

Local Image Descriptor of Feature Combination and Rotation Invariant Space Division Combination
-
摘要: 提出了一种新的局部图像描述符: 特征联合和旋转不变空间分割联合描述符(Feature combination and rotation invariant space division combination descriptor, FCSCD). 提出了一种新的局部特征: WLBP (Weber local binary pattern), 该特征由局部二进制模式和韦伯二进制差分激励联合得到. 提出了一种新的用于特征汇聚的旋转不变空间分割方法, 该方法由强度序空间分割和圆环空间分割联合得到. WLBP在局部旋转不变坐标系计算得到, 强度序和圆环空间分割本身也具有旋转不变性, 所以FCSCD描述符在不需要计算图像块主方向下保持了旋转不变性. 与现有的局部描述符相比, 本文的联合方法编码了多种类型的信息在描述符直方图中, 所以FCSCD辨别能力更强, 鲁棒性更强. 图像匹配实验结果表明了本文方法的有效性和优越性, 所提出的描述符具有很高的匹配性能, 优于其他的主流局部描述符(SIFT、CS-LBP、OSID、LIOP、EOD和MRRID).Abstract: This paper proposes a novel local image descriptor called FCSCD (feature combination and rotation invariant space division combination descriptor). A new local feature, WLBP (Weber local binary pattern), is proposed which combines Weber binary differential excitation and local binary pattern. A new rotation-invariant space division for feature pooling is also proposed which combines intensity order space division and annular space division. WLBP is computed in a rotation invariant local coordinate system. Intensity order and annular space division are inherently rotation invariant. So, FCSCD obtains rotation invariance without computing principle orientation of the image patch. Compared with other existing descriptors, this combination method makes FCSCD encode various types of information into a histogram, and so it is more distinctive and robust. Experimental results on image matching demonstrate the effectiveness and superiorities of the proposed descriptor compared to the state-of-the-art descriptors including SIFT, CS-LBP, OSID, LIOP, EOD, and MRRID.
-
Key words:
- Local image descriptor /
- SIFT /
- image matching /
- rotation invariance
-
云控制系统[1-2]在结构上表现为云计算与信息物理系统的深度融合, 在性能上体现了网络化控制系统[3]和云计算技术[4]的优点.如图 1所示, 云控制系统主要涉及物联网[5]、多智能体系统[6]和复杂系统[7]的控制.云计算为云控制系统中大数据存储与处理、控制器设计和控制系统性能优化提供了有力的技术支持.
云控制系统研究目前正处在起始阶段, 面临着许多挑战[8].建立云计算、物理对象、计算软件与通信网络的综合模型是云控制系统设计的首要问题.总体任务的分割以及分布式计算单元任务的分配都是云控制系统设计的关键环节.合理提炼云控制系统的性能指标, 并对其进行分析和优化, 对设计云控制系统具有实际意义.
Petri网[9-11]因可表征同步、并发等现象在计算机软硬件[12]、分布式数据库[13]、生产管理[14]、通信网络[15]、生物[16]等系统的建模和分析中有着广泛的应用.极大-加代数[17-19]是一个具有重要理论意义和应用价值的代数系统.基于极大-加代数的线性系统理论已有许多研究.例如, 极大-加线性系统的周期性[20-23]、稳定性[24-25]、能达性[26-28]和可预测性[29-30]等. Baccelli等[18]运用极大-加代数方法给出了Petri网的动态方程.
本文运用Petri网模拟云控制系统的并行处理过程, 并采用极大-加代数方法分析系统性能.并行计算[31]是云计算系统的核心技术, 基本思想是用多个处理器协同求解同一问题, 就是将要求解的问题分解成若干子过程, 让多个子部件并行地处理问题.本文引入并行处理系统的时钟周期、吞吐率和任务完成时间性能指标.并行处理能力强的系统应具备时钟周期小、吞吐率高、任务完成时间短等特点.时钟周期受限于瓶颈子过程的运行时间.从理论角度来看, 子过程划分越细, 系统的时钟周期就越小, 吞吐率就越高, 任务完成时间就越短.然而, 考虑到指令在锁存器中的存取时间, 子过程的细分因锁存器增多而增加指令在子部件之间的传输延迟, 从而一定程度上会抵消因子过程细分而带来的吞吐率提高的效果.采用何种原则对子过程进行分割?如何合理分配各子过程的运行时间, 使任务完成时间最短?在发生指令相关的情况下, 如何用Petri网模拟并行处理过程, 以分析系统性能?是本文将要研究的问题.采用重复设置多套瓶颈段并联的方式同样可达到减小时钟周期的目的, 同时避免因锁存器的增多造成总传输延迟增长的弊端.如何对瓶颈子过程进行并联控制? {如何设置并联通道的数目, 以使任务完成时间最短?}也是本文将要研究的问题.
本文结构如下:第1节介绍有关极大-加代数以及Petri网的概念和结论. {第2节建立云控制器并行处理指令的Petri网模型.第3节提出子过程细分的优化方法, 并给出使得任务完成时间最短的任务分配优化算法.第4节提出重复设置多套瓶颈段并联的优化方法, 并运用Petri网实现瓶颈子过程的并联控制.}第5节概括本文的结论, 并提出进一步研究的问题.
1. 预备知识
本节介绍极大-加代数、极大-加代数上的矩阵以及Petri网等相关数学概念.未加注明的定义和符号源自文献[17-18].
${\bf R}$是实数集.定义集合上的加法和乘法运算:对于,
$ a\oplus b=\max\{a, b\}, \ \ a\otimes b=a+b $
(${\bf R}\cup \{-\infty\}, \oplus, \otimes)$构成一个代数系统, 称为极大-加代数, 记为${\bf R}_{\max}$.在${\bf R}_{\max}$中, 零元为$-\infty$, 用符号$\varepsilon$表示; 单位元为$0$, 用符号$e$表示.
${\bf R}_{\max}^{m\times n}$表示${\bf R}_{\max}$上$m\times n$矩阵的集合.定义极大-加代数上矩阵的加法、乘法和标量运算:对于${A}$ $=$ $( a_{ij})$, , ${A}\oplus {B}$定义为
$ ({A}\oplus {B})_{ij}= a_{ij}\oplus b_{ij} $
对于$ {A}=( a_{ij})\in{\bf R}_{\max}^{m\times p}$, , ${A}$ $\otimes$ ${B}$定义为
$ {{(A\otimes B)}_{ij}}=\underset{l=1}{\overset{p}{\mathop{\oplus }}}\,{{a}_{il}}\otimes {{b}_{lj}} $
对于$a\in{\bf R}_{\max}$, , $a {\circ}{A}$定义为
$ (a {\circ}{A})_{ij}=a\otimes a_{ij} $
构成一个代数系统, 其中零矩阵和单位矩阵分别为
$ {\mathcal{E}_{n}}=\begin{pmatrix} \varepsilon &\varepsilon&\cdots&\varepsilon \\ \varepsilon &\varepsilon& \cdots&\varepsilon \\ \vdots&\vdots&\ddots &\vdots \\ \varepsilon&\varepsilon&\cdots&\varepsilon \end{pmatrix}\rm{\ 和\ }\mathit{I_n}=\begin{pmatrix} e &\varepsilon&\cdots&\varepsilon \\ \varepsilon &e& \cdots&\varepsilon \\ \vdots&\vdots&\ddots&\vdots \\ \varepsilon&\varepsilon&\cdots &e \end{pmatrix} $
在不引起混淆的情况下, 乘法运算符号$\otimes$、{标量运算符号$\circ$}以及零矩阵和单位矩阵的维数通常省略不写.把${\bf R}_{\max}^{n\times n}$中$l$个相同矩阵的乘积写成幂的形式:
$ {A}^{l}=\underbrace{ {A}\otimes {A}\otimes\cdots \otimes {A}}_{l\ \rm{个}} $
方阵${A}$的${A}^{*}$运算定义为
$ {A}^{*}= {I}\oplus {A}\oplus {A}^{2}\oplus \cdots $
$({\bf R}_{\max}^{n\times 1}, \oplus, {\circ})$构成${\bf R}_{\max}$上的一个$n$维列向量空间, 简记为${\bf R}_{\max}^{n}$, 其中零向量为$\mathcal{E}_{n\times1}$.设${A}\in{\bf R}_{\max}^{n\times n}$, 如果存在$\lambda\in{\bf R}_{\max}$和非零$n$维向量${\pmb v}$使得${A}{\pmb v}$ $=\lambda {\pmb v}, $则称$\lambda$为${A}$的特征值, ${\pmb v}$为${A}$的属于特征值$\lambda$的特征向量. Olsder等[32-33]证明了极大-加代数上任意$n\times n$矩阵至少存在一个特征值.关于极大-加代数上矩阵特征值和特征向量的刻画与计算, 可参见文献[20, 22-23, 34-35].
设${A}=( a_{ij})\in{\bf R}_{\max}^{n\times n}$.矩阵${A}$的前趋图是一个包含$n$个结点的赋权有向图, 且满足当时, 存在一条从结点$j$到结点$i$且权重为$a_{ij}$的有向弧; 当$a_{ij}=\varepsilon$时, 不存在从结点$j$到结点$i$的有向弧.矩阵${A}$的前趋图记为$\mathcal{G}({A})$. Karp[36]证明了$\mathcal{G}({A})$的极大回路均值就是矩阵${A}$的一个特征值.
Petri网[9-11, 18]是一种特殊的赋权有向图, 可表示为一个六元组
$ PN=(\mathcal{P}, \ \mathcal{Q}, \ F, \ W, \ M, \ M_{0}) $
其中, $\mathcal{P}=\{p_{1}, p_{2}, \cdots, p_{m}\}$为位置集, $\mathcal{Q}=\{q_{1}, q_{2}, $ $\cdots$, $q_{n}\}$为变迁集, $F$为有向弧集, $W$为有向弧的权函数, $M$为状态标识(也称为托肯(Token)), $M_{0}$为初始标识.如果变迁$q_{j}$的每一个输入位置$p_{i}$中至少包含1个托肯, 则称变迁$q_{j}$的发射是使能的. Petri网中的一个使能变迁完成发射后, 各输入位置减少1个托肯, 输出位置增加1个托肯.
具有兼容初始条件的计时Petri网的状态向量${\pmb x}(k)$ $=$ $(x_{i}(k))\in{\bf R}_{\max}^{n}$满足如下动态方程:
$ \begin{align*} {\pmb x}(k)=&\ {A}(k, k){\pmb x}(k)\oplus {A}(k, k-1){\pmb x}(k-1)\oplus\cdots\oplus\\ &\ {A}(k, k-N){\pmb x}(k-N), \ \ k=1, 2, \cdots \end{align*} $
令$\mu_{i}$表示位置$p_{i}$包含初始托肯的数目, $\alpha_{i}$表示位置$p_{i}$的保留时间, 则$N=\bigoplus_{i=1}^{|\mathcal{P}|}\mu_{i}$且状态矩阵${A}(k, k)$, $\cdots$, ${A}(k, k-N)$的定义为
$ {{A}_{jl}}(k,k-m)=\underset{\{i\in {{\pi }^{q}}(j)|{{\pi }^{p}}(i)=l,{{\mu }_{i}}=m\}}{\mathop \oplus }\,{{\alpha }_{i}} $
其中, $\pi^{q}(j)$表示变迁$q_{j}$的输入位置, $\pi^{p}(i)$表示位置$p_{i}$的输入变迁.
2. 并行处理系统Petri网模型
在云控制系统中, 随着系统规模的扩大, 系统的感知移动设备、测量工具、软件日志、音视觉输入设备、射频识别器和无线网络传感器等将产生海量数据.为了描述这些数据, 人们提出了一个新的概念:大数据[37].云计算的迅速发展为大数据存储与处理、控制器设计和控制系统性能优化提供了有力的技术支持.并行计算是云计算系统的核心技术, 基本思想是用多个处理器协同求解同一问题, 就是将要求解的问题分解成若干子过程, 让多个子部件并行执行运算处理.
在云控制系统中, 大数据存储在云端.云控制器是用户使用云服务的可见入口点和管理员做出全局决定的部件, 用于回应用户发出的请求或系统管理员发出的管理请求, 做出高层的虚拟机实例调度决定.系统将用户和管理员的请求转化为指令传达给处理器.云控制器的功能主要体现在对这些指令执行过程的控制方面, 它提供系统协同运行所需要的控制信号, 以保证系统按照预先选定的目标和规定的步骤有条不紊地运行.
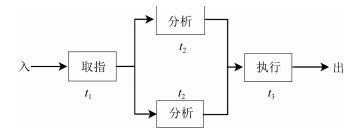
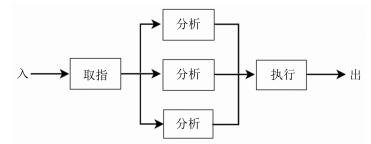
图 2是控制器并行处理指令的一个典型示例.一条指令的处理过程分解为取指、分析和执行三个子过程, 每个子过程可以与其他子过程同时运行.若各子过程的运行时间均为$\triangle t$, 在$2\triangle t$和$3\triangle t$之间, 第$k+2$条指令在取指部件取指, 同时第$k+1$条指令在分析部件分析, 而第$k$条指令则在执行部件执行.多个部件在时间上交错重叠地并行工作, 加快了程序的运行速度.
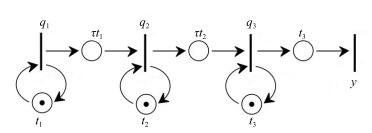
实际上, 各子过程的运行时间不一定相同.设取指、分析和执行三个子过程的运行时间分别为$t_{1}$, $t_{2}$, $t_{3}$, 锁存器的传输延迟为$\tau$ (为平滑缓冲各子部件的速度差异, 往往在子部件之间设置高速接口锁存器来保存中间结果.这些锁存器受同一时钟信号控制, 以实现各子部件信息流的同步推进), 则上述并行处理系统可由如图 3所示的Petri网描述, 其中变迁$q_{1}$, $q_{2}$, $q_{3}$分别表示指令的取指、分析和执行, $y$表示结果的输出.
设有$m$条指令等待处理, $x_{1}(k)$, $x_{2}(k)$, $x_{3}(k)$分别表示第$k$条指令开始取指、分析和执行的时刻, $y(k)$表示第$k$条指令输出的时刻, 则上述并行处理过程可表示为如下极大-加线性系统:
$ \begin{align}\label{e1} \begin{cases} {\pmb x}(k)={A}_{0}{\pmb x}(k)\oplus {A}_{1}{\pmb x}(k-1)\\ {y}(k)={C}{\pmb x}(k), \quad k=1, 2, \cdots, m \end{cases} \end{align} $
(1) 其中, 为状态向量,
$ {A}_{0}=\tau\begin{pmatrix} \varepsilon&\varepsilon&\varepsilon\\ t_{1}& \varepsilon&\varepsilon\\ \varepsilon&t_{2}&\varepsilon \end{pmatrix}, \ \ \ {A}_{1}=\begin{pmatrix} t_{1}& \varepsilon&\varepsilon\\ \varepsilon& t_{2}&\varepsilon\\ \varepsilon&\varepsilon&t_{3} \end{pmatrix} $
为状态矩阵, ${C}=(\varepsilon\ \varepsilon\ t_{3})$为输出矩阵.由动态方程(1)迭代可得
$ \begin{align*} {\pmb x}(k)=&\ {A}_{0}{\pmb x}(k)\oplus{A}_{1}{\pmb x}(k-1)=\\ &\ {A}_{0}({A}_{0}{\pmb x}(k)\oplus {A}_{1}{\pmb x}(k-1))\oplus {A}_{1}{\pmb x}(k-1)=\\ &\ {A}_{0}^{2}{\pmb x}(k)\oplus({A}_{0}\oplus{I}){A}_{1}{\pmb x}(k-1)=\\ &\ {A}_{0}^{3}{\pmb x}(k)\oplus({A}^{2}_{0}\oplus{A}_{0}\oplus{I}){A}_{1}{\pmb x}(k-1)=\\ &\ ({A}^{2}_{0}\oplus{A}_{0}\oplus{I}){A}_{1}{\pmb x}(k-1) \end{align*} $
令
$ {A}={A}_{0}^{*}{A}_{1}=\begin{pmatrix} t_{1}& \varepsilon&\varepsilon\\ t^{2}_{1}\tau& t_{2}&\varepsilon\\ t^{2}_{1}t_{2}\tau^{2}& t^{2}_{2}\tau&t_{3} \end{pmatrix} $
则动态方程(1)转化为
$ \begin{align}\label{e2} {\pmb x}(k)={A}{\pmb x}(k-1), \quad k=1, 2, \cdots, m \end{align} $
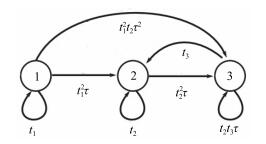
(2) 图 4是矩阵${A}$的前趋图$\mathcal{G}({A})$.由图 4可知, $\mathcal{G}({A})$的极大回路均值(即矩阵${A}$的特征值)为
$ \begin{align}\label{e03} \lambda=\max\{t_{1}, \ t_{2}, \ t_{3}\} \end{align} $
(3) 指令级并行处理系统常常会发生指令相关[31].例如, 当第$k$条指令的结果数地址刚好是第$k+1$条指令的源操作数地址时, 为保证计算结果准确无误, 应是第$k+1$条指令取出第$k$条指令的处理结果后, 才能进行下一步的运算.但是, 如果按照图 5的时间关系进行并行处理, 第$k+1$条指令在``分析''子过程时, 从$C$中取出的源操作数显然不是应有的第$k$条指令存入的结果, 而是第$k$条指令存入结果之前的旧内容, 也就是说, 第$k$条指令与其后的第$k+1$条指令发生了相关.为了避免运算出错, 这时就应等到第$k$条指令流出``执行''部件后, 才能让第$k+1$条指令流入``分析''部件.
发生指令相关的并行处理系统的Petri模型如图 6所示.此时, 动态方程(1)的状态矩阵${A}_{1}$变为
$ \left( \begin{align} &{{t}_{1}}\ \ \varepsilon \ \ \varepsilon \\ &\varepsilon \ \ {{t}_{2}}\ \ {{t}_{3}} \\ &\varepsilon \ \ \varepsilon \ \ {{t}_{3}} \\ \end{align} \right) $
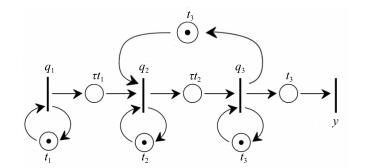 图 6 发生指令相关的并行处理系统的Petri网模型Fig. 6 Petri net of the parallel processing with instruction dependency
图 6 发生指令相关的并行处理系统的Petri网模型Fig. 6 Petri net of the parallel processing with instruction dependency动态方程(2)变为
$ \begin{align*} {\pmb x}(k)={B}{\pmb x}(k-1), \quad k=1, 2, \cdots, m \end{align*} $
其中
$ {B}=\begin{pmatrix} t_{1}& \varepsilon&\varepsilon\\ t^{2}_{1}\tau& t_{2}&t_{3}\\ t^{2}_{1}t_{2}\tau^{2}& t^{2}_{2}\tau&t_{3}t_{2}\tau \end{pmatrix} $
图 7是矩阵${B}$的前趋图$\mathcal{G}({B})$.由图 7可知, $\mathcal{G}({B})$的极大回路均值(即矩阵${B}$的特征值)为, $t_{2}+t_{3}+\tau\}. $显然, 指令相关现象使系统的处理周期变长.假设下文所研究的并行处理系统皆不具有指令相关性.
3. 任务分配优化算法
首先介绍云控制并行处理系统的几个性能指标.
1) 时钟周期$\lambda$
指令级并行处理的所有子过程都由同一个时钟脉冲来控制, 这个时钟脉冲的周期称为时钟周期.由式(3)可知, 并行处理系统的时钟周期受限于最慢的子过程(也称瓶颈子过程)所需要的时间.欲使指令处理不产生拥塞, 要求时钟信号的周期不得低于瓶颈子过程的运行时间.
2) 吞吐率TP
吞吐率是指并行处理系统单位时间内流出的任务数或结果数, 它直接反映了系统的并行处理能力.一个并行处理系统的最大吞吐率是时钟周期的倒数, 即TP$_{\max}=1/\lambda$.
3) 任务完成时间$T(m)$
全部处理完$m$条指令所需要的时间称为任务完成时间.在由动态方程(1)描述的并行处理系统中, 处理$m$条指令的任务完成时间为
$ T(m)=y(m)-x_{1}(0) $
由以上概念可以看出, 一个并行处理能力强的云控制系统应具备时钟周期小、吞吐率高、任务完成时间短等特点.通过改变系统的体系结构, 合理地对总体任务进行分割, 都能达到提高系统处理能力的目的.例如, 对于图 2中的并行处理系统, 如果瓶颈子过程是``分析'', 那么将其再细分成``指令译码''和``取操作数''两个子过程, 如图 8所示.此时, 并行处理系统的时钟周期变为
$ \lambda=\max\{t_{1}, \ t_{21}, \ t_{22}, \ t_{3}\} $
其中, $t_{21}+t_{22}=t_{2}$.显然, 子过程的进一步细分使得系统的时钟周期减小, 吞吐率提高, 任务完成时间也随之缩短.
指令从并行处理系统的一个子过程传输到下一个子过程时, 需考虑各子过程的实际执行时间的差异及可能产生的各子过程之间的干扰.子过程细分会因这类干扰的增多而增加了指令在子过程之间的传输延迟.过度细分反而导致系统的吞吐率下降, 任务完成时间延长.寻求使得任务完成时间最短的子过程的分割数目和各子过程的运行时间, 是值得研究的问题.
设$x_{1}(1)=e$表示首个流入由动态方程(1)描述的并行处理系统的指令的取指时间, 则分析和执行时间分别为
$ \begin{align*} x_{2}(1)&= t_{1}\tau x_{1}(0)=t_{1}\tau\\ x_{3}(1)&= t_{2}\tau x_{2}(0)= t_{1}t_{2}\tau^{2} \end{align*} $
即由动态方程(1)描述的并行处理系统的初始条件为
$ {\pmb x}(1)=\begin{pmatrix} e\\ t_{1}\tau\\ t_{1}t_{2}\tau^{2} \end{pmatrix} $
记$t=t_{1}t_{2}t_{3}$, 则
$ \begin{align*} y(1)=&\ C{\pmb x}(1)=t\tau^{2}\\ y(2)=&\ C{\pmb x}(2)=CA{\pmb x}(1)=\\ &\ t_{1}^{2}t_{2}t_{3}\tau^{2}\oplus t_{1}t_{2}^{2}t_{3}\tau^{2}\oplus t_{1}t_{2}t_{3}^{2}\tau^{2}=\\ &\ (t_{1}\oplus t_{2}\oplus t_{3})t\tau^{2}=\lambda t\tau^{2}=\lambda y(1)\\ &\qquad\qquad \quad \quad\vdots\ \\ y(m)=&\ \lambda y(m-1)=\cdots=\\ &\ \lambda^{m-1}y(1)= t\tau^{2}\lambda^{m-1} \end{align*} $
若将子过程分成$n$段, 则处理$m$条指令的任务完成时间为
$ \begin{align}\label{e3} T(m)=y(m)-x_{1}(0)=t\tau^{n-1}\lambda^{m-1} \end{align} $
(4) 显然, 减小时钟周期$\lambda$可缩短任务完成时间$T(m)$.由于时钟周期受限于瓶颈子过程所需要的时间, 因此, 平均分配各子过程的运行时间, 可最大限度地减小时钟周期. {在实际应用中, 常常会出现工作量过度集中, 而用户较难进行工作量分配的问题, 进而发生系统整体负载不均现象, 导致整体系统效能受限.云控制系统充分利用云计算按需分配的能力, 尽可能合理地将任务均衡分配到各处理器上, 以充分发挥系统的效能[8].
如果子过程的数目为$n$, 且各子过程的运行时间相同, 则上述并行处理系统的时钟周期为$\lambda=t/n$.由此可知, 增加子过程的数目可减小时钟周期.然而, 增加子过程数目$n$又会增加指令在锁存器之间的传输延迟($\tau^{n-1}$), 进而导致任务完成时间$T(m)$的延长.下面给出最优分配方案.
将式(4)表示为传统意义下的代数表达式, 即
$ \begin{align*} T(m)=&\ t+(n-1)\tau+(m-1)\lambda=\\ &\ \tau n+\frac{(m-1)t}{n}+(t-\tau) \end{align*} $
定义目标函数如下:
$ f(n)=\tau n+\frac{(m-1)t}{n} $
求解最优控制问题
$ \begin{align}\label{e4} \min\limits_{n\in{\bf Z}^{+}}f(n) \end{align} $
(5) 其中, ${\bf Z}^{+}$表示正整数的集合.设
$ f(x)=\tau x+\frac{(m-1)t}{x}, \quad x\in {\bf R} $
由Jensen不等式可知, 当且仅当
$ x=\sqrt{\frac{(m-1)t}{\tau}} $
时, 函数$f(x)$取得最小值$2\sqrt{\tau (m-1)t}$.考虑到子过程的数目应为正整数, 令
$ \begin{align*} \underline{n}=\left\lfloor \sqrt{\frac{(m-1)t}{\tau}}\right\rfloor, \ \ \ \overline{n}=\left\lceil\sqrt{\frac{(m-1)t}{\tau}}\ \right\rceil \end{align*} $
其中, $\underline{n}$和$\overline{n}$分别表示$\sqrt{(m-1)t/\tau}$的下取整和上取整(实数$x$的下取整表示不大于$x$的最大整数, 上取整表示不小于$x$的最小整数.例如, 4.5的下取整为$\lfloor4.5\rfloor=4$, 上取整为$\lceil4.5\rceil=5$).于是$\min\{f(\underline{n})$, $f(\overline{n})\}$为目标函数$f(n)$满足约束条件$n$ $\in$ ${\bf Z}^{+}$的最小值, 相应的自变量$n$就是最优控制问题(5)的最优解, 也就是使得任务完成时间$T(m)$最短的子过程分割数目.下面给出求这一最短任务完成时间的算法, 具体步骤为:
步骤1. 计算$\sqrt{(m-1)t/\tau}$.
步骤2. 计算$\underline{n}$和$\overline{n}$.
步骤3. 计算$f(\underline{n})$和$f(\overline{n})$, 并比较二者大小.
步骤4. 若$f(\underline{n})\leq f(\overline{n})$, 则将子过程分割成$\underline{n}$段.此时任务完成时间最短: $T(m)=f(\underline{n})+(t-\tau);$若, 则将子过程分割成$\overline{n}$段.此时任务完成时间最短: $T(m)=f(\overline{n})+(t-\tau).$
在上述算法中, 步骤1需要减法、乘法、除法和开方运算各1次, 共计4次算术运算.步骤2需要上、下取整共2次算术运算.计算$f(x)$分别需要1次减法、2次乘法、1次除法和1次加法运算, 共计5次算术运算.因此, 步骤3计算$f(\underline{n})$和$f(\overline{n})$, 并比较二者大小, 共需$11 (5+5+1)$次算术运算.步骤4计算$T (m)$需要减法和加法运算各1次, 共计2次算术运算.综上所述, 计算最短任务完成时间共需$19 (4+2+11+2)$次算术运算.
下面看一个例子.
例1. 设有50条指令等待处理, 且每条指令取指、分析和执行所需要的时间单位分别为$t_{1}=2$, $t_{2}$ $=$ $5$, $t_{3}=3, $锁存器的传输延迟为$\tau=1$个时间单位, 则
$ \begin{align*} \begin{cases} {\pmb x}(k)={A}{\pmb x}(k-1)\\ {y}(k)={C}{\pmb x}(k), \quad k=1, 2, \cdots, m \end{cases} \end{align*} $
其中,
$ {A}=\begin{pmatrix} 2&\varepsilon&\varepsilon\\ 5&5&\varepsilon\\ 11 &11&3 \end{pmatrix}, \quad {C}=(\varepsilon\ \varepsilon\ 3) $
系统的时钟周期为$\lambda=\max\{t_{1}, \ t_{2}, \ t_{3}\}=5$个时间单位.如果将首条指令的流入时间设为0, 那么由动态方程(1)描述的并行处理系统的初始条件为${\pmb x}(1)$ $=$ $(e\ 3\ 9){'}.$于是
$ \begin{align*} &y(1)=C{\pmb x}(1)=12\\ &y(2)=C{\pmb x}(2)=CA{\pmb x}(1)=17=5y(1)\\ &y(3)=C{\pmb x}(3)={C}{A}^{2}{\pmb x}(1)=22=5^{2}y(1)\\ &\qquad\qquad\qquad \vdots\ \ \ \ \\ &y(50)= 5^{49}y(1)=257 \end{align*} $
由此可知, 处理50条指令的任务完成时间为257个时间单位.下面计算使得任务完成时间$T(m)$最短的子过程分割数目, 以及相应的最短任务完成时间.
令$m=50$, $t=t_{1}t_{2}t_{3}=2+5+3=10$.
步骤1.
$ \sqrt{\frac{(m-1)t}{\tau}}=\sqrt{\frac{49\times10}{1}}\approx22.14 $
步骤2. $\underline{n}=\lfloor22.14\rfloor=22$, $\overline{n}=\lceil22.14\rceil=23$.
步骤3. $f(22)\approx44.27 < f(23)\approx44.30$.
步骤4. 将子过程分成22个, 每个子过程的运行时间约为0.455个时间单位.此时, 处理50条指令的任务完成时间最短, 约为$T(50)=f(22)+(10$ $-$ $1)\approx53.27$个时间单位.
容易验证, 当子过程细分数目超过22时, 子过程数目越多, 任务完成时间反而越长.例如, 如果将子过程细分成30个, 则
$ T(50)=f(30)+(10-1)\approx55.27> 53.27 $
云控制系统中存在大数据.云计算系统利用深度学习等智能算法对这些数据进行处理, 并向系统各个执行部件发送控制信号.处理器并行处理能够提高云计算对大数据的处理能力, 从而更高效地实现云控制系统的自主智能控制.在上面的例子中, 如果处理器每处理一条控制指令, 便生成一组控制信号, 那么在子过程不再细分的情况下, 并行生成50组控制信号需要257个时间单位.相比串行生成50组控制信号所需要的个时间单位, 处理器并行处理使云控制系统控制任务的完成时间缩短了将近一半.如果按照前面的优化算法对子过程进行分割, 即将指令处理过程划分为22个时间相等的子过程, 那么并行生成50组控制信号大约需要53个时间单位.相比子过程不再细分的情况, 这种分配方案使得云控制系统控制任务的完成时间缩短了将近80 %.
4. 瓶颈子过程并联控制
另一种提高系统并行处理能力的途径是重复设置多套瓶颈段并联, 每隔一段时间轮流给其中一个瓶颈段分配任务, 让它们交叉并行, 如图 9所示.多段瓶颈子过程并联控制可有效避免因锁存器增多而造成总传输延迟增长的弊端.这种并联系统同样采用同步时钟信号控制.首先, 设置系统的时钟周期.并联两套处理器轮流分析指令, 使得分析子过程的完成时间$t_{2}$缩短为原来的一半.系统的时钟周期受限于取指、分析和执行三个子过程中最慢的子过程所需要的时间.注意到指令在锁存器中的传输延迟$\tau$, 系统的}时钟周期可设为
$ \begin{align*} \lambda=\max\left\{t_{1}, \ \frac{t_{2}}{2}, \ t_{3}\right\}+\tau \end{align*} $
设$x_{ij}(k)$表示变迁$q_{ij}$第$k$次发射的时刻, 其中, $i=1, 2, 3$, $j=1, 2$; $\overline{y}(k)$和$\widetilde{y}(k)$分别表示上下两个输出端口第$k$次输出结果的时刻, 则该并联系统可表示为如下极大-加线性系统:
$ \begin{align}\label{e6} \begin{cases} {\pmb x}(k)={A}_{0}{\pmb x}(k)\oplus {A}_{1}{\pmb x}(k-1)\\ {\pmb y}(k)={C}{\pmb x}(k), \quad k=1, 2, \cdots \end{cases} \end{align} $
(6) 其中, 状态和输出向量分别为
$ \begin{align*} {\pmb x}(k)=&\ \begin{pmatrix} x_{11}(k)\\ x_{12}(k)\\ x_{21}(k)\\ x_{12}(k)\\ x_{31}(k)\\ x_{32}(k) \end{pmatrix}\\[2mm] {\pmb y}(k)=&\ \begin{pmatrix} \overline{y}(k)\\ \widetilde{y}(k) \end{pmatrix}\end{align*} $
状态矩阵${A}_{0}, {A}_{1}$分别为
$ \begin{pmatrix} \varepsilon&\varepsilon&\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \lambda &\varepsilon&\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \lambda &\varepsilon&\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\lambda &\lambda &\varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\varepsilon&\lambda^{2}& \varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\varepsilon&\varepsilon& \lambda^{2}&\varepsilon& \varepsilon \end{pmatrix}, \ \ \begin{pmatrix} \varepsilon&\lambda &\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\varepsilon&\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\varepsilon&\varepsilon& \lambda &\varepsilon& \varepsilon\\ \varepsilon&\varepsilon&\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\varepsilon&\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\varepsilon&\varepsilon& \varepsilon&\varepsilon& \varepsilon \end{pmatrix} $
输出矩阵为
$ {C}=\begin{pmatrix} \varepsilon&\varepsilon&\varepsilon& \varepsilon&\lambda& \varepsilon\\ \varepsilon&\varepsilon&\varepsilon& \varepsilon&\varepsilon&\lambda \end{pmatrix} $
由动态方程(6)迭代可得
$ \begin{align}\label{e7} {\pmb x}(k)={A}{\pmb x}(k-1), \quad k=1, 2, \cdots \end{align} $
(7) 其中,
$ {A}={A}_{0}^{*}{A}_{1}=\begin{pmatrix} \varepsilon&\lambda &\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\lambda^{2}&\varepsilon& \varepsilon&\varepsilon& \varepsilon\\ \varepsilon&\lambda^{2}&\varepsilon& \lambda &\varepsilon& \varepsilon\\ \varepsilon&\lambda^{3}&\varepsilon& \lambda^{2}&\varepsilon& \varepsilon\\ \varepsilon&\lambda^{4}&\varepsilon& \lambda^{3}&\varepsilon& \varepsilon\\ \varepsilon&\lambda^{5}&\varepsilon& \lambda^{4}&\varepsilon& \varepsilon \end{pmatrix} $
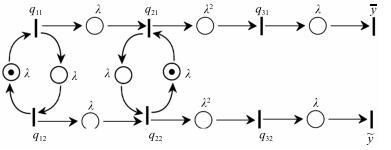
图 10是由动态方程(6)描述的并行处理系统的初始状态(即指令流入前的状态).设$x_{11}(1)=e$表示首个流入并联系统的指令的取指时间, 则各个时刻系统的状态可由如图 11所示的Petri网模型来表征.图 11 (a)是0时刻:变迁$q_{11}$第1次发生, 表示第1条指令取指.图 11 (b)是1时刻:变迁$q_{21}$第1次发生, 表示第1条指令分析; 变迁$q_{12}$第1次发生, 表示第2条指令取指.图 11 (c)是2时刻:变迁$q_{12}$第2次发生, 表示第3条指令取指; 变迁$q_{22}$第1次发生, 表示第2条指令分析.图 11 (d)是3时刻:变迁$q_{12}$第2次发生, 表示第4条指令取指; 变迁$q_{21}$第2次发生, 表示第3条指令分析; 变迁$q_{31}$第1次发生, 表示第1条指令执行.图 11 (e)是4时刻:变迁$q_{11}$第3次发生, 表示第5条指令取指; 变迁$q_{22}$第2次发生, 表示第4条指令分析; 变迁$q_{32}$第1次发生, 表示第2条指令执行; 第1条指令的执行结果从$\bar{y}$输出.图 11 (f)是5时刻:变迁$q_{12}$第3次发生, 表示第6条指令取指; 变迁$q_{21}$第3次发生, 表示第5条指令分析; 变迁$q_{31}$第2次发生, 表示第3条指令执行; 第2条指令的执行结果从$\tilde{y}$输出.
 图 11 不同时刻并联系统的状态描述Fig. 11 State descriptions of the parallel system at various moments
图 11 不同时刻并联系统的状态描述Fig. 11 State descriptions of the parallel system at various moments由图 11和式(7)可知
$ {\pmb x}(1)=\begin{pmatrix} e\\ \lambda\\ \lambda\\ \lambda^{2}\\ \lambda^{3}\\ \lambda^{4} \end{pmatrix}, \ \ {\pmb x}(2)=\begin{pmatrix} \lambda^{2}\\ \lambda^{3}\\ \lambda^{3}\\ \lambda^{4}\\ \lambda^{5}\\ \lambda^{6} \end{pmatrix}, \ \ \cdots $
由动态方程(6)可知
$ {\pmb y}(1)=\begin{pmatrix} \lambda^{4}\\ \lambda^{5} \end{pmatrix}, \ \ {\pmb y}(2)=\begin{pmatrix} \lambda^{6}\\ \lambda^{7} \end{pmatrix}, \ \ \cdots $
设$y(k)$表示第$k$条指令输出的时刻, 则
$ \begin{align*} \begin{cases} {y}(2k)=\overline{y}(k)\\ {y}(2k+1)=\widetilde{y}(k), \quad k=0, 1, \cdots \end{cases} \end{align*} $
在同步时钟的控制下, 上下两条并联通道中的变迁轮番发射, 两个输出端口$\overline{y}$和$\widetilde{y}$每隔时间$\lambda$轮流输出一个结果.处理$m$条指令的任务完成时间为
$ \begin{align}\label{e09} T(m)=\lambda^{m+3} \end{align} $
(8) 以上讨论了两个处理通道的情况.并联通道的数目可以延伸至多个.下面考虑如图 12所示的三套瓶颈段并联的情形.图 13给出了三套瓶颈段并联时, 指令并行处理的Petri网模型, 其中变迁$q_{11}$, $q_{12}$, $q_{13}$分别表示第1次、第2次和第3次取指令; 变迁$q_{21}$, $q_{22}$, $q_{23}$分别表示第1个、第2个和第3个并联通道分析指令; 变迁$q_{31}$, $q_{32}$, $q_{33}$分别表示第1次、第2次和第3次执行指令; 变迁$y_{1}$, $y_{2}$, $y_{3}$分别表示第1个、第2个和第3个结果输出.系统不断重复上述步骤, 直到遇到停机指令或外来的干预为止.类似地, 可以得到系统有$n$套瓶颈段并联时, 指令并行处理的Petri网模型.
 图 13 三套瓶颈段并联的Petri网模型Fig. 13 Petri net of parallel connection with three bottleneck sub-processes
图 13 三套瓶颈段并联的Petri网模型Fig. 13 Petri net of parallel connection with three bottleneck sub-processes当系统有$n$条并联通道并行处理指令(即$n$个处理器轮流分析指令)时, 系统的时钟周期为
$ \begin{align}\label{e06} \lambda=\max\Big\{t_{1}, \ \frac{t_{2}}{n}, \ t_{3}\Big\}+\tau \end{align} $
(9) 显然, 当$t_{2}/{n} < \max\{t_{1}, \ t_{3}\}$时, 继续增加并联通道的数目$n$不仅不会使系统的时钟周期$\lambda$缩短, 反而还会增加设备成本.因此, 在实际应用中, 应该合理设置并联通道的数目.下面看一个例子.
例2. 设取指、分析和执行的时间单位分别为$t_{1}$ $=$ $2$, $t_{2}=9$, $t_{3}=4, $锁存器的传输延迟为$\tau=1$个时间单位.显然, 分析子过程所需要的时间最长, 它是指令级并行处理的瓶颈段.
1) 当系统串行处理指令时, 其时钟周期为$\lambda=$ $2$ $+$ $9+4=15$个时间单位.
2) 当系统只有单通道并行处理指令时, 由式(3)可知, 它的时钟周期为$\lambda=\max\{2, \ 9, \ 4\}=9$个时间单位.
3) 当系统有2条并联通道并行处理指令时, 由式(9)可知, 它的时钟周期为$\lambda=\max\{2, \ {9}/{2}, \ 4\}+$ $1$ $=5.5$个时间单位.
4) 当系统有3条并联通道并行处理指令时, 其时钟周期为$\lambda=\max\{2, \ {9}/{3}, \ 4\}+1=5$个时间单位; 当系统有4条并联通道并行处理指令时, 其时钟周期为个时间单位.
类似地, 继续增加并联通道的数目, 系统的时钟周期恒为5个时间单位.考虑到设备成本以及控制系统的复杂性, 采用3套处理器并联分析指令较为适宜.此时, 由式(8)可知, 处理50条指令的任务完成时间为$T(50)=\lambda^{53}= 5\times 53=265$个时间单位.
下面给出并联控制在协同云控制系统[2]控制任务并行处理中的一个应用.
例3. 图 14是协同云控制系统的框架图, 其中, $C_{1}$ $\sim$ $C_{8}$是具有相同时间步长的云控制器, CT是任务管理服务器.在协同云控制系统中, 控制任务将由多个云控制器以合作的形式来完成.在任务的初始阶段, CT根据任务的规模选择若干合适的云控制器协同工作.然后利用分布式算法, 对总体任务进行分割, 并将不同的任务分配给相应的云控制器.云控制器向CT发送反馈信号, CT根据任务分配算法计算出最终的控制信号, 并将其发送到执行器.执行器接收控制信号, 并对被控对象施加控制.
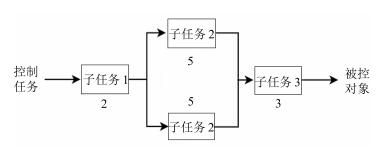
设CT把某控制任务分割成子任务1、子任务2和子任务3三个部分并行处理, 并把子任务1分配给云控制器$C_{1}$处理, 子任务2分配给云控制器$C_{2}$和$C_{3}$并联处理, 子任务3分配给云控制器$C_{4}$处理, 则CT生成控制信号的过程可由如图 15所示的并联模型来描述.
设三个子任务所需要的时间单位分别为$t_{1}=2$, $t_{2}$ $=$ $5$, $t_{3}=3$, 控制信号在控制器之间的传输延迟为$\tau=1$个时间单位.由式(9)可知, 协同云控制系统对被控对象施加控制的时钟周期为$\lambda=\max\{2$, $\frac{5}{2}$, $3\}+1=4$个时间单位.由式(8)可知, 执行50项控制任务的完成时间为$T(50)=\lambda^{53}=212$个时间单位.也就是说, 执行器每4个时间单位接收一次控制信号, 完成50次控制操作需要212个时间单位.
5. 结论
对于云控制系统的并行任务分配优化算法及并联控制, 本文建立了并行处理系统的Petri网模型, 分析了并行处理过程中发生的指令相关现象.为了衡量系统的并行处理能力, 本文引入了时钟周期、吞吐率和任务完成时间性能指标, 并通过两种方式提高系统性能.一种是对子过程进行合理分割, 通过求解一类最优控制问题, 设计并行任务分配优化方案, 以保证任务完成时间最短, 并给出计算最短任务完成时间的有效算法.另一种是重复设置多套瓶颈段并联, 利用Petri实现了瓶颈子过程的并联控制, 并给出并联控制在协同云控制系统控制任务并行处理中的一个应用.并行处理系统的子过程数目越多, 同时进入系统的指令数目就越多, 发生指令相关的机会也就越多.如果处理不当, 将会导致并行处理能力显著下降.在发生指令相关的情况下, 如何合理分配处理任务以保持系统较强的并行处理性能, 是我们将要进一步研究的问题.此外, 相对于瓶颈子过程再细分的优化方法, 并联控制方法较为复杂.合理设置并联通道的数目, 制定最优的并联控制策略, 在低设备成本的前提下, 使任务完成时间达到最短, 也是我们将要进一步研究的问题.
-
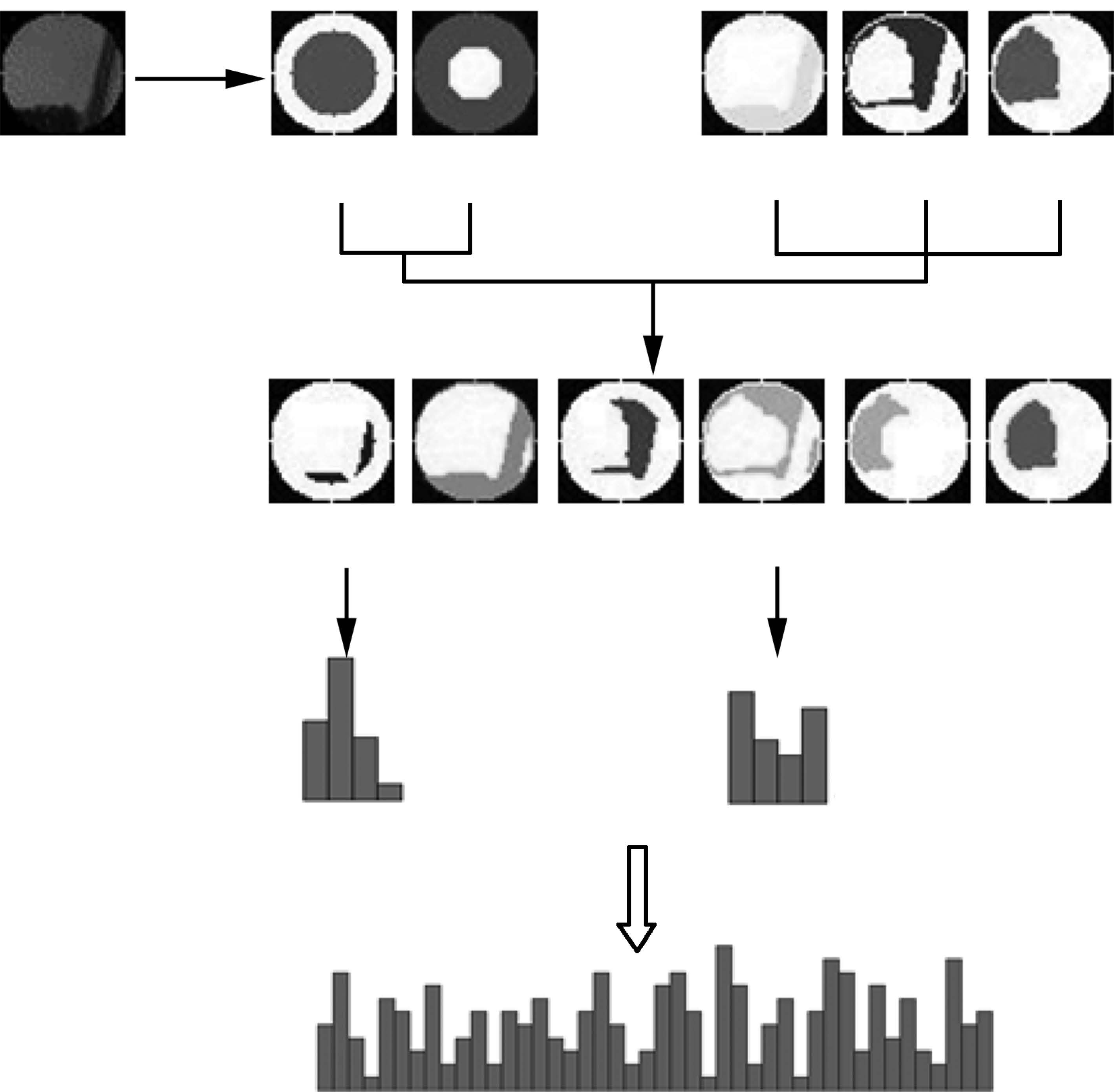
图 3 通过联合空间分割汇聚支撑域中局部特征的流程
Fig. 3 The procedure of pooling local features in a support region by the combination of space divisions

图 4 四个支撑区域选择及其归一化
Fig. 4 The selection of four support regions and their normalization

图 6 不同参数下FCSCD 描述符的匹配性能
Fig. 6 Matching performances of FCSCD under di®erent parameter settings

图 7 各种联合情况下FCSCD 描述符的匹配性能对比
Fig. 7 Matching performance comparisons of FCSCD under di®erent combination situations

图 8 多支撑域条件下FCSCD 描述符的匹配性能对比
Fig. 8 Matching performance comparisons of FCSCD under multiple support regions
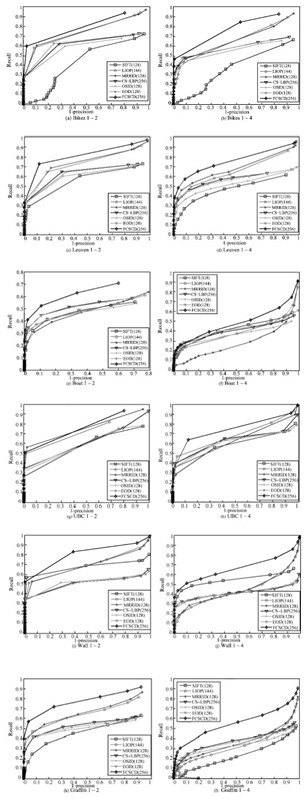
图 9 FCSCD 描述符和其他主流描述符的匹配性能对比
Fig. 9 Matching performance comparisons of FCSCD and other popular descriptors

图 10 FCSCD 描述符和其他主流描述符的图像匹配图
Fig. 10 Image matching results of FCSCD and other popular descriptors
表 1 FCSCD 描述符的参数设置
Table 1 The setting of parameters for FCSCD descriptor
参数 设置值 k 3, 4, 5 d 2, 3  下载: 导出CSV
下载: 导出CSV
表 2 描述符运行时间对比
Table 2 Comparison of run-time of descriptors
SIFT CS-LBP OSID LIOP MRRID MRRID(4) EOD FCSCD 耗时(ms) 2.4 1.6 2.1 3.1 2.6 10.4 3.3 2.7
下载: 导出CSV
-
[1] Dong Z L, Zhang G F, Jia J Y, Bao H J. Efficient keyframe-based real-time camera tracking. Computer Vision and Image Understanding, 2014, 118: 97-110 doi: 10.1016/j.cviu.2013.08.005 [2] Cummins M, Newman P. Appearance-only SLAM at large scale with FAB-MAP 2.0. The International Journal of Robotics Research, 2011, 30(9): 1100-1123 doi: 10.1177/0278364910385483 [3] 桂振文, 吴侹, 彭欣. 一种融合多传感器信息的移动图像识别方法. 自动化学报, 2015, 41(8): 1394-1404 http://www.aas.net.cn/CN/abstract/abstract18714.shtmlGui Zhen-Wen, Wu Ting, Peng Xin. A novel recognition approach for mobile image fusing inertial sensors. Acta Automatica Sinica, 2015, 41(8): 1394-1404 http://www.aas.net.cn/CN/abstract/abstract18714.shtml [4] Zhou W G, Li H Q, Hong R C, Lu Y J, Tian Q. BSIFT: toward data-independent codebook for large scale image search. IEEE Transactions on Image Processing, 2015, 24(3): 967-979 doi: 10.1109/TIP.2015.2389624 [5] 刘培娜, 刘国军, 郭茂祖, 刘扬, 李盼. 非负局部约束线性编码图像分类算法. 自动化学报, 2015, 41(7): 1235-1243 http://www.aas.net.cn/CN/abstract/abstract18697.shtmlLiu Pei-Na, Liu Guo-Jun, Guo Mao-Zu, Liu Yang, Li Pan. Image classification based on non-negative locality-constrained linear coding. Acta Automatica Sinica, 2015, 41(7): 1235-1243 http://www.aas.net.cn/CN/abstract/abstract18697.shtml [6] 祝继华, 周颐, 王晓春, 邗汶锌, 马亮. 基于图像配准的栅格地图拼接方法. 自动化学报, 2015, 41(2): 285-294 http://www.aas.net.cn/CN/abstract/abstract18607.shtmlZhu Ji-Hua, Zhou Yi, Wang Xiao-Chun, Han Wen-Xin, Ma Liang. Grid map merging approach based on image registration. Acta Automatica Sinica, 2015, 41(2): 285-294 http://www.aas.net.cn/CN/abstract/abstract18607.shtml [7] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91-110 doi: 10.1023/B:VISI.0000029664.99615.94 [8] Ke Y, Sukthankar R. PCA-SIFT: a more distinctive representation for local image descriptors. In: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, USA: IEEE, 2004. II-506-II-513 [9] 颜雪军, 赵春霞, 袁夏. 2DPCA-SIFT: 一种有效的局部特征描述方法. 自动化学报, 2014, 40(4): 675-682 http://www.aas.net.cn/CN/abstract/abstract18333.shtmlYan Xue-Jun, Zhao Chun-Xia, Yuan Xia. 2DPCA-SIFT: an efficient local feature descriptor. Acta Automatica Sinica, 2014, 40(4): 675-682 http://www.aas.net.cn/CN/abstract/abstract18333.shtml [10] Mikolajczyk K, Schmid C. A performance evaluation of local descriptors. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(10): 1615-1630 doi: 10.1109/TPAMI.2005.188 [11] Bay H, Ess A, Tuytelaars T, van Gool L. Speeded-up robust features (SURF). Computer Vision and Image Understanding, 2008, 110(3): 346-359 doi: 10.1016/j.cviu.2007.09.014 [12] Tola E, Lepetit V, Fua P. DAISY: an efficient dense descriptor applied to wide-baseline stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(5): 815-830 doi: 10.1109/TPAMI.2009.77 [13] Brown M, Gang H, Winder S. Discriminative learning of local image descriptors. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(1): 43-57 doi: 10.1109/TPAMI.2010.54 [14] Simonyan K, Vedaldi A, Zisserman A. Learning local feature descriptors using convex optimisation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(8): 1573-1585 doi: 10.1109/TPAMI.2014.2301163 [15] Heikkilä M, Pietikäinen M, Schmid C. Description of interest regions with local binary patterns. Pattern Recognition, 2009, 42(3): 425-436 doi: 10.1016/j.patcog.2008.08.014 [16] Tang F, Lim S H, Change N L, Tao H. A novel feature descriptor invariant to complex brightness changes. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL: IEEE, 2009. 2631-2638 [17] Chen J, Shan S G, He C, Zhao G Y, Pietikainen M, Chen X L, Gao W. WLD: a robust local image descriptor. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1705-1720 doi: 10.1109/TPAMI.2009.155 [18] Kim B, Yoo H, Sohn K. Exact order based feature descriptor for illumination robust image matching. Pattern Recognition, 2013, 46(12): 3268-3278 doi: 10.1016/j.patcog.2013.04.015 [19] Lazebnik S, Schmid C, Ponce J. A sparse texture representation using local affine regions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1265-1278 doi: 10.1109/TPAMI.2005.151 [20] Fan B, Wu F C, Hu Z Y. Rotationally invariant descriptors using intensity order pooling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(10): 2031-2045 doi: 10.1109/TPAMI.2011.277 [21] Wang Z H, Fan B, Wu F C. Local intensity order pattern for feature description. In: Proceedings of the 2011 IEEE Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 603-610 [22] Mikolajczyk K, Tuytelaars T, Schmid C, Zisserman A, Matas J, Schaffalitzky F, Kadir T, van Gool L. A comparison of affine region detectors. International Journal of Computer Vision, 2005, 65(1-2): 43-72 doi: 10.1007/s11263-005-3848-x 期刊类型引用(11)
1. 周勇樟,王艳,纪志成. 扰动下离散再制造系统瓶颈漂移波动性分析. 系统仿真学报. 2023(04): 809-821 .  百度学术
百度学术2. 鲁法明,黄莹,曾庆田,包云霞,唐梦凡. 基于Petri网展开的多线程程序数据竞争检测与重演. 软件学报. 2023(08): 3726-3744 . 百度学术3. WANG Jin,YANG Hongjiu,XIA Yuanqing,YAN Ce. Stochastic stabilization of Markovian jump cloud control systems based on max-plus algebra. Journal of Systems Engineering and Electronics. 2022(04): 827-834 . 必应学术4. 关守平,王梁. 云控制系统不确定性分析与控制器设计方法. 自动化学报. 2022(11): 2677-2687 . 本站查看5. 吕书玉,马中,戴新发,高毅,胡哲琨. 云控制系统研究现状综述. 计算机应用研究. 2021(05): 1287-1293 . 百度学术6. 赵瑞锋,李波,王海柱,郭文鑫,卢建刚,曾坚永. 基于云计算的电力系统快速静态安全分析方法. 计算机应用与软件. 2021(06): 278-283+317 . 百度学术7. 姜斌,梁敏,霍贝. 基于“作战云”的“云作战”问题探析. 火力与指挥控制. 2020(07): 1-5 . 百度学术8. 谭浩然,黄志武,吴敏. 基于云控制系统的监控系统设计与实现. 控制与决策. 2019(08): 1688-1694 . 百度学术9. 袁源,杨洪玖,夏元清,袁欢欢. 基于因果逻辑关系的CPS建模研究. 信息与控制. 2018(01): 119-128 . 百度学术10. 王艳,程丽军. 基于事件驱动的云端动态任务分解模式优化方法. 系统仿真学报. 2018(11): 4029-4042 . 百度学术11. 程丽军,王艳. 面向云端融合的任务-资源双边匹配决策模型. 系统仿真学报. 2018(11): 4348-4358 . 百度学术其他类型引用(8)
-

 下载:
下载:








计量
- 文章访问数: 1879
- HTML全文浏览量: 294
- PDF下载量: 1169
- 被引次数: 19
