

Two-stage Optimal Modeling and Algorithm of Production Scheduling for Steelmaking and Continuous Casting
-
摘要: 以某钢厂多台转炉及多台精炼炉对多台连铸机的复杂生产线为研究对象,针对其调度过程涉及多设备、多目标、多约束等调度要素,且离散和连续变量混杂,采用常规建模方法难以满足现场对调度的精度及排产速度的需求问题,提出一种新型的两阶段优化建模方法.首先,证明了炉次从炼钢到连铸总等待时间最小的调度目标与该炉次在转炉开始作业时间最大是等价的事实,并以离散型的设备变量为决策变量,以转炉开始作业时间最大为动态规划最优指标,建立设备指派多阶段动态规划基本方程和设备指派优化模型;然后,以炉次在设备开始作业时间的连续型变量为决策变量,并将准时开浇的非线性调度指标转化成与之等价的线性优化目标,以在同一台连铸机上浇铸的炉次之间断浇的时间间隔最小、钢包在设备之间的冗余等待时间最小、提前与滞后理想开浇时间的时间间隔最小为目标,建立线性规划冲突解消模型.工业实验表明所提出两阶段优化建模方法在求解速度与求解精度均满足现场要求.Abstract: Steelmaking and continuous casting production scheduling is a multi-equipment assignment, multi-objective, multi-constraint, discrete and continuous variables hybrid optimization problem. Traditional modeling and solving methods are usually adopted to solve it, but they cannot meet the requirement in terms of high scheduling accuracy and fast problem solving speed. A new two-stage optimal modeling algorithm is proposed in this paper. In stage one, we show that minimizing the waiting time from steelmaking to continuous casting is equivalent to maximizing the converter operating time at first. Then we built a multiple-stage dynamic programming equation and optimization model using discrete variables, with the goal of maximizing the converter operating time. In stage two, we establish a linear programming conflict elimination model using continuous variables by converting a non-linear performance index into two equavalent linear optimization indexes including lead time, lag time between pratical casting and planned casting, and combining the other two indexes including time gap between furnaces on same caster and waiting duration for steel ladle among converters, refining furnaces and casters. On-site industry application validates that the proposed method can solve the scheduling problem with high speed and accuracy.
-
随机噪声与有界噪声 同时干扰自动控制系统的现象普遍存在, 例如, 在雷达跟踪系统中, 接收系统的热噪声以及天线受到阵风的影响是典型的随机噪声 [1], 而加速度的物理特性、外界未知环境不确定干扰等噪声因素的影响, 相比其随机统计特性获得边界是更加可行的 [2]; 单晶在生长控制过程中, 一方面受到随机对流的作用, 另一方面温度场按偏微分方程演化, 而在用有限元方法求解偏微分方程时, 需要对不规则区域用三角形进行分割, 对于分割接近边界邻域的狭小部分通常会忽略, 忽略的这部分是有界不确定性; 对于非线性随机系统, 在用扩展卡尔曼滤波(Extended Kalman filter, EKF)时, 线性化过程中同样也忽略了高阶余项. 这些实例都表明, 系统存在两种不确定性, 一种是概率统计特性已知的随机不确定性, 而另一种是已知边界的有界不确定性, 当两种不确定性同时存在时, 本文称之为双重不确定性.
系统的不确定性分析存在两种方法 [3], 概率方法和非概率方法, 而选择采用哪种方法往往取决于样本统计数据的多少及其性质. 概率方法需要知道随机变量的概率统计特性, 而区间分析理论(非概率方法)解决不确定问题需要已知有界不确定参数或变量所在范围的边界. 概率方法适合解决随机不确定, 而非概率方法适合解决有界不确定. 在不确定系统的状态估计问题中, 卡尔曼滤波是一种典型的概率方法, 集员滤波(Set-membership filter, SMF) [4-7]是一种典型的非概率方法. 两种滤波方法中, 卡尔曼滤波以贝叶斯推理为基础, 解决了高斯白噪声假设下线性系统状态的最优估计问题; SMF以包含系统真实状态的外定界椭球集合为基础, 只要求系统噪声有界, 且噪声界已知, 而不需要知道边界内噪声的统计特性. 相比卡尔曼滤波在每一步估计得到的是一个状态值, SMF得到的是一个椭球集合, 且此集合内的值都是可行解. 因此, 两种滤波方法有各自的适用范围, 且都在工程实践中得到广泛的应用 [8-10]. 对于存在两种不确定性的混合噪声系统, 非高斯白噪声的存在使单一卡尔曼滤波的估计结果往往过分乐观 [11], 甚至收敛性也不能保证; 高斯白噪声的存在导致单一SMF选取的噪声边界会过分保守, 估计精度下降. 总之, 现有方法一般都是假设一种噪声的存在, 意味着人为地排除了另一种噪声. 为克服这些单一滤波算法的局限性, 研究具有双重不确定性系统的滤波问题有重要的理论价值和实际应用前景.
然而处理双重不确定性噪声模型问题的研究还处于起步阶段, 如何将随机不确定性和有界不确定性整合成一个混合的数学描述, 是一个挑战性问题 [12]. 面对这个难题, 相关文献已经提出的能够结合两种不确定的数学形式有: 随机集合、集合概率密度以及其他不精确概率描述方法. Hanbeck等 [13]利用随机集合提出的统计和集合论信息(Statistical and set-theoretic information, SSI)滤波器, 其特点是传统单一的滤波方法得到的值只是SSI滤波器的边界情况, 即当随机噪声为零时, 收敛于集合估计; 当有界误差为零时, 收敛于贝叶斯估计, 该方法的局限性在于只能解决线性标量状态. Noack等 [14]采用集合密度的概念来描述双重不确定性, 即用适合描述不确定集合的集合概率密度取代了单一概率密度函数. Klumpp等 [15]比较了基于随机集合的SSI滤波器和基于集合概率密度的CS (Credal state)滤波器, 得出CS滤波器具有更加保守的特点. Henningsson [16]用椭球包含混合噪声中有界集合部分的估计误差, 通过线性矩阵不等式得到最优滤波增益, 该算法的性能受到一个权系数的影响, 而该系数的取值取决于实际系统总体噪声中随机不确定和有界不确定的某种权重关系, 且这种权重关系并没有定量地给出. Liu等 [17]提出的椭球集合滤波算法在解决纯方位机动目标的跟踪问题时, 在集员椭球更新的过程中考虑了随机不确定性, 得到了跟踪性能优于单一EKF的结论.
本文根据随机不确定性和有界不确定性对估计结果影响的各自特点, 将统计特性未知但有界的(Unknown but bounded, UBB)噪声引入到卡尔曼滤波模型中, 得到一组包含集合运算的卡尔曼滤波方程. 其中的UBB噪声应用SMF的思想进行处理, 而随机噪声应用卡尔曼滤波的思想进行处理, 实现了两种滤波方法的联合处理. 文章的最后将该算法推广到非线性系统中.
1. 数学基础
1.1 数学模型
为了处理包含随机噪声和UBB噪声系统, 需要建立能够正确描述该系统的数学模型, 因此, 系统状态方程可写成如下形式
${ x}_{k}=f_{k}( {x}_{k-1}, {w}_{k} , {d}_{k}) $
(1) 式中${x}_{k}$为k时刻n维状态向量, ${ w}_{k}$、${ d}_{k}$为过程噪声, 其中${w}_{k}\sim {\rm N}(0, Q_{k})$属于零均值高斯白噪声, $Q_{k}$为过程噪声的非负定协方差矩阵, ${ d}_{k}\in D_{k}\subset R^{n}$为UBB噪声, $D_{k}$为边界已知的有界集合.
测量方程
${{y}_{k}}={{h}_{k}}({{x}_{k, }}{{v}_{k}}, {{e}_{k}})$
(2) 式中${ y}_{k}$为k时刻m维测量输出, ${ v}_{k}$、${ e}_{k}$为测量噪声, 其中${ v}_{k}\sim {\rm N}(0, R_{k})$属于零均值高斯白噪声, $R_{k}$为测量噪声的正定协方差矩阵, ${ e}_{k}\in E_{k}\subset R^{m}$为UBB噪声, $E_{k}$为边界已知的有界集合.
这时, 我们得到了包含高斯白噪声和UBB噪声的双重不确定性非线性系统. 在解决非线性模型的滤波问题中, 非线性模型可以通过线性化来近似表示, 为了易于说明, 首先考虑系统是线性的式(1)和式(2)写成如下形式
${{x}_{k}}={{A}_{k}}{{x}_{k-1}}+{{B}_{k}}({{w}_{k}}+{{d}_{k}})$
(3) ${{y}_{k}}={{H}_{k}}{{x}_{k}}+{{v}_{k}}+{{e}_{k}}$
(4) 假设在模型中UBB噪声${ d}_{k}=0$、${ e}_{k}=0$, 即典型的随机模型, 此时该模型满足经典卡尔曼滤波条件, 其一步状态预测方程为
$\hat{{ x}}_{k, k-1}=A_{k}\hat{{ x}}_{k-1} $
(5) 预测估计协方差矩阵
$P_{k, k-1}=A_{k}P_{k-1}A^{{\rm T}}_{k}+B_{k}Q_{k}B_{k}^{\rm T} $
(6) 滤波增益
$K_{k}=P_{k, k-1}H^{\rm T}_{k}[H_{k}P_{k, k-1}H^{\rm T}_{k}+R_{k}]^{-1} $
(7) 更新状态估计值
${{{\hat{x}}}_{k}}={{{\hat{x}}}_{k, k-1}}+{{K}_{k}}[{{y}_{k}}-{{H}_{k}}{{{\hat{x}}}_{k, k-1}}]=(I-{{K}_{k}}{{H}_{k}}){{{\hat{x}}}_{k, k-1}}+{{K}_{k}}{{y}_{k}}$
(8) 更新估计协方差矩阵
$P_{k}=[I-K_{k}H_{k}]P_{k, k-1} $
(9) 如果考虑UBB噪声项, 由于高斯白噪声一阶矩为常数, 不会引起系统变量均值的变化, 而UBB噪声会引起均值的偏移, 因此均值不再是唯一值, 定义如下集合
${{\delta }_{k}}=\{{{d}_{k}}|{{d}_{k}}\in {{D}_{k}}\}{{\psi }_{k}}=\{{{y}_{k}}-{{e}_{k}}|{{e}_{k}}\in {{E}_{k}}\}$
(10) ${{\psi }_{k}}=\{{{y}_{k}}-{{e}_{k}}|{{e}_{k}}\in {{E}_{k}}\}$
(11) 式中 ${\delta_{k}}$为UBB噪声均值集合, ${\psi_{k}}$为测量输出均值集合. 当系统包含UBB噪声集合后, 可以将点运算变为集合运算. 那么类似于式(5)和式(8), 状态的一步预测和更新分别可写成集合运算的形式
${{\chi }_{k, k-1}}={{A}_{k}}{{\chi }_{k-1}}\oplus {{B}_{k}}{{\delta }_{k}}{{\chi }_{k}}=(I-{{K}_{k}}{{H}_{k}}){{\chi }_{k, k-1}}\oplus {{K}_{k}}{{\psi }_{k}}$
(12) ${{\chi }_{k}}=(I-{{K}_{k}}{{H}_{k}}){{\chi }_{k, k-1}}\oplus {{K}_{k}}{{\psi }_{k}}$
(13) ${\chi_{k}}$称为条件均值集合, 符号$\oplus$表示椭球的闵可夫斯基 (Minkowski)和. 在随后的内容中, 我们通过适当的方法参数化这些集合, 推导出一个能够处理线性系统的估计方法.
如果考虑系统是非线性的, 滤波过程中就需要对非线性系统线性化, 然而在这类混合噪声模型中, 此时估计的并不是一个值, 而是一个状态集合, 因此, EKF中用的线性化方法在处理该问题时并不适用, 如何找到一种合适的近似方法将在第2.2节中讨论.
这里建立的双重不确定性模型, 都是假定合理有效的. 然而由于实际系统中噪声的复杂性, 建立合理有效的模型并不容易. 事实上, 随机和有界很难严格地划分, 并且也可以近似地相互转换. 例如, 高斯白噪声, 如果用有界的形式表示, 可以采用$3\sigma$置信区间, 选取的噪声边界为高斯白噪声方差$\sigma$的3倍, 那么噪声在$3\sigma$区间的概率为$99.73 %$. 对于有些情况下定义的有界噪声, 并非是指边界内噪声的统计特性完全未知, 可能的情况是统计特性已知但属于非高斯分布, 当非高斯程度较小时, 这时完全可以根据有界噪声的期望和方差来转化为近似高斯分布的随机噪声. 因此, 只有对实际噪声的合理划分, 才能建立合理有效的双重不确定性模型, 但这需要对系统进行大量的分析和实践.
1.2 椭球集合及其运算性质
在给出的双重不确定性模型中, 我们已经分离出模型的有界部分, SMF是一种基于集合论的估计方法, 解决了有界集合如何被椭球近似包含的问题, 以及滤波过程中的集合运算问题. 下面介绍集员相关的定义与定理.
假设线性动态模型存在UBB噪声, 在此条件下, 状态估计由点估计变为一个状态可行集合的估计问题, UBB噪声集合和状态可行集均可以用椭球集合来近似描述.
定义 1. 椭球集合$F( {a}, S)$可以表示为
$F(a, S)=\{x\in {{R}^{n}}|{{(x-a)}^{\text{T}}}{{S}^{-1}}(x-a)\le 1\}$
(14) 式中${ a}$为椭球中心, $S\in R^{n\times n}$为对称正定矩阵, 度量椭球的形状大小.
定义 2. 椭球$F( {a}, S)$的支持函数 [5]可表示为
$\eta (F(a, S))={{\eta }_{\beta }}(\alpha )={{\max }_{\beta \in F(a}}, S){{\beta }^{\text{T}}}\alpha ={{\alpha }^{\text{T}}}a+{{({{\alpha }^{\text{T}S}}\alpha )}^{\frac{1}{2}}}, \ \ \alpha \in {{R}^{n}}\ \ \ \ \ \ $
(15) 这里注意$\eta(\cdot)$与$\eta_{{ \beta}}(\cdot)$的区别, $\eta(\cdot)$的自变量为椭球集合, $\eta_{{ \beta}}(\cdot)$的自变量为向量.
去掉上式中max函数, 得到不等式形式
${{\beta }^{\text{T}}}\alpha \le {{\eta }_{\beta }}(\alpha )={{\alpha }^{\text{T}}}a+{{({{\alpha }^{\text{T}S}}\alpha )}^{\frac{1}{2}}}, \{\beta \in F(a, S), \ \ \ \alpha \in {{R}^{n}}$
(16) 引理 1. 支持函数存在如下运算性质: 椭球集合$F({a_1},{S_1}),F({a_2},{S_2}) \subseteq {R^n}$, 其支持函数的Minkowski和存在以下性质
$\eta (F({a_1},{\rm{ }}{S_1}) \oplus F({a_2},{S_2})) = \eta (F({a_1},{\rm{ }}{S_1})) + \eta (F({a_2},{S_2}))$
(17) 根据引理1中支持函数的性质, 假设式(12)中条件均值集合$ \chi_{k-1}$和UBB噪声的边界集合${\delta_{k}}$包含在椭球集合(闭凸集)内, 将式(12)写成如下支持函数计算形式
$\eta ({{\chi }_{k, k-1}})=\text{ }\eta ({{A}_{k}}{{\chi }_{k-1}}\oplus {{B}_{k}}{{\delta }_{k}})=\eta ({{A}_{k}}{{\chi }_{k-1}})+\eta ({{B}_{k}}{{\delta }_{k}})$
(18) 由于集合的线性运算保留集合"凸"的特性, 那么预测条件均值集合$ \chi_{k, k-1}$为凸集.
同样假设测量输出集合$ \psi_{k}$也包含在椭球集合内, 那么式(13)可写成
$\begin{align} &\eta (\chi k)=\eta ((I-{{K}_{k}}{{H}_{k}}){{\chi }_{k, k-1}}\oplus {{K}_{k}}{{\psi }_{k}})= \\ &\eta ((I-{{K}_{k}}{{H}_{k}}){{\chi }_{k, k-1}})+\eta ({{K}_{k}}{{\psi }_{k}}) \\ \end{align}$
(19) 同理, 计算得到的更新条件均值集合$\chi_{k}$也是凸集. 可以看出, 支持函数将椭球集合运算中Minkowski和转换为加法.
根据上面的内容可知, 滤波模型中加入了有界集合, 有界集合可以用椭球集合来包含. 定义1给出了椭球集合的描述, 但该描述下的两个椭球集合不能直接进行运算, 因此, 定义2给出了椭球集合的支持函数, 引理1给出了支持函数的运算性质. 虽然引理1中的$F({{a}_{1}}和{{S}_{1}})F({{a}_{2}}$的Minkowski和求出的是一个凸集, 但并不意味着该凸集是一个确定形状大小的集合. 也就是说, 两个椭球集合的Minkowski和不会产生一个新的椭球, 例如式(18)中的凸集 $\chi_{k, k-1}$形状大小就不能确定. 一般可行的方法就是找到包含两个椭球集合$F({a}_{1}, S_{1})$和 $F( {a}_{2}, S_{2})$ Minkowski和的外定界椭球$F({a}, S)$, 如图 1所示.
下面通过如下定理, 找到某种最优准则下的外定界椭球$F( {a}, S)$.
定理 1. $F( {a}, S)$为椭球集合, A为已知n维方阵, 则
$AF(a, S)=F(Aa, ASA\text{T})$
(20) 证明. $F( {a}, S)$用支持函数形式表示, 那么
$AF(a, S)=A[{{\alpha }^{\text{T}}}a+{{({{\alpha }^{\text{T}S}}\alpha )}^{\frac{1}{2}}}]=A{{\alpha }^{\text{T}}}a+{{({{\alpha }^{\text{T}A}}^{\text{T}}SA\alpha )}^{\frac{1}{2}}}=F(Aa, AS{{A}^{\text{T}}})$
(21) 定理 2. 已知椭球$F( {a}_{1}, S_{1})$、$F( {a}_{2}, S_{2})$, 包含两个椭球集合Minkowski和的外定界椭球$F( {a}, S)$可以表示为
$F(a, S)=F({{a}_{1}}, {{S}_{1}})\oplus F({{a}_{2}}, {{S}_{2}})=F({{a}_{1}}+{{a}_{2}}, S(p))$
(22) 式中
$\left\{ \matrix{ a = {a_1} + {a_2} \hfill \cr S(p) = (1 + {p^{ - 1}}) \hfill \cr {S_1} + (1 + p){S_2},\;p > 0 \hfill \cr} \right.\;$
证明. 考虑两个椭球$F( {a}_{1}, S_{1})$、$F( {a}_{2}, S_{2})$,
$F({{a}_{i}}, {{S}_{i}})=\{x\in {{R}^{n}}|{{(x-{{a}_{i}})}^{\text{T}}}S_{i}^{-1}\times (x-{{a}_{i}})\le 1\}, \ \ \ i=1, 2$
(23) 假定一个椭球
$F(a, S)=\{x\in {{R}^{n}}|{{(x-a)}^{\text{T}}}{{S}^{-1}}(x-a)\le 1\}$
(24) 如图 1所示, 由于两个椭球的Minkowski和并不能直接表示为一个椭球, 为了使椭球$F( {a}, S)$ 能够包含椭球$F( {a}_{1}, S_{1})$和$F( {a}_{2}, S_{2})$的Minkowski和, 则必须满足不等式 [5]
$\eta (F(a, S)) \ge \eta (F({a_1}, {S_1})) + \eta (F({a_2}, {S_2}))$
(25) 式中$\eta(\cdot)$为支持函数, 根据支持函数的定义, 则
${\alpha ^{\rm{T}}}a + {({\alpha ^{\rm{T}}}S\alpha )^{{1 \over 2}}} \ge {\alpha ^{\rm{T}}}{a_1} + {({\alpha ^{\rm{T}}}{S_1}\alpha )^{{1 \over 2}}} + {\alpha ^{\rm{T}}}{a_2} + {({\alpha ^{\rm{T}}}{S_2}\alpha )^{{1 \over 2}}}$
(26) 取外定界椭球中心
${ a}={ a}_{1}+{ a}_{2} $
(27) 取正定矩阵S为$S_{1}$与$S_{2}$的线性组合
$S=\gamma S_{1}+ \rho S_{2} $
(28) 那么式(26)可以表示为
$\gamma {{\alpha }^{\text{T}}}{{S}_{1}}\alpha +\rho {{\alpha }^{\text{T}}}{{S}_{2}}\alpha \ge {{\alpha }^{\text{T}}}{{S}_{1}}\alpha +2{{(\alpha \text{T}{{S}_{1}}\alpha )}^{\frac{1}{2}}}{{({{\alpha }^{\text{T}}}{{S}_{2}}\alpha )}^{\frac{1}{2}}}+{{\alpha }^{\text{T}}}{{S}_{2}}\alpha $
(29) 令$g_{1}^{2}={ \alpha}^{\rm T}S_{1}{ \alpha}$, $g_{2}^{2}={ \alpha}^{\rm T}S_{2}{ \alpha}$, 并乘以因子$\gamma-1$, 则上式变为
$[(\gamma-1)g_{1}-g_{2}]^{2}+[(\gamma-1)(\rho-1)-1]g_{2}^{2}\geq 0 $
(30) 显然, 当满足下式时, 不等式(30)必然成立
$(\gamma-1)(\rho-1)\geq 1 $
(31) 令可行标量p满足$\gamma-1=p^{-1}$, $\rho-1\geq p$, 则
$\gamma=1+p^{-1}\\rho=1+p $
(32) $rho=1+p$
(33) 即$S(p)$可以表示为
$S(p)=(1+{{p}^{-1}}){{S}_{1}}+(1+p){{S}_{2}}, \ \ \ p>0$
(34) 已知椭球集合描述中的S表征椭球的形状大小, 通过定理2可以看出, 包含两个椭球的Minkowski和的外定界椭球是关于形状大小矩阵$S(p)$的函数, p为引入的可行标量, 不同的p对应不同的矩阵S, 不同 的S又对应不同形状大小的外定界椭球, 在所有这些外定界椭球中, 希望找到某种优化意义下的封闭椭球.
定理 3. 外定界椭球$F( {a}, S(p))$中的最优椭球, 可在如下两种不同最优意义下获得 1)容积最小意义下的最小容积椭球可由如下方程计算
$\sum\limits_{i=1}{n}{{\lambda }_{i}}({{S}_{1}}S_{2}^{-1)+p}=np(p+1), \ \ \ p>0$
(35) 其中, ${{\lambda }_{i}}({{S}_{1}}{{S}_{2}}^{-1})$为矩阵 $S_{1}S_{2}^{-1}$ 的特征值, n 为状态维数.
2)半轴平方和最小意义下的最小迹椭球可由如下方程计算
$p=\text{tr}({{S}_{1}})\text{tr}({{S}_{2}})$
(36) 证明. 最小化椭球$F( {a}, S)$的容积等价于求取椭球形状大小矩阵的最小行列式 [18]
$f(p)=\det (S(p))=\det ((1+{{p}^{-1}}){{S}_{1}}+(1+p){{S}_{2}}), \ \ \ p>0$
(37) 即等价于求取方程(35)特征值.
最小化椭球$F( {a}, S)$的最小迹等价于求取如下函数的最小值
$f(p)=\text{tr}(S(p))=\text{tr}((\text{1+}{{\text{p}}^{\text{-1}}}){{\text{S}}_{\text{1}}}\text{+}(\text{1+p})\text{2}), \ \ \ \text{p}>\text{0}$
(38) 即等价于求取式(36). 可以看出, p可以在不同的最优意义下计算得到. 获得最小容积椭球的计算需要求解方程(35), 需要较大的计算量, 而通过式(36)获得最小迹椭球计算简单. 此外, 迹是更加适当的标准, 因为半轴的最大长度等价于一个有界误差的最大边界.
2. 联合滤波算法
基于前面集员的知识, 本文提出一种包含椭球集合运算, 且同时能够处理随机和有界噪声的滤波算法 该算法将噪声的随机部分和有界部分分别处理, 随机部分的处理运用卡尔曼滤波的思想, 而有界部分的处理运用SMF的思想, 由于该算法结合了两种滤波思想, 我们将其称之为联合滤波. 下面将线性系统和非线性系统分别展开讨论.
2.1 线性系统
时间更新
线性系统状态方程见式(3), 式中, 状态向量${{x}_{k-1}}\in {{\chi }_{k-1}}\subseteq F({{a}_{k-1}}, {{S}_{k-1}})$, 其中$F( {a}_{k-1}, S_{k-1})$为椭球集合, 且其协方差矩阵为$P_{k-1}$. 系统被零均值高斯白噪声${ w}_{k}$和UBB噪声${ d}_{k}$同时污染, 其中${ w}_{k}$的协方差矩阵为$Q_{k}$, 且${ d}_{k}\in {\delta_{k}}\subseteq F({0}, D_{k})$. 由于高斯白噪声的均值和UBB噪声的中心都为零, 那么将两种噪声结合在一起, 其均值的集合也包含在椭球集合$F({0}, D_{k})$内, 其协方差矩阵记为$Q_{k}$.
状态集合一步预测
${{\chi }_{k, k-1}}={{A}_{k}}{{\chi }_{k-1}}\oplus {{B}_{k}}{{\delta }_{k}}\subseteq F({{a}_{k, k-1}}, {{S}_{k, k-1}})$
(39) 此时的状态用椭球集合表示. 由于椭球集合${\delta_{k}}$中心为0, 依据定理1及定理2, 包含状态集合$ \chi_{k, k-1}$的外定界椭球$F( {a}_{k, k-1}, S_{k, k-1})$的中心值$ {a}_{k, k-1}$为
${ a}_{k, k-1}=A_{k}{ a}_{k-1} $
(40) 表征椭球形状大小的矩阵$S_{k, k-1}$为
${{S}_{k, k-1}}=(1+{{p}^{-1}}){{A}_{k}}{{S}_{k-1}}A_{k}^{\text{T}}+(1+p){{B}_{k}}{{D}_{k}}B_{k}^{\text{T}}$
(41) 式中p的选择依据定理3的结论.
协方差矩阵一步预测
$P_{k, k-1}=A_{k}P_{k-1}A^{\rm T}_{k}+B_{k}Q_{k}B^{\rm T}_{k} $
(42) 测量更新 线性系统测量方程见式(4), 同样, 式中包含两种测量噪声, ${ v}_{k}$为高斯白噪声, 其均值为0且协方差矩阵为$R_{k}$. ${ e}_{k}$为UBB噪声, 其包含在椭球$F({0}, Y_{k})$内. 可以得出$( {y}_{k}-{ e}_{k})\in\psi_{k}$包含在椭球集合$F( {y}_{k}, Y_{k})$内.
状态估计集合
${{\chi }_{k}}=(I-{{K}_{k}}{{H}_{k}}){{\chi }_{k, k-1}}\oplus {{K}_{k}}{{\psi }_{k}}$
(43) 滤波增益
${{K}_{k}}={{P}_{k, k-1}}H_{k}^{\text{T}}{{({{H}_{k}}{{P}_{k, k-1}}H_{k}^{\text{T}}+{{R}_{k}})}^{-1}}$
(44) 类似预测步骤, 包含状态集合$\chi_{k}$的外定界椭球$F( {a}_{k}, S_{k})$的中心${ a_{k}}$为
${{a}_{k}}=(I-{{K}_{k}}{{H}_{k}}){{a}_{k, k-1}}+{{K}_{k}}{{y}_{k}}$
(45) 表征椭球形状大小的矩阵为
${{S}_{k}}=(1+{{q}^{-1}})(I-{{K}_{k}}{{H}_{k}}){{S}_{k, k-1}}{{(I-{{K}_{k}}{{H}_{k}})}^{\text{T}}}+(1+q){{K}_{k}}{{Y}_{k}}K_{k}^{\text{T}}$
(46) 同样, 式中q的选择依据定理3的结论.
估计误差方差阵
$P_{k}=P_{k, k-1}-K_{k}H_{k}P_{k, k-1} $
(47) 对于受到随机和有界两种噪声影响的线性系统, 为了描述统计特性未知的有界噪声, 引入均值集合的概念: 零均值的高斯白噪声不会引起均值的偏移, 而UBB噪声会引起均值的偏移, 将这些所有可能的偏移用集合的形式表达, 即均值集合. 因此, 相比传统的卡尔曼滤波, 当利用椭球边界来描述有界噪声时, 需要多考虑一个参数. 椭球中心均值的计算(式(40)和式(45))和协方差矩阵的计算(式(43)和式(47))都是基于卡尔曼滤波方程实现, 而描述椭球形状大小的矩阵利用集员滤波的思想实现(式(41)和式(46)), 且时间更新和测量更新 步骤都涉及椭球Minkowski和的计算, 并产生一组条件均值. 本文在计算外定界椭球时采用定理3中的最小迹椭球, 当然, 相比较传统的卡尔曼滤波, 相应地增加了计算量.
2.2 非线性系统
EKF在处理非线性滤波问题时, 通过线性化逼近非线性函数, 其中所述的线性化 是在该点(预测值)的一阶泰勒级数展开获得. 然而, 这类双重不确定性系统预测的已不再是唯一的点, 当然不能再以相同的方式实现系统模型的线性化. 因此, 我们需要找到一种能够线性化均值集合的方法. 为了完成这个目的, 将采用文献[19]中提出的方法.
我们需要选择一组近似点, 近似点的选择依据是: 对状态方程和测量方程仿射映射近似时参数的计算, 以尽量减少非线性函数的函数值和那些选择适当近似点的线性化值的加权平方误差和. 选择近似点的方法依赖于估计椭球集合的形状大小. 在文献[19]中, N维椭球建议选择$4N+1$个近似点, 且这些点等间距的分布在椭球的轴上, 如图 2所示. 在随后讨论的时间更新和测量更新过程中, 将采用该方法来实现非线性函数的线性近似.
非线性系统的近似仿射可写成如下形式:状态方程
${{x}_{k}}={{f}_{k}}({{x}_{k-1}})={{A}_{k}}{{x}_{k-1}}+f_{k}^{0}$
(48) 测量方程
${{y}_{k}}={{h}_{k}}({{x}_{k}})={{H}_{k}}{{x}_{k}}+h_{k}^{0}$
(49) 线性化的实现需要解得$A_{k}, { f}_{k}^{0}$和 $H_{k}, { h}_{k}^{0}$. 令${ x}_{k}^{0}$, ${ x}_{k}^{1}$, $\cdots$, $ { x}_{k}^{N}$为椭球集合${{\chi }_{k}}({{\chi }_{k}}\in F({{a}_{k}}, {{S}_{k}}))$滤波的近似点; 令${ x}_{k, k-1}^{0}$, ${ x}_{k, k-1}^{1}$, $\cdots$, ${ x_{k, k-1}}^{N}$为${{\chi }_{k, k-1}}({{\chi }_{k, k-1}}\in F({{a}_{k, k-1}}, {{S}_{k, k-1}}))$预测的近似点. 令$ {d}_{k}^{N}$为真实状态方程和在${ x}_{k}^{N}$点线性化近似计算的误差
$d_{k}^{i}={{f}_{k}}({{x}_{k}}^{i})-{{A}_{k}}x_{k-1}^{i}-f_{k}^{0}, i=1, \cdots , N$
(50) 同样, 令${ e}_{k}^{N}$为真实测量方程和在${ x}_{k, k-1}^{N}$点线性化近似计算的误差
${ e}_{k}^{i}=h_{k}( {x}_{k, k-1}^{i})-H_{k}{ x}_{k, k-1}^{i}-{ h}_{k}^{0} $
(51) 要求选择的$A_{k}, { f}_{k}^{0}$和$H_{k}, { h}_{k}^{0}$, 使得各自的误差和最小, 我们分别在近似点计算加权动态平方误差与测量平方误差
$[A_{k}, { f}_{k}^{0}]=\arg \min_{A_{k}, { f}_{k}^{0}} \sum_{n=0}^{N-1}l_{k}^{N}[{ d}_{k}^{n}]^{\rm T}[{ d}_{k}^{n}] $
(52) 及
$[H_{k}, { h}_{k}^{0}]=\arg \min_{H_{k}, { h}_{k}^{0}} \sum_{n=0}^{N-1}l_{k}^{N}[{ e}_{k}^{n}]^{\rm T}[{ e}_{k}^{n}] $
(53) 其中$l_{k}^{N}$为第n个近似点的权系数. $l_{k}^{N}$选取可以通过加权最小二乘求取.
定义如下矩阵
$\eqalign{ &{L_k} = {\rm{diag}}\{ l_{k - 1}^0, \cdots ,l_{k - 1}^{N - 1}\} \cr &{F_k} = \left[ {\matrix{ {x_k^0}& \cdots &{{x_k}^N} \cr 1& \cdots &1 \cr } } \right] \cr &{G_k} = \left[ {\matrix{ {x_{k,k - 1}^0}& \cdots &{{x_{k - 1}}^N} \cr 1& \cdots &1 \cr } } \right] \cr &{\beta _k} = \left[ \matrix{ {\left( {f_k^0} \right)^T} \hfill \cr \vdots \hfill \cr {\left( {f_k^{N - 1}} \right)^T} \hfill \cr} \right],{\alpha _k} = \left[ \matrix{ {\left( {h_k^0} \right)^T} \hfill \cr \vdots \hfill \cr {\left( {h_k^{N - 1}} \right)^T} \hfill \cr} \right] \cr} $
通过加权最小二乘, 可解得线性化后的参数
$\left[ \begin{align} & A_{k}^{T} \\ & {{\left( f_{k}^{0} \right)}^{T}} \\ \end{align} \right]={{\left( {{F}_{k}}{{L}_{k}}F_{k}^{T} \right)}^{-1}}{{F}_{K}}{{L}_{k}}\beta _{k}^{T}$
(54) $\left[ \begin{align} & H_{k}^{T} \\ & {{\left( h_{k}^{0} \right)}^{T}} \\ \end{align} \right]={{\left( {{G}_{k}}{{L}_{k}}G_{k}^{T} \right)}^{-1}}{{G}_{K}}{{L}_{k}}\alpha _{k}^{T}$
(55) 至此, 包含椭球集合的非线性系统完成了线性化.
时间更新
椭球集合$F( {a}_{k, k-1}, S_{k, k-1})$的中心通过计算非线性方程获得
${ a}_{k, k-1}= f_{k}( {a}_{k-1}) $
(56) 由于线性化已得到矩阵$A_{k}$, 则其余步骤与第2.1节的时间更新一致.
测量更新
预测得到的状态集合$F( {a}_{k, k-1}, S_{k, k-1})$和测量集合$F( {y}_{k}, Y_{k})$融合, 得到椭球$F( {a}_{k}, S_{k})$的中心
${a_k} = {a_{k,k - 1}} + {K_k}[{y_k} - {h_k}({a_{k,k - 1}})]$
(57) 同样, 由于线性化已得到矩阵$H_{k}$, 其余步骤与第2.1节的测量更新一致. 至此, 实现了非线性系统的联合滤波.
本节中线性化是通过最小二乘拟合的方法实现的, 与EKF计算雅可比矩阵不同, 该方法线性化近似的精度取决于系统的阶数和选取近似点的数量, 对于高阶系统, 这将导致矩阵$L_{k}, F_{k}, G_{k}, \beta_{k}, \alpha_{k}$维数较大和最小平方和的计算变得复杂. 在这种情况下, 可以选择以牺牲精度为代价, 选取较少的近似点来减少运算量.
3. 仿真实验
3.1 实验场景
二维平面内, 观测雷达建立在坐标原点, 设定飞行目标在平面内做匀速直线运动, 给出非线性系统描述如下:
${{x}_{k}}={{A}_{k}}{{x}_{k-1}}+{{B}_{k}}({{w}_{k}}+{{d}_{k}})$
式中
$\begin{align} & {{\text{A}}_{\text{k}}}\text{=}\left[ \begin{matrix} 1 & T & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & T \\ 0 & 0 & 0 & 1 \\ \end{matrix} \right] \\ & {{B}_{K}}=\left[ \begin{matrix} \frac{{{T}^{2}}}{2} & 0 \\ T & 0 \\ 0 & \frac{{{T}^{2}}}{2} \\ 0 & T \\ \end{matrix} \right] \\ \end{align}$
其中状态方程为线性, 状态向量${ x}=[x_{1}\;\;\dot{x}_{1}\;\; x_{2}\;\; \dot{x}_{2}]$, $x_{1}$与$x_{2}$表示由$X_{1}$轴和$X_{2}$轴组成的直角坐标系下的位移分量, $\dot{x}_{1}$与$\dot{x}_{2}$表示速度分量. 系统过程噪声分为两部分, ${ w}_{k}$为高斯白噪声, ${ d}_{k}$为UBB噪声.
${y_k} = \left[ \matrix{ {r_k} \hfill \cr {\theta _k} \hfill \cr} \right] = \left[ \matrix{ \sqrt {\left( {{x_1}} \right)_K^2\left( {{x_2}} \right)_k^2} \hfill \cr {\tan ^{ - 1}}{{\left( {{x_2}} \right)k} \over {\left( {{x_1}k} \right)}} \hfill \cr} \right] + {v_k} + {e_k}$
雷达系统的测量值用极坐标表示, 因此测量方程为非线性. ${ y}_{k}$为测量向量, 分量$r_{k}$表示斜距, 分量$\theta_{k}$表示方位角, 测量噪声${ v}_{k}$和${ e}_{k}$分别表示高斯白噪声和UBB噪声.
仿真设定的采样时间为T = 1 s, 过程噪声${ w}_{k}$为零均值高斯白噪声, 其协方差阵$Q_{k}={\rm diag}\{0.5^2, 0.5^2\}$; ${ d}_{k}$为UBB噪声, 其包含在椭球$F(0, {\rm{diag}}\left\{ {{{0.8}^2}, {{0.8}^2}} \right\}$内; 状态初始值为${ x}_{0}=[200 12 200 10]^{\rm T}$, 设定初始状态椭球${\chi _0} = F({x_0}, {S_0}), {S_0}$为初始椭球形状大小矩阵. 测量噪声$ { v}_{k}$为零均值高斯白噪声, 其协方差阵$R_{k}={\rm diag}\{20^2, 0.01^2\}$; ${ e}_{k}$为UBB噪声, 其包含在椭球$F({y_k}, {\rm{diag}}\{ {30^2}, {0.015^2})$内.
由于系统状态方程为线性, 而测量方程为非线性, 仿真中预测步骤 按照第2.1节中的时间更新, 校正步骤按照第2.2节中的测量更新.
3.2 仿真结果
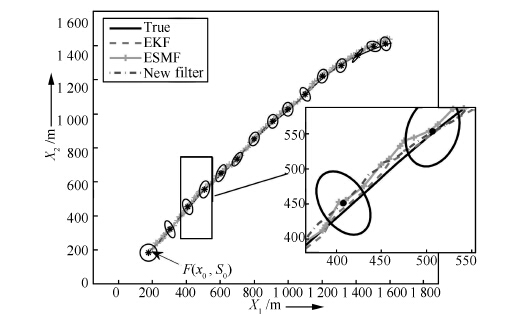
由于实验场景中系统存在噪声, 目标实际运动只能是近似匀速直线运动. 下面分别采用EKF、扩展集员滤波(Extended set-membership filter, ESMF) [20]及本文提出的联合滤波算法对目标运动轨迹进行跟踪.
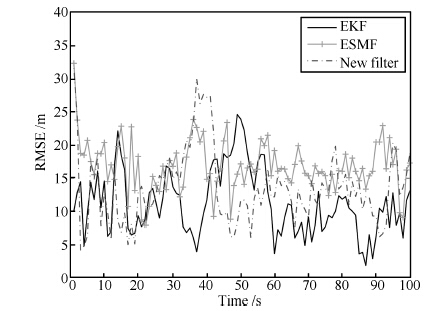
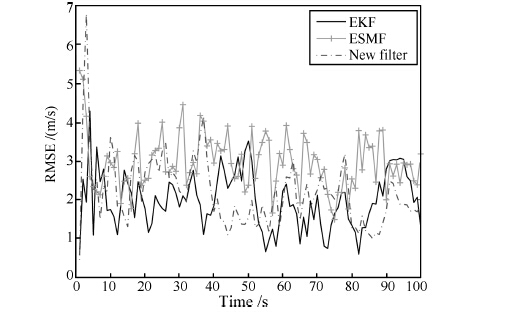
单独一次实验中, 三种算法跟踪结果如图 3所示, 与EKF相比, 联合滤波算法和ESMF算法估计得到的是一个集合. 仿真中, 为了显示联合滤波估计集合, 选取若干等间距椭球中心($\ast$号表示)并画出其表示的椭球集合. 同样, ESMF估计出的也是一个边界集合, 这里为了方便显示, 图中只给出了ESMF估计集合的中心. 为了测试滤波算法的性能, 进行100次蒙特卡罗仿真, 图 4和图 5分别给出了位移分量和速度分量的均方根误差(Root mean square error, RMSE).
由图 4和图 5以及表 1可以看出, 对于本仿真设定的混合噪声, 联合滤波算法的均方根误差好于ESMF, 接近EKF算法. 相比EKF, 新算法没有获得更好的估计结果是由于 SMF算法是一种以保守性换取鲁棒性的算法, 而联合滤波中处理有界部分采用了SMF的思想. 虽然联合滤波目前在精度上不存在优势, 但该算法有如下特点: 1) 对有界噪声的区别处理, 避免了卡尔曼滤波在非高斯假设下导致的滤波性能下降, 因此, 同SMF一样, 联合滤波得到的估计结果也是一种边界保证估计, 即边界内的值都是可靠的. 如图 3中, 真实值(实线)保证在椭球区域内. 2) 联合滤波算法不但具有较强的鲁棒性, 而且未来通过进一步建模分析系统未建模误差以及线性化误差边界, 使得选取的噪声边界尽量的"紧", 从而进一步提高系统的估计精度 [21]. 3) 允许我们从更深入的视角分析系统对非随机噪声的敏感度.
表 1 RMSE 均值对比Table 1 Comparison of RMSE means算法 RMSE 均值 位移(m) 速度(m/s) EKF 11.2541 1.9795 ESMF 17.7999 3.3716 New -lter 13.5249 2.1869 4. 结论
本文根据混合噪声中随机部分和有界部分的特性, 提出的联合滤波算法解决了线性系统和非线性系统存在混合噪声 情况下的滤波问题. 由于高斯白噪声一阶矩阵为常数, 而UBB噪声会引起误差均值发生偏移, 因此, 该算法得到估计结果可以理解为是具有一定误差边界的卡尔曼滤波值, 且边界内的值都是有效的. 然而, 联合滤波在处理过程中, 在传统卡尔曼滤波的基础上增加了椭球 集合的相关运算, 非线性系统选取近似点线性化的过程中更进一步增加了计算量, 尤其是在系统维数较高以及近似点的选取数量较多时. 这类非线性系统在线性化过程中, 如何能够提高近似精度和减少计算量是需要关注的问题. 另外, 状态估计椭球中"点"的选取值得考虑, 目前一般都是选取椭球中心点作为估计值. 那么选取中心点与可行椭球集合中其他点的区别以及对滤波性能的影响 也是未来需要研究的重点.
-
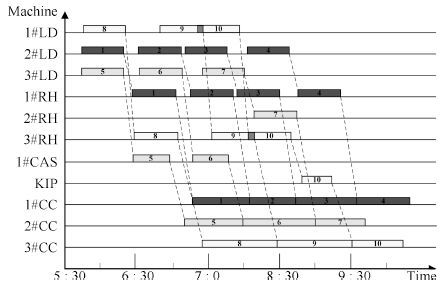
图 2 基于动态规划10个炉次的粗调度甘特图
Fig. 2 Gantt chart of ten charges rough scheduling based on dynamic programming

图 3 10个炉次冲突解消后的调度甘特图
Fig. 3 Scheduling Gantt chart after ten charges machine conflicts eliminated
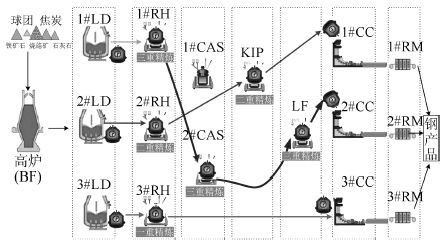
i 浇次序号,i = 1,2,3, $\cdots,N$ ; Ni 第i个浇次中的炉次数; j 炉次序号,j = 1,2,...,Ni; Lij 第i个浇次的第j个炉次; $\vartheta_{ij}$ 炉次Lij从转炉到连铸工序的加工设 备总数; 浇次计划中的精炼方式确定后, $\vartheta_{ij}$ 的取值就确定了; θ 炉次Lij从转炉到连铸加工的顺序号, θ = 1,2,..., $\vartheta_{ij}$ ; g 表示设备类,g = 1,2,3,...,G,如g = 1表示转炉设备; $g = 2$ 表示第一类 精炼设备类, $g = G$ 表示连铸设备类; Ti 浇次i的理想开浇时间,由现场给定; Mg 表示第g类设备中含有的并行机数; kg 设备变量,表示g类设备的第k个设 备序号; kg = 1,2,3 $,\cdots$ ,Mg; Tij( $k_{g(\theta)})$ 炉次Lij的第θ个操作在第g类设备的 第 $k_{g(\theta)}$ 个设备上的加工时间;当θ不 同时,炉次Lij的操作设备类型g也不 同,所以,g是θ的函数,即g = $g(\theta)$ , kg = $k_{g(\theta)}$ ;对于连铸设备,不同炉次在 连铸机的处理时间是不尽相同的.所以, 处理时间Tij( $k_{g(\theta)}$ )是设备变量 $k_{g(\theta)}$ 的函数; Tij( $k_{g(\theta)}$ , $k_{g(\theta+1) }$ ) 炉次Lij从第θ个操作设备 $k_{g(\theta)}$ 到第 $\theta+1$ 个操作设备 $k_{g(\theta+1) }$ 之间的运输时 间.由于炉次Lij的第θ和 $\theta+1$ 个操 作设备不同,其运输时间也不尽相同,所 以运输时间Tij( $k_{g(\theta)}$ , $k_{g(\theta+1) }$ )是炉次上 下操作设备的函数; yij( $k_{g(\theta)}$ ) 设备变量 $k_{g(\theta)}$ 的函数,当yij( $k_{g(\theta)}$ ) = 1,表示炉次Lij的第θ个操作在g类设 备上的第 $k_{g(\theta)}$ 个设备上加工;否则, yij( $k_{g(\theta)}$ ) = 0; xij( $k_{g(\theta)}$ ) 称为时间变量.炉次Lij的第θ个操作在 第g类设备的第 $k_{g(\theta)}$ 个机器上加工的开始时间.  下载: 导出CSV
下载: 导出CSV
表 1 三个浇次10个炉次计划的初始数据
Table 1 Initial data of three cast including ten charges
浇次号 炉次号 制造命令号 钢号 精炼方式 浇铸目的地 1 115578 DV3943D1 R 1#CC 1 2 115579 DT0192D1 R 1#CC 3 115580 DV3948D1 R 1#CC 4 115769 DT0138D1 R 1#CC 5 118275 AP0740D5 C 2#CC 2 6 118277 AP0740D5 C 2#CC 7 118281 DV3943D1 R 2#CC 8 461348 DV3943D1 R 3#CC 3 9 461349 DV3943D1 R 3#CC 10 461350 DV3943D1 RK 3#CC
下载: 导出CSV
表 2 基于动态规划的设备指派结果
Table 2 Equipment assignment base on dynamic programming
浇次号 炉次号 设备指派结果 设备处理时间 运输时间(分钟) 1 1 2#LD-1#RH-1#CC 35,36,48 8,14 2 2#LD-1#RH-1#CC 35,36,39 8,14 3 2#LD-1#RH-1#CC 35,36,52 8,14 4 2#LD-1#RH-1#CC 35,36,45 8,14 5 3#LD-1#CAS-2#CC 35,30,49 9,12 2 6 3#LD-1#CAS-2#CC 35,30,61 9,12 7 3#LD-2#RH-2#CC 35,36,42 9,15 8 1#LD-3#RH-3#CC 35,36,64 8,20 3 9 1#LD-3#RH-3#CC 35,36,64 8,20 10 1#LD-3#RH-KIP-3#CC 35,36,25,43 8,9,19
下载: 导出CSV
表 3 基于动态规划的10个炉次粗调度时刻表
Table 3 Ten charges rough schedule base on dynamic programming
炉次号 转炉 精炼1 精炼2 连铸 始 末 始 末 始 末 始 末 1 5:44 6:19 6:27 7:03 - - 7:17 8:05 2 6:32 7:07 7:15 7:51 - - 8:05 8:44 3 7:11 7:46 7:54 8:30 - - 8:44 9:36 4 8:03 8:38 8:46 9:22 - - 9:36 10:21 5 5:44 6:19 6:28 6:58 - - 7:10 7:59 6 6:33 7:08 7:17 7:47 - - 7:59 9:00 7 7:25 8:00 8:09 8:45 - - 9:00 9:42 8 5:46 6:21 6:29 7:05 - - 7:25 8:29 9 6:50 7:25 7:33 8:09 - - 8:29 9:33 10 7:21 7:56 8:04 8:40 8:49 9:14 9:33 10:16
下载: 导出CSV
表 4 10 个炉次机器冲突解消后的调度表
Table 4 Ten charges schedule table after conflicts eliminated
炉次号 转炉 精炼1 精炼2 连铸 始 末 始 末 始 末 始 末 1 5:44 6:19 6:27 7:03 - - 7:17 8:05 2 6:32 7:07 7:15 7:51 - - 8:05 8:44 3 7:11 7:46 7:54 8:30 - - 8:44 9:36 4 8:03 8:38 8:46 9:22 - - 9:36 10:21 5 5:44 6:19 6:28 6:58 - - 7:10 7:59 6 6:33 7:08 7:17 7:47 - - 7:59 9:00 7 7:25 8:00 8:09 8:45 - - 9:00 9:42 8 5:46 6:21 6:29 7:05 - - 7:25 8:29 9 6:45 7:20 7:28 8:04 - - 8:29 9:33 10 7:21 7:56 8:04 8:40 8:49 9:14 9:33 10:16
下载: 导出CSV
-
[1] 吴启迪, 乔非, 李莉, 吴莹. 基于数据的复杂制造过程调度. 自动化学报, 2009, 35(6): 807-813 doi: 10.3724/SP.J.1004.2009.00807Wu Qi-Di, Qiao Fei, Li Li, Wu Ying. Data-based scheduling for complex manufacturing processes. Acta Automatica Sinica, 2009, 35(6): 807-813 doi: 10.3724/SP.J.1004.2009.00807 [2] 王秀英, 柴天佑, 郑秉霖. 炼钢—连铸智能调度软件的开发及应用. 计算机集成制造系统, 2006, 12(8): 1220-1226 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJJ200608010.htmWang Xiu-Ying, Chai Tian-You, Zheng Bing-Lin. Intelligent scheduling software & its application in steelmaking and continuous casting. Computer Integrated Manufacturing Systems, 2006, 12(8): 1220-1226 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJJ200608010.htm [3] Missbauer H, Hauber W, Stadler W. A scheduling system for the steelmaking-continuous casting process. A case study from the steel-making industry. International Journal of Production Research, 2009, 47(15): 4147-4172 [4] Pacciarelli D, Pranzo M. Production scheduling in a steelmaking-continuous casting plant. Computers and Chemical Engineering, 2004, 28(12): 2823-2835 doi: 10.1016/j.compchemeng.2004.08.031 [5] 黄敏, 付亚平, 王洪峰, 朱兵虎, 王兴伟. 设备带有恶化特性的作业车间调度模型与算法. 自动化学报, 2015, 41(3): 551-558 http://www.aas.net.cn/CN/abstract/abstract18633.shtmlHuang Min, Fu Ya-Ping, Wang Hong-Feng, Zhu Bing-Hu, Wang Xing-Wei. Job-shop scheduling model and algorithm with machine deterioration. Acta Automatica Sinica, 2015, 41(3): 551-558 http://www.aas.net.cn/CN/abstract/abstract18633.shtml [6] Bellabdaoui A, Teghem J. A mixed-integer linear programming model for the continuous casting planning. International Journal of Production Economics, 2006, 104(2): 260-270 doi: 10.1016/j.ijpe.2004.10.016 [7] Mao K, Pan Q K, Pang X F, Chai T Y. A novel Lagrangian relaxation approach for a hybrid flowshop scheduling problem in the steelmaking-continuous casting process. European Journal of Operational Research, 2014, 236(1): 51-60 doi: 10.1016/j.ejor.2013.11.010 [8] Tang L X, Zhao Y, Liu J Y. An improved differential evolution algorithm for practical dynamic scheduling in steelmaking-continuous casting production. IEEE Transactions on Evolutionary Computation, 2014, 18(2): 209-225 doi: 10.1109/TEVC.2013.2250977 [9] Sbihi A, Bellabdaoui A, Teghem J. Solving a mixed integer linear program with times setup for the steel-continuous casting planning and scheduling problem. International Journal of Production Research, 2014, 52(24): 7276-7296 doi: 10.1080/00207543.2014.919421 [10] 俞胜平, 柴天佑. 开工时间延迟下的炼钢—连铸生产重调度方法. 自动化学报, 2016, 42(3): 358-374 http://www.aas.net.cn/CN/abstract/abstract18826.shtmlYu Sheng-Ping, Chai Tian-You. Rescheduling method for starting time delay in steelmaking and continuous casting production processes. Acta Automatica Sinica, 2016, 42(3): 358-374 http://www.aas.net.cn/CN/abstract/abstract18826.shtml [11] Tan Y Y, Liu S X. Models and optimisation approaches for scheduling steelmaking-refining-continuous casting production under variable electricity price. International Journal of Production Research, 2014, 52(4): 1032-1049 doi: 10.1080/00207543.2013.828179 [12] 李铁克, 苏志雄. 炼钢连铸生产调度问题的两阶段遗传算法. 中国管理科学, 2009, 17(5): 68-74 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGGK200905010.htmLi Tie-Ke, Su Zhi-Xiong. Two-stage genetic algorithm for SM-CC production scheduling. Chinese Journal of Management Science, 2009, 17(5): 68-74 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGGK200905010.htm [13] Atighehchian A, Bijari M, Tarkesh H. A novel hybrid algorithm for scheduling steel-making continuous casting production. Computers & Operations Research, 2009, 36(8): 2450-2461 http://cn.bing.com/academic/profile?id=2060539563&encoded=0&v=paper_preview&mkt=zh-cn [14] Pan L, Yu S P, Zheng B L, Chai T Y. Cast batch planning for steelmaking and continuous casting based on ant colony algorithm. In: Proceedings of the 2010 International Symposium on Computational Intelligence and Design. Hangzhou, China: IEEE, 2010. 244-247 [15] Li J Q, Pan Q K, Mao K, Suganthan P N. Solving the steelmaking casting problem using an effective fruit fly optimisation algorithm. Knowledge-Based Systems, 2014, 72: 28-36 doi: 10.1016/j.knosys.2014.08.022 [16] Pan Q K. An effective co-evolutionary artificial bee colony algorithm for steelmaking-continuous casting scheduling. European Journal of Operational Research, 2016, 250(3): 702-714 doi: 10.1016/j.ejor.2015.10.007 [17] Wang X Y, Jiang X J, Wang H H. Optimal modeling and analysis of steelmaking and continuous casting production scheduling. In: Proceedings of the 11th World Congress on Intelligent Control and Automation. Shenyang, China: IEEE, 2014. 5057-5062 [18] 王秀英. 炼钢—连铸混合优化调度方法及应用[博士学位论文], 东北大学, 中国, 2012Wang Xiu-Ying. Hybrid Optimization Scheduling Method of Steelmaking and Continuous Casting and its Application [Ph.D. dissertation], Northeastern University, China, 2012 [19] 王秀英, 柴天佑, 郑秉霖. 炼钢—连铸调度模型参数优化设定方法. 系统工程学报, 2011, 26(4): 531-537 http://www.cnki.com.cn/Article/CJFDTOTAL-XTGC201104015.htmWang Xiu-Ying, Chai Tian-You, Zheng Bing-Lin. Parameter optimization setting of steel making and continuous casting scheduling model. Journal of Systems Science and Systems Engineering, 2011, 26(4): 531-537 http://www.cnki.com.cn/Article/CJFDTOTAL-XTGC201104015.htm 期刊类型引用(11)
1. 杨志军,郑皓元,丁洪伟. 连续时间门限完全服务两级轮询系统性能分析. 计算机工程与设计. 2024(08): 2248-2255 .  百度学术
百度学术2. 杨志军,郑皓元,丁洪伟. 无线局域网多机器人系统轮询MAC协议研究. 计算机应用研究. 2022(04): 1178-1182 . 百度学术3. 杨志军,寇倩兰,丁洪伟. 适应于WSN的具有差错重传的轮询服务性能研究. 现代电子技术. 2022(09): 13-20 . 百度学术4. 杨志军,毛磊,丁洪伟,寇倩兰. 连续时间两级完全轮询接入MAC协议分析. 计算机工程与应用. 2022(09): 136-143 . 百度学术5. 程满,王新春,何京鸿,丁彩云. 基于非对称双队列门限服务周期查询轮询系统性能分析(英文). 楚雄师范学院学报. 2022(03): 7-14 . 百度学术6. 杨志军,寇倩兰,丁洪伟. 5G切片架构下具有重传机制的轮询系统研究. 计算机工程. 2022(10): 202-211 . 百度学术7. 杨志军,毛磊. 基于多服务器的轮询接入控制协议分析. 计算机工程与设计. 2021(06): 1509-1516 . 百度学术8. 杨志军,刘征,丁洪伟,柳虔林. 战术数据链网络的介质访问控制层优化控制及性能分析. 兵工学报. 2020(02): 305-314 . 百度学术9. 李超,李波,丁洪伟,杨志军,柳虔林. 基于FPGA的战术数据链协议设计与实现. 计算机工程. 2020(10): 173-181 . 百度学术10. YANG Zhijun,MAO Lei,GAN Jianhou,DING Hongwei. Performance Analysis and Prediction of Double-Server Polling System Based on BP Neural Network. Chinese Journal of Electronics. 2020(06): 1046-1053 . 必应学术11. 杨志军,刘征,丁洪伟. 连续时间完全服务与门限服务两级轮询系统性能研究. 计算机应用. 2019(07): 2019-2023 . 百度学术其他类型引用(7)
-


 下载:
下载:

计量
- 文章访问数: 1894
- HTML全文浏览量: 169
- PDF下载量: 924
- 被引次数: 18
