

Large-scale Image Retrieval Based on a Fusion of Gravity Aware Orientation Information
-
摘要: 海量图像检索算法的核心问题是如何对特征进行有效的编码以及快速的检索.局部集聚向量描述(Vector of locally aggregated descriptors,VLAD)算法因其精确的编码方式以及较低的特征维度,取得了良好的检索性能.然而VLAD算法在编码过程中并没有考虑到局部特征的角度信息,VLAD编码向量维度依然较高,无法支持实时的海量图像检索.本文提出一种在VLAD编码框架中融合重力信息的角度编码方法以及适用于海量图像的角度乘积量化快速检索方法.在特征编码阶段,利用前端移动设备采集的重力信息实现融合特征角度的特征编码方法.在最近邻检索阶段将角度分区与乘积量化子分区相结合,采用改进的角度乘积量化进行快速近似最近邻检索.另外本文提出的基于角度编码的图像检索算法可适用于主流的词袋模型及其变种算法等框架.在GPS及重力信息标注的北京地标建筑(Beijing landmark)数据库、Holidays数据库以及SUN397数据库中进行测试,实验结果表明本文算法能够充分利用匹配特征在描述符以及几何空间的相似性,相比传统的VLAD以及协变局部集聚向量描述符(Covariant vector of locally aggregated descriptors,CVLAD)算法精度有明显提升.Abstract: Large scale image retrieval has focused on effective feature coding and efficient searching. Vector of locally aggregated descriptors (VLAD) has achieved great retrieval performance as with its exact coding method and relatively low dimension. However, orientation information of features is ignored in coding step and feature dimension is not suitable for large scale image retrieval. In this paper, a gravity-aware oriented coding and oriented product quantization method based on traditional VLAD framework is proposed, which is efficient and effective. In feature coding step, gravity sensors built-in the mobile devices can be used for feature coding as with orientation information. In vector indexing step, oriented product quantization which combines orientation bins and product quantization bins is used for approximate nearest neighborhood search. Our method can be adapted to any popular retrieval frameworks, including bag-of-words and its variants. Experimental results on collected GPS and gravity-tagged Beijing landmark dataset, Holidays dataset and SUN397 dataset demonstrate that the approach can make full use of the similarity of matching pairs in descriptor space as well as in geometric space and improve the mobile visual search accuracy a lot when compared with VLAD and CVLAD.
-

图 1 融合重力信息和特征角度信息的海量图像检索框架
Fig. 1 The framework of large-scale image retrieval based on a fusion of gravity aware orientation information
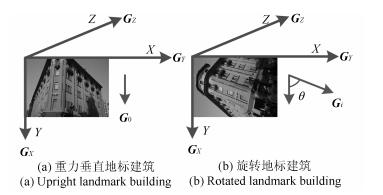
图 2 不同拍摄角度的地标建筑及对应重力信息
Fig. 2 The landmark building with different viewing angles and corresponding gravity information
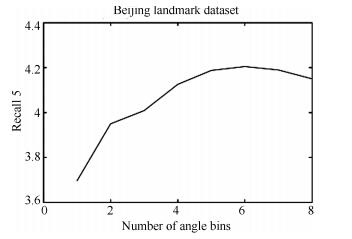
图 6 Oriented coding检索精度与分区数目关系
Fig. 6 The relationship of oriented coding retrieval accuracy and partition number
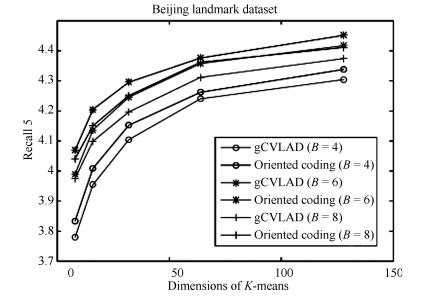
图 7 Oriented coding与重力版本CVLAD方法检索精度对比
Fig. 7 Comparison of retrieval accuracy with oriented coding and gCVLAD

图 8 PCA降维后Oriented coding检索算法精度
Fig. 8 The retrieval accuracy of oriented coding after PCA
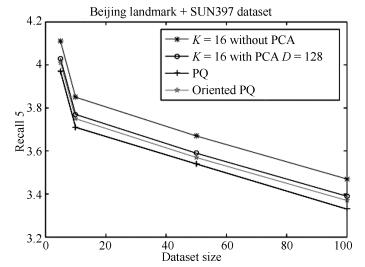
图 9 海量图像最近邻检索方法精度对比
Fig. 9 Comparison of retrieval accuracy with different ANN methods
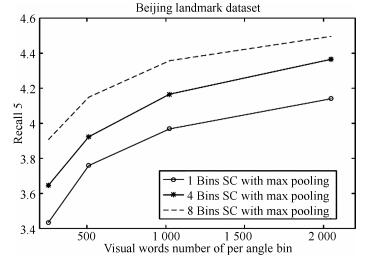
图 10 基于稀疏编码框架的Oriented coding方法检索精度
Fig. 10 The retrieval accuracy of oriented coding based on sparse coding framework
表 1 Holidays数据库检索精度(mAP)
Table 1 The retrieval accuracy of Holidays dataset (mAP)
码书大小 K=8 K=16 K=32 K=64 Holidays Rotated Holidays Rotated Holidays Rotated Holidays Rotated VLAD 0.512 0.515 0.534 0.542 0.551 0.559 0.579 0.587 VLAD+ 0.560 0.564 0.581 0.586 0.597 0.605 0.613 0.622 CVLAD 0.658 0.687 0.663 0.694 0.683 0.709 0.697 0.719 Oriented coding \ 0.709 \ 0.716 \ 0.728 \ 0.736  下载: 导出CSV
下载: 导出CSV
表 2 海量检索时间消耗(ms)
Table 2 Time consuming of image retrieval (ms)
数据库大小 10 KB 100 KB PCA 62.1 671.3 PQ 22.7 104.2 Oriented PQ 24.3 108.5
下载: 导出CSV
-
[1] Sivic J, Zisserman A. Video Google:a text retrieval approach to object matching in videos. In:Proceedings of the 9th IEEE International Conference on Computer Vision. Nice, France:IEEE, 2003. 1470-1477 http://www.oalib.com/references/16296555 [2] Perronnin F, Liu Y, Sánchez J, Poirier H. Large-scale image retrieval with compressed Fisher vectors. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA:IEEE, 2010. 3384-3391 [3] Ge T Z, Ke Q F, Sun J. Sparse-coded features for image retrieval. In:Proceedings of the 24th British Machine Vision Conference. British:British Machine Vision, 2013. 1-8 [4] Jégou H, Perronnin F, Douze M, Sánchez J, Pérez P, Schmid C. Aggregating local image descriptors into compact codes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(9):1704-1716 doi: 10.1109/TPAMI.2011.235 [5] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2):91-110 doi: 10.1023/B:VISI.0000029664.99615.94 [6] Chum O, Philbin J, Sivic J, Isard M, Zisserman A. Total recall:automatic query expansion with a generative feature model for object retrieval. In:Proceedings of the 11th IEEE International Conference on Computer Vision. Rio de Janeiro, Brazil:IEEE, 2007. 1-8 [7] Jegou H, Douze M, Schmid C. Hamming embedding and weak geometric consistency for large scale image search. In:Proceedings of the 10th European Conference on Computer Vision. Berlin, Heidelberg:Springer, 2008. 304-317 [8] Zhao W L, Jégou H, Gravier G. Oriented pooling for dense and non-dense rotation-invariant features. In:Proceedings of the 24th British Machine Vision Conference. British:British Machine Vision, 2013. 1-8 [9] Tolias G, Furon T, Jégou H. Orientation covariant aggregation of local descriptors with embeddings. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer, 2014. 382-397 [10] Wang Z X, Di W, Bhardwaj A, Jagadeesh V, Piramuthu R. Geometric VLAD for large scale image search. In:Proceedings of the 31th International Conference on Machine Learning. Beijing, China, 2014. 134-141 [11] Kurz D, Ben H S. Inertial sensor-aligned visual feature descriptors. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA:IEEE, 2011. 161-166 https://www.computer.org/csdl/proceedings/cvpr/2011/0394/00/index.html [12] Guan T, He Y F, Gao J, Yang J Z, Yu J Q. On-device mobile visual location recognition by integrating vision and inertial sensors. IEEE Transactions on Multimedia, 2013, 15(7):1688-1699 doi: 10.1109/TMM.2013.2265674 [13] Jégou H, Chum O. Negative evidences and co-occurences in image retrieval:the benefit of PCA and whitening. In:Proceedings of the 12th European Conference on Computer Vision. Florence, Italy:Springer, 2012. 774-787 [14] Paulevé L, Jégou H, Amsaleg L. Locality sensitive hashing:a comparison of hash function types and querying mechanisms. Pattern Recognition Letters, 2010, 31(11):1348-1358 doi: 10.1016/j.patrec.2010.04.004 [15] Weiss Y, Torralba A, Fergus R. Spectral hashing. In:Proceedings of Advances in Neural Information Processing Systems. USA:MIT Press, 2009. 1753-1760 [16] Zhang R M, Lin L, Zhang R, Zuo W M, Zhang L. Bit-scalable deep hashing with regularized similarity learning for image retrieval and person re-identification. IEEE Transactions on Image Processing, 2015, 24(12):4766-4779 doi: 10.1109/TIP.2015.2467315 [17] Bentley J L. Multidimensional binary search trees used for associative searching. Communications of the ACM, 1975, 18(9):509-517 doi: 10.1145/361002.361007 [18] Muja M, Lowe D G. Fast approximate nearest neighbors with automatic algorithm configuration. In:Proceedings of the 2009 International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications. Lisboa, Portugal:Thomson Reuters, 2009. 331-340 [19] Jegou H, Douze M, Schmid C. Product quantization for nearest neighbor search. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(1):117-128 doi: 10.1109/TPAMI.2010.57 [20] Ge T, He K, Ke Q, Sun J. Optimized product quantization for approximate nearest neighbor search. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 2946-2953 [21] Bay H, Tuytelaars T, Van Gool L. Surf:speeded up robust features. In:Proceedings of the 9th European Conference on Computer Vision. Graz, Austria:Springer, 2006. 404-417 http://www.oalib.com/references/16892056 [22] 桂振文, 吴廷, 彭欣.一种融合多传感器信息的移动图像识别方法.自动化学报, 2015, 41(8):1394-1404 http://www.aas.net.cn/CN/Y2015/V41/I8/1394Gui Zhen-Wen, Wu Ting, Peng Xin. A novel recognition approach for mobile image fusing inertial sensors. Acta Automatica Sinica, 2015, 41(8):1394-1404 http://www.aas.net.cn/CN/Y2015/V41/I8/1394 [23] 何云峰, 周玲, 于俊清, 徐涛, 管涛.基于局部特征聚合的图像检索方法.计算机学报, 2011, 34(11):2224-2233 doi: 10.3724/SP.J.1016.2011.02224He Yu-Feng, Zhou Ling, Yu Jun-Qing, Xu Tao, Guan Tao. Image retrieval based on locally features aggregating. Chinese Journal of Computers, 2011, 34(11):2224-2233 doi: 10.3724/SP.J.1016.2011.02224 [24] Jegou H, Douze M, Schmid C. On the burstiness of visual elements. In:Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA:IEEE, 2009. 1169-1176 https://www.computer.org/web/csdl/index/-/csdl/proceedings/cvpr/2009/3992/00/index.html [25] Xiao J, Hays J, Ehinger K A, Oliva A, Torralba A. Sun database:large-scale scene recognition from abbey to zoo. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA:IEEE, 2010. 3485-3492s [26] Arandjelovic R, Zisserman A. All about VLAD. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA:IEEE, 2013. 1578-1585 [27] 汤红忠, 张小刚, 陈华, 程炜, 唐美玲.带边界条件约束的非相干字典学习方法及其稀疏表示.自动化学报, 2015, 41(2):312-319 http://www.aas.net.cn/CN/Y2015/V41/I2/312Tang Hong-Zhong, Zhang Xiao-Gang, Chen Hua, Cheng Wei, Tang Mei-Ling. Incoherent dictionary learning method with border condition constrained for sparse representation. Acta Automatica Sinica, 2015, 41(2):312-319 http://www.aas.net.cn/CN/Y2015/V41/I2/312 [28] 刘培娜, 刘国军, 郭茂祖, 刘扬, 李盼.非负局部约束线性编码图像分类算法.自动化学报, 2015, 41(7):1235-1243 http://www.aas.net.cn/CN/Y2015/V41/I7/1235Liu Pei-Na, Liu Guo-Jun, Guo Mao-Zu, Liu Yang, Li Pan. Image classification based on non-negative locality-constrained linear coding. Acta Automatica Sinica, 2015, 41(7):1235-1243 http://www.aas.net.cn/CN/Y2015/V41/I7/1235 [29] 任越美, 张艳宁, 李映.压缩感知及其图像处理应用研究进展与展望.自动化学报, 2014, 40(8):1563-1575 http://www.aas.net.cn/CN/Y2014/V40/I8/1563Ren Yue-Mei, Zhang Yan-Ning, Li Ying. Advances and perspective on compressed sensing and application on image processing. Acta Automatica Sinica, 2014, 40(8):1563-1575 http://www.aas.net.cn/CN/Y2014/V40/I8/1563 -

 下载:
下载:



计量
- 文章访问数: 2391
- HTML全文浏览量: 295
- PDF下载量: 1261
- 被引次数: 0
