

A Single-channel Speech Enhancement Approach Based on Perceptual Masking Deep Neural Network
-
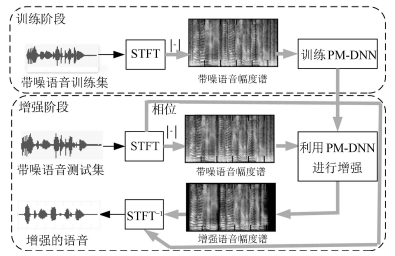
摘要: 本文将心理声学掩蔽特性应用于基于深度神经网络(Deep neural network,DNN)的单通道语音增强任务中,提出了一种具有感知掩蔽特性的DNN结构.首先,提出的DNN对带噪语音幅度谱特征进行训练并分别得到纯净语音和噪声的幅度谱估计.其次,利用估计的纯净语音幅度谱计算噪声掩蔽阈值.然后,将噪声掩蔽阈值和估计的噪声幅度谱联合计算得到一个感知增益函数.最后,利用感知增益函数从带噪语音幅度谱中估计出增强语音幅度谱.在TIMIT数据库上,对不同信噪比下的20种噪声进行的仿真实验表明,无论噪声类型是否在语音的训练集中出现,所提出的感知掩蔽DNN都能够在有效去除噪声的同时保持较小的语音失真,增强效果明显优于常见的DNN增强方法以及NMF(Nonnegative matrix factorization)增强方法.Abstract: A new deep neural network (DNN) is proposed for single-channel speech enhancement, which incorporates the perceptual masking properties of psychoacoustic models. Firstly, the proposed DNN is trained to learn both the clean speech magnitude spectrum and the noise magnitude spectrum from the noisy magnitude spectrum. Secondly, the estimated clean speech magnitude spectrum is used to calculate the noise masking threshold. Then, the noise masking threshold and the estimated noise magnitude spectrum are combined to calculate a perceptual gain function. Finally, the enhanced speech magnitude spectrum are obtained by jointly training the perceptual gain function and the noisy speech magnitude spectrum. Experimental results on TIMIT with 20 noise types at various SNR (signal-noise ratio) levels demonstrate that the proposed perceptual masking DNN can effectively remove the noise while maintaining small speech distortion, so as to obtain better performance than the common DNN methods and the NMF (nonnegative matrix factorization) method, no matter noise conditions are included in the training set or not.
-
Key words:
- Speech enhancement /
- deep neural network /
- perceptual gain function /
- masking threshold
1) 本文责任编委 柯登峰 -
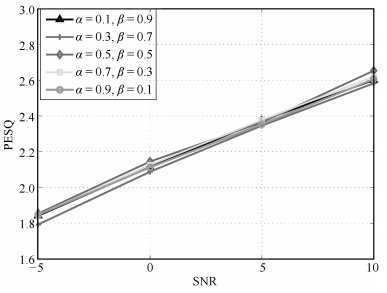
图 4 PM-DNN目标函数中的权重$\alpha$和$\beta$对20种噪声的PESQ均值影响
Fig. 4 The PESQ scores of PM-DNN objective function with different $\alpha$ and $\beta$ (For each condition, the numbers are the mean values over all the 20 noise types.)
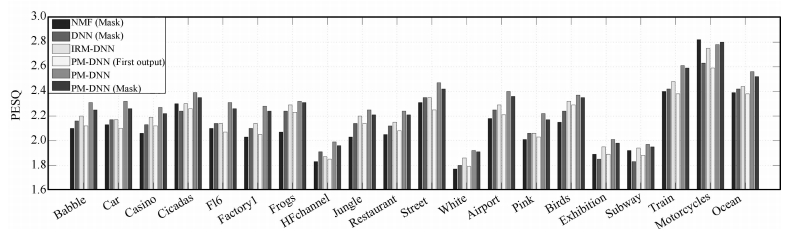
图 5 4种增强方法在20种不同噪声情况下的PESQ值(每种噪声的PESQ值是在-5 dB, 0 dB, 5 dB和10 dB 4种信噪比下的平均值.)
Fig. 5 The PESQ scores of the 4 enhancement methods for the 20 noise types (For each noise type, the numbers are the mean values over four input SNR conditions, i.e. from -5 dB to 10 dB spaced by 5 dB.)
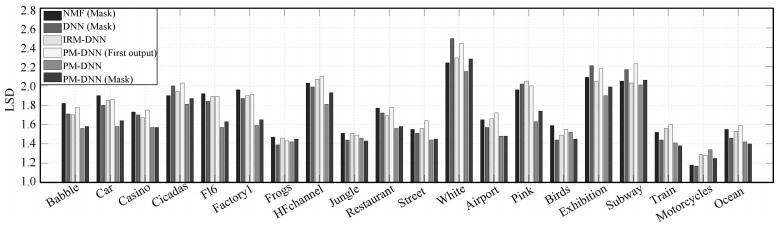
图 6 4种增强方法在20种不同噪声情况下的LSD值(每种噪声的LSD值是在-5 dB, 0 dB, 5 dB和10 dB 4种信噪比下的平均值.)
Fig. 6 The LSD values of the 4 enhancement methods for the 20 noise types (For each noise type, the numbers are the mean values over four input SNR conditions, i.e. from -5 dB to 10 dB spaced by 5 dB.)

图 7 4种增强方法在20种不同噪声情况下的fwSNRseg值(每种噪声的fwSNRseg值是在-5 dB, 0 dB, 5 dB和10 dB 4种信噪比下的平均值.)
Fig. 7 The fwSNRseg values of the 4 enhancement methods for the 20 noise types (For each noise type, the numbers are the mean values over four input SNR conditions, i.e. from -5 dB to 10 dB spaced by 5 dB.)
表 1 4种信噪比下, 不同方法对20种噪声的PESQ均值
Table 1 The PESQ scores of different methods at four different input SNR levels (For each condition, the numbers are the mean values over all the 20 noise types.)
SNR (dB) NMF DNN IRM-DNN PM-DNN (First output) PM-DNN NMF (Mask) DNN (Mask) IRM-DNN (Mask) PM-DNN (Mask) -5 1.705 1.74 1.787 1.732 1.875 1.701 1.775 1.74 1.834 0 2.002 1.995 2.061 1.996 2.165 1.995 2.034 2.015 2.122 5 2.261 2.194 2.35 2.256 2.445 2.262 2.284 2.308 2.411 10 2.524 2.35 2.631 2.518 2.714 2.52 2.535 2.596 2.691  下载: 导出CSV
下载: 导出CSV
-
[1] Boll S F. Suppression of acoustic noise in speech using spectral subtraction. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1979, 27(2):113-120 doi: 10.1109/TASSP.1979.1163209 [2] Chen J D, Benesty J, Huang Y T, Doclo S. New insights into the noise reduction Wiener filter. IEEE Transactions on Audio, Speech and Language Processing, 2006, 14(4):1218-1234 doi: 10.1109/TSA.2005.860851 [3] Ephraim Y, Malah D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984, 32(6):1109-1121 doi: 10.1109/TASSP.1984.1164453 [4] Gerkmann T, Hendriks R C. Unbiased MMSE-based noise power estimation with low complexity and low tracking delay. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(4):1383-1393 doi: 10.1109/TASL.2011.2180896 [5] Jensen J R, Benesty J, Christensen M G, Jensen S H. Enhancement of single-channel periodic signals in the time-domain. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(7):1948-1963 doi: 10.1109/TASL.2012.2191957 [6] Wilson K W, Raj B, Smaragdis P, Divakaran A. Speech denoising using nonnegative matrix factorization with priors. In:Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing. Las Vegas, USA:IEEE, 2008. 4029-4032 [7] Sun C L, Zhu Q, Wan M H. A novel speech enhancement method based on constrained low-rank and sparse matrix decomposition. Speech Communication, 2014, 60:44-55 doi: 10.1016/j.specom.2014.03.002 [8] Sun M, Li Y N, Gemmeke J, Zhang X W. Speech enhancement under low SNR conditions via noise estimation using sparse and low-rank NMF with Kullback-Leibler divergence. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(7):1233-1242 doi: 10.1109/TASLP.2015.2427520 [9] Xu Y, Du J, Dai L R, Lee C H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1):7-19 doi: 10.1109/TASLP.2014.2364452 [10] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(12):2136-2147 doi: 10.1109/TASLP.2015.2468583 [11] Wang Y X, Narayanan A, Wang D L. On training targets for supervised speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12):1849-1858 doi: 10.1109/TASLP.2014.2352935 [12] Sun M, Zhang X W, Van hamme H, Zheng T F. Unseen noise estimation using separable deep auto encoder for speech enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(1):93-104 doi: 10.1109/TASLP.2015.2498101 [13] Williamson D S, Wang Y X, Wang D L. Complex ratio masking for monaural speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(3):483-492 doi: 10.1109/TASLP.2015.2512042 [14] Narayanan A, Wang D L. Improving robustness of deep neural network acoustic models via speech separation and joint adaptive training. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1):92-101 https://www.researchgate.net/publication/273296153_Improving_Robustness_of_Deep_Neural_Network_Acoustic_Models_via_Speech_Separation_and_Joint_Adaptive_Training [15] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527-1554 doi: 10.1162/neco.2006.18.7.1527 [16] Bengio Y. Learning deep architectures for AI. Foundations and Trends® in Machine Learning, 2009, 2(1):1-127 doi: 10.1561/2200000006 [17] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. In:Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA:JMLR, 2011. 315-323 [18] 张勇, 刘轶, 刘宏.结合人耳听觉感知的两级语音增强算法.信号处理, 2014, 30(4):363-373 http://www.cnki.com.cn/Article/CJFDTOTAL-XXCN201404001.htmZhang Yong, Liu Yi, Liu Hong. A two-stage speech enhancement algorithm combined with human auditory perception. Journal of Signal Processing, 2014, 30(4):363-373 http://www.cnki.com.cn/Article/CJFDTOTAL-XXCN201404001.htm [19] Johnston J D. Transform coding of audio signals using perceptual noise criteria. IEEE Journal on Selected Areas in Communications, 1988, 6(2):314-323 doi: 10.1109/49.608 [20] Udrea R M, Vizireanu N D, Ciochina S. An improved spectral subtraction method for speech enhancement using a perceptual weighting filter. Digital Signal Processing, 2008, 18(4):581-587 doi: 10.1016/j.dsp.2007.08.002 [21] Hu Y, Loizou P C. Incorporating a psychoacoustical model in frequency domain speech enhancement. IEEE Signal Processing Letters, 2004, 11(2):270-273 doi: 10.1109/LSP.2003.821714 [22] Rix A W, Beerends J G, Hollier M P, Hekstra A P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In:Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Salt Lake City, USA:IEEE, 2001. 749-752 [23] 邹霞, 陈亮, 张雄伟.基于Gamma语音模型的语音增强算法.通信学报, 2006, 27(10):118-123 http://www.cnki.com.cn/Article/CJFDTOTAL-TXXB200610019.htmZou Xia, Chen Liang, Zhang Xiong-Wei. Speech enhancement with Gamma speech modeling. Journal on Communications, 2006, 27(10):118-123 http://www.cnki.com.cn/Article/CJFDTOTAL-TXXB200610019.htm [24] Hu Y, Loizou P C. Evaluation of objective quality measures for speech enhancement. IEEE Transactions on Audio, Speech, and Language Processing, 2008, 16(1):229-238 doi: 10.1109/TASL.2007.911054 [25] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Deep learning for monaural speech separation. In:Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. Florence, Italy:IEEE, 2014. 1562-1566 -

 下载:
下载:



计量
- 文章访问数: 3474
- HTML全文浏览量: 1467
- PDF下载量: 878
- 被引次数: 0
