

Prediction of Pareto Dominance Using Nearest Neighbor Method Based on Decision Space Transformation
-
摘要: 为提高在决策空间运用最近邻方法预测多目标优化Pareto支配性的精度,提出一种基于决策空间变换的最近邻预测方法.在分析目标函数与决策分量相关性的基础上,提出属性变化趋势模型的构造方法,建立低计算成本的属性趋势代理模型.通过属性趋势模型引入决策空间到目标空间的映射知识,对多目标问题的决策空间进行变换,使决策空间的最近邻更有效反映目标空间的最近邻.选取具有不同相关系数特征的典型多目标优化问题,进行Pareto支配性预测的可对比实验,结果表明在新空间中运用最近邻方法可显著提高分类准确性.Abstract: In this paper, nearest neighbor prediction is used to decide Pareto dominance of candidate solutions in expensive multi-objective optimization. For improving the accuracy of predicting Pareto dominance in decision space, a transformation method of decision space is proposed. Based on correlation analysis of objective functions and decision attributes, computationally efficient attribute tendency models of objective functions are set up. These models are used to re-construct the decision space such that the knowledge of objective space is introduced and the neighborhood relation in decision space can more effectively reflect that in the original objective space. Experiments of Pareto dominance prediction are carried out on a group of typical multi-objective optimization problems. The results indicate that the prediction of Pareto dominance using the proposed method is more accurate and efficient than the existing methods.
-
Key words:
- Tendency model /
- space transformation /
- nearest neighbor method /
- Pareto dominance
1) 本文责任编委 乔俊飞 -
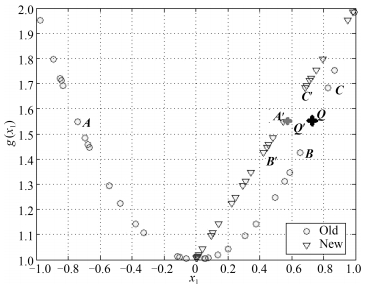
图 1 决策空间的线性化过程(圆点表示原样本点的分布, 三角表示经过趋势模型$y=g (x_i)$映射后的样本点
Fig. 1 The linearization process of decision space (Circles are the original sample points and triangles are the mapped sample points by the trend model $y=g (x_i)$.)
表 1 测试函数的决策属性与目标属性的相关系数
Table 1 Correlation coefficient of decision attribute and objective attribute of test function
测试函数 f1 (x) f2 (x) f3 (x) ZDT1 n=10 (1, 0, 0, 0, …) (-0.59, 0.27, 0.27, 0.27, …) n=30 (1, 0, 0, 0, …) (-0.79, 0.11, 0.11, 0.11, …) ZDT3 n=3 (1, 0, 0) (-0.28, 0.65, 0.65) n=10 (1, 0, 0, 0, …) (-0.49, 0.25, 0.25, …) ZDT6 n=3 (0.47, 0, 0) (0.02, 0.69, 0.69) n=10 (0.48, 0, 0, 0, …) (0.02, 0.69, 0.69) KUR n=3 (0.02, 0, -0.01) (0.02, 0.02, 0.02) UF1 n=15 (0.92, 0, -0.07, 0, -0.07, 0, …) (-0.51, -0.11, 0, -0.12, …) DTLZ2 n=10 (-0.64, -0.64, 0.01, -0.01, …) (-0.64, 0.64, 0.01, 0.01, …) (0.94, 0, 0, 0.01, 0, …) DTLZ4 n=10 (-0.64, -0.64, 0.01, -0.01, …) (-0.64, 0.64, 0.01, 0, -0.01, …) (0.94, -0.01, 0, 0.01, 0, …)  下载: 导出CSV
下载: 导出CSV
表 2 变换前后的最近邻分类误差
Table 2 Nearest neighbor classification error before and after transformation
测试函数 按目标分类的误差均值 按目标分类的最大误差 f1 (x) f2 (x) f3 (x) f1 (x) f2 (x) f3 (x) ZDT1 原空间 0.1516 0.4302 0.5115 1.3159 变换后 0.0013 0.1725 0.0074 0.9304 ZDT3 原空间 0.0437 0.446 0.1837 1.7126 变换后 0.0011 0.3282 0.0042 1.5289 ZDT6 原空间 0.1047 0.1873 0.6864 1.8303 变换后 0.0031 0.0765 0.0454 0.4374 KUR 原空间 0.6601 5.7885 2.2948 23.423 变换后 0.2909 1.6843 1.6411 4.6841 UF1 原空间 0.1985 0.1753 0.8847 1.0659 变换后 0.0753 0.068 0.2736 0.4554 DTLZ2 原空间 0.2314 0.2368 0.2344 1.0053 0.8732 1.0964 变换后 0.0624 0.0569 0.0471 0.3102 0.1942 0.199 DTLZ4 原空间 0.2072 0.2431 0.2459 0.8283 0.7537 0.895 变换后 0.0582 0.0724 0.0488 0.2478 0.2178 0.0488
下载: 导出CSV
表 3 Pareto支配性预测的平均精度
Table 3 Average precision of Pareto dominance prediction
测试函数 方法 n Pareto支配性(%) 总体正确 非支配类 支配类 不可比类 ZDT1 DSTNN 10 92.32 81.7 88.61 96.64 ENNC 64.79 40.58 42.3 74.88 ESNNC 83.23 70.32 75.24 88.31 GP 88.76 65.55 65.55 90.21 DSTNN 30 90.85 71.2 81.51 95.2 ENNC 54.32 17.36 23.26 63.41 ESNNC 68.9 37.49 40.28 80.54 GP 73.41 32.97 32.97 84.49 ZDT3 DSTNN 3 93.13 80.47 93.14 97.19 ENNC 76.84 75.54 69.03 79.2 ESNNC 68.82 56.95 68.85 72.26 GP 57.73 54.6 54.6 59.48 DSTNN 10 83.29 71.53 77.56 88.69 ENNC 59.33 34.81 38.61 70.03 ESNNC 77.86 72.05 66.85 84.12 GP 71.1 54.2 54.2 78.56 ZDT6 DSTNN 3 95.94 89.83 95.59 99.36 ENNC 53.68 42.23 48.88 55.9 ESNNC 49.78 43.06 49.49 52.97 GP 52.96 36.92 36.92 66.89 DSTNN 10 91.43 87.77 93.58 92.33 ENNC 44.3 37.8 47.55 46.1 ESNNC 64.86 66.12 60.53 66.44 GP 48.88 47.03 47.03 50.82 DTLZ2 DSTNN 10 86.49 43.89 66.87 89.66 ENNC 54.89 17.24 17.42 58.87 ESNNC 90.92 22.68 28.41 95.31 GP 89.5 12 12 96.75 DTLZ4 DSTNN 10 85.39 50.14 74.64 88.55 ENNC 53.74 16.93 20.42 57.23 ESNNC 72.23 48.38 44.56 79.99 GP 70.87 9.51 9.51 76.65 UF1 DSTNN 10 86.14 71.9 84.17 91.64 ENNC 60.08 54.86 50.23 65.76 ESNNC 60.84 65.23 70.69 71.49 GP 57.7 61.53 61.53 51.61 KUR DSTNN 3 85.43 79.73 86.79 89.87 ENNC 46.47 53.95 56.71 34.54 ESNNC 50.73 52.88 55.39 45.02 GP 44.19 41.79 41.79 47.76
下载: 导出CSV
-
[1] 公茂果, 焦李成, 杨咚咚, 马文萍.进化多目标优化算法研究.软件学报, 2009, 20(2):271-289 doi: 10.3724/SP.J.1001.2009.00271Gong Mao-Guo, Jiao Li-Cheng, Yang Dong-Dong, Ma Wen-Ping. Research on evolutionary multi-objective optimization algorithms. Journal of Software, 2009, 20(2):271-289 doi: 10.3724/SP.J.1001.2009.00271 [2] 詹炜.求解高维多目标优化问题的流形学习算法研究[博士学位论文], 中国地质大学, 中国, 2013.Zhan Wei. Research on Manifold Learning Algorithm for High-Dimensional Multi-objective Optimization Problems[Ph.D. dissertation], China University of Geosciences, China, 2013. [3] Tesch M, Schneider J, Choset H. Expensive multiobjective optimization for robotics. In:Proceedings of the 2013 IEEE International Conference on Robotics and Automation. Karlsruhe, Germany:IEEE, 2013. 973-980 [4] Douguet D. e-LEA3D:a computational-aided drug design web server. Nucleic Acids Research, 2010, 38(Suppl 2):W615-W621 https://www.researchgate.net/publication/44575457_e-LEA3D_A_computational-aided_drug_design_web_server [5] Zhang Q F, Liu W D, Tsang E, Virginas B. Expensive multiobjective optimization by MOEA/D with Gaussian process model. IEEE Transactions on Evolutionary Computation, 2010, 14(3):456-474 doi: 10.1109/TEVC.2009.2033671 [6] Palar P S, Tsuchiya T, Parks G T. A comparative study of local search within a surrogate-assisted multi-objective memetic algorithm framework for expensive problems. Applied Soft Computing Journal, 2016, 43:1-19 doi: 10.1016/j.asoc.2015.12.039 [7] Rosales-Pérez A, Coello C A C, Gonzalez J A, Reyes-Garcia C A, Escalante H J. A hybrid surrogate-based approach for evolutionary multi-objective optimization. In:Proceedings of the 2013 IEEE Congress on Evolutionary Computation (CEC). Cancun, Mexico:IEEE, 2013. 2548-2555 [8] Akhtar T, Shoemaker C A. Multi objective optimization of computationally expensive multi-modal functions with RBF surrogates and multi-rule selection. Journal of Global Optimization, 2016, 64(1):17-32 doi: 10.1007/s10898-015-0270-y [9] Montemayor-García G, Toscano-Pulido G. A study of surrogate models for their use in multiobjective evolutionary algorithms. In:Proceedings of the 8th International Conference on Electrical Engineering Computing Science and Automatic Control (CCE). Merida, Mexico:IEEE, 2011. 1-6 [10] Guo G Q, Li W, Yang B, Li W B, Yin C. Predicting Pareto dominance in multi-objective optimization using pattern recognition. In:Proceedings of the 2nd International Conference on Intelligent System Design and Engineering Application (ISDEA). Sanya, China:IEEE, 2012. 456-459 [11] Guo G Q, Yin C, Yan T S, Li W. Nearest neighbor classification of Pareto dominance in multi-objective optimization. In:Proceedings of the 5th International Conference on Advanced Computational Intelligence (ICACI). Nanjing, China:IEEE, 2012. 328-331 [12] 郭观七, 尹呈, 曾文静, 李武, 严太山.基于等价分量交叉相似性的Pareto支配性预测.自动化学报, 2014, 40(1):33-40 http://www.aas.net.cn/CN/abstract/abstract18264.shtmlGuo Guan-Qi, Yin-Cheng, Zeng Wen-Jing, Li Wu, Yan Tai-Shan. Prediction of Pareto dominance by cross similarity of equivalent components. Acta Automatica Sinica, 2014, 40(1):33-40 http://www.aas.net.cn/CN/abstract/abstract18264.shtml [13] 陈志旺, 白锌, 杨七, 黄兴旺, 李国强.区间多目标优化中决策空间约束、支配及同序解筛选策略.自动化学报, 2015, 41(12):2115-2124 http://www.aas.net.cn/CN/abstract/abstract18784.shtmlChen Zhi-Wang, Bai Xin, Yang Qi, Huang Xing-Wang, Li Guo-Qiang. Strategy of constraint, dominance and screening solutions with same sequence in decision space for interval multi-objective optimization. Acta Automatica Sinica, 2015, 41(12):2115-2124 http://www.aas.net.cn/CN/abstract/abstract18784.shtml [14] 盛骤, 谢式千, 潘承毅.概率论与数理统计.北京:高等教育出版, 2005.Sheng Zhou, Xie Shi-Qian, Pan Cheng-Yi. Probability and Mathematical Statistics. Beijing:Higher Education Press, 2005. [15] 田作华, 陈学中, 翁正新.工程控制基础.北京:清华大学出版社, 2007.Tian Zuo-Hua, Chen Xue-Zhong, Weng Zheng-Xin. Control Engineering Construction. Beijing:Tsinghua University Press, 2007. [16] Zitzler E, Deb K, Thiele L. Comparison of multiobjective evolutionary algorithms:empirical results. Evolutionary Computation, 2000, 8(2):173-195 doi: 10.1162/106365600568202 [17] Kursawe F. A variant of evolution strategies for vector optimization. Parallel Problem Solving from Nature. Berlin:Springer, 1991. [18] Deb K, Thiele L, Laumanns M, Zitzler E. Scalable multi-objective optimization test problems. In:Proceedings of the 2002 IEEE Congress on Evolutionary Computation (CEC). Honolulu, USA:IEEE, 2002. 825-830 [19] Li H, Zhang Q F. Multiobjective optimization problems with complicated Pareto sets, MOEA/D and NSGA-II. IEEE Transactions on Evolutionary Computation, 2009, 13(2):284-302 doi: 10.1109/TEVC.2008.925798 -

 下载:
下载:

计量
- 文章访问数: 2169
- HTML全文浏览量: 292
- PDF下载量: 724
- 被引次数: 0
