

Applications of Deep Learning for Handwritten Chinese Character Recognition: A Review
-
摘要: 手写汉字识别(Handwritten Chinese character recognition,HCCR)是模式识别的一个重要研究领域,最近几十年来得到了广泛的研究与关注,随着深度学习新技术的出现,近年来基于深度学习的手写汉字识别在方法和性能上得到了突破性的进展.本文综述了深度学习在手写汉字识别领域的研究进展及具体应用.首先介绍了手写汉字识别的研究背景与现状.其次简要概述了深度学习的几种典型结构模型并介绍了一些主流的开源工具,在此基础上详细综述了基于深度学习的联机和脱机手写汉字识别的方法,阐述了相关方法的原理、技术细节、性能指标等现状情况,最后进行了分析与总结,指出了手写汉字识别领域仍需要解决的问题及未来的研究方向.Abstract: Handwritten Chinese character recognition (HCCR) is an important research filed of pattern recognition, which has attracted extensive studies during the past decades. With the emergence of deep learning, new breakthrough progresses of HCCR have been obtained in recent years. In this paper, we review the applications of deep learning models in the field of HCCR. First, the research background and current state-of-the-art HCCR technologies are introduced. Then, we provide a brief overview of several typical deep learning models, and introduce some widely used open source tools for deep learning. The approaches of online HCCR and offline HCCR based on deep learning are surveyed, with the summaries of the related methods, technical details, and performance analysis. Finally, further research directions are discussed.
-
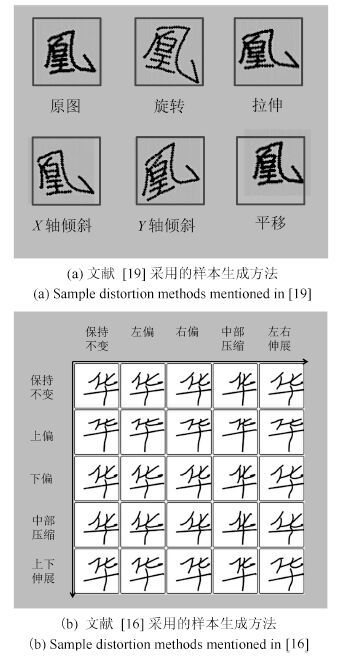
图 1 几种常用的手写汉字数据增广技术示意图
Fig. 1 The influences of the controller parameters on the tracking errors
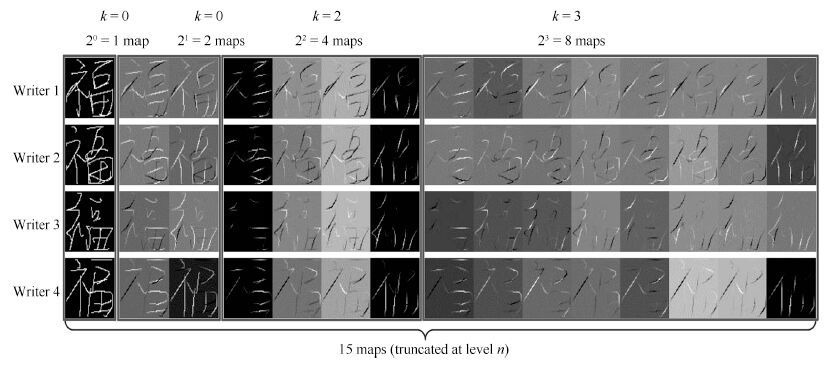
图 2 手写汉字的路径积分特征图可视化
Fig. 2 Path signature feature map visualization of handwritten Chinese characters
表 1 目前一些主流的深度学习开源仿真工具及其下载地址
Table 1 Some mainstream deep-learning open source toolboxes and their download address at present
工具名称 说明及备注 下载地址 Caffe[112] UC Berkeley BVLC 实验室发布的深度学习开源工具,是目前使用最为广泛的深度学习实验平台之一 https://github.com/BVLC/caffe Theano[113-114] 基于Python 语言的深度学习开源仿真工具 https://github.com/Theano/Theano Torch[115] 基于Lua 脚本语言的工具,支持iOS、Android 等嵌入式平台 http://torch.ch/ Purine[116] 支持多GPU,提供线性加速能力 https://github.com/purine/purine2 MXNet[117] 由百度牵头组织的深度机器学习联盟(DMCL) 发布的C++ 深度学习工具库 https://github.com/dmlc/mxnet DIGITS[118] 由NVIDIA 公司集成开发发布的一款基于Web 页面的可视化深度学习仿真工具,支持Caffe 及Touch 工程代码 https://github.com/NVIDIA/DIGITS ConvNet[119] 最早的支持GPU 的CNN 开源工具之一,ILSVRC2012 比赛第一名提供的代码 https://code.google.com/p/cuda-convnet/ Cuda-ConvNet2[109] 支持多GPU 的ConvNet https://github.com/akrizhevsky/cuda-convnet2 DeepCNet[120] 英国Warwick 大学Graham 教授发布的开源CNN 仿真工具,曾获ICDAR 2013 联机手写汉字识别竞赛第一名 https://github.com/btgraham/SparseConvNet Petuum[121] CMU 发布的一款基于多CPU/GPU 集群并行化分布式,机器学习开源仿真平台除了支持深度学习的常用算法之外,还提供很多传统机器学习算法的实现. 可部署在云计算平台之中 https://github.com/petuum/bosen/wiki CURRENT[122] 支持GPU 的回归神经网络函数库 http://sourceforge.net/projects/currennt/ Minerva[123] 深度机器学习联盟(DMCL) 发布的支持多GPU 并行化的深度学习工具 https://github.com/dmlc/minerva TensorFlow[124] 谷歌发布的机器学习可视化开发工具,支持多CPU 及多GPU 并行化仿真,支持CNN、RNN 等深度学习模型 https://github.com/tensor°ow/tensor°ow DMTK[125] 微软发布的一套通用的分布式深度学习开源仿真工具 https://github.com/Microsoft/DMTK  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在CASIA-OLHWDB1.1联机手写中文单字数据集上的识别结果对比
Table 2 Comparison with different methods on the CASIA-OLHWDB1.1
方法 准确率 (%) 伪样本变形 模型集成 (模型数量) 传统最佳方法: DFE+DLQDF[10] 94.85 × × HDNN-SSM-MCE[66] 89.39 × × MCDNN[127] 94.39 √ √(35) DeepCNet[40] 96.42 √ × DeepCNet-8方向直方图特征[40] 96.18 √ × DCNN (4种领域知识融合)[60] 96.35 √ × HSP-DCNN (4种领域知识集成)[64] 96.87 √ √(8) DeepCNet-FMP (单次测试)[132] 96.74 √ × DeepCNet-FMP (多次测试)[132] 97.03 √ √(12 test) DropSample-DCNN[61] 96.55 √ × DropSample-DCNN (集成)[61] 97.06 √ √(9)
下载: 导出CSV
表 3 不同深度学习方法在CASIA-OLHWDB1.0-1.1以及ICDAR2013竞赛数据集上的识别结果 (%)
Table 3 Comparison with different methods on the CASIA-OLHWDB1.0-1.1 and ICDAR 2013 Online CompetitionDB (%)
下载: 导出CSV
表 4 不同深度学习方法及部分典型的传统方法在ICDAR2013脱机手写汉字竞赛集上的识别性能
Table 4 Comparison with different traditional and deep-learning besed methods on ICDAR 2013 Offline CompetitionDB
方法 Top1 (%) Top5 (%) Top10 (%) 模型存储量 HCCR-Gradient-GoogLeNet[77] 96.28 99.56 99.80 27.77MB HCCR-Gabor-GoogLeNet[77] 96.35 99.6 99.80 27.77MB HCCR-Ensemble-GoogLeNet[77] (average of 4 models) 96.64 99.64 99.83 110.91MB HCCR-Ensemble-GoogLeNet[77] (average of 10 models) 96.74 99.65 99.83 277.25MB CNN-Fujitsu[39] 94.77 - 99.59 2460MB MCDNN-INSIA[74] 95.79 - 99.54 349MB MQDF-HIT[39] 92.61 - 98.99 120MB MQDF-THU[39] 92.56 - 99.13 198MB DLQDF[39] 92.72 - - - ART-CNN[76] 95.04 - - 51.64MB2 R-CNN Voting[76] 95.55 - - 51.64MB2 ATR-CNN Voting[76] 96.06 - - 206.56MB2 MQDF-CNN[78] 94.44 - - - Multi-CNN Voting[129] 96.79 - - - 2根据文献[76]给出的模型参数(CNN层数、各层卷积核大小及数量、聚合层大小及数量、全连接数量),按照每个参数以浮点数存储(占用4个字节)方式推算而得.
下载: 导出CSV
表 5 不同研究方法在ICDAR 2013 Offine Text CompetitionDB 数据对比记录表(%)
Table 5 Comparison with di®erent methods on the ICDAR 2013 Offine Text CompetitionDB (%)
下载: 导出CSV
-
[1] Hildebrandt T H, Liu W T. Optical recognition of handwritten Chinese characters:advances since 1980. Pattern Recognition, 1993, 26(2):205-225 doi: 10.1016/0031-3203(93)90030-Z [2] Suen C Y, Berthod M, Mori S. Automatic recognition of handprinted characters——the state of the art. Proceedings of the IEEE, 1980, 68(4):469-487 doi: 10.1109/PROC.1980.11675 [3] Tai J W. Some research achievements on Chinese character recognition in China. International Journal of Pattern Recognition and Artificial Intelligence, 1991, 5(01n02):199-206 doi: 10.1142/S0218001491000132 [4] Liu C L, Jaeger S, Nakagawa M. Online recognition of Chinese characters:the state-of-the-art. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(2):198-213 doi: 10.1109/TPAMI.2004.1262182 [5] Cheriet M, Kharma N, Liu C L, Suen C Y. Character Recognition Systems:a Guide for Students and Practitioners. USA:John Wiley & Sons, 2007. [6] Plamondon R, Srihari S N. Online and off-line handwriting recognition:a comprehensive survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(1):63-84 doi: 10.1109/34.824821 [7] Dai R W, Liu C L, Xiao B H. Chinese character recognition:history, status and prospects. Frontiers of Computer Science in China, 2007, 1(2):126-136 doi: 10.1007/s11704-007-0012-5 [8] Liu C L. High accuracy handwritten Chinese character recognition using quadratic classifiers with discriminative feature extraction. In:Proceedings of the 18th International Conference on Pattern Recognition. Hong Kong, China:IEEE, 2006.942-945 [9] Long T, Jin L W. Building compact MQDF classifier for large character set recognition by subspace distribution sharing. Pattern Recognition, 2008, 41(9):2916-2925 doi: 10.1016/j.patcog.2008.02.009 [10] Liu C L, Yin F, Wang D H, Wang Q F. Online and offline handwritten Chinese character recognition:benchmarking on new databases. Pattern Recognition, 2013, 46(1):155-162 doi: 10.1016/j.patcog.2012.06.021 [11] Zhang H G, Guo J, Chen G, Li C G. HCL2000——a large-scale handwritten Chinese character database for handwritten character recognition. In:Proceedings of the 10th International Conference on Document Analysis and Recognition. Barcelona, Spain:IEEE, 2009.286-290 http://cn.bing.com/academic/profile?id=2137472923&encoded=0&v=paper_preview&mkt=zh-cn [12] 钱跃良, 林守勋, 刘群, 刘洋, 刘宏, 谢萦. 863计划中文信息处理与智能人机接口基础数据库的设计和实现. 高技术通讯, 2005, 15(1):107-110Qian Yue-Liang, Lin Shou-Xun, Liu Qun, Liu Yang, Liu Hong, Xie Ying. Design and construction of HTRDP corpora resources for Chinese language processing and intelligent human-machine interaction. Chinese High Technology Letters, 2005, 15(1):107-110 [13] Jin L W, Gao Y, Liu G, Liu G Y, Li Y Y, Ding K. SCUT-COUCH2009——a comprehensive online unconstrained Chinese handwriting database and benchmark evaluation. International Journal on Document Analysis and Recognition, 2011, 14(1):53-64 doi: 10.1007/s10032-010-0116-6 [14] Liu C L, Sako H, Fujisawa H. Handwritten Chinese character recognition:alternatives to nonlinear normalization. In:Proceedings of the 7th International Conference on Document Analysis and Recognition. Edinburgh, UK:IEEE, 2003.524-528 [15] Liu C L, Marukawa K. Pseudo two-dimensional shape normalization methods for handwritten Chinese character recognition. Pattern Recognition, 2005, 38(12):2242-2255 doi: 10.1016/j.patcog.2005.04.019 [16] Jin L W, Huang J C, Yin J X, He Q H. Deformation transformation for handwritten Chinese character shape correction. In:Proceedings of the 3rd International Conference on Advances in Multimodal Interfaces. Beijing, China:Springer, 2000.450-457 [17] Miyao H, Maruyama M. Virtual example synthesis based on PCA for off-line handwritten character recognition. In:Proceedings of the 7th International Workshop on Document Analysis Systems VⅡ. Nelson, New Zealand:Springer, 2006.96-105 [18] Chen G, Zhang H G, Guo J. Learning pattern generation for handwritten Chinese character using pattern transform method with cosine function. In:Proceedings of the 2006 International Conference on Machine Learning and Cybernetics. Dalian, China:IEEE, 2006.3329-3333 [19] Leung K C, Leung C H. Recognition of handwritten Chinese characters by combining regularization, Fisher's discriminant and distorted sample generation. In:Proceedings of the 10th International Conference on Document Analysis and Recognition. Barcelona, Spain:IEEE, 2009.1026-1030 https://www.computer.org/web/csdl/index/-/csdl/proceedings/icdar/2009/3725/00/index.html [20] Okamoto M, Nakamura A, Yamamoto K. Direction-change features of imaginary strokes for on-line handwriting character recognition. In:Proceedings of the 14th International Conference on Pattern Recognition. Brisbane, QLD:IEEE, 1998.1747-1751 [21] Okamoto M, Yamamoto K. On-line handwriting character recognition using direction-change features that consider imaginary strokes. Pattern Recognition, 1999, 32(7):1115-1128 doi: 10.1016/S0031-3203(98)00153-8 [22] Ding K, Deng G Q, Jin L W. An investigation of imaginary stroke techinique for cursive online handwriting Chinese character recognition. In:Proceedings of the 10th International Conference on Document Analysis and Recognition. Barcelona, Spain:IEEE, 2009.531-535 [23] Jin L W, Wei G. Handwritten Chinese character recognition with directional decomposition cellular features. Journal of Circuits, Systems, and Computers, 1998, 8(4):517-524 doi: 10.1142/S0218126698000316 [24] Bai Z L, Huo Q. A study on the use of 8-directional features for online handwritten Chinese character recognition. In:Proceedings of the 8th International Conference on Document Analysis and Recognition. Seoul, Korea:IEEE, 2005.262-266 [25] Liu C L, Zhou X D. Online Japanese character recognition using trajectory-based normalization and direction feature extraction. In:Proceedings of 10th International Workshop on Frontiers in Handwriting Recognition. La Baule, France:IEEE, 2006. http://or.nsfc.gov.cn/bitstream/00001903-5/96633/1/1000007198379.pdf [26] Ge Y, Huo Q, Feng Z D. Offline recognition of handwritten Chinese characters using Gabor features, CDHMM modeling and MCE training. In:Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing. Orlando, FL, USA:IEEE, 2002. I-1053-I-1056 [27] Liu C L. Normalization-cooperated gradient feature extraction for handwritten character recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(8):1465-1469 doi: 10.1109/TPAMI.2007.1090 [28] Kimura F, Takashina K, Tsuruoka S, Miyake Y. Modified quadratic discriminant functions and the application to Chinese character recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1987, PAMI-9(1):149-153 http://cn.bing.com/academic/profile?id=2041570030&encoded=0&v=paper_preview&mkt=zh-cn [29] Mangasarian O L, Musicant D R. Data discrimination via nonlinear generalized support vector machines. Complementarity:Applications, Algorithms and Extensions. US:Springer, 2001.233-251 http://cn.bing.com/academic/profile?id=1518494348&encoded=0&v=paper_preview&mkt=zh-cn [30] Kim H J, Kim K H, Kim S K, Lee J K. On-line recognition of handwritten Chinese characters based on hidden Markov models. Pattern Recognition, 1997, 30(9):1489-1500 doi: 10.1016/S0031-3203(96)00161-6 [31] Liu C L, Sako H, Fujisawa H. Discriminative learning quadratic discriminant function for handwriting recognition. IEEE Transactions on Neural Networks, 2004, 15(2):430-444 doi: 10.1109/TNN.2004.824263 [32] Jin X B, Liu C L, Hou X W. Regularized margin-based conditional log-likelihood loss for prototype learning. Pattern Recognition, 2010, 43(7):2428-2438 doi: 10.1016/j.patcog.2010.01.013 [33] Srihari S N, Yang X S, Ball G R. Offline Chinese handwriting recognition:an assessment of current technology. Frontiers of Computer Science in China, 2007, 1(2):137-155 doi: 10.1007/s11704-007-0015-2 [34] Su T H, Zhang T W, Guan D J, Huang H J. Off-line recognition of realistic Chinese handwriting using segmentation-free strategy. Pattern Recognition, 2009, 42(1):167-182 doi: 10.1016/j.patcog.2008.05.012 [35] Wang Q F, Yin F, Liu C L. Handwritten Chinese text recognition by integrating multiple contexts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(8):1469-1481 doi: 10.1109/TPAMI.2011.264 [36] Zhou X D, Wang D H, Tian F, Liu C L, Nakagawa M. Handwritten Chinese/Japanese text recognition using semi-Markov conditional random fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(10):2413-2426 doi: 10.1109/TPAMI.2013.49 [37] Qiu L Q, Jin L W, Dai R F, Zhang Y X, Li L. An open source testing tool for evaluating handwriting input methods. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.136-140 [38] Lin C L, Yin F, Wng Q F, Wang D H. ICDAR 2011 Chinese handwriting recognition competition. In:Proceedings of the 11th International Conference on Document Analysis and Recognition. Beijing, China:IEEE, 2011.1464-1469 [39] Yin F, Wang Q F, Zhang X Y, Liu C L. ICDAR 2013 Chinese handwriting recognition competition. In:Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, DC, USA:IEEE, 2013.1464-1470 [40] Graham B. Spatially-sparse convolutional neural networks. arXiv:1409.6070, 2014. http://cn.bing.com/academic/profile?id=2270144854&encoded=0&v=paper_preview&mkt=zh-cn [41] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786):504-507 doi: 10.1126/science.1127647 [42] Bengio Y, Courville A, Vincent P. Representation learning:a review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8):1798-1828 doi: 10.1109/TPAMI.2013.50 [43] Schmidhuber J. Deep learning in neural networks:an overview. Neural Networks, 2015, 61:85-117 doi: 10.1016/j.neunet.2014.09.003 [44] LeCun Y, Boser B, Denker J S, Howard R E, Habbard W, Jackel L D, Henderson D. Handwritten digit recognition with a back-propagation network. In:Proceedings of Advances in Neural Information Processing Systems 2. San Francisco, CA, USA:Morgan Kaufmann Publishers Inc., 1990.396-404 http://cn.bing.com/academic/profile?id=2109779438&encoded=0&v=paper_preview&mkt=zh-cn [45] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11):2278-2324 doi: 10.1109/5.726791 [46] Ranzato M A, Poultney C, Chopra S, LeCun Y. Efficient learning of sparse representations with an energy-based model. In:Proceedings of the 2007 Advances in Neural Information Processing Systems. USA:MIT Press, 2007.1137-1144 [47] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8):1735-1780 doi: 10.1162/neco.1997.9.8.1735 [48] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In:Proceedings of the 2012 Advances in Neural Information Processing Systems 25. Lake Tahoe, Nevada, USA:Curran Associates, Inc., 2012.1097-1105 [49] Ouyang W L, Wang X G, Zeng X Y, Qiu S, Luo P, Tian Y L, Li H S, Yang S, Wang Z, Loy C C, Tang X O. Deepid-net:Deformable deep convolutional neural networks for object detection. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015.2403-2412 [50] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556, 2014. http://cn.bing.com/academic/profile?id=1445015017&encoded=0&v=paper_preview&mkt=zh-cn [51] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. arXiv:1409.0473, 2014. http://arxiv.org/abs/1409.0473v6 [52] Graves A, Mohamed A, Hinton G. Speech recognition with deep recurrent neural networks. In:Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, BC, Canada:IEEE, 2013.6645-6649 http://cn.bing.com/academic/profile?id=2276532228&encoded=0&v=paper_preview&mkt=zh-cn [53] Xu K, Ba J, Kiros R, Cho, Courville A, Salakhutdinov R, Zemel R, Bengio Y. Show, attend and tell:neural image caption generation with visual attention. arXiv:1502.03044, 2015. https://arxiv.org/pdf/1505.00393.pdf [54] Vinyals O, Toshev A, Bengio S, Erhan D. Show and tell:a neural image caption generator. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015.3156-3164 http://arxiv.org/pdf/1602.05875.pdf [55] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553):436-444 doi: 10.1038/nature14539 [56] Tang Y C, Mohamed A R. Multiresolution deep belief networks. In:Proceedings of the 15th International Conference on Artificial Intelligence and Statistics. La Palma, Canary Islands, Spain:Microtome Publishing, 2012.1203-1211 [57] Srivastava N, Salakhutdinov R. Multimodal learning with deep Boltzmann machines. In:Proceedings of the 2012 Advances in Neural Information Processing Systems. Tahoe, Nevada, USA:Curran Associates, Inc., 2012.2222-2230 [58] Shao J, Kang K, Loy C C, Wang X G. Deeply learned attributes for crowded scene understanding. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015.4657-4666 [59] Oquab M, Bottou L, Laptev I, Sivic J. Learning and transferring mid-level image representations using convolutional neural networks. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA:IEEE, 2014.1717-1724 http://cn.bing.com/academic/profile?id=2396013981&encoded=0&v=paper_preview&mkt=zh-cn [60] Yang W X, Jin L W, Xie Z C, Feng Z Y. Improved deep convolutional neural network for online handwritten Chinese character recognition using domain-specific knowledge. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.551-555 http://dl.acm.org/citation.cfm?id=2880878 [61] Yang W X, Jin L W, Tao D C, Xie Z C, Feng Z Y. DropSample:a new training method to enhance deep convolutional neural networks for large-scale unconstrained handwritten Chinese character recognition. arXiv:1505.05354, 2015. http://arxiv.org/pdf/1606.05763v1.pdf [62] Yang W X, Jin L W, Liu M F. Character-level Chinese writer identification using path signature feature, dropstroke and deep CNN. arXiv:1505.04922, 2015. [63] Yang W X, Jin L W, Liu M F. DeepWriterID:an end-to-end online text-independent writer identification system. arXiv:1508.04945, 2015. [64] Su T H, Liu C L, Zhang X Y. Perceptron learning of modified quadratic discriminant function. In:Proceedings of the 2011 International Conference on Document Analysis and Recognition. Beijing, China:IEEE, 2011.1007-1011 [65] Du J, Hu J S, Zhu B, Wei S, Dai L R. A study of designing compact classifiers using deep neural networks for online handwritten Chinese character recognition. In:Proceedings of the 22nd International Conference on Pattern Recognition. Stockholm, Sweden:IEEE, 2014.2950-2955 [66] Du J. Irrelevant variability normalization via hierarchical deep neural networks for online handwritten Chinese character recognition. In:Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition. Heraklion, Greece:IEEE, 2014.303-308 [67] Du J, Huo Q, Chen K. Designing compact classifiers for rotation-free recognition of large vocabulary online handwritten Chinese characters. In:Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing. Kyoto, Japan:IEEE, 2012.1721-1724 [68] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527-1554 doi: 10.1162/neco.2006.18.7.1527 [69] Du J, Hu J S, Zhu B, Wei S, Dai L R. Writer adaptation using bottleneck features and discriminative linear regression for online handwritten Chinese character recognition. In:Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition. Heraklion, Greece:IEEE, 2014.311-316 [70] Liwicki M, Graves A, Bunke H. A novel approach to on-line handwriting recognition based on bidirectional long short-term memory networks. In:Proceedings of the 9th International Conference on Document Analysis and Recognition. Curitiba, Paraná, Brazil, 2007.367-371 [71] Frinken V, Bhattacharya N, Uchida S, Pal U. Improved BLSTM neural networks for recognition of on-line Bangla complex words. Structural, Syntactic, and Statistical Pattern Recognition. Berlin Heidelberg, German:Springer, 2014.404-413 [72] Wu W, Gao G L. Online cursive handwriting Mongolia words recognition with recurrent neural networks. International Journal of Information Processing and Management, 2011, 2(3):20-26 doi: 10.4156/ijipm [73] Graves A. Generating sequences with recurrent neural networks. arXiv:1308.0850, 2013. http://arxiv.org/pdf/1605.00064.pdf [74] Cireçsan D, Meier U. Multi-column deep neural networks for offline handwritten Chinese character classification. In:Proceedings of the 2015 International Joint Conference on Neural Networks. Killarney, Ireland:IEEE, 2015.1-6 [75] Cireçsan D C, Meier U, Gambardella L M, Schmidhuber J. Convolutional neural network committees for handwritten character classification. In:Proceedings of the 2011 International Conference on Document Analysis and Recognition. Beijing, China:IEEE, 2011.1135-1139 [76] Wu C P, Fan W, He Y, Sun J, Naoi S. Handwritten character recognition by alternately trained relaxation convolutional neural network. In:Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition. Crete, Greece:IEEE, 2014.291-296 [77] Zhong Z Y, Jin L W, Xie Z C. High performance offline handwritten Chinese character recognition using GoogLeNet and directional feature maps. In:Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR). Tunis:IEEE, 2015.846-850 http://dl.acm.org/citation.cfm?id=2880878 [78] Wang Y W, Li X, Liu C S, Ding X Q, Chen Y X. An MQDF-CNN hybrid model for offline handwritten Chinese character recognition. In:Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition. Heraklion, Greece:IEEE, 2014.246-249 [79] 高学, 王有旺. 基于CNN和随机弹性形变的相似手写汉字识别. 华南理工大学学报:自然科学版, 2014, 42(1):72-76 http://www.cnki.com.cn/Article/CJFDTOTAL-HNLG201401016.htmGao Xue, Wang You-Wang. Recognition of similar handwritten Chinese characters based on CNN and random elastic deformation. Journal of South China University of Technology:Natural Science Edition, 2014, 42(1):72-76 http://www.cnki.com.cn/Article/CJFDTOTAL-HNLG201401016.htm [80] 杨钊, 陶大鹏, 张树业, 金连文. 大数据下的基于深度神经网的相似汉字识别. 通信学报, 2014, 35(9):184-189 http://www.cnki.com.cn/Article/CJFDTOTAL-TXXB201409019.htmYang Zhao, Tao Da-Peng, Zhang Shu-Ye, Jin Lian-Wen. Similar handwritten Chinese character recognition based on deep neural networks with big data. Journal on Communications, 2014, 35(9):184-189 http://www.cnki.com.cn/Article/CJFDTOTAL-TXXB201409019.htm [81] Feng B Y, Ren M W, Zhang X Y, Suen C Y. Automatic recognition of serial numbers in bank notes. Pattern Recognition, 2014, 47(8):2621-2634 doi: 10.1016/j.patcog.2014.02.011 [82] He M J, Zhang S Y, Mao H Y, Jin L W. Recognition confidence analysis of handwritten Chinese character with CNN. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.61-65 http://dl.acm.org/citation.cfm?id=2880731 [83] Bengio Y, Goodfellow I J, Courville A. Deep learning[Online], available:http://www.deeplearningbook.org,May11,2016 [84] LeCun Y, Boser B, Denker J S, Henderson D, Howard R E, Hubbard W, Jackel L D. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989, 1(4):541-551 doi: 10.1162/neco.1989.1.4.541 [85] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015.1-9 http://www.mdpi.com/2072-4292/8/6/483/htm [86] Lin M, Chen Q, Yan S C. Network in network. arXiv:1312.4400, 2013. http://cn.bing.com/academic/profile?id=2293132816&encoded=0&v=paper_preview&mkt=zh-cn [87] Orr G B, Müller K R. Neural Networks:Tricks of the Trade. German:Springer, 1998. [88] Hinton G E, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv:1207.0580, 2012. http://cn.bing.com/academic/profile?id=2195273494&encoded=0&v=paper_preview&mkt=zh-cn [89] Wan L, Zeiler M, Zhang S X, LeCun Y, Fergus R. Regularization of neural networks using dropConnect. In:Proceedings of the 30th International Conference on Machine Learning. Atlanta, USA, 2013.1058-1066 https://arxiv.org/pdf/1505.00393.pdf [90] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S A, Huang Z H, Karpathy A, Khosla A, Bernstein M, Berg A C, Li F F. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3):211-252 doi: 10.1007/s11263-015-0816-y [91] Sun Y, Chen Y H, Wang X G, Tang X O. Deep learning face representation by joint identification-verification. In:Proceedings of Advances in Neural Information Processing Systems 27. Montréal, Canada:MIT, 2014.1988-1996 [92] Taigman Y, Yang M, Ranzato M A, Wolf L. DeepFace:closing the gap to human-level performance in face verification. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE, 2014.1701-1708 http://europepmc.org/articles/PMC4373928 [93] Toshev A, Szegedy C. Deeppose:Human pose estimation via deep neural networks. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE, 2014.1653-1660 https://www.computer.org/csdl/proceedings/cvpr/2014/5118/00/index.html [94] Williams R J, Zipser D. A learning algorithm for continually running fully recurrent neural networks. Neural Computation, 1989, 1(2):270-280 doi: 10.1162/neco.1989.1.2.270 [95] Graham B. Sparse arrays of signatures for online character recognition. arXiv:1308.0371, 2013. http://cn.bing.com/academic/profile?id=2360228825&encoded=0&v=paper_preview&mkt=zh-cn [96] Jaderberg M, Simonyan K, Vedaldi A, Zisserman A. Synthetic data and artificial neural networks for natural scene text recognition. arXiv:1406.2227, 2014. http://arxiv.org/abs/1406.2227?context=cs [97] Jaderberg M, Vedaldi A, Zisserman A. Deep features for text spotting. In:Proceedings of the 13th European Conference Computer Vision. Zurich, Switzerland:Springer, 2014.512-528 http://cn.bing.com/academic/profile?id=70975097&encoded=0&v=paper_preview&mkt=zh-cn [98] Wu Y C, Yin F, Liu C L. Evaluation of neural network language models in handwritten Chinese text recognition. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.166-170 [99] Bengio Y, Schwenk H, Senécal J S, Morin F, Gauvain J L. Neural probabilistic language models. Innovations in Machine Learning. Berlin Heidelberg, Germany:Springer, 2006.137-186 [100] Chen X, Tan T, Liu X, Lanchantin P, Wan M, Gales MJF, Woodland PC. Recurrent neural network language model adaptation for multi-genre broadcast speech recognition. In:Proceedings of the 2015 International Speech Communication Association Interspeech. Dresden, Germany, 2015.3511-3515 [101] Sak H, Senior A, Rao K,ÌIrsoy O, Graves A, Beaufays F, Schalkwyk J. Learning acoustic frame labeling for speech recognition with recurrent neural networks. In:Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing. South Brisbane, QLD:IEEE, 2015.4280-4284 [102] De Mulder W, Bethard S, Moens M F. A survey on the application of recurrent neural networks to statistical language modeling. Computer Speech & Language, 2015, 30(1):61-98 http://cn.bing.com/academic/profile?id=2154137718&encoded=0&v=paper_preview&mkt=zh-cn [103] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers:surpassing human-level performance on imagenet classification. In:Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile:IEEE, 2015.1026-1034 [104] Ioffe S, Szegedy C. Batch normalization:accelerating deep network training by reducing internal covariate shift. arXiv:1502.03167, 2015. http://cn.bing.com/academic/profile?id=2397299141&encoded=0&v=paper_preview&mkt=zh-cn [105] Fukushima K. Neocognitron:a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 1980, 36(4):193-202 doi: 10.1007/BF00344251 [106] Werbos P J. Backpropagation through time:what it does and how to do it. Proceedings of the IEEE, 1990, 78(10):1550-1560 doi: 10.1109/5.58337 [107] Littman M L. Reinforcement learning improves behaviour from evaluative feedback. Nature, 2015, 521(7553):445-451 doi: 10.1038/nature14540 [108] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, Graves A, Riedmiller M, Fidjeland A K, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540):529-533 doi: 10.1038/nature14236 [109] Cuda-ConvNet2 [Online], available:https://github.com/akrizhevsky/cuda-convnet2, May 11, 2016 [110] Bengio Y, LeCun Y, Nohl C, Burges C. LeRec:a NN/HMM hybrid for on-line handwriting recognition. Neural Computation, 1995, 7(6):1289-1303 doi: 10.1162/neco.1995.7.6.1289 [111] Simard P Y, Steinkraus D, Platt J C. Best practices for convolutional neural networks applied to visual document analysis. In:Proceedings of the 7th International Conference on Document Analysis and Recognition. Edinburgh, UK:IEEE, 2003.958-963 [112] Caffe[Online], available:http://caffe.berkeleyvision.org/, May 11, 2016 [113] Bastien F, Lamblin P, Pascanu R, Bergstra J, Goodfellow I, Bergeron A, Bouchard N, Warde-Farley D, Bengio Y. Theano:new features and speed improvements. arXiv:1211.5590, 2012. http://cn.bing.com/academic/profile?id=2166015963&encoded=0&v=paper_preview&mkt=zh-cn [114] Bergstra J, Breuleux O, Bastien F, Lamblin P, Pascanu R, Desjardins G, Turian J, Warde-Farley D, Bengio Y. Theano:a CPU and GPU math expression compiler. In:Proceedings of the 9th Python for Scientific Computing Conference. Austin, TX, USA, 2010.1-7 http://dl.acm.org/citation.cfm?id=2912118 [115] Torch[Online], available:http://torch.ch/, May 11, 2016 [116] Lin M, Li S, Luo X, Yan S C. Purine:a bi-graph based deep learning framework. arXiv:1412.6249, 2014. [117] MXNet[Online], available:https://github.com/dmlc/mx-net,May11,2016 [118] DIGITS[Online], available:https://developer.nvidia.com/digits, May 11, 2016 [119] ConvNet[Online], available:https://code.google.com/p/cuda-convnet/, May 11, 2016 [120] DeepCNet[Online], available:http://www2.warwick.ac.u-k/fac/sci/statistics/staff/academic-research/graham/,May11,2016 [121] Xing E P, Ho Q R, Dai W, Kim J K, Wei J L, Lee S, Zheng X, Xie P T, Kumar A, Yu Y L. Petuum:a new platform for distributed machine learning on big data. IEEE Transactions on Big Data, 2015, 1(2):49-67 doi: 10.1109/TBDATA.2015.2472014 [122] Weninger F, Bergmann J, Schuller B. Introducing CURRENNT:the Munich open-source CUDA recurrent neural network toolkit. The Journal of Machine Learning Research, 2015, 16(1):547-551 [123] Minerva[Online], available:https://github.com/dmlc/min-erva,May11,2016 [124] TensorFlow[Online], available:https://github.com/tensor-flow/tensorflow,May11,2016 [125] DMTK[Online], available:https://github.com/Microsoft/DMTK,May3,2016 [126] Cireçsan D C, Meier U, Schmidhuber J. Transfer learning for Latin and Chinese characters with deep neural networks. In:Proceedings of the 2012 International Joint Conference on Neural Networks. Brisbane, QLD:IEEE, 2012.1-6 [127] Ciresan D, Meier U, Schmidhuber J. Multi-column deep neural networks for image classification. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, Rhode Island:IEEE, 2012.3642-3649 [128] Bastien F, Bengio Y, Bergeron A, Boulanger-Lewandowski N, Breuel T, Chherawala Y, Cisse M, Côté M, Erhan D, Eustache J, Glorot X, Muller X, Lebeuf S P, Pascanu R, Rifai S, Savard F, Sicard G. Deep self-taught learning for handwritten character recognition. arXiv:1009.3589, 2010. [129] Chen L, Wang S, Fan W, Sun J, Naoi S. Beyond human recognition:a CNN-based framework for handwritten character recognition. In:Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition. Kuala Lumpur, Malaysia:IEEE, 2015.695-699 [130] Chen K T. Integration of paths-A faithful representation of paths by noncommutative formal power series. Transactions of the American Mathematical Society, 1958, 89(2):395-407 http://cn.bing.com/academic/profile?id=2074884967&encoded=0&v=paper_preview&mkt=zh-cn [131] Lyons T. Rough paths, Signatures and the modelling of functions on streams. arXiv:1405.4537, 2014. http://econpapers.repec.org/RePEc:arx:papers:1405.4537 [132] Graham B. Fractional max-pooling. arXiv:1412.6071, 2014. http://arxiv.org/abs/1412.6071 [133] Graves A, Fernández S, Gomez F, Schmidhuber J. Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks. In:Proceedings of the 23rd International Conference on Machine Learning. Pittsburgh, Pennsylvania, USA:ACM, 2006.369-376 http://cn.bing.com/academic/profile?id=2168772685&encoded=0&v=paper_preview&mkt=zh-cn [134] Graves A, Schmidhuber J. Offline handwriting recognition with multidimensional recurrent neural networks. In:Proceedings of the 2009 Advances in Neural Information Processing Systems 21. Vancouver, B.C., Canada:Curran Associates, Inc., 2009.545-552 [135] Zhang X, Wang M, Wang L J, Huo Q, Li H F. Building handwriting recognizers by leveraging skeletons of both offline and online samples. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.406-410 [136] Simistira F, Ul-Hassan A, Papavassiliou V, Gatos B, Katsouros V, Liwicki M. Recognition of historical Greek polytonic scripts using LSTM networks. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.766-770 http://dl.acm.org/citation.cfm?id=2880878 [137] Frinken V, Uchida S. Deep BLSTM neural networks for unconstrained continuous handwritten text recognition. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.911-915 http://dl.acm.org/citation.cfm?id=2880731 [138] Messina R, Louradour J. Segmentation-free handwritten Chinese text recognition with LSTM-RNN. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.171-175 http://dl.acm.org/citation.cfm?id=2880731 [139] Mioulet L, Garain U, Chatelain C, Barlas P, Paquet T. Language identification from handwritten documents. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.676-680 [140] Huang S M, Jin L W, Lv J. A novel approach for rotation free online handwritten Chinese character recognition. In:Proceedings of the 10th International Conference on Document Analysis and Recognition. Barcelona, Spain:IEEE, 2009.1136-1140 [141] Moysset B, Kermorvant C, Wolf C, Louradour J. Paragraph text segmentation into lines with recurrent neural networks. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015, 456-460 http://dl.acm.org/citation.cfm?id=2880731 [142] He P, Huang W L, Qiao Y, Loy C C, Tang X O. Reading scene text in deep convolutional sequences. arXiv:1506.04395, 2015. http://cn.bing.com/academic/profile?id=2338605913&encoded=0&v=paper_preview&mkt=zh-cn [143] Shi B G, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. arXiv:1507.05717, 2015. http://arxiv.org/abs/1507.05717 [144] iiMedia Research. 2015Q2 Report of input methods for mobile phone in China market[Online], available:http://www.iimedia.com.cn/,May11,2016 [145] 中华人民共和国国家质量监督检验检疫总局, 中国国家标准化管理委员会. GB/T18790-2010联机手写汉字识别系统技术要求与测试规程. 2011General Administration of Quality Supervision, Inspection and Quarantine of the People's Republic of China, Standardization Administration of the People's Republic of China. GB/T18790-2010 Requirements and test procedure of on-line handwriting Chinese character recognition system. 2011 [146] Long T, Jin L W. A novel orientation free method for online unconstrained cursive handwritten Chinese word recognition. In:Proceedings of the 19th International Conference on Pattern Recognition. Tampa, FL, USA:IEEE, 2008.1-4 [147] He T T, Huo Q. A character-structure-guided approach to estimating possible orientations of a rotated isolated online handwritten Chinese character. In:Proceedings of the 10th International Conference on Document Analysis and Recognition. Barcelona, Spain:IEEE, 2009.536-540 [148] 黄盛明.联机手写汉字的旋转无关识别研究[硕士学位论文].华南理工大学, 2010 http://cdmd.cnki.com.cn/article/cdmd-10561-1014063919.htmHuang S. A Study on Recognition for Rotated Isolated Online Handwritten Chinese Character[Master dissertation], South China University of Technology, China, 2010 http://cdmd.cnki.com.cn/article/cdmd-10561-1014063919.htm [149] Karatzas D, Gomez-Bigorda L, Nicolaou A, Ghosh S, Bagdanov A, Iwamura M, Matas J, Neumann L, Chandrasekhar V R, Lu S J, Shafait F, Uchida S, Valveny E. ICDAR 2015 competition on robust reading. In:Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis:IEEE, 2015.1156-1160 -

 下载:
下载:

计量
- 文章访问数: 7796
- HTML全文浏览量: 5969
- PDF下载量: 5506
- 被引次数: 0
