

-
摘要: 提出一种基于压缩感知(Compressive sensing, CS)和多分辨分析(Multi-resolution analysis, MRA)的多尺度最小二乘支持向量机(Least squares support vector machine, LS-SVM). 首先将多尺度小波函数作为支持向量核, 推导出多尺度最小二乘支持向量机模型, 然后基于压缩感知理论, 利用最小二乘匹配追踪(Least squares orthogonal matching pursuit, LS-OMP)算法对多尺度最小二乘支持向量机的支持向量进行稀疏化, 最后用稀疏的支持向量实现函数回归. 实验结果表明, 本文方法利用不同尺度小波核逼近信号的不同细节, 而且以比较少的支持向量能达到很好的泛化性能, 大大降低了运算成本, 相比普通最小二乘支持向量机, 具有更优越的表现力.Abstract: A multi-scale least squares support vector machine (LS-SVM) based on compressive sensing (CS) and multi-resolution analysis (MRA) is proposed. First, a multi-scale LS-SVM model is conducted, in which a support vector kernel with the multi-resolution wavelet function is employed; then inspired by CS theory, sparse support vectors of multi-scale LS-SVM are constructed via least squares orthogonal matching pursuit (LS-OMP); finally, sparse support vectors are applied to function approximation. Simulation experiments demonstrate that the proposed method can estimate diverse details of signal by means of wavelet kernel with different scales. What is more, it can achieve good generalization performance with fewer support vectors, reducing the operation cost greatly, performing more superiorly compared to ordinary LS-SVM.
-
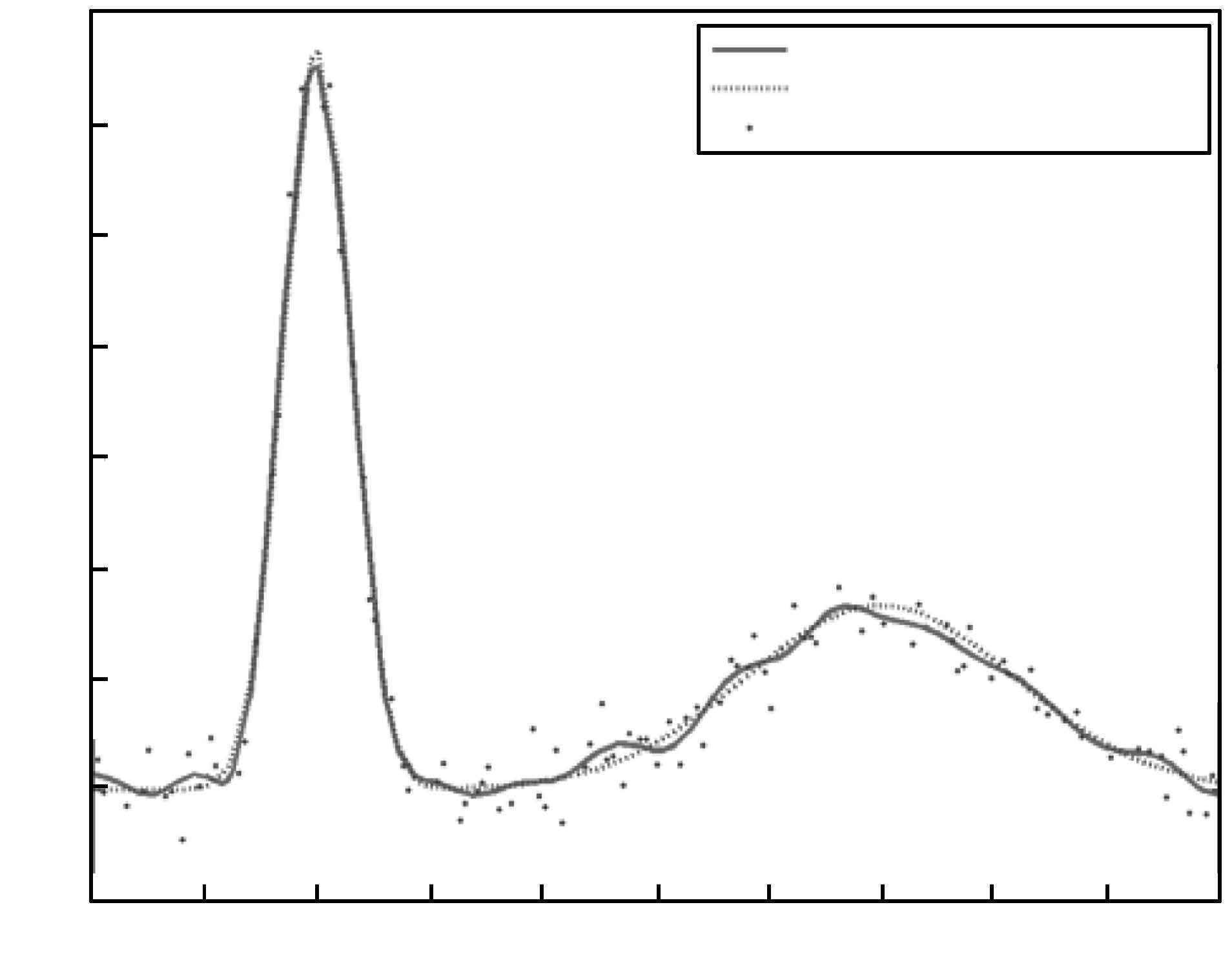
图 2 两尺度径向基小波核LS-SVM的实验结果
Fig. 2 Experimental results of two-scale RBF wavelet kernel LS-SVM
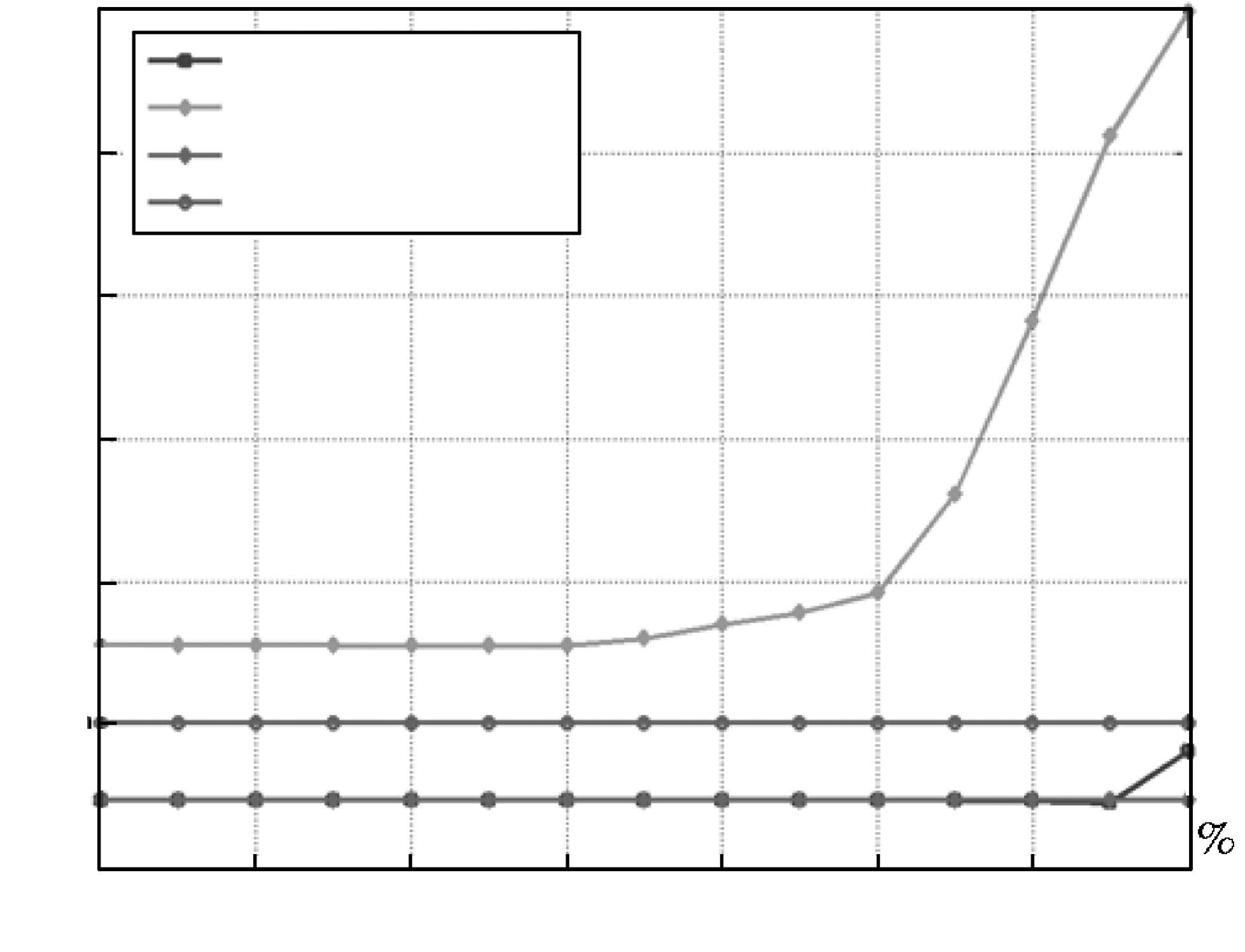
图 3 标准LS-SVM、稀疏LS-SVM、两尺度LS-SVM、稀 疏两尺度LS-SVM 四算法在不同稀疏度下NMSE 比较
Fig. 3 NMSE comparison of standard LS-SVM, sparse LS-SVM, two-scale LS-SVM, sparse two-scale LS-SVM algorithms under di®erent sparse degrees

图 4 标准LS-SVM和两尺度LS-SVM的回归结果比较
Fig. 4 Regression results comparison of standard LS-SVM and two-scale LS-SVM

图 6 90% 稀疏度两尺度LS-SVM 逼近效果
Fig. 6 Approximation result of 90% sparse degree two-scale LS-SVM

图 7 90% 稀疏度标准LS-SVM 逼近效果
Fig. 7 Approximation result of 90% sparse degree standard LS-SV

图 8 标准LS-SVM 和两尺度LS-SVM 在50% 稀疏度下拟合结果比较
Fig. 8 Approximation results comparison of standard LS-SVM and two-scale LS-SVM under 50% sparse degree
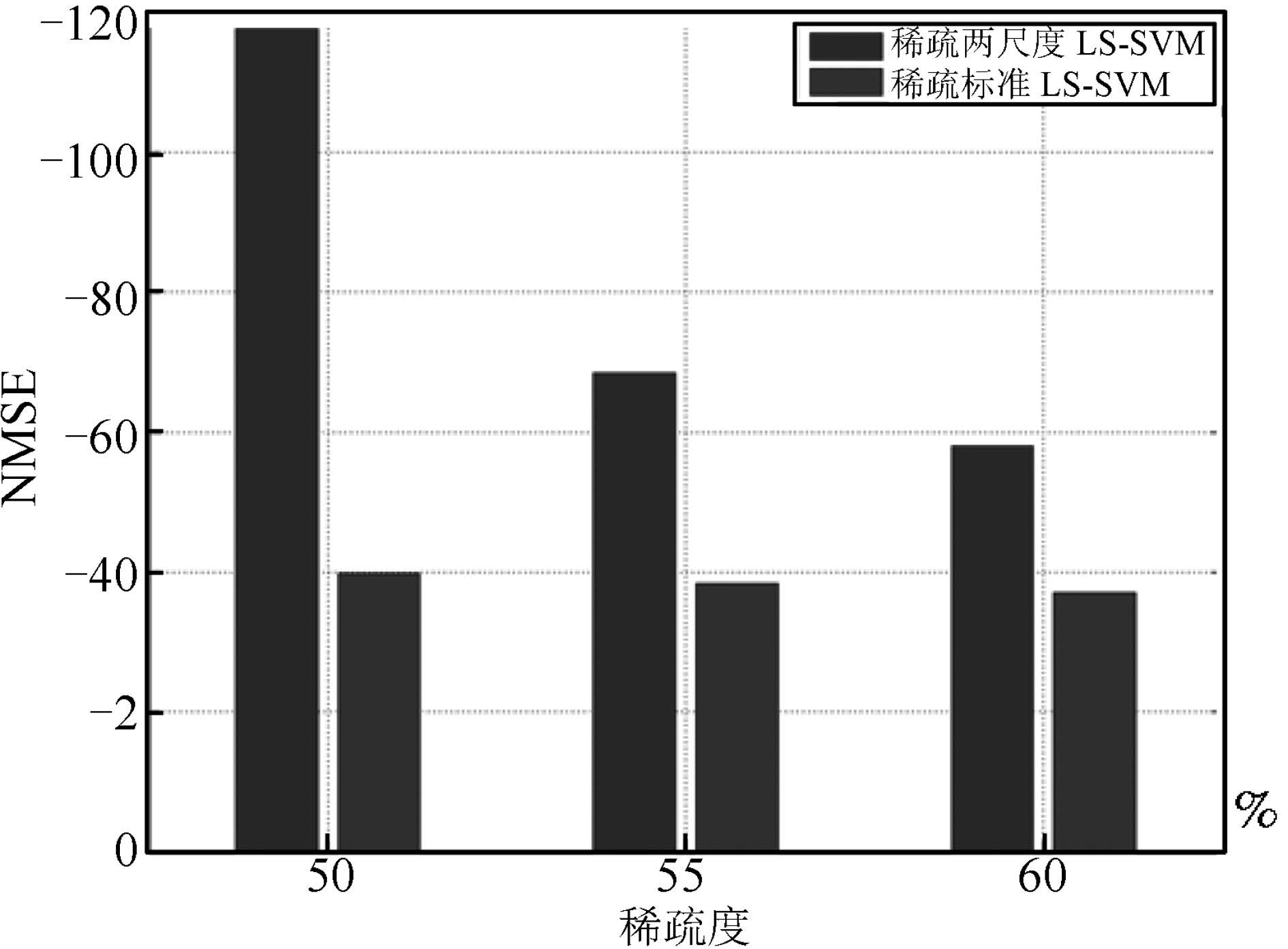
图 9 标准LS-SVM 和两尺度LS-SVM 在不同稀疏度下 NMSE 比较
Fig. 9 NMSE comparison of standard LS-SVM and two-scale LS-SVM under di®erent sparse degrees
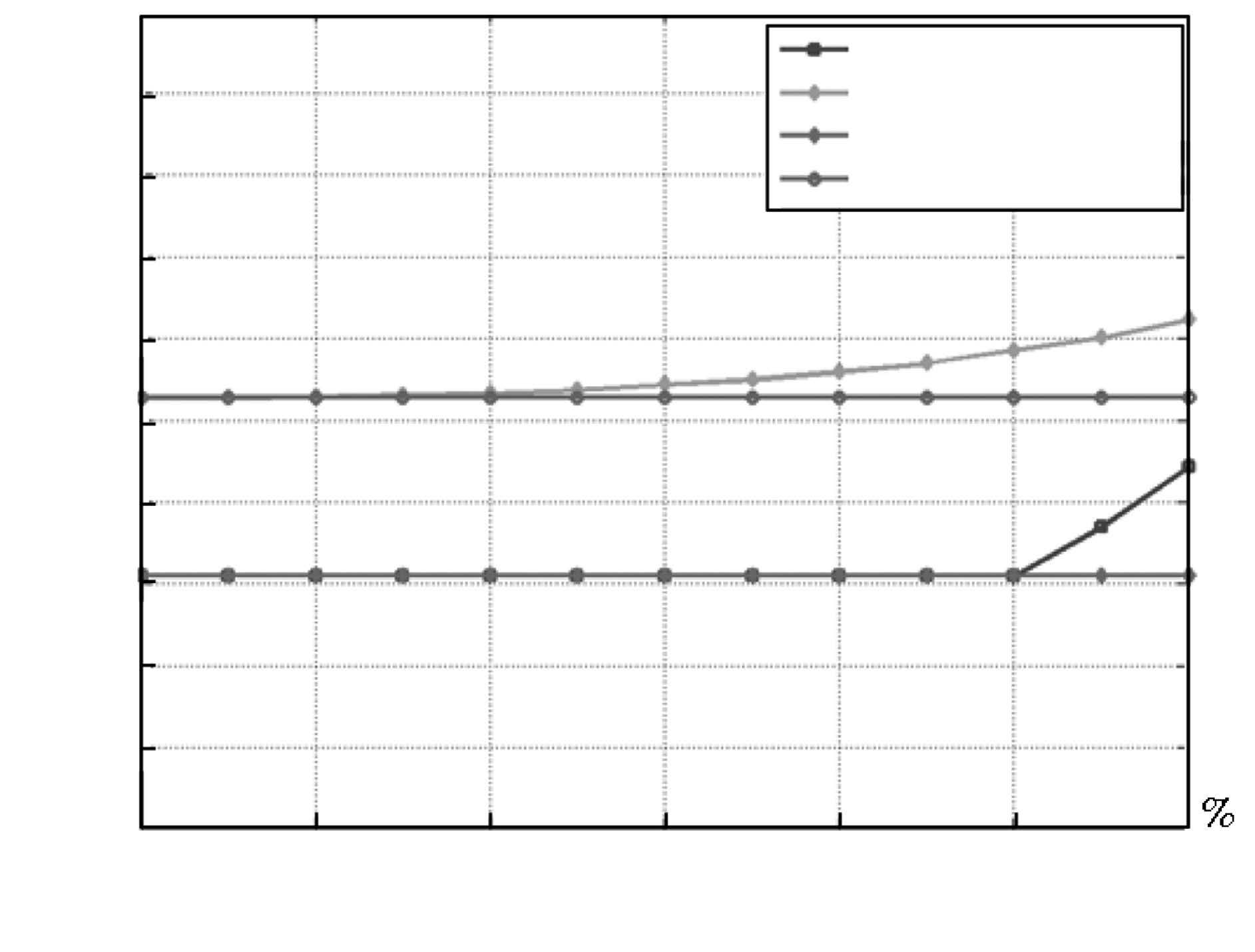
图 11 标准LS-SVM、稀疏LS-SVM、两尺度LS-SVM、稀 疏两尺度LS-SVM 四算法在不同稀疏度下NMSE 比较
Fig. 11 NMSE comparison of standard LS-SVM, sparse LS-SVM, two-scale LS-SVM, sparse two-scale LS-SVM algorithms under di®erent sparse degrees
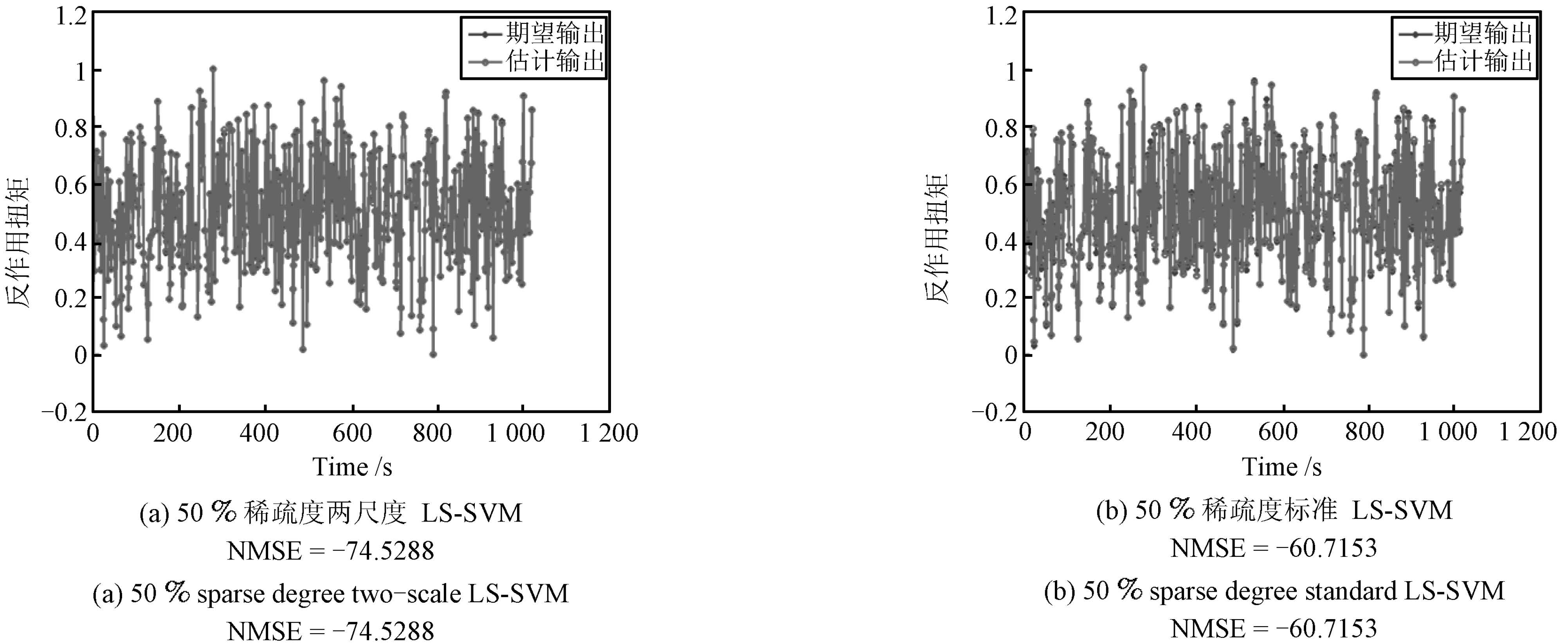
图 12 标准LS-SVM 和两尺度LS-SVM 在50% 稀疏度下的拟合结果比较
Fig. 12 Approximation results comparison of standard LS-SVM and two-scale LS-SVM under 50% sparse degree
表 1 不同小波核函数的两尺度LS-SVM NMSE 比较
Table 1 NMSE comparison of two-scale LS-SVM with di®erent wavelet kernel functions
核函数 参数选择 准确率(NMSE) RBF 小波核 $\gamma_1=50, \gamma_2=100, \sigma_1^2=0.5, \sigma_2^2=3.5$ -47.1780 Morlet 小波核 $\gamma_1=80, \gamma_2=150, \sigma_1^2=0.8, \sigma_2^2=4$ -46.4707 Mexican hat 小波核 $\gamma_1=100, \gamma_2=200, \sigma_1^2=0.35, \sigma_2^2=6.25$ -46.6829  下载: 导出CSV
下载: 导出CSV
表 2 不同核函数的两尺度LS-SVM NMSE 比较
Table 2 NMSE comparison of two-scale LS-SVM with di®erent kernel functions
核函数 参数选择 准确率(NMSE) RBF 小波核 $\gamma_1=50, \gamma_2=100, \sigma_1^2=0.5, \sigma_2^2=3.5$ -47.1780 RBF 核 $\gamma_1=100, \gamma_2=200, \sigma_1^2=0.3, \sigma_2^2=3$ -44.7617 Sinc 小波核 $\gamma_1=60, \gamma_2=220, \sigma_1^2=0.5, \sigma_2^2=5$ -44.1170
下载: 导出CSV
表 4 稀疏两尺度LS-SVM 和稀疏标准LS-SVM 在不同稀疏度下NMSE 比较
Table 4 NMSE comparison of sparse two-scale LS-SVM and sparse standard LS-SVM algorithms under di®erent sparse degrees
稀疏度(%) 90 80 70 60 50 40 30 20 10 NMSE 两尺度 -52.8800 -59.7540 -69.7735 -72.7535 -72.9664 -72.9800 -72.9805 -72.9805 -72.9805 标准 -49.9373 -54.9217 -58.7773 -63.1308 -64.8218 -65.3600 -65.4205 -65.4312 -65.4312
下载: 导出CSV
-
[1] Vapnik V N. The Nature of Statistical Learning Theory. New York: Springer-Verlag, 1995. 69-83 http://www.oalib.com/references/16885293 [2] Suykens J A K, Vandewalle J. Least squares support vector machine classifiers. Neural Processing Letters, 1999, 9(3): 293-300 doi: 10.1023/A:1018628609742 [3] Zhao H B, Ru Z L, Chang X, Yin S D, Li S J. Reliability analysis of tunnel using least square support vector machine. Tunnelling and Underground Space Technology, 2014, 41: 14-23 doi: 10.1016/j.tust.2013.11.004 [4] Esfahani S, Baselizadeh S, Hemmati-Sarapardeh A. On determination of natural gas density: least square support vector machine modeling approach. Journal of Natural Gas Science and Engineering, 2015, 22: 348-358 doi: 10.1016/j.jngse.2014.12.003 [5] Yang J, Bouzerdoum A, Phung S L. A training algorithm for sparse LS-SVM using compressive sampling. In: Proceedings of the 2010 IEEE International Conference on Acoustics Speech and Signal Processing. Dallas, TX, USA: IEEE, 2010. 2054-2057 [6] Zhang L, Zhou W D, Jiao L C. Wavelet support vector machine. IEEE Transactions on Systems, Man, and Cybernetics-Part B: Cybernetics, 2004, 34(1): 34-39 doi: 10.1109/TSMCB.2003.811113 [7] 沈燕飞, 李锦涛, 朱珍民, 张勇东, 代锋. 基于非局部相似模型的压缩感知图像恢复算法. 自动化学报, 2015, 41(2): 261-272 http://www.aas.net.cn/CN/abstract/abstract18605.shtmlShen Yan-Fei, Li Jin-Tao, Zhu Zhen-Min, Zhang Yong-Dong, Dai Feng. Image reconstruction algorithm of compressed sensing based on nonlocal similarity model. Acta Automatica Sinica, 2015, 41(2): 261-272 http://www.aas.net.cn/CN/abstract/abstract18605.shtml [8] Mallat S G. A Wavelet Tour of Signal Processing. Sam Diego: Academic Press, 1998. [9] Zhao J X, Song R F, Zhao J, Zhu W P. New conditions for uniformly recovering sparse signals via orthogonal matching pursuit. Signal Processing, 2015, 106: 106-113 doi: 10.1016/j.sigpro.2014.06.010 [10] Elad M. Sparse and Redundant Representations: From Theory to Applications in Signal and Image Processing. New York: Springer-Verlag, 2010. http://www.oalib.com/references/16302471 [11] Yang L, Han J Q, Chen D K. Identification of nonlinear systems using multi-scale wavelet support vectors machines. In: Proceedings of the 2007 IEEE International Conference on Control and Automation. Guangzhou, China: IEEE, 2007. 1779-1784 [12] Yang L X, Yang S Y, Zhang R, Jin H H. Sparse least square support vector machine via coupled compressive pruning. Neurocomputing, 2014, 131: 77-86 doi: 10.1016/j.neucom.2013.10.038 [13] Schniter P, Potter L C, Ziniel J. Fast Bayesian matching pursuit. In: Proceedings of the 2008 Information Theory and Applications Workshop. San Diego, CA, USA: IEEE, 2008. 326-333 [14] Zhang Y P, Sun J G. Multikernel semiparametric linear programming support vector regression. Expert Systems with Applications, 2011, 38(3): 1611-1618 doi: 10.1016/j.eswa.2010.07.082 [15] 赵永平, 孙建国. 一类非平坦函数的多核最小二乘支持向量机的鲁棒回归算法. 信息与控制, 2008, 37(2): 160-165 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK200802007.htmZhao Yong-Ping, Sun Jian-Guo. A non-flat function robust regression algorithm using multi-kernel LS-SVM. Information and Control, 2008, 37(2): 160-165 http://www.cnki.com.cn/Article/CJFDTOTAL-XXYK200802007.htm [16] Cai Y N, Wang H Q, Ye X M, Fan Q G. A multiple-kernel LSSVR method for separable nonlinear system identification. Journal of Control Theory and Applications, 2013, 11(4): 651-655 doi: 10.1007/s11768-013-2035-9 [17] Balasundaram S, Gupta D, Kapil. Lagrangian support vector regression via unconstrained convex minimization. Neural Networks, 2014, 51: 67-79 doi: 10.1016/j.neunet.2013.12.003 期刊类型引用(8)
1. 杨静宗,杨天晴,周成江,潘安宁. 基于改进ABC-LSSVM的浆体管道临界淤积流速预测. 南京师大学报(自然科学版). 2020(01): 136-142 .  百度学术
百度学术2. 任世锦,潘剑寒,李新玉,徐桂云,巩固. 基于ELMD与改进SMSVM的机械故障诊断方法. 南京航空航天大学学报. 2019(05): 693-703 . 百度学术3. 郭慧,刘忠宝,赵文娟,张静. 模糊双超球学习机. 广西大学学报(自然科学版). 2018(03): 1097-1102 . 百度学术4. 陈善雄,熊海灵,廖剑伟,周骏,左俊森. 一种基于CGLS和LSQR的联合优化的匹配追踪算法. 自动化学报. 2018(07): 1293-1303 . 本站查看5. 邓怀勇,马琴,陈国彬,刘超,牛培峰. 基于AWOA算法与LSSVM的主蒸汽流量软测量模型. 仪表技术与传感器. 2018(12): 78-82 . 百度学术6. 李莹琦,黄越,孙晓川. 基于深度置信回声状态网络的网络流量预测模型. 南京邮电大学学报(自然科学版). 2018(05): 85-90 . 百度学术7. 车磊,王海起,费涛,闫滨,刘玉,桂丽,陈冉,翟文龙. 基于多尺度最小二乘支持向量机优化的克里金插值方法. 地球信息科学学报. 2017(08): 1001-1010 . 百度学术8. 李康,王福利,何大阔,贾润达. 基于数据的湿法冶金全流程操作量优化设定补偿方法. 自动化学报. 2017(06): 1047-1055 . 本站查看其他类型引用(10)
-

计量
- 文章访问数: 2423
- HTML全文浏览量: 231
- PDF下载量: 1085
- 被引次数: 18
