

-
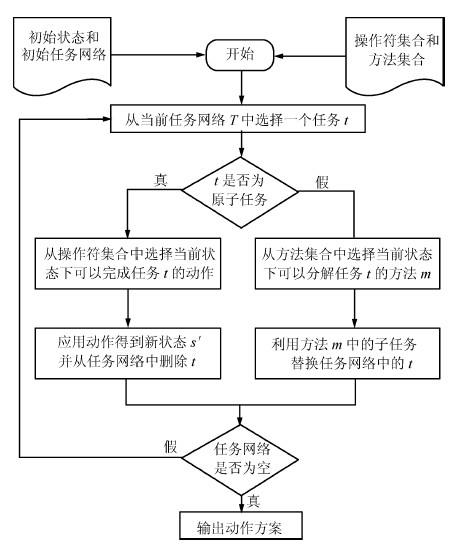
摘要: 层次任务网络(Hierarchical task network, HTN)规划作为一项重要的智能规划技术被广泛应用于实际规划问题中, 传统的HTN规划无法处理不确定规划问题.然而, 现实世界不可避免地存在无法确定或无法预测的信息, 这使许多学者开始关注不确定规划问题, 不确定HTN规划研究也成为HTN规划研究的前沿.本文从HTN规划过程出发分析了不确定HTN规划问题中涉及的三类不确定, 即状态不确定、动作效果不确定和任务分解不确定; 总结了系统状态、动作效果和任务分解等不确定需要扩展确定性HTN规划模型的工作, 以此对现有不确定HTN规划的研究工作加以梳理和归类; 最后,对不确定HTN规划研究中仍需要解决的问题和未来的研究方向作了进一步展望.Abstract: As an important automated planning technique, hierarchical task network (HTN) planning has been widely used in practical planning problems, but traditional HTN planning cannot deal with a planning problem with uncertainty. However, there inevitably exist uncertain or unpredictable information in the real world. As a result, many scholars began to focus on planning under uncertainty, and HTN planning under uncertainty has become the forefront research of HTN planning. In this paper, uncertainties of state, action effects and task decomposition are analysed, followed by a summary of the expansion of HTN planning model for treating these three types of uncertainties. Also, existing research works about HTN planning under uncertainty are reviewed and categorized, based on which some unsolved problems in HTN planning with uncertainty and future research directions are brought forward.
-
表 1 不确定规划问题分类及代表性规划器
Table 1 quad Classification of planning problem with uncertaintyand representative planner
 下载: 导出CSV
下载: 导出CSV
表 2 现有的不确定HTN规划研究
Table 2 Existing research on HTN planning under uncertainty
不确定HTN规划研究 不确定规划问题 不确定表示方式 扩展 ND-SHOP2、YoYo P1 逻辑表示 扩展1、2、3 Cond-SHOP2 P2 逻辑表示 扩展4、5(2)、6、7 RTDPSHOP2、LRTDPSHOP2、Fwd-VISHOP2 P1 概率表示 扩展10、2、30(1) Hierarchical Factored POMDPs P3 概率表示 扩展10、40、5(1)、60 C-SHOP、PC-SHOP P3 概率表示 扩展10、40、5(1)、60、70(2) Probabilistic-HTN P1+ 任务分解不确定 概率表示 扩展10、8、9
下载: 导出CSV
-
[1] Ghallab M, Nau D, Traverso P [著], 姜云飞, 杨强, 凌应标, 伍丽华, 陈蔼祥, 张学农, 黄巍[译]. 自动规划: 理论与实践. 北京: 清华大学出版社, 2008. [2] Sacerdoti E D. The nonlinear nature of plans. In: Proceedings of the 4th International Joint Conference on Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann, 1975. 206-214 [3] Yang Q. Formalizing planning knowledge for hierarchical planning. Computational Intelligence, 1990, 6(1): 12-24 [4] Kambhampati S, Hendler J A. A validation-structure-based theory of plan modification and reuse. Artificial Intelligence, 1992, 55(2-3): 193-258 [5] Erol K, Hendler J, Nau D S. UMCP: a sound and complete procedure for hierarchical task-network planning. In: Proceedings of the 2nd International Conference on Artificial Intelligence Planning Systems. Palo Alto, California: AAAI Press, 1994. 249-254 [6] Erol K, Nau D S, Subrahmanian V S. Complexity, decidability and undecidability results for domain-independent planning. Artificial Intelligence, 1995, 76(1-2): 75-88 [7] Tate A. Generating project networks. In: Proceedings of the 5th International Joint Conference on Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann, 1977. 888-893 [8] Wilkins D E. Domain-independent planning representation and plan generation. Artificial Intelligence, 1984, 22(3): 269-301 [9] Wilkins D E. Can AI planners solve practical problems? Computational Intelligence, 1990, 6(4): 232-246 [10] Currie K, Tate A. O-Plan: the open planning architecture. Artificial Intelligence, 1991, 52(1): 49-86 [11] Tate A, Drabble B, Kirby R. O-Plan2: an open architecture for command, planning and control. Intelligent Scheduling. San Francisco, CA, USA: Morgan Kaufmann, 1994. 213-239 [12] Nau D, Cao Y, Lotem A, Munoz-Avila H. SHOP: simple hierarchical ordered planner. In: Proceedings of the 16th International Joint Conference on Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann, 1999. 968-973 [13] Nau D, Au T C, Ilghami O, Kuter U, Murdock J W, Wu D, Yaman F. SHOP2: an HTN planning system. Journal of Artificial Intelligence Research, 2003, 20: 379-404 [14] de la Asunción M, Castillo L, Fdez-Olivares J, García-Pérez O, González A, Palao F. SIADEX: an interactive knowledge-based planner for decision support in forest fire fighting. AI Communications, 2005, 18(4): 257-268 [15] Georgievski I, Aiello M. HTN planning: overview, comparison, and beyond. Artificial Intelligence, 2015, 222: 124-156 [16] Wilkins D E, desJardins M. A call for knowledge-based planning. AI Magazine, 2001, 22(1): 99-115 [17] Nau D, Au T C, Ilghami O, Kuter U, Wu D, Yaman F, Munoz-Avila H, Murdock J W. Applications of SHOP and SHOP2. IEEE Intelligent Systems, 2005, 20(2): 34-41 [18] Wilkins D E. Practical Planning: Extending the Classical AI Planning Paradigm. San Francisco, CA, USA: Morgan Kaufmann, 1988. [19] Biundo S, Schattenberg B. From abstract crisis to concrete relief a preliminary report on combining state abstraction and HTN planning. In: Proceedings of the 6th European Conference on Planning. Palo Alto, California: AAAI Press, 2001. 157-168 [20] Arentoft M M, Fuchs J J, Parrod Y, Gasquet A, Stader J, Stokes I, Vadon H. OPTIMUM-AIV: a planning and scheduling system for spacecraft AIV. Future Generation Computer Systems, 1992, 7(4): 403-412 [21] Estlin T A, Chien S A, Wang X M. An argument for a hybrid HTN/operator-based approach to planning. In: Proceedings of the 4th European Conference on Planning: Recent Advances in AI Planning. Heidelberg, Berlin: Springer, 1997. 182-194 [22] Agosta J M. Formulation and implementation of an equipment configuration problem with the SIPE-2 generative planner. In: Proceedings of AAAI-95 Spring Symposium on Integrated Planning Applications. Menlo Park, California: AAAI Press, 1995. 1-10 [23] Smith S J J, Hebbar K, Nau D S, Minis I. Integrating electrical and mechanical design and process planning. In: Proceedings of the IFIP TC5 WG5. 2 International Conference on Knowledge Intensive CAD. US: Springer, 1997. 269-288 [24] Muñoz-Avila H, Aha D W, Nau D S, Weber R, Breslow L, Yamal F. SiN: integrating case-based reasoning with task decomposition. In: Proceedings of the 17th International Joint Conference on Artificial Intelligence-Volume 2. San Francisco, CA, USA: Morgan Kaufmann, 2001. 999-1004 [25] Smith S J, Nau D, Throop T. Computer Bridge: a big win for AI planning. AI Magazine, 1998, 19(2): 93-106 [26] Morisset B, Ghallab M. Learning how to combine sensory-motor modalities for a robust behavior. Advances in Plan-Based Control of Robotic Agents. Heidelberg, Berlin: Springer, 2002. 157-178 [27] Morisset B, Ghallab M. Synthesis of supervision policies for robust sensory-motor behaviors. In: Proceedings of the 7th International Conference on Intelligent Autonomous Systems. Amsterdam: IOS Press, 2002. 236-243 [28] Sirin E, Parsia B, Wu D, Hendler J, Nau D. HTN planning for web service composition using SHOP2. Web Semantics: Science, Services and Agents on the World Wide Web, 2004, 1(4): 377-396 [29] González-Ferrer A, Ten Teije A, Fdez-Olivares J, Milian K. Automated generation of patient-tailored electronic care pathways by translating computer-interpretable guidelines into hierarchical task networks. Artificial Intelligence in Medicine, 2013, 57(2): 91-109 [30] 王红卫, 祁超. 基于层次任务网络规划的应急响应决策理论与方法. 北京: 科学出版社, 2015.Wang Hong-Wei, Qi Chao. Hierarchical Task Network Planning based Emergency Response Decision Making Theory and Method. Beijing: Science Press, 2015. [31] Russell S, Norvig P [著], 姜哲, 金奕江, 张敏, 杨磊等[译]. 人工智能: 一种现代的方法 (第二版). 北京: 人民邮电出版社, 2010. [32] Geier T, Bercher P. On the decidability of HTN planning with task insertion. In: Proceedings of the 22nd International Joint Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2011. 1955-1961 [33] Alford R, Shivashankar V, Kuter U, Nau D. HTN problem spaces: structure, algorithms, termination. In: Proceedings of the 5th Annual Symposium on Combinatorial Search. Palo Alto, California: AAAI Press, 2012. 2-9 [34] Ramírez M, Sardina S. Directed fixed-point regression-based planning for non-deterministic domains. In: Proceedings of the 24th International Conference on Automated Planning and Scheduling. Palo Alto, California: AAAI Press, 2014. 235-243 [35] Alford R, Kuter U, Nau D, Goldman R P. Plan aggregation for strong cyclic planning in nondeterministic domains. Artificial Intelligence, 2014, 216: 206-232 [36] Keller T, Eyerich P. PROST: probabilistic planning based on UCT. In: Proceedings of the 22nd International Conference on Automated Planning and Scheduling. Palo Alto, California: AAAI Press, 2012. 119-127 [37] Muise C, Belle V, McIlraith S A. Computing contingent plans via fully observable non-deterministic planning. In: Proceedings of the 28th AAAI Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2014. 2322-2329 [38] Maliah S, Brafman R, Karpas E, Shani G. Partially observable online contingent planning using landmark heuristics. In: Proceedings of the 24th International Conference on Automated Planning and Scheduling. Palo Alto, California: AAAI Press, 2014. 163-171 [39] Zhang S Q, Stone P. CORPP: commonsense reasoning and probabilistic planning, as applied to dialog with a mobile robot. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, Texas, USA: AAAI Press, 2015. 1394-1400 [40] Taig R, Brafman R I. A relevance-based compilation method for conformant probabilistic planning. In: Proceedings of the 28th AAAI Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2014. 2374-2380 [41] Nguyen K, Tran V, Son T C, Pontelli E. On computing conformant plans using classical planners: a generate-and-complete approach. In: Proceedings of the 22nd International Conference on Automated Planning and Scheduling. Palo Alto, California: AAAI Press, 2012. 190-198 [42] Bresina J, Dearden R, Meuleau N, Ramakrishnan S, Smith D, Washington R. Planning under continuous time and resource uncertainty: a challenge for AI. In: Proceedings of the 8th Conference on Uncertainty in Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann, 2002. 77-84 [43] Celorrio S J. Planning and Learning under Uncertainty [Ph.D. dissertation], Universidad Carlos III de Madrid, Spain, 2011 [44] Cimatti A, Pistore M, Roveri M, Traverso P. Weak, strong, and strong cyclic planning via symbolic model checking. Artificial Intelligence, 2003, 147(1-2): 35-84 [45] McAllester D, Rosenblitt D. Systematic nonlinear planning. In: Proceedings of the 9th National conference on Artificial intelligence-Volume 2. Palo Alto, California: AAAI Press, 1991. 634-639 [46] Kambhampati S, Mali A, Srivastava B. Hybrid planning for partially hierarchical domains. In: Proceedings of the 15th National Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 1998. 882-888 [47] Kuter U. Learning and planning (intelligent systems). Encyclopedia of Complexity and Systems Science. New York: Springer, 2009. 5188-5206 [48] Garland A, Ryall K, Rich C. Learning hierarchical task models by defining and refining examples. In: Proceedings of the 1st International Conference on Knowledge Capture. New York: ACM, 2001. 44-51 [49] Ilghami O, Muñoz-Avila H, Nau D S, Aha D W. Learning approximate preconditions for methods in hierarchical plans. In: Proceedings of the 22nd International Conference on Machine Learning. New York: ACM, 2005. 337-344 [50] Xu K, Muñoz-Avila H. A domain-independent system for case-based task decomposition without domain theories. In: Proceedings of the 20th National Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2005. 234-239 [51] Nejati N, Langley P, Konik T. Learning hierarchical task networks by observation. In: Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006. 665-672 [52] Reddy C, Tadepalli P. Learning goal-decomposition rules using exercises. In: Proceedings of the 14th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 1997. 278-286 [53] Zhuo H H, Muñoz-Avila H, Yang Q. Learning hierarchical task network domains from partially observed plan traces. Artificial Intelligence, 2014, 212: 134-157 [54] Hogg C, Muñoz-Avila H, Kuter U. HTN-MAKER: learning HTNs with minimal additional knowledge engineering required. In: Proceedings of the 23th National Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2008. 950-956 [55] Kuter U, Nau D. Forward-chaining planning in nondeterministic domains. In: Proceedings of the 19th National Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2004. 513-518 [56] Kuter U. Planning under Uncertainty: Moving Forward [Ph.D. dissertation]. Maryland University College Park, USA, 2006 [57] Kvarnström J, Doherty P. TALplanner: a temporal logic based forward chaining planner. Annals of Mathematics and Artificial Intelligence, 2000, 30(1-4): 119-169 [58] Bacchus F, Kabanza F. Using temporal logics to express search control knowledge for planning. Artificial Intelligence, 2000, 116(1-2): 123-191 [59] Bertoli P, Cimatti A, Pistore M, Roveri M, Traverso P. MBP: a model based planner. In: Proceedings of the IJCAI-2001 Workshop on Planning under Uncertainty and Incomplete Information. San Francisco, USA: Morgan Kaufmann, 2001. 473-478 [60] Kuter U, Nau D, Pistore M, Traverso P. Task decomposition on abstract states, for planning under nondeterminism. Artificial Intelligence, 2009, 173(5-6): 669-695 [61] Bryant R E. Symbolic boolean manipulation with ordered binary-decision diagrams. ACM Computing Surveys, 1992, 24(3): 293-318 [62] Kuter U, Nau D, Reisner E, Goldman R. Conditionalization: adapting forward-chaining planners to partially observable environments. In: ICAPS-2007 Workshop on Planning and Execution for Real-World Systems. Providence, Rhode Island, USA, 2007. [63] Petrick R P A, Bacchus F. A knowledge-based approach to planning with incomplete information and sensing. In: Proceedings of the 6th International Conference on AI Planning and Scheduling. Palo Alto, California: AAAI Press, 2002. 212-222 [64] Petrick R P A, Bacchus F. Extending the knowledge-based approach to planning with incomplete information and sensing. In: Proceedings of the 9th International Conference on Knowledge Representation and Reasoning. Palo Alto, California: AAAI Press, 2004. 613-622 [65] Bertoli P, Cimatti A, Roveri M, Traverso P. Strong planning under partial observability. Artificial Intelligence, 2006, 170(4-5): 337-384 [66] Kuter U, Nau D. Using domain-configurable search control for probabilistic planning. In: Proceedings of 20th National Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2005. 1169-1174 [67] Bonet B, Geffner H. Planning with incomplete information as heuristic search in belief space. In: Proceedings of the 5th International Conference on AI Planning and Scheduling. Palo Alto, California: AAAI Press, 2000. 52-61 [68] Bonet B, Geffner H. Labeled RTDP: improving the convergence of real-time dynamic programming. In: Proceedings of the 13th International Conference on Automated Planning and Scheduling. Trento, Italy: AAAI Press, 2003. 12-21 [69] Bertsekas D P. Dynamic Programming and Optimal Control. Belmont, Massachusetts: Athena Scientific, 1995. [70] Müller F, Späth C, Geier T, Biundo S. Exploiting expert knowledge in factored POMDPs. In: Proceedings of the 20th European Conference on Artificial Intelligence. Amsterdam: IOS Press, 2012. 606-611 [71] Müller F, Biundo S. HTN-style planning in relational POMDPs using first-order FSCs. KI 2011: Advances in Artificial Intelligence. Heidelberg, Berlin: Springer, 2011. 216-227 [72] Hansen E A. Solving POMDPs by searching in policy space. In: Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann, 1998. 211-219 [73] Nilsson N J. Principles of Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann, 2014. [74] Kocsis L, Szepesvári C. Bandit based Monte-Carlo planning. In: Proceedings of 17th European Conference on Machine Learning. Heidelberg, Berlin: Springer, 2006. 282-293 [75] Bouguerra A, Karlsson L. Hierarchical task planning under uncertainty. In: Proceedings of the 3rd Italian Workshop on Planning and Scheduling. Perugia, Italy, 2004. [76] Bouguerra A, Karlsson L. PC-SHOP: a probabilistic-conditional hierarchical task planner. Intelligenza Artificiale, 2005, 2(4): 44-50 [77] Tang Y Q, Meneguzzi F, Sycara K, Parsons S. Planning over MDPs through probabilistic HTNs. In: AAAI-2011 Workshop on Generalized Planning. San Francisco, CA, USA: AAAI, 2011. [78] Stolcke A. An efficient probabilistic context-free parsing algorithm that computes prefix probabilities. Computational Linguistics, 1995, 21(2): 165-201 [79] Barrett A, Weld D S. Task-decomposition via plan parsing. In: Proceedings of the 12th National Conference on Artificial Intelligence. San Francisco, CA, USA: AAAI Press, 1994. 1117-1122 [80] Earley J. An efficient context-free parsing algorithm. Communications of the ACM, 1970, 13(2): 94-102 [81] Zhao J, Sun J, Yin M. Recent advances in conformant planning. In: Proceedings of the 2007 IEEE International Conference on Robotics and Biomimetics (ROBIO). Sanya: IEEE, 2007. 2001-2006 [82] Kuter U, Sirin E, Parsia B, Nau D, Hendler J. Information gathering during planning for web service composition. Web Semantics: Science, Services and Agents on the World Wide Web, 2005, 3(2-3): 183-205 [83] da Silva F A G, Ciarlini A E M, Siqueira S W M. A planning algorithm for incorporating attempts and nondeterminism into interactive stories. In: Proceedings of the 23rd IEEE International Conference on Tools with Artificial Intelligence. Boca Raton, FL: IEEE, 2011. 96-101 [84] Biundo S, Holzer R, Schattenberg B. Project planning under temporal uncertainty. In: Proceedings of Planning, Scheduling and Constraint Satisfaction from Theory to Practice. Amsterdam: IOS Press, 2005. 189-198 [85] Yaman F, Nau D S. Timeline: an HTN planner that can reason about time. In: Proceedings of AIPS-02 Workshop on Planning for Temporal Domains. San Francisco, CA, USA: AAAI Press, 2002. 75-81 [86] Castillo L A, Fdez-Olivares J, García-Pérez O, Palao F. Efficiently handling temporal knowledge in an HTN planner. In: Proceedings of 16th International Conference on Automated Planning and Scheduling. San Francisco, CA, USA: AAAI Press, 2006. 63-72 [87] Tang P, Wang H W, Qi C, Wang J. Anytime heuristic search in temporal HTN planning for developing incident action plans. AI Communications, 2012, 25(4): 321-342 [88] Wang Z, Wang H W, Qi C, Wang J. A resource enhanced HTN planning approach for emergency decision-making. Applied Intelligence, 2013, 38(2): 226-238 [89] Beaudry È, Kabanza F, Michaud F. Planning with concurrency under resources and time uncertainty. In: Proceedings of the 19th European Conference on Artificial Intelligence. Amsterdam, The Netherlands: IOS Press, 2010. 217-222 [90] Yoon S W, Fern A, Givan R. FF-Replan: a baseline for probabilistic planning. In: Proceedings of the 17th International Conference on Automated Planning and Scheduling. San Francisco, CA, USA: AAAI Press, 2007. 352-359 [91] Palacios H, Albore A, Geffner H. Compiling contingent planning into classical planning: new translations and results. In: Proceedings of ICAPS-2014 Workshop on Models and Paradigms for Planning under Uncertainty: a Broad Perspective. San Francisco, CA, USA: AAAI Press, 2014. 27-34 [92] Shani G, Brafman R I. Replanning in domains with partial information and sensing actions. In: Proceedings of the 22nd International Joint Conference on Artificial Intelligence. San Francisco, CA, USA: AAAI Press, 2011. 2021-2026 [93] Hogg C, Kuter U, Muñoz-Avila H. Learning hierarchical task networks for nondeterministic planning domains. In: Proceedings of the 21st International Joint Conference on Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann, 2009. 1708-1714 -

 下载:
下载:

图(1) / 表(2)
计量
- 文章访问数: 3236
- HTML全文浏览量: 503
- PDF下载量: 1317
- 被引次数: 0
