

-
摘要: 在基于子空间学习的背景建模方法中,利用背景信息对前景误差进行补偿有助于建立准确的背景模型.然而,当动态背景(摇曳的树枝、波动的水面等)和复杂前景等干扰因素存在时,补偿过程的准确性和稳定性会受到一定的影响.针对这些问题,本文提出了一种基于误差补偿的增量子空间背景建模方法.该方法可以实现复杂场景下的背景建模.首先,本文在误差补偿的过程中考虑了前景的空间连续性约束,在补偿前景信息的同时减少了动态背景的干扰,提高了背景建模的准确性.其次,本文将误差估计过程归结为一个凸优化问题,并根据不同的应用场合设计了相应的精确求解算法和快速求解方法.再次,本文设计了一种基于Alpha通道的误差补偿策略,提高了算法对复杂前景的抗干扰能力.最后,本文构建了不依赖于子空间模型的背景模板,减少了由前景信息反馈引起的背景更新失效,提高了算法的鲁棒性.多项对比实验表明,本文算法在干扰因素存在的情况下仍然可以实现对背景的准确建模,表现出较强的抗扰性和鲁棒性.Abstract: Compensating foreground error with background information usually helps to build an accurate background model for the subspace learning based background modeling method. However, dynamic background (swaying tree or waving water surface) and complex foreground signal may have bad influences on the compensation process. To solve the problem, we propose an error compensation based incremental subspace method for background modeling, which aims to build an accurate background model in complex scenarios. First, we bring a spatial continuity constraint to the foreground error estimation process, which helps to preserve more dynamic background information and increase the accuracy of the background model. Second, we formulate the foreground estimation task into a convex optimization problem, and design an accurate optimization algorithm and a fast optimization algorithm, respectively for different applications. Third, an alpha-mating based error compensation strategy is designed, which increases the anti-interference performance of our algorithm. At last, a median background template which does not rely on background model is constructed, which increases the robustness of our algorithm. Multiple experiments show that the proposed method is able to model background accurately even in complex scenarios, demonstrating the anti-interference performance and the robustness of our method.
-
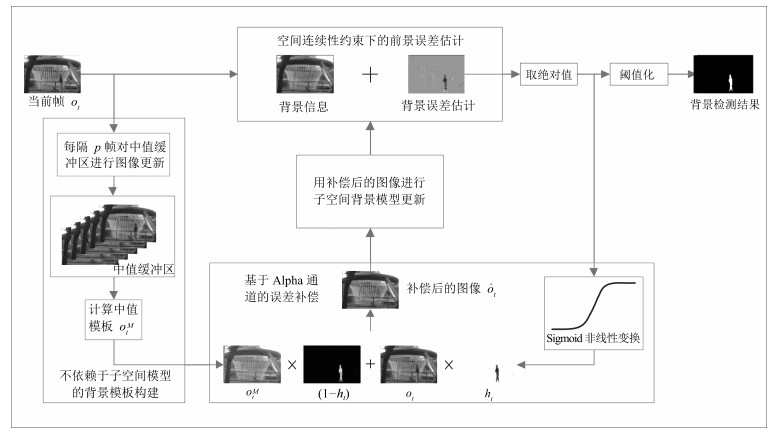
图 1 基于抗干扰误差补偿的背景建模算法流程示意图
Fig. 1 The flow chart of the proposed robust error compensation based background modeling method

图 4 二值分类函数与保留距离信息的分类策略
Fig. 4 Comparison between binary classification function and distance information preservation based classification strategy
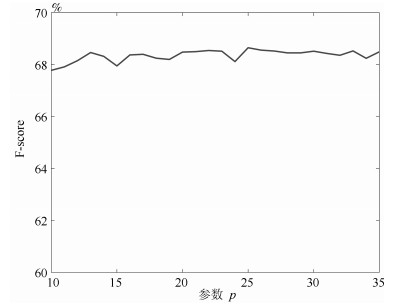
图 6 背景模板更新间隔p对算法平均性能的影响
Fig. 6 The average F-score performance with respect to different parameter p
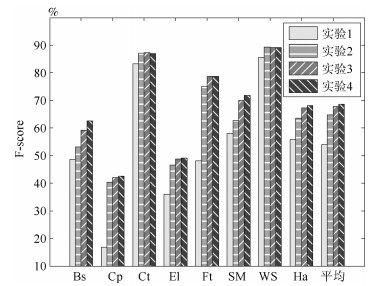
图 7 本文算法的三个主要组成部分的有效性展示
Fig. 7 The effectiveness of the main three components in the proposed algorithm

图 8 不同前景检测算法的前景掩膜结果
Fig. 8 The foreground masks obtained from different foreground detection algorithms
表 1 本文算法与其他算法的F-score得分(%)
Table 1 The F-score results (%) of the proposed method and the other methods

DPGMM RPCA GoDec GRASTA LRFSO RFDSA DECOLOR Ours(fast) Ours(accurate) Bootstrap 60.24 61.19 60.91 59.45 56.68 68.41 69.74 62.54 69.68 Campus 75.67 29.19 24.26 18.38 36.08 67.79 74.59 42.59 69.47 Curtain 82.03 54.97 63.03 78.91 79.35 89.76 87.35 87.00 90.34 Escalator 50.55 56.77 47.33 38.24 48.01 63.53 75.00 49.18 76.61 Fountain 70.49 68.81 70.31 63.86 70.58 75.44 87.87 78.74 80.15 ShoppingMall 65.22 70.03 66.53 68.96 54.46 74.07 65.58 71.78 75.40 WaterSurface 90.90 48.48 66.56 78.34 76.69 87.96 54.27 89.21 89.43 Hall 54.84 51.75 51.15 53.49 49.08 66.73 55.88 68.16 68.85 Average 68.74 55.14 56.26 57.45 58.8 74.21 71.29 68.65 77.50 FPS N/A 9.97 20.28 62.90 0.02 2.66 1.88 35.34 3.12  下载: 导出CSV
下载: 导出CSV
-
[1] 霍东海, 杨丹, 张小洪, 洪明坚.一种基于主成分分析的Codebook背景建模算法.自动化学报, 2012, 38(4): 591-600 doi: 10.3724/SP.J.1004.2012.00591Huo Dong-Hai, Yang Dan, Zhang Xiao-Hong, Hong Ming-Jian. Principal component analysis based codebook background modeling algorithm. Acta Automatica Sinica, 2012, 38(4): 591-600 doi: 10.3724/SP.J.1004.2012.00591 [2] 储珺, 杨樊, 张桂梅, 汪凌峰.一种分步的融合时空信息的背景建模.自动化学报, 2014, 40(4): 731-743 http://www.aas.net.cn/CN/abstract/abstract18339.shtmlChu Jun, Yang Fan, Zhang Gui-Mei, Wang Ling-Feng. A stepwise background subtraction by fusion spatio-temporal information. Acta Automatica Sinica, 2014, 40(4): 731-743 http://www.aas.net.cn/CN/abstract/abstract18339.shtml [3] 王永忠, 梁彦, 潘泉, 程咏梅, 赵春晖.基于自适应混合高斯模型的时空背景建模.自动化学报, 2009, 35(4): 371-378 http://www.aas.net.cn/CN/abstract/abstract15852.shtmlWang Yong-Zhong, Liang Yan, Pan Quan, Cheng Yong-Mei, Zhao Chun-Hui. Spatiotemporal background modeling based on adaptive mixture of Gaussians. Acta Automatica Sinica, 2009, 35(4): 371-378 http://www.aas.net.cn/CN/abstract/abstract15852.shtml [4] Stauffer C, Grimson W E L. Adaptive background mixture models for real-time tracking. In: Proceedings of the 14th IEEE Conference on Computer Vision and Pattern Recognition. Fort Collins, USA: IEEE, 1999. 246-252 [5] Elgammal A M, Harwood D, Davis L S. Non-parametric model for background subtraction. In: Proceedings of the 6th European Conference on Computer Vision. Dublin, Ireland: Springer-Verlag, 2000. 751-767 [6] Candés E, Li X D, Ma Y, Wright J. Robust principal component analysis? Journal of the ACM, 2011, 58(3): Article No. 11 http://cn.bing.com/academic/profile?id=2145962650&encoded=0&v=paper_preview&mkt=zh-cn [7] Zhou T Y, Tao D C. GoDec: randomized low-rank & sparse matrix decomposition in noisy case. In: Proceedings of the 28th International Conference on Machine Learning. Bellevue, USA: ACM, 2011. 33-40 [8] Dikmen M, Huang T S. Robust estimation of foreground in surveillance videos by sparse error estimation. In: Proceedings of the 19th International Conference on Pattern Recognition. Tampa, USA: IEEE, 2008. 1-4 [9] Xue G J, Song L, Sun J, Wu M. Foreground estimation based on robust linear regression model. In: Proceedings of the 18th International Conference on Image Processing. Brussels, Belgium: IEEE, 2011. 3269-3272 [10] Xue G J, Song L, Sun J. Foreground estimation based on linear regression model with fused sparsity on outliers. IEEE Transactions on Circuits and Systems for Video Technology, 2013, 23(8): 1346-1357 doi: 10.1109/TCSVT.2013.2243053 [11] Qin M, Lu Y, Di H J, Huang W. Background basis selection from multiple clustering on local neighborhood structure. In: Proceedings of the 2015 IEEE International Conference on Multimedia and Expo. Torino, Italy: IEEE, 2015. 1-6 http://cn.bing.com/academic/profile?id=2096642693&encoded=0&v=paper_preview&mkt=zh-cn [12] Seo J W, Kim S D. Recursive on-line (2D)2PCA and its application to long-term background subtraction. IEEE Transactions on Multimedia, 2014, 16(8): 2333-2344 doi: 10.1109/TMM.2014.2353772 [13] He J, Balzano L, Szlam A. Incremental gradient on the Grassmannian for online foreground and background separation in subsampled video. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 1568-1575 [14] Wang L, Wang M, Wen M, Zhuo Q, Wang W Y. Background subtraction using incremental subspace learning. In: Proceedings of the 2007 IEEE International Conference on Image Processing. San Antonio, USA: IEEE, 2007. V-45-V-48 http://cn.bing.com/academic/profile?id=2096642693&encoded=0&v=paper_preview&mkt=zh-cn [15] 蒋建国, 金玉龙, 齐美彬, 詹曙.基于稀疏表达残差的自然场景运动目标检测.电子学报, 2015, 43(9): 1738-1744 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201509009.htmJiang Jian-Guo, Jin Yu-Long, Qi Mei-Bin, Zhan Shu. Moving target detection in natural scene based on sparse representation of residuals. Acta Electronica Sinica, 2015, 43(9): 1738-1744 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201509009.htm [16] Xu Z F, Gu I Y H, Shi P F. Recursive error-compensated dynamic eigenbackground learning and adaptive background subtraction in video. Optical Engineering, 2008, 47(5): 525-534 http://cn.bing.com/academic/profile?id=2055138117&encoded=0&v=paper_preview&mkt=zh-cn [17] Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and TrendsoledR in Machine Learning, 2011, 3(1): 1-122 http://cn.bing.com/academic/profile?id=2164278908&encoded=0&v=paper_preview&mkt=zh-cn [18] Donoho D L. De-noising by soft-thresholding. IEEE Transactions on Information Theory, 1995, 41(3): 613-627 doi: 10.1109/18.382009 [19] Ross D A, Lim J, Lin R-S, Yang M H. Incremental learning for robust visual tracking. International Journal of Computer Vision, 2008, 77(1-3): 125-141 doi: 10.1007/s11263-007-0075-7 [20] Guo X J, Wang X G, Yang L, Cao X C, Ma Y. Robust foreground detection using smoothness and arbitrariness constraints. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 535-550 http://cn.bing.com/academic/profile?id=242805321&encoded=0&v=paper_preview&mkt=zh-cn [21] Wang L C, You Y, Lian H. A simple and efficient algorithm for fused LASSO signal approximator with convex loss function. Computational Statistics, 2013, 28(4): 1699-1714 doi: 10.1007/s00180-012-0373-6 [22] Sun D Q, Roth S, Black M J. A quantitative analysis of current practices in optical flow estimation and the principles behind them. International Journal of Computer Vision, 2014, 106(2): 115-137 doi: 10.1007/s11263-013-0644-x [23] Porter T, Duff T. Compositing digital images. In: Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques. Minneapolis, USA: ACM, 1984. 253-259 http://www.oalib.com/references/17182941 [24] Li L Y, Huang W M, Gu I Y H, Tian Q. Statistical modeling of complex backgrounds for foreground object detection. IEEE Transactions on Image Processing, 2004, 13(11): 1459-1472 doi: 10.1109/TIP.2004.836169 [25] Haines T S F, Tao X. Background subtraction with Dirichlet process mixture models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(4): 670-683 doi: 10.1109/TPAMI.2013.239 [26] Zhou X W, Yang C, Yu W C. Moving object detection by detecting contiguous outliers in the low-rank representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(3): 597-610 doi: 10.1109/TPAMI.2012.132 -



计量
- 文章访问数: 1643
- HTML全文浏览量: 292
- PDF下载量: 1129
- 被引次数: 0
