

-
摘要: 提出了一种基于视觉知识加工模型的目标识别方法. 该加工模型结合目标定位、模板筛选和MFF-HMAX (Hierarchical model and X based on multi-feature fusion)方法对图像进行学习, 形成相应的视觉知识库, 并用于指导目标的识别. 首先, 利用Itti模型获取图像的显著区, 结合视觉通路中What和Where通道的位置、大小等特征以及视觉知识库中的定位知识确定初期候选目标区域; 然后, 采用二步去噪处理获取候选目标区域, 利用MFF-HMAX模型提取目标区域的颜色、亮度、纹理、轮廓、大小等知识特征, 并采用特征融合思想将各项特征融合供目标识别; 最后, 与单一特征以及目前的流行方法进行对比实验, 结果表明本文方法不仅具备较高的识别效果, 同时能够模仿人脑学习视觉知识的过程形成视觉知识库.Abstract: A novel object recognition method based on visual knowledge processing model is presented. Combined with object localization, template screening and hierarchical model and X based on multi-feature fusion (MFF-HMAX) method, the visual knowledge processing model yields a visual knowledge base which can be used as a guide in object recognition. Firstly, significant areas of the image can be obtained via Itti model; according to these areas and "what" and "where" information, such as location, size, etc., the candidate objects are conformed. Secondly, MFF-HMAX model is used to extract various features, like color, intensity, texture, contour, size, etc., from the objects denoised by the two-step denoising process. After multi-feature fusion, the features can be used in object recognition. Finally, the method is tested and compared with single feature method and current popular methods. The results show that this method can not only get good performance in improving accuracy of object detection, but also yield a base of visual knowledge by imitating the forming process in human brain.
-

图 2 基于视觉知识加工模型的目标识别方法图
Fig. 2 Object recognition method based on visual knowledge processing

图 4 原图与候选目标对象图的对比图
Fig. 4 Comparison between the original images and the candidate object

图 5 二步去噪处理后的轮廓信息图
Fig. 5 The contour information maps after two-step denoising processing

图 7 不同方法针对Caltech 101数据集的分类效果对比图
Fig. 7 Performance of different methods for Caltech 101
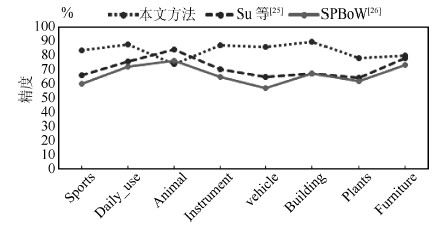
图 8 Caltech 101数据集不同类型的分类效果对比图
Fig. 8 Performance for different categories of Caltech 101

图 9 Pascal 2007数据集不同类型的分类效果对比图
Fig. 9 Performance for different categories of Pascal 2007
表 1 本文方法参数设置
Table 1 Parameters setting of our method
Band $\Sigma$ Filt sizes $\delta$ $\lambda$ $N$$^\Sigma$ Orient $\theta$ Patch $n_j$ 1 7 & 9 2.8 & 3.6 3.5 & 4.6 8 0 4$\times$4 2 11 & 13 4.5 & 5.4 5.6 & 6.8 10 3 15 & 17 6.3 & 7.3 7.9 & 9.1 12 $\dfrac{\pi}{4}$ 8$\times$8 4 19 & 21 8.2 & 9.2 10.3 & 11.5 14 5 23 & 25 10.2 & 11.3 12.7 & 14.1 16 $\dfrac{\pi}{2}$ 12$\times$12 6 27 & 29 12.3 & 13.4 15.4 & 16.8 18 7 31 & 33 14.6 & 15.8 18.2 & 19.7 20 $\dfrac{3\pi}{4}$ 14$\times$14 8 35 & 37 17.0 & 18.2 21.2 & 22.8 22  下载: 导出CSV
下载: 导出CSV
-
[1] Serre T, Wolf L, Poggio T. Object recognition with features inspired by visual cortex. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). San Diego, CA: IEEE, 2005. 994-1000 [2] 朱庆生, 张敏, 柳锋. 基于HMAX特征的层次式柑桔溃疡病识别方法. 计算机科学, 2008, 35(4): 231-232Zhu Qing-Sheng, Zhang Min, Liu Feng. Hierarchical citrus canker recognition based on HMAX features. Computer Science, 2008, 35(4): 231-232 [3] 汤毓婧. 基于人脑视觉感知机理的分类与识别研究 [硕士学位论文], 南京理工大学, 中国, 2009Tang Yu-Qian. Classification and Recognition Research based on Human Visual Perception Mechanism [Master dissertation], Nanjing University of Science, China, 2009 [4] 江达秀. 基于HMAX模型的人脸表情识别研究 [硕士学位论文], 浙江理工大学, 中国, 2010Jiang Da-Xiu. Research on the Facial Expression Recognition based on HMAX model [Master dissertation], Zhejiang Sci-Tech University, China, 2010 [5] Walther D, Koch C. Modeling attention to salient proto-objects. Neural Networks, 2006, 19(9): 1395-1407 [6] 何佳聪,蔡恒进,邓娟,吕恒,刘翘楚. 基于改进的 HMAX 算法的车型识别应用. 计算机科学与应用, 2012, 2(5): 233-239He Jia-Cong, Cai Heng-Jin, Deng Juan, Lv Heng, Liu Qiao-Chu. Improved HMAX model for vehicle type recognition. Computer Science and Application, 2012, 2(5): 233-239 [7] 邱香, 傅小兰, 隋丹妮, 李健, 唐一源. 复合字母刺激心理旋转加工中的整体优先效应. 心理学报, 2009, 41(1): 1-9Qiu Xiang, Fu Xiao-Lan, Sui Dan-Ni, Li Jian, Tang Yi-Yuan. The effect of global precedence on mental rotation of compound stimuli. Acta Psychologica Sinica, 2009, 41(1): 1-9 [8] Navon D. Forest before trees: the precedence of global features in visual perception. Cognitive psychology, 1977, 9(3): 353-383 [9] 胡湘萍. 基于多核学习的多特征融合图像分类研究. 计算机工程与应用, 2016, 52(5): 194-198Hu Xiang-Ping. Multiple feature fusion via multiple kernel learning for image classification. Computer Engineering and Applications, 2016, 52(5): 194-198 [10] Borji A, Sihite D N, Itti L. Probabilistic learning of task-specific visual attention. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI: IEEE, 2012. 470-477 [11] Itti L, Koch C. Feature combination strategies for saliency-based visual attention systems. Journal of Electronic Imaging, 2001, 10(1): 161-169 [12] Chikkerur S, Serre T, Tan C, Poggio T. What and where: a Bayesian inference theory of attention. Vision Research, 2010, 50(22): 2233-2247 [13] Navalpakkam V, Itti L. An integrated model of top-down and bottom-up attention for optimizing detection speed. In: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). New York, NY: IEEE, 2006. 2049-2056 [14] Marat S, Itti L. Influence of the amount of context learned for improving object classification when simultaneously learning object and contextual cues. Visual Cognition, 2012, 20(4-5): 580-602 [15] Ungerleider L G. Two cortical visual systems. Analysis of Visual Behavior. Cambridge: MIT Press, 1982. 549-586 [16] Riesenhuber M, Poggio T. Hierarchical models of object recognition in cortex. Nature Neuroscience, 1999, 2(11): 1019-1025 [17] Zhou H, Friedman H S, Von Der Heydt R. Coding of border ownership in monkey visual cortex. The Journal of Neuroscience, 2000, 20(17): 6594-6611 [18] DiCarlo J J, Maunsell J H R. Form representation in monkey inferotemporal cortex is virtually unaltered by free viewing. Nature Neuroscience, 2000, 3(8): 814-821 [19] Zien A, Ong C S. Multiclass multiple kernel learning. In: Proceedings of the 24th International Conference on Machine Learning. Corvallis, OR: ACM, 2007. 1191-1198 [20] Vedaldi A, Fulkerson B. Vlfeat: an open and portable library of computer vision algorithms. In: Proceedings of the 18th ACM International Conference on Multimedia. Firenze: ACM, 2010. 1469-1472 [21] Sohn K, Jung D Y, Lee H, Hero A O. Efficient learning of sparse, distributed, convolutional feature representations for object recognition. In: Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV). Barcelona, Spain: IEEE, 2011. 2643-2650 [22] Balasubramanian K, Yu K, Lebanon G. Smooth sparse coding via marginal regression for learning sparse representations. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, Georgia, USA: IMLS, 2012. 289-297 [23] Wang J J, Yang J C, Yu K, Lv F J, Huang T, Gong Y H. Locality-constrained linear coding for image classification. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, CA: IEEE, 2010. 3360-3367 [24] Qiao M, Li J. Distance-based mixture modeling for classification via hypothetical local mapping. Statistical Analysis and Data Mining: The ASA Data Science Journal, 2016, 9(1): 43-57 [25] Su Y, Jurie F. Improving image classification using semantic attributes. International Journal of Computer Vision, 2012, 100(1): 59-77 [26] Wu L, Hoi S C H, Yu N H. Semantics-preserving bag-of-words models and applications. IEEE Transactions on Image Processing, 2010, 19(7): 1908-1920 [27] 杨波, 敬忠良. 梅花形采样离散小波框架图像融合算法. 自动化学报, 2010, 36(1): 12-22Yang Bo, Jing Zhong-Liang. Image fusion algorithm based on the quincunx-sampled discrete wavelet frame. Acta Automatica Sinica, 2010, 36(1): 12-22 [28] 朱仁欢, 魏海锋, 卢一相, 孙冬. 不均匀光照车牌增强算法研究. 小型微型计算机系统, 2015, 36(3): 601-604Zhu Ren-Hua, Wei Hai-Feng, Lu Yi-Xiang, Sun Dong. Study on enhancement algorithm of license plate under non-uniform illumination. Journal of Chinese Computer Systems, 2015, 36(3): 601-604 [29] 张小利, 李雄飞, 李军. 融合图像质量评价指标的相关性分析及性能评估. 自动化学报, 2014, 40(2): 306-315Zhang Xiao-Li, Li Xiong-Fei, Li Jun. Validation and correlation analysis of metrics for evaluating performance of image fusion. Acta Automatica Sinica, 2014, 40(2): 306-315 [30] 徐萌萌. 基于小波变换的图像融合算法研究 [硕士论文], 哈尔滨理工大学, 中国, 2014Xu Meng-Meng. Image Fusion Algorithm based on Wavelet Transform [Master dissertation], Harbin University of Science and Technology, China, 2014 [31] 郭雄飞. 图像融合技术研究与应用 [硕士学位论文], 中北大学, 中国, 2014Guo Xiong-Fei. Image Fusion Algorithms Research and Application [Master dissertation], North University of China, China, 2014 -

 下载:
下载:



计量
- 文章访问数: 2263
- HTML全文浏览量: 407
- PDF下载量: 900
- 被引次数: 0
