

-
摘要: 随着指纹识别技术的广泛应用,大量指纹图像需要被收集和存储.在指纹识别系统中,对于大容量的指纹数据库,指纹图像必须经过压缩后存储以减少存储空间,本文提出了基于自适应稀疏变换的指纹图像压缩算法.该算法在离线状态下提取指纹图像特征训练超完备字典;在编码过程中,首先利用差分预测编码和稀疏变换将待压缩指纹图像转换到稀疏域,然后对直流系数和稀疏表达系数进行量化和熵编码,从而实现图像信息的压缩.实验表明,在中低码率段,本文算法相比于JPEG、JPEG2000和WSQ等主流压缩算法表现出更优越的率失真性能;在相同码率时,本文算法生成的压缩图像的主观视觉效果更好,指纹识别率更高.Abstract: With the wide application of fingerprint identification technology, a large number of fingerprint images need to be collected and stored. In fingerprint identification, as for the fingerprint database with large-capacity, the fingerprint images must be stored after compression to reduce the storage space. In this paper, a fingerprint image compression algorithm based on adaptive sparse transformation is proposed. The feature of the fingerprint image is extracted offline to train the over-complete dictionary. In the encoding process, the fingerprint image to be compressed is converted to sparse domain by utilizing the differential predictive coding and sparse transformation in the first place; after that the DC coefficients and the sparse coefficients are quantized and entropy coded to achieve the compression of the image information. Experimental results show that the proposed algorithm outperforms the mainstream compression methods, such as JPEG, JPEG2000 and WSQ, in terms of ratio-distortion performance of decoded fingerprint image, especially at low to medium bit rates. At the same bit rate, the compression image generated by the proposed algorithm exhibits better subjective visual effect and higher fingerprint recognition rate.
-
集束型设备已被广泛地应用于半导体制造的晶圆加工中[1-2].由于集束型设备加工晶圆时存在多重入流、驻留及资源约束等现象[3],使得集束型设备的调度变得非常复杂.近年来,为了提高设备的产能,集束型设备的结构随着不断改进也出现很多不同的变化,其中一些学者另辟蹊径,希望通过合理地设置缓冲模块来提高设备的产能[4].而对于增加缓冲模块的新型结构的集束型设备来说,现有的调度方法定然不能满足其生产要求,这就需要新的调度方法来支持其调度.
集束型设备一般由多个晶圆加工模块(Processing module,PM)、一个晶圆搬运模块(Transport module,TM)和负责晶圆输入输出的卡匣模块(Cassette modules,CM) 组成.作为晶圆加工特有的工艺要求,驻留约束限制了晶圆在加工模块完成加工后所能停留的时间上限(Upper bound) ,即当晶圆在加工完成后,必须在规定时间范围内离开加工模块,否则残余气体或不适宜温度会导致晶圆出现质量问题,甚至不良品.驻留现象广泛存在于半导体制造过程中[5].针对一般的驻留约束问题,大部分研究都是通过调整晶圆的加工开始时间来满足晶圆的驻留约束[6],一些学者通过设置缓冲模块的方法,使晶圆在加工完成后能够尽早离开加工模块,释放资源,提前下一个晶圆的加工开始时间.
目前,对于一般的集束型设备的周期调度研究已经比较成熟. Perkinson等[7] 与Venkatesh等[8]在不考虑驻留约束的情况下,分别采用推策略和交换策略来获得单臂与双臂集束型设备的最优的基本周期(Fundamental period,FP). Lim等[9] 为了有效提高整体调度周期,考虑晶圆搬运延迟,并提出了一个基于时间表技术的有效实时调度算法.
然而,前面的文献没有考虑驻留约束对集束型设备的调度影响.目前已有相关文献对带驻留约束的集束型设备调度问题进行了研究,Wu等[10]为带驻留约束的集束型设备建立了Petri-网模型,提出了一个封闭式调度算法来获得最优周期的调度.Rostami等[11]运用线性规划和启发式算法来调度带驻留约束的单集束型设备.Zhou等[12]提出了基于侦误的调度启发式算法用于解决带驻留约束的集束型设备调度问题.Rostami等[13]对集束型设备带有加工模块和搬运模块的双驻留约束模型提出了一种调度算法,得到了问题的近优解.
上述文献虽然考虑了驻留约束,却没有考虑缓冲模块对设备产能的影响.对于集束型设备的缓冲模块的研究目前正在起步,Ding等[14]在集束型设备群的研究中,对各个集束型之间的缓冲连接进行了研究.Dawande等[15]比较了制造单元里带输出缓冲和无缓冲的模型,证明带有输出缓冲的制造单元比双爪不带缓冲的制造单元的生产率提高了20%.Drobouchevitch等[16]表明在制造单元的每个机器已存在输出缓冲的基础上增加一个输入缓冲不会提高设备的产能.
上述文献表明,目前对同时带驻留约束和缓冲模块的集束型设备调度问题尚无人研究.本文旨在上述文献的研究基础上,对带驻留约束的集束型设备进行了研究,通过在加工模块之间设置缓冲模块的方法,提高系统产能.该调度问题主要是确定优化的搬运顺序和搬运时间点以获得最小的周期调度.首先,对调度问题在不同搬运模式下建立了相应数学模型;再提出两种不同的调度算法;最后,评价算法的同时,分析缓冲对系统产能的影响.
1. 问题描述
集束型设备里,晶圆由卡匣模块进入,按顺序到每个加工模块加工,完成所有加工后回到卡匣模块.本文的研究对象为加工模块之间带有缓冲模块的单臂集束型设备,如图 1所示.
为有效地描述带缓冲的集束型晶圆制造设备的调度问题,做如下的基本定义与假设:1) 加工模块,搬运模块和缓冲模块在同一时间均只能处理一个晶圆.2) 加工模块上存在驻留约束现象.3) 搬运模块搬运晶圆的时间和装卸时间是确定的.4) 每个晶圆的加工工艺流程都相同.5) 若晶圆进入缓冲模块,缓冲模块被视作虚拟的加工模块,其加工时间为零,且不存在驻留约束;否则,晶圆跳过缓冲模块直接到下一个加工模块进行加工.6) 晶圆在卡匣模块供应充足,晶圆完成最后一道加工工序后直接被搬运到卡匣模块.
为了清晰地表述调度问题,现定义如下符号与变量:
$m$ : 集束型设备加工模块的数量.
$p_i$ : 晶圆 $j$ 在加工模块 $i$ 上的加工时间.
$\delta_i$ : 搬运模块把晶圆从 $M_i$ 搬运到 $M_{i+1}$ 的时间,包括装载和卸载晶圆的时间 $\delta_i=\delta$ .
$\theta_{ij}$ : 搬运模块从 $M_i$ 到 $M_j$ 的空移动的时间 $\theta_{ij}=\min(|i-j|,2m-|i-j|)\cdot\theta$ .
$λ_k$ : 表示晶圆 $j$ 是否经过模块 $M_k$ ,如果是,那么 $λ_k=1$ ;否则, $λ_k=0$ .
$\varphi(i)$ : 表示搬运模块从第 $\varphi(i)$ 模块搬运到 $(\varphi(i)+2-λ_{\varphi(i)+1})$ 模块.
$s_j$ : 搬运模块的搬运模式.
$T$ : 生产每个晶圆的周期时间.
定义 1. 一个单元搬运模式(One-unit TM move style)是指一个晶圆进入加工模块到下一个晶圆开始进入加工模块之间的搬运模块的所有搬运动作.可以通过如下形式来表示: $s=[\varphi(0) ,\varphi(1) ,\varphi(2) ,\cdots,\varphi(m)]$ ,其中 $s$ 是由 $\{0,1,2,\cdots,m\}$ 的排列组成.
由于搬运模式的重复性,假设 $\varphi(0)=0$ ,不失一般性, $\varphi[i\pm(\sum_{k=0}^{2m-1}\lambda_k+1)]=\varphi(i)$ . 两个加工模块的单集束型设备的搬运模式包括如下: $s_1=[0,1,3]$ , $s_2=[0,3,1]$ , $s_3=[0,1,2,3]$ , $s_4=[0,1,3,2]$ , $s_5=[0,2,1,3]$ , $s_6=[0,2,3,1]$ , $s_7=[0,3,1,2]$ , $s_8=[0,3,2,1]$ .
定义 2. 给定一个搬运模式 $s$ ,其中 $\varphi(k)=i$ ,那么 $\varphi(k)$ 的反函数为 $\varphi^-(k)$ , $0\leq\varphi^-(k)\leq m$ , $k=0,1,\cdots,m$ , $\varphi^-(\varphi(i))=i$ ,且 $\varphi(\varphi^-(k))=k$ .
从定义可知,对给定的搬运模式来说,如果搬运模块从 $M_k$ 卸载晶圆,该搬运动作处于单元搬运模式的 $\varphi^-(k)$ th位置,那么当存在 $\varphi^-(k)>\varphi^-(k-2+λ_{k-1})$ 时,从 $M_k$ 装载和卸载的同一片晶圆的搬运动作处于同一个单元搬运模式内;当存在 $\varphi^-(k)<\varphi^-(k-2+λ_{k-1})$ 时,从 $M_k$ 装载和卸载的同一片晶圆的搬运动作却分别处于两个先后的单元搬运模式内.所以 $u_k$ 被定义如下:
\begin{align}u_k=\left\{\begin{array}{c}1,\quad \varphi^-(k)<\varphi^-(k-2+λ_{k-1})\\0,\quad \varphi^-(k)>\varphi^-(k-2+λ_{k-1})\end{array} \right. \end{align}
(1) 任何单元搬运模式内都存在一些不可避免的搬运动作,如晶圆卸载和装载、晶圆的搬运等,用 $IC(s)$ 来表示给定单元搬运模式 $s$ 中必然存在的搬运动作,其表达式如下:
$IC(s)=\sum\limits_{i=0}^{2m-1}{(}{{\delta }_{\varphi (i)}}+{{\theta }_{\varphi (i)}}+2-{{\lambda }_{\varphi (i)+1}},\varphi (i+2-{{\lambda }_{i+1}}))\text{ }$
(2) 在单元搬运模式 $s$ 下,一片晶圆从装载至模块 $M_k$ 到加工完后被卸载这段时间内,搬运模块所耗费的所有的繁忙时间用 $z_k(s)$ 表示:
${{z}_{k}}(s)={{\theta }_{k,{{\tau }_{k}}(s)}}+\sum\limits_{i}^{{{b}_{k}}}{(}{{\delta }_{\varphi (i)}}+{{\theta }_{\varphi (i)}}+2-{{\lambda }_{\varphi (i)+1}},\varphi (i+2-{{\lambda }_{i+1}}))$
(3) 其中, $\tau_k(s)$ 为搬运动作 $k-1$ 的下一搬运动作,即 $\tau_k(s)=\varphi[\varphi^-(k-2+λ_{k-1})+1]$ ,而 $i$ 的初始值为: $\varphi^-(k-2+λ_{k-1})+1$ ,且 $b_k=\varphi^-(k)-1+u_k(\sum_{j=0}^{2m}λ_j+1) $ .
若存在常数 $T$ 使得集束型设备生产状态经 $T$ 时间回到相同的状态,则该时间 $T$ 被称作周期时间.
令 $w_{kj}$ 是指搬运模块在 $M_k$ 等待搬运晶圆 $j$ 的时间.由于周期生产的性质,假设 $\sigma(j\pm n)=\sigma(j)$ , $w_{k,\sigma(j\pm n)}=w_{k,\sigma(j)}$ ,从假设5) 和6) 可知,当 $k$ 是偶数时, $w_{kj}=0$ .
若 $T(s)$ 是相应的搬运模式 $s$ 的周期时间,则目标函数 $T(s)$ 就有:
\begin{align}T(s)=\min\left(IC(s)+\sum_{j=1}^n\sum_{k=0}^mw_{kj}\right) \end{align}
(4) 由加工时间需求的约束与假设1) 可知,晶圆在 $M_k$ 上加工需满足如下约束:
$\sum\limits_{i}^{{{\varphi }^{-}}(k)}{{{w}_{\varphi (i)}}}\ge \max ({{p}_{k}}-{{z}_{k}},0),{{u}_{k}}=0$
(5) $\sum\limits_{i=1}^{\Sigma {{\lambda }_{l}}}{+}\sum\limits_{i}^{{{\varphi }^{-}}(k)}{{{w}_{\varphi (i)}}}\ge \max ({{p}_{k}}-{{z}_{k}},0),{{u}_{k}}=1$
(6) 其中,式(5) 和式(6) 中 $i$ 的初始值为: $i=\varphi^-(k-2+λ_{k-1})+2-λ_{\varphi^-(k-2+λ_{k-1})+1}$ .
由假设2) 的驻留约束有:
\begin{align}z_k-p_k\leq a_k \end{align}
(7) 搬运模块的等待时需满足非负:
\begin{align}w_k\geq 0 \end{align}
(8) 所以,对于给定的搬运模式 $s$ ,要优化目标函数(4) ,服从约束(5) $\sim$ (8) .其中的 $IC(s)$ 与决策变量 $w_{kj}$ 相互独立.
本文是在搬运模式下建立相应的数学模型,在前面数学建模里,该模型的复杂度为 ${\rm O}(m× n)$ ,是多项式内可以求解. 而搬运模式的规模为 ${\rm O}((m+2) m!)$ ,那么整个问题解空间的规模为 ${\rm O}(n(m^2+2m)m!)$ .所以对于问题的求解分为两个阶段:加工等待时间优化和晶圆搬运顺序优化.然后分别构建全局搜索算法和分枝搜索算法对问题进行求解.
2. 全局搜索算法
在集束型设备中,为了方便构建算法,提出以下引理:
引理 1. 生产单晶圆类型的集束型设备,使用超过两个单元搬运模式一般都不是最优的搬运策略.
证明. 假设 $T_i^h$ 是在 $s_i$ 搬运模式下的周期时间, $T_i^h$ 表示在 $s_i$ 搬运模式下的周期时间,且有 $T_i^h=T_j^h$ .那么 $2T_i^h$ 就是在 $s_i$ 下生产两个晶圆的时间,而 $2T_j^h$ 为在 $s_j$ 下生产两个晶圆的时间.如果有 $T_i^h\geq T_j^h$ ,则 $2T_i^h\geq T_i^h+T_j^h\geq 2T_j^h$ ;否则,如果 $T_i^h\leq T_j^h$ ,则有 $2T_i^h\leq T_i^h+T_j^h\leq 2T_j^h$ .可知 $T_i^h+T_j^h$ 不可能小于 $\min(2T_i^h,2T_j^h)$ 的,即两种搬运模式的组合一般不是最优策略.对于超过两个周期的情况证法相似.
定理 1.生产单晶圆类型的集束型设备,最优的搬运策略必定是单一的搬运模式.
证明. 假设 $\Omega$ 为所有的搬运策略集合, $\Omega$ 由 $k$ 个集合即 $\{\Omega_1,\Omega_2,\cdots,\Omega_k\}$ 组成,其中 $\Omega_k$ 表示 $k$ 种不同搬运模式组成的搬运策略集合,那么必有最优策略 $X\in\Omega$ .假设定理1不成立,那么有 $X\in\Omega$ . 由引理1可知, $X\in\Omega|k\geq2$ ,则 $X\in {\bf C}_\Omega(\Omega_k)$ , ${\bf C}_\Omega(\Omega_k)$ ,即 $X\in\Omega_1$ ,与假设矛盾.所以定理成立.
由定理1可知,最优搬运模式 $s_i$ 必然存在于有限搬运模式集合 $\{s\}$ .给定的晶圆搬运模式 $s_i$ 里,问题可被描述为前一部分提出的模型.分别用 $u_{ki}$ , $z_{ki}$ 和 $w_{ki}$ 表示在搬运模式 $s_i$ 下的 $u_k$ , $z_k$ 和 $w_k$ .
单晶圆类型的调度搜索算法描述如下:
输入. 搬运时间 $\delta$ 与 $\theta$ ,加工晶圆 $W_j$ 的加工时间 $p_k$ 和驻留约束时间 $a_k$ .
输出. 晶圆 $W_j$ 的最优搬运策略周期时间 $T_j$ .
步骤 1. 载入相关参数,比如 $m$ , $p_k$ , $a_k$ , $\delta$ 和 $\theta$ . 令 $i=0$ , $k=0$ 和 $T=+\infty$ .
步骤 2.令 $i=i+1$ ,如果有 $italic>(m+2) m!||italic>G$ ,那么转到步骤7;否则,转到步骤3.
步骤 3.令 $k=k+1$ ,如果 $k>2m+1$ ,那么转到步骤5;否则,搬运模式为 $s_i$ ,利用式(2) 计算出 $IC(s_i)$ ,利用式(3) 计算出 $z_{ki}$ .
步骤 4.如果满足 $z_{ki}-p_k>a_k$ ,那么转到步骤2;否则,转到步骤3.
步骤 5. 如果 $k$ 为偶数,就令 $w_{ki}=0$ .
步骤 6. 优化的目标函数(4) ,服从约束(5) $\sim$ (8) ,求得所有 $w_{kt}$ 和 $T(s_i)$ .如果 $T(s_i)<T$ ,那么 $T=T(s_i)$ 且 $h=i$ ;否则, $T$ 保持不变.然后转回步骤2.
步骤 7. $s_h$ 就是晶圆 $W_j$ 的最优搬运策略.
3. 下界估算
问题的下界首先被用于提高分枝算法的速度,再被用来验证近似最优解的优劣.该部分松弛驻留约束(7) ,那么原问题就转换为以式(4) 为优化目标函数,并服从约束(5) 、(6) 和(8) 的松弛问题.按照文献 [7-8]的拉式与推式策略结合得到下界估算算法:
步骤 1. 初始化数据,如果 $p_{\max} {\geq2m(\delta+\theta)}$ ,则 $T=p_{\max}+2(\delta+\theta)$ ; 否则,转到步骤2.
步骤 2. 令 $i=1$ , $j=1$ , $K$ 取最大值下标.
步骤 3. $n=i+j$ ,当 $n\leq m$ 时,转步骤4; 否则,当 $j\geq2$ 时转步骤8, $j=1$ 转步骤10.
步骤 4. 若 $n=K$ ,则转步骤6; 否则,转步骤5.
步骤 5. 若 $\sum_i^n{p_i}+(n-i)\delta\leq p_{\max}$ ,则 $j=j+1$ ,转到步骤3;否则,若 $\sum_i^{n-1}{p_i}+(n-1-i)\delta<p_{\max}$ ,转到步骤9;否则, $i=i+1$ , $j=1$ ,转步骤3.
步骤 6. 如果 $\sum_i^{n-1}{p_i}+(n-1-i)\delta\leq p_{\max}$ ,转到步骤7.
步骤 7. $p_i=\sum_i^{K-1}{p_i}+(K-1-i)\delta$ , $p_{i+k}=p_{K-1+k}$ , $m=m+i-K+1$ , $K=i+1$ , $i=K+1$ , $j=1$ ,转到步骤3.
步骤 8.若 $\sum_i^{n-1}{p_i}+(n-1-i)\delta<p_{\max}$ ,转到步骤9,否则 $i=i+1$ , $j=1$ ,转步骤3.
步骤 9. $p_i=\sum_i^{n-1}{p_i}+(n-1-i)\delta$ , $p_{i+k}=p_{n-1+k}$ , $m=m+i-n+1$ , $K=K+i-n+1$ ,若 $p_{\max}\geq2m(\delta+\theta)$ ,则 $T=p_{\max}+2(\delta+\theta)$ ; 否则, $i=i+1$ , $j=1$ ,转到步骤3.
步骤 10. 如果当 $p_{\max}\geq 2m(\delta+\theta)$ ,那么有 $T=p_{\max}+2(\delta+\theta)$ ; 否则, $T=2(m+1) (\delta+\theta)$ .
最后算法得到的最优解即为原问题的下界.
4. 分枝搜索算法
本节对带缓冲的两加工模块的集束型设备详细分析,根据第一节的模型建立数学模型,得到每种搬运模式的周期时间的表达式,最后分析比较各自的周期时间.
当 $s=s_5$ 时, $\varphi(k)$ 、 $\varphi^-(k)$ 、 $u_{k5}$ 和 $λ_k$ 的值如表 1所示.
表 1 $s=s_5$ 时相应参数的值Table 1 The relevant parameter when $s=s_5$$k$ 0 1 2 3 $\varphi(k)$ 0 2 1 3 $\varphi^-(k)$ 0 2 1 3 $u_k5$ $\setminus$ 0 1 0 ${{\lambda }_{k}}$ 1 1 1 1 那么问题可以转化为目标函数:
$\min \sum\limits_{i=1}^{3}{({{w}_{i5}})}$
约束条件为
${{w}_{15}}+{{w}_{25}}\ge \max ({{p}_{1}}-{{z}_{15}},0)\text{ }$
(9) ${{w}_{25}}+{{w}_{35}}\ge \max ({{p}_{2}}-{{z}_{25}},0)\text{ }$
(10) ${{w}_{15}}+{{w}_{35}}\ge \max ({{p}_{3}}-{{z}_{35}},0)\text{ }$
(11) ${{z}_{15}}-{{p}_{1}}\le {{a}_{1}}$
(12) ${{z}_{25}}-{{p}_{2}}\le {{a}_{2}}$
(13) ${{z}_{35}}-{{p}_{3}}\le {{a}_{3}}$
(14) 解得:
${{w}_{15}}=\max ({{p}_{1}}-{{z}_{15}},0)\text{ }$
(15) ${{w}_{25}}=0\text{ }$
(16) ${{w}_{35}}=\max ({{p}_{3}}-{{z}_{35}}-{{w}_{15}},{{p}_{2}}-{{z}_{25}},0)\text{ }$
(17) 搬运模式 $s_5$ 的周期时间为 $T_5$ ,由式(4) 可知:
\begin{align}T_5=IC(s_5) +\sum_{i=1}^3w_{i5} \end{align}
(18) 其中
\begin{align}IC(s_5) =4\delta+4\theta \end{align}
(19) 把式(15) $\sim$ (17) 、(19) 带入式(18) 可得:
\begin{align*}&T_5=4\delta+4\theta+w_{15}+w_{25}+w_{35}=\\&\quad 4\delta+4\theta+w_{15}+\max(p_3-\delta-3\theta-w_{15},0) =\\&\quad 4\delta+4\theta+\max(p_3-\delta-3\theta,w_{15})=\\&\quad 4\delta+4\theta+\max(p_3-\delta-3\theta,\max(p_3-\delta-3\theta,0) )=\\&\quad 3\delta+\theta+\max(p_3,\max(p_1,\delta+3\theta))=\\&\quad 3\delta+\theta+\max(p_3,p_1,\delta+3\theta)\end{align*}
整理后:
\begin{align}T_5=3\delta+\theta+\max(p_3,p_1,\delta+3\theta) \end{align}
(20) 相似地,能分别得到各种搬运模式 $s_1$ , $s_2$ , $s_3$ , $s_4$ , $s_5$ , $s_6$ , $s_7$ , $s_8$ 的周期时间 $T_1$ , $T_2$ , $T_3$ , $T_4$ , $T_5$ , $T_6$ , $T_7$ , $T_8$ 为
${{T}_{1}}=3\delta +{{p}_{1}}+{{p}_{3}}\text{ }$
(21) ${{T}_{2}}=2\delta +\theta +\max ({{p}_{1}},{{p}_{3}},\delta +3\theta )$
(22) ${{T}_{3}}=4\delta +{{p}_{1}}+{{p}_{3}}$
(23) ${{T}_{4}}=2\delta +2\theta +\max ({{p}_{1}}+2\delta +2\theta ,{{p}_{3}})$
(24) ${{T}_{6}}=2\delta +2\theta +\max ({{p}_{1}},{{p}_{3}}+2\delta +2\theta )$
(25) ${{T}_{7}}=3\delta +\theta +\max ({{p}_{1}},{{p}_{3}},\delta +3\theta )$
(26) ${{T}_{8}}=2\delta +2\theta +\max ({{p}_{1}},{{p}_{3}},2\delta +6\theta )$
(27) 定义 3. 若搬运模式 $s_i$ 下的周期时间 $T_i$ 大于或者等于搬运模式 $s_j$ 下的周期时间 $T_j$ ,则可说搬运模式 $s_i$ 受支配于搬运模式 $s_j$ ,即搬运模式 $s_j$ 相对于搬运模式 $s_i$ 具有一定优势.
定理 2. 对于任意的晶圆,在满足驻留约束的前提下,搬运模式 $s_3$ 受支配于搬运模式 $s_1$ ,搬运模式 $s_7$ 受支配于搬运模式 $s_2$ .
证明. 搬运模式 $s_3$ 与搬运模式 $s_1$ 的搬运动作相似,不同之处仅为搬运模式 $s_3$ 比搬运模式 $s_1$ 多了缓冲模块与加工模块之间的搬运.对周期时间进行分析, $T_1=3\delta+p_1+p_3$ 且 $T_3=4\delta+p_1+p_3$ ,有 $T_1<T_3$ ,则对于任意的晶圆,搬运模式 $s_3$ 受支配于搬运模式 $s_1$ .搬运模式 $s_7$ 里搬运模块到缓冲模块进行装卸,而搬运模式 $s_2$ 的晶圆直接跳过缓冲模块,对周期的表达式分析,有 $T_7=T_2+\delta>T_2$ ,则对于任意的晶圆,在满足时间驻留约束的前提下,搬运模式 $s_7$ 受支配于搬运模式 $s_2$ .
定理 3. 对于任意晶圆,在满足驻留约束的前提下,搬运模式 $s_4$ , $s_5$ , $s_6$ , $s_8$ 受支配于搬运模式 $s_2$ .
证明. 将各个搬运模式分别与搬运模式 $s_2$ 进行比较:
1) 由式(22) 与(24) 可知,明显地,有不等式 $\max(p_1,p_3,\delta+3\theta)\leq\max(p_1+2\delta+3\theta,p_3+\theta)$ 成立,可推出 $T_2\leq T_4$ .
2) 由式(22) 与(20) 可得, $T_5=T_2+\delta\geq T_2$ .
3) 推理同1) 类似,由式(22) 与(25) 推得 $T_2\leq T_6$ .
4) 由式(22) 与(27) 可知,明显地,有不等式 $\max(p_1,p_3,\delta+3\theta)\leq\max(p_1+\theta,p_3+\theta,2\delta+7\theta)$ 成立,可以推出 $T_2\leq T_8$ .
总之,在满足驻留约束的前提下,搬运模式 $s_4$ , $s_5$ , $s_6$ , $s_8$ 受支配于搬运模式 $s_2$ .
为更加方便地描述复杂条件,定义了如下的逻辑表达:
\begin{align*}&A(x)=\{x\leq 4\theta\}\\[1mm]&B(x)=\{x\geq 4\theta\}\\[1mm]&C(x,y)=\{\max(x,y)\leq 2\delta+6\theta\}\\[1mm]&D(x,y)=\{\max(x,y)\geq 2\delta+6\theta\}\\[1mm]&E(x,y)=\{(x-y)\leq 2\delta+6\theta\}\\[1mm]&F(x,y)=\{(x-y)\geq 2\delta+6\theta\}\\[1mm]&g(x,y)=\{[A(y)\cap C(x,y)\cap E(x,y)]\cup\\[1mm]&\qquad [C(x,y)\cap F(x,y)]\}\\[1mm]&h(x,y)=\{D(x,y)\cup[B(y)\cap C(x,y)\cap E(x,y)]\}\end{align*}
定理 4. 搬运模式之间的周期时间存在如下的大小关系:
1) $T_1\leq T_2\Leftrightarrow p_1+p_3\leq 4\theta$ 而 $T_1\geq T_2\Leftrightarrow p_1+p_3\geq 4\theta$ .
2) $T_1\leq T_4\Leftrightarrow p_1\leq 2\theta-\delta\Arrowvert p_3\leq 4\theta+\delta$ 而 $T_1\geq T_4\Leftrightarrow p_1\geq2\theta-\delta~\&~p_3\geq 4\theta+\delta$ .
3) $T_1\leq T_5\Leftrightarrow p_1\leq\theta\Arrowvert p_3\leq\theta\Arrowvert p_1+p_3\leq\delta+3\theta$ 而 $T_1\geq T_5\Leftrightarrow p_1\geq\theta~\&~ p_3\geq\theta ~\&~p_1+p_3\geq\delta+3\theta$ .
4) $T_1\leq T_6\Leftrightarrow p_1\leq4\theta+\delta\Arrowvert p_3\leq 2\theta-\delta$ 而 $T_1\geq T_6\Leftrightarrow p_1\geq4\theta+\delta~\&~ p_3\geq 2\theta-\delta$ .
5) $T_1\leq T_8\Leftrightarrow \max(p_1,p_3) \leq2\theta-\delta\Arrowvert p_1+p_3\leq\delta+8\theta$ 而 $T_1\geq T_8\Leftrightarrow \max(p_1,p_3) \geq 2\theta-\delta~\&~p_1+p_3\geq\delta+8\theta$ .
6) $T_4\leq T_5\Leftrightarrow p_3-p_1\geq3\theta+\delta$ 而 $T_4\geq T_5\Leftrightarrow p_3-p_1\leq3\theta+\delta$ .
7) $T_4\leq T_6\Leftrightarrow p_1\leq p_3$ 而 $T_4\leq T_6\Leftrightarrow p_1\leq p_3$ .
8) $T_4\leq T_7\Leftrightarrow p_3-p_1\geq3\theta+\delta$ 而 $T_4\geq T_7\Leftrightarrow p_3-p_1\leq3\theta+\delta$ .
9) $T_4\leq T_8\Leftrightarrow g(p_3,p_1) $ 而 $T_4\geq T_8\Leftrightarrow h(p_3,p_1) $ .
10) $T_5\leq T_6\Leftrightarrow p_1-p_3\leq2\theta+2\delta$ 而 $T_5\geq T_6\Leftrightarrow p_1-p_3\geq2\theta+2\delta$ .
11) $T_5\leq T_8\Leftrightarrow \max(p_1,p_3) \leq2\theta+6\delta$ 而 $T_5\geq T_8\Leftrightarrow \max(p_1,p_3) \geq2\theta+6\delta$ .
12) $T_6\leq T_8\Leftrightarrow g(p_1,p_3) $ 而 $T_6\leq T_8\Leftrightarrow h(p_1,p_3) $ .
证明. 1) 从式(21) 与(22) 可知,若有 $T_1\leq T_2\Rightarrow\delta+p_1+p_3\leq\max(p_1+\theta,p_3+\theta,\delta+4\theta)$ ,由于 $\delta$ 表示晶圆移动时间而 $\theta$ 表示机械手空移动,存在 $\delta\geq\theta$ .由于 $\delta+p_1+p_3\leq\max(p_1+\theta,p_3+\theta)$ 始终成立,则需有 $\delta+p_1+p_3\leq \delta +4\theta\Rightarrow p_1+p_3\leq4\theta$ . 相似地, $T_1\geq T_2$ 需满足条件 $p_1+p_3\geq 4\theta$ .其他2) $\sim$ 12) 都可用类似的方法推理得到.
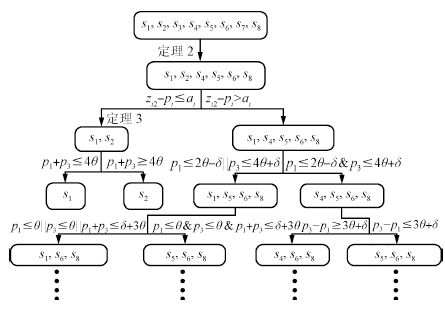
根据定理2 $\sim$ 4,结合单晶圆类型调度的全局搜索算法,首先利用驻留约束确定 $s_2$ 的可行性得到两个分枝,其中的第一分枝利用定理2和定理3里的支配关系排除了 $s_4$ , $s_5$ , $s_6$ , $s_7$ , $s_8$ ,第二分枝利用定理4的条件分析再进行分枝.图 2为改进型搜索决策树示例.
5. 实验分析
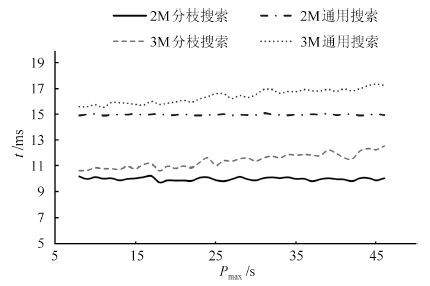
为了对带缓冲的集束型设备进行评价,把不带缓冲的集束型设备用于对比分析. 运用量化的分析方法,为带有缓冲的单臂集束型设备相对于无缓冲的集束型设备的产能提高提供了较为可靠的数据.本节中假设 $\delta=4$ , $\theta=2$ , $a_i=5$ 为最基本的实验条件.由于增加缓冲的优势主要体现在最大加工时间的加工模块上,所以有 $p_{\max}=\max_{1\leq i\leq 2m}\{p_i\}$ .用C++分别对两种算法进行编程,统计50组算例数据,求得平均的结果,并对比两种算法的数值实验结果. 图 3为两种算法所需的时间,可以看出分枝搜索的速度会比全局搜索算法更加优越.但图 4表明在小规模时,两种算法都能得到较好的结果.
将本文提出的算法与文献[13]的算法进行比较. 取加工时间为 $p_i\sim{\rm N}(60,2.5^2) $ ,如图 5所示为算法之间调度结果的比较.
由图 5可知,在小规模问题时,本文的算法与文献的算法得到的解基本相同,但随着规模的增加,本文的算法呈现出较为明显的优势,得到的解更优.
本文定义了提高率 $R$ 来评价带缓冲模块相对于无缓冲模块的系统之间产量提高:
$R=\frac{C{{T}_{G}}-C{{T}_{B}}}{C{{T}_{B}}}\times 100\%$
上式表示的是带缓冲的集束型设备与无缓冲的设备的集束型设备产能的提高率.其中 $R$ 越大,表示提高率越大.其中 $CT_B$ 代表带缓冲的集束型设备的周期时间,而 $CT_G$ 为无缓冲的集束型设备的周期时间. $Bd={p_{\max}}/{(\delta+\theta)}$ 表示搬运模块的繁忙程度, $Bd$ 越大表示搬运块模块越空闲.
5.1 生产率的提高与机械手的繁忙程度的关系
令机械手繁忙程度 $Bd$ 取[0,10]的均匀分布,通过仿真分析,得到如图 6的结果.
 图 6 生产率提高与搬运模块繁忙程度的关系Fig. 6 The relationship of improvement rates with the busy degree of TM
图 6 生产率提高与搬运模块繁忙程度的关系Fig. 6 The relationship of improvement rates with the busy degree of TM分析图 6可知,对于两集束型而言,仅当 $Bd\geq3$ 时,产能的提高率为正数,即仅当搬运模块繁忙程度 $Bd\geq3$ 时,缓冲模块能提高集束型设备的产能. 相反,当搬运模块繁忙程度 $Bd\leq3$ 时,产能提高率小于零,说明缓冲模块不提高产能,而对于三集束型而言, $Bd$ 的临界值为 $3.1$ .同时随着产能提高率的减少,最大加工时间 $p_{\max}$ 也相应减少,故TM在PM上等待时间也相应减少,直到晶圆加工完毕.若晶圆在PM上的等待搬运的时间大于驻留约束,那么搬运模块的搬运模式必须改变; 否则,晶圆会出现质量问题.无论搬运模块的繁忙程度如何的变化,最后TM都会处于搬运模式 $s_1$ ,说明在缓冲模块上的晶圆增加了额外的搬运.
5.2 生产率的提高与加工模块的加工时间的关系
设置变量 $P={p_t}/{(\delta+\theta)}$ ,然后令 $Bd$ 分布取均匀分布[3, 9]. 经过仿真分析,得到结果如图 7所示.
 图 7 生产率提高与加工时间之间的关系Fig. 7 The relationship of improvement rates with processing time of PMs
图 7 生产率提高与加工时间之间的关系Fig. 7 The relationship of improvement rates with processing time of PMs由图 7可知,在所有的搬运模块繁忙程度中,产能提高率从不稳定改变到达稳定的状态.主要原因在于随着模块加工时间的增加,搬运模块空闲使得加工模块的驻留约束的影响被降低.
6. 结论
本文针对带缓冲模块的集束型设备的调度问题建立了数学模型,构建全局搜索算法. 再通过具体分析两集束型设备,提出了分枝搜索算法.最后经仿真表明,分枝搜索算法比全局搜索算法更加迅速.同时通过和文献[13]的调度算法进行对比,表明本文的算法在加工模块比较少的时候调度结果提高不多,但随着规模增大,本文所得到的结果有明显的优势.通过对比带缓冲的集束型设备与无缓冲的集束型设备,证明了在加工模块之间增加缓冲,在一定程度上可以提高单臂集束型设备的产能.基于实验数据,仅当搬运模块TM的繁忙程度 $Bd$ 大于阈值时,设备产能才会提高.实验还表明驻留约束对于产能提高的影响是通过约束限制状态的改变产生的.随着加工模块的加工时间不断增加,产能提高越来越不显著,系统产能渐渐趋于平稳状态.
-
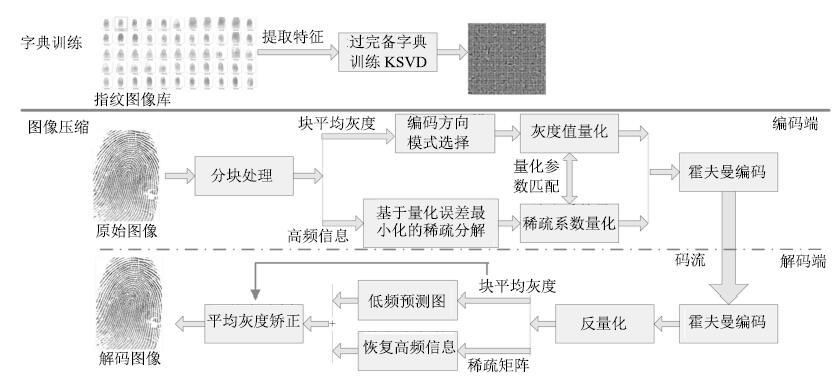
图 1 本文提出的基于自适应稀疏变换的指纹图像压缩算法框架
Fig. 1 The framework of the proposed fingerprint image compression algorithm via adaptive sparse transformation

图 2 本文算法低频预测图像(a)与K-SVD-SR 算法低频图像 (b)块效应对比
Fig. 2 The comparison of low-frequency predicted image between the proposed algorithm (a) and the K-SVD-SR algorithm(b)

图 3 块间像素预测对最终编解码效果的影响
Fig. 3 The effect of inter-block pixel prediction on the final codec
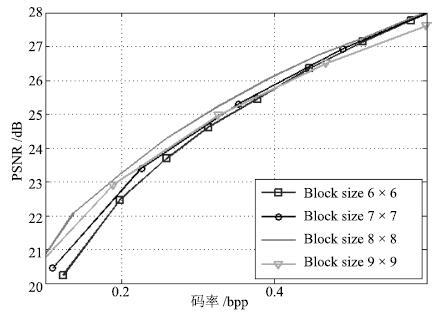
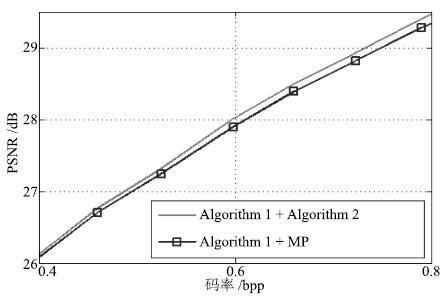
图 5 分块尺寸分别为6× 6、7× 7、8× 8、9×9的率失真性能比较
Fig. 5 The comparison of rate distortion performance between the blocks with the size of 6× 6,7× 7,8× 8,and 9× 9
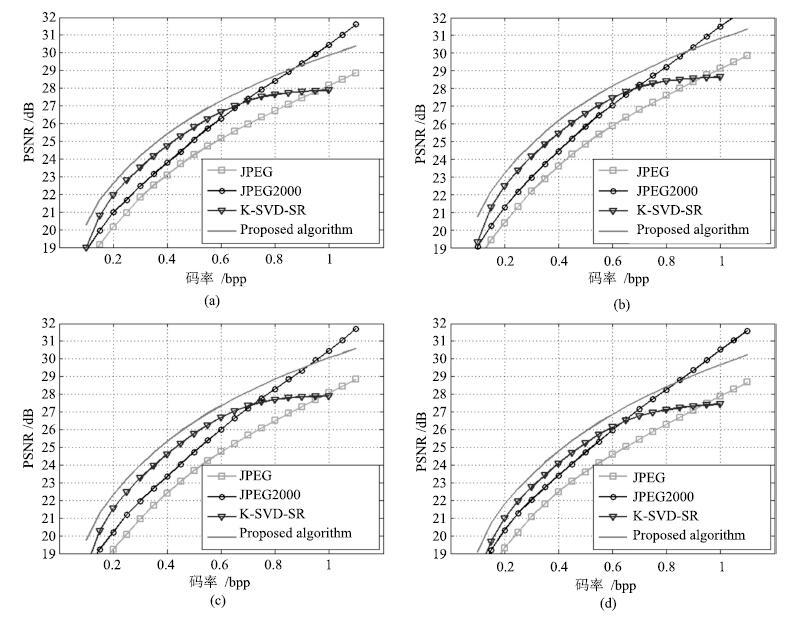
图 6 (a)~(d) 分别表示测试图像库中的数据库2~5在四种压缩算法下的平均率失真性能
Fig. 6 The (a),(b),(c),(d) respectively denotes the average rate distortion performance of the test image library Database2,Database3,Database4,and Database5 at 4 compression algorithms

图 7 从左至右分别表示原始图像和码率同为0.1 bpp的JPEG、JPEG2000、K-SVD-SR和本文算法的解码图像
Fig. 7 From left to right respectively represents the original image and the decoded image of JPEG,JPEG2000,K-SVD-SR,and the proposed algorithm at the same rate as 0.1 bpp

图 8 稀疏度自适应选择与固定稀疏度L=2、6、10、14对比
Fig. 8 The contrast of the adaptive sparsity and the fixed sparsity of L=2,6,10,14

图 10 两种量化模式对图像压缩性能的影响比较
Fig. 10 The comparison of the impact on image compression performance between the two quantization modes
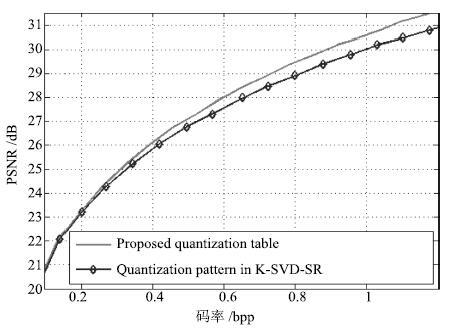
图 11 “索引-权值”编码模式与“原子个数-索引-权值”编码模式对比
Fig. 11 The contrast of the "index-weight" encoding mode and the "number of atoms-index-weight" encoding mode
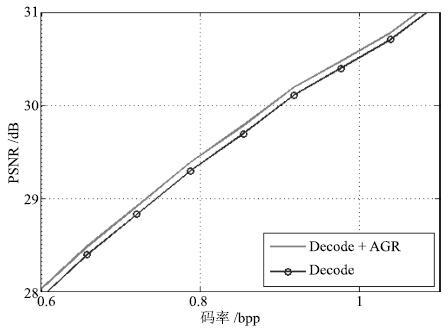
图 12 基于AGR的图像解码与K-SVD-SR的 直接解码对比
Fig. 12 The contrast of the image decoding based on AGR and the direct decoding of K-SVD-SR
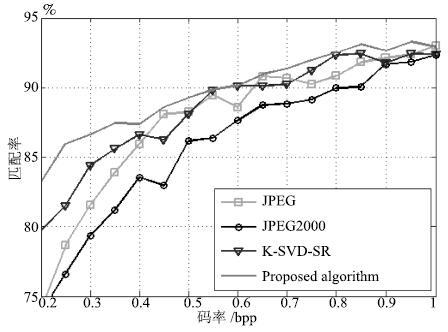
图 13 测试图像库数据库2在四种压缩算法下的\\图像的平均特征匹配率
Fig. 13 The average image feature matching rate of the test image library Database 2 at 4 compression algorithms
表 1 四种压缩算法的时间复杂度比较 (s)
Table 1 The comparison of time complexity about 4 compression algorithms (s)
码率 (bpp) 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 JPEG 0.16 0.16 0.16 0.16 0.17 0.17 0.17 0.17 0.17 JPEG2000 0.08 0.08 0.08 0.08 0.07 0.08 0.08 0.08 0.08 K-SVD-SR 1.26 1.74 2.20 2.64 3.19 3.61 4.13 4.49 4.89 本文算法 2.13 2.80 3.26 2.88 4.53 4.95 5.83 5.76 6.84  下载: 导出CSV
下载: 导出CSV
-
[1] Pennebaker W B, Mitchell J L. JPEG:Still Image Data Compression Standard. US:Springer, 1993. http://cn.bing.com/academic/profile?id=1540900967&encoded=0&v=paper_preview&mkt=zh-cn [2] Marcellin M W, Gormish M J, Bilgin A, Boliek M P. An overview of JPEG-2000. In:Proceedings of the 2000 Data Compression Conference. Snowbird, UT:IEEE, 2000.523-541 [3] Bradley J N, Brislawn C M, Hopper T. FBI wavelet/scalar quantization standard for gray-scale fingerprint image compression. In:Proceedings of the SPIE 1961, Visual Information Processing Ⅱ. Orlando, FL:SPIE, 1993.293-304 [4] Skodras A, Christopoulos C, Ebrahimi T. The JPEG 2000 still image compression standard. IEEE Signal Processing Magazine, 2001, 18(5):36-58 doi: 10.1109/79.952804 [5] Shao G, Wu Y, Yong A, Liu X, Guo T. Fingerprint compression based on sparse representation. IEEE Transactions on Image Processing, 2014, 23(2):489-501 doi: 10.1109/TIP.2013.2287996 [6] Olshausen B A, Field D J. Sparse coding with an overcomplete basis set:a strategy employed by V1? Vision Research, 1997, 37(23):3311-3325 doi: 10.1016/S0042-6989(97)00169-7 [7] Emmanuel B, Mu'Azu M, Sani S, Garba S. A review of wavelet-based image processing methods for fingerprint compression in biometric application. British Journal of Mathematics and Computer Science, 2014, 4(19):2781-2798 doi: 10.9734/BJMCS [8] Qian C, Xu Z. Robust visual tracking via sparse representation under subclass discriminant constraint. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 26(7):1293-1307 doi: 10.1109/TCSVT.2015.2424091 [9] Sun B, Liu Z, Sun Y, Su F, Cao L, Zhang H. Multiple objects tracking and identification based on sparse representation in surveillance video. In:Proceedings of the 2015 IEEE International Conference on Multimedia Big Data (BigMM). Beijing, China:IEEE, 2015.268-271 [10] Cheng M, Wang C, Li J. Single-image super-resolution in RGB space via group sparse representation. Iet Image Processing, 2015, 9(6):461-467 doi: 10.1049/iet-ipr.2014.0313 [11] Tropp J A. Greed is good:algorithmic results for sparse approximation. IEEE Transactions on Information Theory, 2004, 50(10):2231-2242 doi: 10.1109/TIT.2004.834793 [12] Mallat S G, Zhang Z F. Matching pursuits with time-frequency dictionaries. IEEE Transactions on Signal Processing, 1993, 41(12):3397-3415 doi: 10.1109/78.258082 [13] Pati Y C, Rezaiifar R, Krishnaprasad P S. Orthogonal matching pursuit:recursive function approximation with applications to wavelet decomposition. In:Proceedings of the 1993 Conference Record of the 27th Asilomar Conference on Signals, Systems, and Computers. Pacific Grove, CA:IEEE, 1993.40-44 http://cn.bing.com/academic/profile?id=185716565&encoded=0&v=paper_preview&mkt=zh-cn [14] Gharavi-Alkhansari M, Huang T S. A fast orthogonal matching pursuit algorithm. In:Proceedings of the 1998 IEEE International Conference on Acoustics, Speech, and Signal Processing. Seattle, WA:IEEE, 1998.1389-1392 http://dl.acm.org/citation.cfm?id=1892575 [15] Chen S S, Donoho D L, Saunders M A. Atomic decomposition by basis pursuit. SIAM Journal on Scientific Computing, 1998, 20(1):33-61 doi: 10.1137/S1064827596304010 [16] Zhu J Y, Wang Z Y, Zhong R, Qu S M. Dictionary based surveillance image compression. Journal of Visual Communication and Image Representation, 2015, 31:225-230 doi: 10.1016/j.jvcir.2015.07.002 [17] Setiawan A D, Suksmono A B, Mengko T L R, Gunawan H. Low-bitrate medical image compression. In:Proceedings of the ACA2011 IAPR Conference on Machine Vision Applications. Nara, Japan, 2011.544-547 [18] Xu J, Pi Y, Ming R. SAR image compression based on sparse representation. In:Proceedings of the 11th International Radar Symposium (IRS). Vilnius, Lithuania:IEEE, 2010.1-4 [19] Zhan X, Zhang R, Yin D, Huo C. SAR image compression using multiscale dictionary learning and sparse representation. IEEE Geoscience and Remote Sensing Letters, 2013, 10(5):1090-1094 doi: 10.1109/LGRS.2012.2230394 [20] Aharon M, Elad M, Bruckstein A. K-SVD:an algorithm for designing overcomplete dictionaries for sparse representation. IEEE Transactions on Signal Processing, 2006, 54(11):4311-4322 doi: 10.1109/TSP.2006.881199 [21] Anurakphanawan N, Lamsrichan P. Fingerprint recognition performance with WSQ, CAWDR, and JPEG2000 compression. In:Proceedings of the 6th International Conference of Information and Communication Technology for Embedded Systems (IC-ICTES). Hua-Hin, Thailand:IEEE, 2015.1-6 [22] Fingerprint images[Online], available:http://pan.baidu.com/s/1i3KxQZV,November27,2015 [23] Abraham J, Kwan P, Gao J B. Fingerprint matching using a hybrid shape and orientation descriptor. State of the Art in Biometrics. New York:InTech, 2011. 期刊类型引用(6)
1. 黄年昌,杨阳,张强,韩军功. 基于深度学习的RGB-D图像显著性目标检测前沿进展. 计算机学报. 2025(02): 284-316 .  百度学术
百度学术2. 闫梦凯,钱建军,杨健. 弱对齐的跨光谱人脸检测. 自动化学报. 2023(01): 135-147 . 本站查看3. 王利锋,辛丽平,刘家硕,鞠莲. 基于热红外视频图像监测的海面溢油识别技术研究. 海洋学报. 2022(05): 148-160 . 百度学术4. 蔺素珍,张海松,禄晓飞,李大威,李毅. RBNSM:一种复杂背景下红外弱小目标检测新方法. 红外技术. 2022(07): 667-675 . 百度学术5. 刘晓玲,牛海春,宋海燕,秦富贞. 复杂环境下弱信号中的红外小目标自动检测. 激光杂志. 2020(10): 82-86 . 百度学术6. 刘松涛,姜康辉,刘振兴. 基于区域协方差和目标度的航空侦察图像舰船目标检测. 系统工程与电子技术. 2019(05): 972-980 . 百度学术其他类型引用(2)
-


 下载:
下载:



计量
- 文章访问数: 2545
- HTML全文浏览量: 477
- PDF下载量: 756
- 被引次数: 8
