

Multi-object Tracking Using Hierarchical Data Association Based on Generalized Correlation Clustering Graphs
-
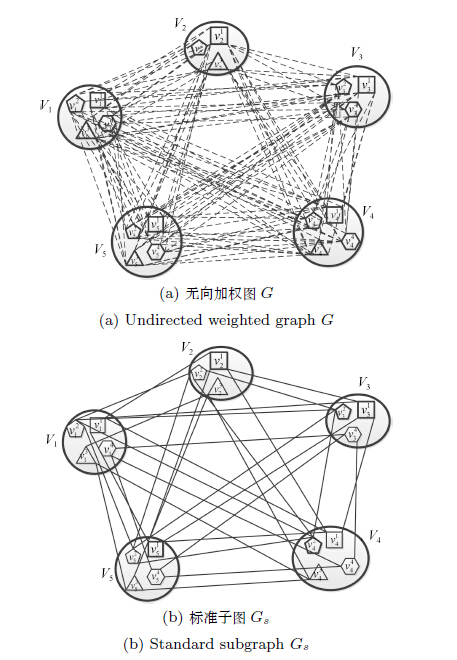
摘要: 检测跟踪是近期多目标跟踪研究的热点方向之一.目前大部分方法都是基于相邻帧之间的双向匹配,对检测点进行数据融合.本文提出的方法是,给定一个滑动时间窗口,在窗口内对某个目标每帧出现的检测点进行一次性数据融合.我们把多目标跟踪看作图的分割问题,利用广义关联聚类(Generalized correlation clustering problem,GCCP)图优化文中提出的数据融合.吸取分层数据关联的思想,把多目标跟踪分成两个阶段.首先,在时间窗口内遵循检测点,利用广义关联聚类,得到自适应长度的轨迹片段,轨迹片段长度不受窗口宽度的限制.然后,基于轨迹片段进一步数据关联,得到目标的长轨迹.在公共数据集上的实验测试表明,本文方法能够有效地实现多目标跟踪,对于遮挡处理、身份转换处理以及轨迹的生成具有很好的鲁棒性,多目标跟踪准确率(Multiple object tracking accuracy,MOTA)超过当前水平.Abstract: Tracking by detection based on data association of detections is a main research direction in the field of multi-object tracking. The majority of current methods, such as bipartite matching, solve the data association problem between adjacent frames. We propose an approach to solve data association for one object whose all detections are in a sliding temporal window at a time. The task of multi-object tracking can be considered as a graph partitioning problem that takes the form of a generalized correlation clustering problem (GCCP). The multi-object tracking problem can be divided into two phases using hierarchical data association. Firstly, adaptive length tracklets can be obtained from all detections in a sliding temporal window by using the GCCP. The length of tracklets is not restricted to the window width. Secondly, we treat tracklets as detections, using the similar method described in first phase to acquire trajectories. Experiments show that the proposed method can handle occlusion and ID-switch effectively, which makes significant improvement in multi-object tracking on the public datasets. Our multiple object tracking accuracy (MOTA) is higher than that of the-state-of-the-art.
-
表 1 自适应轨迹片段与传统轨迹片段比较
Table 1 The difference between traditional-tracklet and adaptive-tracklet
Methods MOTA(%) MOTP(%) IDS TC Time(s) Rcll(%) Prcsn(%) Traditional-tracklet 93.08 83.57 16 356 2.5 94.61 98.74 Adaptive-tracklet 95.11 83.04 4 77 2.34 96.31 98.88  下载: 导出CSV
下载: 导出CSV
表 2 跟踪结果
Table 2 The results of tracking
Sequence Methods MOTA(%) MOTP(%) Rcll(%) Prcsn(%) Longyin[13] 92.7 72.9 94.4 98.4 Andriyenko[15] 88.3 79.6 90 98.7 PETS-S2L1 Zamir[10] 90.3 69.02 96.45 93.64 Afshin[18] 90.4 63.12 -- -- Izadinia[12] 90.7 76 95.2 96.8 Ours 95.11 83.04 96.31 98.88 Longyin[13] 62.1 52.7 71.2 90.3 PETS-S2L2 Anton[26] 56.9 59.4 65.5 89.8 Ours 52.98 68.63 57.15 93.58 Longyin[13] 88.4 81.9 90.8 98.3 Andriyenko[15] 73.1 76.5 86.8 89.4 Parking lot Zamir[10] 90.43 74.1 85.3 98.2 Guang[8] 79.3 74.1 -- -- Izadinia[12] 88.9 77.5 96.5 93.6 Ours 91.37 74.8 96.61 95.24 Zamir[10] 75.59 71.93 -- -- Guang[8] 72.9 71.3 -- -- Town center McLaughlin[6] 74.15 72.41 83.27 90.4 Izadinia[12] 75.7 71.6 81.8 93.6 Ours 79.67 70.6 84.56 93.98
下载: 导出CSV
-
[1] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In:Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). San Diego, CA, USA:IEEE, 2005. 886-893 http://www.oalib.com/references/16879692 [2] Wu B, Nevatia R. Detection and tracking of multiple, partially occluded humans by Bayesian combination of edgelet based part detectors. International Journal of Computer Vision, 2007, 75(2):247-266 doi: 10.1007/s11263-006-0027-7 [3] Felzenszwalb P F, Girshick R B, McAllester D, Ramanan D. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9):1627-1645 doi: 10.1109/TPAMI.2009.167 [4] Bae S H, Yoon K J. Robust online multi-object tracking based on tracklet confidence and online discriminative appearance learning. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH:IEEE, 2014. 1218-1225 http://cn.bing.com/academic/profile?id=b51a27abfe6ed8c117c6592b09704056&encoded=0&v=paper_preview&mkt=zh-cn [5] Huang C, Li Y, Nevatia R. Multiple target tracking by learning-based hierarchical association of detection responses. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(4):898-910 doi: 10.1109/TPAMI.2012.159 [6] McLaughlin N, del Rincon J M, Miller P. Online multiperson tracking with occlusion reasoning and unsupervised track motion model. In:Proceedings of the 10th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). Krakow:IEEE, 2013. 37-42 https://www.computer.org/csdl/proceedings/avss/2013/9999/00/index.html [7] Henriques J F, Caseiro R, Batista J. Globally optimal solution to multi-object tracking with merged measurements. In:Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV). Barcelona:IEEE, 2011. 2470-2477 http://cn.bing.com/academic/profile?id=3f2887f7ffb4e1720cf6c1b8cf6763b6&encoded=0&v=paper_preview&mkt=zh-cn [8] Shu G, Dehghan A, Oreifej O, Hand E, Shah M. Part-based multiple-person tracking with partial occlusion handling. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI:IEEE, 2012. 1815-1821 [9] Zhang L, Li Y, Nevatia R. Global data association for multi-object tracking using network flows. In:Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Anchorage, AK:IEEE, 2008. 1-8 [10] Zamir A R, Dehghan A, Shah M. Gmcp-tracker:global multi-object tracking using generalized minimum clique graphs. In:Proceedings of the 12th European Conference on Computer Vision (ECCV) 2012. Florence, Italy:Springer-Verlag, 2012. 343-356 [11] Ristani E, Tomasi C. Tracking multiple people online and in real time. In:Proceedings of the 12th Asian Conference on Computer Vision (ACCV) 2014. Singapore:Springer International Publishing, 2015. 444-459 http://cn.bing.com/academic/profile?id=40f7f1fb493f5c240dac436babfbf566&encoded=0&v=paper_preview&mkt=zh-cn [12] Izadinia H, Saleemi I, Li W H, Shah M. (MP)2m t:multiple people multiple parts tracker. In:Proceedings of the 12th European Conference on Computer Vision (ECCV) 2012. Florence, Italy:Springer-Verlag, 2012. 100-114 [13] Wen L, Li W, Yan J, Lei Z, Yi D, Li S Z. Multiple target tracking based on undirected hierarchical relation hypergraph. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH:IEEE, 2014. 1282-1289 [14] Yang B, Nevatia R. An online learned CRF model for multi-target tracking. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI:IEEE, 2012. 2034-2041 [15] Andriyenko A, Schindler K, Roth S. Discrete-continuous optimization for multi-target tracking. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI:IEEE, 2012. 1926-1933 [16] Kuhn H W. The Hungarian method for the assignment problem. Naval Research Logistics Quarterly, 1955, 2(1-2):83-97 doi: 10.1002/(ISSN)1931-9193 [17] Chari V, Lacoste-Julien S, Laptev I, Sivic J. On pairwise costs for network flow multi-object tracking. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA:IEEE, 2015. 5537-5545 [18] Dehghan A, Tian Y, Torr P H S, Shah M. Target identity-aware network flow for online multiple target tracking. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA:IEEE, 2015. 1146-1154 [19] Bansal N, Blum A, Chawla S. Correlation clustering. Machine Learning, 2004, 56(1-3):89-113 doi: 10.1023/B:MACH.0000033116.57574.95 [20] Bagon S, Galun M. Large scale correlation clustering optimization. arXiv:1112.2903, 2011. [21] Feremans C, Labbé M, Laporte G. Generalized network design problems. European Journal of Operational Research, 2003, 148(1):1-13 doi: 10.1016/S0377-2217(02)00404-6 [22] Ojala T, Pietikainen M, Harwood D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions. In:Proceedings of the 12th IAPR International Conference on Pattern Recognition, 1994. Vol.1-Conference A:Computer Vision & Image Processing. Jerusalem:IEEE, 1994. 582-585 [23] Ferryman J, Shahrokni A. PETS2009:dataset and challenge. In:Proceedings of the 12th IEEE International Workshop on Performance Evaluation of Tracking and Surveillance. Snowbird, UT:IEEE, 2009. 1-6 [24] Benfold B, Reid I. Stable multi-target tracking in real-time surveillance video. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI:IEEE, 2011. 3457-3464 [25] Bernardin K, Stiefelhagen R. Evaluating multiple object tracking performance:the CLEAR MOT metrics. EURASIP Journal on Image and Video Processing, 2008, 2008:Article ID 246309 [26] Milan A, Roth S, Schindler K. Continuous energy minimization for multitarget tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(1):58-72 [27] Milan A, The Data. The detections and ground truth for MOT[Online], available:http://www.milanton.de/data/, April 12, 2016. -

 下载:
下载:






图(6) / 表(2)
计量
- 文章访问数: 2290
- HTML全文浏览量: 309
- PDF下载量: 1066
- 被引次数: 0
