

-
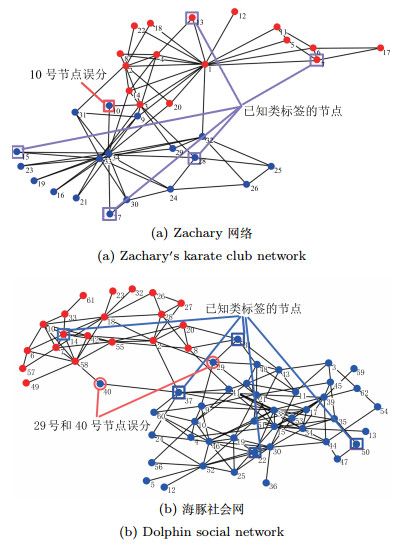
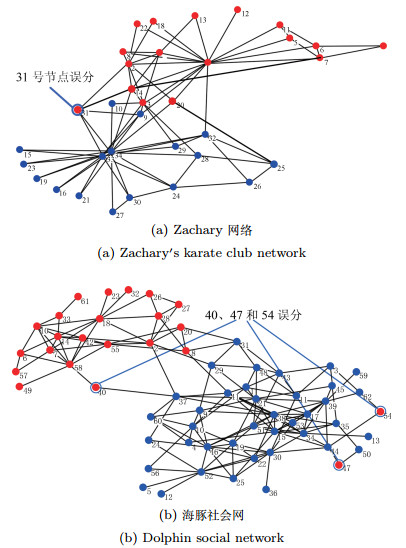
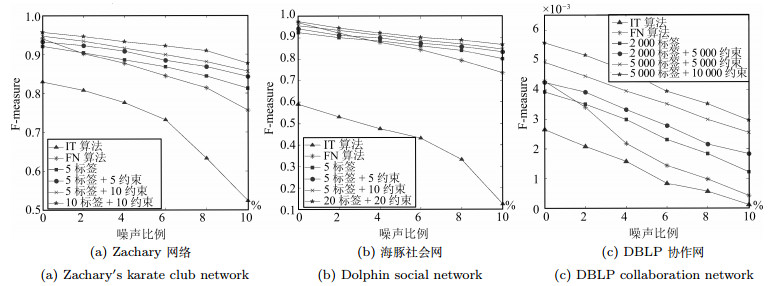
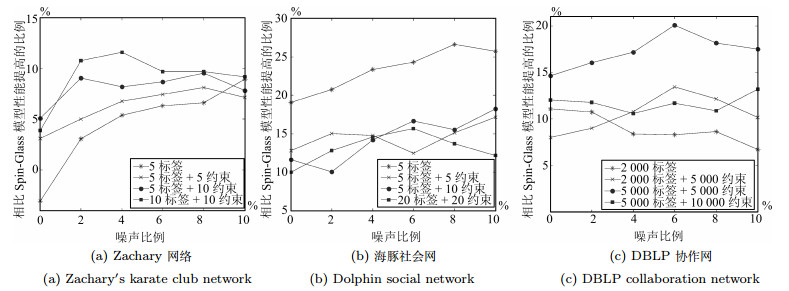
摘要: 社区发现是社交网络分析中一个重要的研究方向.当前大部分的研究都聚焦在自动社区发现问题,但是在具有数据缺失或噪声的网络中,自动社区发现算法的性能会随着噪声数据的增加而迅速下降.通过在社区发现中融合先验信息,进行半监督的社区发现,有望为解决上述挑战提供一条可行的途径.本文基于因子图模型,通过融入先验信息到一个统一的概率框架中,提出了一种基于因子图模型的半监督社区发现方法,研究具有用户引导情况下的社交网络社区发现问题.在三个真实的社交网络数据(Zachary社会关系网、海豚社会网和DBLP协作网)上进行实验,证明通过融入先验信息可以有效地提高社区发现的精度,且将我们的方法与一种最新的半监督社区发现方法(半监督Spin-Glass模型)进行对比,在三个数据集中F-measure平均提升了6.34%、16.36%和12.13%.Abstract: Community detection is an important research direction of social network analysis. Most of the current studies focused on automated community detection. However, in networks having missing data or noise, the ability for an automated community detection algorithm to discover true community structures may degrade rapidly with the increase of noise. On the other hand, semi-supervised community detection provides a feasible way for solving the above problem by incorporating priori information into the community detection process. In this paper, based on the factor graph model, by incorporating the priori information into a unified probabilistic framework, we propose a factor graph-based semi-supervised community detection method. We evaluate the method with three different genres of real datasets (Zachary, Dolphins and DBLP). Experiments indicate that incorporating priori information into the community detection process can improve the prediction accuracy significantly. Compared with a latest semi-supervised community detection algorithm (semi-supervised spin-glass model), the F-measure of our method is on average improved by 6.34%, 16.36% and 12.13% in the three datasets.
-
[1] Fortunato S. Community detection in graphs. Physics Reports, 2010, 486(3-5):75-174 doi: 10.1016/j.physrep.2009.11.002 [2] Eaton E, Mansbach R. A spin-glass model for semi-supervised community detection. In:Proceedings of the 26th AAAI Conference on Artificial Intelligence. Toronto, Ontario, Canada:AAAI, 2012:900-906 [3] Newman M E J, Girvan M. Finding and evaluating community structure in networks. Physical Review E, 2004, 69(2):026113-1-026113-15 https://compepi.cs.uiowa.edu/uploads/Readings/Newman04/newman04.pdf [4] Good B H, De Montjoye Y A, Clauset A. Performance of modularity maximization in practical contexts. Physical Review E, 2010, 81(4):046106-1-046106-19 http://tuvalu.santafe.edu/~aaronc/courses/7000/readings/Good_Montjoye_Clauset_10_PerformanceOfModularityMaximizationInPracticalContexts.pdf [5] Yang Z, Tang J, Li J Z, Yang W J. Social community analysis via a factor graph model. IEEE Intelligent Systems, 2011, 26(3):58-65 doi: 10.1109/MIS.2010.55 [6] Girvan M, Newman M E J. Community structure in social and biological networks. Proceedings of the National Academy of Sciences of the United States of America, 2002, 99(12):7821-7826 doi: 10.1073/pnas.122653799 [7] Brandes U, Delling D, Gaertler M, Gorke R, Hoefer M, Nikoloski Z, Wagner D. On modularity clustering. IEEE Transactions on Knowledge and Data Engineering, 2008, 20(2):172-188 doi: 10.1109/TKDE.2007.190689 [8] Newman M E J. Fast algorithm for detecting community structure in networks. Physical Review E, 2004, 69(6):066133 doi: 10.1103/PhysRevE.69.066133 [9] Duch J, Arenas A. Community detection in complex networks using extremal optimization. Physical Review E, 2005, 72(2):027104 doi: 10.1103/PhysRevE.72.027104 [10] Guimerá R, Amaral L A N. Functional cartography of complex metabolic networks. Nature, 2005, 433(7028):895-900 doi: 10.1038/nature03288 [11] White S, Smyth P. A spectral clustering approach to finding communities in graph. In:Proceedings of the 2005 International Conference on Data Mining. New York, USA:IEEE, 2005, 5:76-84 [12] Guimerá R, Sales-Pardo M, Amaral L A N. Modularity from fluctuations in random graphs and complex networks. Physical Review E, 2004, 70(2):025101-1-025101-4 https://archive.org/details/arxiv-cond-mat0403660 [13] Fortunato S, Barthélemy M. Resolution limit in community detection. Proceedings of the National Academy of Sciences of the United States of America, 2007, 104(1):36-41 doi: 10.1073/pnas.0605965104 [14] Shen H W, Cheng X Q, Fang B X. Covariance, correlation matrix, and the multiscale community structure of networks. Physical Review E, 2010, 82(1):016114-1-016114-9 https://www.researchgate.net/publication/46423234_Covariance_correlation_matrix_and_the_multiscale_community_structure_of_networks [15] Palla G, Derényi I, Farkas I, Vicsek T. Uncovering the overlapping community structure of complex networks in nature and society. Nature, 2005, 435(7043):814-818 doi: 10.1038/nature03607 [16] Palla G, Barabási A L, Vicsek T. Quantifying social group evolution. Nature, 2007, 446(7136):664-667 doi: 10.1038/nature05670 [17] Mucha P J, Richardson T, Macon K, Porter M A, Onnela J-P. Community structure in time-dependent, multiscale, and multiplex networks. Science, 2010, 328(5980):876-878 doi: 10.1126/science.1184819 [18] Ma X K, Gao L, Yong X R, Fu L D. Semi-supervised clustering algorithm for community structure detection in complex networks. Physica A:Statistical Mechanics and its Applications, 2010, 389(1):187-197 doi: 10.1016/j.physa.2009.09.018 [19] Allahverdyan A E, Ver Steeg G, Galstyan A. Community detection with and without prior information. EPL (Europhysics Letters), 2010, 90(1):983-995 http://www.academia.edu/2814591/Community_detection_with_and_without_prior_information [20] Liu D, Liu X, Wang W J, Bai H Y. Semi-supervised community detection based on discrete potential theory. Physica A:Statistical Mechanics and its Applications, 2014, 416:173-182 doi: 10.1016/j.physa.2014.08.051 [21] Li L, Du M, Liu G F, Hu X G, Wu G Q. Extremal optimization-based semi-supervised algorithm with conflict pairwise constraints for community detection. In:Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. New York, USA:IEEE, 2014. 180-187 [22] Yang L, Cao X C, Jin D, Wang X, Meng D. A unified semi-supervised community detection framework using latent space graph regularization. IEEE Transactions on Cybernetics, 2014, 45(11):2585-2598 https://www.researchgate.net/publication/269933321_A_Unified_Semi-Supervised_Community_Detection_Framework_Using_Latent_Space_Graph_Regularization [23] Yang L, Jin D, Wang X, Cao X C. Active link selection for efficient semi-supervised community detection. Scientific Reports, 2015, 5:9039-1-9039-12 https://www.researchgate.net/profile/Xiao_Wang44/publication/273468099_Active_link_selection_for_efficient_semi-supervised_community_detection/links/5530287b0cf20ea0a06f665d.pdf?inViewer=true&pdfJsDownload=true&disableCoverPage=true&origin=publication_detail [24] Tang W B, Zhuang H L, Tang J. Learning to infer social ties in large networks. Machine Learning and Knowledge Discovery in Databases. Berlin Heidelberg:Springer, 2011, 6913:381-397 doi: 10.1007/978-3-642-23808-6_25?no-access=true [25] Hammersley J M, Clifford P. Markov fields on finite graphs and lattices. 1971. http://www.oalib.com/references/16301575 [26] Geman S, Geman D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1984, 6(6):721-741 http://www.ncbi.nlm.nih.gov/pubmed/22499653 [27] Basu S, Bilenko M, Mooney R J. A probabilistic framework for semi-supervised clustering. In:Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA:ACM, 2004. 59-68 [28] Kleinberg J, Tardos É. Approximation algorithms for classification problems with pairwise relationships:Metric labeling and Markov random fields. Journal of the ACM, 2002, 49(5):616-639 doi: 10.1145/585265.585268 [29] Murphy K P, Weiss Y, Jordan M I. Loopy belief propagation for approximate inference:an empirical study. In:Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence. San Francisco, CA, USA:Morgan Kaufmann Publishers Inc., 1999. 467-475 [30] Lusseau D, Schneider K, Boisseau O J, Haase P, Slooten E, Dawson S M. The bottlenose dolphin community of doubtful sound features a large proportion of long-lasting associations. Behavioral Ecology and Sociobiology, 2003, 54(4):396-405 doi: 10.1007/s00265-003-0651-y [31] Yang J, Leskovec J. Defining and evaluating network communities based on ground-truth. Knowledge and Information Systems, 2015, 42(1):181-213 doi: 10.1007/s10115-013-0693-z [32] Basu S. Semi-supervised Clustering:Probabilistic Models, Algorithms and Experiments[Ph.D. dissertation], University of Texas at Austin, USA, 2005. [33] Rosvall M, Bergstrom C T. An information-theoretic framework for resolving community structure in complex networks. Proceedings of the National Academy of Sciences of the United States of America, 2007, 104(18):7327-7331 doi: 10.1073/pnas.0611034104 -

 下载:
下载:




图(7)
计量
- 文章访问数: 2537
- HTML全文浏览量: 535
- PDF下载量: 765
- 被引次数: 0
