

A Video Co-segmentation Algorithm by Means of Maximizing Submodular Function and RRWM
-
摘要: 成对视频共同运动模式的协同分割指的是同时检测出两个相关视频中共有的行为模式,是计算机视觉研究的一个热点.本文提出了一种新的成对视频协同分割方法.首先,利用稠密轨迹方法对视频运动部分进行检测,并对运动轨迹进行特征表示;然后,引入子模优化方法对单视频内的运动轨迹进行聚类分析;接着采用基于重加权随机游走的图匹配方法对成对视频运动轨迹进行匹配,该方法对出格点、变形和噪声都具有很强的鲁棒性;同时根据图匹配结果实现运动轨迹的共显著性度量;最后,将所有轨迹分类成共同运动轨迹和异常运动轨迹的问题转化为基于图割的马尔科夫随机场的二值化标签问题.通过典型运动视频数据集的比较实验,其结果验证了本文方法的有效性.Abstract: Co-segmentation of common motion pattern in a pair of videos aims to detect and segment common motion pattern of the two videos simultaneously, which has become a new hotspot in computer vision. We propose a novel method to address the problem. Firstly, we detect the movement part of the video using dense trajectories and represent the movement trajectory characteristic. Then we introduce submodular function is to group these dense trajectories in the single video. Furthermore, reweighted random walks for graph matching (RRWM) is used to match the obtained trajectory clusters in different videos, which is the robust to noise, outlier, and deformation. And the trajectory co-saliency is measured according to the matching results of RRWM. Finally, classify the trajectories into common motion trajectories and outlier motion trajectories; we formulate the problem as a binary labeling of a Markov random field (MRF) based on graph cut. Experimental results on the benchmark datasets show the effectiveness of the proposed approach.
-
Key words:
- Dense trajectories /
- submodular function /
- graph matching /
- co-saliency /
- Markov random field
-
图像分割是计算机视觉领域的一个基本问题.传统图像分割只是从单一视角对图像进行块划分, 其分割的有意义性不强, 分割效果也很难评判.而同时考虑成对或多幅图像, 利用不同图像间的互补信息进行协同分割已引起了相关学者的广泛兴趣[1-4], 例如Rother等[1]首先将协同分割思想引入到图像分割领域; 文献[2]进一步研究了基于图像对象的协同分割, 该方法目的是提取成对图像中相似的对象; 文献[3-4]将成对图像分析扩展到多幅图像处理, Cao等[3]应用低秩分解去探索多个显著性映射之间的关系以获得自适应权重, 基于这些权重提出了显著性映射融合框架, 在多幅图像中探测共显著性区域以实现相似对象的最终分割; 针对低水平图像特征表达不同状态下对象能力的不足, 以及相似背景与对象均出现在同组的多幅图像中, 于是卷积神经网络学习方法被提出去抓取图像分类与分割概念的深度信息, 以及利用不同组视觉相似图像(具有相似背景)间的宽度信息以促进共显著性映射[4].这些方法的结果普遍优于基于单幅图像分割方法, 从而证明了协同分割思想的优越性.
视频分割作为后续视频处理的一个关键步骤, 已被进行了广泛研究, 然而已有的许多工作[5-7]都是基于单视频分割, 常需要用户提供前景和背景抽样, 或者纠正分割错误, 同时也有其内在局限性, 例如单个视频仅反映出部分视角, 无法预测分割的意义, 外观或运动模式的偶然相似可能导致一个模糊甚至错误的划分; 另外, 单视频的分割不能有效反映分割区域间的结构信息.针对上述不足及受到图像协同分割思想的启发, 类似地利用多个相关视频信息进行相互补充来进行分割, 使之能够提供一个更好的、更有意义的划分.但是到目前为止, 基于多视频协同分割的相关工作并不多见[8-16], 且绝大部分工作集中在相同或相似对象的定位与分割, 对于对象的协同定位[8-9], Prest等[9]考虑了一组图像或视频信息, 结合时间项与相关约束条件进入一个二次规划框架, 通过引入Frank-Wolfe算法, 最终将对象的协同定位问题转化为求解一个简单的整数规划问题; 这两种方法均利用了边界框来定位对象将可能导致定位的不够精确, 于是文献[10]提出了一种基于运动信息的视频分割方法在成对视频中寻找共同的前景区域; 基于相似视频间的互补信息, Rubio等[11]从多个视频中分割出相同或同类对象, 然而这两种方法对分割对象都提出了很强假设, 从而限制了它们的应用.针对二元与相似对象协同分割难以满足现实需求, 文献[12]提出了基于视频分割先验的非参数贝叶斯模型, 实现了多类对象的视频协同分割; 近来, 有些方法[13-14]提出了高水平特征——Object proposal, 直接处理这些可能的对象区域实现协同分割, 从而避免了在复杂背景下低水平特征(颜色、纹理等)的局限性; 通过结合帧内显著性、帧间一致性和视频间的相似性信息来构建一个能量优化框架, 这种方法[15]不用对前景外观和运动模式做出严格前期假设.相对于相似对象或前景/背景的视频协同分割, 针对有意义的共同运动模式的提取研究极少, 文献[16]对每个视频采用稠密轨迹进行运动跟踪, 通过成对视频轨迹聚类间的运动轨迹匹配记分来度量视频中共同运动模式的显著性水平以实现视频共同运动模式的分割.由于共同运动模式协同分割对促进视频检索、行为识别等相关方面的研究有积极作用, 基于文献[16]的工作, 本文提出了一种新的成对视频共同运动模式提取方法.
本文首先利用高效的基于光流场的稠密轨迹方法对视频进行运动跟踪, 稠密轨迹对视频信息的有效覆盖与产生的数据规模进行了有效折中, 相对于稀疏兴趣点轨迹法有明显的优势[17]; 接着引入子模函数优化方法来实现视频内运动轨迹的聚类分析, 子模函数优化类似于连续凸优化的离散化形式, 已应用于文本摘要、图像检索、视频摘要等多个领域[18-21], 其解能够以一个常数因子逼近最优解; 然后针对传统图匹配[22]对噪声、出格点和变形敏感, 本文运用RRWM方法[23]实现成对视频轨迹簇间运动轨迹的图匹配, 获取不同视频轨迹簇间的匹配计分, 进而计算出视频运动轨迹的共显著性表达水平; 最后将成对视频中共同运动模式的协同分割看成是基于马尔科夫随机场的一个二值标签问题, 即将两视频所有运动轨迹分类成共同运动模式和异常运动模式, 其中数据项惩罚具有低的共显著性表达水平的运动轨迹, 平滑项惩罚单个视频内具有不同标签的相邻运动轨迹.本文主要贡献有: 1)提出了新的子模函数优化方法聚类视频运动轨迹, 并给出求解的贪婪算法流程, 其聚类结果能够在多项式时间内完成且以常数因子 $(1-1/{\rm e})$ 逼近最优解, 而时间复杂度相对于谱聚类有显著降低. 2)将RRWM算法应用于不同视频中轨迹聚类簇间的匹配, 该算法能够有效抑制噪声、出格点和变形对图匹配的影响, 同样在时间复杂度上相对于传统图匹配也有显著改善. 3)对于单个视频内轨迹间的亲近度度量和不同视频的轨迹聚类簇间的图匹配, 相对于文献[16], 分别提出了不同的改进方法, 引入权重因子反映轨迹间空间距离和速率估计对轨迹间的近亲关系的影响(详见后文式(4)); 同时融入了轨迹本身信息、轨迹对信息以及时间信息, 通过计算轨迹对在共存时间内相对变化幅度和相对变化方向的均值与方差来衡量待匹配轨迹间的一致性(详见后文式(7)).
1. 稠密轨迹提取
为了获取视频中的运动信息, 特征轨迹已经被证明可以作为一种有效的视频表达方式, 相对于KLT追踪方法或特征点匹配方法, 稠密轨迹追踪方法在轨迹质量和量化方面更有优势[17], 本文依据文献[17]对相关参数的对比分析结果, 采用类似参数设置, 即对视频中的每帧, 以 $1/2$ 为尺度因子, 采样间隔为4个像素, 即 $d=4$ , 轨迹长度为 $L=15$ , 分别在 $8$ 个尺度上进行轨迹追踪以获得运动轨迹数据, 这些轨迹包含: 1)异常运动轨迹; 2)背景运动轨迹; 3)共同运动轨迹.在此将异常运动轨迹和背景运动轨迹统称为异常运动轨迹, 而本文主要研究内容为提取成对视频中共同运动轨迹.
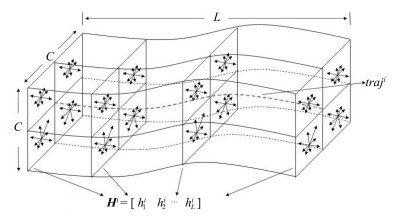
利用局部描述子表达视频中的兴趣点或时空体已经变得越来越流行, 而视频中不可避免地融入了摄像机运动.因此本文对于给定的轨迹将采用运动边界直方图(Motion boundary histogram, MBH)[24]来构建轨迹的特征表示, 该特征是基于光流场水平分量与竖直分量的导数计算得到, 能够有效消除摄像机运动影响.首先给定轨迹 $traj^{i}$ , 其长度为 $L=15$ , 以轨迹 $traj^{i}$ 为中心, 形成 $C\times C\times L$ 的空间立方体, 其中 $C=32$ 个像素, 对每帧 $C\times C$ 的局部区域进行 $2\times 2$ 网格划分, 在每个单元里根据像素空间导数模值与方向得到 $8$ 维直方图特征并进行 $L_2$ 模归一化, 接着对水平分量与竖直分量上共 $8$ 个单元的特征进行级联得到MBH描述子, 维数为 $64$ , 则轨迹 $traj^i$ 在长度 $L$ 上的MBH特征表示为 ${\pmb H}^i$ $=$ $[h^i_1$ $h^i_2$ $\cdots$ $h^i_L]$ , 直观表示如图 1.
2. 视频协同分割
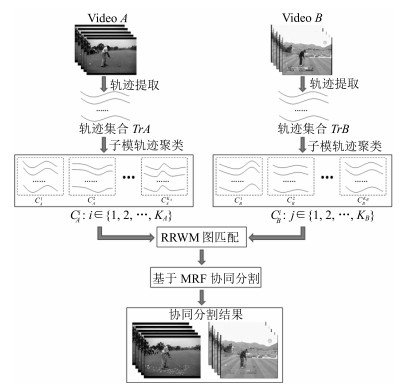
在这里, 视频协同分割的目的是萃取成对视频中共有的运动模式, 利用稠密的视频轨迹表达视频, 不仅有效保留了视频内容信息, 而且也极大降低了基于像素级处理的规模, 图 2给出了本文算法的流程图.
首先, 对于输入的成对视频 $A$ 与 $B$ , 运用稠密轨迹追踪方法提取稠密特征轨迹( $TrA$ 和 $TrB$ ); 接着引入子模优化方法实现稠密轨迹的聚类以便于后续图匹配的处理, 获得视频 $A$ 和 $B$ 的轨迹聚类表示为 $\{ C^1_A, C^2_A, \cdots, C^{K_A}_A \}$ 和 $\{ C^1_B, C^2_B, \cdots, C^{K_B}_B \}$ ; 为了得到 $C^i_A$ 和 $ C_B^j$ 的对应性, 我们采用RRWM算法给不同视频中轨迹聚类子集进行匹配打分; 最后基于马尔科夫随机场的能量最小化获取共同运动模式的协同分割, 图 2中两视频共有运动模式为一个人打高尔夫球(以较深的灰度点标记).以下将对轨迹聚类、图匹配、能量最小化协同分割部分进行介绍.
2.1 轨迹聚类
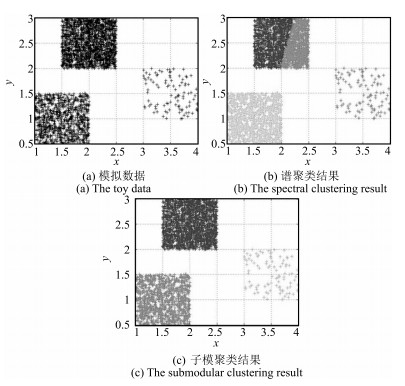
相对于传统聚类方法 $K$ -means、GMM等表现出的不足, 例如计算量大、陷入局部最优解等, 一些新的聚类算法已经被提出, 例如谱聚类、子模聚类; 谱聚类利用了图谱理论, 虽然谱聚类能够获取样本的主要特征, 对噪声具有一定的鲁棒性, 然而对于大规模数据, 高复杂度将使谱聚类变得不可行, 因此本文选用近来提出的子模优化方法进行聚类, 在聚类效果、时间和空间复杂度方面, 都有很好的表现, 如图 3所示, 通过谱聚类与子模聚类算法分别对模拟数据( $3\, 100$ 点)聚类, 可以发现子模聚类效果最好且完成聚类时间仅为 $0.842778\, {\rm s}$ , 而相同条件下, 谱聚类耗时 $23.208819\, {\rm s}$ .
下面给出子模函数定义:设 $V$ 为有限数据集, $2^V$ 表示由 $V$ 中的元素组成的子集的集合, 记集合函数 $f:2^V\rightarrow R$ , 使得任意 $S\subseteq V$ 对应一个实数, 同时对任意 $S\subseteq R\subseteq V$ 且 $s\in V\backslash R$ , 式(1)都成立, 则称集合函数 $f(\cdot)$ 为子模函数[25].
$ f\left(R\cup \{s\}\right)-f(R) \leq f(S\cup \{s\})-f(S) $
(1) 式(1)即为子模函数的效益递减属性, 即增加一个元素到一个小集合产生的效益不小于将其加入到一个大集合所产生的效益.本文采用了设施选址问题中的子模函数模型并加入了惩罚项, 如式(2)所示:
$ \begin{align} &f_{p{\text{-}}{\rm facility}}(S)=\sum_{i \in V}\max\limits_{j\in S}(w_{i,j})-\lambda \times \sum_{i,j \in S}w_{i,j} \notag \\ &\,{\rm s.t.}\quad S \subseteq V, ~~ |S|=K \end{align} $
(2) 由于设施选址作为经典的子模函数优化问题, 惩罚项 $-\lambda \times \sum_{i, j \in S}W_{i, j}$ 的子模性证明较简单, 见文献[18], 在本文中 $\lambda$ 设置为 $30$ .由于子模满足可加性, 因此 $f_{p{\text{-}}{\rm facility}}$ 也为子模函数.一般情况下, 通过最大化子模函数获得最优解是一个NP难问题, 但是当 $f(\cdot)$ 满足: 1)非降性, 对 $S_1 \subseteq S_2 \subseteq V$ , $f(s_1)$ $\leq$ $f(s_2)$ ; 2)正则性, $f(\emptyset)=0$ ; 3)子模性.则存在一个简单的贪婪算法能在一个多项式时间内以常数因子 $( 1-{1}/{\rm e} )$ 逼近问题的最优解[26].
给定一个视频 $V$ , 轨迹 $traj^i=\{ (x_l^i, y_l^i) | l=1$ , $2, \cdots, L \}$ 为一个有序数对集合, $(x_l^i, y_l^i)$ 为第 $i$ 条轨迹在 $l$ 帧上的坐标位置.记轨迹集合 $Tr=\{ traj^1$ , $traj^2$ , $\cdots, traj^M \}$ , $M$ 为轨迹数, 为了将 $V$ 中轨迹划分成 $K$ 个子集, 本文采用基于最大化子模函数的方法进行轨迹聚类, 该方法能够获得一个常数因子逼近的最优解, 聚类及优化过程如下:
步骤1. 初始化轨迹聚类中心集合 $S$ , $\lambda$ , 其中 $S$ 设置为空集 $\emptyset$ ;
步骤2. 遍历所有轨迹, 根据式(3)获得使目标函数最大化的轨迹 $s^*$
$ s^* \in \arg\max\limits_{s \in V \setminus S } f(S \cup \{ s\})-f(S) $
(3) 步骤3. 将 $s^*$ 添加元素到 $S$ 中, 并重复步骤2直到 $|S|=K$ , 即为 $K$ 个聚类中心;
步骤4. 计算所有轨迹到 $S$ 中 $K$ 个中心的距离, 如果 $traj^i$ $(i=1, 2, \cdots, M)$ 轨迹离中心 $s_k$ $(k$ $=$ $1$ , $2$ , $\cdots, |S|)$ 越近, 则 $traj^i$ 和 $s_k$ 属于同一类.
下面就复杂度展开分析, 对于视频轨迹数据, 其规模通常成千上万, 因此在考虑聚类效果的同时, 复杂度的考虑也非常重要.以下从子模聚类和谱聚类的理论算法上简单分析各自的复杂度:假设有 $M$ 条轨迹需要聚类, 每个样本点 $P$ 维, 聚类数为 $K$ , 由于两者都需要先构建邻接关系矩阵, 所以这部分复杂度不予考虑.
时间复杂度: 1)谱聚类, 当 $M$ 维关系矩阵构建完成后, 需要对该矩阵进行特征值分解, 这一个过程的时间复杂度为O $(M^3)$ , 通过提取前 $p'$ $(p'<M)$ 个最小特征向量, 利用 $K$ -means对特征向量数据进行聚类, 由于特征向量数据与样本数据对应, 最终完成 $K$ 类样本数据的划分, $K$ -means聚类过程时间复杂度为O $(T\times K\times M)$ ( $T$ 为迭代次数), 总的时间复杂度为O $(M^3)$ + O $(T\times K\times M)$ ; 2)子模聚类, 同样先构建 $M$ 维的邻接关系矩阵, 设置初始集合 $S=\emptyset$ (用来保存 $K$ 个聚类中心), 对矩阵进行行扫描(第 $i$ 行数据代表 $i$ 样本与所有样本之间的亲近关系), 计算该行元素之和, 共进行了 $M-1$ 次加法运算, 选取收益最大的行, 于是将对应行号的样本加入到 $S$ 中, 其时间复杂度为O $(M^2)$ , 接着重复进行行扫描, 寻找次小收益的样本加入 $S$ , 依次类推, 直到 $|S|= K$ 时结束, 共循环 $K$ 次得到 $K$ 个聚类中心, 最后通过度量各个样本与 $K$ 个中心的距离实现所有样本的划分, 其时间复杂度为O $(K\times M)$ , 则总的时间复杂度为O $(kM^2)$ + O $(K\times M)$ .此外, 当邻接关系矩阵构建完成后, 子模聚类过程涉及到的主要是加法运算, 相对于谱聚类, 子模聚类更有效率.
空间复杂度:通过时间复杂度分析, 子模聚类需要的存储空间主要用于保存邻接关系矩阵, 而谱聚类在特征值分解过程中需要的存储空间远大于子模聚类.
最后给出式(2)中轨迹关系矩阵 $W=(w_{i, j})_{M \times M}$ , 通过考虑两因素——特征点在轨迹上的速率差异及特征点轨迹间的最大空间距离来度量其运动模式的相似性, 即速率差异和空间距离越小越相似, 对于将两种因素直接相乘的结合方式, 虽然能够反映轨迹间的相似性, 但是这种无差别对待将无法有效地评价两种因素对关系度量的贡献[19], 而经本文发现, 速率的影响通常比空间距离的影响大, 这也正好符合了本文针对的数据特点——运动轨迹数据.因此, 本文引入了权重因子 $\theta$ 来反映两种因素的影响, 对于视频 $V$ 中的任意两条轨迹 $traj^i$ 和 $traj^j$ , 共存时间为 $[\tau_1, \tau_2]$ , 则轨迹间的距离度量如下:
$ \begin{align} &d^{ij}_{\rm intra}= \theta\times \max\limits_{t\in [\tau_1~\tau_2]}d^{ij}_{\rm spatial}[t]\,+\notag\\ &\qquad\quad (1-\theta)\times \frac{1}{\tau_2-\tau_1}\sum_{k=\tau_1}^{\tau_2}d^{ij}_{\rm velocity}[k]\notag\\[2mm] & d^{ij}_{\rm velocity}[t]=\left|v^i[t]-v^j[t]\right|_2\notag\\[2mm] & v^i[t]= traj^i[t]-traj^i[t-1]\notag\\[2mm] & d^{ij}_{\rm spatial}[t]=\left| traj^i[t]-traj^j[t] \right|_2 \end{align} $
(4) 其中, $d^{ij}_{\rm spatial}[t]$ , $d^{ij}_{\rm velocity}[t]$ 和 $v^i[t]$ 分别表示轨迹 $traj^i$ 和 $traj^j$ 在 $t$ 时刻的空间欧氏距离、速率差异和速度, 经实验验证 $\theta=0.1$ 时能够有效反映轨迹间的相似度.接着, 利用高斯函数对轨迹间的距离进行变换以反映轨迹对的亲近性 $w(i, j)$ .
$ \begin{align} w(i,j)= \begin{cases} \exp(-d^{ij}_{\rm intra}),& \max\limits_{t \in [\tau_1~\tau_2]}d^{ij}_{\rm spatial}[t] \geq 30\\[2mm] 0,&\mbox{否则} \end{cases} \end{align} $
(5) 子模聚类算法的详细流程见算法1.
算法1.子模聚类算法
1. Input:对应轨迹集合 $Tr$ 的序号集合 $Index_{Tr}=$ $[1$ , $2$ , $\cdots, M]$ , $M$ 为轨迹数, 轨迹间边集 $E$ 及对应边权矩阵 $W$ , 聚类数 $K$ , 参数 $\lambda$ .
2. Initialization: $S=\emptyset$ , $Q=[q_1, q_2, \cdots, q_M]$ , $q_i=$ $0$ , $i=1, 2, \cdots, M$ }.
3. while { $|S| \leq K$ } do
4.
5.{ $S\leftarrow S\cup \{s^*\}$ }
6. for all { $i\in Index_{Tr}$ } do
7. $q_i=\max\{q_i, w_{i, s^*}\}$
8. end for
9. end while
10. for all { $traj^j \in Tr$ } do
11. $CLASSLabel_{traj^j}=\arg\max\limits_{s\in S}w_{s, j}$
12. end for.
2.2 RRWM匹配
对于聚类后的 $Tr_A$ 和 $Tr_B$ 分别记为 $C_A=$ $\{ C^1_A$ , $C_A^2$ , $\cdots, C^{K_A}_A\}$ 和 $C_B=\{ C^1_B, C_B^2, \cdots, C^{K_B}_B\}$ , $C_A^h$ , $C^h_B$ 分别表示视频 $V_A$ 第 $h$ 个和 $V_B$ 第 $k$ 个轨迹聚类, $K_A$ 为聚类数; 接着本文采用一种新的、有别于传统谱匹配的方法[22]——基于重加权随机游走的图匹配方法RRWM[23]实现 $C_A^h$ 和 $C^h_B$ 内轨迹间的匹配.
首先, 按式(6)计算 $Tr_A$ 与 $Tr_B$ 中轨迹间的距离并排序选取距离最小的前 $0.01\, \%$ 个轨迹对, 分别统计落入 $C_A$ 和 $C_B$ 不同聚类中的轨迹数目并将这些轨迹作为后续该聚类的有效数据进行匹配计算, 如果数目大于等于2, 则可以进行后续计算; 对于数目小于2的, 则匹配计分记为 $0$ .
$ d_{\rm inter}(traj^i_A, traj^j_B)=\| \pmb F_A^i-{\pmb F}^j_B \| $
(6) 其中, $\tilde{F}^i=\frac{1}{L}{\pmb H}^i({\pmb H}^i)^{\rm T}$ , ${\pmb H}^i$ 为轨迹 $i$ 的MBH描述子, 于是取矩阵 $\tilde{F}^i$ 的上三角元素依次排列形成向量 ${\pmb F}^i$ $=$ $[\tilde{F}^i_{11}, \tilde{F}^i_{12}, \cdots, \tilde{F}^i_{1d}, \tilde{F}^i_{22}, \tilde{F}^i_{23}, \cdots, \tilde{F}^i_{dd}]$ , 作为轨迹 $i$ 的特征表示, 该特征不仅包含了单个时间帧的特征信息, 还包括了 $L$ 长度内不同帧之间的互信息.
接着, 为了匹配 $C_A^h$ 和 $C^h_B$ 中的轨迹, 本文提出了一种新的基于视频轨迹的成对亲和矩阵 $M$ 构建方法, 该矩阵融入了一元特征信息和二元成对特征互信息, 其中 $m_{ab, a'b'}$ 表示对应轨迹 $a\rightarrow b$ 与 $a'$ $\rightarrow$ $b'$ 的亲和度, 计算方式见式(7), 其中 $a, a'\in Tr_A$ , $b$ , $b'$ $\in$ $Tr_B$ , $a\rightarrow b$ 表示轨迹 $a$ 与轨迹 $b$ 匹配.
$ \begin{align} &m_{ab,a'b'}=\exp\left(-( |\mu_{D_{a,a'}}-\mu_{D_{b,b'}}|~+ \right.\notag\\ &\qquad\ |s_{D_{a,a'}}-s_{D_{b,b'}}|+|\mu_{R_{a,a'}}-\mu_{R_{b,b'}}|~+\notag\\ &\qquad \left. |s_{R_{a,a'}}-s_{R_{b,b'}}|)\right)\notag\\[1mm] &\mu_{D_{a,a'}}=\frac{1}{T}\sum_{t=1}^{T}\frac{d^t_{a,a'}}{d^{\rm max}_{a,a'}}\notag\\ &s_{D_{a,a'}}=\sqrt{\frac{1}{T-1}\sum_{t=1}^{T}\left(d^t_{a,a'}-\mu_{D_{a,a'}}\right)}\notag\\ &\mu_{R_{a,a'}}=\frac{1}{T}\sum_{t=1}^{T}\frac{r^t_{a,a'}}{r^{\rm max}_{a,a'}}\notag\\ &s_{R_{a,a'}}=\sqrt{\frac{1}{T-1}\sum_{t=1}^{T}\left(r^t_{a,a'}-\mu_{R_{a,a'}}\right)} \end{align} $
(7) 式中 $\mu_{D_{b, b'}}$ , $s_{D_{b, b'}}$ , $\mu_{R_{b, b'}}$ , $s_{R_{b, b'}}$ 同理可求.其中, $D_{a, a'}$ $=$ $[d^1_{a, a'}\ d^2_{a, a'}\ \cdots\ d^T_{a, a'}]$ 表示轨迹 $a$ 与 $a'$ 在共存时间 $T=\tau_1-\tau_2$ 内在各帧上的欧氏距离集合, $R_{a, a'}$ $=$ $[r^1_{a, a'}\ r^2_{a, a'}\ \cdots\ r^T_{a, a'}]$ 为共存时间内各帧上以 $a$ 和 $a'$ 形成的向量与水平方向形成的夹角, $d^{\rm max}_{a, a'}=\max\nolimits_{t\in[\tau_1 \tau_2]} \{ d^t_{a, a'} \}$ , $r^{\rm max}_{a, a'}=\max\nolimits_{t\in [\tau_1 \tau_2]}\{ r^t_{a, a'} \}$ .然后, 通过RRWM方法求匹配指示向量, 主要包括膨胀和双随机正规化的迭代过程, 迭代方程如下:
$ \begin{align} &\left({\pmb X}^{(n+1)T}, x^{(n+1)T}_{abs}\right) =\notag\\ &\qquad\rho\left({\pmb X}^{(n)T},x^n_{abs}\right)\left( \begin{array}{cc} \frac{M}{D_{\max}} & \frac{1-{\pmb d}}{D_{\max}} \\ 0 & 1 \\ \end{array} \right)\,+\notag\\ &\qquad(1-\rho)\left(f_c\left({{\pmb X}^{(n)T}M}\right),0\right),\notag\\[1mm] &\qquad\qquad\qquad\quad\ \ \ \ D_{\max}=\max\limits_{d_i\in\pmb d}d_i,~~ d_i=\sum_j{m_{i,j}} \end{align} $
(8) 其中, $x_{abs}$ 为吸收节点, $\rho$ 是重加权因子(本文设定为0.2), 上标 $n$ 表示迭代次数, $f_c(\cdot)$ 为融入了双向约束的重加权函数, ${\pmb X}$ 即为所要求的匹配指示向量, 初始值为等概率分布, 最后通过贪婪算法离散化 ${\pmb X}$ 并满足 ${\pmb X}\in{\{0, 1\}}^{|C^h_A||C^k_B|}$ , $|C^h_A|$ 和 $|C^k_B|$ 分别为元素基数.由于求解过程中融入了双向约束条件: $\forall\, b$ , $\sum\nolimits^{|C^h_A|}_{a=1}X_{ab}$ $\leq$ $1$ , $\forall\, a$ , $\sum\nolimits^{|C^k_B|}_{b=1}X_{ab}\leq 1$ , 避免了谱匹配方法容易产生一个局部最优解的情形, 具体细节见文献[11].于是可以得到 $C^h_A$ 和 $C^k_B$ 的匹配计分:
$ Score{\left(C^h_A, C^k_B\right)}=\frac{1}{|C^h_A|+|C^k_B|}\times {{\pmb X}^{\rm T}M{\pmb X}} $
(9) RRWM获取匹配解为一个迭代过程, 其时间复杂度为O $(|E^{C^h_A}|\times{|E^{C^k_B}|})$ , $|E^{C^h_A}|$ , $|E^{C^k_B}|$ 分别为聚类 $C^h_A$ 和 $C^k_B$ 中以轨迹为顶点形成完全图的边的数目, 远低于基于特征值分解的传统图匹配过程.
2.3 共显著性度量与协同分割
为了方便比较, 采取了与文献[16]类似方法, 算法描述如下:
共显著性度量:通过RRWM方法实现了视频 $V_A$ 与 $V_B$ 中轨迹匹配, 于是按下式计算运动轨迹的共显著性并归一化到[0, 1].
$ \begin{align} &CS\left(traj^i_A\right)=\notag\\ &\qquad \max\limits_{C^k_B\in{C_B}}Score\left(C^h_A,C^k_B\right), \ \ traj^i_A\in{C^h_A} \end{align} $
(10) 协同分割:将成对视频中的轨迹分类为共同运动模式和异常运动模式两部分, 该问题可以转化为基于马尔科夫随机场的二值标签问题.本文通过构造包含数据项与平滑项的能量函数, 借助图割算法[27]使得能量最小化以达到视频协同分割的目的.
$ \begin{align} &\min\limits_fE_{AB}(f)=E_A(f)+E_B(f),\notag \\[1mm] &\ \ E_A(f)=\sum\limits_{traj^i_A,traj^j_A\in{Tr_A},traj^i_A,traj^j_A\in{NS}}S\left(f_i,f_j\right)+\notag\\ &\ \ \qquad \eta\times\sum\limits_{traj^i_A\in{Tr_A}}D\left(f_i\right),\notag\\ &\ \ E_B(f) ~~ {\rm similar\ to}~~ E_A(f) \end{align} $
(11) 其中, $f:traj^i_A\rightarrow\sigma\in\{0, 1\}$ 为贴标签函数, $\eta$ 为数据项权重因子, $\eta=50$ , $NS$ 为邻域系统, 利用狄洛尼三角剖分确定轨迹 $traj^i_A$ 和 $traj^j_A$ 是否是邻接对, 即是否属于 $NS$ ; 平滑项 $S\left(f_i, f_j\right)$ 用于约束邻近轨迹的标签应具有一致性, 体现了分割区域内部的连续性与边界的不连续性.
$ S\left(f_i, f_j\right)=\left(1-\delta_{\sigma^i, \sigma^j}\right){\rm exp}\left({-d^{i, j}_{\rm intra}}\right) $
(12) 数据项 $D(f_i)$ 表示轨迹贴标签代价, 惩罚标记低共显著性的轨迹为共同运动模式:
$ \begin{align} D(f_i)=&\ \delta_{\sigma,1}(1-\max(0,flag_i))\,+\notag\\ &\ \delta_{\sigma,0}\max(0,flag_i),\nonumber\\[1mm] &\qquad flag_i={\rm sgn}(CS(traj^i)-\gamma) \end{align} $
(13) 其中, $\delta_{\cdot, \cdot}$ 为克罗内克尔符号, 即如果 $\sigma_1=\sigma_2$ , 则 $\delta_{\sigma_1, \sigma_2}$ $=$ $1$ ; 反之, 如果 $\delta_{\sigma_1, \sigma_2}=0$ , 则 $\gamma$ 为共显著性阈值, 其取值在后文讨论.
3. 实验结果与分析
3.1 实验数据
本文将采用类似于文献[16]的方法, 分别从UCF50数据集和HMDB51数据集1中选取42个视频对和20个视频对, 两个数据集均为公开数据集, 包含了多种运动模式的视频, 本文所选视频对中既有共有运动模式, 也有异常运动部分. 表 1给出了运动类别与数量, 同时本文对所选视频中的运动对象进行了边界框标定(见图 4).
1http://www.bookmetrix.com/detail/chapter/1c0723ad-9aaf-4374-880a-5335802e1e27#downloads
 图 4 Bench press类中视频轨迹聚类与匹配结果Fig. 4 The clustering and matching results of video trajectories表 1 运动标签与其对应的视频对的数量Table 1 Action tags and the corresponding number of pairs of sequences
图 4 Bench press类中视频轨迹聚类与匹配结果Fig. 4 The clustering and matching results of video trajectories表 1 运动标签与其对应的视频对的数量Table 1 Action tags and the corresponding number of pairs of sequences运动类型 数量 Basketball shooting 6 Bench press 8 Clean and jerk 5 Jumping rope 8 Lunges 6 Rope climbing 5 Pommel horse 4 Golf 6 Pullup 4 Pushup 3 Ride bike 7 3.2 实验结果与分析
首先, 本文选取Bench press类中的一个视频对为例, 通过聚类稠密轨迹后对两视频间的聚类簇中的轨迹进行图匹配, 图 5给出了本文方法(Submodular + RRWM)与文献[16]方法(Spectral clustering + graph matching, SC + GM)的聚类和匹配结果.
 图 5 Bench press类中视频轨迹聚类与匹配结果Fig. 5 The clustering and matching results of video trajectories
图 5 Bench press类中视频轨迹聚类与匹配结果Fig. 5 The clustering and matching results of video trajectories图 5中第1列和第2列为Submodular + RRWM方法结果, 每帧图像中的深灰色点为轨迹聚类簇之一; 浅灰色点为其他聚类簇, 不同视频中聚类簇间轨迹的匹配点由直线连接, 同时附上匹配计分(Score); 同理, 第3列和第4列为SC + GM方法得到的结果, 解释同前两列一样.其中第1行4幅图中的深灰色点显示了不同视频中相似对象聚类情况, 从聚类效果上看, 子模函数聚类覆盖准确度和区域纯度更高, 匹配点更多, 且有更高的匹配计分; 而谱聚类效果较差, 匹配点数和匹配计分均不理想.第2行的4幅图, 显示了成对视频中不相似的运动对象或运动模式的匹配情况, 可以发现本文方法能够有效避免误匹配, 使得匹配计分更低, 甚至匹配不发生(即匹配计分为0);反观SC + GM方法, 虽然视觉上极不相似的运动模式, 但仍有匹配可能而导致误匹配.因此, 本文方法不仅可以显著提高共同运动模式的发现, 同时也能够有效抑制异常运动模式的影响.
下面对参数共显著性 $\gamma$ 和最小覆盖阈值 $\alpha$ 进行分析, 图 6给出了6个评价指标随参数变化情况.
 图 6 Bench press类中视频轨迹聚类与匹配结果Fig. 6 The clustering and matching results of video trajectories
图 6 Bench press类中视频轨迹聚类与匹配结果Fig. 6 The clustering and matching results of video trajectories直观上, 共显著性 $\gamma$ 越高, 表明成对视频中共有运动模式相似度要求越高, 导致各自视频中共有运动模式的轨迹覆盖率降低, 故COV指标具有下降趋势; 同时出格点落在边界框外的概率变少, 使得AODE指标越来越低, 即越来越好; 由于出格点的减少导致全部共同运动模式轨迹数的减少, 进而使边界框内共同运动模式的轨迹数与全部共同运动模式轨迹数的比值增加, 从而使LOC指标受 $\gamma$ 影响较小.
从图 6(a)可以看出, 在选取 $\gamma=0.2$ 时, 各指标能够较好地反映了本文方法的性能, 此时具有较高的LOC和COV指标, 同时AODE也降低到 $20\, \%$ 左右; 从图 6(b)可以看出, 当 $\alpha<0.7$ 时, 本文方法与对比方法的LOC指标变化均较缓慢, 而 $\alpha>0.7$ 时, 则都剧烈下降.因此在本文后续实验中, 如无特殊说明, 则设定 $\gamma=0.2$ , $\alpha>0.7$ .
为了验证本文算法的有效性, 我们将与其他两种方法进行比较, 与SC + GM方法[19]比较中, 采用其相同的评价策略, 即行为出格探测错误(Action outlier detection err, AODE), $AODE=$ ${n_{\rm badOuter}}/$ ${N_{\rm totalOuter}}$ , $n_{\rm badOuter}$ 表示边界框外的、被误认为是共同行为的轨迹数, $N_{\rm totalOuter}$ 表示边界框外的轨迹数, 即行为出格轨迹数, AODE主要用来评价行为出格点探测的表现; 空间定位计分(Localization score, LOC)是评价空间定位共同运动模式的表现, $LOC= =\frac{1}{T}\sum^T_{t=1}[\frac{\Lambda_t\cap\Omega_t}{\Lambda_t}\geq\alpha]$ , $\Lambda_t$ 和 $\Omega_t$ 分别表示在时刻 $t$ 属于共同运动模式的轨迹点集合和边界框内的轨迹点集合, $T$ 为共同行为持续时间长度, 即持续视频帧数, $[\cdot]$ 为一个0-1指标函数, $\alpha$ 为最小覆盖阈值; 空间覆盖计分(Coverage score, COV)定义了共同运动轨迹形成的最小矩形面积的覆盖程度, 公式为 $COV=\frac{1}{T}\sum^T_{t=1}\frac{Ar(\Lambda_t\cap\Omega_t)}{Ar_g}$ , 其中, $Ar(\cdot)$ 表示 $\Lambda_t$ $\cap$ $\Omega_t$ 形成的最小矩形面积, $Ar_g$ 为边界框的面积.
表 2中每类第1行为本文方法结果, 第2行为SC + GM结果, 指标AODE (mean)表示在共有时间帧上AODE的均值, AODE (median)为中值, 其他指标类似, 在6类运动数据集上, 本文算法在6项指标上比SC + GM方法均有提高, 对于Kayaking类, 由于划船形成水的波动在成对视频中具有相似的运动模式, 所以在度量共显著性时, 水面波动具有很高的共显著性导致与划船的运动模式一起作为共同运动模式被分割出来. 图 4给出了来自两个数据集8个类的成对视频协同分割结果, 每个类给出了一个实例, 每类中第1列为两个视频帧, 并给出了运动对象边界框(浅白色框), 第2列为第一例对应的协同分割结果, 深灰色点为共同运动模式, 浅灰色点为异常运动模式.可以看出, 本文方法对处于不同背景中的成对视频中共同运动模式进行了有效分割, 甚至具有复杂背景, 如Bench press类, 都得到很好的结果.
表 2 本文方法与SC + GM方法的实验结果对比Table 2 The experimental results of the proposed method and SC + GM类名 AODE (%, mean) AODE (%, median) LOC (%, mean) LOC (%, median) COV (%, mean) COV (%, median) Basketball 36.76 34.38 96.35 100 86.05 87.81 47.66 47.84 64.42 50 73.90 81.03 Bench press 24.10 27.47 100 100 86.57 88.49 27.34 26.56 84.09 100 75.52 81.86 Clean and jerk 31.05 30.94 100 100 73.81 82.22 30.79 33.34 94.50 100 70.40 76.31 Jumping rope 5.45 38.60 100 100 84.23 83.58 20.18 23.69 65.89 100 77.30 86.15 Lunges 28.28 31.91 89.62 100 52.78 57.58 29.31 28.48 37.65 50 65.05 83.76 Kayaking 51.62 53.68 41.50 50 64.96 69.39 42.51 43.67 42.13 50 65.48 62.60 Rope climbing 20.60 22.00 74.17 100 63.08 82.16 33.81 19.41 64.75 72.14 56.43 71.33 最后, 我们在HMDB51数据集也给出了与VCS方法[12]的比较结果, VCS方法首先对视频帧进行超像素分割, 同时对每个超像素提取外观特征、时空位置和运动信息, 用一组超像素表达视频.虽然该方法的目的与本文不一致, 但是同样也利用了运动信息.由于AODE与LOCS不适合评价VCS结果, 因此采用COV指标和互识别率(Mutual recognition, MR)对不同方法进行评价, 即方框内的共有部分(像素/轨迹)比全部协同分割出的部分(像素/轨迹).结果如表 3所示, 对于成对视频中简单的动作模式, 本文方法与SC + GM方法均能给出较好的分割结果, 像Pullup类视频.由于本文与SC + GM方法主要基于运动信息, 当观察运动的视角发生剧烈变化时(Golf类和Pushup类), 相同动作的运动模式将产生较大差异, 因此性能有所下降, 反观VCS方法, 由于融入了空间位置和外观特征信息, 所以其表现优于本文方法; 对于Ride-bike类, 目标的运动速率、位置、视角、光照条件、外观形状及大小等因素都有很大变化, 因此导致三种方法的性能均有所下降.
表 3 本文方法与其他方法的实验结果对比Table 3 The experimental results of the proposed method and other methods类名 方法 MR (%, mean) COV (%, mean) 本文方法 51.37 60.12 Golf SC + GM 50.64 58.90 VCS 48.82 54.17 本文方法 82.20 80.35 Pullup SC + GM 79.58 78.78 VCS 70.22 72.41 本文方法 47.54 52.81 Pushup SC + GM 45.61 52.97 VCS 55.34 60.15 本文方法 35.30 35.78 Ride bike SC + GM 34.62 36.35 VCS 38.45 34.56 从上述结果与对比分析可得, 在静态背景和观察视角变化不大的背景下, 利用本文方法提取成对视频中共同的运动模式是基本可行的、有效的.
4. 结论
本文提出了一种新的基于稠密轨迹的视频协同分割算法, 通过引入子模函数优化和RRWM算法, 使得相对于谱聚类与传统图匹配的结合, 无论是在空间定位精度上, 还是在时间复杂度上都有显著的提高, 同时也提出了改进的视频内轨迹亲进度度量方法和不同视频内轨迹簇间亲和矩阵构建方法, 在运动数据集上的实验结果表明了本文方法是有效的、可行的.
本文算法很容易推广到基于运动模式的不同类型视频数据和应用领域, 像动物视频、交通车辆视频以及基于这些视频的检索和分类等, 进一步的工作包括对视频检索的时域定位、具有相似运动背景的共同运动对象协同分割以及多个视频的协同分割.
-
图 4 Bench press类中视频轨迹聚类与匹配结果
Fig. 4 The clustering and matching results of video trajectories
图 5 Bench press类中视频轨迹聚类与匹配结果
Fig. 5 The clustering and matching results of video trajectories
图 6 Bench press类中视频轨迹聚类与匹配结果
Fig. 6 The clustering and matching results of video trajectories
表 1 运动标签与其对应的视频对的数量
Table 1 Action tags and the corresponding number of pairs of sequences
运动类型 数量 Basketball shooting 6 Bench press 8 Clean and jerk 5 Jumping rope 8 Lunges 6 Rope climbing 5 Pommel horse 4 Golf 6 Pullup 4 Pushup 3 Ride bike 7  下载: 导出CSV
下载: 导出CSV
表 2 本文方法与SC + GM方法的实验结果对比
Table 2 The experimental results of the proposed method and SC + GM
类名 AODE (%, mean) AODE (%, median) LOC (%, mean) LOC (%, median) COV (%, mean) COV (%, median) Basketball 36.76 34.38 96.35 100 86.05 87.81 47.66 47.84 64.42 50 73.90 81.03 Bench press 24.10 27.47 100 100 86.57 88.49 27.34 26.56 84.09 100 75.52 81.86 Clean and jerk 31.05 30.94 100 100 73.81 82.22 30.79 33.34 94.50 100 70.40 76.31 Jumping rope 5.45 38.60 100 100 84.23 83.58 20.18 23.69 65.89 100 77.30 86.15 Lunges 28.28 31.91 89.62 100 52.78 57.58 29.31 28.48 37.65 50 65.05 83.76 Kayaking 51.62 53.68 41.50 50 64.96 69.39 42.51 43.67 42.13 50 65.48 62.60 Rope climbing 20.60 22.00 74.17 100 63.08 82.16 33.81 19.41 64.75 72.14 56.43 71.33
下载: 导出CSV
表 3 本文方法与其他方法的实验结果对比
Table 3 The experimental results of the proposed method and other methods
类名 方法 MR (%, mean) COV (%, mean) 本文方法 51.37 60.12 Golf SC + GM 50.64 58.90 VCS 48.82 54.17 本文方法 82.20 80.35 Pullup SC + GM 79.58 78.78 VCS 70.22 72.41 本文方法 47.54 52.81 Pushup SC + GM 45.61 52.97 VCS 55.34 60.15 本文方法 35.30 35.78 Ride bike SC + GM 34.62 36.35 VCS 38.45 34.56
下载: 导出CSV
-
[1] Rother C, Minka T, Blake A, Kolmogorov V. Cosegmentation of image pairs by histogram matching-incorporating a global constraint into MRFs. In:Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA:IEEE, 2006. 993-1000 [2] Vicente S, Rother C, Kolmogorov V. Object cosegmentation. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI:IEEE, 2011. 2217-2224 [3] Cao X C, Tao Z Q, Zhang B, Fu H Z, Feng W. Self-adaptively weighted co-saliency detection via rank constraint. IEEE Transactions on Image Processing, 2014, 23(9):4175-4186 https://www.ncbi.nlm.nih.gov/pubmed/24968170 [4] Zhang D W, Han J W, Li C, Wang J D. Co-saliency detection via looking deep and wide. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, Massachusetts, USA:IEEE, 2015. 2994-3002 [5] Galasso F, Iwasaki M, Nobori K, Cipolla R. Spatio-temporal clustering of probabilistic region trajectories. In:Proceedings of the 2011 International Conference on Computer Vision. Barcelona, Spain:IEEE, 2011. 1738-1745 [6] 王蒙, 戴亚平, 王庆林.单目视觉下目标三维行为的时间尺度不变建模及识别.自动化学报, 2014, 40(8):1644-1653 http://www.aas.net.cn/CN/article/downloadArticleFile.do?attachType=PDF&id=18432Wang Meng, Dai Ya-Ping, Wang Qing-Lin. Time-scale invariant modeling and classifying for object behaviors in 3D space based on monocular vision. Acta Automatica Sinica, 2014, 40(8):1644-1653 http://www.aas.net.cn/CN/article/downloadArticleFile.do?attachType=PDF&id=18432 [7] 褚一平, 张引, 叶修梓, 张三元.基于隐条件随机场的自适应视频分割算法.自动化学报, 2007, 33(12):1252-1258 http://www.aas.net.cn/CN/article/searchArticle.do#Chu Yi-Ping, Zhang Yin, Ye Xiu-Zi, Zhang San-Yuan. Adaptive video segmentation algorithm using hidden conditional random fields. Acta Automatica Sinica, 2007, 33(12):1252-1258 http://www.aas.net.cn/CN/article/searchArticle.do# [8] Joulin A, Tang K, Li F F. Efficient image and video co-localization with frank-wolfe algorithm. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer, 2014. 253-268 doi: 10.1007%2F978-3-319-10599-4_17 [9] Prest A, Leistner C, Civera J, Schmid C, Ferrari V. Learning object class detectors from weakly annotated video. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, Rhode Island, USA:IEEE, 2012. 3282-3289 [10] Chen D J, Chen H T, Chang L W. Video object cosegmentation. In:Proceedings of the 20th ACM International Conference on Multimedia. Nara, Japan:ACM, 2012. 805-808 [11] Rubio J C, Serrat J, López A. Video co-segmentation. In:Proceedings of the 11th Asian Conference on Computer Vision. Daejeon, Korea:Springer, 2013. 13-24 doi: 10.1007%2F978-3-642-37444-9_2 [12] Chiu W C, Fritz M. Multi-class video co-segmentation with a generative multi-video model. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR:IEEE, 2013. 321-328 [13] Zhang D, Javed O, Shah M. Video object co-segmentation by regulated maximum weight cliques. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer, 2014. 551-566 doi: 10.1007%2F978-3-319-10584-0_36 [14] Fu H Z, Xu D, Zhang B, Lin S. Object-based multiple foreground video co-segmentation. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, Ohio, USA:IEEE, 2014. 3166-3173 [15] Wang W G, Shen J B, Li X L, Porikli F. Robust video object cosegmentation. IEEE Transactions on Image Processing, 2015, 24(10):3137-3148 doi: 10.1109/TIP.2015.2438550 [16] Guo J M, Li Z W, Cheong L F, Zhou S Z. Video co-segmentation for meaningful action extraction. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 2232-2239 [17] Wang H, Kläser A, Schmid C, Liu C L. Action recognition by dense trajectories. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI:IEEE, 2011. 3169-3176 [18] Tang J, Shao L, Li X L. Efficient dictionary learning for visual categorization. Computer Vision and Image Understanding, 2014, 124:91-98 doi: 10.1016/j.cviu.2014.02.007 [19] Yang F, Jiang Z L, Davis L S. Submodular reranking with multiple feature modalities for image retrieval. In:Proceedings of the 12th Asian Conference on Computer Vision. Singapore:Springer, 2015. 19-34 http://www.umiacs.umd.edu/~fyang/papers/accv14.pdf [20] Xu J, Mukherjee L, Li Y, Warner J, Rehg J M, Singht V. Gaze-enabled egocentric video summarization via constrained submodular maximization. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, Massachusetts, USA:IEEE, 2015. 2235-2244 [21] Gygli M, Grabner H, van Gool L. Video summarization by learning submodular mixtures of objectives. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, Massachusetts, USA:IEEE, 2015. 3090-3098 [22] Leordeanu M, Hebert M. A spectral technique for correspondence problems using pairwise constraints. In:Proceedings of the 10th IEEE International Conference on Computer Vision. Beijing, China:IEEE, 2005. 1482-1489 [23] Cho M, Lee J, Lee K M. Reweighted random walks for graph matching. In:Proceedings of the 11th European Conference on Computer Vision. Crete, Greece:Springer, 2010. 492-505 doi: 10.1007%2F978-3-642-15555-0_36 [24] Dalal N, Triggs B, Schmid C. Human detection using oriented histograms of flow and appearance. In:Proceedings of the 9th European Conference on Computer Vision. Graz, Austria:Springer, 2006. 428-441 http://www.oalib.com/references/17185810 [25] Lovász L. Submodular functions and convexity. Mathematical Programming the State of the Art. Berlin Heidelberg:Springer, 1983. 235-257 doi: 10.1007%2F978-3-642-68874-4_10 [26] Jiang Z L, Davis L S. Submodular salient region detection. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR:IEEE, 2013. 2043-2050 [27] Boykov Y, Veksler O, Zabih R. Fast approximate energy minimization via graph cuts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(11):1222-1239 doi: 10.1109/34.969114 -

 下载:
下载:
计量
- 文章访问数: 2490
- HTML全文浏览量: 365
- PDF下载量: 539
- 被引次数: 0
