

-
摘要: 近来, 稀疏表示分类算法已经在模式识别和特征提取领域获得了广泛的关注. 受最近提出的稀疏表示判别投影算法启发, 本文提出了一种新的特征加权组稀疏判别投影算法(Feature weighted group sparse classification steered discriminative projection, FWGSDP). 首先, 提出特征加权组稀疏分类算法(Feature weighted group sparsebased classification, FWGSC)进行稀疏系数编码, 该算法采用带特征加权约束的保局性信息, 能够鲁棒地重构给定的输入数据; 其次, 通过类内重构散度最小、类间重构散度最大为目标计算最优投影判别矩阵, 使得输入数据具有最佳的模式分类效果; 最后, 提出迭代重约束稀疏编码方法并结合特征分解操作进行FWGSDP模型高效求解. 在ExYaleB, PIE和AR三个人脸数据库的实验验证了所提算法在普通数据和带噪数据中的分类效果都优于现存的算法.Abstract: Recently, sparse representation classification (SRC) has attracted more and more attention in pattern recognition and feature extraction. Motivated by the recent developed SRC steered discriminative projection algorithm, a new feature weighted group sparse discriminative projection algorithm (FWGSDP) is proposed in this paper. First, sparse coefficients are produced by a new proposed feature weighted group sparse representation classification algorithm (FWGSC), which can robustly regress a given signal with regularized regression coefficients by introducing the feature weighted locality structure of the data. Second, FWGSDP maximizes the subtraction of inter-class reconstruction residual and intra-class reconstruction residual, and thus enables data-in to achieve better separation. Finally, a sequentially iteratively re-restrained sparse coding and eigen-decomposition strategy is developed to solve the FWGSDP model efficiently. Experimental results on the ExYaleB, the PIE, and the AR database demonstrate that the proposed algorithm is more effective than other feature extraction methods.
-
Key words:
- Sparse representation /
- locality-constraint /
- group sparse /
- discriminative projection
-
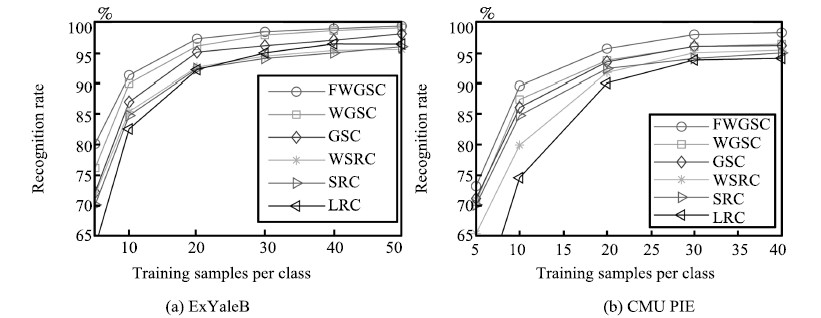
图 2 稀疏型分类器在不同数据库中识别率对比
Fig. 2 The recognition rates of different sparse representation classifiers in ExYaleB and PIE databases

图 4 不同子空间维数的人脸识别率和方差对比
Fig. 4 Comparison of recognition rates and variance under different feature dimensions
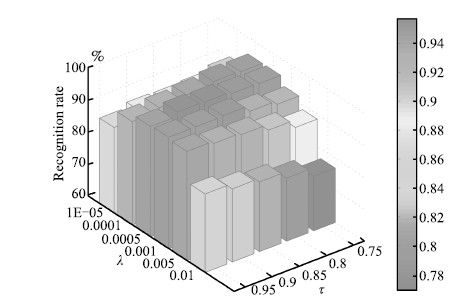
图 5 PIE中FWGSC参数λ和τ选择
Fig. 5 The selection of parameter λ and τ of FWGSC in PIE database
表 1 AR数据库有遮挡情形下不同算法的识别率对比
Table 1 Recognition rate by competing algorithms on AR database with occlusion
测试样本 算法 墨镜遮挡(%) 围巾遮挡(%) FWGSC 99.3 95.7 RRC 99.0 94.7 同时期 CESR 95.3 38.0 GSRC 87.3 85.0 SRC 89.3 32.3 FWGSC 89.3 78.3 RRC 89.3 76.3 不同时期 CESR 79.0 20.7 GSRC 45.0 66.0 SRC 57.3 12.7  下载: 导出CSV
下载: 导出CSV
表 2 降维前后FWGSC分类算法的人脸识别对比
Table 2 Comparison of FWGSC performance with and without dimension reduction
唯数 ExYaleB PIE 识别率(%) 测试时间(s) 识别率(%) 测试时间(s) 原始样本1024 97.34 0.9983 95.69 1.4002 FWGSDP 100 95.04 0.1103 93.62 0.4683 FWGSDP200 96.25 0.1170 95.20 0.4896 FWGSDP300 97.44 0.1215 95.80 0.5046 FWGSDP 400 97.61 0.1286 95.89 0.5175 FWGSDP500 97.61 0.1332 95.95 0.5296
下载: 导出CSV
表 3 AR数据库有遮挡情形下不同算法的识别率对比
Table 3 Comparison of competing dimension reduction algorithms on AR database with occlusion
测试样本 算法 墨镜遮挡识别率(%) 墨镜遮挡耗时(s) 围巾遮挡识别率(%) 围巾遮挡耗时(s) PCA 91.0 1.083 85.7 1.184 LPP 92.5 2.810 89.6 2.672 同时期 LFDA 93.4 4.380 91.5 4.253 SRCDP 92.8 21.27 58.4 21.96 FWGSDP 99.5 14.72 96.0 14.03 PCA 84.6 1.079 70.6 1.067 LPP 87.3 2.714 75.1 2.705 不同时期 LFDA 86.5 4.525 75.4 4.361 SRCDP 78.7 22.15 52.4 22.06 FWGSDP 90.8 15.18 79.6 14.98
下载: 导出CSV
-
[1] Wright J, Yang A Y, Ganesh A, Sastry S S, Yi M. Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227 [2] Xu Y, Zhang D, Yang J, Yang J Y. A two-phase test sample sparse representation method for use with face recognition. IEEE Transactions on Circuits and Systems for Video Technology, 2011, 21(9): 1255-1262 [3] He R, Hu B G, Zheng W S, Guo Y Q. Two-stage sparse representation for robust recognition on large-scale database. In: Proceedings of the 24th AAAI Conference on Artificial Intelligence. Atlanta, Georgia, USA: AAAI, 2010. 475-480 [4] Yang M, Zhang L, Feng X C, Zhang D. Sparse representation based fisher discrimination dictionary learning for image classification. International Journal of Computer Vision, 2014, 109(3): 209-232 [5] He R, Zheng W S, Hu B G. Maximum correntropy criterion for robust face recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8): 1561-1577 [6] Yang M, Zhang L. Gabor feature based sparse representation for face recognition with Gabor occlusion dictionary. In: Proceedings of the 11th European Conference on Computer Vision. Heraklion, Crete, Greece: Springer, 2010. 448-461 [7] 刘建伟, 崔立鹏, 刘泽宇, 罗雄麟. 正则化稀疏模型综述. 计算机学报, 2015, 38(7): 1307-1325Liu Jian-Wei, Cui Li-Peng, Liu Ze-Yu, Luo Xiong-Lin. Survey on the regularized sparse models. Chinese Journal of Computers, 2018, 38(7): 1307-1325 [8] Chen Z H, Zuo W M, Hu Q H, Lin L. Kernel sparse representation for time series classification. Information Sciences, 2015, 292: 15-26 [9] Zhang L, Yang M, Feng X C. Sparse representation or collaborative representation: which helps face recognition? In: Proceedings of the 2011 International Conference on Computer Vision. Barcelona: IEEE, 2011. 471-478 [10] Zhu P F, Zuo W M, Zhang L, Shiu S C K, Zhang D. Image set-based collaborative representation for face recognition. IEEE Transactions on Information Forensics and Security, 2014, 9(7): 1120-1132 [11] Majumdar A, Ward R K. Fast group sparse classification. Canadian Journal of Electrical and Computer Engineering, 2009, 34(4): 136-144 [12] Elhamifar E, Vidal R. Robust classification using structured sparse representation. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI: IEEE, 2011. 1873-1879 [13] Huang J, Nie F P, Huang H, Ding C. Supervised and projected sparse coding for image classification. In: Proceedings of the 27th AAAI Conference on Artificial Intelligence. Bellevue, Washington, USA: AAAI, 2013. 438-444 [14] Wang L J, Lu H C, Wang D. Visual tracking via structure constrained grouping. IEEE Signal Processing Letters, 2015, 22(7): 794-798 [15] Liu H C, Li S T, Yin H T. Infrared surveillance image super resolution via group sparse representation. Optics Communications, 2013, 289: 45-52 [16] Lu C Y, Min H, Gui J, Zhu L, Lei Y K. Face recognition via weighted sparse representation. Journal of Visual Communication and Image Representation, 2013, 24(2): 111-116 [17] Timofte R, van Gool L. Adaptive and weighted collaborative representations for image classification. Pattern Recognition Letters, 2014, 43: 127-135 [18] Wu J Q, Timofte R, van Gool L. Learned collaborative representations for image classification. In: Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision. Waikoloa, HI: IEEE, 2015. 456-463 [19] Chao Y W, Yeh Y R, Chen Y W, Lee Y J, Wang Y C F. Locality-constrained group sparse representation for robust face recognition. In: Proceedings of the 18th IEEE International Conference on Image Processing. Brussels: IEEE, 2011. 761-764 [20] Tang X, Feng G C, Cai J X. Weighted group sparse representation for undersampled face recognition. Neurocomputing, 2014, 145: 402-415 [21] Yang M, Zhang L, Yang J, Zhang D. Regularized robust coding for face recognition. IEEE Transactions on Image Processing, 2013, 22(5): 1753-1766 [22] Jerome F, Trevor H, Robert T. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York: Springer, 2001. 534-553 [23] Duda R O, Hart P E, Stork D G. Pattern Classification (2nd edition). New York, USA: Wiley, 2001. [24] 郑建炜, 王万良, 姚晓敏, 石海燕. 张量局部Fisher判别分析的人脸识别. 自动化学报, 2012, 38(9): 1485-1495Zheng Jian-Wei, Wang Wan-Liang, Yao Xiao-Min, Shi Hai-Yan. Face recognition using tensor local Fisher discriminant analysis. Acta Automatica Sinica, 2012, 38(9): 1485-1495 [25] Zheng J W, Yang D, Chen S Y, Wang W L. Incremental min-max projection analysis for classification. Neurocomputing, 2014, 123: 121-130 [26] 杨利平, 龚卫国, 辜小花, 李伟红, 杜兴. 完备鉴别保局投影人脸识别算法. 软件学报, 2010, 21(6): 1277-1286Yang Li-Ping, Gong Wei-Guo, Gu Xiao-Hua, Li Wei-Hong, Du Xing. Complete discriminant locality preserving projections for face recognition. Journal of Software, 2010, 21(6): 1277-1286 [27] 赵家程, 崔慧敏, 冯晓兵. 基于统计学习分析多核间性能干扰. 软件学报, 2013, 24(11): 2558-2570Zhao Jia-Cheng, Cui Hui-Min, Feng Xiao-Bing. Analyzing cross-core performance interference on multi-core processors based on statistical learning. Journal of Software, 2013, 24(11): 2558-2570 [28] He X F, Yan S C, Hu Y X, Niyogi P, Zhang H J. Face recognition using Laplacianfaces. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(3): 328-340 [29] Sugiyama M. Dimensionality reduction of multimodal labeled data by local Fisher discriminant analysis. Journal of Machine Learning Research, 2007, 8(5): 1027-1061 [30] Yan S C, Xu D, Zhang B Y, Zhang H J, Yang Q, Lin S. Graph embedding and extensions: a general framework for dimensionality reduction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(1): 40-51 [31] Qiao L S, Chen S C, Tan X Y. Sparsity preserving projections with applications to face recognition. Pattern Recognition, 2010, 43(1): 331-341 [32] Cheng B, Yang J C, Yan S C, Fu Y, Huang T S. Learning with l1-graph for image analysis. IEEE Transactions on Image Processing, 2010, 19(4): 858-866 [33] 郑忠龙, 黄小巧, 贾泂, 杨杰. 稀疏局部保持投影. 计算机学报, 2014, 37(9): 2038-2046Zheng Zhong-Long, Huang Xiao-Qiao, Jia Jiong, Yang Jie. Locality preserving projection with sparse penalty. Chinese Journal of Computers, 2014 37(9): 2038-2046 [34] Shao Z F, Zhang L. Sparse dimensionality reduction of hyperspectral image based on semi-supervised local Fisher discriminant analysis. International Journal of Applied Earth Observation and Geoinformation, 2014, 31: 122-129 [35] Ly N H, Du Q, Fowler J E. Sparse graph-based discriminant analysis for hyperspectral imagery. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(7): 3872-3884 [36] Yang J, Chu D L, Zhang L, Yu Y, Yang J Y. Sparse representation classifier steered discriminative projection with applications to face recognition. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(7): 1023-1035 [37] Lu C Y, Huang D S. Optimized projections for sparse representation based classification. Neurocomputing, 2013, 113: 213-219 [38] Ly N H, Du Q, Fowler J E. Collaborative graph-based discriminant analysis for hyperspectral imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014, 7(6): 2688-2696 [39] Yang W K, Wang Z Y, Sun C Y. A collaborative representation based projections method for feature extraction. Pattern Recognition, 2015, 48(1): 20-27 [40] 马小虎, 谭延琪. 基于鉴别稀疏保持嵌入的人脸识别算法. 自动化学报, 2014, 40(1): 73-82Ma Xiao-Hu, Tan Yan-Qi. Face recognition based on discriminant sparsity preserving embedding. Acta Automatica Sinica, 2014, 40(1): 73-82 [41] Yang M, Zhang D, Zhang D, Wang S L. Relaxed collaborative representation for pattern classification. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI: IEEE, 2012. 2224- 2231 [42] Liu Y, Li X M, Liu C Y, Tang Y F. Group sparsity in dimensionality reduction of sparse representation. In: Proceedings of the 2014 International Symposium on Wireless Personal Multimedia Communications. Sydney, NSW: IEEE, 2014. 541-546 [43] Naseem I, Togneri R, Bennamoun M. Linear regression for face recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(11): 2106-2112 [44] Liu J, Ji S W, Ye J P. SLEP: Sparse Learning with Efficient Projections. Arizona State University, USA, 2009 [Online], available: http://www.yelab.net/software/SLEP/, May 4, 2016 [45] Salman A M, Romberg J. Dynamic updating for l1 minimization. IEEE Journal of Selected Topics in Signal Processing, 2010, 4(2): 421-434 [46] Beck A, Teboulle M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Journal on Imaging Sciences, 2009, 2(1): 183-202 [47] Lu C Y, Lin Z C, Yan S C. Smoothed low rank and sparse matrix recovery by iteratively reweighted least squares minimization. IEEE Transactions on Image Processing, 2015, 24(2): 646-654 [48] Lei Y, Song Z J. An improved IRLS algorithm for sparse recovery with intra-block correlation. Optik, 2015, 126(7-8): 850-854 [49] Li F, Wang J X, Tang B P, Tian D Q. Life grade recognition method based on supervised uncorrelated orthogonal locality preserving projection and K-nearest neighbor classifier. Neurocomputing, 2014, 138: 271-282 [50] Lee K C, Ho J, Kriegman D. Acquiring linear subspaces for face recognition under variable lighting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 684-698 [51] Gross R, Matthews I, Cohn J, Kanade T, Baker S. Multi-PIE. Image and Vision Computing, 2010, 28(5): 807-813 -

 下载:
下载:



计量
- 文章访问数: 2237
- HTML全文浏览量: 503
- PDF下载量: 1323
- 被引次数: 0
