

-
摘要: 人们对大数据的认识已从"3Vs" (Volume-大容量; Variety-多样性; Velocity-处理实时性)、"4Vs" ("3Vs"与Value-价值)、到现今的"5Vs" ("4Vs"与Veracity-真实性).在此背景下, 首先分析过程工业大数据的"5Vs"特性; 接下来, 综述现有数据建模方法, 并结合过程工业大数据特有性质 (包括:多层面不规则采样性、多时空时间序列性、不真实数据混杂性) 论述现有数据建模方法应用于工业大数据建模时的局限; 最后, 探讨过程工业大数据建模有待研究的问题, 包括:1) 多层面不规则采样数据的潜结构建模; 2) 用于事件发现、决策和因果分析的多时空时间序列数据建模; 3) 含有不真实数据的鲁棒建模; 4) 支持实时建模的大容量数据计算架构与方法.
-
关键词:
- 过程工业大数据 /
- 多层面数据潜结构建模 /
- 多时空时间序列数据建模 /
- 大数据计算架构
Abstract: The understanding of big data goes through three stages, i.e., "3Vs" (Volume, variety and velocity), "4Vs" ("3Vs" and value), and "5Vs" ("4Vs" and veracity). In the era of big data of process industries, the "5Vs" characteristics of industrial big data are analyzed. After that, the existing methods on data modeling are reviewed while the corresponding limitations are analyzed under industrial big data circumstances with specific characteristics, i.e., multi-layer irregularly sampling, multiple temporal and spatial time series, and non-veracity with outlier. Finally, the perspectives on industrial big data modeling are discussed, including: i) latent structure modeling of multi-layer irregularly sampled big data; ii) multiple temporal and spatial time-series data modeling for event discovery, decision-making, and causality analysis; iii) robust modeling of data with non-veracity samples; and iv) data-friendly system architecture and method towards big data real-time modeling. -
近些年来, 由于多智能体协同控制在编队控制[1]、机器人网络[2]、群集行为[3]、移动传感器[4-5]等方面的广泛应用, 多智能体系统的协同控制问题受到了众多研究者的广泛关注.一致性问题是多智能体系统协同控制领域的一个关键问题, 其目的是通过与邻居之间的信息交换, 使所有智能体的状态达成一致.迄今为止, 对多智能体一致性的研究也已取得了丰硕的成果, 根据多智能体的动力学模型分类, 主要可以将其分为以下4种情形:一阶[6-9]、二阶[10-13]、三阶[14-15]、高阶[16-18].
在实际应用中, 由于CPU处理速度和内存容量的限制, 智能体不能频繁地进行控制以及与其邻居交换信息.因此, 事件触发控制策略作为减少控制次数和通信负载的有效途径, 受到了越来越多的关注.到目前为止, 对事件触发控制机制的研究也取得了很多成果[19-23].Xiao等[19]基于事件触发控制策略, 解决了带有领航者的离散多智能体系统的跟踪问题.通过利用状态测量误差并且基于二阶离散多智能体系统动力学模型, Zhu等[20]提出了一种自触发的控制策略, 该策略使得所有智能体的状态均达到一致. Huang等[21]研究了基于事件触发策略的Lur$'$e网络的跟踪问题.针对不同的领航者-跟随者系统, Xu等[22]提出了3种不同类型的事件触发控制器, 包含分簇式控制器、集中式控制器和分布式控制器, 以此来解决对应的一致性问题.然而, 大多数现有的事件触发一致性成果集中于考虑一阶多智能体系统和二阶多智能体系统, 很少有成果研究三阶多智能体系统的事件触发控制问题, 特别是对于三阶离散多智能体系统, 成果更是少之又少.所以, 设计相应的事件触发控制协议来解决三阶离散多智能体系统的一致性问题已变得尤为重要.
本文研究了基于事件触发控制机制的三阶离散多智能体系统的一致性问题, 文章主要有以下三点贡献:
1) 利用位置、速度和加速度三者的测量误差, 设计了一种新颖的事件触发控制机制.
2) 利用不等式技巧, 分析得到了保证智能体渐近收敛到一致状态的充分条件.与现有的事件触发文献[19-22]不同的是, 所得的一致性条件与通信拓扑的Laplacian矩阵特征值和系统的耦合强度有关.
3) 给出了排除类Zeno行为的参数条件, 进而使得事件触发控制器不会每个迭代时刻都更新.
1. 预备知识
1.1 代数图论
智能体间的通信拓扑结构用一个有向加权图来表示, 记为.其中, $\vartheta = \left\{ {1, 2, \cdots, n} \right\}$表示顶点集, $\varsigma\subseteq\vartheta\times\vartheta$表示边集, 称作邻接矩阵, ${a_{ij}}$表示边$\left({j, i} \right) \in \varsigma $的权值.当$\left({j, i} \right) \in \varsigma $时, 有${a_{ij}} > 0$; 否则, 有${a_{ij}} = 0$. ${a_{ij}} > 0$表示智能体$i$能收到来自智能体$j$的信息, 反之则不成立.对任意一条边$j$, 节点$j$称为父节点, 节点$i$则称为子节点, 节点$i$是节点$j$的邻居节点.假设通信拓扑中不存在自环, 即对任意$i\in \vartheta $, 有${a_{ii}} = 0$.
定义$L = \left({{l_{ij}}}\right)\in{\bf R}^{n\times n}$为图${\cal G}$的Laplacian矩阵, 其中元素满足${l_{ij}} = - {a_{ij}} \le 0, i \ne j$; ${l_{ii}} = \sum\nolimits_{j = 1, j \ne i}^n {{a_{ij}} \ge 0} $.智能体$i$的入度定义为${d_i} = \sum\nolimits_{j = 1}^n {{a_{ij}}} $, 因此可得到$L = D - \Delta $, 其中, .如果有向图中存在一个始于节点$i$, 止于节点$j$的形如的边序列, 那么称存在一条从$i$到$j$的有向路径.特别地, 如果图中存在一个根节点, 并且该节点到其他所有节点都有有向路径, 那么称此有向图存在一个有向生成树.另外, 如果有向图${\cal G}$存在一个有向生成树, 则Laplacian矩阵$L$有一个0特征值并且其他特征值均含有正实部.
1.2 模型描述
考虑多智能体系统由$n$个智能体组成, 其通信拓扑结构由有向加权图${\cal G}$表示, 其中每个智能体可看作图${\cal G}$中的一个节点, 每个智能体满足如下动力学方程:
$ \begin{equation} \left\{ \begin{array}{l} {x_i}\left( {k + 1} \right) = {x_i}\left( k \right) + {v_i}\left( k \right)\\ {v_i}\left( {k + 1} \right) = {v_i}\left( k \right) + {z_i}\left( k \right)\\ {z_i}\left( {k + 1} \right) = {z_i}\left( k \right) + {u_i}\left( k \right) \end{array} \right. \end{equation} $
(1) 其中, ${x_i}\left(k \right) \in \bf R$表示位置状态, ${v_i}\left(k \right) \in \bf R$表示速度状态, ${z_i}\left(k \right) \in \bf R$表示加速度状态, ${u_i}\left(k \right) \in \bf R$表示控制输入.
基于事件触发控制机制的控制器协议设计如下:
$ \begin{equation} {u_i}\left( k \right) = \lambda {b_i}\left( {k_p^i} \right) + \eta {c_i}\left( {k_p^i} \right) + \gamma {g_i}\left( {k_p^i} \right), k \in \left[ {k_p^i, k_{p + 1}^i} \right) \end{equation} $
(2) 其中, $\lambda> 0$, $\eta> 0$, $\gamma> 0$表示耦合强度,
$ \begin{align*}&{b_i}\left( k \right)= \sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{x_j}\left( k \right) - {x_i}\left( k \right)} \right)} , \nonumber\\ &{c_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{v_j}\left( k \right) - {v_i}\left( k \right)} \right)}, \nonumber\\ & {g_i}\left( k \right)=\sum\nolimits_{j \in {N_i}} {{a_{ij}}\left( {{z_j}\left( k \right) - {z_i}\left( k \right)} \right)} .\end{align*} $
触发时刻序列定义为:
$ \begin{equation} k_{p + 1}^i = \inf \left\{ {k:k > k_p^i, {E_i}\left( k \right) > 0} \right\} \end{equation} $
(3) ${E_i}\left(k \right)$为触发函数, 具有以下形式:
$ \begin{align} {E_i}\left( k \right)= & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|- {\delta _2}{\beta ^k} - \nonumber\nonumber\\ &{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| - {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| \end{align} $
(4) 其中, ${\delta _1} > 0$, ${\delta _2} > 0$, $\beta > 0$, , ${e_{ci}}\left(k \right) = {c_i}\left({k_p^i} \right) - {c_i}\left(k \right)$, ${e_{gi}}\left(k \right) = {g_i}\left({k_p^i} \right) - {g_i}\left(k \right)$.
令$\varepsilon _i\left(k\right)={x_i}\left(k\right)-{x_1}\left(k\right)$, ${\varphi _i}\left(k\right)={v_i}\left(k \right)-$ ${v_1}\left(k\right)$, ${\phi _i}(k) = {z_i}(k) - {z_1}\left(k \right)$, $i = 2, \cdots, n$. , $\cdots, {\varphi _n}\left(k \right)]^{\rm T}$, $\phi \left(k \right) = {\left[{{\phi _2}\left(k \right), \cdots, {\phi _n}\left(k \right)} \right]^{\rm T}}$. $\psi \left(k \right) = {\left[{{\varepsilon ^{\rm T}}\left(k \right), {\varphi ^{\rm T}}\left(k \right), {\phi ^{\rm T}}\left(k \right)} \right]^{\rm T}}$, , ${\bar e_b} = {\left[{{e_{b1}}\left(k \right), \cdots, {e_{b1}}\left(k \right)} \right]^{\rm T}}$, , ${e_{c1}}\left(k \right)]^{\rm T}$, , ${\bar e_g} = $ ${\left[{{e_{g1}}\left(k \right), \cdots, {e_{g1}}\left(k \right)} \right]^{\rm T}}$, $\tilde e\left(k \right) = [\tilde e_b^{\rm T}\left(k \right), \tilde e_c^{\rm T}\left(k \right), $ $\tilde e_g^{\rm T}\left(k \right)]^{\rm T}$, $\bar e\left(k \right) = [\bar e_b^{\rm T}\left(k \right), \bar e_c^T\left(k \right), \bar e_g^{\rm T}\left(k \right)]^{\rm T}$,
$ \hat L = \left[ {\begin{array}{*{20}{c}} {{d_2} + {a_{12}}}&{{a_{13}} - {a_{23}}}& \cdots &{{a_{1n}} - {a_{2n}}}\\ {{a_{12}} - {a_{32}}}&{{d_3} + {a_{13}}}& \cdots &{{a_{1n}} - {a_{3n}}}\\ \vdots & \vdots & \ddots & \vdots \\ {{a_{12}} - {a_{n2}}}&{{a_{13}} - {a_{n3}}}& \cdots &{{d_n} + {a_{1n}}} \end{array}} \right] $
再结合式(1)和式(2)可得到:
$ \begin{equation} \psi \left( {k + 1} \right) = {Q_1}\psi \left( k \right) + {Q_2}\left( {\tilde e\left( k \right) - \bar e\left( k \right)} \right) \end{equation} $
(5) 其中, , .
定义1.对于三阶离散时间多智能体系统(1), 当且仅当所有智能体的位置变量、速度变量、加速度变量满足以下条件时, 称系统(1)能够达到一致.
$ \begin{align*} &{\lim _{k \to \infty }}\left\| {{x_j}\left( k \right) - {x_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{v_j}\left( k \right) - {v_i}\left( k \right)} \right\| = 0 \nonumber\\ & {\lim _{k \to \infty }}\left\| {{z_j}\left( k \right) - {z_i}\left( k \right)} \right\| = 0 \\&\quad\qquad \forall i, j = 1, 2, \cdots , n \end{align*} $
定义2.如果$k_{p + 1}^i - k_p^i > 1$, 则称触发时刻序列$\left\{ {k_p^i} \right\}$不存在类Zeno行为.
假设1.假设有向图中存在一个有向生成树.
2. 一致性分析主要结果
假设$\kappa$是矩阵${Q_1}$的特征值, ${\mu _i}$是$L$的特征值, 则有如下等式成立:
$ {\rm{det}}\left( {\kappa {I_{3n - 3}} - {Q_1}} \right)=\nonumber\\ \det \left(\! \!{\begin{array}{*{20}{c}} {\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\!&\!{{0_{n - 1}}}\\ {{0_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}}}\!&\!{ - {I_{n - 1}}}\\ {\lambda {{\hat L}_{n - 1}}}\!&\!{\eta {{\hat L}_{n - 1}}}\!&\!{\left( {\kappa - 1} \right){I_{n - 1}} + \gamma {{\hat L}_{n - 1}}} \end{array}} \!\!\right)=\nonumber\\ \prod\limits_{i = 2}^n {\left[ {{{\left( {\kappa - 1} \right)}^3} + \left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i}} \right]} $
令
$ \begin{align} {m_i}\left( \kappa \right)= &{\left( {\kappa - 1} \right)^3} + \nonumber\\&\left( {\lambda + \eta \left( {\kappa - 1} \right) + \gamma {{\left( {\kappa - 1} \right)}^2}} \right){\mu _i} = 0, \nonumber\\& \qquad\qquad\qquad\qquad\qquad i = 2, \cdots , n \end{align} $
(6) 则有如下引理:
引理1[15]. 如果矩阵$L$有一个0特征值且其他所有特征值均有正实部, 并且参数$\lambda $, $\eta $, $\gamma $满足下列条件:
$ \left\{ \begin{array}{l} 3\lambda - 2\eta < 0\\ \left( {\gamma - \eta + \lambda } \right)\left( {\lambda - \eta } \right) < - \dfrac{{\lambda \Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}}\\ \left( {4\gamma + \lambda - 2\eta } \right)<\dfrac{{8\Re \left( {{\mu _i}} \right)}}{{{{\left| {{\mu _i}} \right|}^2}}} \end{array} \right. $
那么, 方程(6)的所有根都在单位圆内, 这也就意味着矩阵${Q_1}$的谱半径小于1, 即$\rho \left({{Q_1}} \right) < 1$.其中, 表示特征值${\mu _i}$的实部.
引理2[23]. 如果, 那么存在$M \ge 1$和$0 < \alpha < 1$使得下式成立
$ {\left\| {{Q_1}} \right\|^k} \le M{\alpha ^k}, \quad k \ge 0 $
定理1. 对于三阶离散多智能体系统(1), 基于假设1, 如果式(2)中的耦合强度满足引理1中的条件, 触发函数(4)中的参数满足$0 < {\delta _1} < 1$, , $0 < \alpha < \beta < 1$, 则称系统(1)能够实现渐近一致.
证明.令$\omega \left(k \right) = \tilde e\left(k \right) - \bar e\left(k \right)$, 式(5)能够被重新写成如下形式:
$ \begin{equation} \psi \left( k \right) = Q_1^k\psi \left( 0 \right) + {Q_2}\sum\limits_{s = 0}^{k - 1} {Q_1^{k - 1 - s}\omega \left( s \right)} \end{equation} $
(7) 根据引理1和引理2可知, 存在$M \ge 1$和$0 < \alpha < 1$使得下式成立.
$ \begin{align} \left\| {\psi \left( k \right)} \right\|\le & {\left\| {{Q_1}} \right\|^k}\left\| {\psi \left( 0 \right)} \right\| + \nonumber\\ & \left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{{\left\| {{Q_1}} \right\|}^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|}\le \nonumber\\ & M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+\nonumber\\ & M\left\| {{Q_2}} \right\|\sum\limits_{s = 0}^{k - 1} {{\alpha ^{k - 1 - s}}\left\| {\omega \left( s \right)} \right\|} \end{align} $
(8) 由触发条件可得:
$ \begin{align} & \left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ & \qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^k}\le\nonumber\\ &\qquad {\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\| + {\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\| + \nonumber\\ &\qquad{\delta _1}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\|+ {\delta _1}\left| {{e_{bi}} \left( k \right)} \right| + \nonumber\\ &\qquad{\delta _1}\left| {{e_{ci}} \left( k \right)} \right|+ {\delta _1}\left| {{e_{gi}}\left( k \right)} \right| + {\delta _2}{\beta ^k} \end{align} $
(9) 对上式移项可求解得:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le \nonumber\\ &\qquad\frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varepsilon \left( k \right)} \right\|}}{{1 - {\delta _1}}} + \frac{{{\delta _1}\left\| L \right\| \cdot \left\| {\varphi \left( k \right)} \right\|}}{{1 - {\delta _1}}}{\rm{ + }}\nonumber\\ &\qquad\frac{{{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\phi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(10) 又因为, 和, 可得出下列不等式:
$ \begin{align} &\left| {{e_{bi}}\left( k \right)} \right| + \left| {{e_{ci}}\left( k \right)} \right| + \left| {{e_{gi}}\left( k \right)} \right|\le\nonumber\\ &\qquad \frac{{{\delta _1}\left\| L \right\|}}{{1 - {\delta _1}}} \cdot \left( {\left\| {\varepsilon \left( k \right)} \right\|{\rm{ + }}\left\| {\varphi \left( k \right)} \right\|{\rm{ + }}\left\| {\phi \left( k \right)} \right\|} \right) +\nonumber\\ &\qquad \frac{{{\delta _2}{\beta ^k}}}{{1 - {\delta _1}}}\le \frac{{3{\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{{\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(11) 接着有如下不等式成立:
$ \begin{align} \left\| {e\left( k \right)} \right\|\le \frac{{3\sqrt n {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| + \frac{{\sqrt n {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(12) 其中, , ${e_b}(k) = \left[{{e_{b1}}(k), \cdots, {e_{bn}}(k)} \right]$, ${e_c}(k) = \left[{{e_{c1}}(k), \cdots, {e_{cn}}(k)} \right]$,
注意到
$ \begin{equation} \left\| {\tilde e( k )} \right\| + \left\| {\bar e( k )} \right\| \le \sqrt {6( {n - 1} )} \left\| {e( k )} \right\| \end{equation} $
(13) 于是有
$ \begin{align} \left\| {\omega ( k )} \right\| &= \left\| {\tilde e( k ) - \bar e\left( k \right)} \right\| \le\nonumber\\ & \left\| {\tilde e\left( k \right)} \right\| + \left\| {\bar e\left( k \right)} \right\|\le\nonumber\\ & \frac{{3\sqrt {6n( {n - 1} )} {\delta _1}}}{{1 - {\delta _1}}}\left\| L \right\| \cdot \left\| {\psi \left( k \right)} \right\| +\nonumber\\ & \frac{{\sqrt {6n( {n - 1} )} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^k} \end{align} $
(14) 把式(14)代入式(8)可得
$ \begin{align} \left\| {\psi \left( k \right)} \right\| &\le M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^k}+ \nonumber\\ &\frac{{M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}} {\delta _1}3\sqrt {6n\left( {n - 1} \right)} \left\| L \right\|}}{{1 - {\delta _1}}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}}\left\| {\psi \left( s \right)} \right\|} + M\left\| {{Q_2}} \right\|{\alpha ^{k - 1}}\times\nonumber\\ &\sum\limits_{s = 0}^{k - 1} {{\alpha ^{ - s}} \frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}} {{1 - {\delta _1}}}{\beta ^s}} \end{align} $
(15) 接下来的部分, 将证明下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| \le W{\beta ^k}.\end{equation} $
(16) 其中, $W = \max \left\{ {{\Theta _1}, {\Theta _2}} \right\}$,
首先, 证明对任意的$\rho > 1$, 下列不等式成立.
$ \begin{equation} \left\| {\psi \left( k \right)} \right\| < \rho W{\beta ^k} \end{equation} $
(17) 利用反证法, 先假设式(17)不成立, 则必将存在${k^ * } > 0$使得并且当$k \in \left({0, {k^ * }} \right)$时$\left\| {\psi \left(k \right)} \right\| < \rho W{\beta ^k}$成立.因此, 根据式(17)可得:
$ \begin{align*} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le\\ &\qquad M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} +\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}M\times \end{align*} $
$ \begin{align*} &\qquad\sum\limits_{s = 0}^{{k^ * } - 1} {\alpha ^{ - s}}\left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot \left\| {\psi \left( s \right)} \right\|}}{{1 - {\delta _1}}}} \right]+ \\ &\qquad M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}}}{{1 - {\delta _1}}}{\beta ^s}} \right]} < \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}} + \rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}}\times\\ &\qquad \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{3\sqrt {6n\left( {n - 1} \right)} {\delta _1}\left\| L \right\| \cdot W{\beta ^s}}} {{1 - {\delta _1}}}} \right]} +\\ &\qquad\rho M\left\| {{Q_2}} \right\|{\alpha ^{{k^ * } - 1}} \sum\limits_{s = 0}^{{k^ * } - 1} {{\alpha ^{ - s}} \left[ {\frac{{\sqrt {6n\left( {n - 1} \right)} {\delta _2}{\beta ^s}}}{{1 - {\delta _1}}}} \right]=} \\ &\qquad \rho M\left\| {\psi \left( 0 \right)} \right\|{\alpha ^{{k^ * }}}- \nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\alpha ^{{k^ * }}}+\nonumber\\ &\qquad \rho \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}}{\beta ^{{k^ * }}} \end{align*} $
1) 当$W = M\left\| {\psi \left(0 \right)} \right\|$时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\| - \nonumber\\ &\qquad \frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} \ge 0 \end{aligned} \end{equation*} $
所以可得到
$ \begin{equation} \rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\| \le \rho M\left\| {\psi \left( 0 \right)} \right\|{\beta ^{{k^ * }}}=\rho W{\beta ^{{k^ * }}} \end{equation} $
(18) 2) 当时, 则有
$ \begin{equation*} \begin{aligned} &M\left\| {\psi \left( 0 \right)} \right\|- \nonumber\\ &\qquad\frac{{M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} \left( {3{\delta _1}\left\| L \right\|W + {\delta _2}} \right)}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right)}} < 0 \end{aligned} \end{equation*} $
所以有
$ \begin{align} &\rho W{\beta ^{{k^ * }}} \le \left\| {\psi \left( {{k^ * }} \right)} \right\|\le\nonumber\\ & \frac{{\rho {\delta _2}M\left\| {{Q_2}} \right\|\sqrt {6n\left( {n - 1} \right)} {\beta ^{{k^ * }}}}}{{\left( {\beta - \alpha } \right)\left( {1 - {\delta _1}} \right) - 3{\delta _1}M\left\| {{Q_2}} \right\|\left\| L \right\|\sqrt {6n\left( {n - 1} \right)} }}=\nonumber\\ &\rho W{\beta ^{{k^ * }}} \end{align} $
(19) 根据以上结果, 式(18)和式(19)都与假设相矛盾.这说明原命题成立, 即对任意的$\rho > 1$, 式(17)成立.易知, 如果$\rho \to 1$, 则式(16)成立.根据式(16)可知, 当$k \to + \infty $时, 有, 则系统(5)是收敛的.由$\psi \left(k \right)$的定义可知, 系统(1)能够实现渐近一致.
定理2. 对于系统(1), 如果定理1中的条件成立, 并且控制器(2)中的设计参数满足如下条件,
$ {\delta _1} \in \left( {\frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}}, 1} \right)\\ {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } $
那么触发序列中的类Zeno行为将被排除.
证明. 易知排除类Zeno行为的关键是要证明不等式$k_{p + 1}^i - k_p^i > 1$成立.根据事件触发机制可知, 下一个触发时刻将会发生在触发函数(4)大于0时.进而可得到如下不等式
$ \begin{align} &\left| {{e_{bi}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{ci}}\left( {k_{p + 1}^i} \right)} \right| + \left| {{e_{gi}}\left( {k_{p + 1}^i} \right)} \right|\ge\nonumber\\ &\qquad{\delta _1}\left| {{b_i}\left( {k_p^i} \right)} \right| + {\delta _1}\left| {{c_i}\left( {k_p^i} \right)} \right| +\nonumber\\ &\qquad {\delta _1}\left| {{g_i}\left( {k_p^i} \right)} \right| + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{align} $
(20) 定义, .结合式(20), 可得到下式
$ \begin{equation} {G_i}\left( {k_{p + 1}^i} \right) \ge {\delta _1}{H_i}\left( {k_p^i} \right) + {\delta _2}{\beta ^{k_{p + 1}^i}} \end{equation} $
(21) 结合式(16)和式(21)可得
$ \begin{align} {\delta _2}{\beta ^{k_{p + 1}^i}} &\le {G_i}\left( {k_{p + 1}^i} \right) - {\delta _1}{H_i}\left( {k_p^i} \right)\le\nonumber\\ & \left\| L \right\|\left( {\left\| {\psi \left( {k_p^i} \right)} \right\| + \left\| {\psi \left( {k_{p + 1}^i} \right)} \right\|} \right)\le\nonumber\\ & W\left\| L \right\|\left( {{\beta ^{k_p^i}} + {\beta ^{k_{p + 1}^i}}} \right) \end{align} $
(22) 求解上式得
$ \begin{equation} \left( {{\delta _2} - \left\| L \right\|W} \right){\beta ^{k_{p + 1}^i}} \le \left\| L \right\|W{\beta ^{k_p^i}} \end{equation} $
(23) 根据式(23)可得
$ \begin{equation} k_{p + 1}^i - k_p^i > \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}} } {\ln \beta } \end{equation} $
(24) 基于(24)易知当时, 有如下不等式成立
$ \begin{equation} \dfrac{{\ln \dfrac{{W\left\| L \right\|}}{{{\delta _2} - W\left\| L \right\|}}}} {\ln \beta } > 1 \end{equation} $
(25) 此外, 因为$W = M\left\| {\psi \left(0 \right)} \right\|$以及
$ \begin{equation} {\delta _1} > \frac{{\left( {\beta - \alpha } \right)}}{{\left( {\beta - \alpha } \right) + 3\sqrt {6n\left( {n - 1} \right)} M\left\| {{Q_{\rm{2}}}} \right\|\left\| L \right\|}} \end{equation} $
(26) 又可以得出
$ \begin{equation} {\delta _2} > \frac{{\left\| L \right\|\left\| {\psi \left( 0 \right)} \right\|M\left( {1 + \beta } \right)}}{\beta } = \frac{{\left\| L \right\|W\left( {1 + \beta } \right)}}{\beta } \end{equation} $
(27) 该式意味着式(25)成立, 又结合式(24)易知$k_{p + 1}^i - k_p^i > 1$, 即排除类Zeno行为的条件得已满足.
注2.类Zeno行为广泛存在于基于事件触发控制机制的离散系统中.然而, 当前极少有文献研究如何排除类Zeno行为, 尤其是对于三阶多智能体动态模型.定理2给出了排除三阶离散多智能体系统的类Zeno行为的参数条件.
3. 仿真实验
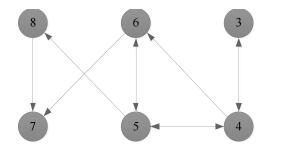
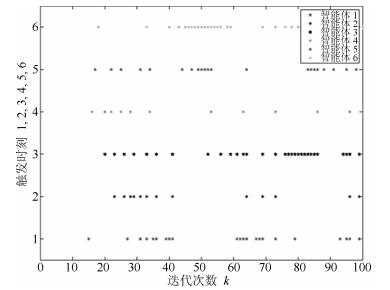
本部分将利用一个仿真实验来验证本文所提算法及理论的正确性和有效性.假设三阶离散多智能体系统(1)包含6个智能体, 且有向加权通信拓扑结构如图 1所示, 权重取值为0或1, 可以明显地看出该图包含有向生成树(满足假设1).
通过简单的计算可得, ${\mu _1} = 0$, ${\mu _2} = 0.6852$, ${\mu _3} = 1.5825 + 0.3865$i, ${\mu _4} = 1.5825 - 0.3865$i, ${\mu _5} = 3.2138$, ${\mu _6} = 3.9360$.令$M = 1$, 结合定理1和定理2可得到$0.035 < {\delta _1} < 1$, ${\delta _2} > 44.0025$, $0 < \alpha < \beta < 1$.令${\delta _1} = 0.2$, ${\delta _2} = 200$, $\alpha = 0.6$, $\beta = 0.9$, $\lambda = 0.02$, $\eta = 0.3$, $\gamma = 0.5$, 不难验证满足引理1的条件并且计算可知$\rho \left({{Q_1}} \right) = 0.9958 < 1$.三阶离散多智能体系统(1)的一致性结果如图 2~图 6所示.根据定理1可知, 基于控制器(2)和事件触发函数(4)的系统(1)能实现一致.从图 2~图 6可以看出, 仿真结果与理论分析符合.
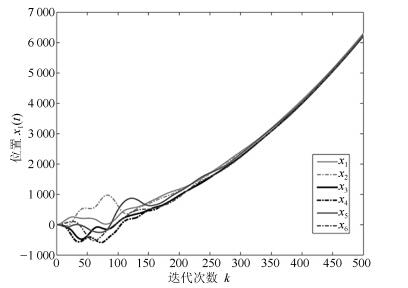 图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems
图 2 三阶离散多智能体系统的位置轨迹图Fig. 2 The trajectories of position in third-order discrete-time multi-agent systems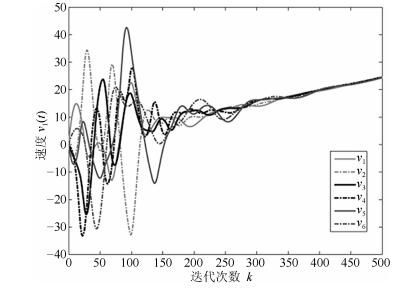 图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems
图 3 三阶离散多智能体系统的速度轨迹图Fig. 3 The trajectories of speed in third-order discrete-time multi-agent systems 图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems
图 4 三阶离散多智能体系统的加速度轨迹图Fig. 4 The trajectories of acceleration in third-order discrete-time multi-agent systems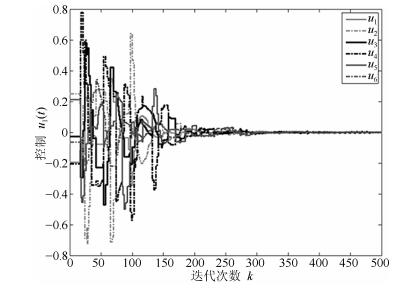 图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems
图 5 三阶离散多智能体系统的控制轨迹图Fig. 5 The trajectories of control in third-order discrete-time multi-agent systems图 2~图 4分别表征了系统(1)中所有智能体的位置、速度和加速度的轨迹, 从图中可以看出以上3个变量确实达到了一致.图 5展示了控制输入的轨迹.为了更清楚地体现事件触发机制的优点, 图 6给出了0$ \sim $100次迭代内的各智能体的触发时刻轨迹.从图 6可以看出, 本文设计的事件触发协议确实达到了减少更新次数, 节省资源的目的.
4. 结论
针对三阶离散多智能体系统的一致性问题, 构造了一个新颖的事件触发一致性协议, 分析得到了在通信拓扑为有向加权图且包含生成树的条件下, 系统中所有智能体的位置状态、速度状态和加速度状态渐近收敛到一致状态的充分条件.同时, 该条件指出了通信拓扑的Laplacian矩阵特征值和系统的耦合强度对系统一致性的影响.另外, 给出了排除类Zeno行为的参数条件.仿真实验结果也验证了上述结论的正确性.将文中获得的结论扩展到拓扑结构随时间变化的更高阶多智能体网络是极有意义的.这将是未来研究的一个具有挑战性的课题.
-
[1] Wu X D, Zhu X Q, Wu G Q, Ding W. Data mining with big data. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(1):97-107 doi: 10.1109/TKDE.2013.109 [2] Syed A R, Gillela K, Venugopal C. The future revolution on big data. International Journal of Advanced Research in Computer and Communication Engineering, 2013, 2(6):2446-2451 http://www.doc88.com/p-6631367365432.html [3] Condliffe J. The problem with big data is that nobody und-erstands it[Online], available:http://gizmodo.com/59062-04/the-problem-with-big-data-is-that-nobody-understan-ds-it, April 30, 2012. [4] Manyika J, Chui M, Brown B, Bughin J, Dobbs R, Roxburgh C, Byers A H. Big data:the next frontier for innovation, competition, and productivity. McKinsey Global Institute Report[Online], available:http://www.mckinsey.com/insights/mgi/research/technology_and_innovation/big_data_the_next_frontier_for_innovation, June, 2011. [5] Halevi G, Moed H. The Evolution of big data as a research and scientific topic:overview of the literature. Special Issue on Big Data, Research Trends, 2012, (30):1-37 [6] Ginsberg J, Mohebbi M H, Patel R S, Brammer L, Smolinski M S, Brilliant L. Detecting influenza epidemics using search engine query data. Nature, 2009, 457(7232):1012-1014 doi: 10.1038/nature07634 [7] Preis T, Moat H S, Stanley H E. Quantifying trading behavior in financial markets using Google trends. Scientific Reports, 2013, 3:1684 http://adsabs.harvard.edu/abs/2013NatSR...3E1684P [8] GE智能平台.工业大数据云利用大数据集推动创新、竞争和增长.自动化博览, 2012, (12):40-42 http://www.cnki.com.cn/Article/CJFDTOTAL-ZDBN201212025.htmGE intelligent platform. Industrial big data cloud promotes innovation, competition and growth using big data. Automation Panorama, 2012, (12):40-42 http://www.cnki.com.cn/Article/CJFDTOTAL-ZDBN201212025.htm [9] 钟路音.工业数据增速是其他大数据领域的两倍.人民邮电报.)[Online], available:http://www.cnii.com.cn/wlkb/rmydb/content/2013-08/27/content_1210645.htm, August 27, 2013.Zhong Lu-Yin. Industrial data growth rate will be two times the other big data fields. People's Posts and Telecommunications News. [10] Industrial Big Data. Know the future-automate processes. Software for data analysis and accurate forecasting[Online], available:http://differentia.co/qlikview/docs/Blue-Yonder-White-Paper-Industrial-Big-Data.pdf, October 23, 2015.. [11] Obitko M, Jirkovský V, Bezdíček J. Big data challenges in industrial automation. Industrial Applications of Holonic and Multi-Agent Systems, Lecture Notes in Computer Science. Berlin Heidelberg:Springer, 2013, 8062:305-316 http://www.springer.com/gp/book/9783642400896 [12] Schroeck M, Shockley R, Smart J, Romero-Mora-les D, Tu-fano P. Analytics:the real-world use of big data[Online], available:http://www-03.ibm.com/systems/hu/resources/the_real_word_use_of_big_data.pdf, 2013. [13] Hillard R. It's time for a new definition of big data[Online], available:http://mike2.openmethodology.org/blogs/information-development/2012/03/18/its-time-for-a-new-defin-ition-of-big-data, March 18, 2012. [14] Yan J. Big data, bigger opportunities[Online], available:http://www.meritalk.com/pdfs/bdx/bdx-whitepaper-090413.pdf, April 9, 2013. [15] Qin S J. Survey on data-driven industrial process monitoring and diagnosis. Annual Reviews in Control, 2012, 36(2):220-234 doi: 10.1016/j.arcontrol.2012.09.004 [16] Kano M, Tanaka S, Hasebe S, Hashimoto I, Ohno H. Monitoring independent components for fault detection. AIChE Journal, 2003, 49(4):969-976 doi: 10.1002/(ISSN)1547-5905 [17] Lee J M, Qin S J, Lee I B. Fault detection and diagnosis based on modified independent component analysis. AIChE Journal, 2006, 52(10):3501-3514 doi: 10.1002/(ISSN)1547-5905 [18] Ku W F, Storer R H, Georgakis C. Disturbance detection and isolation by dynamic principal component analysis. Chemometrics and Intelligent Laboratory Systems, 1995, 30(1):179-196 doi: 10.1016/0169-7439(95)00076-3 [19] Singhal A, Seborg D E. Evaluation of a pattern matching method for the Tennessee Eastman challenge process. Journal of Process Control, 2006, 16(6):601-613 doi: 10.1016/j.jprocont.2005.10.005 [20] Yoo C K, Villez K, Lee I B, Rosén C, Vanrolleghem P A. Multi-model statistical process monitoring and diagnosis of a sequencing batch reactor. Biotechnology and Bioengineering, 2007, 96(4):687-701 doi: 10.1002/(ISSN)1097-0290 [21] Kano M, Hasebe S, Hashimoto I, Ohno H. Evolution of multivariate statistical process control:application of independent component analysis and external analysis. Computers & Chemical Engineering, 2004, 28(6-7):1157-1166 https://www.researchgate.net/publication/222649593_Evolution_of_multivariate_statistical_process_control_Application_of_independent_component_analysis_and_external_analysis [22] Rosipal R. Kernel partial least squares for nonlinear regression and discrimination. Neural Network World, 2003, 13(3):291-300 https://www.researchgate.net/profile/Roman_Rosipal/publication/228639853_Kernel_Partial_Least_Squares_for_Nonlinear_Regression_and_Discrimination/links/02e7e537efbddccf5e000000/Kernel-Partial-Least-Squares-for-Nonlinear-Regression-and-Discrimination.pdf [23] Sheng N, Liu Q, Qin S J, Chai T Y. Comprehensive monitoring of nonlinear processes based on concurrent kernel projection to latent structures. IEEE Transactions on Automation Science and Engineering, 2015, (99):1-9, DOI: 10.1109/TASE.2015.2477272 [24] Negiz A, Çinar A. Statistical monitoring of multivariable dynamic processes with state-space models. AIChE Journal, 1997, 43(8):2002-2020 doi: 10.1002/(ISSN)1547-5905 [25] Simoglou A, Martin E B, Morris A J. Statistical performance monitoring of dynamic multivariate processes using state space modelling. Computers & Chemical Engineering, 2002, 26(6):909-920 https://www.researchgate.net/publication/223030941_Statistical_performance_monitoring_of_dynamic_multivariate_processes_using_state_space_modeling [26] Qin S J. An overview of subspace identification. Computers & Chemical Engineering, 2006, 30(10-12):1502-1513 https://www.researchgate.net/publication/223164646_An_overview_of_subspace_identification [27] Wang J, Qin S J. A new subspace identification approach based on principal component analysis. Journal of Process Control, 2002, 12(8):841-855 doi: 10.1016/S0959-1524(02)00016-1 [28] Li W H, Qin S J. Consistent dynamic PCA based on errors-in-variables subspace identification. Journal of Process Control, 2001, 11(6):661-678 doi: 10.1016/S0959-1524(00)00041-X [29] Ding S X, Zhang P, Naik A, Ding E L, Huang B. Subspace method aided data-driven design of fault detection and isolation systems. Journal of Process Control, 2009, 19(9):1496-1510 doi: 10.1016/j.jprocont.2009.07.005 [30] Wen Q J, Ge Z Q, Song Z H. Data-based linear Gaussian state-space model for dynamic process monitoring. AIChE Journal, 2012, 58(12):3763-3776 doi: 10.1002/aic.13776 [31] Li G, Qin S J, Zhou D H. A new method of dynamic latent variable modeling for process monitoring. IEEE Transactions on Industrial Electronics, 2014, 61(11):6438-6445 doi: 10.1109/TIE.2014.2301761 [32] Kaspar M H, Ray W H. Dynamic PLS modelling for process control. Chemical Engineering Science, 1993, 48(20):3447-3461 doi: 10.1016/0009-2509(93)85001-6 [33] Dong Y N, Qin S J. Dynamic-inner partial least squares for dynamic data modeling. In:Proceedings of the 9th International Symposium on Advanced Control of Chemical Processes (ADCHEM). Whistler, British Columbia, Canada:IFAC, 2015. 117-122 [34] Li G, Liu B S, Qin S J, Zhou D H. Quality relevant data-driven modeling and monitoring of multivariate dynamic processes:the dynamic T-PLS approach. IEEE Transactions on Neural Networks, 2011, 22(12):2262-2271 doi: 10.1109/TNN.2011.2165853 [35] Liu Q, Qin S J, Chai T Y. Quality-relevant monitoring and diagnosis with dynamic comcurrent projection to latent structures. In:Proceedings of the 19th IFAC World Congress. Cape Town, South Africa:IFAC, 2014. 2740-2745 [36] Dean J, Ghemawat S. MapReduce:simplified data processing on large clusters. In:Proceedings of the 6th Symposium on Operating Systems Design and Implementation. Berkeley, CA, USA:USENIX Association, 2004. 137-149 [37] Dittrich J, Quiané-Ruiz J A, Jndal A, Kargin Y, Setty V, Schad J. Hadoop++:making a yellow elephant run like a cheetah (without it even noticing). Proceedings of the VLDB Endowment, 2010, 3(1-2):515-529 doi: 10.14778/1920841 [38] Su X Y, Swart G. Oracle in-database hadoop:when mapreduce meets RDBMS. In:Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. New York:ACM, 2012. 779-790 [39] Silva Y A, Reed J M. Exploiting MapReduce-based similarity joins. In:Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. New York:ACM, 2012. 693-696 [40] Gudmundsson G P, Amsaleg L, Jonsson B P. Distributed high-dimensional index creation using Hadoop, HDFS and C++. In:Proceedings of the 10th International Workshop on Content-Based Multimedia Indexing. Annecy, France:IEEE, 2012. 1-6 [41] Yang L, Shi Z Z, Xu L D, Liang F, Kirsh I. DH-TRIE frequent pattern mining on Hadoop using JPA. In:Proceedings of the 2011 IEEE International Conference on Granular Computing. Kaohsiung:IEEE, 2011. 875-878 [42] Böse J H, Andrzejak A, Högqvist M. Beyond online aggregation:parallel and incremental data mining with online Map-Reduce. In:Proceedings of the 2010 Workshop on Massive Data Analytics on the Cloud. New York, USA:ACM, 2010. Article No. 3 [43] Condie T, Conway N, Alvaro P, Hellerstein J M, Elmeleegy K, Sears R. MapReduce online. In:Proceedings of the 7th USENIX Conference on Networked Systems Design and Implementation. Berkeley, CA, USA:USENIX Association, 2010. 313-328 [44] Bu Y Y, Howe B, Balazinska M, Ernst M D. HaLoop:efficient iterative data processing on large clusters. Proceedings of the VLDB Endowment, 2010, 3(1-2):285-296 doi: 10.14778/1920841 [45] Zhang Y F, Gao Q X, Gao L X, Wang C R. iMapReduce:a distributed computing framework for iterative computation. Journal of Grid Computing, 2012, 10(1):47-68 doi: 10.1007/s10723-012-9204-9 [46] Elnikety E, Elsayed T, Ramadan H E. iHadoop:asynchronous iterations for MapReduce. In:Proceedings of the 2011 IEEE 3rd International Conference on Cloud Computing Technology and Science. Athens:IEEE, 2011. 81-90 [47] Zhang Y F, Gao Q X, Gao L X, Wang C R. PrIter:a distributed framework for prioritizing iterative computations. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(9):1884-1893 doi: 10.1109/TPDS.2012.272 [48] Mazur E, Li B D, Diao Y L, Shenoy P J. Towards scalable one-pass analytics using MapReduce. In:Proceedings of the 2011 IEEE International Symposium on Parallel and Distributed Processing Workshops and Ph.D Forum. Shanghai, China:IEEE, 2011. 1102-1111 [49] Li B D, Mazur E, Diao Y L, McGreor A, Shenoy P. A platform for scalable one-pass analytics using MapReduce. In:Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data. New York:ACM, 2011. 985-996 [50] Brito A, Martin A, Knauth T, Creutz S, Becker D, Weigert S, Fetzer C. Scalable and low-latency data processing with stream MapReduce. In:Proceedings of the 2011 IEEE 3rd International Conference on Cloud Computing Technology and Science. Athens:IEEE, 2011. 48-58 [51] Sato-Ilic M. Preface to Part Ⅲ Adaptive big data analytics. Procedia Computer Science, 2012, 12:211 doi: 10.1016/j.procs.2012.09.057 [52] Yan W Z, Brahmakshatriya U, Xue Y, Gilder M, Wise B. p-PIC:parallel power iteration clustering for big data. Journal of Parallel and Distributed Computing, 2013, 73(3):352-359 doi: 10.1016/j.jpdc.2012.06.009 [53] Zhao W Z, Ma H F, He Q. Parallel K-means clustering based on MapReduce. Cloud Computing, 2009, 5931:674-679 doi: 10.1007/978-3-642-10665-1 [54] Gao H, Jiang J, She L, Fu Y. A new agglomerative hierarchical clustering algorithm implementation based on the map reduce framework. International Journal of Digital Content Technology and Its Applications, 2010, 4(3):95-100 doi: 10.4156/jdcta [55] Ordonez C, Pitchaimalai S K. Fast UDFs to compute sufficient statistics on large data sets exploiting caching and sampling. Data & Knowledge Engineering, 2010, 69(4):383-398 https://www.researchgate.net/publication/223782408_Fast_UDFs_to_compute_sufficient_statistics_on_large_data_sets_exploiting_caching_and_sampling [56] Qin S J. Process data analytics in the era of big data. AIChE Journal, 2014, 60(9):3092-3100 doi: 10.1002/aic.v60.9 [57] Alma Ö G. Comparison of robust regression methods in linear regression. International Journal of Contemporary Mathematical Sciences, 2011, 6(9):409-421 https://www.researchgate.net/publication/229017751_Comparison_of_Robust_Regression_Methods_in_Linear_Regression [58] 周晓剑.考虑梯度信息的ε-支持向量回归机.自动化学报, 2014, 40(12):2908-2915 http://www.aas.net.cn/CN/abstract/abstract18568.shtmlZhou Xiao-Jian. Enhancing ε-support vector regression with gradient information. Acta Automatica Sinica, 2014, 40(12):2908-2915 http://www.aas.net.cn/CN/abstract/abstract18568.shtml [59] 曹鹏飞, 罗雄麟.基于Wiener结构的软测量模型及辨识算法.自动化学报, 2014, 40(10):2179-2192 http://www.aas.net.cn/CN/abstract/abstract18493.shtmlCao Peng-Fei, Luo Xiong-Lin. Wiener structure based modeling and identifying of soft sensor systems. Acta Automatica Sinica, 2014, 40(10):2179-2192 http://www.aas.net.cn/CN/abstract/abstract18493.shtml [60] 钱富才, 黄姣茹, 秦新强.基于鲁棒优化的系统辨识算法研究.自动化学报, 2014, 40(5):988-993 http://www.aas.net.cn/CN/abstract/abstract18368.shtmlQian Fu-Cai, Huang Jiao-Ru, Qin Xin-Qiang. Research on algorithm for system identification based on robust optimization. Acta Automatica Sinica, 2014, 40(5):988-993 http://www.aas.net.cn/CN/abstract/abstract18368.shtml [61] Trygg J, Wold S. Orthogonal projections to latent structures (O-PLS). Journal of Chemometrics, 2002, 16(3):119-128 doi: 10.1002/(ISSN)1099-128X [62] Li G, Qin S J, Zhou D H. Output relevant fault reconstruction and fault subspace extraction in total projection to latent structures models. Industrial & Engineering Chemistry Research, 2010, 49(19):9175-9183 https://www.researchgate.net/publication/231391323_Output_Relevant_Fault_Reconstruction_and_Fault_Subspace_Extraction_in_Total_Projection_to_Latent_Structures_Models [63] Zhou D H, Li G, Qin S J. Total projection to latent structures for process monitoring. AIChE Journal, 2010, 56(1):168-178 https://www.researchgate.net/publication/229883646_Total_projection_to_latent_structures_for_process_monitoring [64] Qin S J, Zheng Y Y. Quality-relevant and process-relevant fault monitoring with concurrent projection to latent structures. AIChE Journal, 2013, 59(2):496-504 doi: 10.1002/aic.v59.2 [65] Liu Q, Qin S J, Chai T Y. Multiblock concurrent PLS for decentralized monitoring of continuous annealing processes. IEEE Transactions on Industrial Electronics, 2014, 61(11):6429-6437 doi: 10.1109/TIE.2014.2303781 [66] Bengio Y. Learning deep architectures for AI. Foundations and Trends in Machine Learning, 2009, 2(1):1-127 doi: 10.1561/2200000006 [67] Qin S J. Process monitoring in the era of big data. In:Proceeding of the 9th International Symposium on Advanced Control of Chemical Processes (ADCHEM). Plenary Talk, Whictler, British Columbia, Canada:IFAC, 2015. [68] Fu T C. A review on time series data mining. Engineering Applications of Artificial Intelligence, 2011, 24(1):164-181 doi: 10.1016/j.engappai.2010.09.007 [69] Keogh E, Kasetty S. On the need for time series data mining benchmarks:a survey and empirical demonstration. Data Mining and Knowledge Discovery, 2003, 7(4):349-371 doi: 10.1023/A:1024988512476 [70] Rakthanmanon T, Campana B, Mueen A, Batista G, Westover B, Westover B, Zhu Q, Zakaria J, Keogh E. Addressing big data time series:mining trillions of time series subsequences under dynamic time warping. ACM Transactions on Knowledge Discovery from Data, 2013, 7(3):Article No.10 https://www.researchgate.net/publication/262394370_Addressing_Big_Data_Time_Series_Mining_Trillions_of_Time_Series_Subsequences_Under_Dynamic_Time_Warping [71] Jegou H, Douze M, Schmid C, Perez P. Aggregating local descriptors into a compact image representation. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA:IEEE, 2010. 3304-3311 [72] Yuan T, Qin S J. Root cause diagnosis of plant-wide oscillations using Granger causality. Journal of Process Control, 2014, 24(2):450-459 doi: 10.1016/j.jprocont.2013.11.009 [73] Kadlec P, Gabrys B, Strandt S. Data-driven soft sensors in the process industry. Computers & Chemical Engineering, 2009, 33(4):795-814 http://www.sciencedirect.com/science/article/pii/S0098135409000076 [74] Suykens J A K, de Brabanter J, Lukas L, Vandewalle J. Weighted least squares support vector machines:robustness and sparse approximation. Neurocomputing, 2002, 48(1-4):85-105 doi: 10.1016/S0925-2312(01)00644-0 [75] 张淑宁, 王福利, 何大阔, 贾润达.在线鲁棒最小二乘支持向量机回归建模.控制理论与应用, 2011, 28(11):1601-1606 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201111012.htmZhang Shu-Ning, Wang Fu-Li, He Da-Kuo, Jia Run-Da. Modeling method of online robust least-squares-support-vector regression. Control Theory & Applications, 2011, 28(11):1601-1606 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201111012.htm [76] Mackey L W, Talwalkar A, Jordan M I. Divide-and-conquer matrix factorization. Advances in Neural Information Processing Systems, 2011, 24:1134-1142 http://bigdata2013.sciencesconf.org/conference/bigdata2013/pages/mackey.pdf [77] Candés E J, Li X D, Ma Y, Wright J. Robust principal component analysis. Journal of the ACM, 2011, 58(3):Article No.11 http://lagrange.math.siu.edu/Olive/pprpca.pdf [78] Mahoney M W. Randomized algorithms for matrices and data. Foundations and Trends in Machine Learning, 2011, 3(2):123-224 http://www.sfbayacm.org/sites/default/files/rafmad1.pdf 期刊类型引用(3)
1. 岳振宇,范大昭,董杨,纪松,李东子. 一种星载平台轻量化快速影像匹配方法. 地球信息科学学报. 2022(05): 925-939 .  百度学术
百度学术2. 王若兰,潘万彬,曹伟娟. 图像局部区域匹配驱动的导航式拼图方法. 计算机辅助设计与图形学学报. 2020(03): 452-461 . 百度学术3. 胡敬双,聂洪玉. 灰度序模式的局部特征描述算法. 中国图象图形学报. 2017(06): 824-832 . 百度学术其他类型引用(9)
-

 下载:
下载:
 下载:
下载:
计量
- 文章访问数: 3670
- HTML全文浏览量: 387
- PDF下载量: 3814
- 被引次数: 12
