

A Semi-supervised Affinity Propagation Clustering Method with Homogeneity Constraint
-
摘要: 以近邻反射传播 (Affinity propagation, AP) 聚类算法为基础, 提出了一种基于同类约束的半监督近邻反射传播聚类方法 (Semi-supervised affinity propagation clustering method with homogeneity constraints, HCSAP).该方法在聚类目标函数中引入同类约束项, 以保证聚类结果与同类集先验信息一致.利用最大和信任传播 (Max-sum belief propagation) 优化过程对目标函数进行求解, 导出同类约束下的吸引度 (Responsibility) 和归属度 (Availability) 的迭代方程.人工数据集和真实数据集上的实验结果表明本文所提方法的有效性.Abstract: In this paper, a semi-supervised affinity propagation (AP) clustering algorithm with homogeneity constraint, called HCSAP (semi-supervised affinity propagation clustering method with homogeneity constraints), is proposed. To keep consistency between the clustering results and the priori information about homogeneity sets, the constraint terms are introduced to the objection function of algorithm AP. With the max-sum belief propagation procedure, the objection function can be resolved into the corresponding responsibility and availability update equations. Experiments on synthetic dataset and real-world datasets indicate the effectiveness of the proposed HCSAP.
-
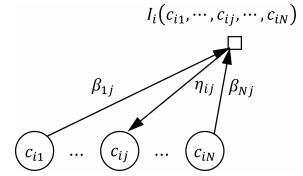
图 3 $\eta_{ij}$ 与其相关信息关系图
Fig. 3 Relationship among $\eta_{ij}$ and its correlative message
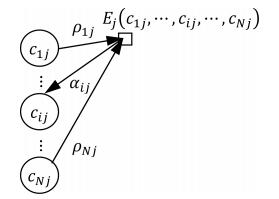
图 4 $\alpha_{ij}$ 与其相关信息关系图
Fig. 4 Relationship among $\alpha_{ij}$ and its correlative message
表 1 部分符号说明
Table 1 The explanation of some symbol
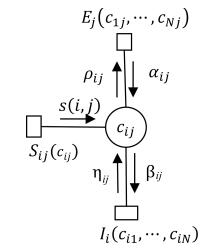
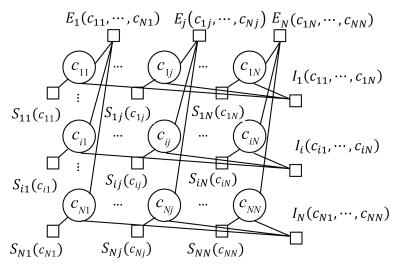
符号 意义 $N$ 聚类数据点个数 $M$ 同类集个数 $h_1,h_2$ 数据点 $h_1,h_2$ $c_{ij}$ 变量节点, 为0表示 $j$ 不是 $i$ 的类中心点; 为1表示 $j$ 是 $i$ 的类中心点 $E_{ij}(\cdot)$ $E_j(c_{1j},\cdots,c_{Nj})$ 数据点 $j$ 的同类约束与一致性约束函数 $\rho_{ij}$ 表示变量节点 $c_{ij}$ 向函数节点 $E_j$ 所发送的标量信息 $c_i$ 数据点 $i$ 的类中心点 $P$ 全体同类集所构成的集合 $p^i$ 数据点 $i$ 所在的同类约束集 $I_i(\cdot)$ $I_i(c_{i1},\cdots,c_{iN})$ 为数据点 $i$ 的唯一性约束函数 $\alpha_{ij}$ 表示函数节点 $E_j$ 向变量节点 $ c_{ij}$ 所发送的标量信息 $\beta_{ij}$ 表示变量节点 $c_{ij}$ 向函数节点 $I_i$ 所发送的标量信息 $p_v$ 第 $v$ 个同类集 ⊕ 异或 ${{\bar P}}$ 无同类约束的数据点集 $S_{ij}(\cdot)$ 定义在数据点 $i$ , $j$ 之间的相似度函数 $s(i,j)$ 数据点 $i$ , $j$ 之间的相似度 $\eta_{ij}$ 表示函数节点 $I_i$ 向变量节点 $c_{ij}$ 所发送的标量信息  下载: 导出CSV
下载: 导出CSV
表 2 人工数据上的聚类结果参数对比
Table 2 Performance comparison on man-made dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 72.12 72.12 72.12 70.31 69.3 56.50 56.50 56.50 53.43 55.0 0 std (0) (0) (0) (1.3) (3.6) (0) (0) (0) (1.1) (2.1) p-value - - - 4.2E-3 6.6E-3 - - - 1.8E-1 3.4E-1 Mean 87.24 82.74 80.22 85.27 81.66 80.47 72.41 70.50 77.39 75.4 10 std (6.6) (4.7) (0.8) (5.2) (9.2) (1.7) (1.1) (2.4) (2.1) (3.7) p-value - 3.1E-2 (+) 2.2E-5 (+) 9.7E-2 6.3E-3 (+) - 3.9E-2 (+) 4.1E-5 (+) 6.4E-2 6.8E-2 Mean 96.15 80.45 81.78 90.00 88.6 95.75 72.57 73.66 90.41 76.8 20 std (1.0) (1.6) (1.8) (4.1) (4.5) (4.0) (1.6) (2.7) (0.5) (1.4) p-value - 9.4E-4 (+) 7.8E-5 (+) 9.2E-3 (+) 9.2E-3 (+) - 1.7E-7 (+) 2.3E-6 (+) 1.4E-2 (+) 7.5E-6 (+) Mean 96.24 91.24 92.47 90.36 91.33 97.58 89.00 85.74 90.06 89.6 30 std (2.0) (4.1) (5.1) (0.8) (1.6) (0.2) (6.6) (4.1) (0.2) (2.8) p-value - 4.9E-2 (+) 5.1E-2 8.4E-3 (+) 7.4E-3 (+) - 3.4E-3 (+) 9.5E-8 (+) 1.6E-2 (+) 4.7E-4 (+) Mean 96.66 88.57 87.98 90.21 89.2 97.35 88.65 86.97 90.33 90.5 40 std (1.3) (3.0) (2.7) (0.2) (4.5) (2.0) (1.2) (0.9) (0.5) (7.7) p-value - 5.7E-3 (+) 1.1E-3 (+) 6.6E-3 (+) 3.9E-3 (+) - 1.1E-4 (+) 2.4E-7 (+) 1.8E-2 (+) 7.1E-3 (+) Mean 98.05 90.34 88.84 90.70 90.8 98.25 89.65 90.45 88.87 90.0 50 std (0.2) (7.1) (1.4) (0.6) (2.3) (0.2) (2.8) (9.6) (0.7) (3.4) p-value - 5.1E-2 7.2E-4 (+) 9.0E-5 (+) 1.4E-4 (+) - 42E-4 (+) 3.7E-7 (+) 8.4E-3 (+) 6.7E-3 (+) 注:表中p-value为5 %显著性水平下的 $t$ 检验值, "+"表示HCSAP在5 %显著性水平下优于对比聚类算法."-"表示在5 %显著性水平下HCSAP劣于对比聚类算法.粗体字表示对比较优者 (下同).
下载: 导出CSV
表 3 实验数据集
Table 3 Dataset used in experiment
Item Number of instance Dimension Class Preference Optdigit 1 797 64 10 $1\times Mid$ Iris 150 4 3 $3\times Mid$ Ionosphere 351 34 2 $10\times Mid$ Letter recogni- 2 241 16 3 $1\times Mid$ tion {I, J, L} Pendigits 3 498 16 10 $1\times Mid$ glass 214 9 6 $5\times Mid$ wine 178 13 3 $5\times Mid$ wdbc 768 8 2 $50\times Mid$
下载: 导出CSV
表 4 Optdigit数据集上的聚类结果对比
Table 4 Performance comparison on Optdigit dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 22.35 22.35 22.35 19.14 20.61 12.57 12.57 12.57 10.68 11.46 0 std (0) (0) (0) (1.25) (3.87) (0) (0) (0) (1.6) (0.9) p-value - - - 4.3E-3 4.9E-2 - - - 4.1E-2 (+) 4.8E-2 Mean 31.86 30.03 29.30 27.98 30.41 18.97 17.75 15.34 14.68 16.35 10 std (4.69) (1.30) (2.47) (1.50) (4.94) (5.02) (5.92) (6.1) (5.7) (2.2) p-value - 3.1E-1 3.3E-1 2.6E-1 5.1E-1 - 2.7E-1 6.1E-1 1.4E-1 9.9E-2 Mean 42.57 43.15 44.63 40.55 41.55 27.10 27.71 27.96 27.30 24.63 20 std (7.4) (8.01) (6.91) (7.65) (9.52) (9.00) (3.36) (4.86) (7.96) (8.14) p-value - 2.2E-1 6.6E-1 1.0E-1 2.9E-1 - 5.7E-1 6.7E-1 4.3E-1 7.4E-2) Mean 54.41 52.5 51.23 49.87 52.44 36.61 35.78 34.79 30.76 31.87 30 std (9.02) (2.01) (4.31) (2.44) (3.75) (2.67) (0.79) (6.6) (8.2) (7.8) p-value - 2.6E-1 1.7E-1 4.6E-2 (+) 5.7E-1 - 4.3E-1 8.7E-2 4.4E-2 (+) 2.5E-2 (+) Mean 62.67 61.35 61.22 59.57 61.24 45.85 44.46 45.20 41.85 40.27 40 std (2.39) (1.71) (1.6) (4.21) (8.34) (0.86) (3.12) (4.20) (7.14) (9.48) p-value - 4.0E-1 4.3E-1 2.9E-1 1.6E-1 - 1.7E-1 2.7E-1 7.7E-2 2.1E-2 (+) Mean 71.75 68.84 68.8 69.54 69.33 56.09 52.69 51.27 48.62 50.11 50 std (9.58) (6.32) (9.96) (8.47) (10.20) (2.45) (4.79) (2.70) (5.47) (5.50) p-value - 2.4E-1 2.4E-11 8.1E-2 9.8E-2 - 1.4E-2 (+) 1.1E-1 2.5E-3 (+) 5.8E-2
下载: 导出CSV
表 5 Iris数据集的聚类结果对比
Table 5 Performance comparison on Iris dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 61.87 61.87 61.87 56.27 55.38 55.33 55.33 55.33 52.61 53.70 0 std (0) (0) (0) (3.1) (3.6) (0) (0) (0) (2.30) (4.81) p-value - - - 1.4E-2 2.2E-2 - - - 1.6E-1 4.8E-1 Mean 73.36 72.93 72.55 71.84 69.57 75.60 56.53 55.22 60.77 58.45 10 std (2.69) (0.93) (1.21) (6.40) (3.72) (5.3) (0.87) (4.11) (2.57) (12.72) p-value - 1.5E-4 (+) 1.3E-4 (+) 5.3E-4 (+) 2.2E-4 (+) - 1.3E-3 (+) 1.4E-3 (+) 5.6E-3 (+) 4.2E-2 (+) Mean 79.04 79.78 76.99 81.21 74.31 75.33 69.11 66.22 64.21 70.40 20 std (3.22) (8.02) (5.90) (8.3) (6.61) (7.33) (12.10) (18.9) (14.1) (11.23) p-value - 2.8E-1 1.4E-1 8.2E-1 5.4E-3 - 2.7E-1 2.3E-1 5.4E-1 9.1E-1 Mean 88.46 80.33 81.24 80.74 75.33 81.33 72.22 71.25 72.11 69.44 30 std (1.75) (9.15) (9.47) (4.4) (10.1) (2.91) (12.15) (11.41) (13.15) (10.9) p-value - 2.1E-1 3.4E-1 1.1E-2 1.2E-2 - 2.3E-1 2.0E-1 2.8E-1 1.1E-1 Mean 94.72 89.62 88.25 85.74 84.27 92.93 84.40 84.00 81.23 83.78 40 std (3.64) (3.79) (4.8) (5.9) (5.6) (5.77) (6.95) (8.3) (7.9) (9.1) p-value - 1.5E-1 4.6E-2 (+) 4.9E-1 5.9E-1 - 1.7E-1 1.1E-1 1.4E-1 2.4E-1 Mean 94.43 92.38 93.50 90.22 89.01 94.44 88.22 87.20 86.33 90.01 50 std (0.39) (1.39) (2.0) (7.1) (5.1) (0.03) (5.00) (6.89) (6.12) (10.88) p-value - 1.0E-1 1.7E-1 5.5E-1 6.4E-1 - 1.5E-1 1.2E-1 2.7E-1 1.4E-1
下载: 导出CSV
表 6 Ionosphere数据集上的聚类结果对比
Table 6 Performance comparison on Ionosphere dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 51.96 51.96 51.96 45.89 46.31 40.35 40.35 40.35 43.48 41.25 0 std (0) (0) (0) (5.2) (3.4) (0) (0) (0) (2.50) (1.31) p-value - - - 7.3E-1 6.9E-1 - 4.4E-1 5.2E-1 1.3E-1 2.3E-1 Mean 55.24 56.74 57.30 58.21 54.21 58.21 59.38 57.66 55.24 58.00 10 std (2.45) (7.87) (1.2) (7.2) (3.6) (7.32) (2.78) (7.27) (6.17) (5.48) p-value - 3.5E-2 (-) 4.8E-2 (-) 5.4E-1 7.9E-1 - 8.2E-1 6.3E-1 5.2E-1 4.5E-1 Mean 56.45 61.13 60.34 54.29 55.12 63.41 64.12 64.30 62.34 61.25 20 std (1.97) (2.36) (1.90) (4.87) (3.57) (5.79) (3.18) (5.54) (7.53) (4.74) p-value - 5.40E-3 (-) 3.47E-2 (-) 4.4E-1 5.1E-1 - 2.8E-1 3.5E-1 6.4E-1 4.1E-1 Mean 66.61 61.16 65.14 57.02 59.54 63.74 67.20 61.42 61.28 60.11 30 std (3.25) (5.47) (3.32) (5.42) (4.14) (5.20) (1.44) (8.54) (3.15) (7.21) p-value - 2.8E-1 4.2E-1 3.3E-1 2.4E-1 - 1.9E-1 2.9E-1 1.6E-1 1.7E-1 Mean 67.61 71.68 68.50 64.71 69.87 62.66 64.04 57.99 60.34 61.23 40 std (4.23) (3.03) (1.20) (4.56) (1.57) (8.17) (7.24) (4.8) (1.36) (5.4) p-value - 2.4E-2 (-) 3.7E-2 (-) 1.7E-1 5.6E-1 - 2.5E-1 3.6E-1 2.2E-1 1.4E-1 Mean 84.16 83.17 80.26 80.66 84.78 72.53 71.33 72.55 70.21 69.88 50 std (6.12) (4.87) (2.80) (2.69) (4.31) (5.60) (7.53) (5.33) (2.42) (4.69) p-value - 3.6E-1 3.4E-1 4.7E-1 2.1E-1 - 1.9E-1 3.9E-1 2.2E-1 1.0E-1
下载: 导出CSV
表 7 Letter-recognition {I, J, L}上的聚类结果对比
Table 7 Performance comparison on Letter-recognition dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 49.87 49.87 49.87 41.30 42.33 33.33 33.33 33.33 31.54 30.36 0 std (0) (0) (0) (1.9) (4.1) (0) (0) (0) (2.5) (3.1) p-value - - - 5.7E-2 6.9E-2 - - - 1.7E-1 1.0E-1 Mean 54.42 55.01 54.36 55.11 57.21 39.00 38.10 40.23 39.98 40.05 10 std (8.90) (2.63) (5.7) (6.4) (3.89) (8.08) (2.78) (1.4) (2.0) (3.7) p-value - 6.2E-1 2.1E-1 4.8E-1 1.2E-1 - 2.3E-1 5.6E-1 7.4E-1 6.1E-1 Mean 59.47 52.01 51.69 57.20 55.31 42.66 35.33 34.88 37.90 35.87 20 std (1.92) (5.73) (4.8) (6.8) (5.0) (9.57) (7.26) (5.8) (3.2) (2.8) p-value - 4.2E-2 (+) 3.2E-2 (+) 1.1E-1 3.1E-1 - 4.9E-2 2.3E-2 4.7E-2 2.6E-2 Mean 67.90 65.36 66.30 64.87 60.45 52.66 50.00 49.68 50.33 51.74 30 std (0.41) (6.44) (3.2) (5.6) (4.9) (1.84) (1.54) (1.74) (2.53) (3.40) p-value - 2.6E-1 3.0E-1 1.7E-1 2.6E-1 - 2.3E-1 1.2E-1 2.9E-1 5.4E-1 Mean 77.05 72.97 73.33 71.4 70.24 64.66 60.00 59.40 58.67 51.77 40 std (2.00) (4.43) (1.5) (2.6) (2.4) (8.17) (4.26) (7.26) (8.11) (14.25) p-value - 3.3E-1 4.2E-1 1.1E-1 1.5E-1 - 3.4E-1 2.9E-1 4.1E-1 5.3E-1 Mean 84.16 83.17 84.12 83.00 81.47 73.33 71.33 70.11 68.25 67.49 50 std (4.55) (7.41) (5.4) (4.9) (4.4) (2.62) (7.53) (5.1) (7.6) (5.3) p-value - 4.9E-1 5.0E-1 2.3E-1 2.3E-1 - 3.3E-1 2.8E-1 1.0E-1 4.4E-2 (+)
下载: 导出CSV
表 8 Pendigits数据集的聚类结果对比
Table 8 Performance comparison on Pendigits dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 19.23 19.23 19.23 17.21 16.32 11.20 11.20 11.20 9.79 9.64 0 std (0) (0) (0) (1.42) (2.51) (0) (0) (0) (0.25) (0.36) p-value - - - 9.4E-3 (+) 2.8E-3 (+) - - - 3.9E-2 (+) 2.8E-2 (+) Mean 27.40 23.17 24.65 24.68 21.97 16.72 13.75 12.99 13.58 11.95 10 std (1.38) (8.62) (7.64) (9.17) (4.11) (5.03) (3.15) (2.87) (2.77) (1.44) p-value - 2.3E-1 5.6E-2 2.8E-1 5.8E-2 - 4.1E-1 9.6E-2 6.7E-1 6.1E-1 Mean 38.66 35.19 34.67 33.74 34.21 36.14 25.58 24.71 21.95 27.64 20 std (0.88) (3.67) (4.25) (5.50) (6.67) (3.13) (8.79) (3.34) (5.61) (4.13) p-value - 5.6E-1 2.4E-1 2.7E-1 3.1E-1 - 8.3E-3 2.3E-3 9.8E-4 1.9E-3 Mean 60.54 57.56 55.82 51.64 56.83 46.19 43.08 40.27 39.87 41.56 30 std (9.90) (0.26) (1.13) (4.21) (6.57) (0.54) (2.86) (3.41) (4.12) (3.49) p-value - 8.3E-1 5.3E-1 5.6E-2 6.6E-1 - 5.8E-1 4.1E-1 8.6E-2 2.9E-1 Mean 68.49 62.12 63.77 60.16 62.57 55.46 48.51 44.21 39.48 41.67 40 std (1.28) (5.29) (6.84) (3.46) (4.57) (6.09) (1.93) (1.53) (4.85) (3.34) p-value - 5.6E-1 6.8E-1 4.9E-1 1.4E-1 - 4.6E-2 (+) 5.3E-3 (+) 2.1E-4 (+) 9.4E-3 (+) Mean 75.75 66.30 67.38 67.22 64.14 65.23 53.60 54.69 55.21 53.96 50 std (4.58) (8.38) (7.52) (7.31) (5.63) (2.58) (6.82) (7.39) (4.61) (9.42) p-value - 6.1E-2 7.6E-1 4.9E-1 2.0E-1 - 3.8E-2 (+) 4.2E-2 (+) 1.6E-2 (+) 6.4E-3 (+)
下载: 导出CSV
表 9 glass数据集的聚类结果对比
Table 9 Performance comparison on glass dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 31.02 31.02 31.02 28.66 27.14 31.66 31.66 31.66 28.51 30.69 0 std (0) (0) (0) (2.80) (3.74) (0) (0) (0) (1.90) (2.45) p-value - - - 2.63E-1 1.77E-1 - - - 2.1E-1 2.6E-1 Mean 37.24 35.85 35.62 31.89 33.57 38.00 38.00 37.15 35.46 34.76 10 std (8.90) (3.17) (4.66) (5.78) (9.51) (8.08) (2.78) (3.64) (5.21) (4.23) p-value - 6.0E-1 3.4E-1 1.9E-1 2.4E-1 - 8.4E-1 5.6E-1 3.6E-1 3.1E-1 Mean 40.98 37.80 35.70 36.44 37.15 42.66 35.33 34.36 31.93 32.19 20 std (0.06) (0.02) (0.08) (1.62) (3.48) (9.57) (7.26) (6.19) (8.42) (2.96) p-value - 1.1E-1 6.4E-2 8.3E-2 4.8E-1 - 5.4E-2 4.9E-2 (+) 2.5E-2 (+) 3.4E-2 (+) Mean 46.05 43.32 44.22 40.35 45.11 70.87 54.52 55.21 52.94 57.14 30 std (0.15) (3.21) (3.90) (5.44) (7.16) (1.50) (6.36) (4.83) (8.91) (7.88) p-value - 2.9E-1 5.2E-1 9.7E-2 4.5E-1 - 4.6E-2 (+) 2.0E-2 (+) 9.4E-3 (+) 5.6E-2 Mean 53.23 47.71 46.25 42.18 47.84 80.06 61.06 64.37 59.81 60.56 40 std (1.46) (5.89) (4.77) (4.65) (7.21) (5.00) (7.27) (8.36) (7.24) (4.98) p-value - 1.8E-1 1.3E-1 7.6E-2 5.5E-1 - 5.7E-2 1.7E-1 8.7E-3 (+) 7.68E-2 Mean 54.67 50.70 51.28 49.57 51.14 79.63 64.02 61.44 62.37 59.87 50 std (7.43) (4.98) (6.40) (7.15) (8.44) (8.83) (5.42) (6.48) (7.21) (9.18) p-value - 1.6E-1 3.6E-1 7.4E-2 6.1E-1 - 5.0E-2 (+) 4.4E-2 (+) 4.5E-2 (+) 6.9E-3 (+)
下载: 导出CSV
表 10 wine数据集的聚类结果对比
Table 10 Performance comparison on wine dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 60.21 60.21 60.21 54.39 57.82 70.54 70.54 70.54 64.87 61.49 0 std (0) (0) (0) (5.67) (4.10) (0) (0) (0) (5.10) (6.54) p-value - - - 2.9E-1 4.6E-1 - - - 1.3E-1 9.3E-2 Mean 79.16 68.98 69.33 65.47 67.26 84.94 72.36 73.66 75.19 70.58 10 std (5.450) (3.82) (5.44) (8.21) (4.94) (8.35) (5.26) (5.87) (4.24) (6.29) p-value - 6.3E-3 (+) 9.2E-4 (+) 6.1E-3 (+) 8.1E-2 (+) - 4.7E-2 (+) 4.9E-2 (+) 6.7E-2 8.1E-3 (+) Mean 81.36 71.82 69.88 68.15 60.47 84.83 73.88 71.20 69.64 65.88 20 std (3.65) (5.49) (5.40) (8.14) (6.47) (8.22) (4.55) (6.88) (7.52) (10.37) p-value - 7.4E-2 4.8E-2 1.3E-1 9.1E-2 - 1.5E-1 8.3E-2 7.2E-2 4.3E-2 (+) Mean 84.78 83.27 80.31 81.55 82.41 92.06 89.40 85.94 90.31 88.49 30 std (2.93) (5.21) (6.40) (3.70) (7.52) (1.68) (6.34) (5.80) (1.23) (3.54) p-value - 1.8E-1 1.1E-1 3.4E-1 4.4E-1 - 1.7E-1 8.3E-2 4.6E-1 9.7E-2 Mean 90.22 84.24 80.64 81.47 72.63 95.06 89.66 88.33 90.27 87.92 40 std (2.81) (3.51) (4.36) (1.42) (0.99) (1.51) (5.82) (6.42) (8.66) (9.11) p-value - 4.0E-2 (+) 2.2E-3 (+) 3.6E-2 (+) 9.4E-3 (+) - 1.3E-1 8.4E-2 5.2E-2 4.3E-2 (+) Mean 89.76 86.68 85.85 80.74 81.69 88.82 85.74 85.63 84.22 80.75 50 std (1.99) (4.99) (6.41) (6.28) (7.11) (2.62) (7.53) (8.90) (7.24) (9.11) p-value - 2.7E-1 2.0E-1 5.7E-2 3.3E-1 - 2.7E-1 1.1E-1 3.4E-1 2.1E-1
下载: 导出CSV
表 11 wdbc数据集的聚类结果对比
Table 11 Performance comparison on wdbc dataset
Sample rate Item F-measure (%) Pure (%) (%) HCSAP SAP SSAP MPCK-MEAN DSCA HCSAP SAP SSAP MPCK-MEAN DSCA Mean 52.31 52.31 52.31 48.42 47.49 55.74 55.74 55.74 51.78 52.69 0 std (0) (0) (0) (1.10) (1.67) (0) (0) (0) (0.62) (0.37) p-value - - - 4.5E-2 (+) 3.1E-2 (+) - - - 4.8E-2 (+) 5.7E-2 Mean 66.35 50.72 48.39 51.46 49.21 61.39 47.80 47.92 44.91 51.68 10 std (13.38) (1.42) (2.82) (2.6) (5.06) (11.73) (3.50) (6.41) (17.46) (14.25) p-value - 1.5E-1 9.2E-2 3.4E-1 1.1E-1 - 1.2E-1 2.4E-1 4.2E-1 2.9E-1 Mean 74.27 66.58 67.24 64.21 60.37 72.16 61.16 60.58 57.26 59.34 20 std (13.78) (14.87) (11.35) (15.87) (9.58) (14.45) (17.51) (15.68) (11.34) (8.48) p-value - 5.0E-1 6.2E-1 9.8E-2 4.1E-1 - 4.1E-1 5.4E-1 1.2E-1 2.6E-1 Mean 85.90 59.10 58.22 57.31 56.74 84.23 52.42 50.72 48.64 51.77 30 std (0. 86) (17.4) (20.55) (8.27) (4.90) (1.26) (4.28) (5.60) (4.89) (2.77) p-value - 9.0E-03 (+) 2.5E-2 (+) 5.1E-3 (+) 6.4E-3 (+) - 7.4E-04 (+) 5.6E-5 (+) 4.9E-6 (+) 1.8E-7 (+) Mean 88.09 71.83 71.27 69.58 64.96 87.39 70.61 71.33 64.99 68.41 40 std (1.35) (8.86) (7.89) (10.54) (9.73) (3.0) (8.14) (6.64) (10.37) (12.85) p-value - 4.70E-2 (+) 2.8E-2 (+) 4.2E-3 (+) 7.7E-3 (+) - 5.3E-2 5.1E-2 4.8E-3 (+) 2.5E-2 (+) Mean 87.53 84.82 84.32 81.62 82.44 88.32 84.74 80.16 75.32 72.19 50 std (7.18) (9.02) (10.33) (8.27) (9.11) (7.80) (9.83) (8.12) (10.77) (11.65) p-value - 4.8E-2 (+) 3.4E-2 (+) 8.9E-3 (+) 7.7E-3 (+) - 4.1E-2 (+) 2.2E-2 (+) 3.6E-2 (+) 1.8E-2 (+)
下载: 导出CSV
-
[1] Frey B J, Dueck D. Clustering by passing messages between data points. Science, 2007, 315(5814):972-976 doi: 10.1126/science.1136800 [2] 许晓丽, 卢志茂, 张格森, 李纯, 张琦.改进近邻传播聚类的彩色图像分割.计算机辅助设计与图形学学报, 2012, 24(4):514-519 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201204015.htmXu Xiao-Li, Lu Zhi-Mao, Zhang Ge-Sen, Li Chun, Zhang Qi. Color image segmentation based on improved affinity propagation clustering. Journal of Computer-Aided Design & Computer Graphics, 2012, 24(4):514-519 http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201204015.htm [3] Borile C, Labarre M, Franz S, Sola C, Refrégier G. Using affinity propagation for identifying subspecies among clonal organisms:lessons from M. tuberculosis. BMC Bioinformatics, 2011, 12:224 doi: 10.1186/1471-2105-12-224 [4] 储岳中, 徐波, 高有涛, 邰伟鹏.基于近邻传播聚类与核匹配追踪的遥感图像目标识别方法.电子与信息学报, 2014, 36(12):2923-2928 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201412021.htmChu Yue-Zhong, Xu Bo, Gao You-Tao, Tai Wei-Peng. Technique of remote sensing image target recognition based on affinity propagation and kernel matching pursuit. Journal of Electronics and Information Technology, 2014, 36(12):2923-2928 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201412021.htm [5] 王开军, 张军英, 李丹, 张新娜, 郭涛.自适应仿射传播聚类.自动化学报, 2007, 33(12):1242-1246 http://www.aas.net.cn/CN/abstract/abstract15756.shtmlWang Kai-Jun, Zhang Jun-Ying, Li Dan, Zhang Xin-Na, Guo Tao. Adaptive affinity propagation clustering. Acta Automatica Sinica, 2007, 33(12):1242-1246 http://www.aas.net.cn/CN/abstract/abstract15756.shtml [6] 刘建伟, 刘媛, 罗雄麟.半监督学习方法.计算机学报, 2015, 38(8):1592-1617Liu Jian-Wei, Liu Yuan, Luo Xiong-Lin. Semi-supervised learning methods. Chinese Journal of Computers, 2015, 38(8):1592-1617 [7] Bijral A S, Ratliff N, Srebro N. Semi-supervised learning with density based distances.[Online], available:http://ttic.uchicago.edu/~nati/Publications/SemiSupDBD.pdf, October 10, 2014 [8] Wagstaff K, Cardie C. Clustering with instance-level constraints. In:Proceedings of the 17th International Conference on Machine Learning (ICML2000). Stanford:Morgan Kaufmann Publishers, 2000. 1103-1110 [9] 肖宇, 于剑.基于近邻传播算法的半监督聚类.软件学报, 2008, 19(11):2803-2813 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200811005.htmXiao Yu, Yu Jian. Semi-supervised clustering based on affinity propagation algorithm. Journal of Software, 2008, 19(11):2803-2813 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200811005.htm [10] 张震, 汪斌强, 伊鹏, 兰巨龙.一种分层组合的半监督近邻传播聚类算法.电子与信息学报, 2013, 35(3):645-651 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201303020.htmZhang Zhen, Wang Bin-Qiang, Yi Peng, Lan Ju-Long. Semi-supervised affinity propagation clustering algorithm based on stratified combination. Journal of Electronics and Information Technology, 2013, 35(3):645-651 http://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201303020.htm [11] 张建朋, 陈福才, 李邵梅, 刘力雄.基于密度与近邻传播的数据流聚类算法.自动化学报, 2014, 40(2):277-288 http://www.aas.net.cn/CN/abstract/abstract16309.shtmlZhang Jian-Peng, Chen Fu-Cai, Li Shao-Mei, Liu Li-Xiong. Data stream clustering algorithm based on density and affinity propagation techniques. Acta Automatica Sinica, 2014, 40(2):277-288 http://www.aas.net.cn/CN/abstract/abstract16309.shtml [12] Givoni I E, Frey B J. Semi-supervised affinity propagation with instance-level constraints. In:Proceedings of the 12th International Conference on Artificial Intelligence and Statistics (AISTATS). Clearwater Beach, Florida, USA:JMLR W & CP5, 2009. 161-168 [13] 赵宪佳, 王立宏.近邻传播半监督聚类算法的分析与改进.计算机工程与应用, 2010, 46(36):168-170 http://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201036047.htmZhao Xian-Jia, Wang Li-Hong. Analysis and improvement of semi-supervised clustering algorithm based on affinity propagation. Computer Engineering and Applications, 2010, 46(36):168-170 http://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201036047.htm [14] Wagstaff K, Cadrie C, Rogers S, Schroedl S. Constrained K-means clustering with background knowledge. In:Proceedings of the 18th International Conference on Machine Learning (ICML2001). Williamstown:Morgan Kaufmann Publishers, 2001. 577-584 [15] 尹学松, 胡恩良, 陈松灿.基于成对约束的判别型半监督聚类分析.软件学报, 2008, 19(11):2791-2802 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200811004.htmYin Xue-Song, Hu En-Liang, Chen Song-Can. Discriminative semi-supervised clustering analysis with pairwise constraints. Journal of Software, 2008, 19(11):2791-2802 http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB200811004.htm [16] Kschischang F R, Frey B J, Loeliger H A. Factor graphs and the sum-product algorithm. IEEE Transactions on Information Theory, 2001, 47(2):498-519 doi: 10.1109/18.910572 [17] Weiss Y, Freeman W T. On the optimality of solutions of the max-product belief-propagation algorithm in arbitrary graphs. IEEE Transactions on Information Theory, 2001, 47(2):736-744 doi: 10.1109/18.910585 [18] Givoni I E, Frey B J. A binary variable model for affinity propagation. Neural Computation, 2009, 21(6):1589-1600 doi: 10.1162/neco.2009.05-08-785 -

 下载:
下载:

计量
- 文章访问数: 2862
- HTML全文浏览量: 276
- PDF下载量: 969
- 被引次数: 0
