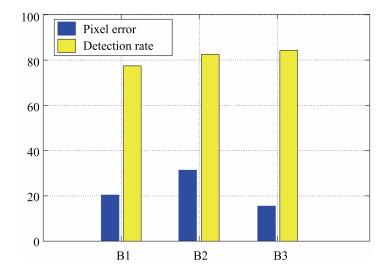
图 10 不同高层图像语义在物体结构假设中的像素误差和物体识别率
Fig. 10 The pixel error and object recognition rate of different high-level image semantics in object structure hypothesis
表 1 房间结构假设误差
Table 1 Room hypothesis error
方法(OPP) A1 A2 A3 A4 Pixel error 21.2 26.8 17.0 15.9 Corner error 6.3 11.4 5.5 5.0  下载: 导出CSV
下载: 导出CSV
-
[1] Coughlan J M, Yuille A L. Manhattan world:compass direction from a single image by Bayesian inference. In:Proceedings of the 7th IEEE International Conference on Computer Vision. Kerkyra, Greece:IEEE, 1999. 941-947 http://ieeexplore.ieee.org/document/790349/authors [2] Hedau V, Hoiem D, Forsyth D. Recovering the spatial layout of cluttered rooms. In:Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 1849-1856 Recovering the spatial layout of cluttered rooms [3] Lee D C, Hebert M, Kanade T. Geometric reasoning for single image structure recovery. In:Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA:IEEE, 2009. 2136-2143 Geometric reasoning for single image structure recovery [4] Košecká J, Zhang W. Video compass. In:Proceedings of the 7th European Conference on Computer Vision. Copenhagen, Denmark:Springer, 2002. 476-490 http://dl.acm.org/citation.cfm?id=649358 [5] Rother C. A new approach to vanishing point detection in architectural environments. Image and Vision Computing, 2002, 20(9-10):647-655 doi: 10.1016/S0262-8856(02)00054-9 [6] Barinova O, Konushin V, Yakubenko A, Lee K, Lim H, Konushin A. Fast automatic single-view 3-D reconstruction of urban scenes. In:Proceedings of the 10th European Conference on Computer Vision. Marseille, France:Springer, 2008. 100-113 [7] Yu S X, Zhang H, Malik J. Inferring spatial layout from a single image via depth-ordered grouping. In:Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Anchorage, AK, USA:IEEE, 2008. 1-7 Inferring spatial layout from a single image via depth-ordered grouping [8] Nabbe B, Hoiem D, Efros A A A, Hebert M. Opportunistic use of vision to push back the path-planning horizon. In:Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems. Beijing, China:IEEE, 2006. 2388-2393 doi: 10.1109/IROS.2006.281676 [9] Hoiem D, Efros A A, Hebert M. Recovering surface layout from an image. International Journal of Computer Vision, 2007, 75(1):151-172 doi: 10.1007/s11263-006-0031-y [10] Micusik B, Wildenauer H, Kosecka J. Detection and matching of rectilinear structures. In:Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK, USA, 2008. 1-7 doi: 10.1109/CVPR.2008.4587488 [11] Saxena A, Schulte J, Ng A Y. Depth estimation using monocular and stereo cues. In:Proceedings of the 20th International Joint Conference on Artificial Intelligence. San Francisco, CA, USA:Morgan Kaufmann Publishers Inc., 2007. 2197-2203 [12] Liu B Y, Gould S, Koller D. Single image depth estimation from predicted semantic labels. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA:IEEE, 2010. 1253-1260 [13] Liu M M, Salzmann M, He X M. Discrete-continuous depth estimation from a single image. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE, 2014. 716-723 http://dblp.uni-trier.de/db/conf/cvpr/cvpr2014.html#LiuSH14 [14] Gupta A, Efros A A, Hebert M. Blocks world revisited:image understanding using qualitative geometry and mechanics. In:Proceedings of the 11th European Conference on Computer Vision. Heraklion, Crete, Greece:Springer, 2010. 482-496 [15] Lee D C, Gupta A, Hebert M, Kanade T. Estimating spatial layout of rooms using volumetric reasoning about objects and surfaces. In:Proceedings of the 2010 Advances in Neural Information Processing Systems 23. Vancouver, British Columbia, Canada:Curran Associates, Inc., 2010. 1288-1296 [16] Hedau V, Hoiem D, Forsyth D. Thinking inside the box:using appearance models and context based on room geometry. In:Proceedings of the 11th European Conference on Computer Vision. Heraklion, Crete, Greece:Springer, 2010. 224-237 [17] Wang H Y, Gould S, Koller D. Discriminative learning with latent variables for cluttered indoor scene understanding. In:Proceedings of the 11th European Conference on Computer Vision. Heraklion, Crete, Greece:Springer, 2010. 497-510 [18] Schwing A G, Fidler S, Pollefeys M, Urtasun R. Box in the box:joint 3D layout and object reasoning from single images. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, VIC, Australia:IEEE, 2013. 353 -360 [19] Choi W, Chao Y W, Pantofaru C, Savarese S. Understanding indoor scenes using 3D geometric phrases. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 33-40 http://ieeexplore.ieee.org/document/6618856/authors [20] Tsochantaridis I, Joachims T, Hofmann T, Altun Y. Large margin methods for structured and interdependent output variables. The Journal of Machine Learning Research, 2005, 6:1453-1484 [21] Li F X, Carreira J, Sminchisescu C. Object recognition as ranking holistic figure-ground hypotheses. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA:IEEE, 2010. 1712-1719 [22] Lampert C H, Blaschko M B, Hofmann T. Efficient subwindow search:a branch and bound framework for object localization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12):2129-2142 doi: 10.1109/TPAMI.2009.144 [23] Russakovsky O, Ng A Y. A Steiner tree approach to efficient object detection. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA:IEEE, 2010. 1070-1077 [24] Vijayanarasimhan S, Grauman K. Efficient region search for object detection. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA:IEEE, 2011. 1401-1408 [25] Russell S, Norvig P. Artificial Intelligence:A Modern Approach (3rd edition). New Jersey:Pearson, 2009. [26] Russell B C, Torralba A, Murphy K P, Freeman W T. LabelMe:a database and web-based tool for image annotation. International Journal of Computer Vision, 2008, 77(1-3):157-173 doi: 10.1007/s11263-007-0090-8 期刊类型引用(5)
1. 吴强,董雁,吴域西,谢丽萍. 基于概念格因子分解的零件三维CAD模型检索. 自动化学报. 2019(02): 407-419 .  本站查看
本站查看2. 刘天亮,顾雁秋,曹旦旦,戴修斌,罗杰波. 一种由粗至精的室内场景的空间布局估计方法. 机器人. 2019(01): 58-64 . 百度学术3. 胡家强. 小户型室内空间视觉合理性评价仿真. 计算机仿真. 2019(07): 339-342 . 百度学术4. 蒋梦菲. 建筑室内环境空间结构特征多层次布局仿真. 计算机仿真. 2019(09): 397-401 . 百度学术5. 刘天亮,陆泮宇,戴修斌,刘峰,罗杰波. 融合信息化边界和多模态特征的室内空间布局估计. 南京信息工程大学学报(自然科学版). 2019(06): 735-742 . 百度学术其他类型引用(1)
-







图(10) / 表(1)
计量
- 文章访问数: 2217
- HTML全文浏览量: 245
- PDF下载量: 401
- 被引次数: 6
