

-
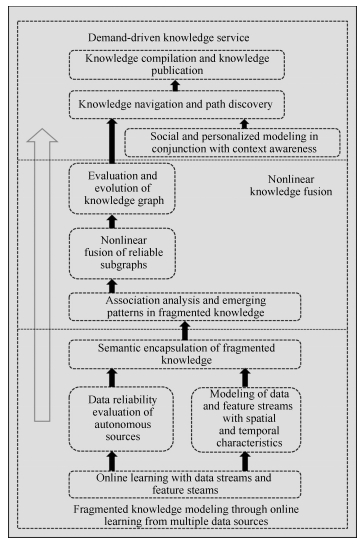
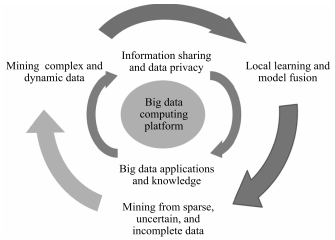
摘要: 大数据面向异构自治的多源海量数据,旨在挖掘数据间复杂且演化的关联.随着数据采集存储和互联网技术的发展,大数据分析和应用已成为各行各业的研发热点.本文从大数据的本质特征开始,评述现有的几种大数据模型,包括5V,5R,4P和HACE定理,同时从知识建模的角度,介绍一种大数据知识工程模型BigKE来生成大知识,并对大知识的前景进行展望.Abstract: Big data deals with heterogeneous and autonomous multi-sources, and aims at mining complex and evolving relationships among data. With the fast development of data collection, data storage and networking technologies, big data analytics has become a hot topic for research and development in various fields. This paper starts with the essential characteristics of big data, reviews existing popular models for big data, including 5V, 5R, 4P and the HACE theorem. Also, from the viewpoint of knowledge modeling, this paper introduces BigKE, a big data knowledge engineering model for big knowldedge, and discusses the challenges and opportunities of big knowledge research and development.
-
Key words:
- Big data /
- knowledge mining /
- heterogeneity /
- fragmented knowledge /
- online learning
-
[1] Beyer M A, Laney D. The importance of "Big Data":a definition[Online], available:https://www.gartner.com/doc/2057415, February 17, 2016 [2] Marr B. Big data:the 5 Vs everyone must know[Online], http://www.linkedin.com/pulse/20140306073407-64875646-big-data-the-5-vs-everyone-must-know, January 21, 2016 [3] Mervis J. Agencies rally to tackle big data. Science, 2013, 336(6077):22-22 http://cn.bing.com/academic/profile?id=1978954664&encoded=0&v=paper_preview&mkt=zh-cn [4] 王飞跃.软件定义的系统与知识自动化:从牛顿到默顿的平行升华.自动化学报, 2015, 42(1):1-8 http://www.aas.net.cn/CN/abstract/abstract18578.shtmlWang Fei-Yue. Software-deined systems and knowledge automation:a parallel paradigm shift from Newton to Merton. Acta Automatica Sinica, 2015, 42(1):1-8 http://www.aas.net.cn/CN/abstract/abstract18578.shtml [5] Fish A N. Knowledge Automation:How to Implement Decision Management in Business Processes. USA:Wiley, 2012. [6] Fernández A, Del Río S, López V, Bawakid A, Del Jesus M J, Benítez J M, Herrera F. Big data with cloud computing:an insight on the computing environment, MapReduce, and programming frameworks. Wiley Interdisciplinary Reviews:Data Mining and Knowledge Discovery, 2014, 4(5):380-409 doi: 10.1002/widm.2014.4.issue-5 [7] Kent S M. Sloan digital sky survey. Science with Astronomical Near-Infrared Sky Surveys. France:Springer, 1994. 27-30 [8] Labrinidis A, Jagadish H V. Challenges and opportunities with big data. Proceedings of the VLDB Endowment, 2012, 5(12):2032-2033 doi: 10.14778/2367502 [9] Knoll A, Meinkoehn J. Data fusion using large multi-agent networks:an analysis of network structure and performance. In:Proceedings of the 1994 IEEE International Conference on MFI'94, Multisensor Fusion and Integration for Intelligent Systems (MFI). Las Vegas, NV:IEEE, 1994. 113-120 [10] Nature Editorial. Community cleverness required. Nature, 2008, 455(7209):1-1 doi: 10.1038/455001a [11] Che D R, Safran M, Peng Z Y. From big data to big data mining:challenges, issues, and opportunities. In:Proceedings of the 18th International Conference on Database Systems for Advanced Applications. Wuhan, China:Springer, 2013. 1-15 [12] Stidston M. Business leaders need R's not V's:the 5 R's of big data[Online], available:https://www.mapr.com/blog/business-leaders-need-r%E2%80%99s-not-v%E2%80%99s-5-r%E2%80%99s-big-data#.U2qmcq1dWIU, December 21, 2015 [13] 王济, 王琦.中医体质研究与4P医学的实施.中国中西医结合杂志, 2012, 32(5):693-695 http://www.cnki.com.cn/Article/CJFDTOTAL-ZZXJ201205035.htmWang Ji, Wang Qi. Chinese constitution research and the practice of 4P medical model. Chinese Journal of Integrated Traditional and Western Medicine, 2012, 32(5):693-695 http://www.cnki.com.cn/Article/CJFDTOTAL-ZZXJ201205035.htm [14] Auffray C, Charron D, Hood L. Predictive, preventive, personalized and participatory medicine:back to the future. Genome Medicine, 2010, 2(8):57-57 doi: 10.1186/gm178 [15] Wu X D, Zhu X Q, Wu G Q, Ding W. Data mining with big data. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(1):97-107 doi: 10.1109/TKDE.2013.109 [16] Wikipedia. Big data[Online], available:https://en.wikipe-dia.org/wiki/Big_data#Definition, December 12, 2015 [17] IDC权威定义大数据概念:满足4V标准[Online], available:http://www.d1net.com/bigdata/news/237143.html, December 12, 2015 [18] Tien J M. Big data:unleashing information. Journal of Systems Science and Systems Engineering, 2013, 22(2):127-151 doi: 10.1007/s11518-013-5219-4 [19] 王元卓, 靳小龙, 程学旗.网络大数据:现状与展望.计算机学报, 2013, 36(6):1125-1138 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201306001.htmWang Yuan-Zhuo, Jin Xiao-Long, Cheng Xue-Qi. Network big data:present and future. Chinese Journal of Computers, 2013, 36(6):1125-1138 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201306001.htm [20] 王卫卫, 李小平, 冯象初, 王斯琪.稀疏子空间聚类综述.自动化学报, 2015, 41(8):1373-1384Wang Wei-Wei, Li Xiao-Ping, Feng Xiang-Chu, Wang Si-Qi. A survey on sparse subspace clustering. Acta Automatica Sinica, 2015, 41(8):1373-1384 [21] Armbrust M, Fox A, Griffith R, Joseph A D, Katz R H, Konwinski A, Lee G, Patterson D A, Rabkin A, Stoica I, Zaharia M. Above the Clouds:A Berkeley View of Cloud Computing, Technical Report UCB/EECS-2009-28, EECS Department, University of California, Berkeley, 2009 http://cn.bing.com/academic/profile?id=2131629857&encoded=0&v=paper_preview&mkt=zh-cn [22] Blaabjerg F, Teodorescu R, Liserre M, Timbus A V. Overview of control and grid synchronization for distributed power generation systems. IEEE Transactions on Industrial Electronics, 2006, 53(5):1398-1409 doi: 10.1109/TIE.2006.881997 [23] Leskovec J, Huttenlocher D, Kleinberg J. Signed networks in social media. In:Proceedings of the 2010 SIGCHI Conference on Human Factors in Computing Systems. New York:ACM, 2010. 1361-1370 [24] Zikopoulos P, Eaton C. Understanding Big Data:Analytics for Enterprise Class Hadoop and Streaming Data. USA:McGraw-Hill Osborne Media, 2011. [25] The four V's of big data[Online], available:http://www.ib-mbigdatahub.com/sites/default/files/infographic_file/4-Vs-of-big-data.jpg, January 21, 2016 [26] Lazer D, Kennedy R, King G, Vespignan A. The parable of google flu:traps in big data analysis. Science, 2014, 343(6176):1203-1205 doi: 10.1126/science.1248506 [27] IBM. What is big data?[Online], available:http://www-01.ibm.com/software/data/bigdata/what-is-big-data.html, December 2, 2015 [28] Barwick H. The "four Vs" of big data. Implementing information infrastructure symposium[Online], available:http://www.computerworld.com.au/article/396198/iiis_four_vs_big_data, December 2, 2015 [29] 数据并非越大越好:谷歌流感趋势错在哪儿了?[Online], available:http://www.guokr.com/article/438117/, December 2, 2015 [30] Ghemawat S, Gobioff H, Leung S T. The Google file system. In:Proceedings of the 19th ACM Symposium on Operating Systems Principles. New York:ACM, 2003. 29-43 [31] Dean J, Ghemawat S. MapReduce:simplified data processing on large clusters. In:Proceedings of the 6th Symposium on Operating Systems Design and Implementation. Berkeley, CA, USA:USENIX Association, 2004. 137-149 [32] Big data solution offering[Online], available:http://mike2.openmethodology.org/wike/Big_Data_Solution_Offering, November 28, 2015 [33] White T. Hadoop:The Definitive Guide (2nd Edition). USA:Yahoo Press, 2010. 1-4 [34] Gupta P, Kumar P, Gopal G. Sentiment analysis on Hadoop with Hadoop streaming. International Journal of Computer Applications, 2015, 121(11):4-8 doi: 10.5120/21582-4651 [35] Liao S H. Expert system methodologies and applications——a decade review from 1995 to 2004. Expert Systems with Applications, 2005, 28(1):93-103 doi: 10.1016/j.eswa.2004.08.003 [36] 吴信东, 叶明全, 胡东辉, 吴共庆, 胡学钢, 王浩.普适医疗信息管理与服务的关键技术与挑战.计算机学报, 2012, 35(5):827-845 doi: 10.3724/SP.J.1016.2012.00827Wu Xin-Dong, Ye Ming-Quan, Hu Dong-Hui, Wu Gong-Qing, Hu Xue-Gang, Wang Hao. Pervasive medical information management and services:key techniques and challenges. Chinese Journal of Computers, 2012, 35(5):827-845 doi: 10.3724/SP.J.1016.2012.00827 [37] Auffray C, Chen Z, Hood L. Systems medicine:the future of medical genomics and healthcare. Genome Medicine, 2009, 1(1):2-2 doi: 10.1186/gm2 [38] 罗旭, 陈博, 罗莉娅, 张宏雁, 吴昊, 李景波. 4P医学理念下医院健康管理体系重构思考.中国医院, 2014, 18(7):61-63 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGYU201407026.htmLuo Xu, Chen Bo, Luo Li-Ya, Zhang Hong-Yan, Wu Hao, Li Jing-Bo. Discussion on reconstructing hospital healthcare management under 4P medical conception. Chinese Hospitals, 2014, 18(7):61-63 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGYU201407026.htm [39] Wu X D, Chen H H, Wu G Q, Liu J, Zheng Q H, He X F, Zhou A Y, Zhao Z Q, Wei B F, Li Y, Zhang Q P, Zhang S C, Lu R Q, Zheng N N. Knowledge engineering with big data. IEEE Intelligent Systems, 2015, 30(5):46-55 doi: 10.1109/MIS.2015.56 [40] Klasnja P, Pratt W. Healthcare in the pocket:mapping the space of mobile-phone health interventions. Journal of Biomedical Informatics, 2012, 45(1):184-198 doi: 10.1016/j.jbi.2011.08.017 [41] Vassis D, Belsis P, Skourlas C, Pantziou G. Providing advanced remote medical treatment services through pervasive environments. Personal and Ubiquitous Computing, 2010, 14(6):563-573 doi: 10.1007/s00779-009-0273-0 [42] 合肥工业大学吴信东:大数据Processing Framework多层架构[Online], available:http://www.csdn.net/article/2012-07-27/2825305, December 7, 2015 [43] Petersen W P, Arbenz P. Introduction to Parallel Computing. Oxford:Oxford University Press, 2004. [44] Corbett J C, Dean J, Epstein M, Fikes A, Frost C, Furman J J, Ghemawat S, Gubarev A, Heiser C, Hochschild P, Hsieh W, Kanthak S, Kogan E, Li H Y, Lloyd A, Melnik S, Mwaura D, Nagle D, Quinlan S, Rao R, Rolig L, Saito Y, Szymaniak M, Taylor C, Wang R, Woodford D. Spanner:Google's globally-distributed database. ACM Transactions on Computer Systems, 2012, 31(3):Article No.8 http://cn.bing.com/academic/profile?id=2112564224&encoded=0&v=paper_preview&mkt=zh-cn [45] Chang F, Dean J, Ghemawat S, Hsieh W C, Wallach D A, Burrows M, Chandra T, Fikes A, Gruber R E. BigTable:a distributed storage system for structured data. ACM Transactions on Computer Systems, 2008, 26(2):Article No.4 http://cn.bing.com/academic/profile?id=1981420413&encoded=0&v=paper_preview&mkt=zh-cn [46] Peel M, Rowley J. Information sharing practice in multi-agency working. ASLIB Proceedings, 2010, 62(1):11-28 doi: 10.1108/00012531011015172 [47] Wang M D, Li B, Zhao Y X, Pu G G. Formalizing Google file system. In:Proceedings of the 20th IEEE Pacific Rim International Symposium on Dependable Computing (PRDC). Singapore:IEEE, 2014. 190-191 [48] Cormode G, Srivastava D. Anonymized data:generation, models, usage. In:Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data. Providence, RI:ACM, 2009. 1015-1018 [49] Sweeney L. k-anonymity:a model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5):557-570 doi: 10.1142/S0218488502001648 [50] Kopanas I, Avouris N M, Daskalaki S. The role of domain knowledge in a large scale data mining project. Methods and Applications of Artificial Intelligence. Thessaloniki, Greece:Springer, 2002. 288-299 [51] Salton G M, Wong A, Yang C S. A vector space model for automatic indexing. Communications of the ACM, 1975, 18(11):613-620 doi: 10.1145/361219.361220 [52] Deerwester S C, Dumais S T, Furnas G W, Landauer T K, Harshman R. Indexing by latent semantic analysis. Journal of the American Society for Information Science, 1990, 41(6):391-407 doi: 10.1002/(ISSN)1097-4571 [53] Freedman E G, Shah P. Toward a model of knowledge-based graph comprehension. Diagrammatic Representation and Inference. Callaway Gardens, GA, USA:Springer, 2002. 18-30 [54] Aral S, Walker D. Identifying influential and susceptible members of social networks. Science, 2012, 337(6092):337-341 doi: 10.1126/science.1215842 [55] Centola D. The spread of behavior in an online social network experiment. Science, 2010, 329(5996):1194-1197 doi: 10.1126/science.1185231 [56] Strassel S, Adams D, Goldberg H, Herr J, Keesing R, Oblinger D, Simpson H, Schrag R, Wright J. The DARPA machine reading program——encouraging linguistic and reasoning research with a series of reading tasks. In:Proceedings of the 7th International Conference on Language Resources and Evaluation. Valletta, Malta:European Language Resources Association, 2010. 986-993 [57] Studer R, Benjamins V R, Fensel D. Knowledge engineering:principles and methods. Data and Knowledge Engineering, 1998, 25(1-2):161-197 doi: 10.1016/S0169-023X(97)00056-6 [58] 潘云鹤, 王金龙, 徐从富.数据流频繁模式挖掘研究进展.自动化学报, 2006, 32(4):594-602 http://www.aas.net.cn/CN/abstract/abstract14320.shtmlPan Yun-He, Wang Jin-Long, Xu Cong-Fu. State-of-the-art on frequent pattern mining in data streams. Acta Automatica Sinica, 2006, 32(4):594-602 http://www.aas.net.cn/CN/abstract/abstract14320.shtml [59] 王珊, 王会举, 覃雄派, 周烜.架构大数据:挑战、现状与展望.计算机学报, 2011, 34(10):1741-1752 doi: 10.3724/SP.J.1016.2011.01741Wang Shan, Wang Hui-Ju, Qin Xiong-Pai, Zhou Xuan. Architecting big data:challenges, studies and forecasts. Chinese Journal of Computers, 2011, 34(10):1741-1752 doi: 10.3724/SP.J.1016.2011.01741 [60] Guha S, Mishra N, Motwani R, O'Callaghan L. Clustering data streams. In:Proceedings of the 41st Annual Symposium on Foundations of Computer Science. Redono Beach, USA:IEEE, 2000. 359-366 [61] 朱群, 张玉红, 胡学钢, 李培培.一种基于双层窗口的概念漂移数据流分类算法.自动化学报, 2011, 37(9):1077-1084 http://www.aas.net.cn/CN/abstract/abstract17531.shtmlZhu Qun, Zhang Yu-Hong, Hu Xue-Gang, Li Pei-Pei. A double-window-based classification algorithm for concept drifting data streams. Acta Automatica Sinica, 2011, 37(9):1077-1084 http://www.aas.net.cn/CN/abstract/abstract17531.shtml [62] 张昕, 李晓光, 王大玲, 于戈.数据流中一种快速启发式频繁模式挖掘方法.软件学报, 2005, 16(12):2099-2105 doi: 10.1360/jos162099Zhang Xin, Li Xiao-Guang, Wang Da-Ling, Yu Ge. A high-speed heuristic algorithm for mining frequent patterns in data stream. Journal of Software, 2005, 16(12):2099-2105 doi: 10.1360/jos162099 [63] Wu X D, Yu K, Ding W, Wang H, Zhu X Q. Online feature selection with streaming features. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(5):1178-1192 doi: 10.1109/TPAMI.2012.197 [64] Zhang Q, Zhang P, Long G D, Ding W, Zhang C Q, Wu X D. Towards mining trapezoidal data streams. In:Proceedings of the 2015 IEEE International Conference on Data Mining (ICDM'15). Atlantic City, NJ, USA:IEEE, 2015. 1111-1116 [65] Wu X D, Yu K, Wang H, Ding W. Online streaming feature selection. In:Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel, 2010. 1159-1166 [66] Kivinen J, Smola A J, Williamson R C. Online learning with kernels. IEEE Transactions on Signal Processing, 2004, 52(8):2165-2176 doi: 10.1109/TSP.2004.830991 [67] Kimeldorf G, Wahba G. Some results on Tchebycheffian spline functions. Journal of Mathematical Analysis and Applications, 1971, 33(1):82-95 doi: 10.1016/0022-247X(71)90184-3 [68] Zhou Z H, Chawla N V, Jin Y C, Williams G J. Big data opportunities and challenges:discussions from data analytics perspectives[Discussion forum]. IEEE Computational Intelligence Magazine, 2014, 9(4):62-74 doi: 10.1109/MCI.2014.2350953 [69] Vijayakumar S, D'Souza A, Schaal S. Incremental online learning in high dimensions. Neural Computation, 2005, 17(12):2602-2634 doi: 10.1162/089976605774320557 [70] Hunter A, Summerton R. Fusion rules for context-dependent aggregation of structured news reports. Journal of Applied Non-Classical Logics, 2004, 14(3):329-366 doi: 10.3166/jancl.14.329-366 [71] Žliobaitė I. Learning under concept drift:an overview. Computer Science——Artificial Intelligence[Online], available:http://arxiv.org/abs/1010.4784, May 31, 2015 [72] 李建中, 刘显敏.大数据的一个重要方面:数据可用性.计算机研究与发展, 2013, 50(6):1147-1162 http://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201306006.htmLi Jian-Zhong, Liu Xian-Min. An important aspect of big data:data usability. Journal of Computer Research and Development, 2013, 50(6):1147-1162 http://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201306006.htm [73] Samarati P, Sweeney L. Protecting privacy when disclosing information:k-anonymity and its enforcement through generalization and suppression. In:Proceedings of the 1998 IEEE Symposium on Research in Security and Privacy. Palo Alto, CA:IEEE, 1998. 1-19 [74] 王超, 杨静, 张健沛.基于轨迹特征及动态邻近性的轨迹匿名方法研究.自动化学报, 2015, 41(2):330-341 http://www.aas.net.cn/CN/abstract/abstract18612.shtmlWang Chao, Yang Jing, Zhang Jian-Pei. Research on trajectory privacy preserving method based on trajectory characteristics and dynamic proximity. Acta Automatica Sinica, 2015, 41(2):330-341 http://www.aas.net.cn/CN/abstract/abstract18612.shtml [75] Wu X D, Zhu X Q. Mining with noise knowledge:error-aware data mining. IEEE Transactions on Systems, Man, and Cybernetics——Part A:Systems and Humans, 2008, 38(4):917-932 doi: 10.1109/TSMCA.2008.923034 [76] He H B, Garcia E A. Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9):1263-1284 doi: 10.1109/TKDE.2008.239 [77] 王飞跃.迈向知识自动化[Online], available:http://www.cas.cn/xw/zjsd/201401/t20140103_4009925.shtml, June 1, 2016 [78] 邓建玲, 王飞跃, 陈耀斌, 赵向阳.从工业4.0到能源5.0:智能能源系统的概念、内涵及体系框架.自动化学报, 2015, 41(12):2003-2016 http://www.aas.net.cn/CN/abstract/abstract18774.shtmlDeng Jian-Ling, Wang Fei-Yue, Chen Yao-Bin, Zhao Xiang-Yang. From industries 4.0 to energy 5.0:concept and framework of intelligent energy systems. Acta Automatica Sinica, 2015, 41(12):2003-2016 http://www.aas.net.cn/CN/abstract/abstract18774.shtml [79] Twitter Blog. Dispatch from the Denver debate[Online], available:http://blog.twitter.com/2012/100dispatch-reom-denver-debate.html, October 1, 2012 [80] Chun D X, Jun C J, Zhong C Y, Chao T M, Cong P. Data engineering in information system construction. In:Proceedings of the 2012 IEEE Symposium on Robotics and Applications (ISRA). Kuala Lumpur:IEEE, 2012. 135-137 [81] Aggarwal C C. . US:Springer, 2007. [82] Silva J A, Faria E R, Barros R C, Hruschka E R, de Carvalho A C P L F, Gama J. Data stream clustering:a survey. ACM Computing Surveys, 2013, 46(1):Article No.13 http://cn.bing.com/academic/profile?id=2088340225&encoded=0&v=paper_preview&mkt=zh-cn [83] Patil P D, Kulkarni P. Adaptive supervised learning model for training set selection under concept drift data streams. In:Proceedings of the 2013 International Conference on Cloud and Ubiquitous Computing and Emerging Technologies. Pune:IEEE, 2013. 36-41 [84] Hakkani-Tür D, Heck L, Tur G. Using a knowledge graph and query click logs for unsupervised learning of relation detection. In:Proceedings of the 2013 IEEE International Conference on Acoustics, Speech, and Signal Processing. Vancouver, BC:IEEE, 2013. 8327-8331 [85] Dantas J R V, Farias P P M. Conceptual navigation in knowledge management environments using NavCon. Information Processing and Management, 2010, 46(4):413-425 doi: 10.1016/j.ipm.2009.08.007 [86] Xu C J, Li A P, Liu X M. Knowledge fusion and evaluation system with fusion-knowledge measure. In:Proceedings of the 2nd International Symposium on Computational Intelligence and Design. Changsha, China:IEEE, 2009. 127-131 [87] Shahabi C, Zarkesh A M, Adibi J, Shah V. Knowledge discovery from users web-page navigation. In:Proceedings of the 7th International Workshop on Research Issues in Data Engineering. Birmingham:IEEE, 1997. 20-29 [88] Baldauf M, Dustdar S, Rosenberg F. A survey on context-aware systems. International Journal of Ad Hoc and Ubiquitous Computing, 2007, 2(4):263-277 doi: 10.1504/IJAHUC.2007.014070 [89] Herlocker J L, Konstan J A, Terveen L G, Riedl J T. Evaluating collaborative filtering recommender systems. ACM Transactions on Information Systems, 2004, 22(1):5-53 doi: 10.1145/963770 [90] 岳元龙, 左信, 罗雄麟.提高测量可靠性的多传感器数据融合有偏估计方法.自动化学报, 2014, 40(9):1843-1852 http://www.aas.net.cn/CN/abstract/abstract18453.shtmlYue Yuan-Long, Zuo Xin, Luo Xiong-Lin. Improving measurement reliability with biased estimation for multi-sensor data fusion. Acta Automatica Sinica, 2014, 40(9):1843-1852 http://www.aas.net.cn/CN/abstract/abstract18453.shtml [91] Xu C, Zhang Y Q, Li R Z. On the feasibility of distributed kernel regression for big data. Statistics[Online], available:http://arxiv.org/abs/1505.00869, May 31, 2016 -

 下载:
下载:

图(2)
计量
- 文章访问数: 4087
- HTML全文浏览量: 685
- PDF下载量: 2951
- 被引次数: 0
