

-
摘要: 基于区分业务优先级和提高系统时延性能的网络需求,提出了依托站点状态的两级轮询控制系统.系统在混合服务两级轮询模型的基础上,根据站点缓冲区状态采用并行调度方式仅对有数据分组的活动站点提供服务.该模型既能满足区分站点优先级的需求又能避免空闲查询,从而提高系统利用率、降低等待时延.采用嵌入式马尔科夫链和概率母函数的方法对该系统建立数学模型,对系统平均等待时延特性进行了精确解析.通过理论计算与仿真实验结果的对比验证了理论分析的正确性,与已有两级轮询系统相比,具有更好的时延性能.Abstract: Based on priority differentiation and the system efficiency, this paper proposes a station dependent two-level polling system. The mixed service two-level polling system is extended by using queue state-dependent routing, in which only active stations with information packets could be visited by server. The scheme meets the requirement not only for conflict free but also for priority differentiation and efficiency, and provides a lower latency. An embedded Markov chain framework is set up to drive the closed-form expression for the mean waiting time. Numerical examples demonstrate that theoretical and simulation results are identical and the new system has a better efficiency at both key station and normal station.
-
Key words:
- Polling system /
- priority queue /
- performance evaluation /
- time-delay
-

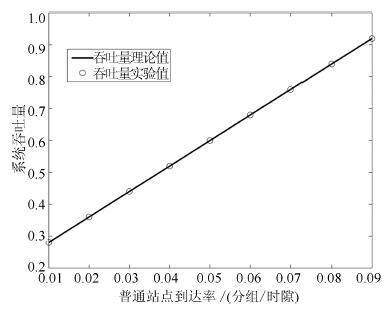
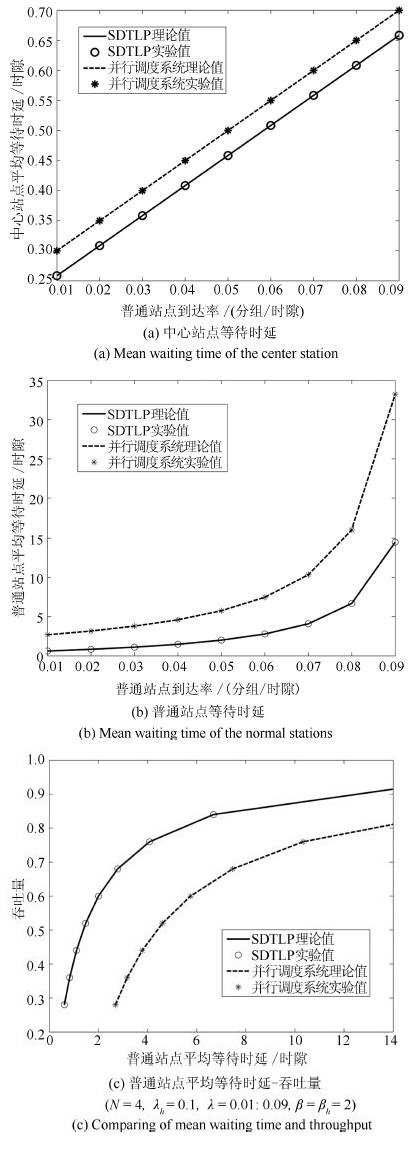
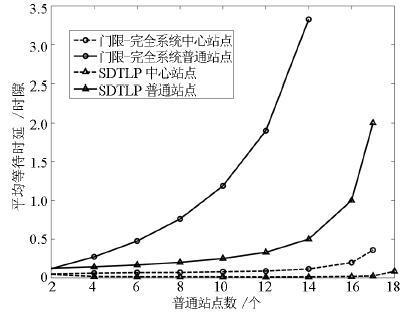
图 2 平均等待时延与系统参数的关系
Fig. 2 Relationship between the mean waiting time and thesystem parameters
-
[1] Boon M A A, van der Mei R D, Winands E M M. Applications of polling systems. Surveys in Operations Research and Management Science, 2011, 16(2):67-82 doi: 10.1016/j.sorms.2011.01.001 [2] 赵继军, 谷志群, 薛亮, 李志华, 关新平. WSN中层次型拓扑控制与网络资源配置联合设计方法. 自动化学报, 2015, 41(3):646-660 http://www.aas.net.cn/CN/abstract/abstract18641.shtmlZhao Ji-Jun, Gu Zhi-Qun, Xue Liang, Li Zhi-Hua, Guan Xin-Ping. A joint design method of hierarchical topology control and network resource allocation for wireless sensor networks. Acta Automatica Sinica, 2015, 41(3):646-660 http://www.aas.net.cn/CN/abstract/abstract18641.shtml [3] Panagiotakis A, Nicopolitidis P, Papadimitriou G I, Sarigiannidis P G. Performance increase for highly-loaded RoF access networks. IEEE Communications Letters, 2015, 19(9):1628-1631 doi: 10.1109/LCOMM.2015.2456911 [4] Zhao W B, Tang X Y. Scheduling sensor data collection with dynamic traffic patterns. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(4):789-802 doi: 10.1109/TPDS.2012.163 [5] Rasul A, Erlebach T. Reducing idle listening during data collection in wireless sensor networks. In:Proceedings of the 10th International Conference on Mobile Ad-hoc and Sensor Network. Maui, USA:IEEE, 2014.16-23 https://www.computer.org/csdl/proceedings/msn/2014/7394/00/index.html [6] Guan Z, Zhao D F, Zhao Y F. A discrete time two-level mixed service parallel polling model. Journal of Electronics (China), 2012, 29(1-2):103-110 doi: 10.1007/s11767-012-0781-3 [7] Boon M A A, Adan I J B F, Boxma O J. A two-queue polling model with two priority levels in the first queue. Discrete Event Dynamic Systems, 2010, 20(4):511-536 doi: 10.1007/s10626-009-0072-9 [8] Boon M A A, Adan I J B F, Boxma O J. A polling model with multiple priority levels. Performance Evaluation, 2010, 67(6):468-484 doi: 10.1016/j.peva.2010.01.002 [9] 刘强, 张中兆, 张乃通. 排队优先权站点轮询系统的平均周期时间. 通信学报, 1999, 20(2):86-91 http://www.cnki.com.cn/Article/CJFDTOTAL-TXXB902.014.htmLiu Qiang, Zhang Zhong-Zhao, Zhang Nai-Tong. Mean cyclic time of queueing priority station polling system. Journal of China Institute of Communications, 1999, 20(2):86-91 http://www.cnki.com.cn/Article/CJFDTOTAL-TXXB902.014.htm [10] 杨志军, 丁洪伟, 陈传龙. 完全服务和门限服务两级轮询系统E(x)特性分析. 电子学报, 2014, 42(4):774-778 http://www.cnki.com.cn/Article/CJFDTotal-DZXU201404023.htmYang Zhi-Jun, Ding Hong-Wei, Chen Chuan-Long. Research on E(x) characteristics of two-class polling system of exhaustive-gated service. Acta Electronica Sinica, 2014, 42(4):774-778 http://www.cnki.com.cn/Article/CJFDTotal-DZXU201404023.htm [11] Liu Q L, Zhao D F, Zhou D M. An analytic model for enhancing IEEE 802.11 point coordination function media access control protocol. European Transactions on Telecommunications, 2011, 22(6):332-338 doi: 10.1002/ett.v22.6 [12] 何敏, 赵东风, 刘心松. 移动Ad hoc网络分布式并行接入控制协议分析. 系统工程与电子技术, 2007, 29(3):443-448 http://www.cnki.com.cn/Article/CJFDTOTAL-XTYD200703031.htmHe Min, Zhao Dong-Feng, Liu Xin-Song. Analysis of a distributed parallel access control protocol for mobile ad hoc networks. Systems Engineering and Electronics, 2007, 29(3):443-448 http://www.cnki.com.cn/Article/CJFDTOTAL-XTYD200703031.htm [13] Dorsman J P L, Boxma O J, van der Mei R D. On two-queue Markovian polling systems with exhaustive service. Queueing Systems, 2014, 78(4):287-311 doi: 10.1007/s11134-014-9413-y [14] Dorsman J P, Borst S C, Boxma O J, Vlasiou M. Markovian polling systems with an application to wireless random-access networks. Performance Evaluation, 2015, 85-86:33-51 doi: 10.1016/j.peva.2015.01.008 [15] 余淼, 胡占义. 高阶马尔科夫随机场及其在场景理解中的应用. 自动化学报, 2015, 41(7):1213-1234 http://www.aas.net.cn/CN/abstract/abstract18696.shtmlYu Miao, Hu Zhan-Yi. Higher-order Markov random fields and their applications in scene understanding. Acta Automatica Sinica, 2015, 41(7):1213-1234 http://www.aas.net.cn/CN/abstract/abstract18696.shtml [16] 李庆奎, 李梅, 贾新春. 具有Markov跳变参数的闭环供应链系统切换控制. 自动化学报, 2015, 41(12):2081-2091 http://www.aas.net.cn/CN/abstract/abstract18781.shtmlLi Qing-Kui, Li Mei, Jia Xin-Chun. Switching control of closed-loop supply chain systems with Markovian jumping parameters. Acta Automatica Sinica, 2015, 41(12):2081-2091 http://www.aas.net.cn/CN/abstract/abstract18781.shtml [17] Kim J, Kim B. Stability of a cyclic polling system with an adaptive mechanism. Journal of Industrial and Management Optimization, 2015, 11(3):763-777 http://cn.bing.com/academic/profile?id=2315384942&encoded=0&v=paper_preview&mkt=zh-cn [18] 赵东风, 李必海, 郑苏民. 周期查询式限定服务排队系统研究. 电子科学学刊, 1997, 19(1):44-49 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX199701007.htmZhao Dong-Feng, Li Bi-Hai, Zheng Su-Min. Study of polling systems with limited service. Journal of Electronics, 1997, 19(1):44-49 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX199701007.htm [19] 赵东风, 郑苏民. 查询式完全服务排队模型分析. 电子学报, 1994, 22(5):102-107 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU405.018.htmZhao Dong-Feng, Zheng Su-Min. Analysis of a polling model with exhaustive service. Acta Electronica Sinica, 1994, 22(5):102-107 http://www.cnki.com.cn/Article/CJFDTOTAL-DZXU405.018.htm -

 下载:
下载:


图(5)
计量
- 文章访问数: 1687
- HTML全文浏览量: 251
- PDF下载量: 657
- 被引次数: 0
