

-
摘要: 在短文本分类中,面对特征稀疏的短文本,如何充分利用文本中的每一个词语成为关键.本文提出概率语义分布模型的思想,首先通过查询词矢量词典,将文本转换为词矢量数据;其次,在概率语义分布模型的假设下利用混合高斯模型对无标注的文本数据进行通用背景语义模型训练;利用训练数据对通用模型进行自适应得到各个领域的目标领域语义分布模型;最后,在测试过程中,计算短文本属于领域模型的概率,得到最终的分类结果.实验结果表明,本文提出的方法能够从一定程度上利用短文本所提供的信息,有效降低了对训练数据的依赖性,相比于支持向量机(Support vector machine,SVM)和最大熵分类方法性能相对提高了17.7%.Abstract: In short text classification, it is critical to deal with each word because of data sparsity. In this paper, we present a novel probabilistic semantic distribution model. Firstly, words are transformed to vectors by looking up word embeddings. Secondly, the universal background semantic model is trained based on unlabelled universal data through mixture Gaussian models. Then, target models are obtained by adapting the background model for each domain training data. Finally, the probability of the test data belonging to each target model is calculated. Experimental results demonstrate that our approach can make best use of each word and effectively reduce the influence of training data size. In comparison with the methods of support vector machine (SVM) and MaxEnt, the proposed method gains a 17.7% relative accuracy improvement.
-
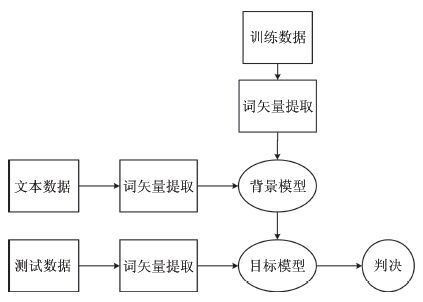
图 1 基于通用语义背景模型的短文本分类
Fig. 1 Short text classification based on universal semantic background model
表 1 网页搜索片段数据分布
Table 1 Statistics of web snippets data
编号 领域 训练数据 测试数据 1 商业 1200 300 2 计算机 1200 300 3 文化与艺术 1880 330 4 教育与科技 2360 300 5 技术 220 150 6 健康 880 300 7 社会政策 1200 300 8 体育 1120 300 共计 10060 2280  下载: 导出CSV
下载: 导出CSV
表 2 未登录词分布
Table 2 Statistics of unseen words
原始单词 词干 训练数据 26 265 21 596 测试数据 10 037 8 200 未登录词 4 378 3 677 未登录词的比例 43.62% 44.84%
下载: 导出CSV
表 3 与基线系统对比实验结果(%)
Table 3 Experimental results of the proposed method against other methods (%)
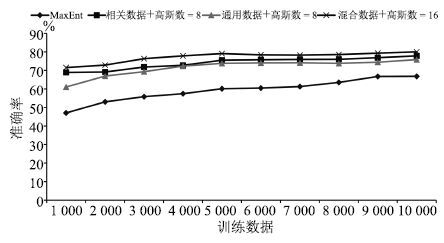
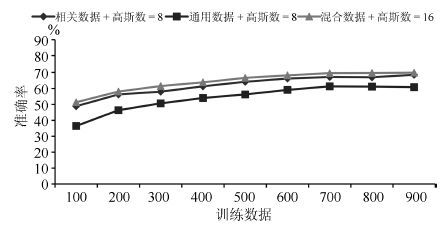
方法 Accuracy TF*IDF+SVM 66.14 TF*IDF+MaxEnt 66.80 LDA+MaxEnt 82.18 Wiki feature+SVM 76.89 Paragraph vector+SVM 61.90 LSTM 63.00 本文的方法 80.00
下载: 导出CSV
表 4 SVM、MaxEnt和本文方法的实验结果
Table 4 Evaluations of SVM,MaxEnt and the proposed method
SVM MaxEnt 本文的方法 领域 P (%) R (%) F1 P (%) R (%) F1 P (%) R (%) F1 社会政策 77.61 52.00 0.6228 70.75 50.00 0.5859 86.36 70.37 0.7755 计算机 73.75 63.67 0.6834 72.26 66.00 0.6899 80.31 87.29 0.8365 教育与科技 41.98 82.00 0.5553 45.93 82.67 0.5905 81.60 68.23 0.7432 体育 85.19 76.67 0.8070 86.08 78.33 0.8202 84.54 89.93 0.8715 健康 89.01 56.67 0.6925 86.94 64.33 0.7395 76.35 85.57 0.8070 技术 76.53 50.00 0.6048 72.84 39.33 0.5108 58.82 93.33 0.7216 商业 70.37 57.00 0.6298 68.05 60.33 0.6396 73.99 67.33 0.7051 文化与艺术 62.27 81.52 0.7060 62.86 78.48 0.6981 88.15 77.85 0.8268
下载: 导出CSV
-
[1] Wang B K, Huang Y F, Yang W X, Li X. Short text classification based on strong feature thesaurus. Journal of Zhejiang University Science C, 2012, 13(9): 649-659 doi: 10.1631/jzus.C1100373 [2] Zelikovitz S, Hirsh H. Improving short text classification using unlabeled background knowledge to assess document similarity. In: Proceedings of the 17th International Conference on Machine Learning. San Francisco, USA: Morgan Kaufmann, 2000. 1183-1190 [3] Bollegala D, Matsuo Y, Ishizuka M. Measuring semantic similarity between words using web search engines. In: Proceedings of the 16th International Conference on World Wide Web. New York, USA: ACM, 2007. 757-766 [4] Gabrilovich E, Markovitch S. Computing semantic relatedness using Wikipedia-based explicit semantic analysis. In: Proceedings of the 20th International Joint Conference on Artificial Intelligence. San Francisco, USA: Morgan Kaufmann, 2007. 1606-1611 [5] Banerjee S, Ramanathan K, Gupta A. Clustering short texts using Wikipedia. In: Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, USA: ACM, 2007. 787-788 [6] Lucene [Online], available: https://lucene.apache.org/, May 3, 2016. [7] Phan X H, Nguyen L M, Horiguchi S. Learning to classify short and sparse text & web with hidden topics from large-scale data collections. In: Proceedings of the 17th International Conference on World Wide Web. New York, USA: ACM, 2008. 91-100 [8] Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation. Journal of Machine Learning Research, 2003, 3: 993-1022 http://cn.bing.com/academic/profile?id=1880262756&encoded=0&v=paper_preview&mkt=zh-cn [9] Kim Y. Convolutional neural networks for sentence classification. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: Association for Computational Linguistics, 2014. 1746-1751 [10] Le Q, Mikolov T. Distributed representations of sentences and documents. In: Proceedings of the 31st International Conference on Machine Learning. Beijing, China: JMLR, 2014. 1188-1196 [11] Kalchbrenner N, Grefenstette E, Blunsom P. A convolutional neural network for modelling sentences. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore, USA: Association for Computational Linguistics, 2014. 655-665 [12] Landauer T K, Foltz P W, Laham D. An introduction to latent semantic analysis. Discourse Processes, 1998, 25(2-3): 259-284 doi: 10.1080/01638539809545028 [13] Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. arXiv: 1301.3781, 2013. [14] Turian J, Ratinov L, Bengio Y. Word representations: a simple and general method for semi-supervised learning. In: Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Uppsala, Sweden: Association for Computational Linguistics, 2010. 384-394 [15] Mikolov T, Yih W T, Zweig G. Linguistic Regularities in Continuous Space Word Representations. In: Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Atlanta, Georgia: Association for Computational Linguistics, 2013. 746-751 [16] Reynolds D A. Speaker identification and verification using Gaussian mixture speaker models. Speech Communication, 1995, 17(1-2): 91-108 doi: 10.1016/0167-6393(95)00009-D [17] Reynolds D A, Quatieri T F, Dunn R B. Speaker verification using adapted Gaussian mixture models. Digital Signal Processing, 2000, 10(1-3): 19-41 doi: 10.1006/dspr.1999.0361 [18] Collobert R, Weston J, Bottou L, Karlen M, Kavukcuoglu K, Kuksa P. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 2011, 12: 2493-2537 [19] Mikolov T, Sutskever I, Chen K, Corrado G S, Dean J. Distributed representations of words and phrases and their compositionality. In: Proceedings of the 2013 Advances in Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates, Inc., 2013. 3111-3119 [20] Porter M F. An algorithm for suffix stripping. Readings in Information Retrieval. San Francisco: Morgan Kaufmann, 1997. 313-316 [21] Ling G C, Asahara M, Matsumoto Y. Chinese unknown word identification using character-based tagging and chunking. In: Proceedings of the 41st Annual Meeting on Association for Computational Linguistics. Sapporo, Japan: Association for Computational Linguistics, 2003. 197-200 [22] Parker R, Graff D, Kong J B, Chen K, Maeda K. English Gigaword Fifth Edition [Online], available: https://catalog.ldc.upenn.edu/LDC2011T07, May 3, 2016. [23] Wang P, Xu B, Xu J M, Tian G H, Liu C L, Hao H W. Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification. Neurocomputing, 2016, 174: 806-814 doi: 10.1016/j.neucom.2015.09.096 [24] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 -


计量
- 文章访问数: 2312
- HTML全文浏览量: 210
- PDF下载量: 918
- 被引次数: 0
