

A Metric Method Using Multidimensional Features for Nonrigid Registration of Medical Images
-
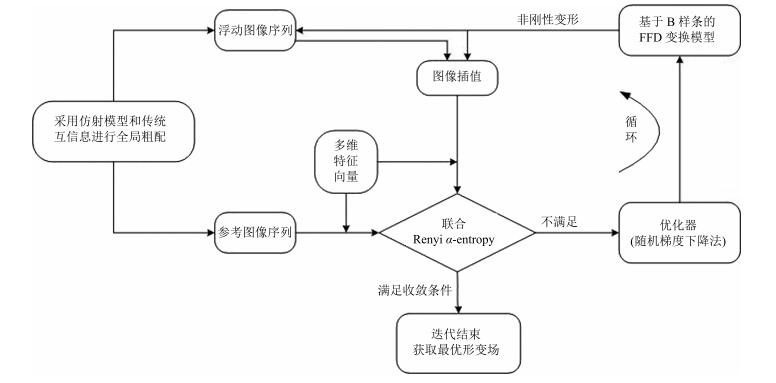
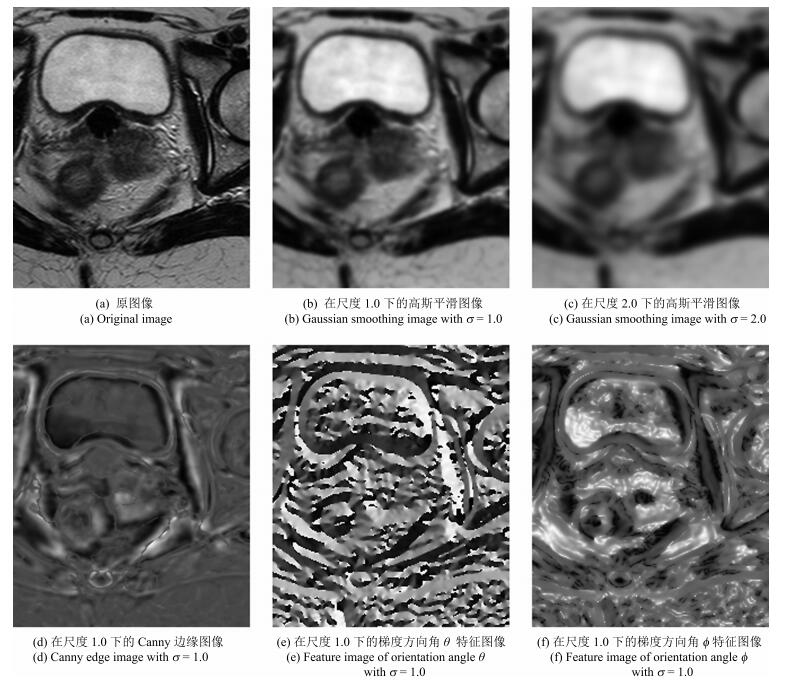
摘要: 医学图像的非刚性配准对于临床的精确诊疗具有重要意义.待配准图像对中目标的大形变和灰度分布呈各向异性给非刚性配准带来困难.本文针对这个问题,提出基于多维特征的联合Renyi α-entropy度量结合全局和局部特征的非刚性配准算法.首先,采用最小距离树构造联合Renyi α-entropy,建立多维特征度量新方法.然后,演绎出新度量准则相对于形变模型参数的梯度解析表达式,采用随机梯度下降法进行参数寻优.最终,将图像的Canny特征和梯度方向特征融入新度量中,实现全局和局部特征相结合的非刚性配准.通过在36对宫颈磁共振(Magnetic resonance,MR)图像上的实验,该方法的配准精度相比较于传统互信息法和互相关系数法有明显提高.这也表明,这种度量新方法能克服因图像局部灰度分布不一致造成的影响,一定程度地减少误匹配,为临床的精确诊疗提供科学依据.
-
关键词:
- 非刚性配准 /
- 联合Renyi α-entropy /
- 最小距离树 /
- 局部特征 /
- 自由形变模型
Abstract: Nonrigid registration of medical images has great significance for accurate diagnosis and therapy in clinic. It is difficult to register the images containing large deformation of object region and data anisotropy. According to this problem, an algorithm of nonrigid registration based on joint Renyi α-entropy is proposed in this paper, which combines global features with local features. Firstly, minimum spanning tree is employed for construction of joint Renyi α-entropy. A new metric is built on multidimensional features. And then, the analytical derivative of the new metric with respect to the parameters of deformation model is derived, in order to find the optima by a stochastic gradient descent method. Finally, Canny feature and gradient orientation feature of images are merged into the new metric, which implements nonrigid registration including global and local features. Experiments are performed on 36 cervical magnetic resonance (MR) image pairs. Compared to the traditional mutual information and correlation coefficient, the registration accuracy is improved significantly. It also manifests that the proposed method is able to overcome the adverse effects of local intensity inhomogeneity, and provides scientific evidence for accurate diagnosis and therapy in clinic, due to reducing mismatch in some degree. -

图 1 膀胱和宫颈放射治疗前后磁共振(Magnetic resonance, MR)图像对比
Fig. 1 Contrast of magnetic resonance (MR) images before and after radiotherapy at the bladder and the cervix

图 4 仿射粗配、互相关系数、互信息、基于图的广义互信息和本文方法的重叠率对比boxplot图(对于每一个解剖结构, 最左边的列显示了仿射粗配的结果, 第2列显示了互相关系数的结果, 第3列显示了互信息的结果, 第4列显示了基于图的广义互信息的结果, 最右边的列显示了本文方法的结果.一个星号表示两种方法重叠率中值在统计上的明显差异.)
Fig. 4 The boxplot of overlap scores using affine matching, CC, MI, GMI and our proposal (For each anatomical structure, the leftmost column shows the result for affine matching. The second column shows the result for CC. The third column shows the result for MI. The fourth column shows the result for GMI. The rightmost column shows the result for our proposal. A star indicates a statistical significant difference of the median overlaps of the two methods.)

图 5 配准结果示例, 参考图像与被形变的浮动图像采用Checkerboard模式融合
Fig. 5 Demonstration of the registration result, and the reference image is combined with the deformed moving image, using a Checkerboard pattern
表 1 所有配准DSC的均值和方差
Table 1 The mean and variance of DSC about all registration results
结构区域 配准方法 DSC值 仿射粗配 0.7618±0.0123 CC 0.8271±0.0056 CTV MI 0.8332±0.0756 GMI 0.8460±0.0706 本文方法 0.8462±0.0684 仿射粗配 0.6756±0.0198 CC 0.7386±0.0200 Bladder MI 0.7375±0.1362 GMI 0.7697±0.1332 本文方法 0.7800±0.1313 仿射粗配 0.6861±0.0083 CC 0.7338±0.0042 Rectum MI 0.7410±0.0673 GMI 0.7566±0.0627 本文方法 0.7680±0.0577  下载: 导出CSV
下载: 导出CSV
-
[1] Savage N. Technology: multiple exposure. Nature, 2013, 502(7473): S90-S91 doi: 10.1038/502S90a [2] Sotiras A, Davatzikos C, Paragios N. Deformable medical image registration: a survey. IEEE Transactions on Medical Imaging, 2013, 32(7): 1153-1190 doi: 10.1109/TMI.2013.2265603 [3] Schmidt-Richberg A, Werner R, Handels H, Ehrhardt J. Estimation of slipping organ motion by registration with direction-dependent regularization. Medical Image Analysis, 2012, 16(1): 150-159 doi: 10.1016/j.media.2011.06.007 [4] 张桂梅, 曹红洋, 储王君, 曾接贤.基于Nyström低阶近似和谱特征的图像非刚性配准.自动化学报, 2015, 41(2): 429-438 http://www.aas.net.cn/CN/abstract/abstract18621.shtmlZhang Gui-Mei, Cao Hong-Yang, Chu Jun, Zeng Jie-Xian. Non-rigid image registration based on low-rank Nyström approximation and spectral feature. Acta Automatica Sinica, 2015, 41(2): 429-438 http://www.aas.net.cn/CN/abstract/abstract18621.shtml [5] 周斌, 宋晓, 黄晓阳, 王博亮.联合直方图的刚性配准方法及其在肝脏CT图像配准中的应用.厦门大学学报(自然科学版), 2015, 54(3): 397-403 http://www.cnki.com.cn/Article/CJFDTOTAL-XDZK201503019.htmZhou Bin, Song Xiao, Huang Xiao-Yang, Wang Bo-Liang.A rigid registration method based on joint distribution histogram and its application on liver CT images. Journal of Xiamen University (Natural Science), 2015, 54(3): 397-403 http://www.cnki.com.cn/Article/CJFDTOTAL-XDZK201503019.htm [6] 夏威, 高欣, 王雷, 周志勇, 张冉.基于点集与互信息的肺部CT图像三维弹性配准算法.江苏大学学报(自然科学版), 2014, 35(5):558-563 http://www.cnki.com.cn/Article/CJFDTOTAL-JSLG201405012.htmXia Wei, Gao Xin, Wang Lei, Zhou Zhi-Yong, Zhang Ran. 3D deformable registration algorithm of CT lung images based on point set and mutual information. Journal of Jiangsu University (Natural Science Edition), 2014, 35(5): 558-563 http://www.cnki.com.cn/Article/CJFDTOTAL-JSLG201405012.htm [7] Cachier P, Bardinet E, Dormont D, Pennec X, Ayache N. Iconic feature based nonrigid registration: the PASHA algorithm. Computer Vision and Image Understanding, 2003, 89(2-3): 272-298 doi: 10.1016/S1077-3142(03)00002-X [8] Mellor M, Brady M. Phase mutual information as a similarity measure for registration. Medical Image Analysis, 2005, 9(4): 330-343 doi: 10.1016/j.media.2005.01.002 [9] Loeckx D, Slagmolen P, Maes F, Vandermeulen D, Suetens P. Nonrigid image registration using conditional mutual information. IEEE Transactions on Medical Imaging, 2010, 29(1): 19-29 doi: 10.1109/TMI.2009.2021843 [10] Neemuchwala H, Hero A, Carson P. Image matching using alpha-entropy measures and entropic graphs. Signal Processing, 2005, 85(2): 277-296 doi: 10.1016/j.sigpro.2004.10.002 [11] Staring M, van der Heide U A, Klein S, Viergever M A, Pluim J P W. Registration of cervical MRI using multifeature mutual information. IEEE Transactions on Medical Imaging, 2009, 28(9): 1412-1421 doi: 10.1109/TMI.2009.2016560 [12] Rivaz H, Karimaghaloo Z, Collins D L. Self-similarity weighted mutual information: a new nonrigid image registration metric. Medical Image Analysis, 2014, 18(2): 343-358 doi: 10.1016/j.media.2013.12.003 [13] 冯兆美, 党军, 崔崤山尧, 焦阳.基于B样条自由形变三维医学图像非刚性配准研究.影像科学与光化学, 2014, 32(2): 200-208 http://www.cnki.com.cn/Article/CJFDTOTAL-GKGH201402009.htmFeng Zhao-Mei, Dang Jun, Cui Xiao-Yao, Jiao Yang. Bspline free-form deformation based 3-D non-rigid registration of medical images. Imaging Science and Photochemistry, 2014, 32(2): 200-208 http://www.cnki.com.cn/Article/CJFDTOTAL-GKGH201402009.htm [14] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91-110 doi: 10.1023/B:VISI.0000029664.99615.94 [15] Bay H, Tuytelaars T, van Gool L. SURF: speeded up robust features. In: Proceedings of the 9th European Conference on Computer Vision. Graz, Austria: Springer, 2006. 404-417 [16] Tola E, Lepetit V, Fua P. DAISY: an efficient dense descriptor applied to wide-baseline stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(5):815-830 doi: 10.1109/TPAMI.2009.77 [17] Canny J. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986, PAMI-8(6): 679-698 doi: 10.1109/TPAMI.1986.4767851 [18] Neemuchwala H F, Hero A O. Image registration in high dimensional feature space. In: Proceedings of the 2005 SPIE 5674, Computational Imaging III. San Jose, CA: SPIE, 2005. 99-113 [19] Sabuncu M R, Ramadge P J. Using spanning graphs for efficient image registration. IEEE Transactions on Image Processing, 2008, 17(5): 788-797 doi: 10.1109/TIP.2008.918951 [20] Hero A O, Ma B, Michel O J J, Gorman J. Applications of entropic spanning graphs. IEEE Signal Processing Magazine, 2002, 19(5): 85-95 doi: 10.1109/MSP.2002.1028355 [21] Klein S, Staring M, Pluim J P W. Evaluation of optimization methods for nonrigid medical image registration using mutual information and B-splines. IEEE Transactions on Image Processing, 2007, 16(12): 2879-2890 doi: 10.1109/TIP.2007.909412 [22] Klein S, Staring M, Murphy K, Viergever M A, Pluim J P W. Elastix: a toolbox for intensity-based medical image registration. IEEE Transactions on Medical Imaging, 2010, 29(1): 196-205 doi: 10.1109/TMI.2009.2035616 [23] Ibanez L, Schroeder W, Ng L, Cates J. The ITK software guide version 2.4 [Online], available: http://www.itk.org, September16, 2014 [24] [24 Dice L R. Measures of the amount of ecologic association between species. Ecology, 1945, 26(3): 297-302 doi: 10.2307/1932409 [25] Wilcoxon F. Individual comparisons by ranking methods.Biometrics Bulletin, 1945, 1(6): 80-83 doi: 10.2307/3001968 期刊类型引用(29)
1. 李倩,聂简,黄鸿殿,孔庆宇,奔粤阳. 基于大脑海马认知机理的主从式AUV协同定位方法. 中国惯性技术学报. 2024(01): 27-33 .  百度学术
百度学术2. 游雄,李科,田江鹏,杨剑,余岸竹,贾奋励. 机器地图信息加工模型. 武汉大学学报(信息科学版). 2024(04): 516-526 . 百度学术3. 高昊,王仁茂. 基于类脑仿生的环境感知技术. 舰船电子对抗. 2024(05): 42-46+55 . 百度学术4. 陈荟慧,钟委钊. 基于人机协作的高质量城市图像采集方法. 应用科学学报. 2023(05): 801-814 . 百度学术5. 朱祥维,沈丹,肖凯,马岳鑫,廖祥,古富强,余芳文,高柯夫,刘经南. 类脑导航的机理、算法、实现与展望. 航空学报. 2023(19): 6-38 . 百度学术6. 于乃功,廖诣深. 基于鼠脑内嗅—海马认知机制的移动机器人空间定位模型. 生物医学工程学杂志. 2022(02): 217-227 . 百度学术7. 刘溢,阳加远,张驰. 一种基于RTX的移动机器人实时控制平台. 电子技术与软件工程. 2022(08): 169-172 . 百度学术8. 于子航,王改云. 基于路径积分强化的机器人目标导向运动控制. 计算机仿真. 2022(07): 412-415+516 . 百度学术9. 董卫华,刘毅龙,黑巧松,杨天宇. 泛地图空间认知理论与方法研究框架. 武汉大学学报(信息科学版). 2022(12): 2007-2014 . 百度学术10. 阮晓钢,李鹏,朱晓庆,刘鹏飞. 基于目标导向行为和空间拓扑记忆的视觉导航方法. 计算机学报. 2021(03): 594-608 . 百度学术11. 赵辰豪,吴德伟,韩昆,代传金. 无环境信息下多尺度网格细胞群空间表征模型. 系统工程与电子技术. 2021(03): 814-822 . 百度学术12. 阮晓钢,柴洁,武悦,张晓平,黄静. 基于海马体位置细胞的认知地图构建与导航. 自动化学报. 2021(03): 666-677 . 本站查看13. 冀俊忠,刘金铎,邹爱笑,杨翠翠. 一种融合多源信息的脑效应连接网络蚁群学习算法. 自动化学报. 2021(04): 864-881 . 本站查看14. 万刚,武易天. 地图空间认知的数学基础. 测绘学报. 2021(06): 726-738 . 百度学术15. 洪涛,史涛,任红格. 一种改进型RatSLAM算法构建认知地图的研究. 现代计算机. 2021(21): 47-52 . 百度学术16. 韩昆,吴德伟,来磊. 类脑导航中基于差分Hebbian学习的网格细胞构建模型. 系统工程与电子技术. 2020(03): 674-679 . 百度学术17. 黄宜庆,王正刚,王徽,葛愿. 基于边缘梯度算法的多移动机器人协作地图构建. 信息与控制. 2020(01): 62-68 . 百度学术18. 于乃功,廖诣深,郑相国. 一种基于海马位置细胞选择机制的空间认知模型. 生物医学工程学杂志. 2020(01): 27-37 . 百度学术19. 胡小平,毛军,范晨,张礼廉,何晓峰,韩国良,范颖. 仿生导航技术综述. 导航定位与授时. 2020(04): 1-10 . 百度学术20. 于乃功,冯慧,廖诣深,郑相国. 一种基于感知速度与感知角度的网格野计算模型. 生物医学工程学杂志. 2020(05): 863-874 . 百度学术21. 晁丽君,熊智,杨闯,华冰,王雅婷,刘建业. 无人飞行器三维类脑SLAM自主导航方法. 飞控与探测. 2020(05): 35-43 . 百度学术22. 张孝伍. 图上的概率分布及位置方向信息的表征方法. 青岛理工大学学报. 2019(01): 113-121 . 百度学术23. 方略,何洪军. 基于鼠脑海马位置细胞与Q学习面向目标导航. 生物信息学. 2019(01): 31-38 . 百度学术24. 王均,凌有铸,王静. 基于特征融合的仿生SLAM算法研究. 安徽工程大学学报. 2019(02): 26-33 . 百度学术25. 刘建业,杨闯,熊智,赖际舟,熊骏. 无人机类脑吸引子神经网络导航技术. 导航定位与授时. 2019(05): 52-60 . 百度学术26. 韩昆,吴德伟,来磊,杨林. 自主导航条件下网格细胞放电模型. 电子科技大学学报. 2019(05): 711-716 . 百度学术27. 丛明,邹强,刘冬,杜宇. 定位细胞认知机理启发的机器人导航研究综述. 机械工程学报. 2019(23): 1-12 . 百度学术28. 邹强,丛明,刘冬,杜宇. 仿鼠脑海马的机器人地图构建与路径规划方法. 华中科技大学学报(自然科学版). 2018(12): 83-88 . 百度学术29. 吴德伟,何晶,韩昆,李卉. 无人作战平台认知导航及其类脑实现思想. 空军工程大学学报(自然科学版). 2018(06): 33-38 . 百度学术其他类型引用(29)
-

计量
- 文章访问数: 2082
- HTML全文浏览量: 487
- PDF下载量: 1225
- 被引次数: 58
