

-
摘要: 在视觉计算研究中,对复杂环境的适应能力通常决定了算法能否实际应用,已经成为该领域的研究焦点之一.由人工社会(Artificial societies)、计算实验(Computational experiments)、平行执行(Parallel execution)构成的ACP理论在复杂系统建模与调控中发挥着重要作用.本文将ACP理论引入智能视觉计算领域,提出平行视觉的基本框架与关键技术.平行视觉利用人工场景来模拟和表示复杂挑战的实际场景,通过计算实验进行各种视觉模型的训练与评估,最后借助平行执行来在线优化视觉系统,实现对复杂环境的智能感知与理解.这一虚实互动的视觉计算方法结合了计算机图形学、虚拟现实、机器学习、知识自动化等技术,是视觉系统走向应用的有效途径和自然选择.Abstract: In vision computing, the adaptability of an algorithm to complex environments often determines whether it is able to work in the real world. This issue has become a focus of recent vision computing research. Currently, the ACP theory that comprises artificial societies, computational experiments, and parallel execution is playing an essential role in modeling and control of complex systems. This paper introduces the ACP theory into the vision computing field, and proposes parallel vision and its basic framework and key techniques. For parallel vision, photo-realistic artificial scenes are used to model and represent complex real scenes, computational experiments are utilized to train and evaluate a variety of visual models, and parallel execution is conducted to optimize the vision system and achieve perception and understanding of complex environments. This virtual/real interactive vision computing approach integrates many technologies including computer graphics, virtual reality, machine learning, and knowledge automation, and is developing towards practically effective vision systems.
-
Key words:
- Parallel vision /
- complex environments /
- ACP theory /
- data-driven /
- virtual/real interaction
-
近些年来, 由于多智能体协同控制在编队控制[1]、机器人网络[2]、群集行为[3]、移动传感器[4-5]等方面的广泛应用, 多智能体系统的协同控制问题受到了众多研究者的广泛关注.一致性问题是多智能体系统协同控制领域的一个关键问题, 其目的是通过与邻居之间的信息交换, 使所有智能体的状态达成一致.迄今为止, 对多智能体一致性的研究也已取得了丰硕的成果, 根据多智能体的动力学模型分类, 主要可以将其分为以下4种情形:一阶[6-9]、二阶[10-13]、三阶[14-15]、高阶[16-18].
在实际应用中, 由于CPU处理速度和内存容量的限制, 智能体不能频繁地进行控制以及与其邻居交换信息.因此, 事件触发控制策略作为减少控制次数和通信负载的有效途径, 受到了越来越多的关注.到目前为止, 对事件触发控制机制的研究也取得了很多成果[19-23].Xiao等[19]基于事件触发控制策略, 解决了带有领航者的离散多智能体系统的跟踪问题.通过利用状态测量误差并且基于二阶离散多智能体系统动力学模型, Zhu等[20]提出了一种自触发的控制策略, 该策略使得所有智能体的状态均达到一致. Huang等[21]研究了基于事件触发策略的Lur$'$e网络的跟踪问题.针对不同的领航者-跟随者系统, Xu等[22]提出了3种不同类型的事件触发控制器, 包含分簇式控制器、集中式控制器和分布式控制器, 以此来解决对应的一致性问题.然而, 大多数现有的事件触发一致性成果集中于考虑一阶多智能体系统和二阶多智能体系统, 很少有成果研究三阶多智能体系统的事件触发控制问题, 特别是对于三阶离散多智能体系统, 成果更是少之又少.所以, 设计相应的事件触发控制协议来解决三阶离散多智能体系统的一致性问题已变得尤为重要.
本文研究了基于事件触发控制机制的三阶离散多智能体系统的一致性问题, 文章主要有以下三点贡献:
1) 利用位置、速度和加速度三者的测量误差, 设计了一种新颖的事件触发控制机制.
2) 利用不等式技巧, 分析得到了保证智能体渐近收敛到一致状态的充分条件.与现有的事件触发文献[19-22]不同的是, 所得的一致性条件与通信拓扑的Laplacian矩阵特征值和系统的耦合强度有关.
3) 给出了排除类Zeno行为的参数条件, 进而使得事件触发控制器不会每个迭代时刻都更新.
1. 预备知识
1.1 代数图论
智能体间的通信拓扑结构用一个有向加权图来表示, 记为.其中, $\vartheta = \left\{ {1, 2, \cdots, n} \right\}$表示顶点集, $\varsigma\subseteq\vartheta\times\vartheta$表示边集, 称作邻接矩阵, ${a_{ij}}$表示边$\left({j, i} \right) \in \varsigma $的权值.当$\left({j, i} \right) \in \varsigma $时, 有${a_{ij}} > 0$; 否则, 有${a_{ij}} = 0$. ${a_{ij}} > 0$表示智能体$i$能收到来自智能体$j$的信息, 反之则不成立.对任意一条边$j$, 节点$j$称为父节点, 节点$i$则称为子节点, 节点$i$是节点$j$的邻居节点.假设通信拓扑中不存在自环, 即对任意$i\in \vartheta $, 有${a_{ii}} = 0$.
定义$L = \left({{l_{ij}}}\right)\in{\bf R}^{n\times n}$为图${\cal G}$的Laplacian矩阵, 其中元素满足${l_{ij}} = - {a_{ij}} \le 0, i \ne j$; ${l_{ii}} = \sum\nolimits_{j = 1, j \ne i}^n {{a_{ij}} \ge 0} $.智能体$i$的入度定义为${d_i} = \sum\nolimits_{j = 1}^n {{a_{ij}}} $, 因此可得到$L = D - \Delta $, 其中, .如果有向图中存在一个始于节点$i$, 止于节点$j$的形如的边序列, 那么称存在一条从$i$到$j$的有向路径.特别地, 如果图中存在一个根节点, 并且该节点到其他所有节点都有有向路径, 那么称此有向图存在一个有向生成树.另外, 如果有向图${\cal G}$存在一个有向生成树, 则Laplacian矩阵$L$有一个0特征值并且其他特征值均含有正实部.
1.2 模型描述
考虑多智能体系统由$n$个智能体组成, 其通信拓扑结构由有向加权图${\cal G}$表示, 其中每个智能体可看作图${\cal G}$中的一个节点, 每个智能体满足如下动力学方程:
$ \begin{equation} \left\{ \begin{array}{l} {x_i}\left( {k + 1} \right) = {x_i}\left( k \right) + {v_i}\left( k \right)\\ {v_i}\left( {k + 1} \right) = {v_i}\left( k \right) + {z_i}\left( k \right)\\ {z_i}\left( {k + 1} \right) = {z_i}\left( k \right) + {u_i}\left( k \right) \end{array} \right. \end{equation} $
(1) 其中, ${x_i}\left(k \right) \in \bf R$表示位置状态, ${v_i}\left(k \right) \in \bf R$表示速度状态, ${z_i}\left(k \right) \in \bf R$表示加速度状态, ${u_i}\left(k \right) \in \bf R$表示控制输入.
基于事件触发控制机制的控制器协议设计如下:
$ \begin{equation} {u_i}\left( k \right) = \lambda {b_i}\left( {k_p^i} \right) + \eta {c_i}\left( {k_p^i} \right) + \gamma {g_i}\left( {k_p^i} \right), k \in \left[ {k_p^i, k_{p + 1}^i} \right) \end{equation} $
(2) 其中, $\lambda> 0$, $\eta> 0$, $\gamma> 0$表示耦合强度,
$ \begin{align*}&{b_i}\left( k \right)= \sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{x_j}\left( k \right) - {x_i}\left( k \right)} \right)} , \nonumber\\ &{c_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{v_j}\left( k \right) - {v_i}\left( k \right)} \right)}, \nonumber\\ & {g_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{z_j}\left( k \right) - {z_i}\left( k \right)} \right)} .\end{align*} $
触发时刻序列定义为:
$ \begin{equation} k_{p + 1}^i = \inf \left\{ {k:k > k_p^i, {E_i}\left( k \right) > 0} \right\} \end{equation} $
(3) ${E_i}\left(k \right)$为触发函数, 具有以下形式:
$ \begin{align} {E_i}\left( k \right)= & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|- {\delta _2}{\beta ^k} - \nonumber\nonumber\\ &{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| \end{align} $
(4) 其中, ${\delta _1} > 0$, ${\delta _2} > 0$, $\beta > 0$, , ${e_{ci}}\left(k \right) = {c_i}\left({k_p^i} \right) - {c_i}\left(k \right)$, ${e_{gi}}\left(k \right) = {g_i}\left({k_p^i} \right) - {g_i}\left(k \right)$.
令$\varepsilon _i\left(k\right)={x_i}\left(k\right)-{x_1}\left(k\right)$, ${\varphi _i}\left(k\right)={v_i}\left(k \right)-$ ${v_1}\left(k\right)$, ${\phi _i}(k) = {z_i}(k) - {z_1}\left(k \right)$, $i = 2, \cdots, n$. , $\cdots, {\varphi _n}\left(k \right)]^{\rm T}$, $\phi \left(k \right) = {\left[{{\phi _2}\left(k \right), \cdots, {\phi _n}\left(k \right)} \right]^{\rm T}}$. $\psi \left(k \right) = {\left[{{\varepsilon ^{\rm T}}\left(k \right), {\varphi ^{\rm T}}\left(k \right), {\phi ^{\rm T}}\left(k \right)} \right]^{\rm T}}$, , ${\bar e_b} = {\left[{{e_{b1}}\left(k \right), \cdots, {e_{b1}}\left(k \right)} \right]^{\rm T}}$, , ${e_{c1}}\left(k \right)]^{\rm T}$, , ${\bar e_g} = $ ${\left[{{e_{g1}}\left(k \right), \cdots, {e_{g1}}\left(k \right)} \right]^{\rm T}}$, $\tilde e\left(k \right) = [\tilde e_b^{\rm T}\left(k \right), \tilde e_c^{\rm T}\left(k \right), $ $\tilde e_g^{\rm T}\left(k \right)]^{\rm T}$, $\bar e\left(k \right) = [\bar e_b^{\rm T}\left(k \right), \bar e_c^T\left(k \right), \bar e_g^{\rm T}\left(k \right)]^{\rm T}$,
$ \hat L = \left[ {\begin{array}{*{20}{c}} {{d_2} + {a_{12}}}&{{a_{13}} - {a_{23}}}& \cdots &{{a_{1n}} - {a_{2n}}}\\ {{a_{12}} - {a_{32}}}&{{d_3} + {a_{13}}}& \cdots &{{a_{1n}} - {a_{3n}}}\\ \vdots & \vdots & \ddots & \vdots \\ {{a_{12}} - {a_{n2}}}&{{a_{13}} - {a_{n3}}}& \cdots &{{d_n} + {a_{1n}}} \end{array}} \right] $
再结合式(1)和式(2)可得到:
$ \begin{equation} \psi \left( {k + 1} \right) = {Q_1}\psi \left( k \right) + {Q_2}\left( {\tilde e\left( k \right) - \bar e\left( k \right)} \right) \end{equation} $
(5) 其中, , .
定义1.对于三阶离散时间多智能体系统(1), 当且仅当所有智能体的位置变量、速度变量、加速度变量满足以下条件时, 称系统(1)能够达到一致.
$ \begin{align*} &{\lim _{k \to \infty }}\left\| {{x_j}\left( k \right) - {x_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{v_j}\left( k \right) - {v_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{z_j}\left( k \right) - {z_i}\left( k \right)} \right\| = 0 \\&\quad\qquad \forall i, j = 1, 2, \cdots , n \end{align*} $
定义2.如果$k_{p + 1}^i - k_p^i > 1$, 则称触发时刻序列$\left\{ {k_p^i} \right\}$不存在类Zeno行为.
假设1.假设有向图中存在一个有向生成树.
2. 一致性分析主要结果
假设$\kappa$是矩阵${Q_1}$的特征值, ${\mu _i}$是$L$的特征值, 则有如下等式成立:
$ {\rm{det}}\left( {\kappa {I_{3n - 3}} - {Q_1}} \right)=\nonumber\\ \det \left(\! \!{\begin{array}{*{20}{c}} {\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\!&\!{{0_{n - 1}}}\\ {{0_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\\ {\lambda {{\hat L}_{n - 1}}}\!&\!{\eta {{\hat L}_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}} + \gamma {{\hat L}_{n - 1}}} \end{array}} \!\!\right)=\nonumber\\ \prod\limits_{i = 2}^n {\left[ {{{\left( {\kappa - 1} \right)}^3} + \left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i}} \right]} $
令
$ \begin{align} {m_i}\left( \kappa \right)= &{\left( {\kappa - 1} \right)^3} + \nonumber\\&\left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i} = 0, \nonumber\\& \qquad\qquad\qquad\qquad\qquad i = 2, \cdots , n \end{align} $
(6) 则有如下引理:
引理1[15]. 如果矩阵$L$有一个0特征值且其他所有特征值均有正实部, 并且参数$\lambda $, $\eta $, $\gamma $满足下列条件:
$ \left\{ \begin{array}{l} 3\lambda - 2\eta < 0\\ \left( {\gamma - \eta + \lambda } \right)\left( {\lambda - \eta } \right) < - \dfrac{{\lambda \Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}}\\ \left( {4\gamma + \lambda - 2\eta } \right)<\dfrac{{8\Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}} \end{array} \right. $
那么, 方程(6)的所有根都在单位圆内, 这也就意味着矩阵${Q_1}$的谱半径小于1, 即$\rho \left({{Q_1}} \right) < 1$.其中, 表示特征值${\mu _i}$的实部.
引理2[23]. 如果, 那么存在$M \ge 1$和$0 < \alpha < 1$使得下式成立
$ {\left\| {{Q_1}} \right\|^k} \le M{\alpha ^k}, \quad k \ge 0 $
定理1. 对于三阶离散多智能体系统(1), 基于假设1, 如果式(2)中的耦合强度满足引理1中的条件, 触发函数(4)中的参数满足$0 < {\delta _1} < 1$, , $0 < \alpha < \beta < 1$, 则称系统(1)能够实现渐近一致.
证明.令$\omega \left(k \right) = \tilde e\left(k \right) - \bar e\left(k \right)$, 式(5)能够被重新写成如下形式:
$ \begin{equation} \psi \left( k \right) = Q_1^k\psi \left( 0 \right) + {Q_2}\sum\limits_{s = 0}^{k - 1} {Q_1^{k - 1 - s}\omega \left( s \right)} \end{equation} $
(7) 根据引理1和引理2可知, 存在$M \ge 1$和$0 < \alpha < 1$使得下式成立.
$ \begin{align} \left\| {\psi \left( k \right)} \right\|\le & {\left\| {{Q_1}} \right\|^k}\left\| {\psi \left( 0 \right)} \right\| + \nonumber\\ & \left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{{\left\| {{Q_1}} \right\|}^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|}\le \nonumber\\ & M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+\nonumber\\ & M\left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{\alpha ^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|} \end{align} $
(8) 由触发条件可得:
$ \begin{align} & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ & \qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^k}\le\nonumber\\ &\qquad {\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\| + {\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\| + \nonumber\\ &\qquad{\delta _1}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\|+ {\delta _1}\left| {{e_{bi}} \left( k \right)} \right| + \nonumber\\ &\qquad{\delta _1}\left| {{e_{ci}} \left( k \right)} \right|+ {\delta _1}\left| {{e_{gi}}\left( k \right)} \right| + {\delta _2}{\beta ^k} \end{align} $
(9) 对上式移项可求解得:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le \nonumber\\ &\qquad\frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\|}}{{1 - {\delta _1}}} + \frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\|}}{{1 - {\delta _1}}}{\rm{ + }}\nonumber\\ &\qquad\frac{{{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(10) 又因为, 和, 可得出下列不等式:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ &\qquad \frac{{{\delta _1}\left\| L \right\|}}{{1 - {\delta _1}}} \cdot \left( {\left\| {\varepsilon \left( k \right)} \right\|{\rm{ + }}\left\| {\varphi \left( k \right)} \right\|{\rm{ + }}\left\| {\phi \left( k \right)} \right\|} \right) +\nonumber\\ &\qquad \frac{{{\delta _2}{\beta ^k}}}{{1 - {\delta _1}}}\le \frac{{3{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(11) 接着有如下不等式成立:
$ \begin{align} \left\| {e\left( k \right)} \right\|\le \frac{{3\sqrt n {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{\sqrt n {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(12) 其中, , ${e_b}(k) = \left[{{e_{b1}}(k), \cdots, {e_{bn}}(k)} \right]$, ${e_c}(k) = \left[{{e_{c1}}(k), \cdots, {e_{cn}}(k)} \right]$,
注意到
$ \begin{equation} \left\| {\tilde e( k )} \right\| + \left\| {\bar e( k )} \right\| \le \sqrt {6( {n - 1} )} \left\| {e( k )} \right\| \end{equation} $
(13) 于是有
$ \begin{align} \left\| {\omega ( k )} \right\| &= \left\| {\tilde e( k ) - \bar e\left( k \right)} \right\| \le\nonumber\\ & \left\| {\tilde e\left( k \right)} \right\| + \left\| {\bar e\left( k \right)} \right\|\le\nonumber\\ & \frac{{3\sqrt {6n( {n - 1} )} {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| +\nonumber\\ & \frac{{\sqrt {6n( {n - 1} )} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(14) 把式(14)代入式(8)可得
$ \begin{align} \left\| {\psi \left( k \right)} \right\| &\le M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+ \nonumber\\ &\frac{{M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}} {\delta _1}3\sqrt {6n\left( {n - 1} \right)} \left\| L \right\|}}{{1 - {\delta _1}}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}}\left\| {\psi \left( s \right)} \right\|} + M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}} \frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}} {{1 - {\delta _1}}}{\beta ^s}} \end{align} $
(15) 接下来的部分, 将证明下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| \le W{\beta ^k}.\end{equation} $
(16) 其中, $W = \max \left\{ {{\Theta _1}, {\Theta _2}} \right\}$,
首先, 证明对任意的$\rho > 1$, 下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| < \rho W{\beta ^k} \end{equation} $
(17) 利用反证法, 先假设式(17)不成立, 则必将存在${k^ * } > 0$使得并且当$k \in \left({0, {k^ * }} \right)$时$\left\| {\psi \left(k \right)} \right\| < \rho W{\beta ^k}$成立.因此, 根据式(17)可得:
$ \begin{align*} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le\\ &\qquad M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} +\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}M\times \end{align*} $
$ \begin{align*} &\qquad\sum\limits_{s = 0}^{{k^ * } - 1} {\alpha ^{ - s}}\left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot \left\| {\psi \left( s \right)} \right\|}}{{1 - {\delta _1}}}} \right]+ \\ &\qquad M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^s}} \right]} < \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} + \rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}\times\\ &\qquad \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot W{\beta ^s}}} {{1 - {\delta _1}}}} \right]} +\\ &\qquad\rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}{\beta ^s}}}{{1 - {\delta _1}}}} \right]=} \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}}- \nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\alpha ^{{k^ * }}}+\nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\beta ^{{k^ * }}} \end{align*} $
1) 当$W = M\left\| {\psi \left(0 \right)} \right\|$时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\| - \nonumber\\ &\qquad \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} \ge 0 \end{aligned} \end{equation*} $
所以可得到
$ \begin{equation} \rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le \rho M\left\| {\psi \left( 0 \right)} \right\|{\beta ^{{k^ * }}}=\rho W{\beta ^{{k^ * }}} \end{equation} $
(18) 2) 当时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\|- \nonumber\\ &\qquad\frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} < 0 \end{aligned} \end{equation*} $
所以有
$ \begin{align} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\|\le\nonumber\\ & \frac{{\rho {\delta _2}M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} {\beta ^{{k^ * }}}}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right) - 3{\delta _1}M\left\| {{Q_2}} \right\|\left\| L \right\|\sqrt {6n\left( {n - 1} \right)} }}=\nonumber\\ &\rho W{\beta ^{{k^ * }}} \end{align} $
(19) 根据以上结果, 式(18)和式(19)都与假设相矛盾.这说明原命题成立, 即对任意的$\rho > 1$, 式(17)成立.易知, 如果$\rho \to 1$, 则式(16)成立.根据式(16)可知, 当$k \to + \infty $时, 有, 则系统(5)是收敛的.由$\psi \left(k \right)$的定义可知, 系统(1)能够实现渐近一致.
定理2. 对于系统(1), 如果定理1中的条件成立, 并且控制器(2)中的设计参数满足如下条件,
$ {\delta _1} \in \left( {\frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}}, 1} \right)\\ {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } $
那么触发序列中的类Zeno行为将被排除.
证明. 易知排除类Zeno行为的关键是要证明不等式$k_{p + 1}^i - k_p^i > 1$成立.根据事件触发机制可知, 下一个触发时刻将会发生在触发函数(4)大于0时.进而可得到如下不等式
$ \begin{align} &\left| {{e_{bi}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{ci}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{gi}}\left( {k_{p + 1}^i} \right)} \right|\ge\nonumber\\ &\qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{align} $
(20) 定义, .结合式(20), 可得到下式
$ \begin{equation} {G_i}\left( {k_{p + 1}^i} \right) \ge {\delta _1}{H_i}\left( {k_p^i} \right) + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{equation} $
(21) 结合式(16)和式(21)可得
$ \begin{align} {\delta _2}{\beta ^{k_{p + 1}^i}} &\le {G_i}\left( {k_{p + 1}^i} \right) - {\delta _1}{H_i}\left( {k_p^i} \right)\le\nonumber\\ & \left\| L \right\|\left( {\left\| {\psi \left( {k_p^i} \right)} \right\| + \left\| {\psi \left( {k_{p + 1}^i} \right)} \right\|} \right)\le\nonumber\\ & W\left\| L \right\|\left( {{\beta ^{k_p^i}} + {\beta ^{k_{p + 1}^i}}} \right) \end{align} $
(22) 求解上式得
$ \begin{equation} \left( {{\delta _2} - \left\| L \right\|W} \right){\beta ^{k_{p + 1}^i}} \le \left\| L \right\|W{\beta ^{k_p^i}} \end{equation} $
(23) 根据式(23)可得
$ \begin{equation} k_{p + 1}^i - k_p^i > \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}} } {\ln \beta } \end{equation} $
(24) 基于(24)易知当时, 有如下不等式成立
$ \begin{equation} \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}}} {\ln \beta } > 1 \end{equation} $
(25) 此外, 因为$W = M\left\| {\psi \left(0 \right)} \right\|$以及
$ \begin{equation} {\delta _1} > \frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}} \end{equation} $
(26) 又可以得出
$ \begin{equation} {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } = \frac{{\left\| L \right\|W\left( {1 + \beta } \right)}}{\beta } \end{equation} $
(27) 该式意味着式(25)成立, 又结合式(24)易知$k_{p + 1}^i - k_p^i > 1$, 即排除类Zeno行为的条件得已满足.
注2.类Zeno行为广泛存在于基于事件触发控制机制的离散系统中.然而, 当前极少有文献研究如何排除类Zeno行为, 尤其是对于三阶多智能体动态模型.定理2给出了排除三阶离散多智能体系统的类Zeno行为的参数条件.
3. 仿真实验
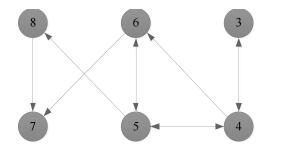
本部分将利用一个仿真实验来验证本文所提算法及理论的正确性和有效性.假设三阶离散多智能体系统(1)包含6个智能体, 且有向加权通信拓扑结构如图 1所示, 权重取值为0或1, 可以明显地看出该图包含有向生成树(满足假设1).
通过简单的计算可得, ${\mu _1} = 0$, ${\mu _2} = 0.6852$, ${\mu _3} = 1.5825 + 0.3865$i, ${\mu _4} = 1.5825 - 0.3865$i, ${\mu _5} = 3.2138$, ${\mu _6} = 3.9360$.令$M = 1$, 结合定理1和定理2可得到$0.035 < {\delta _1} < 1$, ${\delta _2} > 44.0025$, $0 < \alpha < \beta < 1$.令${\delta _1} = 0.2$, ${\delta _2} = 200$, $\alpha = 0.6$, $\beta = 0.9$, $\lambda = 0.02$, $\eta = 0.3$, $\gamma = 0.5$, 不难验证满足引理1的条件并且计算可知$\rho \left({{Q_1}} \right) = 0.9958 < 1$.三阶离散多智能体系统(1)的一致性结果如图 2~图 6所示.根据定理1可知, 基于控制器(2)和事件触发函数(4)的系统(1)能实现一致.从图 2~图 6可以看出, 仿真结果与理论分析符合.
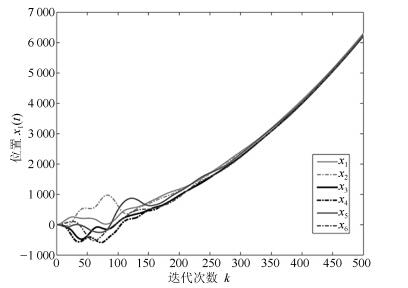 图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems
图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems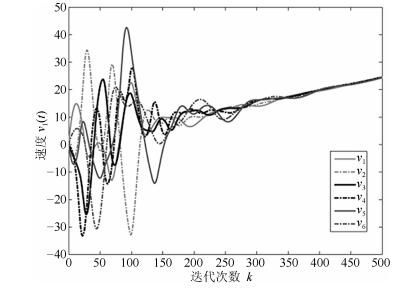 图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems
图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems 图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems
图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems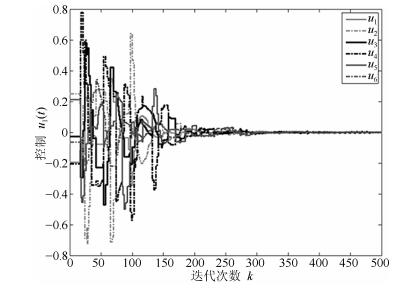 图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems
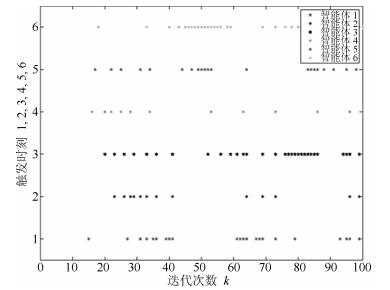
图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems图 2~图 4分别表征了系统(1)中所有智能体的位置、速度和加速度的轨迹, 从图中可以看出以上3个变量确实达到了一致.图 5展示了控制输入的轨迹.为了更清楚地体现事件触发机制的优点, 图 6给出了0$ \sim $100次迭代内的各智能体的触发时刻轨迹.从图 6可以看出, 本文设计的事件触发协议确实达到了减少更新次数, 节省资源的目的.
4. 结论
针对三阶离散多智能体系统的一致性问题, 构造了一个新颖的事件触发一致性协议, 分析得到了在通信拓扑为有向加权图且包含生成树的条件下, 系统中所有智能体的位置状态、速度状态和加速度状态渐近收敛到一致状态的充分条件.同时, 该条件指出了通信拓扑的Laplacian矩阵特征值和系统的耦合强度对系统一致性的影响.另外, 给出了排除类Zeno行为的参数条件.仿真实验结果也验证了上述结论的正确性.将文中获得的结论扩展到拓扑结构随时间变化的更高阶多智能体网络是极有意义的.这将是未来研究的一个具有挑战性的课题.
-
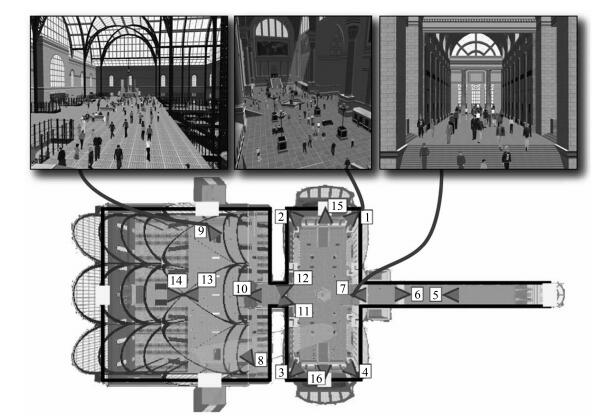
图 1 虚拟火车站的平面图[26](包括站台和火车轨道(左)、主候车室(中)和购物商场(右).该摄像机网络包括16台虚拟摄像机)
Fig. 1 Plan view of the virtual train station[26] (Revealing the concourses and train tracks (left), the main waiting room (middle), and the shopping arcade (right). An example camera network comprising 16 virtual cameras is illustrated.)

图 2 虚拟KITTI数据集[32] (上: KITTI多目标跟踪数据集中的一帧图像; 中:虚拟KITTI数据集中对应的图像帧, 叠加了被跟踪目标的标注边框; 下:自动标注的光流(左)、语义分割(中)和深度(右))
Fig. 2 The virtual KITTI dataset[32]. (Top: a frame of a video from the KITTI multi-object tracking benchmark. Middle: the corresponding synthetic frame from the virtual KITTI dataset with automatic tracking ground truth bounding boxes. Bottom: automatically generated ground truth for optical flow (left), semantic segmentation (middle), and depth (right).)

表 1 人工室外场景的构成要素
Table 1 Components for artificial outdoor scenes
场景要素 内容 静态物体 建筑物、天空、道路、人行道、围墙、植物、立柱、交通标志、路面标线等 动态物体 汽车(轿车、货车、公交车)、自行车、摩托车、行人等 季节 春、夏、秋、冬 天气 晴、阴、雨、雪、雾、霾等 光源 太阳、路灯、车灯等  下载: 导出CSV
下载: 导出CSV
-
[1] 王飞跃.平行系统方法与复杂系统的管理和控制.控制与决策, 2004, 19 (5):485-489, 514 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC200405001.htmWang Fei-Yue. Parallel system methods for management and control of complex systems. Control and Decision, 2004, 19(5):485-489, 514 http://www.cnki.com.cn/Article/CJFDTOTAL-KZYC200405001.htm [2] Wang F Y. Parallel control and management for intelligent transportation systems:concepts, architectures, and applications. IEEE Transactions on Intelligent Transportation Systems, 2010, 11(3):630-638 doi: 10.1109/TITS.2010.2060218 [3] 王飞跃.平行控制:数据驱动的计算控制方法.自动化学报, 2013, 39 (4):293-302 http://www.aas.net.cn/CN/Y2013/V39/I4/293Wang Fei-Yue. Parallel control:a method for data-driven and computational control. Acta Automatica Sinica, 2013, 39(4):293-302 http://www.aas.net.cn/CN/Y2013/V39/I4/293 [4] Wang K F, Liu Y Q, Gou C, Wang F Y. A multi-view learning approach to foreground detection for traffic surveillance applications. IEEE Transactions on Vehicular Technology, 2016, 65(6):4144-4158 doi: 10.1109/TVT.2015.2509465 [5] Wang K F, Yao Y J. Video-based vehicle detection approach with data-driven adaptive neuro-fuzzy networks. International Journal of Pattern Recognition and Artificial Intelligence, 2015, 29(7):1555015 doi: 10.1142/S0218001415550150 [6] Gou C, Wang K F, Yao Y J, Li Z X. Vehicle license plate recognition based on extremal regions and restricted Boltzmann machines. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(4):1096-1107 doi: 10.1109/TITS.2015.2496545 [7] Liu Y Q, Wang K F, Shen D Y. Visual tracking based on dynamic coupled conditional random field model. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(3):822-833 doi: 10.1109/TITS.2015.2488287 [8] Goyette N, Jodoin P M, Porikli F, Konrad J, Ishwar P. A novel video dataset for change detection benchmarking. IEEE Transactions on Image Processing, 2014, 23(11):4663-4679 doi: 10.1109/TIP.2014.2346013 [9] Felzenszwalb P F, Girshick R B, McAllester D, Ramanan D. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9):1627-1645 doi: 10.1109/TPAMI.2009.167 [10] INRIA person dataset[Online], available:http://pascal.inrialpes.fr/data/human/, September26, 2016. [11] Caltech pedestrian detection benchmark[Online], available:http://www.vision.caltech.edu/Image_Datasets/Caltech-Pedestrians/, September26, 2016. [12] The KITTI vision benchmark suite[Online], available:http://www.cvlibs.net/datasets/kitti/, September26, 2016. [13] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In:Advances in Neural Information Processing Systems 25(NIPS 2012). Nevada:MIT Press, 2012. [14] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553):436-444 doi: 10.1038/nature14539 [15] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN:towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, to be published http://es.slideshare.net/xavigiro/faster-rcnn-towards-realtime-object-detection-with-region-proposal-networks [16] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV:IEEE, 2016. 770-778 [17] ImageNet[Online], available:http://www.image-net.org/, September26, 2016. [18] The PASCAL visual object classes homepage[Online], available:http://host.robots.ox.ac.uk/pascal/VOC/, September26, 2016. [19] COCO——Common objects in context[Online], available:http://mscoco.org/, September26, 2016. [20] Torralba A, Efros A A. Unbiased look at dataset bias. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Colorado, USA:IEEE, 2011. 1521-1528 [21] Bainbridge W S. The scientific research potential of virtual worlds. Science, 2007, 317(5837):472-476 doi: 10.1126/science.1146930 [22] Miao Q H, Zhu F H, Lv Y S, Cheng C J, Chen C, Qiu X G. A game-engine-based platform for modeling and computing artificial transportation systems. IEEE Transactions on Intelligent Transportation Systems, 2011, 12(2):343-353 doi: 10.1109/TITS.2010.2103400 [23] Sewall J, van den Berg J, Lin M, Manocha D. Virtualized traffic:reconstructing traffic flows from discrete spatiotemporal data. IEEE Transactions on Visualization and Computer Graphics, 2011, 17(1):26-37 doi: 10.1109/TVCG.2010.27 [24] Prendinger H, Gajananan K, Zaki A B, Fares A, Molenaar R, Urbano D, van Lint H, Gomaa W. Tokyo Virtual Living Lab:designing smart cities based on the 3D Internet. IEEE Internet Computing, 2013, 17(6):30-38 doi: 10.1109/MIC.4236 [25] Karamouzas I, Overmars M. Simulating and evaluating the local behavior of small pedestrian groups. IEEE Transactions on Visualization and Computer Graphics, 2012, 18(3):394-406 doi: 10.1109/TVCG.2011.133 [26] Qureshi F, Terzopoulos D. Smart camera networks in virtual reality. Proceedings of the IEEE, 2008, 96(10):1640-1656 doi: 10.1109/JPROC.2008.928932 [27] Starzyk W, Qureshi F Z. Software laboratory for camera networks research. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2013, 3(2):284-293 doi: 10.1109/JETCAS.2013.2256827 [28] Sun B C, Saenko K. From virtual to reality:fast adaptation of virtual object detectors to real domains. In:Proceedings of the 2014 British Machine Vision Conference. Jubilee Campus:BMVC, 2014. [29] Hattori H, Boddeti V N, Kitani K, Kanade T. Learning scene-specific pedestrian detectors without real data. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, Massachusetts:IEEE, 2015. 3819-3827 [30] Vázquez D, López A M, Marín J, Ponsa D, Gerónimo D. Virtual and real world adaptation for pedestrian detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(4):797-809 doi: 10.1109/TPAMI.2013.163 [31] Xu J L, Vázquez D, López A M, Marín J, Ponsa D. Learning a part-based pedestrian detector in a virtual world. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(5):2121-2131 doi: 10.1109/TITS.2014.2310138 [32] Gaidon A, Wang Q, Cabon Y, Vig E. Virtual worlds as proxy for multi-object tracking analysis. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV:IEEE, 2016. 4340-4349 [33] Handa A, Párácean V, Badrinarayanan V, Stent S, Cipolla R. Understanding real world indoor scenes with synthetic data. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV:IEEE, 2016. 4077-4085 [34] Ros G, Sellart L, Materzynska J, Vazquez D, López A M. The SYNTHIA dataset:a large collection of synthetic images for semantic segmentation of urban scenes. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV:IEEE, 2016. 3234-3243 [35] Movshovitz-Attias Y, Kanade T, Sheikh Y. How useful is photo-realistic rendering for visual learning? arXiv:1603.08152, 2016. https://www.researchgate.net/publication/301837317_How_useful_is_photo-realistic_rendering_for_visual_learning [36] Haines T S F, Xiang T. Background subtraction with Dirichlet process mixture models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(4):670-683 doi: 10.1109/TPAMI.2013.239 [37] Sobral A, Vacavant A. A comprehensive review of background subtraction algorithms evaluated with synthetic and real videos. Computer Vision and Image Understanding, 2014, 122:4-21 doi: 10.1016/j.cviu.2013.12.005 [38] Morris B T, Trivedi M M. Trajectory learning for activity understanding:unsupervised, multilevel, and long-term adaptive approach. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(11):2287-2301 doi: 10.1109/TPAMI.2011.64 [39] Butler D J, Wulff J, Stanley G B, Black M J. A naturalistic open source movie for optical flow evaluation. In:Proceedings of the 12th European Conference on Computer Vision (ECCV). Berlin Heidelberg:Springer-Verlag, 2012. [40] Kaneva B, Torralba A, Freeman W T. Evaluation of image features using a photorealistic virtual world. In:Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV). Barcelona, Spain:IEEE, 2011. 2282-2289 [41] Taylor G R, Chosak A J, Brewer P C. OVVV:using virtual worlds to design and evaluate surveillance systems. In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Minneapolis, MN, USA:IEEE, 2007. 1-8 [42] Zitnick C L, Vedantam R, Parikh D. Adopting abstract images for semantic scene understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(4):627-638 doi: 10.1109/TPAMI.2014.2366143 [43] Veeravasarapu V S R, Hota R N, Rothkopf C, Visvanathan R. Model validation for vision systems via graphics simulation. arXiv:1512.01401, 2015. http://arxiv.org/abs/1512.01401 [44] Veeravasarapu V S R, Hota R N, Rothkopf C, Visvanathan R. Simulations for validation of vision systems. arXiv:1512.01030, 2015. http://arxiv.org/abs/1512.01030?context=cs.cv [45] 国家发展改革委, 交通运输部.青岛市"多位一体"平行交通运用示范.国家发展改革委交通运输部关于印发《推进"互联网+"便捷交通促进智能交通发展的实施方案》的通知[Online], http://www.ndrc.gov.cn/zcfb/zcfbtz/201608/t20160805_814065.html, August5, 2016Qingdao "Integrated Multi-Mode" Parallel Transportation Operation Demo Project. Notice from National Development and Reform Commission.[Online], available:http://www.ndrc.gov.cn/zcfb/zcfbtz/201608/t20160805_814065.html, August 5, 2016 [46] Yuan G, Zhang X, Yao Q M, Wang K F. Hierarchical and modular surveillance systems in ITS. IEEE Intelligent Systems, 2011, 26(5):10-15 doi: 10.1109/MIS.2011.88 [47] Jones N. Computer science:the learning machines. Nature, 2014, 505(7482):146-148 doi: 10.1038/505146a [48] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M, Dieleman S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Graepel T, Hassabis D. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587):484-489 doi: 10.1038/nature16961 [49] Wang F Y, Zhang J J, Zheng X H, Wang X, Yuan Y, Dai X X, Zhang J, Yang L Q. Where does AlphaGo go:from Church-Turing Thesis to AlphaGo Thesis and beyond. IEEE/CAA Journal of Automatica Sinica, 2016, 3(2):113-120 http://www.ieee-jas.org/CN/abstract/abstract145.shtml [50] Huang W L, Wen D, Geng J, Zheng N N. Task-specific performance evaluation of UGVs:case studies at the IVFC. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(5):1969-1979 doi: 10.1109/TITS.2014.2308540 [51] Li L, Huang W L, Liu Y, Zheng N N, Wang F Y. Intelligence testing for autonomous vehicles:a new approach. IEEE Transactions on Intelligent Vehicles, 2016, to be published 期刊类型引用(3)
1. 岳振宇,范大昭,董杨,纪松,李东子. 一种星载平台轻量化快速影像匹配方法. 地球信息科学学报. 2022(05): 925-939 .  百度学术
百度学术2. 王若兰,潘万彬,曹伟娟. 图像局部区域匹配驱动的导航式拼图方法. 计算机辅助设计与图形学学报. 2020(03): 452-461 . 百度学术3. 胡敬双,聂洪玉. 灰度序模式的局部特征描述算法. 中国图象图形学报. 2017(06): 824-832 . 百度学术其他类型引用(9)
-

 下载:
下载:



计量
- 文章访问数: 3735
- HTML全文浏览量: 504
- PDF下载量: 1732
- 被引次数: 12
