

A Semi-supervised Affinity Propagation Clustering Method with Homogeneity Constraint
-
摘要: 以近邻反射传播 (Affinity propagation, AP) 聚类算法为基础, 提出了一种基于同类约束的半监督近邻反射传播聚类方法 (Semi-supervised affinity propagation clustering method with homogeneity constraints, HCSAP).该方法在聚类目标函数中引入同类约束项, 以保证聚类结果与同类集先验信息一致.利用最大和信任传播 (Max-sum belief propagation) 优化过程对目标函数进行求解, 导出同类约束下的吸引度 (Responsibility) 和归属度 (Availability) 的迭代方程.人工数据集和真实数据集上的实验结果表明本文所提方法的有效性.Abstract: In this paper, a semi-supervised affinity propagation (AP) clustering algorithm with homogeneity constraint, called HCSAP (semi-supervised affinity propagation clustering method with homogeneity constraints), is proposed. To keep consistency between the clustering results and the priori information about homogeneity sets, the constraint terms are introduced to the objection function of algorithm AP. With the max-sum belief propagation procedure, the objection function can be resolved into the corresponding responsibility and availability update equations. Experiments on synthetic dataset and real-world datasets indicate the effectiveness of the proposed HCSAP.
-
自寻的反坦克导弹由于具有"发射后不用管"的战术技术性能, 不但具有较高的命中精度, 而且大大提高了作战人员的战场生存能力, 使得世界各国争相对其进行研制和装备.当反坦克导弹处于大射程时, 由于非制冷式红外导引头观测距离有限, 不能直接在视场中观测到目标并进行锁定.此种条件下只能采取"发射后锁定"的工作方式, 即利用红外成像末制导技术在反坦克导弹末制导阶段对目标进行识别和定位, 完成目标的跟踪初始化.
"发射后锁定"的关键是目标的检测识别问题, 主要包括图像分割和目标识别两个方面.其中, 图像分割是目标检测、识别及跟踪等领域的底层图像处理过程, 是计算机视觉和模式识别领域的经典难题之一.因此, 多少年以来国内外大量学者一直对其进行着广泛而深入的研究, 也收获了许多行之有效的图像分割算法[1-5].然而, 由于自寻的反坦克导弹体积小, 红外成像制导系统的硬件处理速度有限, 对图像分割算法实时性提出了较高要求.同时, 由于地面背景相对于天空背景来说一般比较复杂, 在背景和目标比例相差悬殊的情况下, 对算法分割的有效性也提出了严峻的挑战.而在现有的报道中, 算法有效性的提高往往是以大幅增加算法的计算量为代价, 而难以保证实时性.因此, 对自寻的反坦克导弹复杂背景下红外坦克目标图像的快速有效分割算法进行研究, 无疑具有重要的现实意义.
目前, 在种类繁多的图像分割算法中, 阈值分割法是公认的一种简单高效的图像分割技术[6-7].常见的阈值分割法主要有最大类间方差法(即Otsu算法)、基于熵的阈值分割法、最小误差法、共生矩阵法、矩量保持法、概率松弛法、模糊集法以及与其他方法结合的阈值分割法[7-13].在这些阈值分割方法中, Otsu提出的最大类间方差法, 因其计算简单自适应性强而被广泛使用[14-15].该算法基于灰度直方图的一阶统计特性, 具有运算速度快, 适合于实时处理的优点.但是, 面对千差万别的图像, Otsu算法并不会在所有情况下都能得到理想的结果.尤其当背景比较复杂且背景和目标的比例相差悬殊时, 最大类间方差法就会产生错误分割甚至完全失效.因此, 本文立足于自寻的反坦克导弹红外导引头较高的实时处理要求, 选取计算简单的最大类间方差法, 研究其对复杂背景下红外坦克目标的分割效果, 找出最大类间方差法分割失败的本质原因; 然后针对所出现的问题, 对最大类间方差法进行改进, 在充分发挥其计算简单的优势下, 提高算法的分割性能.
1. 最大类间方差法(Otsu算法)及其阈值分析
1.1 最大类间方差法
最大类间方差法即Otsu算法是由Otsu最先提出的, 该算法是以图像的一维直方图为依据, ni以目标物体和背景的类间方差最大为阈值选取准则.设一副图像的灰度等级为L, 灰度值为i的像素个数为ni, 则总的像素为$N=\sum_{i=1}^{L}n_i$, 灰度值i出现的概率为ni/N.设以灰度值T为阈值将图像像素分成两类, 即灰度为[1, …, T]的像素构成一类, 记为C0; 灰度为[T +1, …, L- 1]的像素构成另外一类, 记为C1.将C0和C1出现的概率分别记为P0(T)和P1(T); 两类的灰度均值记为μ0(T)和μ1(T); 两类的方差记为${\sigma_0^2}(T)$, ${\sigma_1^2}(T)$.则各值计算方法如下[16]:
$ {P_0}(T)=\sum\limits_{i=1}^T {{P_i}} $
(1) $ {P_1}(T)=\sum\limits_{i=T+1}^{L - 1} {{P_i}}=1 - {p_0}(T) $
(2) $ {\mu _0}(T)=\frac{1}{{{P_0}(T)}}\sum\limits_{i=1}^T {i \cdot {P_i}} $
(3) $ {\mu _1}(T)=\frac{1}{{{P_1}(T)}}\sum\limits_{i=T+1}^{L - 1} {i \cdot {P_i}} $
(4) $ \sigma _0^2(T)=\;\frac{1}{{{P_0}(T)}}\sum\limits_{i=1}^T {{P_i} \cdot {{\left[{i-{\mu _0}(T)} \right]}^2}} $
(5) $ \sigma _1^2(T)=\;\frac{1}{{{P_1}(T)}}\sum\limits_{i=T+1}^{L - 1} {{P_i} \cdot {{\left[{i-{\mu _1}(T)} \right]}^2}} $
(6) 整幅图像的灰度均值μ为
$ \begin{align} \mu=P_0(T)\mu_0(T)+P_1(T)\mu_1(T) \end{align} $
(7) 两类的类间方差$\sigma _b^2(T)$为
$ \begin{align} \sigma _b^2(T)=P_0(T)\left[\mu_0(T)-\mu \right]^2+P_1(T) \left[\mu_1(T)-\mu \right]^2 \end{align} $
(8) 两类的类内方差之和$\sigma _w^2(T)$为
$ \begin{align} \sigma _w^2(T)=P_0(T)\sigma _0^2(T)+P_1(T)\sigma _1^2(T) \end{align} $
(9) Otsu提出的最大类间方差准则下的阈值为T*, 则
$ \begin{align} \sigma _b^2(T^*)={\mathop {\max }\limits_{1 \le T \le L - 1} \sigma _b^2(T)} \end{align} $
(10) 最小类内方差准则下的阈值为$T^{'*}$, 则
$ \begin{align} \sigma _w^2(T^{'*})={\mathop {\min }\limits_{1 \le T \le L - 1} \sigma _w^2(T)} \end{align} $
(11) Otsu指出最大类间方差准则和最小类内方差准则是等效的, 两者找出的阈值相同[16].
1.2 最大类间方差法阈值分析
以红外导引头在外场试验中拍摄的大量红外坦克目标图像为研究对象, 限于篇幅而又不失一般性, 图 1给出了从400米到1500米距离范围内, 不同距离处的坦克目标红外图像(具体距离值如图 1所示).各图像大小为880像素×480像素, 其中坦克目标在图像中所占比值最大仅为1.3%左右, 属于小目标.从图 1可以看出, 图像中存在着许多亮暗相间的背景, 直观判断, 图像背景比较复杂.由于坦克目标尺寸较小, 使得目标图像纹理弱化或消失, 坦克目标表现为灰度较为均匀的亮色区域.图 2为图 1中各红外图像所对应的灰度直方图, 从中可以发现, 各图像的像素数随灰度值的分布特点各有不同, 但各图像所包含的灰度范围普遍较大, 说明图像中灰度种类比较丰富, 图像背景比较复杂.
为便于对算法的分割效果进行比较, 本文将手工分割结果作为图像分割的理想结果, 相应的分割阈值视为该图像的最佳分割阈值.图 3为利用Otsu算法进行分割的结果, 从分割结果可以看出, 图 3(a)、图 3(b)和图 3(c)中, 由于背景比较复杂, 而且坦克目标距离较远, 目标相对图像的比例较小(最大仅为0.3%), 使得分割后坦克目标完全淹没在背景当中, 说明Otsu算法分割失败; 而在图 3(d)和图 3(e)中, 由于坦克目标距离较近, 目标相对图像的比例变大(分别为0.8%和1.3%), Otsu算法对坦克目标的分割结果要好于前三幅图像的分割结果.但与原图相比, 分割出的目标轮廓并不清晰, 边缘还粘连着较多的背景, 说明算法的分割效果较差.以上实验结果表明, 当红外背景比较复杂且坦克目标相对图像比例较小时, Otsu算法的分割效果较差甚至完全失效.
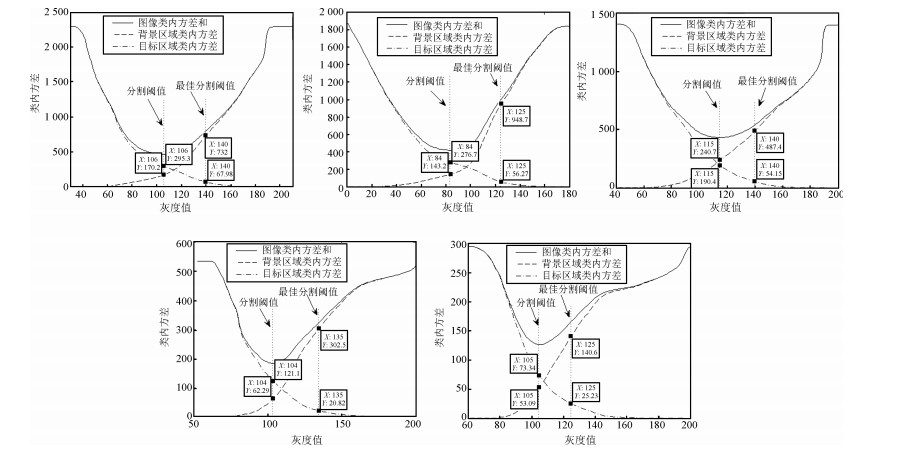
Otsu指出, 式(10)和式(11)两种阈值选取准则是等效的.为了找出影响分割阈值的主要原因, 本文对基于式(11)的最小类内方差准则进行分析.根据式(11), 图像的类内方差取最小值时所对应的灰度值即为分割阈值, 而图像的类内方差又由背景区域类内方差和目标区域类内方差两部分组成(如式(9)所示).也就是说, Otsu分割阈值与背景区域和目标区域两类的类内方差有着密切关系.为此, 本文给出了每幅图像的各种类内方差随灰度值的变化曲线(见图 4).对其进行分析发现, 各图中相应的类内方差随着灰度值的变化规律相同, 即各背景区域的类内方差都随着灰度值的增大而增大, 目标区域类内方差随着灰度值的增大而减小; 而图像的类内方差都存在一个最小值, 该最小值所对应的灰度值即为Otsu法的分割阈值.图中用虚线分别标出了Otsu法分割阈值以及手工分割的最佳阈值位置.我们发现, Otsu阈值与最佳阈值相比普遍偏小; 在Otsu阈值处(即图像类内方差取最小值的位置), 背景区域和目标区域的类内方差相差较小(如图 4所示, Otsu阈值处的两类类内方差相差最大不超过1倍), 而在最佳阈值处, 背景区域和目标区域的类内方差相差过大(如图 4所示, 最佳阈值处的两类类内方差相差最小达5倍, 最大高达15倍).通过以上事实, 可以得出这样一个结论:正是由于背景区域和目标区域相差过大的类内方差, 使得Otsu法计算出的分割阈值与最佳阈值发生了较大的偏移(偏移向着类内方差大的一类进行), 从而导致了算法的失效.该结果与文献[17]的理论分析结果相一致.同时, 这也揭示了Otsu法图像分割的有效性机理:若红外图像中背景和目标的类内方差相近(如背景较平坦的面目标红外图像), 则Otsu法必能得到较好的分割效果; 若背景和目标的类内方差相差过大(如复杂背景下的小目标红外图像), 则Otsu法将会失效.这启发我们, 要想提高复杂背景下Otsu法对红外小目标的分割性能, 必须设法降低背景区域类内方差, 使其与目标区域的类内方差相近.为此, 本文提出了对背景像素和灰度级进行约束的思想, 对算法进行改进, 以提高其分割性能.
2. 最大类间方差法(Otsu法)的改进
2.1 先验信息对背景像素的约束
自寻的反坦克导弹采用的是惯性制导和红外成像制导的复合制导方式.其在发射前, 由地面观瞄装置获取目标的距离等信息.在反坦克导弹飞向坦克目标的过程中, 初始阶段以惯性制导为主, 弹上的惯性制导系统将会对飞行速度及距离信息进行实时解算.当导弹进入飞行末段以后, 将以红外成像制导为主, 最终完成导弹对目标的精确打击.在这个过程中, 利用导弹的惯性制导系统便可获知导弹和坦克目标的实时距离.
设坦克目标的长为l1, 宽为l2, 其与红外导引头的距离为R, 红外导引头的成像焦距为f, 根据几何光学成像原理, 其在红外焦平面上的最大成像面积为
$ \begin{align} S=\;&\frac{l_1{l_2}}{R^2}f^2 \end{align} $
(12) 设红外焦平面的像元中心间距为d, 则坦克目标在红外焦平面成像所占有的最大像素数为
$ \begin{align} N_t=\;&\frac{l_1{l_2}}{{d^2}R^2}f^2 \end{align} $
(13) 由于红外焦平面上的目标图像一般为坦克目标斜视方向的投影, 因此, 由式(13)计算出的目标大小将作为坦克目标所成像的最大值, 即红外图像中坦克目标所占像素数必定在这个数值范围内.据此, 可对红外图像各灰度级的像素数进行约束, 在保持目标像素数量不变的情况下, 对背景像素进行削减, 以降低背景像素所占比例.
2.2 基于黄金分割法对背景灰度级的约束
由前面的分析可知, 在最佳阈值处, 背景区域的类内方差过大, 最终导致最大类间方差法分割的阈值过低.要想使计算的阈值与最佳阈值相接近, 必须要降低背景区域的类内方差, 而背景区域的类内方差与其所分布的灰度级别直接相关.对于复杂背景下的亮小目标而言, 目标灰度大都分布在灰度级较高的区域.而在图像灰度级较低的部分, 几乎全部由背景像素构成, 正是因为这些低灰度级像素的存在直接导致了所计算的背景类内方差过高.基于上述事实, 如果对这些像素采用一定的规则进行约束, 无疑将有助于降低背景区域的类内方差.
众所周知, 黄金分割率φ=0.618是人类发展历史长河中非常奇妙的数字之一.在20世纪70年代, 我国著名数学家华罗庚先生将黄金分割法作为一种优选方法在科学、工程、经济和艺术等领域得到普及和应用[18].至今, 具有完美感、神奇感和科学性的黄金分割法仍在工程技术领域有着广泛的应用[19-24].例如, 文献[25]在确定遗传算法最优变异因子存在的区间之后, 运用黄金分割法最终确定最优变异因子, 解决了人工神经网络训练中陷入局部极小值问题; 文献[26]将黄金分割法应用到自适应小波阈值去噪算法的补偿方法中, 通过每次选取整个不确定区间的两个黄金分割点, 比较该两点值的大小, 从而缩小搜索区间, 达到快速寻优的目的.鉴于此, 本文提出采用黄金分割法对图像背景区域的灰度级别进行约束.考虑到红外图像中, 目标往往占据高频成分, 而红外背景中的绝大部分占据图像的低频成分.设红外图像的灰度级别为L, 以0.618L为分界点, 将低于该值的灰度区域视为背景区域, 高于该值的视为目标区域.设背景区域的灰度级别为Lb, 且Lb=0.618L.然后以0.382 Lb(即0.382Lb=0.382×0.618L ≈ 0.236L)为阈值, 将低于该值的背景区域抑制掉, 从而达到约束红外背景灰度级的目的.由于目标在红外图像中往往占据高频成分, 因此, 按照上述的约束规则对图像背景灰度级进行约束后, 目标像素数不会受到影响.
设红外图像的像素随灰度的分布函数为g(i), 坦克目标图像所占有的像素数最大为Nt.结合上节内容, 利用目标的最大像素数和黄金分割法分别对红外图像的背景区域像素和灰度级进行约束, 具体约束准则如式(14)所示.其中, L为红外图像的灰度级别, L2=0.618L, L1=0.382L2 ≈ 0.236L.
上述准则所表达的物理意义为:以图像灰度级L的0.618处为分界点, 把灰度级较高的部分认为是可能的目标区域, 对每个灰度级按照目标像素数进行保留; 灰度级较低的部分认为是背景区域, 使背景像素按照灰度值减小的方向由目标像素数值进行递减至零; 然后将小于背景灰度范围0.382倍的灰度级置为零.该过程使得图像的灰度分布向着目标区域进行靠拢, 以达到降低背景区域类内方差的目的.
2.3 算法步骤
红外图像经过对背景像素和灰度级进行约束之后, 便可利用最大类间方差法对约束后的红外图像进行处理.算法总的计算步骤如下:
步骤1. 从自寻的反坦克导弹的惯性制导系统获取坦克目标的距离, 并和其他已知参数一起代入式(13)进行计算, 得到坦克目标图像的最大像素值Nt.
步骤2.计算红外图像的灰度直方图g(i);
步骤3.按照式(14)对红外图像的背景像素和灰度级别进行约束;
步骤4.利用最大类间方差法对约束后的红外图像进行处理, 获取分割阈值并对整幅图像进行分割.
值得一提的是, 由于坦克目标的像素不可能全部分布在单一的灰度级上, 即某一灰度级包含的目标像素数应该比坦克目标的总像素数少的多, 而算法中用到的是坦克目标的最大像素值对各灰度级像素进行约束.在一定程度上, 算法对式(13)计算出的坦克目标最大像素值的大小不是很敏感.也就是说, 算法只需要式(13)提供坦克目标总像素值的一个大概范围.因此, 在利用式(13)计算坦克目标的最大像素值时, 只需一次性提供任意型号坦克的长、宽尺寸即可, 算法与坦克具体型号无关.
3. 实验结果及分析
为了验证本文方法的有效性, 以红外导引头在外场试验中拍摄的大量红外坦克目标图像为实验对象, 在CPU为2.0 GHz, 内存为2 GB的笔记本电脑上, 基于Matlab 7.1软件平台, 对本文提出的算法进行实验.由于篇幅有限, 为了方便讨论而又不失一般性, 本文分别就白天和夜间两种情况下的坦克红外图像进行讨论.白天由于有太阳光的照射, 地表环境温度相对于夜间温度较高, 加上地面对阳光的红外漫反射, 造成了白天红外图像与夜间红外图像存在着不同.前已述及, 图 5(a)~图 9(a)为红外导引头在白天拍摄的从400米到1500米距离范围内, 不同距离处的坦克目标红外图像, 图 5(b)~图 9(b)为其所对应的灰度直方图.由于阳光的照射, 地表不同区域因自身温度以及对红外漫反射的不同, 使得图像中存在着许多亮暗相间的背景, 图像包含的灰度范围普遍较大, 说明图像中灰度种类比较丰富, 图像背景比较复杂.图 10(a)~图 14(a)为红外导引头在夜间拍摄的从300米到1600米范围内, 不同距离处的坦克红外图像, 图 10(b)~图 14(b)为其所对应的灰度直方图.由于夜间环境温度与白天相比温度较低, 图像中的白色亮背景较少或消失, 但图像中存在较多地表植被的灰度纹理背景, 使得红外图像背景仍然比较复杂.实验中, 坦克目标的距离由激光测距机给出, 如表 1所示(在算法的实际应用中, 坦克目标的距离由反坦克导弹的惯性制导系统提供).设定坦克目标的长为7.6米, 宽为3.5米, 取红外导引头的焦距f为110毫米, 红外探测器像元间距d为0.017毫米.将这些参数及表 1中相应的坦克目标距离R分别代入式(13), 计算得到各图像中坦克目标的最大像素数(见表 1).
$ f(i)=\left\{ {\begin{array}{*{20}{l}} {0, }&{i \in [1, {L_1}- 1)}\\ {g(i)\frac{i}{{0.618L}}, }&{i \in [{L_1}- 1, {L_2}- 1)且g(i)<{N_t}}\\ {{N_t}\frac{i}{{0.618L}}, }&{i \in [{L_1}- 1, {L_2}- 1)且g(i)\ge {N_t}}\\ {g(i), }&{i \in [{L_2}-1, L-1]{\rm{ }}且g(i)<{N_t}}\\ {{N_t}, }&{i \in [{L_2}-1, L-1]{\rm{ }}且g(i)\ge {N_t}} \end{array}} \right. $
(14) 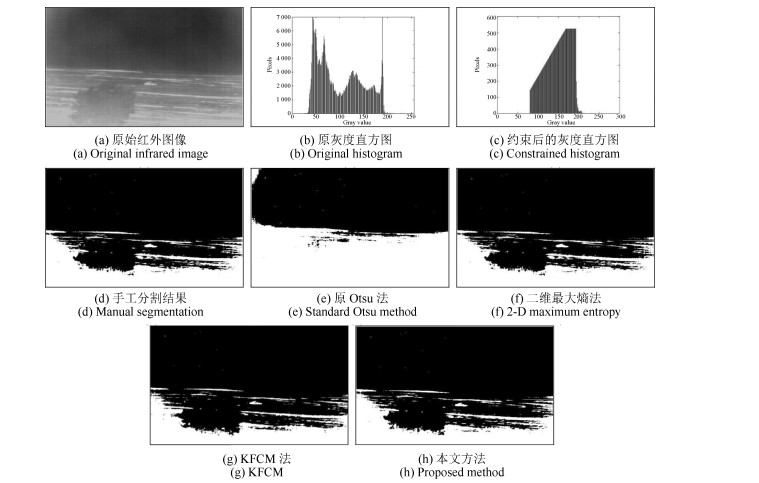 图 5 距离为1 455米处的白天坦克红外图像分割结果Fig. 5 Segmentation results of tank infrared image taken in daytime with distance of 1 455 m
图 5 距离为1 455米处的白天坦克红外图像分割结果Fig. 5 Segmentation results of tank infrared image taken in daytime with distance of 1 455 m 图 6 距离为1 199米处的白天坦克红外图像分割结果Fig. 6 Segmentation results of tank infrared image taken in daytime with distance of 1 199 m
图 6 距离为1 199米处的白天坦克红外图像分割结果Fig. 6 Segmentation results of tank infrared image taken in daytime with distance of 1 199 m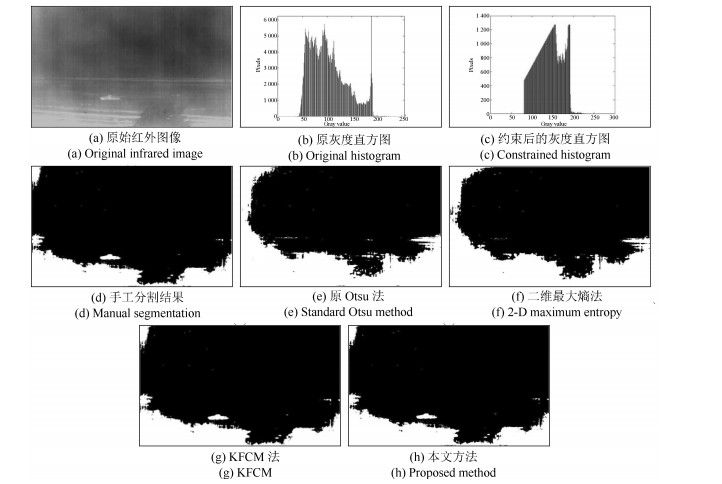 图 7 距离为936米处的白天坦克红外图像分割结果Fig. 7 Segmentation results of tank infrared image taken in daytime with distance of 936 m
图 7 距离为936米处的白天坦克红外图像分割结果Fig. 7 Segmentation results of tank infrared image taken in daytime with distance of 936 m 图 8 距离为573米处的白天坦克红外图像分割结果Fig. 8 Segmentation results of tank infrared image taken in daytime with distance of 573 m
图 8 距离为573米处的白天坦克红外图像分割结果Fig. 8 Segmentation results of tank infrared image taken in daytime with distance of 573 m 图 9 距离为446米处的白天坦克红外图像分割结果Fig. 9 Segmentation results of tank infrared image taken in daytime with distance of 446 m
图 9 距离为446米处的白天坦克红外图像分割结果Fig. 9 Segmentation results of tank infrared image taken in daytime with distance of 446 m 图 10 距离为1 611米处夜间坦克红外图像分割结果Fig. 10 Segmentation results of tank infrared image taken at night with distance of 1 611 m
图 10 距离为1 611米处夜间坦克红外图像分割结果Fig. 10 Segmentation results of tank infrared image taken at night with distance of 1 611 m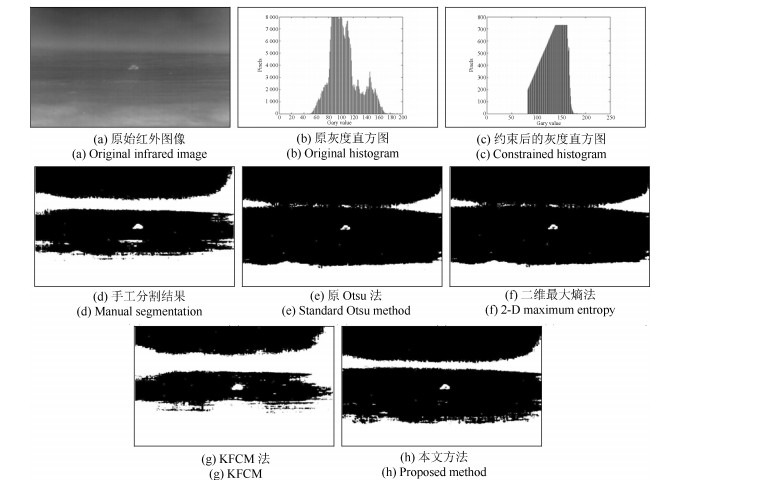 图 11 距离为1 251米处夜间坦克红外图像分割结果Fig. 11 Segmentation results of tank infrared image taken at night with distance of 1 251 m
图 11 距离为1 251米处夜间坦克红外图像分割结果Fig. 11 Segmentation results of tank infrared image taken at night with distance of 1 251 m 图 12 类距离为980米处夜间坦克红外图像分割结果Fig. 12 Segmentation results of tank infrared image taken at night with distance of 980 m
图 12 类距离为980米处夜间坦克红外图像分割结果Fig. 12 Segmentation results of tank infrared image taken at night with distance of 980 m 图 13 距离为740米处夜间坦克红外图像分割结果Fig. 13 egmentation results of tank infrared image taken at night with distance of 740 m
图 13 距离为740米处夜间坦克红外图像分割结果Fig. 13 egmentation results of tank infrared image taken at night with distance of 740 m 图 14 距离为353米处夜间坦克红外图像分割结果Fig. 14 Segmentation results of tank infrared image taken at night with distance of 353 m表 1 坦克目标距离及所占最大像素数Table 1 The target distance and its maximum pixels
图 14 距离为353米处夜间坦克红外图像分割结果Fig. 14 Segmentation results of tank infrared image taken at night with distance of 353 m表 1 坦克目标距离及所占最大像素数Table 1 The target distance and its maximum pixelsDaytime images Night images Fig. 5(a) Fig. 6(a) Fig. 7(a) Fig. 8(a) Fig. 9(a) Fig. 10(a) Fig. 11(a) Fig. 12(a) Fig. 13(a) Fig. 14(a) Target distance (m) 1455 1199 936 573 446 1 611 1 251 980 740 353 Target pixels 526 775 1 271 3 390 5 601 429 712 1 159 2 032 8 924 结合表 1中数据, 利用式(14)对各红外图像的背景进行约束.图 5(c)~图 14(c)分别为各红外图像约束后的灰度直方图, 将其与相应的原灰度直方图进行比较, 发现背景区域的像素数量和灰度级别都得到了不同程度的抑制, 灰度分布明显向着目标区域进行靠拢.
3.1 算法的二值化分割结果对比分析
为了便于对比分析, 图 5(d)~图 14(d)给出了各红外图像相应的手工分割结果, 同时本文还给出了原Otsu算法、二维最大熵法、基于高斯核函数的模糊C均值聚类法(即KFCM算法)以及本文方法的处理结果(分别如图(5)~图(14)中的(e)~(h)所示).将各算法的分割结果分别与手工分割结果进行比较, 发现原Otsu算法的分割效果最差, 在所给出的10幅红外图像样本中, 仅完成了两幅图像的有效分割(见图 9(e)和图 11(e)); 二维最大熵法由于充分考虑了像素灰度及其邻域灰度的空间相关性[13, 27-28], 与原Otsu算法相比, 其分割性能有所提高, 但也仅完成了其中五幅图像的有效分割; KFCM法是一种基于划分的聚类算法, 其思想就是使得被划分到同一类的对象之间相似度最大, 而不同类之间的相似度最小.因此, 其相比于阈值分割算法来说, 一般具有较高的分割精度[29-30].从实验结果来看, KFCM法分割结果与前面两种算法相比确实有了较大的提高, 其完成了八幅图像样本的有效分割.但与本文算法相比, KFCM法仍有两幅红外图像分割失败, 没能达到对所有红外图像的成功分割, 说明其对于红外复杂背景下不同比例尺寸的小目标而言, 也难以保证较好的鲁棒性.而本文算法成功地分割出了所有位于不同距离上的红外坦克目标, 说明所提算法对于红外复杂背景下, 不同比例的坦克小目标分割具有较强的适应性和有效性.分析其原因, 这主要是因为本文算法能够实时根据目标图像的尺寸信息对背景进行抑制, 减少了背景在算法运算过程中对图像分割结果的影响, 从而保证了算法对图像分割的有效性和鲁棒性.另外, 将本文算法的分割结果与手工分割结果比较, 直观上来看, 本文算法分割结果与手工分割结果基本相当, 说明本文算法的分割效果可与手工分割效果相媲美, 从而证明本文算法具有非常高的分割精度, 且具有较强的适应性.
3.2 算法的分割精度对比分析
为能够对算法的分割精度进行定量分析, 本文以Jaccard相似系数作为算法分割性能的评价指标.Jaccard相似系数是衡量两个集合相似度的主要指标, 其已经成为国际上评估算法分割性能的重要手段[30-31].设S1为算法分割出的目标区域, S2为实际目标区域, 则Jaccard相似系数可由式(15)计算得出[31].由式(15)可知, Jaccard相似系数的值域为[0, 1], 其值越大, 说明分割出的目标与实际目标越接近, 即算法的分割精度越高, 反之, 分割精度越低.当分割出的目标与真实目标完全相同时, 达到最大值为1.
$ \begin{align} JS(S_1, S_2)=\frac{| S_1 \bigcap S_2 |}{| S_1 \bigcup S_2 | } \end{align} $
(15) 表 2分别给出了原Otsu算法、二维最大熵法、KFCM法和本文算法对各图像的分割精度.从表中数据可知, 原Otsu算法的分割精度最低, 其平均值仅为22.25%;二维最大熵法则相对较高, 其平均值为48.03%;KFCM法的分割性能要明显好于前两种算法, 其分割精度平均值达72.86%;而本文方法的分割精度最高, 其值都在86.23%以上, 最高为99.91%, 平均值更是高达96.54%.因此, 通过对算法的分割精度进行定量分析, 实验结果再次证明了本文方法具有较高的分割精度, 而且对于复杂背景下不同尺寸的坦克小目标具有较强的适应性.
表 2 算法分割精度对比(%)Table 2 The segmentation accuracy comparison of different methods (%)Images Standard Otsu method 2-D maximum entropy KFCM Proposed method Daytime Fig. 5(a) 0.25 76.57 85.93 96.01 Fig. 6(a) 0.26 0.28 98.19 91.54 Fig. 7(a) 0.90 0.91 97.47 99.69 Fig. 8(a) 62.08 98.08 94.09 97.08 Fig. 9(a) 78.68 96.17 89.40 98.51 Night Fig. 10(a) 0.09 0.09 95.26 99.57 Fig. 11(a) 71.84 73.26 66.81 86.23 Fig. 12(a) 0.59 79.35 0.81 99.91 Fig. 13(a) 0.68 0.67 0.76 99.89 Fig. 14(a) 7.10 54.93 99.92 96.98 Average 22.25 48.03 72.86 96.54 3.3 算法耗时比较
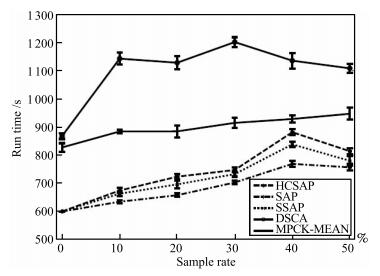
为了证明算法的实时性, 本文分别给出了原Otsu算法、二维最大熵法、KFCM法以及本文算法的计算耗时, 如表 3所示.对表中数据进行分析, 不难发现二维最大熵法和KFCM法的计算耗时远高于原Otsu算法和本文方法, 其计算耗时整整高出了3到4个数量级.这主要是因为二维最大熵法是建立在二维灰度直方图基础之上, 相比一维灰度直方图的分割算法, 虽然提高了分割性能, 但其计算量随图像灰度级成指数增长, 造成算法计算量大幅增加, 算法实时性较差; KFCM法由于采用图像像素作为聚类样本, 会因样本数较大和聚类优化过程中迭代次数较多而使算法耗时巨幅增加, 导致其在几种分割算法中实时性最差.而本文算法在几种算法当中计算耗时最少, 主要是因为算法是建立在一维灰度直方图的基础之上, 同时, 在算法的计算过程中, 由于对图像背景的像素和灰度级进行了抑制, 减少了参与算法计算的像素数和灰度级, 从而使得本文算法的计算耗时相比原Otsu算法也有所降低.从表 3中数据可知, 本文算法的最大耗时不超过1.44ms, 平均耗时仅为1.37ms.以自寻的反坦克导弹红外导引头25帧/秒的采样周期计算, 对于40毫秒的系统处理时间来说, 本文算法不仅完全能够满足算法的实时性要求, 而且为后续其他算法的处理节省了大量的处理时间.另外, 值得一提的是, 算法在对背景像素和灰度级进行抑制的同时, 也抑制掉了背景噪声带来的干扰, 因此, 本文算法还具有一定的抗噪声干扰能力.
表 3 算法耗时对比Table 3 The consuming time comparison of different methodsImages Standard Otsu method (ms) 2-D maximum entropy (ms) KFCM (ms) Proposed method (ms) Daytime Fig. 5(a) 1.42 4 260.79 27597.60 1.40 Fig. 6(a) 1.32 4 247.61 21 529.17 1.27 Fig. 7(a) 1.55 4 237.53 41 853.46 1.41 Fig. 8(a) 1.47 4 031.80 54170.71 1.39 Fig. 9(a) 1.36 4 158.24 52 666.22 1.29 Night Fig. 10(a) 1.44 4 375.39 21 598.83 1.40 Fig. 11(a) 1.64 4 521.92 26614.01 1.40 Fig. 12(a) 1.43 4153.51 27991.33 1.34 Fig. 13(a) 1.52 3 839.10 43 789.32 1.44 Fig. 14(a) 1.40 4 671.52 45 569.53 1.32 Average 1.45 4 249.74 36 338.02 1.37 综上所述, 本文算法经过了红外导引头拍摄的大量红外坦克目标图像的实验验证.限于篇幅而又不失一般性, 本文给出了300到1600米距离范围内, 白天和夜间不同距离上的坦克目标图像的分割结果, 并与原Otsu算法、二维最大熵法、KFCM法以及手工分割的结果进行了对比分析.结果表明, 本文方法在充分发挥原Otsu算法计算简单, 耗时少的优势下, 大幅提高了算法的分割性能, 算法的分割效果不仅好于二维最大熵法和KFCM法的分割效果, 而且可与手工分割效果相媲美.因此, 本文方法完全达到了自寻的反坦克导弹在红外复杂背景下对坦克小目标的快速有效分割要求.这对于自寻的反坦克导弹红外导引头的目标分割算法设计具有重要参考意义.
4. 结论
本文通过对红外导引头拍摄的大量红外坦克目标图像进行分割实验, 对最大类间方差法的阈值性质进行了分析, 阐释了复杂背景下最大类间方差法分割失败的本质原因, 认为正是背景和目标区域相差过大的类内方差导致了算法的失效, 并进一步揭示了算法的有效性机理.在此基础上, 提出了对背景区域像素和灰度级别进行约束的思想, 对最大类间方差法进行了改进.实验证明, 本文方法分割效果不仅好于二维最大熵法和KFCM法的分割效果, 而且与手工分割效果相当; 且计算耗时较少, 最大耗时不超过1.44ms, 这不仅完全能够满足算法的实时性要求, 而且为后续其他算法的处理节省了大量的处理时间.本文为自寻的反坦克导弹复杂背景下红外坦克目标的分割算法设计提供了重要参考.
-
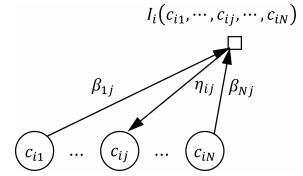
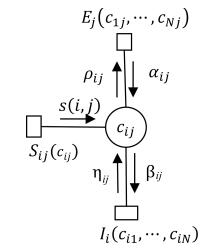
图 3 $\eta_{ij}$ 与其相关信息关系图
Fig. 3 Relationship among $\eta_{ij}$ and its correlative message
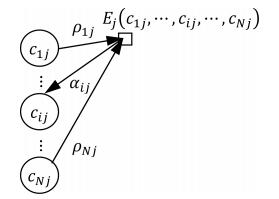
图 4 $\alpha_{ij}$ 与其相关信息关系图
Fig. 4 Relationship among $\alpha_{ij}$ and its correlative message
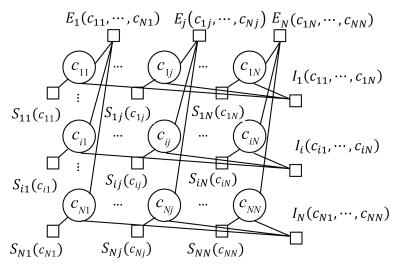
表 1 部分符号说明
Table 1 The explanation of some symbol
符号 意义 $N$ 聚类数据点个数 $M$ 同类集个数 $h_1,h_2$ 数据点 $h_1,h_2$ $c_{ij}$ 变量节点, 为0表示 $j$ 不是 $i$ 的类中心点; 为1表示 $j$ 是 $i$ 的类中心点 $E_{ij}(\cdot)$ $E_j(c_{1j},\cdots,c_{Nj})$ 数据点 $j$ 的同类约束与一致性约束函数 $\rho_{ij}$ 表示变量节点 $c_{ij}$ 向函数节点 $E_j$ 所发送的标量信息 $c_i$ 数据点 $i$ 的类中心点 $P$ 全体同类集所构成的集合 $p^i$ 数据点 $i$ 所在的同类约束集 $I_i(\cdot)$ $I_i(c_{i1},\cdots,c_{iN})$ 为数据点 $i$ 的唯一性约束函数 $\alpha_{ij}$ 表示函数节点 $E_j$ 向变量节点 $ c_{ij}$ 所发送的标量信息 $\beta_{ij}$ 表示变量节点 $c_{ij}$ 向函数节点 $I_i$ 所发送的标量信息 $p_v$ 第 $v$ 个同类集 ⊕ 异或 ${{\bar P}}$ 无同类约束的数据点集 $S_{ij}(\cdot)$ 定义在数据点 $i$ , $j$ 之间的相似度函数 $s(i,j)$ 数据点 $i$ , $j$ 之间的相似度 $\eta_{ij}$ 表示函数节点 $I_i$ 向变量节点 $c_{ij}$ 所发送的标量信息  下载: 导出CSV
下载: 导出CSV
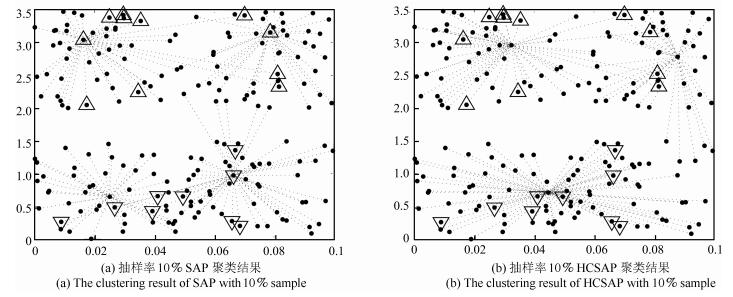
表 2 人工数据上的聚类结果参数对比
Table 2 Performance comparison on man-made dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 72.12 72.12 72.12 70.31 69.3 56.50 56.50 56.50 53.43 55.0 0 std (0) (0) (0) (1.3) (3.6) (0) (0) (0) (1.1) (2.1) p-value - - - 4.2E-3 6.6E-3 - - - 1.8E-1 3.4E-1 Mean 87.24 82.74 80.22 85.27 81.66 80.47 72.41 70.50 77.39 75.4 10 std (6.6) (4.7) (0.8) (5.2) (9.2) (1.7) (1.1) (2.4) (2.1) (3.7) p-value - 3.1E-2 (+) 2.2E-5 (+) 9.7E-2 6.3E-3 (+) - 3.9E-2 (+) 4.1E-5 (+) 6.4E-2 6.8E-2 Mean 96.15 80.45 81.78 90.00 88.6 95.75 72.57 73.66 90.41 76.8 20 std (1.0) (1.6) (1.8) (4.1) (4.5) (4.0) (1.6) (2.7) (0.5) (1.4) p-value - 9.4E-4 (+) 7.8E-5 (+) 9.2E-3 (+) 9.2E-3 (+) - 1.7E-7 (+) 2.3E-6 (+) 1.4E-2 (+) 7.5E-6 (+) Mean 96.24 91.24 92.47 90.36 91.33 97.58 89.00 85.74 90.06 89.6 30 std (2.0) (4.1) (5.1) (0.8) (1.6) (0.2) (6.6) (4.1) (0.2) (2.8) p-value - 4.9E-2 (+) 5.1E-2 8.4E-3 (+) 7.4E-3 (+) - 3.4E-3 (+) 9.5E-8 (+) 1.6E-2 (+) 4.7E-4 (+) Mean 96.66 88.57 87.98 90.21 89.2 97.35 88.65 86.97 90.33 90.5 40 std (1.3) (3.0) (2.7) (0.2) (4.5) (2.0) (1.2) (0.9) (0.5) (7.7) p-value - 5.7E-3 (+) 1.1E-3 (+) 6.6E-3 (+) 3.9E-3 (+) - 1.1E-4 (+) 2.4E-7 (+) 1.8E-2 (+) 7.1E-3 (+) Mean 98.05 90.34 88.84 90.70 90.8 98.25 89.65 90.45 88.87 90.0 50 std (0.2) (7.1) (1.4) (0.6) (2.3) (0.2) (2.8) (9.6) (0.7) (3.4) p-value - 5.1E-2 7.2E-4 (+) 9.0E-5 (+) 1.4E-4 (+) - 42E-4 (+) 3.7E-7 (+) 8.4E-3 (+) 6.7E-3 (+) 注:表中p-value为5 %显著性水平下的 $t$ 检验值, "+"表示HCSAP在5 %显著性水平下优于对比聚类算法."-"表示在5 %显著性水平下HCSAP劣于对比聚类算法.粗体字表示对比较优者 (下同).
下载: 导出CSV
表 3 实验数据集
Table 3 Dataset used in experiment
Item Number of instance Dimension Class Preference Optdigit 1 797 64 10 $1\times Mid$ Iris 150 4 3 $3\times Mid$ Ionosphere 351 34 2 $10\times Mid$ Letter recogni- 2 241 16 3 $1\times Mid$ tion {I, J, L} Pendigits 3 498 16 10 $1\times Mid$ glass 214 9 6 $5\times Mid$ wine 178 13 3 $5\times Mid$ wdbc 768 8 2 $50\times Mid$
下载: 导出CSV
表 4 Optdigit数据集上的聚类结果对比
Table 4 Performance comparison on Optdigit dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 22.35 22.35 22.35 19.14 20.61 12.57 12.57 12.57 10.68 11.46 0 std (0) (0) (0) (1.25) (3.87) (0) (0) (0) (1.6) (0.9) p-value - - - 4.3E-3 4.9E-2 - - - 4.1E-2 (+) 4.8E-2 Mean 31.86 30.03 29.30 27.98 30.41 18.97 17.75 15.34 14.68 16.35 10 std (4.69) (1.30) (2.47) (1.50) (4.94) (5.02) (5.92) (6.1) (5.7) (2.2) p-value - 3.1E-1 3.3E-1 2.6E-1 5.1E-1 - 2.7E-1 6.1E-1 1.4E-1 9.9E-2 Mean 42.57 43.15 44.63 40.55 41.55 27.10 27.71 27.96 27.30 24.63 20 std (7.4) (8.01) (6.91) (7.65) (9.52) (9.00) (3.36) (4.86) (7.96) (8.14) p-value - 2.2E-1 6.6E-1 1.0E-1 2.9E-1 - 5.7E-1 6.7E-1 4.3E-1 7.4E-2) Mean 54.41 52.5 51.23 49.87 52.44 36.61 35.78 34.79 30.76 31.87 30 std (9.02) (2.01) (4.31) (2.44) (3.75) (2.67) (0.79) (6.6) (8.2) (7.8) p-value - 2.6E-1 1.7E-1 4.6E-2 (+) 5.7E-1 - 4.3E-1 8.7E-2 4.4E-2 (+) 2.5E-2 (+) Mean 62.67 61.35 61.22 59.57 61.24 45.85 44.46 45.20 41.85 40.27 40 std (2.39) (1.71) (1.6) (4.21) (8.34) (0.86) (3.12) (4.20) (7.14) (9.48) p-value - 4.0E-1 4.3E-1 2.9E-1 1.6E-1 - 1.7E-1 2.7E-1 7.7E-2 2.1E-2 (+) Mean 71.75 68.84 68.8 69.54 69.33 56.09 52.69 51.27 48.62 50.11 50 std (9.58) (6.32) (9.96) (8.47) (10.20) (2.45) (4.79) (2.70) (5.47) (5.50) p-value - 2.4E-1 2.4E-11 8.1E-2 9.8E-2 - 1.4E-2 (+) 1.1E-1 2.5E-3 (+) 5.8E-2
下载: 导出CSV
表 5 Iris数据集的聚类结果对比
Table 5 Performance comparison on Iris dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 61.87 61.87 61.87 56.27 55.38 55.33 55.33 55.33 52.61 53.70 0 std (0) (0) (0) (3.1) (3.6) (0) (0) (0) (2.30) (4.81) p-value - - - 1.4E-2 2.2E-2 - - - 1.6E-1 4.8E-1 Mean 73.36 72.93 72.55 71.84 69.57 75.60 56.53 55.22 60.77 58.45 10 std (2.69) (0.93) (1.21) (6.40) (3.72) (5.3) (0.87) (4.11) (2.57) (12.72) p-value - 1.5E-4 (+) 1.3E-4 (+) 5.3E-4 (+) 2.2E-4 (+) - 1.3E-3 (+) 1.4E-3 (+) 5.6E-3 (+) 4.2E-2 (+) Mean 79.04 79.78 76.99 81.21 74.31 75.33 69.11 66.22 64.21 70.40 20 std (3.22) (8.02) (5.90) (8.3) (6.61) (7.33) (12.10) (18.9) (14.1) (11.23) p-value - 2.8E-1 1.4E-1 8.2E-1 5.4E-3 - 2.7E-1 2.3E-1 5.4E-1 9.1E-1 Mean 88.46 80.33 81.24 80.74 75.33 81.33 72.22 71.25 72.11 69.44 30 std (1.75) (9.15) (9.47) (4.4) (10.1) (2.91) (12.15) (11.41) (13.15) (10.9) p-value - 2.1E-1 3.4E-1 1.1E-2 1.2E-2 - 2.3E-1 2.0E-1 2.8E-1 1.1E-1 Mean 94.72 89.62 88.25 85.74 84.27 92.93 84.40 84.00 81.23 83.78 40 std (3.64) (3.79) (4.8) (5.9) (5.6) (5.77) (6.95) (8.3) (7.9) (9.1) p-value - 1.5E-1 4.6E-2 (+) 4.9E-1 5.9E-1 - 1.7E-1 1.1E-1 1.4E-1 2.4E-1 Mean 94.43 92.38 93.50 90.22 89.01 94.44 88.22 87.20 86.33 90.01 50 std (0.39) (1.39) (2.0) (7.1) (5.1) (0.03) (5.00) (6.89) (6.12) (10.88) p-value - 1.0E-1 1.7E-1 5.5E-1 6.4E-1 - 1.5E-1 1.2E-1 2.7E-1 1.4E-1
下载: 导出CSV
表 6 Ionosphere数据集上的聚类结果对比
Table 6 Performance comparison on Ionosphere dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 51.96 51.96 51.96 45.89 46.31 40.35 40.35 40.35 43.48 41.25 0 std (0) (0) (0) (5.2) (3.4) (0) (0) (0) (2.50) (1.31) p-value - - - 7.3E-1 6.9E-1 - 4.4E-1 5.2E-1 1.3E-1 2.3E-1 Mean 55.24 56.74 57.30 58.21 54.21 58.21 59.38 57.66 55.24 58.00 10 std (2.45) (7.87) (1.2) (7.2) (3.6) (7.32) (2.78) (7.27) (6.17) (5.48) p-value - 3.5E-2 (-) 4.8E-2 (-) 5.4E-1 7.9E-1 - 8.2E-1 6.3E-1 5.2E-1 4.5E-1 Mean 56.45 61.13 60.34 54.29 55.12 63.41 64.12 64.30 62.34 61.25 20 std (1.97) (2.36) (1.90) (4.87) (3.57) (5.79) (3.18) (5.54) (7.53) (4.74) p-value - 5.40E-3 (-) 3.47E-2 (-) 4.4E-1 5.1E-1 - 2.8E-1 3.5E-1 6.4E-1 4.1E-1 Mean 66.61 61.16 65.14 57.02 59.54 63.74 67.20 61.42 61.28 60.11 30 std (3.25) (5.47) (3.32) (5.42) (4.14) (5.20) (1.44) (8.54) (3.15) (7.21) p-value - 2.8E-1 4.2E-1 3.3E-1 2.4E-1 - 1.9E-1 2.9E-1 1.6E-1 1.7E-1 Mean 67.61 71.68 68.50 64.71 69.87 62.66 64.04 57.99 60.34 61.23 40 std (4.23) (3.03) (1.20) (4.56) (1.57) (8.17) (7.24) (4.8) (1.36) (5.4) p-value - 2.4E-2 (-) 3.7E-2 (-) 1.7E-1 5.6E-1 - 2.5E-1 3.6E-1 2.2E-1 1.4E-1 Mean 84.16 83.17 80.26 80.66 84.78 72.53 71.33 72.55 70.21 69.88 50 std (6.12) (4.87) (2.80) (2.69) (4.31) (5.60) (7.53) (5.33) (2.42) (4.69) p-value - 3.6E-1 3.4E-1 4.7E-1 2.1E-1 - 1.9E-1 3.9E-1 2.2E-1 1.0E-1
下载: 导出CSV
表 7 Letter-recognition {I, J, L}上的聚类结果对比
Table 7 Performance comparison on Letter-recognition dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 49.87 49.87 49.87 41.30 42.33 33.33 33.33 33.33 31.54 30.36 0 std (0) (0) (0) (1.9) (4.1) (0) (0) (0) (2.5) (3.1) p-value - - - 5.7E-2 6.9E-2 - - - 1.7E-1 1.0E-1 Mean 54.42 55.01 54.36 55.11 57.21 39.00 38.10 40.23 39.98 40.05 10 std (8.90) (2.63) (5.7) (6.4) (3.89) (8.08) (2.78) (1.4) (2.0) (3.7) p-value - 6.2E-1 2.1E-1 4.8E-1 1.2E-1 - 2.3E-1 5.6E-1 7.4E-1 6.1E-1 Mean 59.47 52.01 51.69 57.20 55.31 42.66 35.33 34.88 37.90 35.87 20 std (1.92) (5.73) (4.8) (6.8) (5.0) (9.57) (7.26) (5.8) (3.2) (2.8) p-value - 4.2E-2 (+) 3.2E-2 (+) 1.1E-1 3.1E-1 - 4.9E-2 2.3E-2 4.7E-2 2.6E-2 Mean 67.90 65.36 66.30 64.87 60.45 52.66 50.00 49.68 50.33 51.74 30 std (0.41) (6.44) (3.2) (5.6) (4.9) (1.84) (1.54) (1.74) (2.53) (3.40) p-value - 2.6E-1 3.0E-1 1.7E-1 2.6E-1 - 2.3E-1 1.2E-1 2.9E-1 5.4E-1 Mean 77.05 72.97 73.33 71.4 70.24 64.66 60.00 59.40 58.67 51.77 40 std (2.00) (4.43) (1.5) (2.6) (2.4) (8.17) (4.26) (7.26) (8.11) (14.25) p-value - 3.3E-1 4.2E-1 1.1E-1 1.5E-1 - 3.4E-1 2.9E-1 4.1E-1 5.3E-1 Mean 84.16 83.17 84.12 83.00 81.47 73.33 71.33 70.11 68.25 67.49 50 std (4.55) (7.41) (5.4) (4.9) (4.4) (2.62) (7.53) (5.1) (7.6) (5.3) p-value - 4.9E-1 5.0E-1 2.3E-1 2.3E-1 - 3.3E-1 2.8E-1 1.0E-1 4.4E-2 (+)
下载: 导出CSV
表 8 Pendigits数据集的聚类结果对比
Table 8 Performance comparison on Pendigits dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 19.23 19.23 19.23 17.21 16.32 11.20 11.20 11.20 9.79 9.64 0 std (0) (0) (0) (1.42) (2.51) (0) (0) (0) (0.25) (0.36) p-value - - - 9.4E-3 (+) 2.8E-3 (+) - - - 3.9E-2 (+) 2.8E-2 (+) Mean 27.40 23.17 24.65 24.68 21.97 16.72 13.75 12.99 13.58 11.95 10 std (1.38) (8.62) (7.64) (9.17) (4.11) (5.03) (3.15) (2.87) (2.77) (1.44) p-value - 2.3E-1 5.6E-2 2.8E-1 5.8E-2 - 4.1E-1 9.6E-2 6.7E-1 6.1E-1 Mean 38.66 35.19 34.67 33.74 34.21 36.14 25.58 24.71 21.95 27.64 20 std (0.88) (3.67) (4.25) (5.50) (6.67) (3.13) (8.79) (3.34) (5.61) (4.13) p-value - 5.6E-1 2.4E-1 2.7E-1 3.1E-1 - 8.3E-3 2.3E-3 9.8E-4 1.9E-3 Mean 60.54 57.56 55.82 51.64 56.83 46.19 43.08 40.27 39.87 41.56 30 std (9.90) (0.26) (1.13) (4.21) (6.57) (0.54) (2.86) (3.41) (4.12) (3.49) p-value - 8.3E-1 5.3E-1 5.6E-2 6.6E-1 - 5.8E-1 4.1E-1 8.6E-2 2.9E-1 Mean 68.49 62.12 63.77 60.16 62.57 55.46 48.51 44.21 39.48 41.67 40 std (1.28) (5.29) (6.84) (3.46) (4.57) (6.09) (1.93) (1.53) (4.85) (3.34) p-value - 5.6E-1 6.8E-1 4.9E-1 1.4E-1 - 4.6E-2 (+) 5.3E-3 (+) 2.1E-4 (+) 9.4E-3 (+) Mean 75.75 66.30 67.38 67.22 64.14 65.23 53.60 54.69 55.21 53.96 50 std (4.58) (8.38) (7.52) (7.31) (5.63) (2.58) (6.82) (7.39) (4.61) (9.42) p-value - 6.1E-2 7.6E-1 4.9E-1 2.0E-1 - 3.8E-2 (+) 4.2E-2 (+) 1.6E-2 (+) 6.4E-3 (+)
下载: 导出CSV
表 9 glass数据集的聚类结果对比
Table 9 Performance comparison on glass dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 31.02 31.02 31.02 28.66 27.14 31.66 31.66 31.66 28.51 30.69 0 std (0) (0) (0) (2.80) (3.74) (0) (0) (0) (1.90) (2.45) p-value - - - 2.63E-1 1.77E-1 - - - 2.1E-1 2.6E-1 Mean 37.24 35.85 35.62 31.89 33.57 38.00 38.00 37.15 35.46 34.76 10 std (8.90) (3.17) (4.66) (5.78) (9.51) (8.08) (2.78) (3.64) (5.21) (4.23) p-value - 6.0E-1 3.4E-1 1.9E-1 2.4E-1 - 8.4E-1 5.6E-1 3.6E-1 3.1E-1 Mean 40.98 37.80 35.70 36.44 37.15 42.66 35.33 34.36 31.93 32.19 20 std (0.06) (0.02) (0.08) (1.62) (3.48) (9.57) (7.26) (6.19) (8.42) (2.96) p-value - 1.1E-1 6.4E-2 8.3E-2 4.8E-1 - 5.4E-2 4.9E-2 (+) 2.5E-2 (+) 3.4E-2 (+) Mean 46.05 43.32 44.22 40.35 45.11 70.87 54.52 55.21 52.94 57.14 30 std (0.15) (3.21) (3.90) (5.44) (7.16) (1.50) (6.36) (4.83) (8.91) (7.88) p-value - 2.9E-1 5.2E-1 9.7E-2 4.5E-1 - 4.6E-2 (+) 2.0E-2 (+) 9.4E-3 (+) 5.6E-2 Mean 53.23 47.71 46.25 42.18 47.84 80.06 61.06 64.37 59.81 60.56 40 std (1.46) (5.89) (4.77) (4.65) (7.21) (5.00) (7.27) (8.36) (7.24) (4.98) p-value - 1.8E-1 1.3E-1 7.6E-2 5.5E-1 - 5.7E-2 1.7E-1 8.7E-3 (+) 7.68E-2 Mean 54.67 50.70 51.28 49.57 51.14 79.63 64.02 61.44 62.37 59.87 50 std (7.43) (4.98) (6.40) (7.15) (8.44) (8.83) (5.42) (6.48) (7.21) (9.18) p-value - 1.6E-1 3.6E-1 7.4E-2 6.1E-1 - 5.0E-2 (+) 4.4E-2 (+) 4.5E-2 (+) 6.9E-3 (+)
下载: 导出CSV
表 10 wine数据集的聚类结果对比
Table 10 Performance comparison on wine dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 60.21 60.21 60.21 54.39 57.82 70.54 70.54 70.54 64.87 61.49 0 std (0) (0) (0) (5.67) (4.10) (0) (0) (0) (5.10) (6.54) p-value - - - 2.9E-1 4.6E-1 - - - 1.3E-1 9.3E-2 Mean 79.16 68.98 69.33 65.47 67.26 84.94 72.36 73.66 75.19 70.58 10 std (5.450) (3.82) (5.44) (8.21) (4.94) (8.35) (5.26) (5.87) (4.24) (6.29) p-value - 6.3E-3 (+) 9.2E-4 (+) 6.1E-3 (+) 8.1E-2 (+) - 4.7E-2 (+) 4.9E-2 (+) 6.7E-2 8.1E-3 (+) Mean 81.36 71.82 69.88 68.15 60.47 84.83 73.88 71.20 69.64 65.88 20 std (3.65) (5.49) (5.40) (8.14) (6.47) (8.22) (4.55) (6.88) (7.52) (10.37) p-value - 7.4E-2 4.8E-2 1.3E-1 9.1E-2 - 1.5E-1 8.3E-2 7.2E-2 4.3E-2 (+) Mean 84.78 83.27 80.31 81.55 82.41 92.06 89.40 85.94 90.31 88.49 30 std (2.93) (5.21) (6.40) (3.70) (7.52) (1.68) (6.34) (5.80) (1.23) (3.54) p-value - 1.8E-1 1.1E-1 3.4E-1 4.4E-1 - 1.7E-1 8.3E-2 4.6E-1 9.7E-2 Mean 90.22 84.24 80.64 81.47 72.63 95.06 89.66 88.33 90.27 87.92 40 std (2.81) (3.51) (4.36) (1.42) (0.99) (1.51) (5.82) (6.42) (8.66) (9.11) p-value - 4.0E-2 (+) 2.2E-3 (+) 3.6E-2 (+) 9.4E-3 (+) - 1.3E-1 8.4E-2 5.2E-2 4.3E-2 (+) Mean 89.76 86.68 85.85 80.74 81.69 88.82 85.74 85.63 84.22 80.75 50 std (1.99) (4.99) (6.41) (6.28) (7.11) (2.62) (7.53) (8.90) (7.24) (9.11) p-value - 2.7E-1 2.0E-1 5.7E-2 3.3E-1 - 2.7E-1 1.1E-1 3.4E-1 2.1E-1
下载: 导出CSV
表 11 wdbc数据集的聚类结果对比
Table 11 Performance comparison on wdbc dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 52.31 52.31 52.31 48.42 47.49 55.74 55.74 55.74 51.78 52.69 0 std (0) (0) (0) (1.10) (1.67) (0) (0) (0) (0.62) (0.37) p-value - - - 4.5E-2 (+) 3.1E-2 (+) - - - 4.8E-2 (+) 5.7E-2 Mean 66.35 50.72 48.39 51.46 49.21 61.39 47.80 47.92 44.91 51.68 10 std (13.38) (1.42) (2.82) (2.6) (5.06) (11.73) (3.50) (6.41) (17.46) (14.25) p-value - 1.5E-1 9.2E-2 3.4E-1 1.1E-1 - 1.2E-1 2.4E-1 4.2E-1 2.9E-1 Mean 74.27 66.58 67.24 64.21 60.37 72.16 61.16 60.58 57.26 59.34 20 std (13.78) (14.87) (11.35) (15.87) (9.58) (14.45) (17.51) (15.68) (11.34) (8.48) p-value - 5.0E-1 6.2E-1 9.8E-2 4.1E-1 - 4.1E-1 5.4E-1 1.2E-1 2.6E-1 Mean 85.90 59.10 58.22 57.31 56.74 84.23 52.42 50.72 48.64 51.77 30 std (0. 86) (17.4) (20.55) (8.27) (4.90) (1.26) (4.28) (5.60) (4.89) (2.77) p-value - 9.0E-03 (+) 2.5E-2 (+) 5.1E-3 (+) 6.4E-3 (+) - 7.4E-04 (+) 5.6E-5 (+) 4.9E-6 (+) 1.8E-7 (+) Mean 88.09 71.83 71.27 69.58 64.96 87.39 70.61 71.33 64.99 68.41 40 std (1.35) (8.86) (7.89) (10.54) (9.73) (3.0) (8.14) (6.64) (10.37) (12.85) p-value - 4.70E-2 (+) 2.8E-2 (+) 4.2E-3 (+) 7.7E-3 (+) - 5.3E-2 5.1E-2 4.8E-3 (+) 2.5E-2 (+) Mean 87.53 84.82 84.32 81.62 82.44 88.32 84.74 80.16 75.32 72.19 50 std (7.18) (9.02) (10.33) (8.27) (9.11) (7.80) (9.83) (8.12) (10.77) (11.65) p-value - 4.8E-2 (+) 3.4E-2 (+) 8.9E-3 (+) 7.7E-3 (+) - 4.1E-2 (+) 2.2E-2 (+) 3.6E-2 (+) 1.8E-2 (+)
下载: 导出CSV
-
[1] Frey B J, Dueck D. Clustering by passing messages between data points. Science, 2007, 315(5814):972-976 doi: 10.1126/science.1136800 [2] 许晓丽, 卢志茂, 张格森, 李纯, 张琦.改进近邻传播聚类的彩色图像分割.计算机辅助设计与图形学学报, 2012, 24(4):514-519 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201204015.htmXu Xiao-Li, Lu Zhi-Mao, Zhang Ge-Sen, Li Chun, Zhang Qi. Color image segmentation based on improved affinity propagation clustering. Journal of Computer-Aided Design & Computer Graphics, 2012, 24(4):514-519 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201204015.htm [3] Borile C, Labarre M, Franz S, Sola C, Refrégier G. Using affinity propagation for identifying subspecies among clonal organisms:lessons from M. tuberculosis. BMC Bioinformatics, 2011, 12:224 doi: 10.1186/1471-2105-12-224 [4] 储岳中, 徐波, 高有涛, 邰伟鹏.基于近邻传播聚类与核匹配追踪的遥感图像目标识别方法.电子与信息学报, 2014, 36(12):2923-2928 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201412021.htmChu Yue-Zhong, Xu Bo, Gao You-Tao, Tai Wei-Peng. Technique of remote sensing image target recognition based on affinity propagation and kernel matching pursuit. Journal of Electronics and Information Technology, 2014, 36(12):2923-2928 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201412021.htm [5] 王开军, 张军英, 李丹, 张新娜, 郭涛.自适应仿射传播聚类.自动化学报, 2007, 33(12):1242-1246 http://www.aas.net.cn/CN/abstract/abstract15756.shtmlWang Kai-Jun, Zhang Jun-Ying, Li Dan, Zhang Xin-Na, Guo Tao. Adaptive affinity propagation clustering. Acta Automatica Sinica, 2007, 33(12):1242-1246 http://www.aas.net.cn/CN/abstract/abstract15756.shtml [6] 刘建伟, 刘媛, 罗雄麟.半监督学习方法.计算机学报, 2015, 38(8):1592-1617Liu Jian-Wei, Liu Yuan, Luo Xiong-Lin. Semi-supervised learning methods. Chinese Journal of Computers, 2015, 38(8):1592-1617 [7] Bijral A S, Ratliff N, Srebro N. Semi-supervised learning with density based distances.[Online], available:http://ttic.uchicago.edu/~nati/Publications/SemiSupDBD.pdf, October 10, 2014 [8] Wagstaff K, Cardie C. Clustering with instance-level constraints. In:Proceedings of the 17th International Conference on Machine Learning (ICML2000). Stanford:Morgan Kaufmann Publishers, 2000. 1103-1110 [9] 肖宇, 于剑.基于近邻传播算法的半监督聚类.软件学报, 2008, 19(11):2803-2813 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200811005.htmXiao Yu, Yu Jian. Semi-supervised clustering based on affinity propagation algorithm. Journal of Software, 2008, 19(11):2803-2813 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200811005.htm [10] 张震, 汪斌强, 伊鹏, 兰巨龙.一种分层组合的半监督近邻传播聚类算法.电子与信息学报, 2013, 35(3):645-651 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201303020.htmZhang Zhen, Wang Bin-Qiang, Yi Peng, Lan Ju-Long. Semi-supervised affinity propagation clustering algorithm based on stratified combination. Journal of Electronics and Information Technology, 2013, 35(3):645-651 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201303020.htm [11] 张建朋, 陈福才, 李邵梅, 刘力雄.基于密度与近邻传播的数据流聚类算法.自动化学报, 2014, 40(2):277-288 http://www.aas.net.cn/CN/abstract/abstract16309.shtmlZhang Jian-Peng, Chen Fu-Cai, Li Shao-Mei, Liu Li-Xiong. Data stream clustering algorithm based on density and affinity propagation techniques. Acta Automatica Sinica, 2014, 40(2):277-288 http://www.aas.net.cn/CN/abstract/abstract16309.shtml [12] Givoni I E, Frey B J. Semi-supervised affinity propagation with instance-level constraints. In:Proceedings of the 12th International Conference on Artificial Intelligence and Statistics (AISTATS). Clearwater Beach, Florida, USA:JMLR W & CP5, 2009. 161-168 [13] 赵宪佳, 王立宏.近邻传播半监督聚类算法的分析与改进.计算机工程与应用, 2010, 46(36):168-170 http://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201036047.htmZhao Xian-Jia, Wang Li-Hong. Analysis and improvement of semi-supervised clustering algorithm based on affinity propagation. Computer Engineering and Applications, 2010, 46(36):168-170 http://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201036047.htm [14] Wagstaff K, Cadrie C, Rogers S, Schroedl S. Constrained K-means clustering with background knowledge. In:Proceedings of the 18th International Conference on Machine Learning (ICML2001). Williamstown:Morgan Kaufmann Publishers, 2001. 577-584 [15] 尹学松, 胡恩良, 陈松灿.基于成对约束的判别型半监督聚类分析.软件学报, 2008, 19(11):2791-2802 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200811004.htmYin Xue-Song, Hu En-Liang, Chen Song-Can. Discriminative semi-supervised clustering analysis with pairwise constraints. Journal of Software, 2008, 19(11):2791-2802 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200811004.htm [16] Kschischang F R, Frey B J, Loeliger H A. Factor graphs and the sum-product algorithm. IEEE Transactions on Information Theory, 2001, 47(2):498-519 doi: 10.1109/18.910572 [17] Weiss Y, Freeman W T. On the optimality of solutions of the max-product belief-propagation algorithm in arbitrary graphs. IEEE Transactions on Information Theory, 2001, 47(2):736-744 doi: 10.1109/18.910585 [18] Givoni I E, Frey B J. A binary variable model for affinity propagation. Neural Computation, 2009, 21(6):1589-1600 doi: 10.1162/neco.2009.05-08-785 -


 下载:
下载:


计量
- 文章访问数: 2573
- HTML全文浏览量: 260
- PDF下载量: 968
- 被引次数: 0
