

-
摘要: 提出了一种旋转与尺度不变的人身体部位所在区域的视频分割方法.方法中不仅考虑到躯干与四肢之间的关系,还考虑到四肢之间的相互关系,通过空间与时间的连续性约束对每帧中各个可能的身体部位进行优化组合,并巧妙地用动态规划对非线性图模型进行优化,且不受运动目标尺度变化与各种翻转运动的影响.该方法首先用动态规划的优化方法得到每一帧中最优的N个身体部位组合,将每一个组合作为图模型中的一个节点,并用动态规划对所有帧中的各个组合所构成的网格状图结构进行优化,最终得到每一帧中最优的身体部位组合.实验结果表明,该视频分割方法不仅适用于行人视频,还适用于具有各种姿势的运动视频,且具有较好的鲁棒性.Abstract: This paper proposes a rotation-and scale-invariant method for human body parts segmentation. The proposed method considers not only the relationship between torso and limbs but also between limbs. The method optimizes the candidate assembly of body parts in each frame with spatial and temporal constraints, and uses dynamic programming to optimize a non-linear graph model smartly, which is rotation and scale invariant. First, it generates the best N combinations of human body parts using dynamic programming, each being a node in the graph. Then it optimizes the graph which is the grid made up of all the nodes in each frame, using dynamic programming to get the optimal human body part combination in each frame. Experiments show that this method can robustly get efficient and accurate results both on pedestrian videos and sports videos with any human poses.
-
Key words:
- Video segmentation /
- rotation invariant /
- scale invariant /
- dynamic programming
1) 本文责任编委 桑农 -

图 1 “图案结构”检测结果与本方法分割结果图
Fig. 1 Detection result of "pictorial structure" method and the segmentation result of proposed method

图 2 旋转与尺度不变的视频分割方法鸟瞰图
Fig. 2 The bird-view of rotation and scale invariant video segmentation method
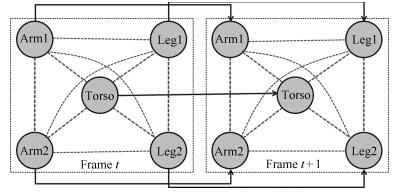
图 3 单帧内与相邻帧之间身体部位关系图
Fig. 3 Human body parts relationships in single frame and between adjacent frames

图 9 该方法与nbest方法实验结果的正确率曲线图
Fig. 9 Detection rate comparisons of nbest and proposed method
表 1 该方法和nbest方法分别与GT的比较结果
Table 1 Comparison of proposed method and GT, nbest method and GT
nbest Ours nbest Ours nbest Ours nbest Ours nbest Ours Arms Arms Legs Legs Torso Torso All All Mean Mean Video 1 13.96 % 25.90 % 45.30 % 37.37 % 24.99 % 40.31 % 45.70 % 62.45 % 32.49 % 41.51 % Video 2 12.15 % 32.49 % 24.71 % 43.87 % 42.61 % 56.41 % 38.47 % 62.43 % 29.49 % 48.80 % Video 3 12.62 % 25.00 % 42.69 % 42.99 % 45.41 % 44.03 % 48.75 % 67.98 % 37.37 % 45.00 % Video 4 22.54 % 25.93 % 44.76 % 54.29 % 51.20 % 53.81 % 50.21 % 67.77 % 42.18 % 50.45 % Video 5 22.29 % 56.10 % 65.32 % 64.17 % 49.75 % 63.18 % 62.96 % 84.58 % 50.08 % 67.01 % Mean 16.71 % 33.08 % 44.56 % 48.54 % 42.79 % 51.55 % 49.22 % 69.04 % 38.32 % 50.55 %  下载: 导出CSV
下载: 导出CSV
-
[1] Criminisi A, Cross G, Blake A, Kolmogorov V. Bilayer segmentation of live video. In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA:IEEE, 2006. 53-60 [2] Cheung S C S, Kamath C. Robust techniques for background subtraction in urban traffic video. In:Proceedings of SPIE 5308, Visual Communications and Image Processing. San Jose, USA:SPIE, 2004, 5308:881-892 [3] Hayman E, Eklundh J. Statistical background subtraction for a mobile observer. In:Proceedings of the 9th IEEE International Conference on Computer Vision. Nice, France:IEEE, 2003. 67-74 [4] Ren Y, Chua C S, Ho Y K. Statistical background modeling for non-stationary camera. Pattern Recognition Letters, 2003, 24(1-3):183-196 doi: 10.1016/S0167-8655(02)00210-6 [5] Giordano D, Murabito F, Palazzo S, Spampinato C. Superpixel-based video object segmentation using perceptual organization and location prior. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015. 4814-4822 [6] Brendel W, Todorovic S. Video object segmentation by tracking regions. In:Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 833-840 [7] Li F X, Kim T, Humayun A, Tsai D, Rehg J M. Video segmentation by tracking many figure-ground segments. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 2192-2199 [8] Varas D, Marques F. Region-based particle filter for video object segmentation. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE, 2014. 3470-3477 [9] Arbeláez P A, Pont-Tuset J, Barron J T, Marques F, Malik J. Multiscale combinatorial grouping. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE, 2014. 328-335 [10] Tsai Y H, Yang M H, Black M J. Video segmentation via object flow. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA:IEEE, 2016. [11] Ramakanth S A, Babu R V. Seamseg:video object segmentation using patch seams. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE, 2014. 376-383 [12] Faktor A, Irani M. Video segmentation by non-local consensus voting. In:Proceedings British Machine Vision Conference 2014. Nottingham:BMVA Press, 2014. [13] Papazoglou A, Ferrari V. Fast object segmentation in unconstrained video. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 1777-1784 [14] Rother C, Kolmogorov V, Blake A. "Grabcut":interactive foreground extraction using iterated graph cuts. Acm Transactions on Graphics, 2004, 23(3):309-314 doi: 10.1145/1015706 [15] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE, 2014. 580-587 [16] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick C L. Microsoft COCO:common objects in context. In:Proceedings of the 13th European Conference. Zurich, Switzerland:Springer International Publishing, 2014. 740-755 [17] Endres I, Hoiem D. Category-independent object proposals with diverse ranking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(2):222-234 doi: 10.1109/TPAMI.2013.122 [18] Krähenbühl P, Koltun V. Geodesic object proposals. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer International Publishing, 2014. 725-739 [19] Zhang D, Javed O, Shah M. Video object segmentation through spatially accurate and temporally dense extraction of primary object regions. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, Oregon, USA:IEEE, 2013. 628-635 [20] Fragkiadaki K, Arbelaez P, Felsen P, Malik J. Learning to segment moving objects in videos. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015. 4083-4090 [21] Perazzi F, Wang O, Gross M, Sorkine-Hornung A. Fully connected object proposals for video segmentation. In:Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile:IEEE, 2015. 3227-3234 [22] Kundu A, Vineet V, Koltun V. Feature space optimization for semantic video segmentation. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, Nevada, USA:IEEE, 2016. [23] Seguin G, Bojanowski P, Lajugie R, Laptev I. Instance-level video segmentation from object tracks. In:Proceeding of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, Nevada, USA:IEEE, 2016. [24] Lee Y J, Kim J, Grauman J. Key-Segments for video object segmentation. In:Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spanish:IEEE, 2011. 1995-2002 [25] Tsai D, Flagg M, Rehg J. Motion coherent tracking with multi-label MRF optimization. In:Proceedings of the British Machine Vision Conference 2010. Aberystwyth:BMVA Press, 2010. 190-202 [26] Ramanan D, Forsyth D A, Zisserman A. Tracking people by learning their appearance. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(1):65-81 doi: 10.1109/TPAMI.2007.250600 [27] Yang Y, Ramanan D. Articulated pose estimation with flexible mixtures-of-parts. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, USA:IEEE, 2011. 1385-1392 [28] Endres I, Hoiem D. Category independent object proposals. In:Proceedings of the 11th European Conference on Computer Vision. Heraklion, Crete, Greece:Springer, 2010. 575-588 [29] Ling H B, Jacobs D W. Shape classification using the innerdistance. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(2):286-299 doi: 10.1109/TPAMI.2007.41 [30] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA: IEEE, 2005. 886-893 [31] Park D, Ramanan D. N-best maximal decoders for part models. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 2627-2634 [32] Sigal L, Black M J. HumanEva: Synchronized Video and Motion Capture Dataset for Evaluation of Articulated Human Motion. Techniacl Report CS-06-08. Brown University, USA, 2006 [33] Grundmann M, Kwatra V, Han M, Essa I. Efficient hierarchical graph based video segmentation. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 2141-2148 [34] Oneata D, Revaud J, Verbeek J, Schmid C. Spatio-temporal object detection proposals. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer International Publishing, 2014. 737-752 [35] Pele O, Werman M. Fast and robust earth mover0s distance. In: Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto, Japan: IEEE, 2009. 460-467 [36] Brox T, Malik J. Large displacement optical flow: descriptor matching in variational motion estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(3): 500-513 doi: 10.1109/TPAMI.2010.143 -

 下载:
下载:






计量
- 文章访问数: 1820
- HTML全文浏览量: 319
- PDF下载量: 520
- 被引次数: 0
