

Modified Robust Covariance Intersection Fusion Steady-state Kalman Predictor for Uncertain Systems
-
摘要: 针对带随机参数和噪声方差两者不确定性的线性离散多传感器系统,利用虚拟噪声补偿随机参数不确定性,原系统可转化为仅带不确定噪声方差的系统.根据极大极小鲁棒估值原理,用Lyapunov方程方法提出局部鲁棒稳态Kalman预报器及其误差方差最小上界,并利用保守的局部预报误差互协方差,提出改进的鲁棒协方差交叉(Covariance intersection,CI)融合稳态Kalman预报器及其误差方差最小上界.克服了原始CI融合方法要求假设已知局部估值及它们的保守误差方差的缺点和融合误差方差上界具有较大保守性的缺点.证明了鲁棒局部和融合预报器的鲁棒性,并证明了改进的CI融合器鲁棒精度高于原始CI融合器鲁棒精度,且高于每个局部预报器的鲁棒精度.一个仿真例子验证了所提出结果的正确性和有效性.
-
关键词:
- 不确定系统 /
- 协方差交叉融合 /
- 极大极小鲁棒Kalman预报器 /
- 虚拟噪声 /
- Lyapunov方程方法
Abstract: For linear discrete time multisensor systems with both stochastic parameter and noise variance uncertainties, the stochastic parametric uncertainty can be compensated by a fictitious noise, so the original system can be converted into the one with only uncertain noise variances. Based on the minimax robust estimation principle, the local robust steady-state Kalman predictors and the minimal upper bounds of their error variances are presented using the Lyapunov equation approach, and a modified robust covariance intersection (CI) fusion steady-state Kalman predictor and the minimal upper bound of its error variances are presented using the cross-covariances of the conservative local prediction errors. They overcome the disadvantages of the original CI fuser that the local estimates and their conservative error variances are assumed to be known, and the upper bound of fused estimation error variances has large conservativeness. The robustness of the robust local and fused predictors is proved, and it is proved that the robust accuracy of the modified CI fuser is higher than that of the original CI fuser and that of each local predictor. A simulation example shows the correctness and effectiveness of the proposed results. -
两轮机器人作为典型的多变量、强耦合和非线性欠驱动复杂动态系统,近年来引起国内外很多研究学者的极大关注[1].而对于两轮机器人的研究主要集中在对其的运动平衡控制上,传统的控制方法主要有PID控制[2-3]、线性二次型调节器(Linear quadratic regulator,LQR)控制[4-5]、模糊控制[6]及其结合[7]等.在传统控制方法基础之上,很多自适应控制方法也应运而生[8-10],效果显著. 20世纪60年代末至70年代初,斯坦福研究所研制的移动式智能机器人Shakey[11],开启了对智能机器人的研究. 今天,对两轮机器人的运动平衡控制也开始由传统控制方法转向智能控制方法[12-13].
目前,对机器人智能控制方法的研究主要是基于对人或动物获得行为技能过程的理解.1952年,日内瓦大学心理学教授Piaget在 The Origins of Intelligence in Children[14]一书中指出人类认知发育的第一阶段是感知运动技能的获得.从神经生理学出发,人或动物的感知运动技能是在其感知器官及运动器官与环境的不断接触过程中渐进形成和发展起来的,模拟人和动物的这种感知运动学习机制,并将其复制到机器人上,对实现机器智能有着重要的意义.有关机器人感知运动系统的研究由来已久并不断发展,Lee等[15]采用嵌入式系统为移动机器人设计了一种人工感知运动系统,使其能通过来自视觉和听觉的信息成功跟踪特定目标.Natale等[16]为人型机器人设计的感知运动系统,能够使其通过认知,由简单的初始化形态形成感知运动神经协调机制.Dong等[17]为模拟人类动作执行过程,提出一种名为SMS (Sensory motor system)的认知模型,并就抓取任务与人类抓取实验数据进行了比较,表明了其认知模型的合理性.Laflaquière等[18]为平面多关节机器人设计的感知运动系统使得机器人从抓取开始,在没有先验假设的情况下,仅仅通过感知运动经历逐渐形成感知概念.Teulière等[19]为机器人iCub建立了一个自主学习模型,通过对主动感知的有效编码,实现眼部运动平滑跟踪,实验结果表明所设计的模型和学习方法具有自校订特性和对感知运动环在强扰动下的鲁棒性.
内发动机(Intrinsic motivation,IM)是发育心理学的一个重要概念,主要涉及自发探索和好奇心[20].内发动机源于智能体对其内在目标和目的的追求,与外界环境的奖励和惩罚无关,是智能体探索和学习环境的原动力.好奇心作为一种重要的内发动机元素,在智能体感知运动学习过程中发挥着重要的作用[21].发育机器人学诞生之后,Oudeyer等[22]提出了智能自适应好奇心IAC算法,实现了机器人高维感知运动空间里的低层动作选择. 之后,其团队对IAC进行改进,提出了SAGG-RIAC算法[23],该算法具有更高的探索能力. 综合好奇心、积极性以及创造性等因素,Der等[24]为自学习系统提出一种新的突触规则,将其在复杂机器人系统上进行测试,表现出一定程度的感知运动智能.
Schyns等[25]指出,如果将大脑看作是一台处理信息的机器,那么其认知活动就可以解释为一个连接刺激(Stimulus)与响应(Response)的信息处理状态集,并在该理论指导下证明了使用学习自动机模拟大脑的可行性. 基于此,本文从智能科学角度出发,以学习自动机为数学模型,为两轮机器人建立起一种人工感知运动系统认知模型,模型中引入好奇心和取向性概念,设计了具有主动探索和学习环境的内发动机机制,使机器人能够在与环境的接触过程中渐进形成平衡技能,为两轮机器人运动平衡控制提供了新的思路. 与已有控制方法相比,本系统不需要被控对象模型,不需要教师信号,完全自主学习,符合生物智能的特点. 实验结果表明,本文设计的感知运动系统不仅学习速度快,同时能够有效避免小概率事件,学习效果稳定,且鲁棒性高.
1. 两轮机器人系统结构及其数学模型
1.1 两轮机器人系统结构
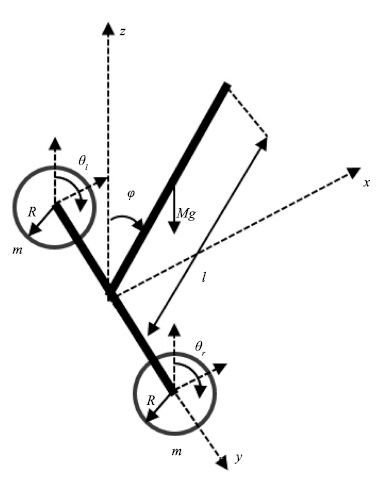
本文以北京工业大学人工智能与机器人研究所研制的一款两轮机器人为研究对象[26],其系统结构如图 1所示,主要由两个轮子和机身组成,两个轮子同轴安装,但独立驱动,机身上安置有姿态传感器,用来检测机器人的姿态信息,两轮机器人通过控制轮子运动来保持其姿态平衡.
1.2 两轮机器人数学模型
针对实际的机器人系统,其运动过程相对比较复杂,很难对其建立起十分精确的数学模型,因此对建模过程进行简化,在允许的范围内忽略或者简化摩擦、弹性等因素,建立满足系统动力学特性的近似模型. 针对本实验中采用的两轮机器人,在其建模过程中做出如下假设:机器人机身和左右两轮均为刚体且质量均匀分布,机器人机身重心与质心重合; 车轮与地面之间只有滚动摩擦,没有滑动摩擦; 同时,忽略内部轴承摩擦的能量损耗;忽略环境中风力、温度、其他摩擦力等造成的影响;忽略实际情况中电机电枢绕组中的电磁转矩、摩擦阻力耦矩等,只考虑摩擦力与摩擦力矩.
基于以上假设,采用拉格朗日方法建立如图 1所示两轮机器人的动力学模型.图 1中,规定x 轴正方向为机器人运动正方向, $\varphi$ 为机器人身姿与 $z$ 轴夹角,顺时针方向为正, $\theta$ 为轮子转角,本文旨在验证所设计的感知运动系统的学习能力,暂时只考虑机器人俯仰平衡,不考虑航向控制,因此对左轮和右轮施加的控制力矩总是相等,两轮转动角度一致,统一表示为 $\theta_{l}=\theta_{r}=\theta$ .建模过程中各参数含义如表 1所示.
表 1 两轮机器人物理参数Table 1 Two-wheeled robot´s physical parameters符号 意义 l 机器人身体长度 M 机器人身体质量 m 轮子质量 R 轮子半径 Jω 轮子转动惯量 τ 轮子转矩 选取广义坐标为 $q=[\theta,\varphi,x]^{\rm T}$ ,则根据拉格朗日方程有
\begin{equation}\displaystyle \frac{\rm d}{{\rm d}t} \frac{\partial {L}}{\partial{\dot{q}_{i}}}-\frac {\partial {L}}{\partial{q_{i}}}=F_{i}, i=1,2,3\end{equation}
(1) 其中, $L=T-U$ 为拉格朗日算子, $q_{i}$ 为第i个广义坐标, $F_{i}$ 为该广义坐标下对应的广义力,T为系统总动能,U为系统总势能.
系统动能由轮子动能和身体动能两部分组成:
\begin{align}T=&\ 2\times \frac{1}{2}m\dot{x}^{2}+2\times\frac{1}{2}J_{\omega}\dot{\theta}^{2} + \\&\ \frac{1}{2}M\left(\frac{{\rm d}}{{\rm d}t}\left(x+\frac{l}{2}{\sin}\varphi\right)\right)^2 + \\&\ \frac{1}{2}M\left(\frac{{\rm d}}{{\rm d}t}\left(\frac{l}{2}{\cos}\varphi\right)\right)^2+\frac{1}{6}Ml^{2}\dot{\varphi}^2= \\&\ \left(m+\frac{1}{2}M\right)\dot{x}^2+J_{\omega}\dot{\theta}^2 + \\&\ \frac{1}{2}Ml\dot{x}\dot{\varphi}{\cos}\varphi+\frac{1}{6}Ml^{2}\dot{\varphi}^2\end{align}
(2) 轮子无势能,所以系统势能等于身体势能
\begin{equation}U=\frac{1}{2}Mgl{\cos}\varphi\end{equation}
(3) 根据拉格朗日方程有
\begin{align}\begin{cases}\dfrac{\rm d}{{\rm d}t}\dfrac{\partial L}{\partial\dot{\theta}}-\dfrac{\partial L}{\partial\theta}=2(\tau-fR)\\\dfrac{\rm d}{{\rm d}t}\dfrac{\partial L}{\partial\dot{\varphi}}-\dfrac{\partial L}{\partial\varphi}=-2\tau\\\dfrac{\rm d}{{\rm d}t}\dfrac{\partial L}{\partial\dot{x}}-\dfrac{\partial L}{\partial x}=2f\end{cases}\end{align}
(4) 其中,f为轮子与地面之间的摩擦力.带入拉格朗日算子有
\begin{align}\begin{cases}2J_{\omega} \ddot{\theta}=2(\tau-fR)\\\dfrac{1}{2}Ml\ddot{x}{\cos}\varphi+\dfrac{1}{3}Ml^{2}\ddot{\varphi}-\dfrac{1}{2}Mgl{\sin}\varphi=-2\tau\\(2m+M)\ddot{x}+\dfrac{1}{2}Ml\ddot{\varphi}{\cos}\varphi-\dfrac{1}{2}Ml\dot{\varphi}^2{\sin}\varphi=2f\end{cases}\end{align}
(5) 对式(5)进行求解,同时带入 $x=R\theta$ ,可得
\begin{align}\begin{cases}\dfrac{1}{2}MRl\ddot{\theta}{\cos}\varphi+\dfrac{1}{3}Ml^2\ddot{\varphi}-\dfrac{1}{2}Mgl{\sin}\varphi=-2\tau\\\left(2mR^2+MR^2+2J_{\omega}\right)\ddot{\theta}+\dfrac{1}{2}MRl\ddot{\varphi}{\cos}\varphi -\\\qquad\dfrac{1}{2}MRl\dot{\varphi}^2{\sin}\varphi=2\tau\end{cases}\end{align}
(6) 令 $\widetilde{q}=[\theta,\varphi]^{\rm T}$ ,可得系统非线性动力学模型
\begin{equation}M(\widetilde{q})\ddot{\widetilde{q}}+N(\widetilde{q},\dot{\widetilde{q}})=Eu\end{equation}
(7) 其中,
\begin{align*}&M(\widetilde{q})=\left[\begin{matrix}\dfrac{1}{2}MRl\cos\varphi & \dfrac{1}{3}Ml^2\\2mR^2+MR^2+2J_{\omega}& \dfrac{1}{2}MRl{\cos}\varphi\end{matrix}\right]\\&N(\widetilde{q},\dot{\widetilde{q}})=\left[\begin{matrix}-\dfrac{1}{2}Mgl{\sin}\varphi\\-\dfrac{1}{2}MRl\dot{\varphi}^2{\sin}\varphi\end{matrix}\right]\\&E=\left[\begin{matrix}-2\\2\end{matrix}\right]\end{align*}
2. 两轮机器人感知运动系统TWR-SMS
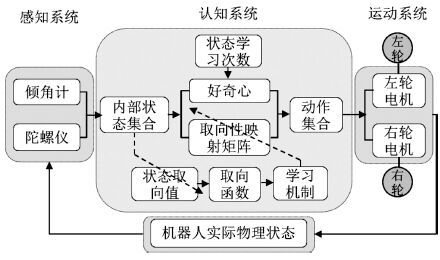
感知运动系统综合了感受器功能和运动神经技能,包含感觉器官、传入神经、控制器官、 传出神经和运动器官.两轮机器人具有类似人或动物的 "感知-运动"特征,其运动控制过程的五个部分与感知运动系统五部分相对应.两轮机器人的传感检测装置对应感知运动系统感受器官,传感输入线路和A/D变换对应传入神经,认知单元对应控制器官,信号输出线路和D/A转换对应传出神经,电机对应运动器官. 因此,可以为两轮机器人设计一种人工感知运动系统,从而使其能够像人或动物一样实现运动平衡控制.
本文设计的两轮机器人感知运动系统结构图如图2所示,主要由三部分构成: 感知系统、运动系统以及用来学习感知运动知识的感知运动认知系统.
2.1 感知系统
两轮机器人的感知系统用来感知机器人自身姿态信息,主要由姿态传感器构成,具体涉及倾角计和陀螺仪.倾角计用来检测机器人身姿倾斜角度,具体采用WQ90系列倾角计,其电压信号通过TMS320F2812处理器处理,得到控制器能够识别的机身倾斜角度信号;陀螺仪用来检测机器人倾角速度,具体使用日本住友精密工业公司与英国航天公司合作研发的产品CRS03系列角速度传感器.感知系统检测到的信号是感知运动系统认知系统的输入.
2.2 认知系统
本文以学习自动机为数学模型,引入影响生物动作选择的两个主要内在因素:取向性和好奇心概念,为两轮机器人感知运动学习过程构建了一种认知模型,具体为一个八元组: $\langle S,M,O,N,C,V,V_{s}$ , $L\rangle$ ,各元素含义具体如下:
1) S:系统离散感知状态集合. $S=\{s_{i}|i=1$ ,2, $\cdots,n_s\}$ , $s_{i}$ 为系统第i个可感知的状态, $n_{s}$ 为可感知状态的数目.
2) M:系统可执行动作集合. $M=\{m_{j}|j=1$ ,2, $\cdots,n_{m}\}$ , $m_{j}$ 为机器人第j个可执行动作, $n_{m}$ 为机器人可执行动作的个数.
3) O:系统"感知-运动" 取向性映射矩阵. O = $\{o_{ij}|i=1,2,\cdots,n_{s},j=1,2,\cdots,n_{m}\}$ , $o_{ij}$ 表示一条"感知-运动" 映射,表征系统在感知状态 ${s_i} \in S$ 下对动作 $m_{j}$ 的取向性,或称感知状态 $s_{i}$ 与动作 $m_{j}$ 的感知运动取向性为 $o_{ij}$ .智能体在任何感知状态下对该状态下所有动作的取向性总和保持不变,即当智能体在某一状态下对其中一动作的取向性增加时,同时意味着对其他动作的取向性减小,本文中所设定的取向性满足 $0\leq o_{ij}\leq 1$ 且 $\sum_{j=1}^{n_{m}}o_{ij}=1$ .
4) N: 状态学习次数. $N=\{n_{i}|i=1,2,\cdots$ , $n_{s}\}$ , $n_{i}$ 为至t时刻状态 $s_{i}$ 被学习的次数.
5) C:好奇心. $C=\{c_{i}|i=1,2,\cdots,n_{s}\}$ , $c_{i}$ 为系统在状态 $s_{i}$ 下的好奇心函数,从生物学角度出发,动物在某一状态下的好奇心随探索该状态次数的增加而下降,基于此,系统好奇心函数设计如下:
\begin{align}c_{i}=\displaystyle\frac{1}{1+{\rm e}^{0.01(n_{i}-1) }}\end{align}
(8) 6) V:系统状态取向值,用来决定取向函数的值. $V(t)=\{v_{i}(t)|i=1,2,\cdots,n_{s}\}$ ,其中 $v_{i}(t)$ 为t时刻系统处于状态 $s_{i}$ 时的状态取向值,具体定义为: ${v_i}(t) = a{\varphi ^2}(t) + b\varphi (t)\dot \varphi (t) + c{\dot \varphi ^2}(t)$ .
7) $V_{s}$ :取向函数,用来决定系统的学习方向.设t时刻系统处于状态 $s_{i}$ ,系统状态取向值为 $v_{i}(t)$ ,执行某一动作后,在 $t+1$ 时刻系统状态变为 $s_{j}$ ,系统状态取向值更新为 $v_{j}(t+1) $ ,则取向函数定义为 $V_{s}(t+1) =v_{i}(t)-v_{j}(t+1) $ .
8) L:系统学习机制. 系统在t时刻处于状态 $s_{i}$ ,执行动作 $m_{j}$ ,系统状态发生变化,取向性也随之发生改变, $t+1$ 时刻系统在状态 $s_{i}$ 下对该状态下不同动作的取向性学习过程如下:
\begin{align}\Delta= \begin{cases}1,& \mbox{若} V_{s}(t+1) >0\\0,&\ mbox{若} V_{s}(t+1) =0\\-1,&\ mbox{若} V_{s}(t+1) <0\end{cases}\end{align}
(9) \begin{align}L: \begin{cases}o_{ij}(t+1) =\\\qquad \dfrac{o_{ij}(t)+\Delta \times o_{ij}(t)(1-{\rm e}^{-\eta |V_{s}(t+1) |})}{1+\Delta \times o_{ij}(t)(1-{\rm e}^{-\eta|V_{s}(t+1) |})}\\o_{ij^{'}}(t+1) =\\\qquad\dfrac{o_{ij^{'}}(t)}{1+\Delta \times o_{ij}(t)(1-{\rm e}^{-\eta |V_{s}(t+1) |})}\end{cases}\end{align}
(10) 其中, $\eta$ 为取向性学习参数.
2.3 运动系统
两轮机器人的运动系统为机器人的两个轮子,机器人通过控制安装在轮子上的直流电机控制机器人前后运动从而达到身体平衡控制.电机具体选用MaxonRe36型直流电机,电机驱动器为奕山电机公司伺服驱动器ED-Y1030A1.
2.4 TWR-SMS基本工作流程
步骤1. t时刻,感知系统感知机器人实际状态;
步骤2. 感知系统将感知到的身姿信息输入认知系统,认知系统首先对来自感知系统的连续信息进行离散化,判定机器人当前所处离散感知状态 $s_{i}$ ;
步骤3.计算机器人当前所处状态下的状态取向值、对各动作的取向性 $o_{ij}(t)$ 以及该状态下的好奇心 $c_{i}(t)$ ,并将该好奇心随机投射到某个动作之上;
步骤4. 依据内发动机机制选择动作,具体为选择所处状态下取向性和好奇心和值最大的动作;
步骤5. 运动系统执行选定的动作,状态发生转移;
步骤6. 计算新的状态取向值及取向函数的值,根据式(9) 和式(10) 更新取向性映射矩阵,获得新的"感知-运动"映射,如此循环,直至达到学习目标.
3. 两轮机器人自平衡学习过程
3.1 实验参数设置
根据设计的感知运动系统对实验过程进行设置.首先针对具体研究对象---两轮机器人,对其身姿倾斜角度和倾斜角速度进行离散化划分,均划分为9个状态,具体如表 2所示.
表 2 TWR-SMS状态划分Table 2 TWR-SMS state divisionφ(º) $\dot \varphi $ (º/s) (-∞,-17.5) (-∞,-20) [-17.5,-12.5) [-20,-15) [-12.5,-7.5) [-15,-10) [-7.5,-2.5) [-10,-5) [-2.5,+2.5) [-5,+5) [+2.5,+7.5) [+5,+10) [+7.5,+12.5) [+10,+15) [+12.5,+17.5) [+15,+20) [+17.5,+∞) [+20,+∞) 因此,系统共有 $n_{s}=9\times9=81$ 个学习状态; 运动操作为轮子转矩,设定系统在每个状态下可执行操作相同,具体为 $M=\{-5,-2,-0.1,0,0.1,2,5\}$ ,因此 $n_{m}=7$ ; 初始时刻,机器人没有任何先验知识,在各状态下对所有动作的取向性相等,即 $o_{ij}(0) =$ $1/n_{m}$ $(i=1,2,\cdots,n_{s},j=1,\cdots,n_{m})$ ;系统其他参数在初始时刻的设置如下: 学习次数 ${n_i}(0) = 0(i = 1, \cdots ,{n_s})$ ,初始时刻各状态下好奇心最大为 $c_{i}(0) =0.5025(i=1,\cdots,n_{s})$ ,状态取向值参数a = 255,b=122,c=9,取向性学习参数为 $\eta=0.1$ .
3.2 仿真实验过程与结果分析
设定机器人初始学习角度为 $-10^{\circ}$ ,学习采样时间为 $t_{s}=0.01$ s. 为清楚显示机器人的学习过程,在此设定轮次学习,每轮学习1000步,之后在前一次学习基础上继续学习.学习过程中,如果倾角 $|\varphi|> 15^{\circ} $ ,则认为机器人倾倒一次,将机器人拉回初始状态继续学习.
实验1. 基本学习过程.为显示TWR-SMS基本学习过程,本文记录了机器人前10轮学习过程中身姿角度及角速度变化曲线,分别如图 3和图 4中实线所示,为第1轮、第4轮、第7轮和第10轮的学习结果.从图 3可以看出,在第1轮学习过程中,机器人没有任何先验知识,对动作的选择具有随机性,因此不稳定,身姿晃动较大,根据实验记录数据,机器人在本轮学习过程中共倾倒8次; 经过两轮学习后,在第4轮中,机器人已经能够不再倾倒,但仍然存在一定晃动; 进入第7轮学习,机器人已经能够迅速到达平衡点并稳定在平衡点附近,实验结果说明,通过学习机器人获得了感知状态和动作之间的有效映射,能够在不同的状态下选择不同的动作从而达到平衡控制,体现了认知模型的学习本质.同样的学习过程也体现在了机器人身姿角速度的变化过程中,如图 4中实线所示,为对应轮次中机器人身姿角速度变化过程,可以看到学习初期机器人角速度变化范围较大,进入学习后期,角速度只在零点附近很小的范围内波动. 由实验结果可知,到达学习后期,机器人的角度和角速度都在一个很小的范围内波动,因此系统较稳定.
为体现本感知运动系统在内发动机机制指导下的主动学习的优越性,将主动学习与依概率学习机制[12-13]指导下的学习方法进行了对比. 所谓的依概率学习机制,指的是智能体在学习过程中,总是以较大的概率选择取向性较大的动作,以较小的概率选择取向性较小的动作. 在同样的条件下,依概率学习下的结果如图 3和图 4中虚线所示,为对应轮次下的学习曲线.首先同样作为一种智能学习机制,可以看出依概率学习体现出类似本文感知运动系统的学习过程,这是学习系统的共同点. 通过实验对比发现,在依概率学习机制指导下,系统仅仅在第1轮的学习过程中发生了4次倾倒,而主动学习方法在前3轮学习过程中均发生过倾倒,倾倒次数分别为8次、1次、2次,之后进入稳定状态,不再倾倒.这是因为本文设计的感知运动系统引 入了好奇心概念,学习初期,智能体对各动作好奇心较大,因此对各动作的探索度较高,容易导致失败.一旦进入稳定期,所设计的感知运动系统就表现出较好的稳定性,从图 3中第7轮与第10轮的学习结果可以看出,感知运动系统下的机器人身体更能够稳定在0点,不发生太大变化,而依概率学习下的学习系统虽然也能稳 定在误差允许范围内,但过程较不稳定,容易发生晃动,该结论在机器人的身姿角速度曲线中体现更为明显,从图 4中第7轮学习可以看出,主动学习下的机器人身姿角速度变化非常小,基本保持在一个很小 的范围内,而在依概率学习下,虽然角速度也能保持在一定范围内,但是变化仍比较明显,出现很多毛刺,有时角速度甚至会突然变大,该情况的发生主要是由于依概率学习过程中存在的小概率事件造成的.
 图 3 主动学习及依概率学习下的身姿角度学习曲线Fig. 3 Learning curves of posture´s angle under active learning and probabilistic learning
图 3 主动学习及依概率学习下的身姿角度学习曲线Fig. 3 Learning curves of posture´s angle under active learning and probabilistic learning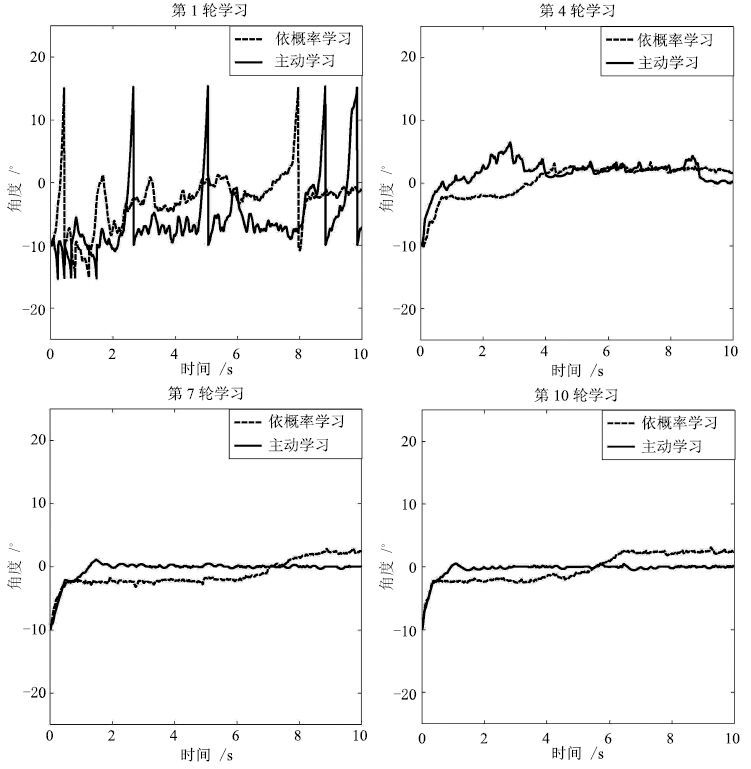 图 4 主动学习及依概率学习下的身姿角速度学习曲线Fig. 4 Learning curves of posture´s angular velocity under active learning and probabilistic learning
图 4 主动学习及依概率学习下的身姿角速度学习曲线Fig. 4 Learning curves of posture´s angular velocity under active learning and probabilistic learning实验2. 小概率事件对比实验. 智能体在学习过程中,当进入稳定状态后,若仍然选择了取向性或概率很小的动作,则称之为小概率事件,从工程角度出发,小概率事件往往具有破坏性的结果,因此在系统进入稳定状态后,应避免小概率事件的发生.本文对主动学习和依概率学习下的小概率事件进行了对比,实验中,认为机器人进入稳定期后,若仍选择了取向性或概率小于0.01的动作,则为小概率事件. 方便起见,本文对10轮学习过程中被选动作取向性或概率小于0.01的次数都进行了记录,结果如表 3所示. 实验数据显示,在主动学习下,系统从第4轮开始,不再选择取 向性小于0.01的动作,因此可知系统之后进入稳定状态后不再发生小概率事件. 观察依概率学习下的身姿角度曲线,可知系统从第4轮开始已进入稳定状态,因此之后的记录数据均为小概率事件,这直接影响智能系统进入稳定期后的学习效果.
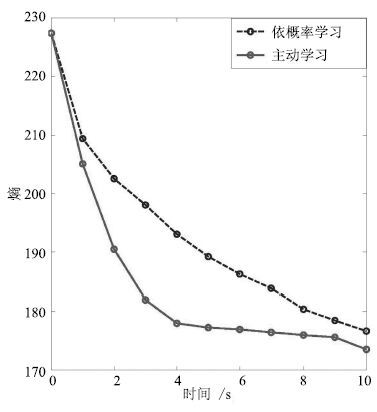
表 3 小概率事件发生次数Table 3 Numbers of small probability event1 2 3 4 5 6 7 8 9 10 主动学习 3 9 4 0 0 0 0 0 0 0 依概率学习 0 2 7 8 12 13 12 7 10 7 实验3. 学习速度对比实验.系统熵表征系统的自学习和自组织特性,常被用来描述系统的学习程度[13],本文感知运动系统熵定义如下:
$\eqalign{ & E(t) = - \sum\limits_{i = 1}^{{n_s}} {\sum\limits_{j = 1}^{{n_m}} {{o_{ij}}} } (t){\rm{lo}}{{\rm{g}}_2}{o_{ij}}(t) = \cr & - \sum\limits_{i = 1}^{{n_s}} {\sum\limits_{j = 1}^{{n_m}} {{o_{ij}}} } ({m_j}(t)|{s_i}){\rm{lo}}{{\rm{g}}_2}{o_{ij}}({m_j}(t)|{s_i}) \cr} $
(11) 将本文主动学习下的感知运动系统与依概率选择下的智能系统的学习速度进行比较,结果如图 5所示.图 5中实线和虚线分别为两种学习机制下的熵曲线,初始时刻,系统由于没有任何先验知识,随机性最大,因此熵值也最 大,随着学习的进行,智能体学习到一定的知识,熵值不断下降,系统熵值的下降速度体现了 系统的学习速度. 从图 5可以看出,相较于依概率学习机制,主动学习机制具有更快的学习速度.
实验同样记录了10轮学习过程中两种学习机制指导下智能体对不同动作的选择次数,分别如表 4和表 5所示. 从表 4中可以看出,主动学习机制下,系统对动作+5和-5的选择次数以很快的速度不 断下降,这是因为随着学习的进行,在之后的轮次学习中,系统能够较早进入稳定状态,因此对 +5和-5的需求减少,这同样体现了主动学习下系统的学习速度. 相比较而言,表5中记录的依概率 学习下,系统对动作+5和-5的选择次数同样经历了一个下降过程,但是下降速度较慢. 该对比数据再一次说明主动学习下的智能系统具有较快的学习速度,相较于依概率学习机制下的智能系 统,能够更早进入稳定状态.
实验4. 抗干扰对比实验. 机器人在运动过程中,难免受到来自外界的干扰,这些干扰有时会严重 影响机器人的平衡和稳定,因此,是否具有好的抗干扰能力是衡量两轮机器人控制系统的一个重要性能指标. 为验证本文感知 运动系统TWR-SMS的抗干扰能力,将本文系统与传统LQR控制方法在同等干扰条件的实验结果进行了对比.假设机器人在运动第500步时,受到一个幅值为10的脉冲扰动,实验结果如图6所示.图 6(a)为机器人身姿角度变化曲线,图 6(b)为身姿角速度变化曲线.两幅图中实线为 TWR-SMS指导下所得曲线,虚线为LQR方法下所得曲线.由仿真数据结果得知,在以上脉冲干扰下,感知运动系统大约经过77步回到平衡位置,期间最大偏移角度约为 $0.97^{\circ}$ ,而LQR控制则大约需要101步回到平衡位置,期间最大偏移角度为 $2.34^{\circ}$ . 图 6(b)中身姿角速度变化曲线体现出同样的特点. 由实验结果可知,相对于传统LQR方法,TWR-SMS在遇到干扰信号时,状态变化幅值小,调节时间短,对来自外界环境的干扰体现出更好的 鲁棒性,这也正是学习系统的特点之一.
表 4 主动学习下动作选择次数Table 4 Motion selection numbers under active learning主动学习 1 2 3 4 5 6 7 8 9 10 -5 191 119 80 27 14 3 4 2 3 2 -2 167 235 241 114 86 167 191 209 150 201 -0.1 130 122 182 145 115 233 213 243 226 359 0 149 120 117 186 59 108 123 133 83 156 0.1 152 128 131 355 653 333 194 213 396 81 2 140 170 146 117 66 156 172 199 140 201 5 71 106 103 56 7 0 3 1 2 0 表 5 依概率学习下动作选择次数Table 5 Motion selection numbers under probabilistic learning依概率学习 1 2 3 4 5 6 7 8 9 10 -5 186 95 73 61 43 30 29 30 44 29 -2 141 122 140 116 197 166 208 197 187 177 -0.1 144 166 217 214 220 237 206 203 231 258 0 137 170 200 215 199 189 196 194 199 172 0.1 148 177 202 181 174 179 172 173 153 174 2 112 161 117 162 132 162 168 175 154 156 5 132 109 51 51 35 37 21 28 32 34 实验5. 模型参数变化对比实验. 现实物理系统中,随着系统不断运行,会由于设备或者电路老化等原因而引起被控对象模型参数发生变化.本文以电路老化引起的电机电压出现偏差,进而导致电机驱动力矩发生偏差为例,进行如下对比实验:假设模型从第300步开始,电机实际驱动力矩与控制器期望输出力矩出现了0.3的偏差.图 7中实线为TWR-SMS在此情况下的控制效果,虚线为传统LQR控制效果.从实验结果可以看出,在模型参数发生变化时,传统LQR控制方法下的机器人角度出现了偏差,而控制系统又没有针对此偏差进行预测并加入相应的控制器进行补偿,导致机器人最终无法回到平衡位置.相比之下,TWR-SMS是基于学习理论建立的,不需要被控对象模型,在模型/环境发生变化后,依旧可以通过重新学习达到控制目标.该实验结果同样说明本系统对模型环境发生变化具有较强的适应性,与传统控制方法相比,具有较强的鲁棒性.
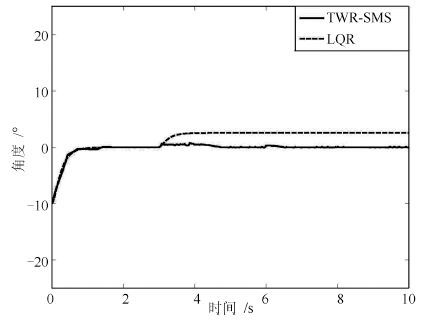 图 7 被控模型参数变化对比曲线Fig. 7 Contrast curves under the change of the controlled model´s parameters
图 7 被控模型参数变化对比曲线Fig. 7 Contrast curves under the change of the controlled model´s parameters4. 结论
本文是为两轮机器人建立感知运动系统的初步探索,所建立的感知运动系统具有内发动机机制,能够使机器人主动探索环境,学习环境知识. 目前,研究的重点主要集中在两轮机器人自平衡控 制上,保持自身平衡是两轮机器人所必须具备的一个重要特性,实验结果表明所建立的感知运动系统能够使机器人通过与环境的不断接触学会保持自身平衡这一技能,并且学习速度快,学习效果稳定,鲁棒性好. 在此基础之上,将来期望完善两轮机器人感知运动系统设计,在保证自身平衡控制的同时,能够实现多模式(如定点运动、自由运动以及速度跟踪运动等)下的运动平衡控制.
-

图 1 基于协方差椭圆的局部和CI融合鲁棒Kalman预报器的矩阵不等式精度比较
Fig. 1 The comparison of matrix inequality accuracies of the local and CI fused robust Kalman predictors based on covariance ellipses

图 2 基于协方差椭圆原始的和改进的鲁棒CI融合Kalman预报器的矩阵不等式精度比较
Fig. 2 The comparison of matrix inequality accuracies of the original and modified CI fused robust Kalman predictors based on covariance ellipses
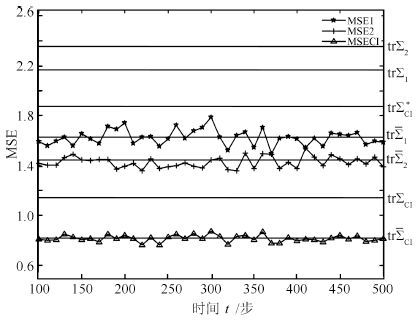
图 3 局部和CI融合鲁棒Kalman预报器的MSE曲线
Fig. 3 The MSE curves of the local and CI fused robust Kalman predictors

图 4 位置预报误差曲线和 $\pm 3\sigma _1$ 界
Fig. 4 The position prediction error curve and $\pm 3\sigma_1 $ bounds
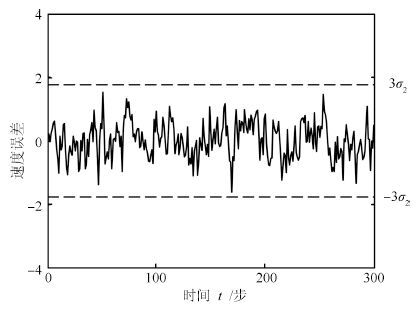
图 5 速度预报误差曲线和 $\pm 3\sigma _2$ 界
Fig. 5 The velocity prediction error curve and $\pm 3\sigma _2 $ bounds
表 1 鲁棒Kalman预报器的鲁棒和实际精度比较
Table 1 The comparison of robust and actual accuracies of robust Kalman predictors
${\mathop{\rm tr}\nolimits} {\bar \Sigma _1}$ ${\mathop{\rm tr}\nolimits} {\Sigma _1}$ ${\mathop{\rm tr}\nolimits} {\bar \Sigma _2}$ ${\mathop{\rm tr}\nolimits} {\Sigma _2}$ ${\mathop{\rm tr}\nolimits} {\bar \Sigma _{{CI}}}$ ${\mathop{\rm tr}\nolimits} {\Sigma _{{CI}}}$ ${\mathop{\rm tr}\nolimits} \Sigma _{{CI}}^*$ 1.6267 2.1690 1.4425 2.3544 0.8158 1.1437 1.8751  下载: 导出CSV
下载: 导出CSV
-
[1] Liggains M E, Hall D L, Llinas J. Handbook of Multisensor Data Fusion:Theory and Practice (Second Edition). Boca Raton, FL:CRC Press, 2009. [2] Julier S J, Uhlmann J K. General decentralized data fusion with covariance intersection. Handbook of Multisensor Data Fusion:Theory and Practice (Second Edition). Boca Raton, FL:CRC Press, 2009.319-342 [3] Hajiyev C, Soken H E. Robust adaptive Kalman filter for estimation of UAV dynamics in the presence of sensor/actuator faults. Aerospace Science and Technology, 2013, 28(1):376-383 doi: 10.1016/j.ast.2012.12.003 [4] Ménec S L, Shin H S, Markham K, Tsourdos A, Piet-Lahanier H. Cooperative allocation and guidance for air defence application. Control Engineering Practice, 2014, 32:236-244 doi: 10.1016/j.conengprac.2014.02.011 [5] Feng J X, Wang Z D, Zeng M. Distributed weighted robust Kalman filter fusion for uncertain systems with autocorrelated and cross-correlated noises. Information Fusion, 2013, 14(1):78-86 doi: 10.1016/j.inffus.2011.09.004 [6] Deng Z L, Zhang P, Qi W J, Gao Y, Liu J F. The accuracy comparison of multisensor covariance intersection fuser and three weighting fusers. Information Fusion, 2013, 14(2):177-185 doi: 10.1016/j.inffus.2012.05.005 [7] Julier S J, Uhlmann J K. A non-divergent estimation algorithm in the presence of unknown correlations. In:Proceedings of the 1997 American Control Conference. Albuquerque, NM:IEEE, 1997.2369-2373 http://cn.bing.com/academic/profile?id=2017642774&encoded=0&v=paper_preview&mkt=zh-cn [8] Uhlmann J K. Covariance consistency methods for fault-tolerant distributed data fusion. Information Fusion, 2003, 4(3):201-215 doi: 10.1016/S1566-2535(03)00036-8 [9] Julier S J, Uhlmann J K. Using covariance intersection for SLAM. Robotics & Autonomous Systems, 2007, 55(1):3-20 http://cn.bing.com/academic/profile?id=2006832107&encoded=0&v=paper_preview&mkt=zh-cn [10] Deng Z L, Zhang P, Qi W J, Liu J F, Gao Y. Sequential covariance intersection fusion Kalman filter. Information Sciences, 2012, 189(7):293-309 http://cn.bing.com/academic/profile?id=1984609538&encoded=0&v=paper_preview&mkt=zh-cn [11] Sijs J, Lazar M. State fusion with unknown correlation:ellipsoidal intersection. Automatica, 2012, 48(8):1874-1878 doi: 10.1016/j.automatica.2012.05.077 [12] de Campos Ferreira J C B, Waldmann J. Covariance intersection-based sensor fusion for sounding rocket tracking and impact area prediction. Control Engineering Practice, 2007, 15(4):389-409 doi: 10.1016/j.conengprac.2006.07.002 [13] Gao Q, Chen S Y, Leung H, Liu S T. Covariance intersection based image fusion technique with application to pansharpening in remote sensing. Information Sciences, 2010, 180(18):3434-3443 doi: 10.1016/j.ins.2010.05.010 [14] 齐文娟, 张鹏, 邓自立. 带观测滞后和不确定噪声方差的多智能体传感网络鲁棒序贯协方差交叉融合Kalman滤波. 自动化学报, 2014, 40(11):2632-2642 doi: 10.1016/S1874-1029(14)60410-9Qi Wen-Juan, Zhang Peng, Deng Zi-Li. Robust sequential covariance intersection fusion Kalman filtering over multi-agent sensor networks with measurement delays and uncertain noise variances. Acta Automatica Sinica, 2014, 40(11):2632-2642 doi: 10.1016/S1874-1029(14)60410-9 [15] Lazarus S B, Tsourdos A, Zbikowski R, Nabil A, White B A. Robust localisation using data fusion via integration of covariance intersection and interval analysis. In:Proceedings of the 2007 International Conference on Control, Automation and Systems. Seoul, Korea:IEEE, 2007.199-206 [16] Qi W J, Zhang P, Deng Z L. Robust weighted fusion Kalman filters for multisensor time-varying systems with uncertain noise variances. Signal Processing, 2014, 99:185-200 doi: 10.1016/j.sigpro.2013.12.013 [17] Qi W J, Zhang P, Nie G H, Deng Z L. Robust weighted fusion Kalman predictors with uncertain noise variances. Digital Signal Processing, 2014, 30:37-54 doi: 10.1016/j.dsp.2014.03.011 [18] Qi W J, Zhang P, Deng Z L. Robust weighted fusion time-varying Kalman smoothers for multisensor system with uncertain noise variances. Information Sciences, 2014, 282:15-37 doi: 10.1016/j.ins.2014.06.008 [19] Qi W J, Zhang P, Deng Z L. Weighted fusion robust steady-state Kalman filters for multisensor system with uncertain noise variances. Journal of Applied Mathematics, 2014, 2014:Article ID 369252 http://cn.bing.com/academic/profile?id=2056593946&encoded=0&v=paper_preview&mkt=zh-cn [20] Sriyananda H. A simple method for the control of divergence in Kalman-filter algorithms. International Journal of Control, 1972, 16(6):1101-1106 doi: 10.1080/00207177208932342 [21] Lewis F L, Xie L H, Popa D. Optimal and Robust Estimation (Second Edition). New York:CRC Press, 2007.315-340 [22] Qu X M, Zhou J. The optimal robust finite-horizon Kalman filtering for multiple sensors with different stochastic failure rates. Applied Mathematics Letters, 2013, 26(1):80-86 doi: 10.1016/j.aml.2012.03.036 [23] 吴黎明, 马静, 孙书利. 具有不同观测丢失率多传感器随机不确定系统的加权观测融合估计. 控制理论与应用, 2014, 31(2):244-249 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201402017.htmWu Li-Ming, Ma Jing, Sun Shu-Li. Weighted measurement fusion estimation for stochastic uncertain systems with multiple sensors of different missing measurement rates. Control Theory & Applications, 2014, 31(2):244-249 http://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201402017.htm [24] 李娜, 马静, 孙书利. 带多丢包和滞后随机不确定系统的最优线性估计. 自动化学报, 2015, 41(3):611-619 http://www.aas.net.cn/CN/abstract/abstract18638.shtmlLi Na, Ma Jing, Sun Shu-Li. Optimal linear estimation for stochastic uncertain systems with multiple packet dropouts and delays. Acta Automatica Sinica, 2015, 41(3):611-619 http://www.aas.net.cn/CN/abstract/abstract18638.shtml [25] Liu W. Optimal filtering for discrete-time linear systems with time-correlated multiplicative measurement noises. IET Control Theory & Applcation, 2015, 9(6):831-842 http://cn.bing.com/academic/profile?id=2039747833&encoded=0&v=paper_preview&mkt=zh-cn [26] Liu W. Optimal estimation for discrete-time linear systems in the presence of multiplicative and time-correlated additive measurement noises. IEEE Transactions on Signal Processing, 2015, 63(17):4583-4593 doi: 10.1109/TSP.2015.2447491 [27] Li F, Zhou J, Wu D Z. Optimal filtering for systems with finite-step autocorrelated noises and multiple packet dropouts. Aerospace Science and Technology, 2013, 24(1):255-263 doi: 10.1016/j.ast.2011.11.013 [28] Zhang S, Zhao Y, Wu F L, Zhao J H. Robust recursive filtering for uncertain systems with finite-step correlated noises, stochastic nonlinearities and autocorrelated missing measurements. Aerospace Science and Technology, 2014, 39(39):272-280 http://cn.bing.com/academic/profile?id=2000347446&encoded=0&v=paper_preview&mkt=zh-cn [29] Tian T, Sun S L, Li N. Multi-sensor information fusion estimators for stochastic uncertain systems with correlated noises. Information Fusion, 2016, 27:126-137 doi: 10.1016/j.inffus.2015.06.001 [30] Carravetta F, Germani A, Raimondi M. Polynomial filtering of discrete-time stochastic linear systems with multiplicative state noise. IEEE Transactions on Automatic Control, 1997, 42(8):1106-1126 doi: 10.1109/9.618240 [31] Wang Z D, Yang F W, Ho D W C, Liu X H. Robust finite-horizon filtering for stochastic systems with missing measurements. IEEE Signal Processing Letters, 2005, 12(6):437-440 doi: 10.1109/LSP.2005.847890 [32] Wang S Y, Fang H J, Tian X G. Recursive estimation for nonlinear stochastic systems with multi-step transmission delays, multiple packet dropouts and correlated noises. Signal Processing, 2015, 115(2):164-175 http://cn.bing.com/academic/profile?id=2080231200&encoded=0&v=paper_preview&mkt=zh-cn [33] Yang F W, Wang Z D, Hung Y S. Robust Kalman filtering for discrete time-varying uncertain systems with multiplicative noises. IEEE Transactions on Automatic Control, 2002, 47(7):1179-1183 doi: 10.1109/TAC.2002.800668 [34] Luo Y T, Zhu Y M, Luo D D, Zhou J, Song E B, Wang D H. Globally optimal multisensor distributed random parameter matrices Kalman filtering fusion with applications. Sensors, 2008, 8(12):8086-8103 doi: 10.3390/s8128086 [35] Kailath T, Sayed A H, Hassibi B. Linear Estimation. New York:Prentice Hall, 2000.766-772 [36] de Koning W L. Optimal estimation of linear discrete-time systems with stochastic parameters. Automatica, 1984, 20(1):113-115 doi: 10.1016/0005-1098(84)90071-2 [37] Wang Z D, Ho D W C, Liu X H. Robust filtering under randomly varying sensor delay with variance constraints. IEEE Transactions on Circuits and Systems Ⅱ:Express Briefs, 2004, 51(6):320-326 doi: 10.1109/TCSII.2004.829572 [38] Anderson B D O, Moore J B. Optimal Filtering. Englewood Cliffs, NJ:Prentice Hall, 1979. http://www.oalib.com/references/16878535 [39] Wu T T, An J, Ding C S, Luo S X. Research on ellipsoidal intersection fusion method with unknown correlation. In:Proceedings of the 15th International Conference on Information Fusion. Singapore:IEEE, 2012.558-564 http://cn.bing.com/academic/profile?id=1708197474&encoded=0&v=paper_preview&mkt=zh-cn 期刊类型引用(17)
1. 严钰文,毕文豪,张安,张百川. 基于序列生成对抗网络的无人机集群任务分配方法. 兵工学报. 2023(09): 2672-2684 .  百度学术
百度学术2. 陈洪银,王松岑,贾晓强,李德智,刘铠诚,钟鸣,芋耀贤,金璐,郭毅. 考虑碳排放的综合能源系统抗差参数辨识. 电力信息与通信技术. 2023(11): 30-38 . 百度学术3. 王睿,孙秋野,张化光. 微电网的电流均衡/电压恢复自适应动态规划策略研究. 自动化学报. 2022(02): 479-491 . 本站查看4. 孙抗,轩旭阳,刘鹏辉,赵来军,龙洁. 小样本下基于CNN-DCGAN的电缆局部放电模式识别方法. 电子科技. 2022(07): 7-13 . 百度学术5. 孙秋野,胡杰,胡旌伟,张化光. 中国特色能源互联网三网融合及其“自–互–群”协同管控技术框架. 中国电机工程学报. 2021(01): 40-51+396 . 百度学术6. 孙秋野,王一帆,杨凌霄,张化光. 比特驱动的瓦特变革——信息能源系统研究综述. 自动化学报. 2021(01): 50-63 . 本站查看7. 熊珞琳,毛帅,唐漾,孟科,董朝阳,钱锋. 基于强化学习的综合能源系统管理综述. 自动化学报. 2021(10): 2321-2340 . 本站查看8. 李洋,肖泽青,聂松松,曹军威,华昊辰. 生成对抗网络及其在新能源数据质量中的应用研究综述. 南方电网技术. 2020(02): 25-33 . 百度学术9. 金红洋,滕云,冷欧阳,张铁岩,陈哲. 基于源荷不确定性状态感知的无废城市多能源协调储能模型. 电工技术学报. 2020(13): 2830-2842 . 百度学术10. 马波,蔡伟东,赵大力. 基于GAN样本生成技术的智能诊断方法. 振动与冲击. 2020(18): 153-160 . 百度学术11. 胡旭光,马大中,郑君,张化光,王睿. 基于关联信息对抗学习的综合能源系统运行状态分析方法. 自动化学报. 2020(09): 1783-1797 . 本站查看12. 王利,陈宇综,张辉. 深度学习下AI生成印象派美术及全景画的微观艺术研究. 艺术工作. 2020(05): 19-23 . 百度学术13. 程乐峰,余涛,张孝顺,殷林飞. 机器学习在能源与电力系统领域的应用和展望. 电力系统自动化. 2019(01): 15-43 . 百度学术14. 高靖,张明理,邓鑫阳,杨博,张子信,韩震焘. 基于特征聚类的多能源系统负荷预测方法研究. 可再生能源. 2019(02): 232-236 . 百度学术15. 吴宏杰,戴大东,傅启明,陈建平,陆卫忠. 强化学习与生成式对抗网络结合方法研究进展. 计算机工程与应用. 2019(10): 36-44 . 百度学术16. 范珊珊,王彬,薛屹洵,赵昊天,郭庆来,孙勇. 基于网络模型的综合能源系统参数辨识与效率识别. 电力建设. 2019(06): 33-40 . 百度学术17. 黄开艺,艾芊,张宇帆,郝然,吕天光,高扬,肖斐. 基于能源细胞-组织架构的区域能源网需求响应研究挑战与展望. 电网技术. 2019(09): 3149-3160 . 百度学术其他类型引用(9)
-

 下载:
下载:

计量
- 文章访问数: 2607
- HTML全文浏览量: 314
- PDF下载量: 1050
- 被引次数: 26
