

Combination of Statistical and Rule-based Approaches for Uyghur Person Name Recognition
-
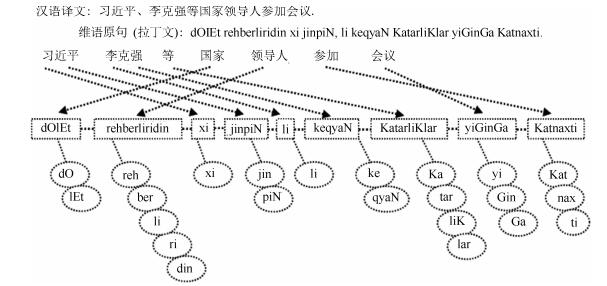
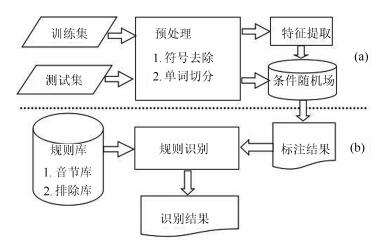
摘要: 命名实体识别(Named entity recognition,NER)是自然语言处理(Natural language processing,NLP)中重要的任务,其中人名实体是主要的识别对象之一.本文从维吾尔语黏着性特点出发,从词干、音节、字符串三个角度对维吾尔语单词进行拆分,获得更小的语言单元,并把切分的新单元作为特征加入到条件随机场(Conditional random field,CRF)中,明显缓解了数据稀疏的影响,取得了比以单词为基本单元的人名识别方法更好的性能.同时还从维吾尔语中汉族人名的特点出发,提出了基于规则的维吾尔语中汉族人名的识别方法,最终利用统计和规则相结合的方法进一步提高了识别的准确率.实验结果表明,该方法人名识别的准确率、召回率和F1值分别达到了87.47%、89.12%和88.29%.Abstract: Named entity recognition (NER) is an important subtask of natural language processing, where person name is one of the major objects. From agglutinative characteristics of the Uyghur language, we split a Uygur word into different level units such as syllable, suffix, stem, etc., so as to significantly reduce the data sparse problem. Since the Han people name is the major remaining errors for the CRF (Conditional random field)-based approach, we also propose a rule-based post-processing approach for Han people name recognition in Uyghur language. Experimental results show that this cascade approach achieves satisfactory performance, and that the recognition accuracy, recall rate and F1 score are 87.47%、89.12% and 88.29%, respectively.1) 本文责任编委 赵铁军
-
表 1 人名词的音节拆分
Table 1 Syllable segmentation of person name
人名原形 音节拆分形式 abduweli (阿布都外力) ab+du+we+li abduqadir (阿不都卡迪尔) ab+du+qa+dir abdusalam (阿不都萨拉姆) ab+du+sa+lam abduraxman (阿布都热合曼) ab+du+rax+man dilmurat (迪里木拉提) dil+mu+rat xalmurat (哈里木拉提) xal+mu+rat  下载: 导出CSV
下载: 导出CSV
表 2 人名用词字符串特点
Table 2 String characters of person name
单词样例 imameli hezirtieli mireli mireli aygül ayshem aynur ayishe aynigar ayimgül ayimnisa mihray gülmire gülire munire almire dilmire semire nadire sebire nurbiye zülpiye gülpiye süriye
下载: 导出CSV
表 3 汉族人名词的字符串特点
Table 3 String characters of Chinese person name
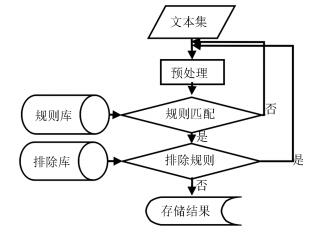
单词样例 shijinping (习近平) dengshyoping (邓小平) liping (李平) xuanggwoping (黄国平) dengyaping (邓亚萍) maping (马平) lyuyang (刘洋) lyudexua (刘德华) lyulu (刘璐)
下载: 导出CSV
表 4 CRF格式数据
Table 4 CRF format data
Word features tag mEmtimin mEm min mEmti timin 0 0 mEmtimin 0 1 mE in mEm min mEmt imin B-PER yvsvp yv svp 0 0 0 0 yvsvp 0 0 yv vp yvs svp yvsv vsvp I-PER bilEn bi lEn 0 0 0 0 bilEn 0 0 bi En bil lEn bilE ilEn O abdureHim ab Him abdu reHim abdure dureHim abdureHim 0 1 ab im abd Him abdu eHim B-PER Otkvr Ot kvr 0 0 0 0 Otkvr 0 0 Ot vr Otk kvr Otkv tkvr I-PER amerikiGa a Ga ame kiGa ameri rikiGa amerika Ga 0 am Ga amr iGa amer kiGa O bardi bar di 0 0 0 0 bar di 0 ba di bar rdi bard ardi O
下载: 导出CSV
表 5 特征及描述符
Table 5 Template and descriptor
特征 描述符 当前词 [W]0 当前词的前一词 [W]-1 当前词的后一词 [W]1 当前词的词典特征值 [Dic]0 当前词的词干、后缀 [Stem]0、[Su–x]0 当前词前一词的词干、后缀 [Stem]-1、[Su–x]-1 当前词后一词的词干、后缀 [Stem]1、[Su–x]1 当前词的音节特征 [S1]0, [SN]0, [S1S2]0, [SN-1SN]0, [S1S2S3]0, [SN-2SN-1SN]0 当前词前一词的音节特征 [S1]-1, [SN]-1, [S1S2]-1, [SN-1SN]-1, [S1S2S3]-1, [SN-2SN-1SN]-1 当前词后一词的音节特征 [S1]1, [SN]1, [S1S2]1, [SN-1SN]1, [S1S2S3]1, [SN-2SN-1SN]1 当前词的字符串特征 [C1C2]0, [CM-1CM]0, [C1C2C3]0, [CM-2CM-1CM]0, [C1C2C3C4]0, [CM-3CM-2CM-1CM]0, [C1C2C3C4C5]0, [CM-4CM-3CM-2CM-1CM]0 当前词前一词的字符串特征 [C1C2]-1, [CM-1CM]-1, [C1C2C3]-1, [CM-2CM-1CM]-1, [C1C2C3C4]-1, [CM-3CM-2CM-1CM]-1, [C1C2C3C4C5]-1, [CM-4CM-3CM-2CM-1CM]-1 当前词后一个词的字符串特征 [C1C2]1, [CM-1CM]1, [C1C2C3]1, [CM-2CM-1CM]1, [C1C2C3C4]1, [CM-3CM-2CM-1CM]1, [C1C2C3C4C5]1, [C1C2C3C4C5]1, [CM-4CM-3CM-2CM-1CM]1
下载: 导出CSV
表 6 上下文单词窗口确定实验
Table 6 Context window experiment
窗口长度 准确率 (%) 召回率 (%) F 1值 (%) [W]-1, [W]0, [W]1 93.70 55.85 69.98 [W]-2, [W]-1, [W]0, [W]1, [W]2 94.28 53.42 68.21 [W]-3, [W]-2, [W]-1, [W]0, [W]1, [W]2, [W]3 94.23 5.19 65.49
下载: 导出CSV
表 7 词典类型确定实验
Table 7 Experiment of dictionary selection
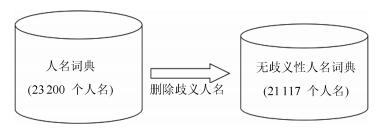
词典类型 准确率 (%) 召回率 (%) F 1值 (%) 人名词典 (全集) 46.23 30.82 36.98 无歧义性人名词典 97.52 28.25 43.80
下载: 导出CSV
表 8 对比实验
Table 8 Comparative experiment
实验名称 特征模板 实验1 [W]$_{-1}$, [W]$_{0}$, [W]$_{1}$ 实验2 [W]$_{-1}$, [W]$_{0}$, [W]$_{1}$, [Dic]$_{0}$ 实验3 [W]$_{-1}$, [W]$_{0}$, [W]$_{1}$, [Stem]$_{-1}$, [Suffix]$_{-1}$, [Stem]$_{0}$, [Suffix]$_{0}$, [Stem]$_{1}$, [Suffix]$_{1}$ 实验4 [W]$_{-1}$, [W]$_{0}$, [W]$_{1}$, [S$_{1}$]$_{0}$, [S$_{N}$]$_{0}$, [S$_{1}$S$_{2}$]$_{0}$, [S$_{N-1}$S$_{N}$]$_{0}$, [S$_{1}$S$_{2}$S$_{3}$]$_{0}$, [S$_{N-2}$S$_{N-1}$S$_{N}$]$_{0}$ 实验5 [W]$_{-1}$, [W]$_{0}$, [W]$_{1}$, [C$_{1}$C$_{2}$]$_{0}$, [C$_{M-1}$C$_{M}$]$_{0}$, [C$_{1}$C$_{2}$C$_{3}$]$_{0}$, [C$_{M-2}$C$_{M-1}$C$_{M}$]$_{0}$, [C$_{1}$C$_{2}$C$_{3}$C$_{4}$]$_{0}$, [C$_{M-3}$C$_{M-2}$C$_{M-1}$C$_{M}$]$_{0}$, [C$_{1}$C$_{2}$C$_{3}$C$_{4}$C$_{5}$]$_{0}$, [C$_{M-4}$C$_{M-3}$C$_{M-2}$C$_{M-1}$C$_{M}$]$_{0}$ 实验6 [W]$_{-1}$, [W]$_{0}$, [W]$_{1}$, [Dic]$_{0}$, [Stem]$_{-1}$, [Suffix]$_{-1}$, [Stem]$_{0}$[Suffix]$_{0}$, [Stem]$_{1}$[Suffix]$_{1}$, [S$_{1}$]$_{-1}$, [S$_{N}$]$_{-1}$, [S$_{1}$S$_{2}$]$_{-1}$, [S$_{N-1}$S$_{N}$]$_{-1}$, [S$_{1}$S$_{2}$S$_{3}$]$_{-1}$, [S$_{N-2}$S$_{N-1}$S$_{N}$]$_{-1}$, [S$_{1}$]$_{0}$, [S$_{N}$]$_{0}$, [S$_{1}$S$_{2}$]$_{0}$, [S$_{N-1}$S$_{N}$]$_{0}$, [S$_{1}$S$_{2}$S$_{3}$]$_{0}$, [S$_{N-2}$S$_{N-1}$S$_{N}$]$_{0}$, [S$_{1}$]$_{1}$, [S$_{N}$]$_{1}$, [S$_{1}$S$_{2}$]$_{1}$, [S$_{N-1}$S$_{N}$]$_{1}$, [S$_{1}$S$_{2}$S$_{3}$]$_{1}$, [S$_{N-2}$S$_{N-1}$S$_{N}$]$_{1}$, [C$_{1}$C$_{2}$]$_{-1}$, [C$_{M-1}$C$_{M}$]$_{-1}$, [C$_{1}$C$_{2}$C$_{3}$]$_{-1}$, [C$_{M-2}$C$_{M-1}$C$_{M}$]$_{-1}$, [C$_{1}$C$_{2}$C$_{3}$C$_{4}$]$_{-1}$, [C$_{M-3}$C$_{M-2}$C$_{M-1}$C$_{M}$]$_{-1}$, [C$_{1}$C$_{2}$C$_{3}$C$_{4}$C$_{5}$]$_{-1}$, [C$_{M-4}$C$_{M-3}$C$_{M-2}$C$_{M-1}$C$_{M}$]$_{-1}$, [C$_{1}$C$_{2}$]$_{0}$, [C$_{M-1}$C$_{M}$]$_{0}$, [C$_{1}$C$_{2}$C$_{3}$]$_{0}$, [C$_{M-2}$C$_{M-1}$C$_{M}$]$_{0}$, [C$_{1}$C$_{2}$C$_{3}$C$_{4}$]$_{0}$, [C$_{M-3}$C$_{M-2}$C$_{M-1}$C$_{M}$]$_{0}$, [C$_{1}$C$_{2}$C$_{3}$C$_{4}$C$_{5}$]$_{0}$, [C$_{M-4}$C$_{M-3}$C$_{M-2}$C$_{M-1}$C$_{M}$]$_{0}$, [C$_{1}$C$_{2}$]$_{1}$, [C$_{M-1}$C$_{M}$]$_{1}$, [C$_{1}$C$_{2}$C$_{3}$]$_{1}$, [C$_{M-2}$C$_{M-1}$C$_{M}$]$_{1}$, [C$_{1}$C$_{2}$C$_{3}$C$_{4}$]$_{1}$, [C$_{M-3}$C$_{M-2}$C$_{M-1}$C$_{M}$]$_{1}$, [C$_{1}$C$_{2}$C$_{3}$C$_{4}$C$_{5}$]$_{1}$, [C$_{M-4}$C$_{M-3}$C$_{M-2}$C$_{M-1}$C$_{M}$]$_{1}$
下载: 导出CSV
表 9 最佳模板确定实验
Table 9 Experiment of best template selection
实验名称 准确率 (%) 召回率 (%) F1值 (%) 实验1 93.70 55.85 69.98 实验2 92.30 62.22 74.33 实验3 94.02 66.53 77.92 实验4 93.70 71.57 81.16 实验5 92.56 73.46 81.91 实验6 87.37 79.05 83.00
下载: 导出CSV
表 10 对比实验
Table 10 Comparative experiment
实验名称 准确率 (%) 召回率 (%) F1值 (%) 基线系统 93.20 72.47 81.54 本文最佳模版 87.37 79.05 83.00
下载: 导出CSV
表 11 维吾尔语中汉语借词音节类别
Table 11 Chinese loanword syllable category in Uyghur
实验名称 拉丁维文 音节格式 拉丁维文 CV xi (习) CVVC guaN (广) VC En (安) CCVC qyaN (强) CVC svn (孙) CVV hua (华) V a (阿)
下载: 导出CSV
表 12 改进前和改进后的切分结果对比
Table 12 Comparison of syllable segmentation
汉语借词 已有切分规则 改进后的切分规则 likeqyaN (李克强) li+keq+yaN li+ke+qyaN lixyawloN (李小龙) lix+yaw+loN li+xyaw+loN goboxyoN (郭伯雄) go+box+yoN go+bo+xyoN jaNdejyaN (张德江) jaN+dej+yaN jaN+de+jyaN xvbyaw (徐彪) xvb+yaw xv+byaw jujyelvn (周杰伦) juj+ye+lvn ju+jye+lvn
下载: 导出CSV
表 13 基于拼音转换的汉语姓氏音节库部分示例
Table 13 Samples of Chinese surname in Uyghur Latin version
汉字-拼音-拉丁维文 汉字-拼音-拉丁维文 王, 汪wang waN 何, 贺he he 韦, 卫wei wey 江, 蒋, 姜jiang jyaN 俞, 于yu yv 李, 黎li li 张, 章zhang jaN 文, 温wen wen
下载: 导出CSV
表 14 基于拼音转换的汉族人名音节库部分示例
Table 14 Samples of Chinese lastname syllables in Uyghur Latin version
汉字-拼音-拉丁维文 汉字-拼音-拉丁维文 平, 萍ping piN 辉, 惠hui hvy 玉, 宇yu yv 晓, 潇xiao xyaw 晶, 静jing jiN 亮, 良liang lyaN
下载: 导出CSV
表 15 汉族人名后缀库部分示例
Table 15 Suffix of Chinese person name
单词缀 释义 复合词缀 释义 niN 的 niNkidEk (niN+ki+dEk) 像XX的 ni 把 nimu (ni+mu) 把XX也 mu 从 dEkla (dEk+la) 像XX一样
下载: 导出CSV
表 16 对比实验
Table 16 Comparative experiment
实验名称 释义 实验1 基于汉语音译音节库的规则匹配 实验2 在实验1的基础上添加基于地名和机构名尾部的排除规则进行错误消除 实验3 在实验1的基础上添加汉语音译地名库的排除规则进行错误消除 实验4 在实验1的基础上添加基于维吾尔语生语料的排除规则来进行错误消除 实验5 将以上实验全部叠加的结果
下载: 导出CSV
表 17 实验结果
Table 17 Experiment result
实验名称 准确率 (%) 召回率 (%) F1值 (%) 实验1 73.25 97.34 83.59 实验2 75.89 97.32 85.28 实验3 89.60 97.06 93.18 实验4 93.64 95.79 94.70 实验5 97.63 98.08 97.86
下载: 导出CSV
表 18 汉族人名识别结果
Table 18 Experimental result of Chinese person name
实验类别 准确率 (%) 召回率 (%) F1值 (%) CRF 91.37 73.05 81.19 规则 (最佳结果) 97.63 98.08 97.86
下载: 导出CSV
表 19 联合实验结果
Table 19 Combined result of experiment
实验类别 准确率 (%) 召回率 (%) F1值 (%) CRF 87.37 79.05 83.00 CRF+规则 87.47 89.12 88.29
下载: 导出CSV
表 20 交叉验证实验
Table 20 Cross-validation
实验名称 准确率 (%) 召回率 (%) F 1值 (%) 1(W1 = 1 493) 87.11 78.10 82.34 2(W2 = 1 707) 86.98 78.04 82.25 3(W3 = 1 616) 86.55 75.84 80.84 4(W4 = 2 173) 87.32 75.04 80.72 5(W5 = 1 669) 87.37 79.05 83.00
下载: 导出CSV
-
[1] 宗成庆.统计自然语言处理.第2版.北京:清华大学出版社, 2013. 150-164 http://www.cnki.com.cn/Article/CJFDTOTAL-SYQY201603027.htmZong Cheng-Qing. Statistical Natural Language Processing (Second edition). Beijing:Tsinghua University Press, 2013. 150-164 http://www.cnki.com.cn/Article/CJFDTOTAL-SYQY201603027.htm [2] Hanisch D, Fundel K, Mevissen H T, Zimmer R, Fluck J. ProMiner:rule-based protein and gene entity recognition. BMC Bioinformatics, 2005, 6(S):S14 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.279.420 [3] Farmakiotou D, Karkaletsis V, Koutsias J, Sigletos G, Spyropoulos C D, Stamatopoulos P. Rule-based named entity recognition for Greek financial texts. In:Proceedings of the 2000 Workshop on Computational lexicography and Multimedia Dictionaries. Athens, Greece:COMLEX, 2000. 75-78 [4] Zhou G D, Su J. Named entity recognition using an HMM-based chunk tagger. In:Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia:Association for Computational Linguistics. Philadelphia, USA:ACL, 2002. 473-480 [5] 曹波, 苏一丹, 邓琦.基于最大熵模型的中国人名自动识别.计算机工程与应用, 2009, 45(4):227-228, 234 http://www.cnki.com.cn/Article/CJFDTOTAL-JSGG200904066.htmCao Bo, Su Yi-Dan, Deng Qi. Automatic recognition of Chinese name based on maximum entropy. Computer Engineering and Applications, 2009, 45(4):227-228, 234 http://www.cnki.com.cn/Article/CJFDTOTAL-JSGG200904066.htm [6] 李珩, 朱靖波, 姚天顺.基于SVM的中文组块分析.中文信息学报, 2004, 18(2):1-7 http://cdmd.cnki.com.cn/Article/CDMD-10141-2006022041.htmLi Heng, Zhu Jing-Bo, Yao Tian-Shun. SVM based Chinese text chunking. Journal of Chinese Information Processing, 2004, 18(2):1-7 http://cdmd.cnki.com.cn/Article/CDMD-10141-2006022041.htm [7] 艾斯卡尔·肉孜, 宗成庆, 姑丽加玛丽·麦麦提艾力, 热合木·马合木提, 艾斯卡尔·艾木都拉.基于条件随机场的维吾尔人名识别方法.清华大学学报 (自然科学版), 2013, 53(6):873-877 http://cdmd.cnki.com.cn/Article/CDMD-10755-1013235428.htmAskar Rozi, Zong Cheng-Qing, Guljamal Mamateli, Rehim Mahmut, Askar Hamdulla. Approach to recognizing Uyhgur names based on conditional random fields. Journal of Tsinghua University (Science and Technology), 2013, 53(6):873-877 http://cdmd.cnki.com.cn/Article/CDMD-10755-1013235428.htm [8] 李佳正, 刘凯, 麦热哈巴·艾力, 吕雅娟, 刘群, 吐尔根·依布拉音.维吾尔语中汉族人名的识别及翻译.中文信息学报, 2013, 25(4):82-87 http://www.cnki.com.cn/Article/CJFDTOTAL-MESS201104018.htmLi Jia-Zheng, Liu Kai, Maierheba Aili, Lv Ya-Juan, Liu Qun, Tuergen Yibulayin. Recognition and translation for Chinese names in Uighur language. Journal of Chinese Information Processing, 2013, 25(4):82-87 http://www.cnki.com.cn/Article/CJFDTOTAL-MESS201104018.htm [9] Le J, Niu Z D. Chinese named entity recognition using improved bi-gram model based on dynamic programming. Knowledge Engineering and Management. Berlin:Beijing, China:Springer-Heidelberg, 2014. 441-451 [10] 加日拉·买买提热衣木, 吐尔根·依布拉音, 艾山·吾买尔.基于统计和规则混合策略的维吾尔人名识别研究.新疆大学学报 (自然科学版), 2014, (3):319-324 http://cdmd.cnki.com.cn/Article/CDMD-10755-1014383790.htmJarulla Muhammad, Turgun Ibrahim, Hasan Omar. Research of Uyghur person names recognition based on statistics and rules. Journal of Xinjiang University (Natural Science Edition), 2014, (3):319-324 http://cdmd.cnki.com.cn/Article/CDMD-10755-1014383790.htm [11] 刘杰.基于规则和统计相结合的地名实体识别的研究.佳木斯大学学报 (自然科学版), 2009, 28(4):520-522 http://www.cnki.com.cn/Article/CJFDTOTAL-JMDB200904012.htmLiu Jie. Research on the recognition of geographical names based on rules and statistics. Journal of Jiamusi University (Natural Science Edition), 2009, 28(4):520-522 http://www.cnki.com.cn/Article/CJFDTOTAL-JMDB200904012.htm [12] 阿布都鲁甫·塔克拉玛干尼.维吾尔语词汇学与研究.北京:民族出版社, 2011. 15-22 http://www.cnki.com.cn/Article/CJFDTOTAL-SYQY201603027.htmAbudulufu Takelamaganni. Research on the Lexicology in Uighur Language. Beijing:The Ethnic Publishing House, 2011. 15-22 http://www.cnki.com.cn/Article/CJFDTOTAL-SYQY201603027.htm [13] Ablimit M, Eli M, Kawahara T. Partly supervised Uighur morpheme segmentation. In:Oriental-COCOSDA Workshop, Kyoto, Japan:ATR, 2008. 71-76 [14] 米成刚, 杨雅婷, 周喜, 李晓, 杨明忠.基于字符串相似度的维吾尔语中汉语借词识别.中文信息学报, 2013, 27(5):173-178 http://www.cnki.com.cn/Article/CJFDTOTAL-MESS201305025.htmMi Cheng-Gang, Yang Ya-Ting, Zhou Xi, Li Xiao, Yang Ming-Zhong. Recognition of Chinese Loan words in Uyghur based on string similarity. Journal of Chinese Information Processing, 2013, 27(5):173-178 http://www.cnki.com.cn/Article/CJFDTOTAL-MESS201305025.htm -

 下载:
下载:



计量
- 文章访问数: 3466
- HTML全文浏览量: 910
- PDF下载量: 734
- 被引次数: 0
