

-
摘要: 基于视觉的目标检测与跟踪是图像处理、计算机视觉、模式识别等众多学科的交叉研究课题,在视频监控、虚拟现实、人机交互、自主导航等领域,具有重要的理论研究意义和实际应用价值.本文对目标检测与跟踪的发展历史、研究现状以及典型方法给出了较为全面的梳理和总结.首先,根据所处理的数据对象的不同,将目标检测分为基于背景建模和基于前景建模的方法,并分别对背景建模与特征表达方法进行了归纳总结.其次,根据跟踪过程有无目标检测的参与,将跟踪方法分为生成式与判别式,对基于统计的表观建模方法进行了归纳总结.然后,对典型算法的优缺点进行了梳理与分析,并给出了其在标准数据集上的性能对比.最后,总结了该领域待解决的难点问题,对其未来的发展趋势进行了展望.Abstract: Vision-based object detection and tracking is an active research topic in image processing, computer vision, pattern recognition, etc. It finds wide applications in video surveillance, virtual reality, human-computer interaction, autonomous navigation, etc. This survey gives a detail overview of the history, the state-of-the-art, and typical methods in this domain. Firstly, object detection is divided into background-modeling-based methods and foreground-modeling-based methods according to the different data objects processed. Background modeling and feature representation are further summarized respectively. Then, object tracking is divided into generative and discriminative methods according to whether the detection process is involved. Statistical based appearance modeling is presented. Besides, discussions are presented on the advantages and drawbacks of typical algorithms. The performances of different algorithms on benchmark datasets are given. Finally, the outstanding issues are summarized. The future trends of this field are discussed.
-
Key words:
- Computer vision /
- object detection /
- object tracking /
- background modeling /
- appearance modeling
-
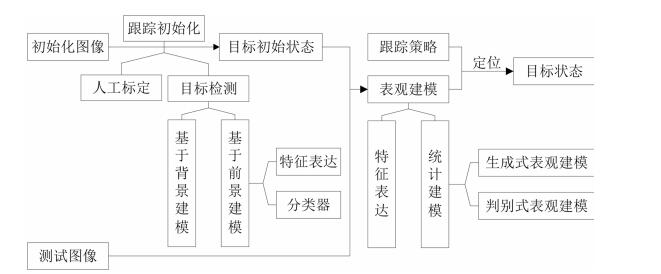
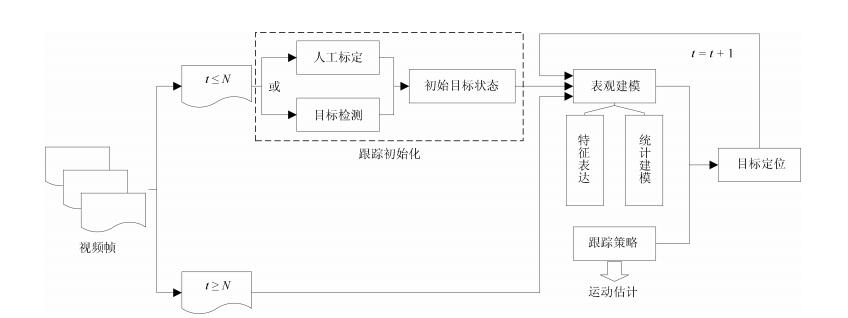
图 1 基于视觉的目标检测与跟踪框架
Fig. 1 General framework of vision-based object detection and tracking
表 1 基于视觉的目标检测与跟踪应用领域
Table 1 Applications of vision-based object detection and tracking
应用领域 具体应用 智能监控 公共安全监控(犯罪预防、人流密度检测)、停车场、超市、百货公司、自动售货机、ATM、小区(外来人员访问控制)、交通场景、家庭环境(老幼看护)等 虚拟现实 交互式虚拟世界、游戏控制、虚拟工作室、角色动画、远程会议等 高级人机交互 手语翻译、基于手势的控制、高噪声环境(机场、工厂等)下的信息传递等 动作分析 基于内容的运动视频检索, 高尔夫、网球等的个性化训练, 舞蹈等的编排, 骨科患者的临床研究等 自主导航 车辆导航、机器人导航、太空探测器的导航等 机器人视觉 工业机器人、家庭服务机器人、餐厅服务机器人、太空探测器等  下载: 导出CSV
下载: 导出CSV
表 2 目标检测与跟踪相关综述文献
Table 2 Related surveys about object detection and tracking
文献 题目 主要内容 讨论主题 发表年限 不足之处 [8] Vision based hand gesture recognition for human computer interaction: a survey 从检测、跟踪与识别三方面对手势识别的发展现状进行了梳理与总结 检测、跟踪、识别 2015 只进行了某些具体应用方向上的梳理 [9] A survey on recent object detection techniques useful for monocular vision-based planetary terrain classification 对行星地形分类中的目标检测技术进行了总结 目标检测 2014 [10] Sparse coding based visual tracking: review and experimental comparison 对基于稀疏编码的目标跟踪进行了全面的梳理与总结, 给出了实验对比与分析 表观建模 2013 只讨论了目标检测与跟踪的组成部分 [11] A survey of appearance models in visual object tracking 从全局与局部信息描述的角度探讨了目标跟踪中的视觉表达问题 表观建模 2013 [12] 面向目标检测的稀疏表示方法研究进展 综述了稀疏表示方法在目标检测领域中的国内外重要研究进展 表观建模 2015 [13] Background subtraction techniques: a review 对几种常用的背景减除方法进行了总结 背景建模 2004 [14] Traditional and recent approaches in background modeling for foreground detection: an overview 对目标检测中背景建模方法进行了详细讨论 背景建模 2014 [15] Visual tracking: an experimental survey 对19种先进的跟踪器在315段视频序列上进行了对比实验与性能评估 目标跟踪 2014 [16] Automated human behavior analysis from surveillance videos: a survey 在人体行为理解的底层处理部分, 对目标检测、分类及其跟踪进行了详细阐述 人体行为理解 2014 没有展开讨论检测跟踪问题 [17] 智能视频监控技术综述 在智能视频监控的底层部分, 对目标检测与跟踪进行了讨论 智能监控 2015 [18] Object tracking: a survey 对目标跟踪中的目标表达、特征或运动模型选取等问题进行了分类归纳 目标跟踪 2006 发表年限比较久远, 不断更新的理论和方法亟需梳理总结 [19] 视觉跟踪技术综述 分类归纳了视觉跟踪, 并论述了其在视频监控、图像压缩和三维重构等的应用 目标跟踪 2006 [20] 运动目标检测算法的探讨 对2007年以前的主流运动目标检测方法进行了分类讨论 目标检测 2006 [21] 运动目标跟踪算法研究综述 将运动目标跟踪问题分为运动检测与目标跟踪, 并对跟踪算法进行了综述工作 目标跟踪 2009 [22] 微弱运动目标的检测与跟踪识别算法研究 对强噪声背景下的微弱运动目标检测与跟踪算法进行了探讨 目标检测与跟踪 2010
下载: 导出CSV
表 3 基于人工设计的特征表达方法
Table 3 Human-engineering-based feature representation methods
序号 文献 典型算法 主要思想 提出年限 方法类别 1 [4] SIFT 通过获取特定关键点附近的梯度信息来描述运动目标, 具有旋转、尺度不变等优良特性, 其改进特征主要有PCA-SIFT[49]、GLOH[50]、SURF[51]、DAISY[52]等 2004 梯度特征 2 [5] HOG 通过计算空间分布区域的梯度强度及其方向信息来描述运动目标, 其改进特征主要有v-HOG[53]、CoHOG[54]、GIST[55]等 2005 3 [56] Gabor 利用Gabor滤波器对图像卷积得到, 在一定程度上模拟了人类视觉的细胞感受野机制 1997 模式特征 4 [57] LBP 通过计算像素点与周围像素的对比信息, 获得的一种对光照不变的局部描述, 其改进特征主要有CS-LBP[58]、NR-LBP[59]等 2004 5 [60] Haar-like 通过计算相邻矩形区域的像素和之差来描述线性、边缘、中心点以及对角线特征, 其改进特征主要有LAB[66]等 2001 6 [6] DPM 其实质是一种弹性形状模型, 是通过将梯度直方图(HOG)特征与Latent SVM相结合而训练得到的一种目标形状描述模型 2010 形状特征 7 [69] Shape context 通过获取形状上某一参考点与其余点的距离分布来描述目标轮廓 2002 8 [71] kAS 使用一组近似线性的线段对目标形状进行描述, 具有平移、尺度等不变特性 2008 9 [77] Color names 通过将图像像素值映射至相应的语义属性来对目标进行描述, 该特征通常包含11种语义属性, 一般需要结合梯度特征一起使用 2009 颜色特征 10 [88] 基于熵的显著性特征 通过计算图像像素的灰度概率分布来获取目标的感兴趣区域 2004
下载: 导出CSV
表 5 目标检测典型数据集
Table 5 Typical data sets for object detection
序号 参考文献 数据集名字 数据规模 是否标注 特点及描述 主页链接 发布时间 1 [139] MIT CBCL Pedestrian Database 共924张图片, 64 × 128, PPM格式 否 人体目标处于图像正中间, 且图像视角限定为正向或背向 http://cbcl.mit.edu/software-datasets/PedestrianData.html 2000 2 [140-141] USC Pedestrian Detection Test Set 共359张图片, 816个人 是 包含单视角下无遮挡、部分遮挡以及多视角下无遮挡的行人检测数据 http://iris.usc.edu/Vision-Users/OldUsers/bowu/DatasetWebpage/dataset.html 2005 / 2007 3 [5] INRIA Person Dataset 共1 805张图片, 64 × 128 是 包含了各种各样的应用背景, 对行人的姿势没有特别的要求 http://pascal.inrialpes.fr/data/human/ 2005 4 [45, 142] ChangeDetection.Net 共51段视频, 约140 000帧图片 是 包含了动态背景、目标运动、夜晚及阴影影响等多种挑战 http://changedetection.net/ 2012/2014 5 [143] Caltech Pedestrian Dataset 10小时视频, 640 × 480 是 视频为城市交通环境下驱车拍摄所得, 行人之间存在一定的遮挡 http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/ 2009 6 [144] CVC Datasets 共9个数据集 部分标注 提供了多种应用场景, 如城市、红外等场景, 行人间存在部分遮挡 http://www.cvc.uab.es/adas/site/?q=node/7 2007/2010/2013~2015 7 [119] PASCAL VOC Datasets 共11540张图, 含20个类 是 该比赛包括分类、检测、分割、动作分类以及人体布局检测等任务 http://host.robots.ox.ac.uk/pascal/VOC/ 2005~2012 8 [120] ImageNet 共14197122张图片 是 大规模目标识别比赛, 包括目标检测、定位以及场景分类等任务 http://image-net.org/ 2010~2015 9 [145] Microsoft COCO 约328000张图片, 含91个类 是 自然场景下的图像分类、检测、场景理解等, 不仅标注了不同的类别, 还对类中个例进行了标注 http://mscoco.org/ 2014
下载: 导出CSV
表 6 目标跟踪典型数据集
Table 6 Typical data sets for object tracking
序号 参考文献 数据集 数据规模 是否标注 特点及描述 主页链接 发布时间 1 [209-210] Visual Tracker Benchmark 100段序列 是 来源于现有文献, 包括了光照及尺度变化、遮挡、形变等9种挑战 http://www.visual-tracking.net 2013 2 [211] VIVID 9段序列 是 主要任务为航拍视角下的车辆目标跟踪, 具有表观微小、相似等特点 http://vision.cse.psu.edu/data/vividEval/datasets/datasets.html 2005 3 [212] CAVIAR 28段序列 是 主要用于人体目标跟踪, 视频内容包含行走、会面、进出场景等行为 http://homepages.inf.ed.ac.uk/rbf/CAVIARDATA1/ 2003 / 2004 4 [213] BIWI Walking Pedestrians Dataset 1段序列 是 主要任务为鸟瞰视角下的行人跟踪, 可用于评测多目标跟踪算法 http://www.vision.ee.ethz.ch/datasets/ 2009 5 [214] “Central” Pedestrian Crossing Sequences 3段序列 是 行人过街序列, 每4帧标定一次 http://www.vision.ee.ethz.ch/datasets/ 2007 6 [215] MOT16 14段序列 是 无约束环境的多目标跟踪, 有不同视角、相机运动、天气影响等挑战 http://motchallenge.net/ 2016 7 [216] PETS2015 7段序列 是 关于停车场中车辆旁边不同活动序列, 可用于目标检测与跟踪、动作识别、场景分析等 http://www.pets2015.net/ 2015 8 [217] VOT Challenge 60段序列(2015年) 是 主要用于短视频跟踪算法的评测, 该比赛从2013年开始举办 http://votchallenge.net/ 2013~2015
下载: 导出CSV
表 7 典型跟踪算法的性能对比
Table 7 Performance comparison of typical tracking algorithms
序号 参考文献 跟踪器 准确度 平均失败数 平均覆盖率 速度(EFO) 时间 方法类别 1 [128] MDNet 0.60 0.69 0.38 0.87 2015 CNN 2 [129] DeepSRDCF 0.56 1.05 0.32 0.38 2015 3 [130] SODLT 0.56 1.78 0.23 0.83 2015 4 [218] SumShift 0.52 1.68 0.23 16.78 2011 核学习 5 [219] ASMS 0.51 1.85 0.21 115.09 2013 6 [217] S3Tracker 0.52 1.77 0.24 14.27 2015 7 [161] IVT 0.44 4.33 0.12 8.38 2008 子空间学习 8 [220] CT 0.39 4.09 0.11 12.90 2012 9 [221] L1APG 0.47 4.65 0.13 1.51 2012 稀疏表示 10 [222] OAB 0.45 4.19 0.13 8.00 2014 Online Boosting 11 [223] MCT 0.47 1.76 0.22 2.77 2011 12 [224] CMIL 0.43 2.47 0.19 5.14 2010 13 [225] Struck 0.47 1.61 0.25 2.44 2014 SVM 14 [217] RobStruck 0.48 1.47 0.22 1.89 2015 15 [226] MIL 0.42 3.11 0.17 5.99 2011 随机学习
下载: 导出CSV
-
[1] Harold W A. Aircraft warning system, U. S. Patent 3053932, September 1962 [2] Papageorgiou C P, Oren M, Poggio T. A general framework for object detection. In:Proceedings of the 6th IEEE International Conference on Computer Vision. Bombay, India:IEEE, 1998. 555-562 [3] Viola P, Jones M J. Robust real-time object detection. International Journal of Computer Vision, 2001, 4:51-52 http://www.academia.edu/9081672/Robust_Real-time_Object_Detection [4] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2):91-110 doi: 10.1023/B:VISI.0000029664.99615.94 [5] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In:Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA:IEEE, 2005. 886-893 http://www.oalib.com/references/16902331 [6] Felzenszwalb P F, Girshick R B, McAllester D, Ramanan D. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9):1627-1645 doi: 10.1109/TPAMI.2009.167 [7] Everingham M, Van Gool L, Williams C K I, Winn J, Zisserman A. The pascal visual object classes (VOC) challenge. International Journal of Computer Vision, 2010, 88(2):303-338 doi: 10.1007/s11263-009-0275-4 [8] Rautaray S S, Agrawal A. Vision based hand gesture recognition for human computer interaction:a survey. Artificial Intelligence Review, 2015, 43(1):1-54 doi: 10.1007/s10462-012-9356-9 [9] Gao Y, Spiteri C, Pham M T, Al-Milli S. A survey on recent object detection techniques useful for monocular vision-based planetary terrain classification. Robotics and Autonomous Systems, 2014, 62(2):151-167 doi: 10.1016/j.robot.2013.11.003 [10] Zhang S P, Yao H X, Sun X, Lu X S. Sparse coding based visual tracking:review and experimental comparison. Pattern Recognition, 2013, 46(7):1772-1788 doi: 10.1016/j.patcog.2012.10.006 [11] Li X, Hu W M, Shen C H, Zhang Z F, Dick A, van den Hengel A. A survey of appearance models in visual object tracking. ACM transactions on Intelligent Systems and Technology (TIST), 2013, 4(4):Article No. 58 http://www.oalib.com/paper/4037071 [12] 高仕博, 程咏梅, 肖利平, 韦海萍.面向目标检测的稀疏表示方法研究进展.电子学报, 2015, 43(2):320-332 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201502018.htmGao Shi-Bo, Cheng Yong-Mei, Xiao Li-Ping, Wei Hai-Ping. Recent advances of sparse representation for object detection. Acta Electronica Sinica, 2015, 43(2):320-332 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201502018.htm [13] Piccardi M. Background subtraction techniques:a review. In:Proceedings of the 2004 IEEE International Conference on Systems, Man and Cybernetics. The Hague, Holland:IEEE, 2004. 3099-3104 http://www.oalib.com/references/8616532 [14] Bouwmans T. Traditional and recent approaches in background modeling for foreground detection:an overview. Computer Science Review, 2014, 11-12:31-66 doi: 10.1016/j.cosrev.2014.04.001 [15] Smeulders A W M, Chu D M, Cucchiara R, Calderara S, Dehghan A, Shah M. Visual tracking:an experimental survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7):1442-1468 doi: 10.1109/TPAMI.2013.230 [16] Gowsikhaa D, Abirami S, Baskaran R. Automated human behavior analysis from surveillance videos:a survey. Artificial Intelligence Review, 2014, 42(4):747-765 doi: 10.1007/s10462-012-9341-3 [17] 黄凯奇, 陈晓棠, 康运锋, 谭铁牛.智能视频监控技术综述.计算机学报, 2015, 38(6):1093-1118 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201506001.htmHuang Kai-Qi, Chen Xiao-Tang, Kang Yun-Feng, Tan Tie-Niu. Intelligent visual surveillance:a review. Chinese Journal of Computers, 2015, 38(6):1093-1118 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201506001.htm [18] Yilmaz A, Javed O, Shah M. Object tracking:a survey. ACM Computing Surveys (CSUR), 2006, 38(4):Article No. 13 doi: 10.1145/1177352 [19] 侯志强, 韩崇昭.视觉跟踪技术综述.自动化学报, 2006, 32(4):603-617 http://www.aas.net.cn/CN/abstract/abstract14397.shtmlHou Zhi-Qiang, Han Chong-Zhao. A survey of visual tracking. Acta Automatica Sinica, 2006, 32(4):603-617 http://www.aas.net.cn/CN/abstract/abstract14397.shtml [20] 万缨, 韩毅, 卢汉清.运动目标检测算法的探讨.计算机仿真, 2006, 23(10):221-226 http://www.cqvip.com/qk/92897x/200610/23059904.htmlWan Ying, Han Yi, Lu Han-Qing. The methods for moving object detection. Computer Simulation, 2006, 23(10):221-226 http://www.cqvip.com/qk/92897x/200610/23059904.html [21] 张娟, 毛晓波, 陈铁军.运动目标跟踪算法研究综述.计算机应用研究, 2009, 26(12):4407-4410 http://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ200912001.htmZhang Juan, Mao Xiao-Bo, Chen Tie-Jun. Survey of moving object tracking algorithm. Application Research of Computers, 2009, 26(12):4407-4410 http://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ200912001.htm [22] 牛芗洁, 黄永春.微弱运动目标的检测与跟踪识别算法研究.计算机仿真, 2010, 27(4):245-247 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJZ201004061.htmNiu Xiang-Jie, Huang Yong-Chun. Research on detection and tracking identification algorithm of weak moving target. Computer Simulation, 2010, 27(4):245-247 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJZ201004061.htm [23] Gutchess D, Trajkovics M, Cohen-Solal E, Lyons D, Jain A K. A background model initialization algorithm for video surveillance. In:Proceedings of the 8th IEEE International Conference on Computer Vision. Vancouver, BC, Canada:IEEE, 2001. 733-740 [24] Wang H Z, Suter D. A novel robust statistical method for background initialization and visual surveillance. In:Proceedings of the 7th Asian Conference on Computer Vision (ACCV 2006). Hyderabad, India:Springer, 2006. 328-337 http://dblp.uni-trier.de/db/conf/accv/accv2006-1 [25] Colombari A, Fusiello A. Patch-based background initialization in heavily cluttered video. IEEE Transactions on Image Processing, 2010, 19(4):926-933 doi: 10.1109/TIP.2009.2038652 [26] Lee B, Hedley M. Background estimation for video surveillance. In:Proceedings of the Image and Vision Computing New Zealand. Auckland, New Zealand, 2002. 315-320 [27] McFarlane N J B, Schofield C P. Segmentation and tracking of piglets in images. Machine Vision and Applications, 1995, 8(3):187-193 doi: 10.1007/BF01215814 [28] Bouwmans T, El Baf F, Vachon B. Statistical background modeling for foreground detection:a survey. Handbook of Pattern Recognition and Computer Vision. Singapore:World Scientific Publishing, 2010. 181-189 [29] Bouwmans T. Recent advanced statistical background modeling for foreground detection:a systematic survey. Recent Patents on Computer Science, 2011, 4(3):147-176 http://benthamscience.com/journal/abstracts.php?journalID=rpcseng&articleID=94725 [30] Butler D E, Bove V M Jr, Sridharan S. Real-time adaptive foreground/background segmentation. EURASIP Journal on Advances in Signal Processing, 2005, 2005:2292-2304 doi: 10.1155/ASP.2005.2292 [31] Kim K, Chalidabhongse T H, Harwood D, Davis L. Background modeling and subtraction by codebook construction. In:Proceedings of the 2004 IEEE International Conference on Image Processing. Singapore:IEEE, 2004. 3061-3064 https://www.researchgate.net/publication/4138335_Background_modeling_and_subtraction_by_codebook_construction [32] Palomo E J, Domínguez E, Luque R M, Muńoz J. Image hierarchical segmentation based on a GHSOM. In:Proceedings of the 16th International Conference on Neural Information Processing. Bangkok, Thailand:Springer, 2009. 743-750 [33] De Gregorio M, Giordano M. Background modeling by weightless neural networks. In:Proceedings of the 2015 Workshops on New Trends in Image Analysis and Processing (ICIAP 2015). Genoa, Italy:Springer, 2015. 493-501 http://www.springer.com/us/book/9783319232218 [34] Toyama K, Krumm J, Brumitt B, Meyers B. Wallflower:principles and practice of background maintenance. In:Proceedings of the 7th IEEE International Conference on Computer Vision. Kerkyra, Greece:IEEE, 1999. 255-261 [35] Ridder C, Munkelt O, Kirchner H. Adaptive background estimation and foreground detection using Kalman-filtering. In:Proceedings of the 1995 International Conference on Recent Advances in Mechatronics. Istanbul, Turkey:Boğaziči University, 1995. 193-199 [36] Kim W, Kim C. Background subtraction for dynamic texture scenes using fuzzy color histograms. IEEE Signal Processing Letters, 2012, 19(3):127-130 doi: 10.1109/LSP.2011.2182648 [37] Bouwmans T, Zahzah E H. Robust PCA via principal component pursuit:a review for a comparative evaluation in video surveillance. Computer Vision and Image Understanding, 2014, 122:22-34 doi: 10.1016/j.cviu.2013.11.009 [38] Cevher V, Sankaranarayanan A, Duarte M F, Reddy D, Baraniuk R G, Chellappa R. Compressive sensing for background subtraction. In:Proceedings of the 10th European Conference on Computer Vision (ECCV 2008). Marseille, France:Springer, 2008. 155-168 [39] Wren C R, Porikli F. Waviz:spectral similarity for object detection. In:Proceedings of the 2005 IEEE International Workshop on Performance Evaluation of Tracking and Surveillance. Breckenridge, Colorado, USA:IEEE, 2005. 55-61 [40] Baltieri D, Vezzani R, Cucchiara R. Fast background initialization with recursive Hadamard transform. In:Proceedings of the 7th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). Boston, USA:IEEE, 2010. 165-171 [41] Bouwmans T, El Baf F, Vachon B. Background modeling using mixture of gaussians for foreground detection——a survey. Recent Patents on Computer Science, 2008, 1(3):219-237 doi: 10.2174/2213275910801030219 [42] Lin H H, Liu T L, Chuang J H. A probabilistic SVM approach for background scene initialization. In:Proceedings of the 2002 International Conference on Image Processing. Rochester, New York, USA:IEEE, 2002. 893-896 [43] Maddalena L, Petrosino A. The SOBS algorithm:what are the limits? In:Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Providence, RI, USA:IEEE, 2012. 21-26 [44] Maddalena L, Petrosino A. The 3dSOBS+ algorithm for moving object detection. Computer Vision and Image Understanding, 2014, 122:65-73 doi: 10.1016/j.cviu.2013.11.006 [45] Goyette N, Jodoin P M, Porikli F, Konrad J, Ishwar P. Changedetection.net:a new change detection benchmark dataset. In:Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Providence, RI, USA:IEEE, 2012. 1-8 [46] Barnich O, Van Droogenbroeck M. ViBe:a powerful random technique to estimate the background in video sequences. In:Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Taipei, China:IEEE, 2009. 945-948 http://cn.bing.com/academic/profile?id=2115352131&encoded=0&v=paper_preview&mkt=zh-cn [47] Hofmann M, Tiefenbacher P, Rigoll G. Background segmentation with feedback:the pixel-based adaptive segmenter. In:Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Providence, RI, USA:IEEE, 2012. 38-43 [48] Sobral A, Bouwmans T. BGS Library:A Library Framework for Algorithm's Evaluation in Foreground/Background Segmentation. London:CRC Press, 2014. https://www.researchgate.net/publication/259574448_BGS_Library_A_Library_Framework_for_Algorithm%27s_Evaluation_in_ForegroundBackground_Segmentation [49] Ke Y, Sukthankar R. PCA-SIFT:a more distinctive representation for local image descriptors. In:Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, D.C., USA:IEEE, 2004. Ⅱ-506-Ⅱ-513 [50] Mikolajczyk K, Schmid C. A performance evaluation of local descriptors. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(10):1615-1630 doi: 10.1109/TPAMI.2005.188 [51] Bay H, Ess A, Tuytelaars T, Van Gool L. Speeded-up robust features (SURF). Computer Vision and Image Understanding, 2008, 110(3):346-359 doi: 10.1016/j.cviu.2007.09.014 [52] Tola E, Lepetit V, Fua P. Daisy:an efficient dense descriptor applied to wide-baseline stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(5):815-830 doi: 10.1109/TPAMI.2009.77 [53] Zhu Q, Yeh M C, Cheng K T, Avidan S. Fast human detection using a cascade of histograms of oriented gradients. In:Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA:IEEE, 2006. 1491-1498 [54] Watanabe T, Ito S, Yokoi K. Co-occurrence histograms of oriented gradients for human detection. Information and Media Technologies, 2010, 5(2):659-667 https://www.researchgate.net/publication/240976706_Co-occurrence_Histograms_of_Oriented_Gradients_for_Human_Detection [55] Torralba A, Oliva A, Castelhano M S, Henderson J M. Contextual guidance of eye movements and attention in real-world scenes:the role of global features in object search. Psychological Review, 2006, 113(4):766-786 doi: 10.1037/0033-295X.113.4.766 [56] Jain A K, Ratha N K, Lakshmanan S. Object detection using Gabor filters. Pattern Recognition, 1997, 30(2):295-309 doi: 10.1016/S0031-3203(96)00068-4 [57] Ahonen T, Hadid A, Pietikäinen M. Face recognition with local binary patterns. In:Proceedings of the 8th European Conference on Computer Vision (ECCV 2004). Prague, Czech Republic:Springer, 2004. 469-481 [58] Heikkilä M, Pietikäinen M, Schmid C. Description of interest regions with local binary patterns. Pattern Recognition, 2009, 42(3):425-436 doi: 10.1016/j.patcog.2008.08.014 [59] Nguyen D T, Ogunbona P O, Li W Q. A novel shape-based non-redundant local binary pattern descriptor for object detection. Pattern Recognition, 2013, 46(5):1485-1500 doi: 10.1016/j.patcog.2012.10.024 [60] Viola P, Jones M. Robust Real-time Object Detection, Technical Report CRL-2001-1, Cambridge Research Laboratory, University of Cambridge, United Kingdom, 2001 http://www.nexoncn.com/read/a611db6e123132763aa5bf23.html [61] Wu J X, Rehg J M. CENTRIST:a visual descriptor for scene categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8):1489-1501 doi: 10.1109/TPAMI.2010.224 [62] Bourdev L, Malik J. Poselets:body part detectors trained using 3D human pose annotations. In:Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 1365-1372 https://www.researchgate.net/publication/221110114_Poselets_Body_Part_Detectors_Trained_Using_3D_Human_Pose_Annotations [63] Girshick R, Song H O, Darrell T. Discriminatively activated sparselets. In:Proceedings of the 30th International Conference on Machine Learning (ICML-13). Atlanta, GA, USA:ACM, 2013. 196-204 [64] Kokkinos I. Shufflets:shared mid-level parts for fast object detection. In:Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, Australia:IEEE, 2013. 1393-1400 https://www.computer.org/csdl/proceedings/iccv/2013/2840/00/index.html [65] Wang X Y, Yang M, Zhu S H, Lin Y Q. Regionlets for generic object detection. In:Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, Australia:IEEE, 2013. 17-24 [66] Yan S Y, Shan S G, Chen X L, Gao W. Locally assembled binary (LAB) feature with feature-centric cascade for fast and accurate face detection. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Anchorage, Alaska, USA:IEEE, 2008. 1-7 [67] Arman F, Aggarwal J K. Model-based object recognition in dense-range images——a review. ACM Computing Surveys (CSUR), 1993, 25(1):5-43 doi: 10.1145/151254.151255 [68] Yang M Q, Kpalma K, Ronsin J. A survey of shape feature extraction techniques. Pattern Recognition. IN-TECH, 2008. 43-90 [69] Belongie S, Malik J, Puzicha J. Shape matching and object recognition using shape contexts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(4):509-522 doi: 10.1109/34.993558 [70] Kontschieder P, Riemenschneider H, Donoser M, Bischof H. Discriminative learning of contour fragments for object detection. In:Proceedings of the 2011 British Machine Vision Conference. Dundee, Scotland:British Machine Vision Association, 2011. 4.1-4.12 [71] Ferrari V, Fevrier L, Jurie F, Schmid C. Groups of adjacent contour segments for object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(1):36-51 doi: 10.1109/TPAMI.2007.1144 [72] Chia A Y S, Rahardja S, Rajan D, Leung M K. Object recognition by discriminative combinations of line segments and ellipses. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, CA, USA:IEEE, 2010. 2225-2232 https://www.computer.org/csdl/proceedings/cvpr/2010/6984/00/index.html [73] Tombari F, Franchi A, Di L. BOLD features to detect texture-less objects. In:Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, Australia:IEEE, 2013. 1265-1272 https://www.computer.org/csdl/proceedings/iccv/2013/2840/00/index.html [74] Jurie F, Schmid C. Scale-invariant shape features for recognition of object categories. In:Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, D. C., USA:IEEE, 2004. Ⅱ-90-Ⅱ-96 [75] Dhankhar P, Sahu N. A review and research of edge detection techniques for image segmentation. International Journal of Computer Science and Mobile Computing (IJCSMC), 2013, 2(7):86-92 http://www.academia.edu/4018689/A_Review_and_Research_of_Edge_Detection_Techniques_for_Image_Segmentation_ [76] Rassem T H, Khoo B E. Object class recognition using combination of color SIFT descriptors. In:Proceedings of the 2011 IEEE International Conference on Imaging Systems and Techniques (IST). Penang, Malaysia:IEEE, 2011. 290-295 [77] Van De Weijer J, Schmid C, Verbeek J, Larlus D. Learning color names for real-world applications. IEEE Transactions on Image Processing, 2009, 18(7):1512-1523 doi: 10.1109/TIP.2009.2019809 [78] Vadivel A, Sural S, Majumdar A K. An integrated color and intensity co-occurrence matrix. Pattern Recognition Letters, 2007, 28(8):974-983 doi: 10.1016/j.patrec.2007.01.004 [79] Walk S, Majer N, Schindler K, Schiele B. New features and insights for pedestrian detection. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, CA, USA:IEEE, 2010. 1030-1037 [80] Shechtman E, Irani M. Matching local self-similarities across images and videos. In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Minneapolis, Minnesota, USA:IEEE, 2007. 1-8 [81] Deselaers T, Ferrari V. Global and efficient self-similarity for object classification and detection. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, CA, USA:IEEE, 2010. 1633-1640 [82] Tuzel O, Porikli F, Meer P. Human detection via classification on Riemannian manifolds. In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Minneapolis, Minnesota, USA:IEEE, 2007. 1-8 https://www.researchgate.net/publication/221361317_Human_Detection_via_Classification_on_Riemannian_Manifolds [83] Burghouts G J, Geusebroek J M. Performance evaluation of local colour invariants. Computer Vision and Image Understanding, 2009, 113(1):48-62 doi: 10.1016/j.cviu.2008.07.003 [84] Bosch A, Zisserman A, Muńoz X. Scene classification using a hybrid generative/discriminative approach. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(4):712-727 doi: 10.1109/TPAMI.2007.70716 [85] Van De Weijer J, Schmid C. Coloring local feature extraction. In:Proceedings of the 9th European Conference on Computer Vision (ECCV 2006). Graz, Austria:Springer, 2006. 334-348 [86] Khan F S, Anwer R M, van de Weijer J, Bagdanov A D, Vanrell M, Lopez A M. Color attributes for object detection. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA:IEEE, 2012. 3306-3313 [87] Danelljan M, Khan F S, Felsberg M, van de Weijer J. Adaptive color attributes for real-time visual tracking. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH, USA:IEEE, 2014. 1090-1097 https://www.computer.org/csdl/proceedings/cvpr/2014/5118/00/index.html [88] Kadir T, Zisserman A, Brady M. An affine invariant salient region detector. In:Proceedings of the 8th European Conference on Computer Vision (ECCV 2004). Prague, Czech Republic:Springer, 2004. 228-241 [89] Lee T S, Mumford D, Romero R, Lamme V A F. The role of the primary visual cortex in higher level vision. Vision Research, 1998, 38(15-16):2429-2454 doi: 10.1016/S0042-6989(97)00464-1 [90] Lee T S, Mumford D. Hierarchical Bayesian inference in the visual cortex. Journal of the Optical Society of America A, 2003, 20(7):1434-1448 doi: 10.1364/JOSAA.20.001434 [91] Jia Y Q, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T. Caffe:convolutional architecture for fast feature embedding. In:Proceedings of the 22nd ACM International Conference on Multimedia. Orlando, Florida, USA:ACM, 2014. 675-678 [92] Dean J, Corrado G, Monga R, Chen K, Devin M, Mao M, Ranzato M, Senior A, Tucker P, Yang K, Le Q V, Ng A Y. Large scale distributed deep networks. In:Proceedings of the 2012 Advances in Neural Information Processing Systems 25. Lake Tahoe, Nevada, USA:MIT Press, 2012. 1223-1231 [93] Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z F, Citro C, Corrado G S, Davis A, Dean J, Devin M, Ghemawat S, Goodfellow I, Harp A, Irving G, Isard M, Jia Y Q, Jozefowicz R, Kaiser L, Kudlur M, Levenberg J, Mane D, Monga R, Moore S, Murray D, Olah C, Schuster M, Shlens J, Steiner B, Sutskever I, Talwar K, Tucker P, Vanhoucke V, Vasudevan V, Viegas F, Vinyals O, Warden P, Wattenberg M, Wicke M, Yu Y, Zheng X Q. TensorFlow:large-scale machine learning on heterogeneous distributed systems. arXiv:1603.04467, 2016. [94] Collobert R, Kavukcuoglu K, Farabet C. Torch7:a Matlab-like environment for machine learning. In:Proceedings of Annual Conference on Neural Information Processing Systems. Granada, Spain:MIT Press, 2011. [95] Krizhevsky A. CUDA-convnet:high-performance C++/CUDA implementation of convolutional neural networks[Online], available:http://code.google.com/p/cuda-convnet/, August6, 2016 [96] Vedaldi A, Lenc K. MatConvNet-convolutional neural networks for MATLAB. arXiv:1412.4564, 2014. [97] Goodfellow I J, Warde-Farley D, Lamblin P, Dumoulin V, Mirza M, Pascanu R, Bergstra J, Bastien F, Bengio Y. Pylearn2:a machine learning research library. arXiv:1308.4214, 2013. [98] The Theano Development Team. Theano:a Python framework for fast computation of mathematical expressions. arXiv:1605.02688, 2016. [99] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527-1554 doi: 10.1162/neco.2006.18.7.1527 [100] Hinton G E, Zemel R S. Autoencoders, minimum description length and Helmholtz free energy. In:Proceedings of the 1993 Advances in Neural Information Processing Systems 6. Cambridge, MA:MIT Press, 1993. 3-10 [101] Lécun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11):2278-2324 doi: 10.1109/5.726791 [102] Lee H, Grosse R, Ranganath R, Ng A Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In:Proceedings of the 26th Annual International Conference on Machine Learning. Montréal, Canada:ACM, 2009. 609-616 [103] Nair V, Hinton G E. 3D object recognition with deep belief nets. In:Proceedings of the 2009 Advances in Neural Information Processing Systems 22. Vancouver, B.C., Canada:MIT Press, 2009. 1339-1347 [104] Eslami S M A, Heess N, Williams C K I, Winn J. The shape Boltzmann machine:a strong model of object shape. International Journal of Computer Vision, 2014, 107(2):155-176 doi: 10.1007/s11263-013-0669-1 [105] Salakhutdinov R, Hinton G. Deep Boltzmann machines. In:Proceedings of the 12th International Conference on Artificial Intelligence and Statistics. Clearwater Beach, Florida, USA:ACM, 2009. 448-455 [106] 郑胤, 陈权崎, 章毓晋.深度学习及其在目标和行为识别中的新进展.中国图象图形学报, 2014, 19(2):175-184 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGTB201402002.htmZheng Yin, Chen Quan-Qi, Zhang Yu-Jin. Deep learning and its new progress in object and behavior recognition. Journal of Image and Graphics, 2014, 19(2):175-184 http://www.cnki.com.cn/Article/CJFDTOTAL-ZGTB201402002.htm [107] Xiong M F, Chen J, Wang Z, Liang C, Zheng Q, Han Z, Sun K M. Deep feature representation via multiple stack auto-encoders. In:Proceedings of the 16th Pacific-Rim Conference on Advances in Multimedia Information Processing (PCM 2015). Gwangju, South Korea:Springer, 2015. 275-284 [108] Yin H P, Jiao X G, Chai Y, Fang B. Scene classification based on single-layer SAE and SVM. Expert Systems with Applications, 2015, 42(7):3368-3380 doi: 10.1016/j.eswa.2014.11.069 [109] Bai J, Wu Y, Zhang J M, Chen F Q. Subset based deep learning for RGB-D object recognition. Neurocomputing, 2015, 165:280-292 doi: 10.1016/j.neucom.2015.03.017 [110] Su S Z, Liu Z H, Xu S P, Li S Z, Ji R R. Sparse auto-encoder based feature learning for human body detection in depth image. Signal Processing, 2015, 112:43-52 doi: 10.1016/j.sigpro.2014.11.003 [111] Hubel D H, Wiesel T N. Receptive fields, binocular interaction and functional architecture in the cat's visual cortex. The Journal of Physiology, 1962, 160(1):106-154 doi: 10.1113/jphysiol.1962.sp006837 [112] Donahue J, Jia Y Q, Vinyals O, Hoffman J, Zhang N, Tzeng E, Darrell T. DeCAF:a deep convolutional activation feature for generic visual recognition. arXiv:1310.1531, 2013. [113] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH, USA:IEEE, 2014. 580-587 [114] He K M, Zhang X Y, Ren S Q, Sun J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9):1904-1916 doi: 10.1109/TPAMI.2015.2389824 [115] Girshick R. Fast R-CNN. arXiv:1504.08083, 2015. [116] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN:towards real-time object detection with region proposal networks. arXiv:1506.01497, 2015. [117] Zhu Y K, Urtasun R, Salakhutdinov R, Fidler S. SegDeepM:exploiting segmentation and context in deep neural networks for object detection. arXiv:1502.04275, 2015. http://www.academia.edu/14266389/segDeepM_Exploiting_Segmentation_and_Context_in_Deep_Neural_Networks_for_Object_Detection [118] Han X F, Leung T, Jia Y Q, Sukthankar R, Berg A C. MatchNet:unifying feature and metric learning for patch-based matching. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015. 3279-3286 [119] Everingham M, Eslami S M A, Van Gool L, Williams C K I, Winn J, Zisserman A. The pascal visual object classes challenge:a retrospective. International Journal of Computer Vision, 2015, 111(1):98-136 doi: 10.1007/s11263-014-0733-5 [120] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z H, Karpathy A, Khosla A, Bernstein M, Berg A C, Li F F. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3):211-252 doi: 10.1007/s11263-015-0816-y [121] Sermanet P, Eigen D, Zhang X, Mathieu M, Fergus R, LeCun Y. OverFeat:integrated recognition, localization and detection using convolutional networks. arXiv:1312.6229, 2013. http://www.bibsonomy.org/bibtex/245b5a51026b1aa160b129a2e05c1a1f2/dblp [122] Lin M, Chen Q, Yan S C. Network in network. arXiv:1312.4400, 2013. [123] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015. 1-9 [124] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556, 2014. http://www.robots.ox.ac.uk/%7Evgg/research/very_deep/ [125] Ouyang W L, Luo P, Zeng X Y, Qiu S, Tian Y L, Li H S, Yang S, Wang Z, Xiong Y J, Qian C, Zhu Z Y, Wang R H, Loy C C, Wang X G, Tang X O. DeepID-Net:multi-stage and deformable deep convolutional neural networks for object detection. arXiv:1409.3505, 2014. [126] Maturana D, Scherer S. VoxNet:a 3D convolutional neural network for real-time object recognition. In:Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Hamburg, Germany:IEEE, 2015. 922-928 [127] He S F, Lau R W H, Liu W X, Huang Z, Yang Q X. SuperCNN:a superpixelwise convolutional neural network for salient object detection. International Journal of Computer Vision, 2015, 15(3):330-344 https://www.researchgate.net/publication/275246763_SuperCNN_A_Superpixelwise_Convolutional_Neural_Network_for_Salient_Object_Detection [128] Nam H, Han B. Learning multi-domain convolutional neural networks for visual tracking. arXiv:1510.07945, 2015. [129] Danelljan M, Häger G, Shahbaz Khan F, Felsberg M. Learning spatially regularized correlation filters for visual tracking. In:Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile:IEEE, 2015. 4310-4318 [130] Wang N Y, Li S Y, Gupta A, Yeung D Y. Transferring rich feature hierarchies for robust visual tracking. arXiv:1501.04587, 2015. [131] Kotsiantis S B, Zaharakis I D, Pintelas P E. Machine learning:a review of classification and combining techniques. Artificial Intelligence Review, 2006, 26(3):159-190 doi: 10.1007/s10462-007-9052-3 [132] Schölkopf B, Smola A J. Learning with Kernels:Support Vector Machines, Regularization, Optimization, and Beyond. London, England:MIT Press, 2002. http://www.researchgate.net/publication/240074728_Kernels_Regularization_and_Optimization [133] Lu Z W, Ip H H S. Image categorization with spatial mismatch kernels. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, Florida, USA:IEEE, 2009. 3974-404 https://www.computer.org/web/csdl/index/-/csdl/proceedings/cvpr/2009/3992/00/index.html [134] Lazebnik S, Schmid C, Ponce J. Beyond bags of features:spatial pyramid matching for recognizing natural scene categories. In:Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA:IEEE, 2006. 2169-2178 http://www.oalib.com/references/16875919 [135] Yang J C, Yu K, Gong Y H, Huang T. Linear spatial pyramid matching using sparse coding for image classification. In:Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, Florida, USA:IEEE, 2009. 1794-1801 [136] Kavukcuoglu K, Ranzato M A, Fergus R, LeCun Y. Learning invariant features through topographic filter maps. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, Florida, USA:IEEE, 2009. 1605-1612 https://www.computer.org/web/csdl/index/-/csdl/proceedings/cvpr/2009/3992/00/index.html [137] Gao S H, Tsang I W H, Chia L T, Zhao P L. Local features are not lonely-Laplacian sparse coding for image classification. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA:IEEE, 2010. 3555-3561 https://www.researchgate.net/publication/221364283_Local_features_are_not_lonely_-_Laplacian_sparse_coding_for_image_classification [138] Meshram S B, Shinde S M. A survey on ensemble methods for high dimensional data classification in biomedicine field. International Journal of Computer Applications, 2015, 111(11):5-7 doi: 10.5120/19580-1162 [139] Papageorgiou C, Poggio T. A trainable system for object detection. International Journal of Computer Vision, 2000, 38(1):15-33 doi: 10.1023/A:1008162616689 [140] Wu B, Nevatia R. Detection of multiple, partially occluded humans in a single image by Bayesian combination of edgelet part detectors. In:Proceedings of the 10th IEEE International Conference on Computer Vision. Beijing, China:IEEE, 2005. 90-97 [141] Wu B, Nevatia R. Cluster boosted tree classifier for multi-view, multi-pose object detection. In:Proceedings of the 11th IEEE International Conference on Computer Vision. Rio de Janeiro, Brazil:IEEE, 2007. 1-8 [142] Wang Y, Jodoin P M, Porikli F, Konrad J, Benezeth Y, Ishwar P. CDnet 2014:an expanded change detection benchmark dataset. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Columbus, OH, USA:IEEE, 2014. 393-400 [143] Dollár P, Wojek C, Schiele B, Perona P. Pedestrian detection:a benchmark. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, Florida, USA:IEEE, 2009. 304-311 [144] González A, Vázquez D, Ramos S, López A M, Amores J. Spatiotemporal stacked sequential learning for pedestrian detection. In:Proceedings of the 7th Iberian Conference on Pattern Recognition and Image Analysis. Santiago de Compostela, Spain:Springer, 2015. 3-12 doi: 10.1007/978-3-319-19390-8 [145] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick C L. Microsoft COCO:common objects in context. In:Proceedings of the 13th European Conference on Computer Vision (ECCV 2014). Zurich, Switzerland:Springer, 2014. 740-755 [146] Seber G A F, Lee A J. Linear Regression Analysis (Second Edition). New York:John Wiley & Sons, 2003. [147] Comaniciu D, Ramesh V, Meer P. Real-time tracking of non-rigid objects using mean shift. In:Proceedings of the 2000 IEEE Conference on Computer Vision and Pattern Recognition. Hilton Head, SC, USA:IEEE, 2000. 142-149 http://www.oalib.com/references/16342699 [148] Chen F S, Fu C M, Huang C L. Hand gesture recognition using a real-time tracking method and hidden Markov models. Image and Vision Computing, 2003, 21(8):745-758 doi: 10.1016/S0262-8856(03)00070-2 [149] Ali N H, Hassan G M. Kalman filter tracking. International Journal of Computer Applications, 2014, 89(9):15-18 doi: 10.5120/15530-4315 [150] Chang C, Ansari R. Kernel particle filter for visual tracking. IEEE Signal Processing Letters, 2005, 12(3):242-245 doi: 10.1109/LSP.2004.842254 [151] Comaniciu D, Ramesh V, Meer P. Kernel-based object tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(5):564-577 doi: 10.1109/TPAMI.2003.1195991 [152] Rahmati H, Aamo O M, StavdahlØ, Adde L. Kernel-based object tracking for cerebral palsy detection. In:Proceedings of the 2012 International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV). United States:CSREA Press, 2012. 17-23 [153] Melzer T, Reiter M, Bischof H. Appearance models based on kernel canonical correlation analysis. Pattern Recognition, 2003, 36(9):1961-1971 doi: 10.1016/S0031-3203(03)00058-X [154] Yilmaz A. Object tracking by asymmetric kernel mean shift with automatic scale and orientation selection. In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, Minnesota, USA:IEEE, 2007. 1-6 [155] Hu J S, Juan C W, Wang J J. A spatial-color mean-shift object tracking algorithm with scale and orientation estimation. Pattern Recognition Letters, 2008, 29(16):2165-2173 doi: 10.1016/j.patrec.2008.08.007 [156] Levey A, Lindenbaum M. Sequential Karhunen-Loeve basis extraction and its application to images. IEEE Transactions on Image Processing, 2000, 9(8):1371-1374 doi: 10.1109/83.855432 [157] Brand M. Incremental singular value decomposition of uncertain data with missing values. In:Proceedings of the 7th European Conference on Computer Vision (ECCV 2002). Copenhagen, Denmark:Springer, 2002. 707-720 http://dl.acm.org/citation.cfm?id=645315&picked=prox [158] De La Torre F, Black M J. A framework for robust subspace learning. International Journal of Computer Vision, 2003, 54(1-3):117-142 doi: 10.1023%2FA%3A1023709501986 [159] Li Y M. On incremental and robust subspace learning. Pattern Recognition, 2004, 37(7):1509-1518 doi: 10.1016/j.patcog.2003.11.010 [160] Skocaj D, Leonardis A. Weighted and robust incremental method for subspace learning. In:Proceedings of the 9th IEEE International Conference on Computer Vision. Nice, France:IEEE, 2003. 1494-1501 https://www.computer.org/csdl/proceedings/iccv/2003/1950/02/index.html [161] Ross D A, Lim J, Lin R S, Yang M H. Incremental learning for robust visual tracking. International Journal of Computer Vision, 2008, 77(1-3):125-141 doi: 10.1007/s11263-007-0075-7 [162] Wang Q, Chen F, Xu W L, Yang M H. Object tracking via partial least squares analysis. IEEE Transactions on Image Processing, 2012, 21(10):4454-4465 doi: 10.1109/TIP.2012.2205700 [163] Li X, Hu W M, Zhang Z F, Zhang X Q, Luo G. Robust visual tracking based on incremental tensor subspace learning. In:Proceedings of the 11th IEEE International Conference on Computer Vision. Rio de Janeiro, Brazil:IEEE, 2007. 1-8 [164] Wen J, Li X L, Gao X B, Tao D C. Incremental learning of weighted tensor subspace for visual tracking. In:Proceedings of the 2009 IEEE International Conference on Systems, Man and Cybernetics. San Antonio, Texas, USA:IEEE, 2009. 3688-3693 [165] Khan Z H, Gu I Y H. Nonlinear dynamic model for visual object tracking on grassmann manifolds with partial occlusion handling. IEEE Transactions on Cybernetics, 2013, 43(6):2005-2019 doi: 10.1109/TSMCB.2013.2237900 [166] Chin T J, Suter D. Incremental kernel principal component analysis. IEEE Transactions on Image Processing, 2007, 16(6):1662-1674 doi: 10.1109/TIP.2007.896668 [167] Mei X, Ling H B. Robust visual tracking using l1 minimization. In:Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 1436-1443 [168] Li H X, Shen C H, Shi Q F. Real-time visual tracking using compressive sensing. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA:IEEE, 2011. 1305-1312 [169] Jia X, Lu H C, Yang M H. Visual tracking via adaptive structural local sparse appearance model. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA:IEEE, 2012. 1822-1829 [170] Dong W H, Chang F L, Zhao Z J. Visual tracking with multifeature joint sparse representation. Journal of Electronic Imaging, 2015, 24(1):013006 doi: 10.1117/1.JEI.24.1.013006 [171] Hu W M, Li W, Zhang X Q, Maybank S. Single and multiple object tracking using a multi-feature joint sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(4):816-833 doi: 10.1109/TPAMI.2014.2353628 [172] Zhang T Z, Liu S, Xu C S, Yan S C, Ghanem B, Ahuja N, Yang M H. Structural sparse tracking. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015. 150-158 https://www.computer.org/csdl/proceedings/cvpr/2015/6964/00/index.html [173] Zhong W, Lu H C, Yang M H. Robust object tracking via sparse collaborative appearance model. IEEE Transactions on Image Processing, 2014, 23(5):2356-2368 doi: 10.1109/TIP.2014.2313227 [174] Bai T X, Li Y F. Robust visual tracking with structured sparse representation appearance model. Pattern Recognition, 2012, 45(6):2390-2404 doi: 10.1016/j.patcog.2011.12.004 [175] Zhang S P, Yao H X, Zhou H Y, Sun X, Liu S H. Robust visual tracking based on online learning sparse representation. Neurocomputing, 2013, 100:31-40 doi: 10.1016/j.neucom.2011.11.031 [176] Wang N Y, Wang J D, Yeung D Y. Online robust nonnegative dictionary learning for visual tracking. In:Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, Australia:IEEE, 2013. 657-664 http://www.oalib.com/references/17185722 [177] Zhang X, Guan N Y, Tao D C, Qiu X G, Luo Z G. Online multi-modal robust non-negative dictionary learning for visual tracking. PLoS One, 2015, 10(5):657-664 [178] Oza N C. Online bagging and boosting. In:Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics. Waikoloa, Hawaii, USA:IEEE, 2005. 2340-2345 [179] Valiant L. Probably Approximately Correct:Nature0s Algorithms for Learning and Prospering in a Complex World. New York, USA:Basic Books, 2013. http://www.amazon.de/Probably-Approximately-Correct-Algorithms-Prospering-ebook/dp/B00BE650IQ [180] Grabner H, Grabner M, Bischof H. Real-time tracking via on-line boosting. In:Proceedings of the 2006 British Machine Conference. Edinburgh, UK:British Machine Vision Association, 2006. 6.1-6.10 [181] Liu X M, Yu T. Gradient feature selection for online boosting. In:Proceedings of the 11th IEEE International Conference on Computer Vision. Rio de Janeiro, Brazil:IEEE, 2007. 1-8 http://www.oalib.com/references/16891977 [182] Avidan S. Ensemble tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(2):261-271 doi: 10.1109/TPAMI.2007.35 [183] Parag T, Porikli F, Elgammal A. Boosting adaptive linear weak classifiers for online learning and tracking. In:Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, Alaska, USA:IEEE, 2008. 1-8 https://www.computer.org/csdl/proceedings/cvpr/2008/2242/00/index.html [184] Visentini I, Snidaro L, Foresti G L. Dynamic ensemble for target tracking. In:Proceedings of the 8th IEEE International Workshop on Visual Surveillance (VS2008). Marseille, France:IEEE, 2008. 1-8 [185] Okuma K, Taleghani A, De Freitas N, Little J J, Lowe D G. A boosted particle filter:multitarget detection and tracking. In:Proceedings of the 8th European Conference on Computer Vision (ECCV 2004). Prague, Czech Republic:Springer, 2004. 28-39 [186] Wang J Y, Chen X L, Gao W. Online selecting discriminative tracking features using particle filter. In:Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA:IEEE, 2005. 1037-1042 https://www.computer.org/web/csdl/index/-/csdl/proceedings/cvpr/2005/2372/02/index.html [187] Avidan S. Support vector tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(8):1064-1072 doi: 10.1109/TPAMI.2004.53 [188] Williams O, Blake A, Cipolla R. Sparse Bayesian learning for efficient visual tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8):1292-1304 doi: 10.1109/TPAMI.2005.167 [189] Tian M, Zhang W W, Liu F Q. On-line ensemble SVM for robust object tracking. In:Proceedings of the 8th Asian Conference on Computer Vision (ACCV 2007). Tokyo, Japan:Springer, 2007. 355-364 [190] Yao R, Shi Q F, Shen C H, Zhang Y N, van den Hengel A. Part-based visual tracking with online latent structural learning. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Portland, OR, USA:IEEE, 2013. 2363-2370 [191] Bai Y C, Tang M. Robust tracking via weakly supervised ranking SVM. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA:IEEE, 2012. 1854-1861 [192] Hare S, Saffari A, Torr P H S. Struck:structured output tracking with kernels. In:Proceedings of the 2011 International Conference on Computer Vision (ICCV). Barcelona, Spain:IEEE, 2011. 263-270 [193] Tang F, Brennan S, Zhao Q, Tao H. Co-tracking using semisupervised support vector machines. In:Proceedings of the 11th IEEE International Conference on Computer Vision. Rio de Janeiro, Brazil:IEEE, 2007. 1-8 https://www.computer.org/web/csdl/index/-/csdl/proceedings/iccv/2007/1630/00/index.html [194] Zhang S L, Sui Y, Yu X, Zhao S C, Zhang L. Hybrid support vector machines for robust object tracking. Pattern Recognition, 2015, 48(8):2474-2488 doi: 10.1016/j.patcog.2015.02.008 [195] Zhang X M, Wang M G. Compressive tracking using incremental LS-SVM. In:Proceedings of the 27th Chinese Control and Decision Conference (CCDC). Qingdao, China:IEEE, 2015. 1845-1850 [196] Breiman L. Random forests. Machine Learning, 2001, 45(1):5-32 doi: 10.1023/A:1010933404324 [197] Saffari A, Leistner C, Santner J, Godec M, Bischof H. Online random forests. In:Proceedings of the 12th IEEE International Conference on Computer Vision (ICCVW). Kyoto, Japan:IEEE, 2009. 1393-1400 http://www.oalib.com/references/19330612 [198] Leistner C, Saffari A, Bischof H. Miforests:multipleinstance learning with randomized trees. In:Proceedings of the 11th European Conference on Computer Vision (ECCV 2010). Crete, Greece:Springer, 2010. 29-42 [199] Godec M, Leistner C, Saffari A, Bischof H. On-line random naive bayes for tracking. In:Proceedings of the 20th International Conference on Pattern Recognition (ICPR). Istanbul, Turkey:IEEE, 2010. 3545-3548 [200] Wang A P, Wan G W, Cheng Z Q, Li S K. An incremental extremely random forest classifier for online learning and tracking. In:Proceedings of the 16th IEEE International Conference on Image Processing (ICIP). Cairo, Egypt:IEEE, 2009. 1449-1452 [201] Lin R S, Ross D A, Lim J, Yang M H. Adaptive discriminative generative model and its applications. In:Proceedings of the 2004 Advances in Neural Information Processing Systems 17. Vancouver, British Columbia, Canada:MIT Press, 2004. 801-808 [202] Nguyen H T, Smeulders A W M. Robust tracking using foreground-background texture discrimination. International Journal of Computer Vision, 2006, 69(3):277-293 doi: 10.1007/s11263-006-7067-x [203] Li X, Hu W M, Zhang Z F, Zhang X Q, Zhu M L, Cheng J. Visual tracking via incremental log-Euclidean Riemannian subspace learning. In:Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, Alaska, USA:IEEE, 2008. 1-8 [204] Wang X Y, Hua G, Han T X. Discriminative tracking by metric learning. In:Proceedings of the 11th European Conference on Computer Vision (ECCV 2010). Heraklion, Crete, Greece:Springer, 2010. 200-214 http://dblp.uni-trier.de/db/conf/eccv/eccv2010-3 [205] Tsagkatakis G, Savakis A. Online distance metric learning for object tracking. IEEE Transactions on Circuits and Systems for Video Technology, 2011, 21(12):1810-1821 doi: 10.1109/TCSVT.2011.2133970 [206] Xu Z F, Shi P F, Xu X Y. Adaptive subclass discriminant analysis color space learning for visual tracking. In:Proceedings of the 9th Pacific Rim Conference on Advances in Multimedia Information Processing (PCM 2008). Tainan, China:Springer, 2008. 902-905 [207] Zhang X Q, Hu W M, Chen S Y, Maybank S. Graphembedding-based learning for robust object tracking. IEEE Transactions on Industrial Electronics, 2014, 61(2):1072-1084 doi: 10.1109/TIE.2013.2258306 [208] 查宇飞, 毕笃彦, 杨源, 董守平, 罗宁.基于全局和局部约束直推学习的鲁棒跟踪研究.自动化学报, 2010, 36(8):1084-1090 doi: 10.3724/SP.J.1004.2010.01084Zha Yu-Fei, Bi Du-Yan, Yang Yuan, Dong Shou-Ping, Luo Ning. Transductive learning with global and local constraints for robust visual tracking. Acta Automatica Sinica, 2010, 36(8):1084-1090 doi: 10.3724/SP.J.1004.2010.01084 [209] Wu Y, Lim J, Yang M H. Online object tracking:a benchmark. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 2411-2418 [210] Wu Y, Lim J, Yang M H. Object tracking benchmark. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9):1834-1848 doi: 10.1109/TPAMI.2014.2388226 [211] Collins R, Zhou X H, Teh S K. An open source tracking testbed and evaluation web site. In:Proceedings of IEEE International Workshop on Performance Evaluation of Tracking and Surveillance. Beijing, China:IEEE, 2005. http://www.oalib.com/references/9307084 [212] Fisher R B. The PETS04 surveillance ground-truth data sets. In:Proceedings of the 6th IEEE International Workshop on Performance Evaluation of Tracking and Surveillance. Prague, Czech Republic:IEEE, 2004. 1-5 [213] Pellegrini S, Ess A, Schindler K, van Gool L. You 0ll never walk alone:modeling social behavior for multi-target tracking. In:Proceedings of the 12th IEEE International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 261-268 [214] Leibe B, Schindler K, Van Gool L. Coupled detection and trajectory estimation for multi-object tracking. In:Proceedings of the 11th IEEE International Conference on Computer Vision. Rio de Janeiro, Brazil:IEEE, 2007. 1-8 https://lirias.kuleuven.be/handle/123456789/276721 [215] Milan A, Leal-Taixe L, Reid I, Roth S, Schindler K. MOT16:a benchmark for multi-object tracking. arXiv:1603.00831, 2016. http://arxiv.org/pdf/1603.00831v2.pdf [216] Li L Z, Nawaz T, Ferryman J. PETS 2015:datasets and challenge. In:Proceedings of the 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). Karlsruhe, Germany:IEEE, 2015. 1-6 https://www.computer.org/csdl/proceedings/avss/2015/7632/00/index.html [217] Kristan M, Matas J, Leonardis A, Felsberg M, Cehovin L, Fernandez G, Vojir T, Hager G, Nebehay G, Pflugfelder R, Gupta A, Bibi A, Lukezic A, Garcia-Martin A, Saffari A, Petrosino A, Montero A S. The visual object tracking VOT 2015 challenge results. In:Proceedings of the 2015 IEEE International Conference on Computer Vision Workshops. Santiago, Chile:IEEE, 2015. 564-586 [218] Lee J Y, Yu W. Visual tracking by partition-based histogram backprojection and maximum support criteria. In:Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics (ROBIO). Karon Beach, Thailand:IEEE, 2011. 2860-2865 [219] Vojir T, Noskova J, Matas J. Robust scale-adaptive meanshift for tracking. Pattern Recognition Letters, 2014, 49:250-258 doi: 10.1016/j.patrec.2014.03.025 [220] Zhang K H, Zhang L, Yang M H. Real-time compressive tracking. In:Proceedings of the 12th European Conference on Computer Vision (ECCV 2012). Florence, Italy:Springer, 2012. 864-877 [221] Bao C L, Wu Y, Ling H B, Ji H. Real time robustll tracker using accelerated proximal gradient approach. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA:IEEE, 2012. 1830-1837 [222] Binh N D. Online boosting-based object tracking. In:Proceedings of the 12th International Conference on Advances in Mobile Computing and Multimedia. Kaohsiung, China:ACM, 2014. 194-202 [223] Dinh T B, Vo N, Medioni G. Context tracker:exploring supporters and distracters in unconstrained environments. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI:IEEE, 2011. 1177-1184 http://www.oalib.com/references/19330642 [224] Dollár P, Belongie S, Perona P. The fastest pedestrian detector in the west. In:Proceedings of the 2010 British Machine Vision Conference. Aberystwyth, UK:British Machine Vision Association, 2010. 68.1-68.11 http://www.researchgate.net/publication/221259170_The_Fastest_Pedestrian_Detector_in_the_West [225] Hare S, Golodetz S, Saffari A, Vineet V, Cheng M M, Hicks S, Torr P. Struck:structured output tracking with kernels. IEEE Transactions on Pattern Analysis and Machine Intelligence, DOI: 10.1109/TPAMI.2015.2509974 [226] Babenko B, Yang M H, Belongie S. Robust object tracking with online multiple instance learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8):1619-1632 doi: 10.1109/TPAMI.2010.226 [227] Kristan M, Pflugfelder R, Leonardis A, Matas J, ČehovinL, Nebehay G, Vojıř T, Fernández G, LukežičA, Dimitriev A, Petrosino A, Saffari A, Li B, Han B, Heng C, Garcia C, PangeršičD, Häger G, Khan F S, Oven F, Possegger H, Bischof H, Nam H, Zhu J K, Li J J, Choi J Y, Choi J W, Henriques J F, van de Weijer J, Batista J, Lebeda K, Öfjäll K, Yi K M, Qin L, Wen L Y, Maresca M E, Danelljan M, Felsberg M, Cheng M M, Torr P, Huang Q M, Bowden R, Hare S, Lim S Y, Hong S, Liao S C, Hadfield S, Li S Z, Duffner S, Golodetz S, Mauthner T, Vineet V, Lin W Y, Li Y, Qi Y K, Lei Z, Niu Z H. The visual object tracking VOT2014 challenge results. In:Proceedings of the European Conference on Computer Vision (ECCV 2014), Lecture Notes in Computer Science. Zurich, Switzerland:Springer International Publishing, 2015. 191-217 -

 下载:
下载:

计量
- 文章访问数: 8066
- HTML全文浏览量: 2286
- PDF下载量: 8272
- 被引次数: 0
