

-
摘要: 研究了一类基于RSSI(Received signal strength indication)测距的分布式移动目标跟踪问题,提出了一种适用于事件触发无线传感器网络(Wireless sensor networks,WSNs)的分布式随机目标跟踪方法.首先考虑移动机器人模型的不确定性,引入了带有随机参数的过程噪声协方差,应用改进平方根容积卡尔曼滤波(Square root cubature Kalman filter,SRCKF)得到局部估计;然后采用无模型CI(Covariance intersection)融合估计方法以降低随机过程噪声协方差带来的不利影响.该方法充分利用有模型和无模型方法的优势,实现系统模型和量测不理想情况下的分布式目标跟踪.基于E-puck机器人的目标跟踪实验表明,事件触发的工作模式可有效地减少能量消耗,带随机参数的滤波方法更适合于随机目标的跟踪.
-
关键词:
- 事件触发 /
- RSSI /
- 随机目标跟踪 /
- 平方根容积卡尔曼滤波
Abstract: This paper is concerned with distributed target tracking problem using RSSI method and presents a distributed tracking method for maneuvering targets with event-triggered wireless sensor networks (WSNs). Firstly process noise covariance with random parameter is introduced under consideration of modeling uncertainties, and then a modified square root cubature Kalman filter (SRCKF) is employed to generate local estimates. Secondly, the non-model-based CI fusion estimation method is employed to reduce the adverse effects of random process noise covariance. The method combines advantages of both model-based and non-model-based estimation methods in the case of inaccurate model and unreliable measurements. Simulation and experiment of the E-puck robot tracking show that the event-triggered mechanism can greatly reduce energy consumption and that the filtering method with random parameters is more suitable for maneuvering target tracking.1) 本文责任编委 潘泉 -
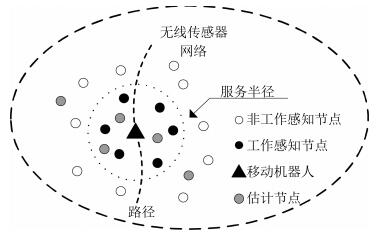
图 1 无线传感器网络环境下的分布式移动机器人跟踪系统
Fig. 1 The distributed mobile robot tracking system in WSNs
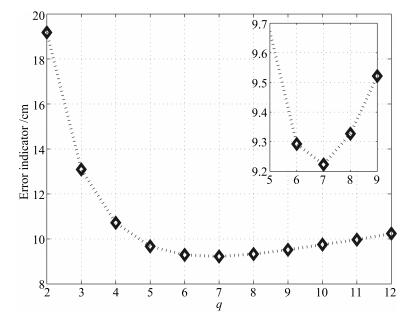
图 2 不同过程噪声协方差下的估计误差
Fig. 2 Results of the estimation errors with different process covariances

图 3 E-puck机器人目标跟踪实验平台
Fig. 3 The E-puck robot-based target tracking experiment platform
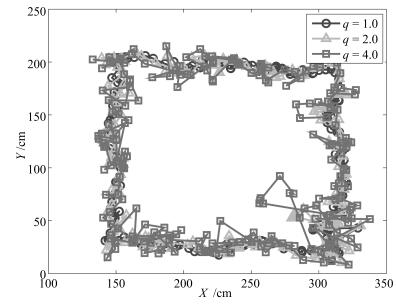
图 4 不同过程噪声协方差下的移动机器人跟踪结果
Fig. 4 Results of the mobile robot tracking with different process covariances
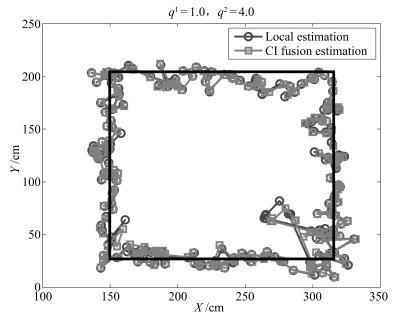
图 5 基于SRCKF的局部跟踪结果和CI融合估计结果的对比
Fig. 5 Comparison of the SRCKF-based local estimates and the CI fusion estimates of the mobile robot tracking

图 6 基于SRCKF的局部估计和CI融合估计 $X$ 轴误差对比
Fig. 6 Comparison of the SRCKF-based local estimation and the CI fusion estimation errors in the $X$ -coordinate
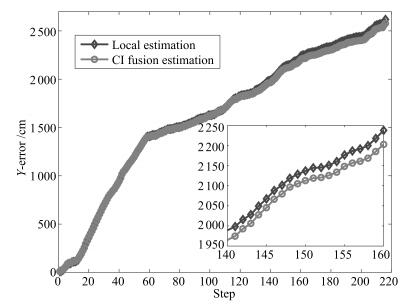
图 7 基于SRCKF的局部估计和CI融合估计 $Y$ 轴误差对比
Fig. 7 Comparison of the SRCKF-based local estimation and the CI fusion estimation errors in the $Y$ -coordinate
表 1 不同过程协方差情况下移动机器人跟踪的仿真结果
Table 1 The simulation results of the mobile robot tracking with the different process noise covariances
序号 q1 q2 局部1 局部2 局部3 平均 LCI CI 1 2.0 6.0 10.7446 10.7439 10.7589 10.7052 10.6792 10.7682 2 4.0 6.0 9.6714 9.6725 9.6676 9.6554 9.6555 9.6613 3 8.0 10.0 9.4976 9.4978 9.4981 9.4927 9.4940 9.4899 4 8.0 12.0 9.7339 9.7360 9.7365 9.7220 9.7289 9.7113 5 2.0 12.0 9.5359 9.5414 9.5236 9.3224 9.3629 9.3252 6 4.0 10.0 9.3189 9.3174 9.3135 9.2346 9.2505 9.2281 7 6.0 8.0 9.2046 9.2055 9.2082 9.1959 9.1985 9.1948  下载: 导出CSV
下载: 导出CSV
-
[1] Li X, Lille I, Falcon R, Nayak A, Stojmenovic I. Servicing wireless sensor networks by mobile robots. IEEE Communications Magazine, 2012, 50(7):147-154 doi: 10.1109/MCOM.2012.6231291 [2] Yoo J H, Kim W, Kim H J. Event-driven Gaussian process for object localization in wireless sensor networks. In:Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems. San Francisco, USA:IEEE, 2011. 2790-2795 [3] Zhang W A, Yang X S, Yu L. Sequential fusion estimation for RSS-based mobile robots localization with event-driven WSNs. IEEE Transactions on Industrial Informatics, 2016, 12(4):1519-1528 doi: 10.1109/TII.2016.2585350 [4] Chang D C, Fang M W. Bearing-only maneuvering mobile tracking with nonlinear filtering algorithms in wireless sensor networks. IEEE Systems Journal, 2014, 8(1):160-170 doi: 10.1109/JSYST.2013.2260641 [5] Zickler S, Veloso M. RSS-based relative localization and tethering for moving robots in unknown environments. In:Proceedings of the 2010 IEEE International Conference on Robotics and Automation. Anchorage, USA:IEEE, 2010. 5466 -5471 [6] Menegatti E, Zanella A, Zilli S, Zorzi F, Pagello E. Range-only slam with a mobile robot and a wireless sensor networks. In:Proceedings of the 2009 IEEE International Conference on Robotics and Automation. Kobe, Japan:IEEE, 2009. 8-14 [7] Luo Q H, Peng Y, Li J B, Peng X Y. RSSI-based localization through uncertain data mapping for wireless sensor networks. IEEE Sensors Journal, 2016, 16(9):3155-3162 doi: 10.1109/JSEN.2016.2524532 [8] 岳元龙, 左信, 罗雄麟.提高测量可靠性的多传感器数据融合有偏估计方法.自动化学报, 2014, 40(9):1843-1852 http://www.aas.net.cn/CN/abstract/abstract18453.shtmlYue Yuan-Long, Zuo Xin, Luo Xiong-Lin. Improving measurement reliability with biased estimation for multi-sensor data fusion. Acta Automatica Sinica, 2014, 40(9):1843-1852 http://www.aas.net.cn/CN/abstract/abstract18453.shtml [9] 汤文俊, 张国良, 曾静, 孙一杰, 吴晋.一种适用于稀疏无线传感器网络的改进分布式UIF算法.自动化学报, 2014, 40(11):2490-2498 http://www.aas.net.cn/CN/abstract/abstract18525.shtmlTang Wen-Jun, Zhang Guo-Liang, Zeng Jing, Sun Yi-Jie, Wu Jin. An improved distributed unscented information filter algorithm for sparse wireless sensor networks. Acta Automatica Sinica, 2014, 40(11):2490-2498 http://www.aas.net.cn/CN/abstract/abstract18525.shtml [10] 杨文, 侍洪波, 汪小帆.卡尔曼一致滤波算法综述.控制与决策, 2011, 26(4):481-488 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201104002.htmYang Wen, Shi Hong-Bo, Wang Xiao-Fan. A survey of consensus based Kalman filtering algorithm. Control and Decision, 2011, 26(4):481-488 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201104002.htm [11] Vercauteren T, Wang X D. Decentralized sigma-point information filters for target tracking in collaborative sensor networks. IEEE Transactions on Signal Processing, 2005, 53(8):2997-3009 doi: 10.1109/TSP.2005.851106 [12] Li W L, Jia Y M. Consensus-based distributed multiple model UKF for jump Markov nonlinear systems. IEEE Transactions on Automatic Control, 2012, 57(1):227-233 doi: 10.1109/TAC.2011.2161838 [13] Arasaratnam I, Haykin S. Cubature Kalman filters. IEEE Transactions on Automatic Control, 2009, 54(6):1254-1269 doi: 10.1109/TAC.2009.2019800 [14] 魏喜庆, 宋申民.无模型容积卡尔曼滤波及其应用.控制与决策, 2013, 28(5):769-773 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201305025.htmWei Xi-Qing Song Shen-Min. Model-free cubature Kalman filter and its application. Control and Decision, 2013, 28(5):769-773 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201305025.htm [15] 赵琳, 王小旭, 孙明, 丁继成, 闫超.基于极大后验估计和指数加权的自适应UKF滤波算法.自动化学报, 2010, 36(7):1007-1019 http://www.aas.net.cn/CN/abstract/abstract13751.shtmlZhao Lin, Wang Xiao-Xu, Sun Ming, Ding Ji-Cheng, Yan Chao. Adaptive UKF filtering algorithm based on maximum a posterior estimation and exponential weighting. Acta Automatica Sinica, 2010, 36(7):1007-1019 http://www.aas.net.cn/CN/abstract/abstract13751.shtml [16] 王璐, 李光春, 乔相伟, 王兆龙, 马涛.基于极大似然准则和最大期望算法的自适应UKF算法.自动化学报, 2012, 38(7):1200-1210 http://www.aas.net.cn/CN/abstract/abstract13671.shtmlWang Lu, Li Guang-Chun, Qiao Xiang-Wei, Wang Zhao-Long, Ma Tao. An adaptive UKF algorithm based on maximum likelihood principle and expectation maximization algorithm. Acta Automatica Sinica, 2012, 38(7):1200-1210 http://www.aas.net.cn/CN/abstract/abstract13671.shtml [17] Jwo D J, Wang S H. Adaptive fuzzy strong tracking extended Kalman filtering for GPS navigation. IEEE Sensors Journal, 2007, 7(5):778-789 doi: 10.1109/JSEN.2007.894148 [18] Yang X S, Zhang W A, Yu L, Xing K X. Multi-rate distributed fusion estimation for sensor network-based target tracking. IEEE Sensors Journal, 2016, 16(5):1233-1242 doi: 10.1109/JSEN.2015.2497464 [19] Zhang W A, Chen B, Chen M. Hierarchical fusion estimation for clustered asynchronous sensor networks. IEEE Transactions on Automatic Control, 2016, 61(10):3064-3069 doi: 10.1109/TAC.2015.2498701 [20] Deng Z L, Zhang P, Qi W J, Yuan G, Liu J F. The accuracy comparison of multisensor covariance intersection fuser and three weighting fusers. Information Fusion, 2013, 14(2):177 -185 doi: 10.1016/j.inffus.2012.05.005 [21] Bolognani S, Tubiana L, Zigliotto M. Extended Kalman filter tuning in sensorless PMSM drives. IEEE Transactions on Industry Applications, 2003, 39(6):1741-1747 doi: 10.1109/TIA.2003.818991 [22] Uhlmann J K. Covariance consistency methods for fault-tolerant distributed data fusion. Information Fusion, 2003, 4(3):201-215 doi: 10.1016/S1566-2535(03)00036-8 -

 下载:
下载:

计量
- 文章访问数: 2201
- HTML全文浏览量: 325
- PDF下载量: 888
- 被引次数: 0
