

A Fast Sparse Algorithm for Least Squares Support Vector Machine Based on Global Representative Points
-
摘要: 非稀疏性是最小二乘支持向量机(Least squares support vector machine,LS-SVM)的主要不足,因此稀疏化是LS-SVM研究的重要内容.在目前LS-SVM稀疏化研究中,多数算法采用的是基于迭代选择的稀疏化策略,但是时间复杂度和稀疏化效果还不够理想.为了进一步改进LS-SVM稀疏化方法的性能,文中提出了一种基于全局代表点选择的快速LS-SVM稀疏化算法(Global-representation-based sparse least squares support vector machine,GRS-LSSVM).在综合考虑数据局部密度和全局离散度的基础上,给出了数据全局代表性指标来评估每个数据的全局代表性.利用该指标,在全部数据中,一次性地选择出其中最具有全局代表性的数据并构成稀疏化后的支持向量集,然后在此基础上求解决策超平面,是该算法的基本思路.该算法对LS-SVM的非迭代稀疏化研究进行了有益的探索.通过与传统的迭代稀疏化方法进行比较,实验表明GRS-LSSVM具有稀疏度高、稳定性好、计算复杂度低的优点.Abstract: For lack of sparseness on least squares support vector machine (LS-SVM), the study on sparsity of LS-SVM is an important topic. Currently, most of the sparse LS-SVM methods are based on the iteration selection strategy. Consequently, they do not perform well in computation complexity and sparsity. To improve the performance of sparse LS-SVM method, a fast method, global-representation-based sparse least squares support vector machine (GRS-LSSVM), is proposed based on the selection of global representative points in this paper. To evaluate datum's representation, an index is given based on local density and global discrete degree. In the algorithm, firstly, the top global representative data are selected from all data in one step using the index to construct the support vector set of sparse LS-SVM, and then the set is used to compute the decision hyperplane of sparse LS-SVM. This algorithm explores the non-iteration on sparse LS-SVM. Experimental results show that the proposed method has higher sparseness degree, more stability, and lower computational complexity than the traditional iteration algorithms.
-
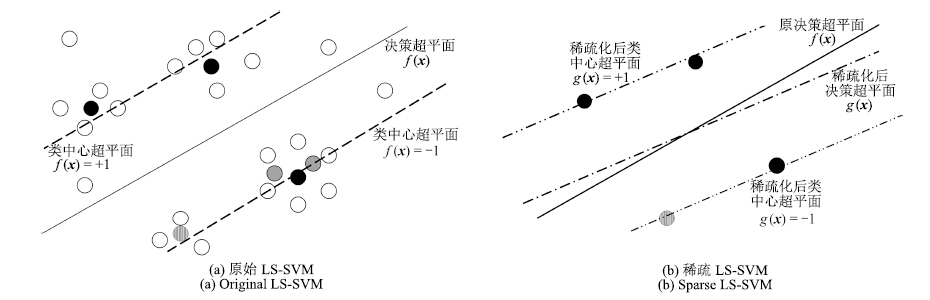
图 1 稀疏化LS-SVM的支持向量选择示意图
Fig. 1 Description of support vector selection of sparse LS-SVM
表 1 数据集描述表
Table 1 Description of datasets
数据集名称 数据量 数据维度 两类比例 Breast cancer wisconsin (BCW) 684 9 445 : 239 Banknote authentication (BA) 1 372 4 610 : 762 Musk (MK) 7 074 166 1 224 : 5 850 Letter recognition (LR) 20 000 16 789 : 19 211  下载: 导出CSV
下载: 导出CSV
表 2 SVM和LS-SVM结果
Table 2 Results of SVM and LS-SVM
数据集 SVM LS-SVM Error ratio (%) Time (s) NS Error ratio (%) Time (s) NS BCW 3.0 (±0.01) 0.02 (±0.005) 93.2 (±0.85) 3.0 (±0.010) 0.020 (±0.001) 500 (±0) BA 2.4 (±0.01) 0.09 (±0.005) 418.8 (±1.96) 1.0 (±0.010) 0.072 (±0.007) 1 000 (±0) MK 5.7 (±0.04) 0.30 (±0.010) 642.2 (±6.40) 5.1 (±0.100) 0.380 (±0.020) 2 000 (±0) LR 1.0 (±0.04) 1.32 (±0.050) 1706.0 (±79.0) 1.0 (±0.035) 1.780 (±0.050) 4 000 (±0)
下载: 导出CSV
-
[1] Han J W, Kamber M, Pei J. Data Mining:Concepts and Techniques (Third edition). San Francisco:Morgan Kaufmann, 2011. 327-330 [2] Vapnik V N. Statistical Learning Theory. New York:Wiley, 1998. 421-426 [3] Theodoridis S, Koutroumbas K. Pattern Recognition (Forth edition). San Diego:Academic Press, 2008. 81-90 [4] Suykens J A K, Vandewalle J. Least squares support vector machine classifiers. Neural Processing Letters, 1999, 9(3):293-300 doi: 10.1023/A:1018628609742 [5] van Gestel T, Suykens J A K, Baesens B, Viaene S, Vanthienen J, Dedene G, de Moor B, Vandewalle J. Benchmarking least squares support vector machine classifiers. Machine Learning, 2004, 54(1):5-32 doi: 10.1023/B:MACH.0000008082.80494.e0 [6] Suykens J A K, Lukas L, Vandewalle J. Sparse approximation using least squares support vector machines. In:Proceedings of the 2000 IEEE International Symposium on Circuits and Systems. Geneva, Switzerland:IEEE, 2000. 757-760 [7] Suykens J A K, De Brabanter J, Lukas L, Vandewalle J. Weighted least squares support vector machines:robustness and sparse approximation. Neurocomputing, 2002, 48(1-4):85-105 doi: 10.1016/S0925-2312(01)00644-0 [8] de Kruif B J, de Vries T J A. Pruning error minimization in least squares support vector machines. IEEE Transactions on Neural Networks, 2003, 14(3):696-702 doi: 10.1109/TNN.2003.810597 [9] Hoegaerts L, Suykens J A K, Vandewalle J, de Moor B. A comparison of pruning algorithms for sparse least squares support vector machines. In:Proceedings of the 11th International Conference on Neural Information Processing:Springer. Calcutta, India, 2004. 1247-1253 [10] Zeng X Y, Chen X W. SMO-based pruning methods for sparse least squares support vector machines. IEEE Transactions on Neural Networks, 2005, 16(6):1541-1546 doi: 10.1109/TNN.2005.852239 [11] Carvalho B P R, Braga A P. IP-LSSVM:a two-step sparse classifier. Pattern Recognition Letters, 2009, 30(16):1507-1515 doi: 10.1016/j.patrec.2009.07.022 [12] 12 de Brabanter K, de Brabanter J, Suykens J A K, de Moor B. Optimized fixed-size kernel models for large data sets. Computational Statistics and Data Analysis, 2010, 54(6):1484-1504 [13] Karsmakers P, Pelckmans K, de Brabanter K, van Hamme H, Suykens J A K. Sparse conjugate directions pursuit with application to fixed-size kernel models. Machine Learning, 2011, 85(1-2):109-148 doi: 10.1007/s10994-011-5253-8 [14] López J, De Brabanter K, Dorronsoro J R, Suykens J A K. Sparse LS-SVMs with L0-norm minimization. In:Proceedings of the 19th European Symposium on Artificial Neural Networks. Bruges, Belgium, 2011. 189-194 [15] Huang K Z, Zheng D N, Sun J, Hotta Y, Fujimoto K, Naoi S. Sparse learning for support vector classification. Pattern Recognition Letters, 2010, 31(13):1944-1951 doi: 10.1016/j.patrec.2010.06.017 [16] Liu J L, Li J P, Xu W X, Shi Y. A weighted L_q adaptive least squares support vector machine classifiers——robust and sparse approximation. Expert Systems with Applications, 2011, 38(3):2253-2259 doi: 10.1016/j.eswa.2010.08.013 [17] Wei L W, Chen Z Y, Li J P. Evolution strategies based adaptive L_p LS-SVM. Information Sciences, 2011, 181(14):3000-3016 doi: 10.1016/j.ins.2011.02.029 [18] Jiao L C, Bo L F, Wang L. Fast sparse approximation for least squares support vector machine. IEEE Transactions on Neural Networks, 2007, 18(3):685-697 doi: 10.1109/TNN.2006.889500 [19] Zhao Y P, Sun J G. Recursive reduced least squares support vector regression. Pattern Recognition, 2009, 42(5):837-842 doi: 10.1016/j.patcog.2008.09.028 [20] Yang X W, Lu J, Zhang G Q. Adaptive pruning algorithm for least squares support vector machine classifier. Soft Computing, 2010, 14(7):667-680 doi: 10.1007/s00500-009-0434-0 [21] Zhao Y P, Sun J G, Du Z H, Zhang Z A, Zhang Y C, Zhang H B. An improved recursive reduced least squares support vector regression. Neurocomputing, 2012, 87:1-9 doi: 10.1016/j.neucom.2012.01.015 [22] Yang J, Bouzerdoum A, Phung S L. A training algorithm for sparse LS-SVM using compressive sampling. In:Proceedings of the 2010 International Conference on Acoustics, Speech and Signal Processing. Dallas, Texas, USA:IEEE, 2010. 2054-2057 [23] Yang L X, Yang S Y, Zhang R, Jin H H. Sparse least square support vector machine via coupled compressive pruning. Neurocomputing, 2014, 131:77-86 doi: 10.1016/j.neucom.2013.10.038 [24] Rodriguez A, Laio A. Clustering by fast search and find of density peaks. Science, 2014, 344(6191):1492-1496 doi: 10.1126/science.1242072 -

 下载:
下载:






图(6) / 表(2)
计量
- 文章访问数: 2247
- HTML全文浏览量: 247
- PDF下载量: 1440
- 被引次数: 0
