

-
摘要: 在线人体动作识别是人体动作识别的最终目标,但由于如何分割动作序列是一个待解决的难点问题,因此目前大多数人体动作识别方法仅关注在分割好的动作序列中进行动作识别,未关注在线人体动作识别问题.本文针对这一问题,提出了一种可以完成在线人体动作识别的时序深度置信网络(Temporal deep belief network, TDBN)模型.该模型充分利用动作序列前后帧提供的上下文信息,解决了目前深度置信网络模型仅能识别静态图像的问题,不仅大大提高了动作识别的准确率,而且由于该模型不需要人为对动作序列进行分割,可以从动作进行中的任意时刻开始识别,实现了真正意义上的在线动作识别,为实际应用打下了较好的理论基础.Abstract: Online human action recognition is the ultimate goal of human action recognition. However, how to segment the action sequence is a difficult problem to be solved. So far, most human action recognition algorithms are only concerned with the action recognition within a segmented action sequences. In order to solve this problem, a deep belief network (DBN) model is proposed which can handle sequential time series data. This model makes full use of the action sequences and frames to provide contextual information so that it can handle video data. Moreover, this model not only greatly improves the action recognition accuracy, but also realizes online action recognition. So it lays a good theoretical foundation for practical applications.
-
预测与健康管理(Prognostics and health management, PHM) 技术能够充分利用系统的状态监测信息, 估计系统在生命周期内的可靠性, 并通过维护活动降低系统失效事件发生的风险[1-5].准确预测系统剩余寿命是PHM的核心和基础, 是能否做出正确维护决策的关键和前提, 只有准确的剩余寿命预测才能够保证系统恰当的维护时机, 进而有效地提高系统的可用性, 减少维修保障费用[3-6].因此, 剩余寿命预测已成为近十年来可靠性领域研究的热点问题[3-6].在工程实际中, 由于系统与系统之间的差异、经历的不同环境, 系统的退化与剩余寿命都具有一定的随机性.
随着现代信息采集技术的发展, 获取系统的退化信号变得相对容易.但在工程实际中, 退化信号一般具有非线性和随机性特征.例如, 金属疲劳裂纹增长、陀螺仪精度降低和锂电池容量减小等[7-12].因此, 对于随机退化系统, 要得到其确定的剩余寿命结果是非常困难, 甚至是不可能的.
一般情况下, 剩余寿命的这种不确定性通过概率密度函数来表示则更为合理, 这也是管理决策所需要的.事实上, 不确定性测量和系统间的个体差异性广泛存在于系统的退化过程中, 导致系统寿命的不确定性.如何将不确定测量和个体差异性的影响融入到剩余寿命分布中, 实现对此类非线性随机退化系统更准确的剩余寿命预测, 是值得研究的现实问题, 且尚未解决.基于退化建模的方法进行剩余寿命估计与传统基于历史寿命数据的方法相比, 无论从经济性还是安全性上都表现出更大的优势. Si等对基于退化建模的剩余寿命估计方法进行了系统而完整的论述[7].然而, 现有文献大多考虑线性退化过程的情况, 建立线性退化模型进行剩余寿命估计[10, 13-14].例如, Wang等[13]利用Wiener过程进行退化建模, 并通过Kalman滤波实现参数的自适应估计, 但其采用的是线性退化模型.然而, 对于工程实际中大量存在的非线性退化过程, 用线性建模方法无法有效地进行跟踪估计.
对此问题, 现有研究大多假设存在某些针对退化数据的转换技术(如对数变换、时间尺度变换等), 将非线性特征的数据转换为近似线性的数据, 再利用线性随机过程进行建模.例如Park等[15]和Gebraeel等[16-17]利用对数变换, 将指数类退化数据进行线性化, 然后通过Wiener过程进行退化建模和剩余寿命估计. Wang等[18-19]利用时间尺度变换, 将非线性数据变换为线性数据再进行寿命估计.但数据转换技术具有一定的局限性, 并不是所有非线性退化过程都可以转换为线性过程, 并且转换后的随机项不一定仍然是标准Brown运动.另外, Zio等[20]和Cadini等[21]利用蒙特卡洛方法和粒子滤波方法估计出非线性退化过程的剩余寿命, 但此类方法只能得到近似数值解, 并不能获取健康管理所需的概率密度函数的解析解.
Si等[9]在随机模型层面, 通过对非线性随机模型的时间-空间变换, 将非线性随机过程首达固定失效阈值的问题转换为标准Brown运动首达时变边界问题, 进而得到剩余寿命分布的解析渐近解, 并考虑了存在个体差异下的剩余寿命估计, 但未考虑不确定测量对剩余寿命估计的影响. Wang等[22]提出了一种对非线性随机退化过程的剩余寿命自适应估计方法, 同时考虑了个体差异性, 但仍未考虑不确定测量的影响.司小胜等[23]虽然考虑了测量误差, 但仅是针对参数估计, 并未在剩余寿命推导中考虑不确定测量. Feng等[24-25]通过建立状态空间估计模型讨论了不同形式的非线性随机退化过程剩余寿命估计, 并通过Kalman滤波技术解决了不确定测量的影响, 但均忽略了个体差异对剩余寿命估计的影响.
综上分析, 本文针对非线性随机退化系统, 提出了一种同时考虑不确定测量和个体差异的非线性退化过程建模和剩余寿命估计方法.首先, 建立了基于扩散过程的非线性退化模型, 然后推导了同时考虑不确定测量与个体差异下的剩余寿命分布.进一步, 利用极大似然估计得到模型参数初值, 再通过建立的状态空间模型和Kalman滤波技术对漂移系数进行自适应估计.最后通过航天用铝合金疲劳裂纹增长数据和陀螺仪漂移数据对本文所提方法进行了验证.
1. 非线性退化过程建模
考虑采用扩散过程来建模非线性退化过程$\left\{ {X (t), t \ge 0} \right\}$, $X (t)$表示t时刻的退化量, 具体表示为
$\begin{equation} X(t) = X(0) + \int_0^t {\mu (t;{\boldsymbol{\theta}} )} {\rm d}t + {\sigma _B}B(t) \end{equation}$
(1) 其中, 退化过程$X (t)$是由标准Brown运动$B (t)$驱动的, $\mu (t; {\boldsymbol{\theta}})$和$\sigma _B$分别表示漂移系数和扩散系数, $\int_0^t {\mu (t; {\boldsymbol{\theta}})} {\rm d}t$是时间t的非线性函数, 用以表征模型的非线性特征, ${\boldsymbol{\theta}}$为未知参数.由于$\mu (t; {\boldsymbol{\theta}})$是依赖时间的函数, 因此本文所研究的退化过程是非时齐的退化过程.另外, 当$\mu (t; {\boldsymbol{\theta}})={\boldsymbol{\theta}}$时, 则模型刻画的退化过程为线性随机退化过程, 即线性模型是本模型的特例.不失一般性, 设初始状态$X (0)=0$.
在工程实践中, 退化状态的测量值虽然能够反映潜在状态的退化趋势, 但由于存在不可避免的测量误差(一般由于仪器或外部环境噪声干扰引起), 测量的退化数据只能部分地反映退化状态, 存在一定的不确定性.为描述这种不确定测量的影响, 本文仅考虑测量是离散的, 在离散时间点$t_k$时刻的测量数据可描述为
$\begin{equation} Y({t_k}) = X({t_k}) + {\varepsilon _k} \end{equation}$
(2) 其中$\varepsilon_k$表示随机测量误差, 假设是独立同分布的, 且${\varepsilon _k} \sim {\rm N}(0, {\sigma _\varepsilon }^2)$.由于同类产品中的每个系统在运行过程中可能经受不同形式的扰动, 导致退化轨迹不同, 因此有必要考虑个体之间的差异.在此, 将退化模型中的未知参数${\boldsymbol{\theta}}$表示为${\boldsymbol{\theta}}=({a}{\bf{, }}\, {b})$, 其中${a}$为随机参数, 描述个体差异, ${b}$是确定参数, 描述同类系统共性特征.为便于分析, 这里假设${\boldsymbol{\theta}}$, $\varepsilon _k$和$B (t)$是独立同分布的.
考虑到系统会经历连续的退化过程, 其剩余寿命也随之逐渐减少.当表征退化过程的状态参量$\left\{ {X (t), t \ge 0} \right\}$首次达到预先设定的失效阈值w时, 即认为系统失效, 此时系统剩余寿命为0.因此, 自然地就可将设备寿命终止的时间定义为随机退化过程首次穿越失效阈值w的时间.基于此首达时间的概念[9-10, 22, 24, 26-28], 寿命T可以定义为
$\begin{equation} T = \inf \left\{ {t:\left. {X(t) \ge w} \right|X(0) < w} \right\} \end{equation}$
(3) 再根据剩余寿命的定义, 定义系统在当前时刻$t_k$的剩余寿命$L_k$为
$\begin{equation} {L_k} = \inf \left\{ {{l_k} > 0:X({l_k} + {t_k}) \ge w} \right\} \end{equation}$
(4) 由以上定义可知, 基于随机退化过程估计系统剩余寿命的关键在于求解寿命T的概率密度函数(Probability density function, PDF) ${f_T}(t)$, 进而估计剩余寿命$L_k$的概率分布.
2. 同时考虑不确定测量和个体差异下的剩余寿命估计
为了获取非线性退化模型剩余寿命分布的近似解析解, 采用文献[9]和[24]中的假设:如果潜在退化过程$\left\{ {X (t), t \ge 0} \right\}$在t时刻精确达到失效阈值, 则该过程在t时刻以前超过边界的概率是可忽略的.基于此假设, 利用如下引理可求解退化过程首达失效阈值时间的概率密度函数.
引理 1[23]. 对由式(1) 描述的退化过程, 如果$\mu (t; {\boldsymbol{\theta}})$是时间t在$[0, \infty)$上的连续函数, 在给定随机参数下, 穿越失效阈值w的首达时间的概率密度函数可以表示为
$\begin{align} {f_{T|{ {a}}}}(t|{ {a}}) \cong &\frac{1}{{\sqrt {2\pi t} }}\left( {\frac{{{S_B}(t)}}{t} + \frac{1}{{{\sigma _B}}}\mu (t;{\boldsymbol{\theta}} )} \right)\times \nonumber \\ & \exp \left[{-\frac{{S_B^2(t)}}{{2t}}} \right] \end{align}$
(5) 其中, ${S_B}(t)=(w -\int_0^t {\mu (\tau; {\boldsymbol{\theta}}){\rm d}} \tau)/{\sigma _B}$.
进一步, 当考虑退化系统的个体差异时, 即考虑${a}$的随机性时, 可通过全概率公式
$\begin{equation} {f_T}(t) = \int_{a}^{} {{f_{T|{a}}}(t|{a})p({a})} {\rm d}{a} = {\textrm{E}_{a}}[{f_{T|{a}}}(t|{a})] \end{equation}$
(6) 得到${f_T}(t)$的表达式, $p ({a})$为参数${a}$的概率密度函数.
为了便于比较和验证, 下面考虑一类满足式(1) 的扩散过程, 令漂移系数$\mu (t; {\boldsymbol{\theta}})=ab{t^{b -1}}$, 则退化模型可变为
$\begin{equation} X(t) = X(0) + a{t^b} + {\sigma _B}B(t) \end{equation}$
(7) 这里a为随机系数刻画系统个体的差异, 且$a\sim {\rm N}({\mu _a}, \sigma _a^2)$.基于引理1和前述假设, 可得到a给定时$\left\{ {X (t), t \ge 0} \right\}$穿越失效阈值w的首达时间的概率密度函数为
$\begin{align} {f_{T|a}}(t|a) \cong \frac{{w - a{t^b}(1 - b)}}{{{\sigma _B}\sqrt {2\pi {t^3}} }}\exp \left[{ \frac{{{{-(w- a{t^b})}^2}}}{{2\sigma _B^2t}}} \right] \end{align}$
(8) 当$b=1$时, 式(8) 简化为逆高斯分布, 可见此结果是现有基于Wiener过程退化模型的一般化推广.
下面考虑在当前时刻$t_k$时估计系统剩余寿命的问题.假设$t_k$监测时间点对应的监测退化状态为${X_k}=X ({t_k})$, 则被估计系统剩余寿命的概率密度函数可由如下定理给出.
定理 1. 若系统在$t_k$时刻的退化状态为$X_k$, 则在$t_k$时刻估计的剩余寿命的概率密度函数可由下式近似解析给出
$\begin{align} {f_{{L_k}|{X_k}, a}}& ({l_k}|a, {X_k})\cong\nonumber \\ & \frac{{{w_k} - a(\eta ({l_k}) - b{l_k}{{({l_k} + {t_k})}^{b - 1}}))}}{{{\sigma _B}\sqrt {2\pi l_k^3} }}\times \nonumber \\ & \exp \left[{-\frac{{{{\left( {{w_k}-a\eta ({l_k})} \right)}^2}}}{{2\sigma _B^2t}}} \right] \end{align}$
(9) 其中$\eta ({l_k})={({l_k} + {t_k})^b} -t_k^b, {w_k}=w -{X_k}$.
证明. 对于任意时刻$t \ge {t_k}$, 由标准Brown运动的马尔科夫性, 退化过程可以表示为$X (t)={X_k} + a ({t^b} -t_k^b) + {\sigma _B}B (t -t_k^{})$, 此时, 若t对应退化过程的首达时间, 则差值$t -{t_k}$就对应着$t_k$时刻的剩余寿命${l_k}=t -{t_k}$, 随机过程$\left\{ {X (t), t \ge {t_k}} \right\}$可以变换为
$\begin{equation} X({l_k} + {t_k}) - X({t_k}) = a[{({l_k} + {t_k})^b}-{t_k}^b] + {\sigma _B}B({l_k}) \end{equation}$
(10) 因此, $t_k$时刻的剩余寿命等于随机过程$\left\{ {R ({l_k}), {l_k} \ge 0} \right\}$首达失效阈值${w_k}=w -{X_k}$的时间, 这里
$\begin{equation} R({l_k}) = a[{({l_k} + {t_k})^b}-{t_k}^b] + {\sigma _B}B({l_k}) \end{equation}$
(11) 且$\left\{ {R ({l_k}), {l_k} \ge 0} \right\}$满足引理1的相关条件.那么对于$\left\{ {Z ({l_k}), {l_k} \ge 0} \right\}$有$\mu ({l_k}; {\boldsymbol{\theta}})=ab{({l_k} + {t_k})^{b -1}}$, 基于引理1, 经过简单推导即可得到式(9).
为了得到同时考虑不确定测量和个体差异下的寿命分布表达式, 首先给出以下引理:
引理 2[9]. 若$Z \sim {\rm N}(\mu, {\sigma ^2})$, ${w_1}, {w_2}, A, B \in {\bf{R}}$, $S \in {{\bf{R}}^ + }$, 则有
$\begin{align} &{{\rm E}_Z}\left[{({w_1}-AZ) \cdot \exp \left( {-\frac{{{{({w_2}-BZ)}^2}}}{{2S}}} \right)} \right]= \nonumber \\ &\qquad\sqrt {\frac{S}{{{B^2}{\sigma ^2} + S}}} \left( {{w_1} - A\frac{{B{\sigma ^2}{w_2} + \mu S}}{{{B^2}{\sigma ^2} + S}}} \right)\times\nonumber \\ &\qquad \exp \left( { - \frac{{{{({w_2} - B\mu )}^2}}}{{2\left( {{B^2}{\sigma ^2} + S} \right)}}} \right) \end{align}$
(12) 引理 3[10]. 给定当前退化状态$X_k$, a和${{\boldsymbol{Y}}_{1:k}}$, 有:
$\begin{equation} {f_{\left. {{L_k}} \right|a, {X_k}, {{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|a, {X_k}, {{\boldsymbol{Y}}_{1:k}}) = {f_{\left. {{L_k}} \right|a, {X_k}}}(\left. {{l_k}} \right|a, {X_k}) \end{equation}$
(13) 证明.
$\begin{align} &{f_{\left. {{L_k}} \right|a, {X_k}, {{\pmb Y}_{1:k}}}}(\left. {{l_k}} \right|a, {X_k}, {{\pmb Y}_{1:k}})= \nonumber \\ &\qquad \frac{\rm d}{{{\rm d}{l_k}}}\Pr ({L_k} \le {l_k}|a, {X_k}, {{\pmb Y}_{1:k}})= \nonumber \\ &\qquad \frac{\rm d}{{{\rm d}{l_k}}}\Pr (\mathop {\sup }\limits_{{l_k} > 0} X({t_k} + {l_k}) \ge \omega |a, {X_k}, {{\pmb Y}_{1:k}})=\nonumber \\ &\qquad \frac{\rm d}{{{\rm d}{l_k}}}\Pr (\mathop {\sup }\limits_{{l_k} > 0} X({t_k} + {l_k}) \ge \omega |a, {X_k})= \nonumber \\ & \qquad{f_{\left. {{L_k}} \right|a, {x_k}}}(\left. {{l_k}} \right|a, {X_k}) \end{align}$
(14) 下面, 将研究如何同时考虑不确定测量和个体差异下的非线性随机退化过程, 并实现对a的实时更新, 用以剩余寿命估计.
为融入个体差异并对参数进行更新, 建立对随机参数a随测量时间的更新机制为$a_k=a_{k -1}$, 其中${a_0}\sim {\rm N}({\mu _a}, \sigma _a^2)$为初始分布.那么, 可以基于监测的退化数据实现对a的后验估计.为此, 构建同时考虑不确定测量和个体差异的状态空间模型为
$\begin{equation} \left\{ \begin{array}{l} {X_k} = {X_{k - 1}} + {a_{k - 1}}(t_k^b - t_{k - 1}^b) + {v_k}\\ {a_k} = {a_{k - 1}}\\ {Y_k} = {X_k} + {\varepsilon _k} \end{array} \right. \end{equation}$
(15) 其中${\{ {v_k}\} _{k \ge 1}}$和${ \{{\varepsilon _k}\} _{k \ge 1}}$分别是统计独立的噪声序列, 且${v_k} \sim {\rm N}\left ({0, \sigma _B^2({t_k} -{t_{k -1}})} \right)$, ${\varepsilon _k} \sim {\rm N}(0, \sigma _\varepsilon ^2)$.
进一步, 可将系统的潜在退化状态$X_k$和随机参数a视作隐含“状态”, 并通过测量数据${\boldsymbol{Y}}_{1:k}$估计.为应用Kalman滤波对退化状态和随机参数进行同时估计, 整理式(15) 为
$\begin{equation} \left\{ {\begin{array}{*{25}{c}} {{{\boldsymbol{Z}}_k} = {{ {A}}_k}{{\boldsymbol{Z}}_{k - 1}} + {{\boldsymbol{\eta}} _k}}\\ {{Y_k} = {\boldsymbol{C}}{{\boldsymbol{Z}}_k} + {\varepsilon _k}} \end{array}} \right. \end{equation}$
(16) 其中${{\boldsymbol{Z}}_k} \in {{\bf{R}}^{2 \times 1}}$, ${\boldsymbol{\eta} _k} \in {{\bf{R}}^{2 \times 1}}$, ${ {A}_k} \in {{\bf{R}}^{2 \times 2}}$, $\boldsymbol{C} \in {{\bf{R}}^{1 \times 2}}$, ${\boldsymbol{\eta} _k} \sim {\rm N}(0, { {Q}_k})$, 且有$\boldsymbol{C}=\left[{1, 0} \right], $
${{\boldsymbol{Z}}_k} \!\!=\! \left[{\begin{array}{*{20}{c}} {{X_k}}\\ {{a_k}} \end{array}} \right], {\boldsymbol{\eta}_k} \!= \!\left[{\begin{array}{*{20}{c}} {{v_k}}\\ 0 \end{array}} \right], { {A}_k}\!=\!\left[{\begin{array}{*{20}{c}} 1&{t_k^b-t_{k-1}^b}\\ 0&1 \end{array}}\right]\!$
${ {Q}_k} = \left[{\begin{array}{*{20}{c}} {\sigma _B^2({t_k}-{t_{k-1}})}&0\\ 0&0 \end{array}} \right]$
类似的, 定义${\boldsymbol{Z}_k}$的期望和方差分别为
$\begin{equation} {\hat {\boldsymbol{Z}}_{\left. k \right|k}} = \left[ {\begin{array}{*{20}{c}} {{{\hat x}_{\left. k \right|k}}}\\ {{a_{\left. k \right|k}}} \end{array}} \right] = {\rm E}(\left. {{{\boldsymbol{Z}}_k}} \right|{{\boldsymbol{Y}}_{1:k}}) \end{equation}$
(17) $\begin{equation} {{ {P}}_{\left. k \right|k}} = \left[{\begin{array}{*{20}{c}} {\kappa _{x, k}^2}&{\kappa _{c, k}^2}\\ {\kappa _{c, k}^2}&{\kappa _{a, k}^2} \end{array}} \right] = {\mathop{\rm cov}} (\left. {{{\boldsymbol{Z}}_k}} \right|{{\boldsymbol{Y}}_{1:k}}) \end{equation}$
(18) 其中${\hat X_{\left. k \right|k}}={\rm E}(\left. {{X_k}} \right|{{\boldsymbol{Y}}_{1:k}})$, ${\hat a_{\left. k \right|k}}={\rm E}(\left. {{a_k}} \right|{{\boldsymbol{Y}}_{1:k}})$, $\kappa _{x, k}^2\\={\mathop{\rm var}} (\left. {{X_k}} \right|{{\boldsymbol{Y}}_{1:k}})$, $\kappa _{a, k}^2={\mathop{\rm var}} (\left. {{a_k}} \right|{{\boldsymbol{Y}}_{1:k}})$, $\kappa _{c, k}^2={\mathop{\rm cov}} (\left. {{X_k}, {a_k}} \right|{{\boldsymbol{Y}}_{1:k}})$.
进一步, 定义一步估计的期望和协方差为
$\begin{equation} {\hat {\boldsymbol{Z}}_{\left. k \right|k - 1}} = \left[ {\begin{array}{*{20}{c}} {{{{\hat{ X}}}_{\left. k \right|k-1}}}\\ {{{\hat a}_{\left. k \right|k-1}}} \end{array}} \right] = {\rm E}(\left. {{{\boldsymbol{Z}}_k}} \right|{{\boldsymbol{Y}}_{1:k - 1}}) \end{equation}$
(19) $\begin{equation} {{ {P}}_{\left. k \right|k - 1}} \!=\! \left[ {\begin{array}{*{20}{c}} {\kappa _{\left. {x, k} \right|k-1}^2}\!&\!{\kappa _{\left. {c, k} \right|k-1}^2}\\ {\kappa _{\left. {c, k} \right|k-1}^2}\!&\!{\kappa _{\left. {a, k} \right|k - 1}^2} \end{array}} \right]\!\! =\! {\mathop{\rm cov}} (\left. {{{\boldsymbol{Z}}_k}} \right|{{\boldsymbol{Y}}_{1:k - 1}}) \end{equation}$
(20) 根据以上设定, 基于实时获取的退化测量数据, 用Kalman滤波方法对由退化状态和随机参数组成的${{\boldsymbol{Z}}_k}$进行联合估计, 过程如下:
状态估计:
$\begin{equation} \begin{array}{l} {{\hat {\boldsymbol{Z}}}_{\left. k \right|k - 1}} = {{ {A}}_k}{{\hat {\boldsymbol{Z}}}_{\left. {k - 1} \right|k - 1}}\\ {{\hat {\boldsymbol{Z}}}_{\left. k \right|k}} = {{\hat {\boldsymbol{Z}}}_{\left. k \right|k - 1}} + {\boldsymbol{K}}(k)({Y_k} - {\boldsymbol{C}}{{\hat {\boldsymbol{Z}}}_{\left. k \right|k - 1}})\\ {\boldsymbol{K}}(k) = {{ {P}}_{\left. k \right|k - 1}}{{\boldsymbol{C}}^{\rm{T}}}{[{\boldsymbol{C}}{P_{k|k-1}}{{\boldsymbol{C}}^{\rm{T}}} + \sigma _\varepsilon ^2]^{ - 1}}\\ {{ {P}}_{\left. k \right|k - 1}} = {{ {A}}_k}{{ {P}}_{k - 1|k - 1}}{ {A}}_k^{\rm{T}} + {{ {Q}}_k} \end{array} \end{equation}$
(21) 协方差更新:
$\begin{equation} {{ {P}}_{\left. k \right|k}} = {{ {P}}_{\left. k \right|k - 1}} - {\boldsymbol{K}}(k){\boldsymbol{C}}{{ {P}}_{\left. k \right|k - 1}} \end{equation}$
(22) 初始值为,
按照Kalman滤波的线性高斯本质, 基于${{\boldsymbol{Y}}_{1:k}}$的${{\boldsymbol{Z}}_k}$的后验PDF是双高斯分布, 即${{\boldsymbol{Z}}_k}\sim {\rm N}({\hat {\boldsymbol{Z}}_{\left. k \right|k}}, {{ {P}}_{\left. k \right|k}})$.此时$X_k$和a在$t_k$时刻的后验估计是相关的, 这与确定性参数的情况明显不同.根据双高斯变量性质, 有:
$\begin{equation} \left. {{a_k}} \right|{{\boldsymbol{Y}}_{1:k}} \sim {\rm N}({\hat a_{k|k}}, \kappa _{a, k}^2) \end{equation}$
(23) $\begin{equation} \left. {{X_k}} \right|{{\boldsymbol{Y}}_{1:k}} \sim {\rm N}({\hat X_{\left. k \right|k}}, \kappa _{x, k}^2) \end{equation}$
(24) $\begin{equation} \left. {{X_k}} \right|{a_k}, {{\boldsymbol{Z}}_{1:k}}\sim {\rm N}({\mu _{\left. {{X_k}} \right|a, k}}, \sigma _{\left. {{X_k}} \right|a, k}^2) \end{equation}$
(25) 其中
$\begin{equation} {\mu _{\left. {{X_k}} \right|a, k}} = {\hat X_{\left. k \right|k}} + \frac{{\kappa _{c, k}^2}}{{\kappa _{a, k}^2}}({a_k} - {\hat a_{\left. k \right|k}}) \end{equation}$
(26) $\begin{equation} \sigma _{\left. {{X_k}} \right|a, k}^2 = \kappa _{x, k}^2 - \frac{{\kappa _{c, k}^4}}{{\kappa _{a, k}^2}} \end{equation}$
(27) 现在, 回到计算测量不确定和个体差异下的剩余寿命估计的概率密度函数${f_{\left. {{L_k}} \right|{{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{{\boldsymbol{Y}}_{1:k}})$的问题.基于全概率公式, 有
$\begin{align} &{f_{\left. {{L_k}} \right|{{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{{\boldsymbol{Y}}_{1:k}})= \nonumber \\ & \int_{ - \infty }^{ + \infty } {{f_{\left. {{L_k}} \right|{z_k}, {{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{{\pmb Z}_k}, {{\boldsymbol{Y}}_{1:k}})p(\left. {{{\pmb Z}_k}} \right|{{\boldsymbol{Y}}_{1:k}}){\rm{d}}{{\pmb Z}_k}}= \nonumber \\ & {\textrm{E}_{\left. {{a_k}} \right|{{\boldsymbol{Y}}_{1:k}}}}\big[ {\textrm{E}_{\left. {{X_k}} \right|{a_k}, {{\boldsymbol{Y}}_{1:k}}}} [{f_{\left. {{L_k}} \right|{a_k}, {X_k}, {{\boldsymbol{Y}}_{1:k}}}}\times\nonumber \\ &(\left. {{l_k}} \right|{a_k}, {X_k}, {{\boldsymbol{Y}}_{1:k}})] \big] \end{align}$
(28) 基于以上结果和引理2、引理3, 对${f_{\left. {{L_k}} \right|{{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{{\boldsymbol{Y}}_{1:k}})$可得以下结论.
定理 2. 根据剩余寿命的定义式(4), 对于式(1) 中退化过程, 基于测量数据${{\boldsymbol{Y}}_{1:k}}$, 同时考虑不确定测量和个体差异时, 有式(29) 成立.其中${w_{1, k}}$, ${w_{2, k}}$, ${A_k}$, ${B_k}$, ${C_k}$由式(30)~(34) 给出.
$\begin{array}{l} {f_{\left. {{L_k}} \right|{{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{{\boldsymbol{Y}}_{1:k}}) = {{\rm E}_{{a_k}{\rm{|}}{{\boldsymbol{Y}}_{1:k}}}}\left[{{{\rm E}_{\left. {{X_k}} \right|{a_k}, {{\boldsymbol{Y}}_{1:k}}}}[{f_{\left. {{L_k}} \right|{a_k}, {X_k}, {{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{a_k}, {X_k}, {{\boldsymbol{Y}}_{1:k}})]} \right]\cong\nonumber \\ \frac{1}{{{C_k}\sqrt {2\pi \left( {B_k^2\kappa _{a, k}^2 + {C_k}} \right)} }}\left( {{\omega _{1, k}} - \frac{{{\omega _{2, k}}{A_k}\kappa _{a, k}^2{B_k} + {C_k}{A_k}{{\hat a}_k}}}{{{C_k} + B_k^2\kappa _{a, k}^2}}} \right) \times \exp \left[{-\frac{{{{\left( {(w-{{\hat X}_{\left. k \right|k}}-\eta ({l_k}){{\hat a}_k})} \right)}^2}}}{{2({C_k} + B_k^2\kappa _{a, k}^2)}}} \right] \end{array}$
(29) $\begin{equation} {w_{1, k}} = (w - {\hat X_{\left. k \right|k}} + \frac{{\kappa _{c, k}^2}}{{\kappa _{a, k}^2}}{\hat a_{\left. k \right|k}})\sigma _B^2 \end{equation}$
(30) $\begin{equation} {w_{2, k}} = w - {\hat X_{\left. k \right|k}} + \frac{{\kappa _{c, k}^2}}{{\kappa _{a, k}^2}}{\hat a_{\left. k \right|k}} \end{equation}$
(31) $\begin{equation} {A_k} = \frac{{\kappa _{c, k}^2}}{{\kappa _{a, k}^2}}\sigma _B^2 + [{({t_k} + {l_k})^b}-t_k^b]\sigma _B^2 + {l_k}b{({t_k} + {l_k})^{b - 1}}\sigma _B^2 - b{({t_k} + {l_k})^{b - 1}}\sigma _{\left. {{X_k}} \right|a, k}^2 \end{equation}$
(32) $\begin{equation} {B_k} = {({t_k} + {l_k})^b} - t_k^b + \frac{{\kappa _{c, k}^2}}{{\kappa _{a, k}^2}} \end{equation}$
(33) $\begin{equation} {C_k} = \sigma _{\left. {{X_k}} \right|a, k}^2 + \sigma _B^2{l_k} \end{equation}$
(34) 证明. 首先, 由定理1和引理3可得
$\begin{align} &{f_{\left. {{L_k}} \right|{{\bf{\theta }}_{2, k}}, {X_k}, {{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{a_k}, {X_k}, {{\boldsymbol{Y}}_{1:k}})=\nonumber\\ &\qquad {f_{\left. {{L_k}} \right|{{\bf{\theta }}_{2, k}}, {X_k}}}(\left. {{l_k}} \right|{a_k}, {X_k})\cong\nonumber \\ &\qquad \frac{{{w_k} - {a_k}(\eta ({l_k}) - b{l_k}{{({l_k} + {t_k})}^{b - 1}})}}{{{\sigma _B}\sqrt {2\pi l_k^3} }}\times\nonumber \\ &\qquad \exp \left[{-\frac{{{{\left( {{w_k}-{a_k}\eta ({l_k})} \right)}^2}}}{{2\sigma _B^2t}}} \right] \end{align}$
(35) 其中$\eta ({l_k})={({l_k} + {t_k})^b} -t_k^b$, ${w_k}=w -{X_k}$.进一步, 由于$\left. {{X_k}} \right|{a_k}, {{\boldsymbol{Y}}_{1:k}} \sim {\rm N}({\mu _{\left. {{X_k}} \right|a, k}}, \sigma _{\left. {{X_k}} \right|a, k}^2)$, 可得式(36), 其中$w_k^ *=w -{a_k}[{({t_k} + {l_k})^b}-t_k^b]$, ${\mu _{\left. {{X_k}} \right|a, k}}$和$\sigma _{\left. {{X_k}} \right|a, k}^2$已由式(26) 和(27) 给出, 且${\mu _{\left. {{X_k}} \right|a, k}}$是${a_k}$的函数.
$\begin{align} &{{\rm E}_{\left. {{X_k}} \right|{a_k}, {{\boldsymbol{Y}}_{1:k}}}}[{f_{\left. {{L_k}} \right|{a_k}, {X_k}, {{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{a_k}, {X_k}, {{\boldsymbol{Y}}_{1:k}})]\cong\nonumber\\ &\qquad \dfrac{1}{{{\sigma _B}\sqrt {2\pi {l_k}^3} }}{{\rm E}_{\left. {{X_k}} \right|a, {{\boldsymbol{Y}}_{1:k}}}}\left\{ {\left( {w_k^ * + {l_k}ab{{({t_k} + {l_k})}^{b - 1}} - {X_k}} \right) \times \exp\left[{-\dfrac{{{{(w_k^ *-{X_k})}^2}}}{{2{l_k}{\sigma _B}^2}}} \right]} \right\}=\nonumber\\ &\qquad \dfrac{1}{{\sqrt {2\pi l_k^2(\sigma _{\left. {{X_k}} \right|a, k}^2 + \sigma _B^2{l_k})} }}\left( {{w^ * } + {a_k}b{l_k}{{({l_k} + {t_k})}^{b - 1}} - \dfrac{{\sigma _{\left. {{X_k}} \right|a, k}^2w_k^ * + \sigma _B^2{l_k}{\mu _{\left. {{X_k}} \right|a, k}}}}{{\sigma _{\left. {{X_k}} \right|a, k}^2 + \sigma _B^2{l_k}}}} \right)\times\nonumber\\ &\qquad \exp \left( { - \dfrac{{{{\left( {w_k^ * - {\mu _{\left. {{X_k}} \right|a, k}}} \right)}^2}}}{{2(\sigma _{\left. {{X_k}} \right|a, k}^2 + \sigma _B^2{l_k})}}} \right) \end{align}$
(36) $\begin{array}{l} {f_{\left. {{L_k}} \right|{{\boldsymbol{Y}}_{1:k}}}}(\left. {{l_k}} \right|{{\boldsymbol{Y}}_{1:k}}) = {\textrm{E}_{{a_k}|{Y_{1:k}}}}\left[{{\textrm{E}_{\left. {{X_k}} \right|{a_k}, {{\boldsymbol{Y}}_{1:k}}}}[{f_{\left. {{L_k}} \right|{a_k}, {X_k}, {Y_{1:k}}}}(\left. {{l_k}} \right|{a_k}, {X_k}, {{\boldsymbol{Y}}_{1:k}})]} \right] \cong\nonumber\\ \qquad {{\rm E}_{\left. {{a_k}} \right|{{\boldsymbol{Y}}_{1:k}}}}\left[{\frac{1}{{\sqrt {2\pi l_k^2{C_k}} }}\left( {w_k^ * + {a_k}b{l_k}{{({l_k} + {t_k})}^{b-1}}-\dfrac{{\sigma _{\left. {{X_k}} \right|a, k}^2w_k^ * + \sigma _B^2{l_k}{\mu _{\left. {{X_k}} \right|a, k}}}}{{{C_k}}}} \right) \times} \right.\nonumber\\ \qquad \left.{\exp \left( {-\frac{{{{\left( {w_k^ * - {\mu _{\left. {{X_k}} \right|a, k}}} \right)}^2}}}{{2{C_k}}}} \right)} \right]=\nonumber\\ \qquad {{\rm E}_{\left. {{a_k}} \right|{{\boldsymbol{Y}}_{1:k}}}}\left[{\dfrac{{\left( {[w_k^ * + {a_k}b{l_k}{{({l_k} + {t_k})}^{b-1}}]{C_k} -\sigma _{\left. {{X_k}} \right|a, k}^2w_k^ * -\sigma _B^2{l_k}({{\hat X}_{\left. k \right|k}} + \kappa _{c, k}^2\kappa _{a, k}^{ -2}({a_k} - {{\hat a}_{\left. k \right|k}}))} \right)}}{{\sqrt {2\pi l_k^2C_k^3} }}} \right. \times \nonumber\\ \qquad \left. { \exp \left( { - \frac{{{{\left( {w_k^ * - ({{\hat X}_{\left. k \right|k}} + \kappa _{c, k}^2\kappa _{a, k}^{ - 2}({a_k} - {{\hat a}_{\left. k \right|k}}))} \right)}^2}}}{{2{C_k}}}} \right)} \right]=\nonumber\\ \qquad \dfrac{1}{{{C_k}\sqrt {2\pi \left( {B_k^2\kappa _{a, k}^2 + {C_k}} \right)} }}\left( {{\omega _{1, k}} - \dfrac{{{\omega _{2, k}}{A_k}\kappa _{a, k}^2{B_k} + {C_k}{A_k}{{\hat a}_k}}}{{{C_k} + B_k^2\kappa _{a, k}^2}}} \right) \\ \times \exp \left( { - \dfrac{{{{\left( {(w - {{\hat X}_{\left. k \right|k}} - \eta ({l_k}){{\hat a}_k})} \right)}^2}}}{{2({C_k} + B_k^2\kappa _{a, k}^2)}}} \right) \end{array}$
(37) 由式(28) 和$\left. {{a_k}} \right|{{\boldsymbol{Y}}_{1:k}}\, \sim\, {\rm N}(a_{k|k}^2, \kappa _{a, k}^2)$, 令${C_k}=\sigma _{\left. {{X_k}} \right|a, k}^2 + \sigma _B^2{l_k}$, 可得式(37), 其中最后一个等式由引理2导出.
基于以上结果, 随着新的监测数据的获取, 可利用状态空间模型(16) 实现剩余寿命估计的自适应更新.定理2将不确定测量和个体差异都融入了剩余寿命的估计中, 并得到解析解, 如$f_{\left. L_k \right|{\boldsymbol{Y}}_{1:k}}(\left. l_k\right|{\boldsymbol{Y}}_{1:k})$, 同时参数$a_{k|k}$和$\kappa_{a, k}^2$通过Kalman滤波实现了实时自适应更新, 使得对具体系统的寿命估计更有针对性.当用状态空间模型(16) 进行实时估计时, 可采用文献[9, 26]中极大似然估计的方法对模型未知参数${\mu _a}, \sigma _a^2, \sigma _\varepsilon ^2$和$\sigma _B^2$进行初始化估计.
3. 实验研究
本节采用文献[9]中的实际退化数据验证本文所提方法, 并与文献[9]中仅考虑个体差异和文献[25]中仅考虑测量误差的剩余寿命估计方法进行比较.为便于比较不同方法的性能, 采用两种常用的性能测度对不同方法所得结果进行量化比较.第一种性能测度为AIC (Akaike information criterion) 准则[29], 用于比较模型对测量数据的拟合程度.其计算式为
$\begin{equation} \textrm{AIC} = - 2\max \ell + 2p \end{equation}$
(38) 其中$\max \ell $为极大对数似然函数值, p为模型参数的总数目. AIC准则在统计和工程实践中主要用于模型选择, 防止过参数化, 达到模型复杂度和拟合精度之间的平衡, AIC值越小表明模型性能越好.此外, 在各监测时间点, 定义损失函数为实际剩余寿命与估计剩余寿命的期望, 即均方误差(Mean square error, MSE)[30], 具体为
$\begin{equation} \textrm{MSE}{_k} = {\rm E}\left( {{{({L_k} - {{\tilde L}_k})}^2}} \right) \end{equation}$
(39) 其中${\tilde L_k}$表示$t_k$时刻实际剩余寿命, 在$t_k$时刻剩余寿命估计值与实际值之差的期望运算可评估估计的剩余寿命分布, MSE越小表示估计结果越准确.进一步可定义总体均方误差(Total mean square error, TMSE), 为所有测量点剩余寿命估计的MSE之和, 表示为
$\begin{equation} \textrm{TMSE} = \sum\limits_{k = 1}^m {\textrm{MSE}{_k}} \end{equation}$
(40) 其中m为一个测量周期内的所有测量数据数目.
3.1 A2017-T4铝合金疲劳裂纹退化数据
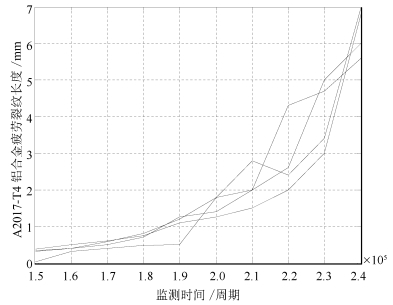
下面对航空航天领域常用的A2017-T4铝合金疲劳裂纹退化数据[9]的研究中, 采用以上两种性能测度评估考虑不同情况下剩余寿命估计的性能.疲劳裂纹的退化数据主要包括4个退化试验在相同旋转周期监测点上退化监测数据, 对每个样本, 其疲劳裂纹的测试时间间隔为每0.1 $\times$ 105个旋转周期, 退化曲线如图 1所示, 预设失效阈值为5.6 mm, 详见文献[9].
从图 1中可以看出, 疲劳裂纹退化数据表现出一定的非线性退化特征, 文献[9]中证明了采用非线性退化模型比用线性退化模型进行剩余寿命估计更具合理性和准确性.这里, 将文献[9]中仅考虑个体差异的情况定义为情况1, 将文献[25]中仅考虑测量误差的情况定义为情况2, 本文所提方法即同时考虑个体差异和测量误差的情况定义为情况3, 为便于和文献[9]中的结果进行比较, 本文按照文献[9]中选择的第三组疲劳裂纹数据进行分析验证, 主要估计结果如表 1所示.
表 1 3种情况下对疲劳裂纹的估计结果Table 1 Comparisons of three degradation models with fatigue-crack growth data$\mu _a$ $\sigma _a$ b ${\sigma _B}$ ${\sigma _\varepsilon }$ log-LF AIC TMSE 情况1 3.9477E-005 8.9347E-006 13.482 1.8977 - -43.1125 94.225 0.0518 情况2 4.9223E-005 - 13.3145 0.5346 0.4907 -37.4882 82.9764 0.0259 情况3 4.9E-003 1.9582E-004 8.1382 0.0114 0.5121 -28.9682 67.9364 0.0063 从表 1的估计结果可以看出, 3种情况下模型参数b均远大于1, 表明了数据的非线性特征.更为重要的是, 按照从情况1到情况3的顺序可以明显发现, log-LF是逐渐增大的, AIC是逐渐减小的, 同样TMSE也是逐渐减小的, 这3个方面的结果都说明情况3的模型明显优于情况2和情况1的模型.为进一步比较3种模型的剩余寿命估计效果, 下面具体分析各监测点剩余寿命估计的PDF、期望和MSE.
图 2展示了各监测点剩余寿命估计的PDF和期望.在图 2中, 实际剩余寿命用圆圈和直线标注, 而估计的平均剩余寿命用星号和直线标注.从图 2中可以看出, 与情况1和情况2相比, 情况3的PDF曲线围绕实际剩余寿命值表现得更加紧致, 表明情况3下估计剩余寿命的不确定性更小.另一方面, 对于剩余寿命的期望值, 虽然情况1在2.1 $\times$ 105周期之前也表现出不错的效果, 但2.1 $\times$ 105周期后估计性能下降, 表现出较大的误差, 而情况3的期望估计值比情况2和情况1的更加精确.
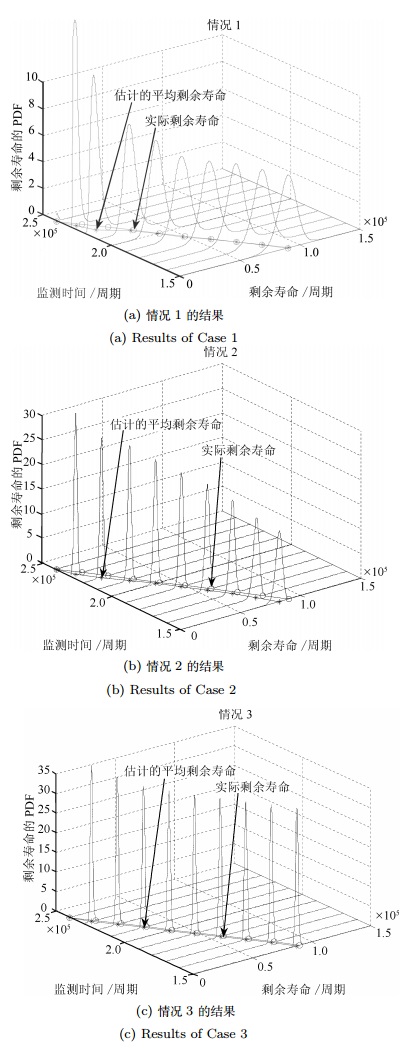 图 2 3种情况下基于疲劳裂纹数据的剩余寿命估计PDF和期望值的比较结果Fig. 2 Comparisons of the PDFs and mean of the RULs for three cases with the fatigue crack data
图 2 3种情况下基于疲劳裂纹数据的剩余寿命估计PDF和期望值的比较结果Fig. 2 Comparisons of the PDFs and mean of the RULs for three cases with the fatigue crack data为便于比较分析, 图 3给出了在2.2 $\times$ 105周期监测点上3种情况下的剩余寿命PDF.从图 3可明显看出在实际剩余寿命为0.2 $\times$ 105周期下, 情况3相比于情况1和情况2具有更加优良的性能.由实际退化数据可知, 退化过程在2.1 $\times$ 105周期后均表现出更强的非线性, 即退化率较之前明显增大.这种情况下, 情况1出现较大的估计误差, 而情况2和情况3表现出更优的性能, 这主要是由于情况2通过卡尔曼滤波对状态进行实时滤波估计, 而情况3同时考虑不确定测量和个体差异, 并通过Kalman滤波对状态和参数进行自适应估计, 表现出更加优良的性能.这种自适应估计的结果如图 4所示.
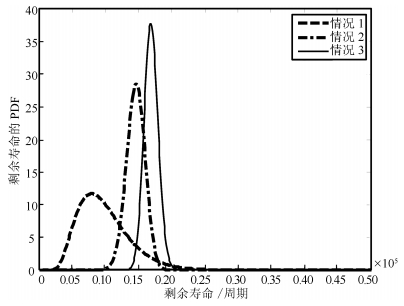 图 3 在第2.2 $\times$ 105周期监测点时3种情况下的剩余寿命PDFFig. 3 PDFs for the three cases at the 2.2 $\times$ 105 cycle
图 3 在第2.2 $\times$ 105周期监测点时3种情况下的剩余寿命PDFFig. 3 PDFs for the three cases at the 2.2 $\times$ 105 cycle从图 4中可以看出, a的后验均值$\mu_{a, k|k}$和后验标准差${\sigma_{a, k}}$可随着测量信号进行自适应调整.与前面分析一致, $\mu_{a, k|k}$在2.1 $\times$ 105周期后随退化状态能够及时跟踪变化, 而${\sigma _{a, k}}$随测量数据的积累不断减小, 表明随机参数a描述的个体差异影响在不断减小, 也就使得估计结果更针对当前被测样本.这种自适应估计的优点可以有效降低由测试样本较少而造成的对$\mu_{a, k|k}$和${\sigma_{a, k}}$的估计误差, 这在实际工程中非常重要.
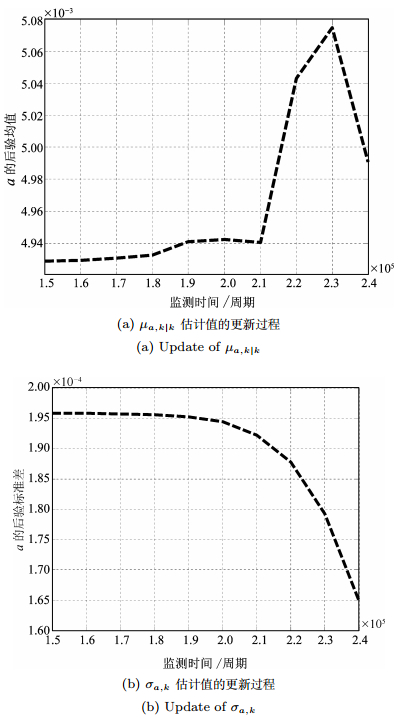 图 4 $\mu _{a, k|k}$和${\sigma _{a, k}}$基于第三组测量数据的更新Fig. 4 Updates of $\mu _{a, k|k}$ and ${\sigma _{a, k}}$ based on the third set of data
图 4 $\mu _{a, k|k}$和${\sigma _{a, k}}$基于第三组测量数据的更新Fig. 4 Updates of $\mu _{a, k|k}$ and ${\sigma _{a, k}}$ based on the third set of data接下来,从MSE的角度对3种情况的估计结果进行比较, 如图 5所示.由图 5可见, 与情况1和情况2相比, 情况3下估计的MSE在整个退化过程中均保持在相对较小的水平上, 情况1和情况2都存在较大波动, 这是由于这两种情况没有同时全面考虑不确定测量和个体差异的结果.相比之下, 情况3有效避免了剩余寿命估计的MSE出现较大的波动, 表现出良好的稳定性, 具体的各监测点定量的MSE值的比较如表 2所示. 图 5和表 2中的结果与前面的分析讨论是一致的, 这进一步支持了本文同时考虑不确定测量和个体差异对非线性随机退化过程进行剩余寿命估计的必要性, 该方法能显著提高退化建模能力和剩余寿命估计的准确性.
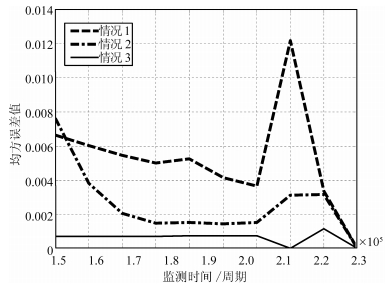 图 5 基于第三组裂纹数据的剩余寿命估计的MSE比较结果Fig. 5 Comparisons for the MSE of the estimated remaining useful life based on the third set of data表 2 3种情况下各状态监测点疲劳裂纹的MSE值Table 2 MSEs of fatigue-crack growth data condition monitoring points for the three cases
图 5 基于第三组裂纹数据的剩余寿命估计的MSE比较结果Fig. 5 Comparisons for the MSE of the estimated remaining useful life based on the third set of data表 2 3种情况下各状态监测点疲劳裂纹的MSE值Table 2 MSEs of fatigue-crack growth data condition monitoring points for the three cases监测点($\times {10^5}$周期) 1.5 1.6 1.7 1.8 1.9 2 2.1 2.2 2.3 情况1 0.0067 0.0060 0.0055 0.0050 0.0053 0.0042 0.0036 0.0122 0.0034 情况2 0.8190 0.7444 0.6603 0.5667 0.4653 0.3655 0.2640 0.1459 0.0449 情况3 0.0076 0.0038 0.0021 0.0015 0.0015 0.0015 0.0015 0.0031 0.0032 3.2 惯导系统陀螺仪漂移退化数据
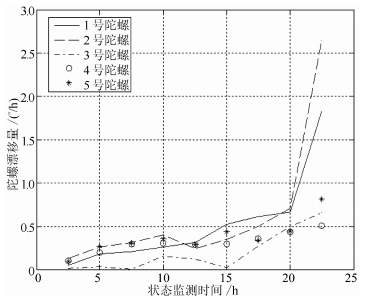
为进一步比较所提方法的有效性, 对广泛应用于航空航天领域的惯导系统陀螺仪的退化数据进行验证, 陀螺漂移退化的监测数据如图 6所示.该数据包括5个同型号惯导系统陀螺仪漂移退化数据, 获取了每个陀螺仪在9个不同监测时间点上的漂移系数数据.按照文献[9]中的实验要求, 设定漂移的阈值为0.6$^\circ $/h, 为便于比较, 这里选择文献[9]所采用的第四组数据进行分析验证.作为比较, 仍将本文提出的方法作为情况3, 将分别仅考虑个体差异和测量误差的情况作为情况1和情况2. 3种情况下对陀螺仪的参数估计结果、AIC值和TMSE见表 3.
表 3 3种情况下对陀螺仪的估计结果Table 3 Comparisons of three degradation models with gyros$\mu _a$ $\sigma _a$ b ${\sigma _B}$ ${\sigma _\varepsilon }$ log-LF AIC TMSE 情况1 6.6895E-021 6.1544E-021 14.8843 0.0668 - 27.6830 -47.3360 66.1468 情况2 1.4625E-013 - 13.3145 0.1563 0.0400 -2.3983 -3.2034 89.5732 情况3 5.2151E-026 4.8076E-026 18.6422 0.0646 0.0253 27.9339 -45.8780 42.8521 从表 3中可以得到与表 1相似的结论, 3种情况下模型参数均远大于1, 表明了数据的非线性特征.需要说明的是, 情况3的log-LF和AIC明显优于情况2, 虽然和情况1相近, 但情况3的TMSE值明显优于情况1和情况2.具体地, 3种情况下各监测点剩余寿命估计的MSE值如图 7所示, 各状态监测时刻的MSE值对比结果如表 4所示.由图 7和表 4可见, 对于3种情况下的MSE, 情况1和情况2不但波动大, 而且各点估计值也较大, 表明估计误差较大, 而情况3明显整体相对稳定, 且各点估计值较小, 表明估计精度明显优于情况2和情况1.这进一步验证了本文提出的同时考虑个体差异和测量不确定性进行剩余寿命估计方法的显著优势.
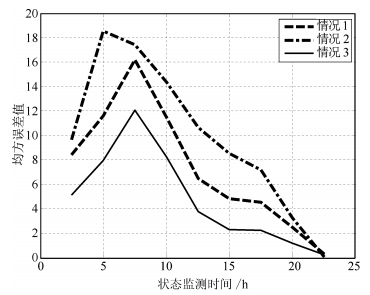 图 7 基于第四组陀螺漂移数据的剩余寿命估计的MSE比较结果Fig. 7 Comparisons for the MSE of the estimated remaining useful life based on the fourth set of gyro data表 4 3种情况下各状态监测点陀螺仪的MSE值Table 4 MSEs of gyros data condition monitoring points for the three cases
图 7 基于第四组陀螺漂移数据的剩余寿命估计的MSE比较结果Fig. 7 Comparisons for the MSE of the estimated remaining useful life based on the fourth set of gyro data表 4 3种情况下各状态监测点陀螺仪的MSE值Table 4 MSEs of gyros data condition monitoring points for the three cases监测点(h) 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 情况1 8.3907 11.5918 16.1759 11.4570 6.4760 4.8352 4.5324 2.4438 情况2 9.6285 18.5416 17.4385 14.3918 10.6622 8.5542 7.1531 3.1990 情况3 5.0858 7.9371 12.0434 8.2163 3.7278 2.2491 2.2328 1.1327 4. 结论
本文主要研究了同时考虑不确定测量和个体差异下的非线性随机退化系统剩余寿命估计问题.首先进行非线性退化过程建模, 然后讨论了同时考虑不确定测量和个体差异下的剩余寿命估计方法, 通过实际退化数据在3种情况下实验结果的比较, 验证了本文提出方法的合理有效性.主要结论如下:
1) 基于扩散过程建立的非线性退化模型, 不仅适用于非线性退化过程, 而且适用于漂移系数为固定值的线性随机退化过程, 所提出的剩余寿命估计方法也同样适用于线性情况.因此本文方法具有一定的一般性.
2) 为了实现对退化模型中未知参数的估计, 采用极大似然估计方法估计出模型各参数初值, 通过建立状态空间模型和Kalman滤波技术实现了对漂移系数的均值和方差的自适应实时估计.
3) 基于疲劳裂纹数据的实验结果表明, 本文提出的同时考虑不确定测量和个体差异情况下的剩余寿命估计结果, 与仅考虑个体差异或不确定测量的剩余寿命估计相比, 具有更好的建模能力, 更小的不确定性和更准确的估计结果.
4) 如何将同时考虑不确定测量和个体差异的非线性随机退化过程剩余寿命估计结果应用到健康管理中, 以提高维护决策效率是需要进一步研究的内容.
总之, 对非线性随机退化过程而言, 本文提出的同时考虑不确定测量和个体差异的退化建模和剩余寿命估计结果, 显著优于现有仅考虑不确定测量或个体差异情况下的剩余寿命估计结果, 具有潜在的工程实用价值.
-

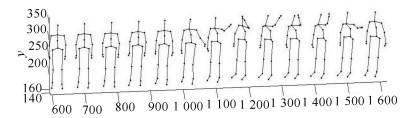
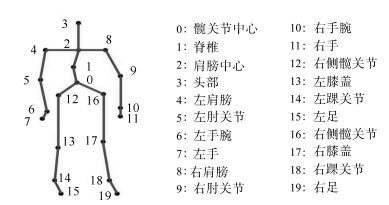
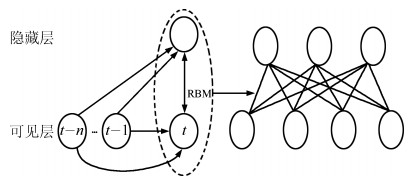
图 11 MSR Action 3D数据库 $AS1_{2}$的混淆矩阵
Fig. 11 Confusion matrix of MSR Action 3D of $AS1_{2}$
表 3 前5帧的识别结果(%)
Table 3 Recognition results of the first 5 sequences (%)
ASl1 AS21 AS31 AS12 AS22 AS32 本文 79.84 79.35 82.93 90.78 92.76 94.66 Yang等[3] 67±1 67±1 74±1 77±1 75±1 82±1  下载: 导出CSV
下载: 导出CSV
表 4 全部实验识别结果(%)
Table 4 All recognition results (%)
1 5 整个动作 ASl1 77.55 79.84 96.67 AS21 78.01 79.35 92.81 AS31 81.60 82.93 96.68 平均 79.05 80.71 95.39 ASl2 89.74 90.78 99.33 AS22 90.78 92.76 97.44 AS32 93.00 94.66 99.87 平均 91.17 92.73 98.88
下载: 导出CSV
表 5 不同阶数的识别时间(ms)
Table 5 Recognition time with different orders (ms)
Action n 0 1 2 3 4 5 6 Horizontal arm wave 4.45 9.78 12.56 14.61 17.21 19.45 23.51 Hammer 3.67 9.89 11.89 14.39 17.12 19.78 22.13 Forward punch 3.79 10.03 12.54 14.48 17.49 20.01 22.56 High throw 3.96 9.92 12.48 14.68 17.73 19.21 22.67 Hand clap 4.13 9.99 12.49 14.63 17.62 19.84 22.78 Bend 4.78 9.79 12.34 14.61 17.94 19.47 21.87 Tennis serve 4.56 9.67 12.52 14.65 17.56 19.49 22.46 Pickup and throw 3.71 9.97 12.67 14.51 17.83 19.92 22.81
下载: 导出CSV
表 6 不同阶数的识别率(%)
Table 6 Recognition rates with different orders (%)
Action n 0 1 2 3 4 5 6 Horizontal arm wave 81.56 85.39 89.12 90.03 91.45 89.97 87.68 Hammer 82.56 86.48 85.34 87.50 86.84 88.10 87.98 Forward punch 73.67 76.45 78.78 79.19 77.87 78.16 78.45 High throw 72.78 73.46 76.98 79.92 79.23 78.89 76.75 Hand clap 87.65 93.78 98.34 98.65 97.85 96.12 96.23 Bend 80.13 81.35 84.56 86.43 86.72 85.97 83.85 Tennis serve 88.74 91.67 92.89 93.67 93.35 92.89 92.54 Pickup and throw 83.81 86.34 86.94 88.34 87.13 87.67 97.56 Average 81.36 84.37 86.62 87.97 87.56 87.22 87.63
下载: 导出CSV
-
[1] (佟丽娜, 侯增广, 彭亮, 王卫群, 陈翼雄, 谭民.基于多路sEMG时序分析的人体运动模式识别方法.自动化学报, 2014, 40(5):810-821) http://www.aas.net.cn/CN/abstract/abstract18349.shtmlTong Li-Na, Hou Zeng-Guang, Peng Liang, Wang Wei-Qun, Chen Yi-Xiong, Tan Min. Multi-channel sEMG time series analysis based human motion recognition method. Acta Automatica Sinica, 2014, 40(5):810-821 http://www.aas.net.cn/CN/abstract/abstract18349.shtml [2] Li W Q, Zhang Z Y, Liu Z C. Action recognition based on a bag of 3D points. In:Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. San Francisco, CA:IEEE, 2010. 9-14 http://www.oalib.com/references/17186320 [3] Yang X D, Zhang C Y, Tian Y L. Recognizing actions using depth motion maps-based histograms of oriented gradients. In:Proceedings of the 20th ACM International Conference on Multimedia. Nara, Japan:ACM, 2012. 1057-1060 http://www.oalib.com/paper/4237135 [4] Ofli F, Chaudhry R, Kurillo G, Vidal R, Bajcsy R. Sequence of the most informative joints (SMIJ):a new representation for human skeletal action recognition. Journal of Visual Communication & Image Representation, 2014, 25(1):24-38 http://cn.bing.com/academic/profile?id=2125073690&encoded=0&v=paper_preview&mkt=zh-cn [5] Theodorakopoulos I, Kastaniotis D, Economou G, Fotopoulos S. Pose-based human action recognition via sparse representation in dissimilarity space. Journal of Visual Communication and Image Representation, 2014, 25(1):12-23 doi: 10.1016/j.jvcir.2013.03.008 [6] (王斌, 王媛媛, 肖文华, 王炜, 张茂军.基于判别稀疏编码视频表示的人体动作识别.机器人, 2012, 34(6):745-750) doi: 10.3724/SP.J.1218.2012.00745Wang Bin, Wang Yuan-Yuan, Xiao Wen-Hua, Wang Wei, Zhang Mao-Jun. Human action recognition based on discriminative sparse coding video representation. Robot, 2012, 34(6):745-750 doi: 10.3724/SP.J.1218.2012.00745 [7] (田国会, 尹建芹, 韩旭, 于静.一种基于关节点信息的人体行为识别新方法.机器人, 2014, 34(3):285-292) http://www.cnki.com.cn/Article/CJFDTOTAL-JQRR201403005.htmTian Guo-Hui, Yin Jian-Qin, Han Xu, Yu Jing. A novel human activity recognition method using joint points information. Robot, 2014, 34(3):285-292 http://www.cnki.com.cn/Article/CJFDTOTAL-JQRR201403005.htm [8] (乔俊飞, 潘广源, 韩红桂.一种连续型深度信念网的设计与应用.自动化学报, 2015, 41(12):2138-2146) http://www.aas.net.cn/CN/Y2015/V41/I12/2138Qiao Jun-Fei, Pan Guang-Yuan, Han Hong-Gui. Design and application of continuous deep belief network. Acta Automatica Sinica, 2015, 41(12):2138-2146 http://www.aas.net.cn/CN/Y2015/V41/I12/2138 [9] Zhao S C, Liu Y B, Han Y H, Hong R C. Pooling the convolutional layers in deep convnets for action recognition[Online], available:http://120.52.73.77/arxiv.org/pdf/1511.02126v1.pdf, November 1, 2015. http://cn.bing.com/academic/profile?id=1969767174&encoded=0&v=paper_preview&mkt=zh-cn [10] Liu C, Xu W S, Wu Q D, Yang G L. Learning motion and content-dependent features with convolutions for action recognition. Multimedia Tools and Applications, 2015, http://dx.doi.org/10.1007/s11042-015-2550-4. [11] Baccouche M, Mamalet F, Wolf C, Garcia C, Baskurt A. Sequential deep learning for human action recognition. Human Behavior Understanding. Berlin:Springer, 2011. 29-39 [12] Lefebvre G, Berlemont S, Mamalet F, Garcia C. BLSTM-RNN based 3d gesture classification. Artificial Neural Networks and Machine Learning. Berlin:Springer, 2013. 381-388 [13] Du Y, Wang W, Wang L. Hierarchical recurrent neural network for skeleton based action recognition. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA:IEEE, 2015. 1110-1118 [14] Taylor G W, Hinton G E, Roweis S. Modeling human motion using binary latent variables. In:Proceedings of Advances in Neural Information Processing Systems. Cambridge, MA:MIT Press, 2007. 1345-1352 [15] Hinton G E, Osindero S. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18:1527-1554 doi: 10.1162/neco.2006.18.7.1527 [16] Bengio Y, Lamblin P, Popovici D, Larochelle H. Personal communications with Will Zou. learning optimization Greedy layerwise training of deep networks. In:Proceedings of Advances in Neural Information Processing Systems. Cambridge, MA:MIT Press, 2007. [17] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088):533-536 doi: 10.1038/323533a0 [18] Hsu E, Pulli K, PopovićJ. Style translation for human motion. ACM Transactions on Graphics, 2005, 24(3):1082-1089 doi: 10.1145/1073204 [19] Xia L, Chen C C, Aggarwal J K. View invariant human action recognition using histograms of 3D joints. In:Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Providence, USA:IEEE, 2012. 20-27 http://www.oalib.com/references/16301407 [20] Ellis C, Masood S Z, Tappen M F, LaViola J J Jr, Sukthankar R. Exploring the trade-off between accuracy and observational latency in action recognition. International Journal of Computer Vision, 2013, 101(3):420-436 doi: 10.1007/s11263-012-0550-7 [21] Chen C, Liu K, Kehtarnavaz N. Real-time human action recognition based on depth motion maps. Journal of Real-Time Image Processing, 2016, 12(1):155-163 doi: 10.1007/s11554-013-0370-1 [22] Gowayyed M A, Torki M, Hussein M E, El-Saban M. Histogram of oriented displacements (HOD):describing trajectories of human joints for action recognition. In:Proceedings of the 2013 International Joint Conference on Artificial Intelligence. Beijing, China, AAAI Press, 2013. 1351-1357 [23] Vemulapalli R, Arrate F, Chellappa R. Human action recognition by representing 3D skeletons as points in a lie group. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA:IEEE, 2014. 588-595 期刊类型引用(21)
1. 郑卫东,熊伟,李晓燕,白培强,林思宇,崔雄华,吕延军,石瑞. 基于VSG-ELM模型的疲劳裂纹扩展剩余寿命预测. 热力发电. 2025(02): 145-153 .  百度学术
百度学术2. 杨家鑫,唐圣金,李良,孙晓艳,祁帅,司小胜. 基于隐含非线性维纳退化过程的剩余寿命预测. 北京航空航天大学学报. 2024(01): 328-340 . 百度学术3. 叶爽怡,扈晓翔,司小胜,袁勃. 采用滑动窗口与克里金插值算法的复杂系统可靠性评估方法. 西安交通大学学报. 2023(04): 171-179 . 百度学术4. 杨家鑫,唐圣金,李良,孙晓艳,祁帅,司小胜. 基于多源信息的隐含非线性维纳退化过程剩余寿命预测. 航空学报. 2023(12): 175-192 . 百度学术5. 高旭东,胡昌华,张建勋,杜党波,喻勇. 基于分数布朗运动过程模型的混合随机退化设备剩余寿命预测. 自动化学报. 2023(09): 1989-2002 . 本站查看6. 张建勋,杜党波,司小胜,胡昌华,郑建飞. 基于最后逃逸时间的随机退化设备寿命预测方法. 自动化学报. 2022(01): 249-260 . 本站查看7. 卢扬,李永丽. 基于实时状态评估与剩余寿命计算的高压断路器预测性维护策略. 高电压技术. 2022(07): 2716-2726 . 百度学术8. 陈云翔,王泽洲,蔡忠义,项华春,王莉莉. 基于EM-EKF与隐含比例退化模型的机载电子设备剩余寿命自适应预测. 电子学报. 2021(03): 500-509 . 百度学术9. CAI Zhongyi,WANG Zezhou,CHEN Yunxiang,GUO Jiansheng,XIANG Huachun. Remaining useful lifetime prediction for equipment based on nonlinear implicit degradation modeling. Journal of Systems Engineering and Electronics. 2020(01): 194-205 . 必应学术10. 蔡忠义,王泽洲,张晓丰,李岩. 隐含非线性退化设备的剩余寿命在线预测方法. 系统工程与电子技术. 2020(06): 1410-1416 . 百度学术11. 王玺,周薇,胡昌华,张建勋,裴洪,刘轩. 基于粒子滤波的非线性退化设备剩余寿命自适应预测. 兵器装备工程学报. 2020(10): 41-47+57 . 百度学术12. 袁烨,张永,丁汉. 工业人工智能的关键技术及其在预测性维护中的应用现状. 自动化学报. 2020(10): 2013-2030 . 本站查看13. 李炜,王成文. 执行器隐含退化下系统寿命预测与延寿方法. 华中科技大学学报(自然科学版). 2020(12): 20-26 . 百度学术14. 苏晓丹. 舰载导弹测发控设备剩余寿命预测概率方法. 舰船科学技术. 2020(21): 161-164 . 百度学术15. 韩敏,李锦冰,许美玲,韩冰. 具有工作状态转换的EIIKF船舶柴油机故障预测. 自动化学报. 2019(05): 920-926 . 本站查看16. 蔡忠义,陈云翔,郭建胜,王泽洲,邓林. 考虑测量误差和随机效应的设备剩余寿命预测. 系统工程与电子技术. 2019(07): 1658-1664 . 百度学术17. 张彬,章立军,罗久飞,张毅,Wang Pingfeng. 基于函数主元分析的多阶段退化过程建模与预测. 仪器仪表学报. 2019(07): 30-38 . 百度学术18. 吴锐,马洁,丁恺林. 航空涡扇引擎剩余使用寿命预测算法研究. 南京理工大学学报. 2019(06): 708-714 . 百度学术19. 喻勇,司小胜,胡昌华,崔忠马,李洪鹏. 数据驱动的可靠性评估与寿命预测研究进展:基于协变量的方法. 自动化学报. 2018(02): 216-227 . 本站查看20. 李军星,王治华,刘成瑞,傅惠民. 随机效应Wiener过程退化可靠性分析方法. 系统工程理论与实践. 2018(09): 2434-2440 . 百度学术21. CAI Zhongyi,CHEN Yunxiang,GUO Jiansheng,ZHANG Qiang,XIANG Huachun. Remaining lifetime prediction for nonlinear degradation device with random effect. Journal of Systems Engineering and Electronics. 2018(05): 1101-1110 . 必应学术其他类型引用(23)
-

 下载:
下载:


计量
- 文章访问数: 3126
- HTML全文浏览量: 454
- PDF下载量: 1189
- 被引次数: 44
