

-
摘要: 在实际应用场景中越来越多的数据具有多标签的特性,且特征维度较高,包含大量冗余信息.为提高多标签数据挖掘的效率,多标签特征提取已经成为当前研究的热点.本文采用去噪自编码器获取多标签数据特征空间的鲁棒表达,在此基础上结合超图学习理论,融合多个标签对样本间几何关系的影响以提升特征提取的性能,构建多标签数据样本间几何关系所对应超图的Laplacian矩阵,并通过Laplacian矩阵的特征值分解得到低维投影空间.实验结果证明了本文所提出的算法在分类性能上是有效可行的.Abstract: In practical application scenarios, more and more data tend to be assigned with multiple labels and contain much redundant information in the high dimensional feature space. To improve the efficiency and effectiveness of multi-label data mining, multi-label data feature selection has become a hotspot. This paper utilizes denoising autoencoders to obtain a more robust version of multi-label data feature representation. Furthermore, based on hypergraph learning theory, a hypergraph Laplacian matrix corresponding to multi-label data is constructed by fusing the effects of all labels on geometrical relationship among all the samples, and then a projection space with lower dimension is obtained by conducting eigenvalue decomposition of the Laplacian matrix. Experimental results demonstrate the effectiveness and feasibility of the proposed algorithm according to its multi-label data classification performance.
-
Key words:
- Deep learning /
- autoencoders /
- multi-label /
- hypergraph /
- feature selection
-
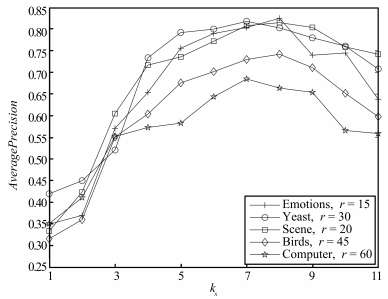
图 1 参数ks对AverageP recision的影响(kd=3)
Fig. 1 The influences of ks to AverageP recision (kd=3)

图 2 参数kd对AveragePrecision的影响(ks=8)
Fig. 2 The influences of kd to AveragePrecision (ks=8)
表 1 重要的标记定义
Table 1 Definitions of important notations
标记 标记语义 n 训练集中训练样本的个数 u, V 顶点 f ∈ Rn 所有样本的得分向量 f(u)或者fu 样本u的得分函数 e, E 超边,超边集合 δ(e) 超边e的度 d(u) 顶点u的度 Dv 顶点集的度矩阵 De 超边集的度矩阵 W(e) 超边e的权重 H 超图对应的邻接矩阵 Ω Ω(i, i)是第i条超边的权重,其他取0 r 约简后的特征维度 I 超图学习前的原特征空间 S 超图学习后的语义特征空间 Pi 基于样本xi的局部批 Pi 基于样本xi的局部批特征投影矩阵  下载: 导出CSV
下载: 导出CSV
表 2 算法空间复杂度
Table 2 Space consumption
矩阵 空间复杂度 Dv |V|×|V| De |E|×|E| H |E|×|V| Ω |E|×|E| Lg |E|×|V|
下载: 导出CSV
表 3 数据集信息
Table 3 Information of data sets
编号 名称 样本数 特征数 标签数 1 Emotions 593 72 6 2 Yeast 2417 103 14 3 Scene 2 407 294 6 4 Birds 645 260 19 5 Computer 5 000 681 33
下载: 导出CSV
表 4 数据集Emotions测试结果(params=(8, 3, 15))
Table 4 Results on Emotions (params=(8, 3, 15))
指标 a0 a1 a2 a3 MLFS-AH OE↓ 0.290 0.277 0.489 0.265 0.256 Cov↓ 1.893 1.842 2.791 1.733 1.756 RL↓ 0.173 0.181 0.349 0.168 0.152 AP↑ 0.770 0.784 0.658 0.811 0.825
下载: 导出CSV
表 5 数据集Yeast测试结果(params=(7, 3, 30))
Table 5 Results on Yeast (params=(7, 3, 30))
指标 a0 al a2 a3 MLFS-AH OE↓ 0.283 0.274 0.289 0.268 0.243 Cov↓ 6.452 6.331 6.538 6.245 6.121 RL↓ 0.174 0.168 0.203 0.156 0.160 AP↑ 0.760 0.758 0.717 0.782 0.811
下载: 导出CSV
表 6 数据集Scene测试结果(params=(8, 3, 20))
Table 6 Results on Scene (params=(8, 3, 20))
指标 a0 a1 a2 a3 MLFS-AH OE↓ 0.275 0.261 0.318 0.260 0.248 Cov↓ 0.573 0.536 0.619 0.425 0.429 RL↓ 0.163 0.165 0.230 0.166 0.157 AP↑ 0.776 0.795 0.723 0.792 0.815
下载: 导出CSV
表 7 数据集Birds测试结果(params=(8, 2, 45))
Table 7 Results on Birds (params=(8, 2, 45))
指标 a0 a1 a2 a3 MLFS-AH OE↓ 0.379 0.371 0.369 0.352 0.344 Cov↓ 3, 411 3.426 3.724 3.385 3.389 RL↓ 0.129 0.125 0.138 0.124 0.121 AP↓ 0.712 0.718 0.705 0.727 0.742
下载: 导出CSV
表 8 数据集Computer测试结果(params=(7, 2, 60))
Table 8 Results on Computer (params=(7, 2, 60))
指标 a0 a1 a2 a3 MLFS-AH OE↓ 0.434 0.438 0.439 0.432 0.425 Cov↓ 4.435 4.439 4.532 4.378 4.339 RL↓ 0.108 0.104 0.106 0.089 0.091 AP↑ 0.641 0.643 0.647 0.649 0.675
下载: 导出CSV
-
[1] Zhang Y, Zhou Z H. Multi-label dimensionality reduction via dependence maximization. In:Proceedings of the 23rd AAAI Conference on Artificial Intelligence. Chicago, USA:AAAI Press, 2008. 1503-1505 [2] 付忠良.多标签代价敏感分类集成学习算法.自动化学报, 2014, 40(6):1075-1085 http://www.aas.net.cn/CN/abstract/abstract18377.shtmlFu Zhong-Liang. Cost-sensitive ensemble learning algorithm for multi-label classification problems. Acta Automatica Sinica, 2014, 40(6):1075-1085 http://www.aas.net.cn/CN/abstract/abstract18377.shtml [3] 张晨光, 张燕, 张夏欢.最大规范化依赖性多标记半监督学习方法.自动化学报, 2015, 41(9):1577-1588Zhang Chen-Guang, Zhang Yan, Zhang Xia-Huan. Normalized dependence maximization multi-label semi-supervised learning method. Acta Automatica Sinica, 2015, 41(9):1577-1588 [4] Zhang M L, Zhang K. Multi-label learning by exploiting label dependency. In:Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Washington, USA:ACM, 2010. 999-1008 [5] Hariharan B, Zelnik-Manor L, Vishwanathan S V N, Varma M. Large scale max-margin multi-label classification with priors. In:Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel:Omnipress, 2010. 423-430 [6] Elisseeff A, Weston J. A kernel method for multi-labelled classification. In:Proleedings of the 2001 Advances in Neural Information Processing Systems 14. British Columbia, Canada:MIT Press, 2001. 681-687 [7] Sun L, Ji S W, Ye J P. Hypergraph spectral learning for multi-label classification. In:Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas, USA:ACM, 2008. 668-676 [8] Zhang M L, Zhou Z H. A review on multi-label learning algorithms. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(8):1819-1837 doi: 10.1109/TKDE.2013.39 [9] Gibaja E, Ventura S. A tutorial on multi-label learning. ACM Computing Surveys, 2015, 47(3):Article No. 52 [10] 田枫, 沈旭昆.基于标签集相关性学习的大规模网络图像在线标注.自动化学报, 2014, 40(8):1635-1643 http://www.aas.net.cn/CN/abstract/abstract18732.shtmlTian Feng, Shen Xu-Kun. Large scale web image online annotation by learning label set relevance. Acta Automatica Sinica, 2014, 40(8):1635-1643 http://www.aas.net.cn/CN/abstract/abstract18732.shtml [11] Boutell M R, Luo J B, Shen X P, Brown C M. Learning multi-label scene classification. Pattern Recognition, 2004, 37(9):1757-1771 doi: 10.1016/j.patcog.2004.03.009 [12] 张振海, 李士宁, 李志刚, 陈昊.一类基于信息熵的多标签特征选择算法.计算机研究与发展, 2013, 50(6):1177-1184 http://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201306008.htmZhang Zhen-Hai, Li Shi-Ning, Li Zhi-Gang, Chen Hao. Multi-label feature selection algorithm based on information entropy. Journal of Computer Research and Development, 2013, 50(6):1177-1184 http://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201306008.htm [13] 段洁, 胡清华, 张灵均, 钱宇华, 李德玉.基于邻域粗糙集的多标记分类特征选择算法.计算机研究与发展, 2015, 52(1):56-65 http://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201501007.htmDuan Jie, Hu Qing-Hua, Zhang Ling-Jun, Qian Yu-Hua, Li De-Yu. Feature selection for multi-label classification based on neighborhood rough sets. Journal of Computer Research and Development, 2015, 52(1):56-65 http://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201501007.htm [14] Sun L, Ji S W, Ye J P. Multi-label Dimensionality Reduction. Britain:Chapman and Hall/CRC Press, 2013. 34-49 [15] Yu K, Yu S P, Tresp V. Multi-label informed latent semantic indexing. In:Proceedings of the 28th Annual International ACM SIGIR Conference on Research & Development in Information Retrieval. Salvador, Brazil:ACM, 2005. 258-265 [16] Tao D C, Li X L, Wu X D, Maybank S J. General tensor discriminant analysis and Gabor features for gait recognition. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2007, 29(10):1700-1715 http://cn.bing.com/academic/profile?id=2154624311&encoded=0&v=paper_preview&mkt=zh-cn [17] Tao D C, Li X L, Wu X D, Maybank S J. Geometric mean for subspace selection. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2009, 31(2):260-274 http://cn.bing.com/academic/profile?id=2117513046&encoded=0&v=paper_preview&mkt=zh-cn [18] Zhou D Y, Huang J Y, Schölkopf B. Learning with hypergraphs:clustering, classification, and embedding. In:Proceedings of the 2007 Advances in Neural Information Processing Systems. Vancouver, Canada:MIT Press, 2007, 1601-1608 [19] Berge C. Hypergraphs:Combinatorics of Finite Sets. Amsterdam:North-Holland, 1989. 83-96 [20] Gao Y, Chua T S. Hyperspectral image classification by using pixel spatial correlation. In:Proceedings of the 19th International Conference on Advances in Multimedia Modeling. Huangshan, China:Springer, 2013. 141-151 [21] Yu J, Tao D C, Wang M. Adaptive hypergraph learning and its application in image classification. IEEE Transactions on Image Processing, 2012, 21(7):3262-3272 doi: 10.1109/TIP.2012.2190083 [22] Shi J B, Malik J. Normalized cuts and image segmentation. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2000, 22(8):888-905 http://cn.bing.com/academic/profile?id=2121947440&encoded=0&v=paper_preview&mkt=zh-cn [23] Gao Y, Wang M, Tao D C, Ji R R, Dai Q H. 3-D object retrieval and recognition with hypergraph analysis. IEEE Transactions on Image Processing, 2012, 21(9):4290-4303 doi: 10.1109/TIP.2012.2199502 [24] Hong C Q, Zhu J K. Hypergraph-based multi-example ranking with sparse representation for transductive learning image retrieval. Neurocomputing, 2013, 101:94-103 doi: 10.1016/j.neucom.2012.09.001 [25] Chen M M, Weinberger K, Sha F, Bengio Y. Marginalized denoising auto-encoders for nonlinear representations. In:Proceedings of the 31st International Conference on Machine Learning. Beijing, China, 2014. 1476-1484 [26] Zhang T H, Tao D C, Li X L, Yang J. Patch alignment for dimensionality reduction. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9):1299-1313 doi: 10.1109/TKDE.2008.212 [27] Zhang M L, Zhou Z H. ML-KNN:a lazy learning approach to multi-label learning. Pattern Recognition, 2007, 40(7):2038-2048 doi: 10.1016/j.patcog.2006.12.019 [28] Lee J, Kim D W. Fast multi-label feature selection based on information-theoretic feature ranking. Pattern Recognition, 2015, 48(9):2761-2771 doi: 10.1016/j.patcog.2015.04.009 -

 下载:
下载:

计量
- 文章访问数: 2796
- HTML全文浏览量: 1206
- PDF下载量: 1839
- 被引次数: 0
