

An Automatic Reconstruction Method of Convex Object Based on Sequence Contours
-
摘要: 凸面目标在成像时会表现尺寸较小、纹理稀疏或缺乏、透光、反光等特点.在对其进行三维重构时,传统的立体视觉匹配、主动视觉扫描(激光或结构光)等重构方法无法提供良好的解决方案.针对此类目标的重构难题,本文提出一种基于序列轮廓线的全自动重构方法.该方法首先采集目标的序列轮廓影像,然后提取高精度的轮廓线,再利用多个视角的轮廓线对初始外包体进行空间切割得到目标的初始三维模型,接着根据角度和面积约束对初始三维模型中的面进行合并,最后利用合并后的面重新对外包体进行精细切割得到目标的精确三维刻面模型.通过对凸面目标(注射器针头,直径约为3mm)的重构实验证明,利用本文的方法重构得到的模型角度误差小于0.7,执行时间小于15s,重构过程无需人工干预,能有效解决凸面目标的三维重构及视觉测量难题.Abstract: There is a small size, lack of or less texture, transparent and reflective phenomenon on the images of convex objects. So the traditional reconstruction methods such as stereo-vision matching and active vision scanning such as laser or structure light cannot be used for such objects. In this paper, a reconstruction method based on multi-contours for miniature convex object is proposed. Firstly, multi-view silhouette images are captured, then the accurate contours are extracted; secondly coarse mesh is generated by space carving of multi-contours, and thirdly, the fragmented polygons are merged according to angle and area constriants; at last, the accurate mesh is generated by space carving of multi-polygons of the coarse mesh. The reconstruction experiments of regular and convex objects(syringe needle, diameter is about 3mm) proved that the angular error is less than 0.7 and the time cost is less than 15 seconds and the total process is without manual intervention. This method can solve the problem of reconstruction and vision measurement of convex objects effectively.
-
Key words:
- Computer vision /
- sequence contours /
- space carving /
- convex object /
- SFS /
- vision measurement
-
三维城市场景模型在城市规划、虚拟旅游以及文化遗产保护等方面有着广泛的应用, 对城市场景进行精确的三维建模具有重要的研究意义.在实际中, 虽然利用激光扫描设备可获取精度较高的三维信息, 但由于其扫描代价的昂贵与扫描范围的局限导致其应用范围存在一定的限制.相对而言, 基于图像的三维场景重建方法由于造价低廉、数据获取方便等优点, 当前仍是城市场景建模中的常用方法.
然而, 由于城市场景光照变化、透视畸变、弱纹理与重复纹理区域等因素的影响, 利用图像信息有效地获取完整的城市场景模型仍是一个具有挑战性的难题.在诸多相关算法中, 基于特定场景模型或区域 (如超像素) 级的重建算法尽管在一定程度上可以克服像素级重建算法难以获得完整场景结构的缺点, 但同时也存在以下几点问题导致其可靠性与效率较低: 1) 采用的场景模型过于简单 (如仅具有3个正交方向的Manhattan场景模型) 或对场景的结构过于限定 (如预先指定几个场景方向), 因而导致重建结果存在较大的偏差; 2) 用于场景完整结构推断的候选平面集缺乏完备性 (即仅包含场景中的部分平面), 进而影响推断结果的可靠性; 3) 对场景中非重建区域 (如天空、地面) 缺乏有效的检测与滤除机制, 整体重建效率因此受到较大的影响.
为了解决以上问题, 本文针对城市场景重建完整性问题提出一种快速、鲁棒的分段平面重建算法.该算法根据城市场景的结构特点, 着重解决如何快速从噪声较大的初始空间点中抽取充分且可靠的候选平面以及如何有效地对场景完整的结构进行可靠推断的问题.本文主要贡献如下: 1) 提出一种鲁棒的基于连通域检测的空间平面拟合方法, 可以快速从噪声较大的空间点中抽取充分且可靠的空间平面; 2) 提出一种在MRF (Markov random field) 能量最小化框架下融合灰度一致性、空间几何约束与可见性等度量与约束的场景完整结构推断方法, 可以有效地解决场景中弱纹理、倾斜表面等区域的重建问题; 3) 针对城市场景重建中的常见干扰因素 (如天空、地面等), 提出了相关可行的滤除与屏蔽方法, 有效地提高了整体场景重建的效率.
本文结构组织如下:第1节对相关工作进行概述; 第2节对所解决的问题进行描述并给出相应的算法流程; 第3节介绍本文算法的几个预处理步骤; 第4、5节分别介绍鲁棒的候选平面抽取与场景完整结构推断方法; 第6节进行实验分析; 第7节对本文进行总结.
1. 相关工作
对于室外场景的重建, 基于特定场景模型与场景分段平面假设的重建算法通常可在一定程度上克服传统像素或空间点级的重建算法难以恢复完整场景结构的缺点.
在双目立体视觉中, 基于场景分段平面假设的算法[1-2]通常先将图像过分割为相互不交迭的若干超像素, 由于每个超像素为颜色相似、位置相近像素的集合, 其对应的空间面片可近似为一个平面 (称为视差平面), 最终的重建问题则转化为为每个超像素分配最优视差平面的问题.为了求解该问题, 此类算法在初始视差图的基础上, 首先利用视差平面拟合的方法获取纹理丰富区域对应的视差平面集, 然后采用全局优化 (如Graph cuts[3]) 方法推断弱纹理、倾斜表面等区域对应的视差平面, 进而获得完整的视差图.此类算法的主要问题在于, 由于初始视差平面集通常缺乏完备性 (如弱纹理、倾斜表面等区域对应的视差平面并不一定包含于初始视差平面集内), 往往会导致视差平面推断产生较大的偏差.此外, 由于此类算法仅采用两幅图像对场景进行重建, 相关像素或区域之间的匹配多义性问题依然较为严重, 因而其可靠性在很多情况下也较低.
由于较多的图像包含了更丰富的场景结构信息, 类似的多视场景重建算法往往更有利于解决场景重建的完整性问题.在相关算法中, 传统的空间平面扫描算法[4]通常在灰度一致性度量标准下采用究举方式确定每个超像素对应的空间平面.然而, 由于扫描空间不易确定, 因而其计算效率不但难以得到保证, 而且可靠性往往也较差.为了克服此问题, 许多算法趋于直接或间接地指定场景的主方向数量以简化场景的重建过程.如Furukawa等[5]假定场景中的空间点或空间平面总是沿3个正交的场景主方向分布 (即Manhattan场景模型), 进而在由PMVS (Patch-based multi-view stereo) 算法[6]获取的具有方向的初始空间点的基础上, 在MRF能量最小化框架下推断完整的场景结构, 进而较好地解决了弱纹理区域的重建问题.然而, 由于算法所依赖的场景模型过于简单, 在复杂场景的重建中往往会产生较大的错误, 如当场景中的空间面片对应的真实空间平面的法向量与所有场景主方向均不一致时, 该空间面片会被分配一个错误的空间平面.同样, Gallup等[7]采用的沿多个场景主方向进行空间平面扫描方法以及Mičušík等[8]在由消影点检测方式获得的3个场景主方向上进行场景结构推断的方法也面临着类似的问题.在实际中, 简单地对场景的结构 (如主方向数量) 进行限制或约束很难适于具有复杂结构的场景重建.
在其他的分段平面重建算法中, Sinha等[9]首先采用传统的SfM (Structure from motion) 方法及直线重建方法获取初始空间点及线段, 然后以此构造场景结构推断时所采用的候选空间平面集.然而, 在复杂场景重建中, 由于初始空间点与直线比较稀疏, 该算法通常会遗漏较多的场景结构细节而重建出过于简单的场景结构; 此外, 该算法中的图像校正与穷举式的平面拟合等过程也会使得算法适应性与效率降低. Chauve等[10]通过在初始空间点云的基础上利用区域增长的方式获取候选平面, 然后根据场景中每个空间面片相对于空间平面的位置而采用类似体素重建的方式对其状态进行标注, 进而获取分段平面的重建结果.在实际中, 如果初始空间点云比较稀疏且噪声较大, 区域增长方法的可靠性往往不易得到保证, 算法的整体性能因此会受到较大的影响.在Kowdle等[11]提出的将图像与空间信息融合于能量优化框架下的物体分割算法中, 空间信息的获取与本文算法较为相关, 但其整体算法侧重于对特定物体的分割, 因而难以适于室外场景的重建. Bódis-Szomorú等[12]在初始稀疏空间点与图像过分割获得的超像素的基础上在MRF能量最小化框架下推断场景的完整结构.该算法虽然速度较快, 但其为了通过空间点拟合的方式获取每个超像素对应的初始空间平面而采用了较大尺寸的超像素, 这在实际中往往会导致算法的可靠性较差.事实上, 尺寸较大的超像素对应的空间点深度变化通常较大, 相应的空间面片并不能简单地近似为空间平面.此外, 如果场景中存在较多的难以获得空间点的区域 (如弱纹理、重复纹理等区域), 即使采用尺寸较大的超像素, 可能也难以满足算法所依赖的假设, 进而难以获得较好的结果.
2. 问题描述与算法流程
对于城市场景, 为了可靠地恢复其完整的结构, 通常需要在数据采集阶段捕获其丰富的结构细节.如图 1所示, 本文采用的图像采集设备由架设于摄影车顶部的6部摄像机构成, 其中的1号摄像机主要用于捕获高层建筑区域的上部结构信息, 其他摄像机彼此间保持相同的夹角以全方位地捕获场景其他结构信息.
本文在初步实验中发现, 以上摄像机架设方式尽管可以对场景的结构进行充分地采集, 但由于光照变化、透视畸变、弱纹理区域等诸多因素的影响, 采用PMVS算法并没有获得较好的重建结果.如图 2所示, 不但场景中许多区域的结构未被可靠地重建 (如存在较大的孔洞), 而且对于距离摄像机较远的已重建区域, 相应的空间点与真值之间的偏差也较大.此外, 大量非重建的区域空间点 (如天空、地面等) 也极大地干扰着建筑区域空间点的可视化与进一步的处理 (如三角化网格).
因此, 当前需解决的问题可简要地描述为:已知城市场景相应的图像集$\left\{ {{I_k}} \right\}\left ({k = 1, \cdots, m} \right)$及对应的初始稀疏且带噪空间点集$\left\{ {{P_k}} \right\}\left ({k = 1, \cdots, m} \right)$ (即图像$I_k$对应的可见空间点为$P_k$), 如何快速、可靠地恢复其完整的结构?
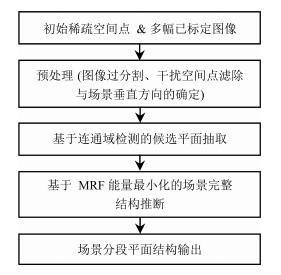
针对此问题, 本文提出一种有效的城市场景分段平面重建算法, 其基本流程如图 3所示.
下文对算法的各个环节进行详细介绍.
3. 预处理
为了根据场景分段平面假设对场景完整的结构进行推断, 本文采用Mean-shift算法[13]对当前图像进行了过分割以将场景结构完整推断问题转化为为每个分割区域 (即超像素) 分配空间平面的问题.需要注意的是, 由于大尺寸超像素对应的空间面片通常存在较大的深度变化而不能将其近似为空间平面, 因而, 本文算法采用小尺寸超像素 (如空间与颜色参数分别为2与1) 对场景结构进行推断.
对于场景中的天空、地面等非重建区域中的空间点 (以下简称干扰空间点), 其不但对重建结果的可视化 (如图 2 (a)所示) 产生较大的干扰, 而且也对重建结果的后续处理 (如场景完整结构的推断、三角化网格等) 产生较大的影响, 因而需要被有效地滤除.因而, 本文也采用文献[14]中算法对图像中的天空、地面与建筑物等3个语义区域进行了标注, 并滤除了相应的干扰空间点 (如图 4 (a)所示).事实上, 此预处理步骤也使得场景完整结构的推断可以针对建筑区域进行, 不但可以提高整体算法的效率, 而且也可以增强采用分段平面假设对以平面为主的建筑结构进行推断的可靠性.
此外, 为了从初始空间点中抽取充分且可靠的空间平面 (参见第4节), 本文算法也采用消影点检测方法[8]确定了场景的垂直方向 (如图 4 (b)所示的根据场景垂直方向确定的水平面).
4. 候选平面的抽取
为了对场景完整的结构进行可靠地推断, 抽取充分且可靠的候选平面是关键环节.在实际中, 对超像素相应的空间点进行拟合是获取候选平面最为直接的方法, 但同时也存在以下问题导致其实用性较差: 1) 当超像素对应空间点存在较大噪声时, 所获得的空间平面与真实空间平面之间往往存在较大的偏差, 特别当空间点较少时, 此问题尤其严重; 2) 当超像素数量较多时, 整体拟合效率较低.
此外, 尽管当前许多经典的多模型 (如空间平面) 拟合方法 (如: J-linkage[15]、PEaRL [16]等) 也可以在一定程度上解决候选平面的抽取问题, 但当空间点数量较多且噪声较大时, 此类方法在初始模型的产生、模型优化等环节通常不易获得较好的效果, 而且效率较低.
为了解决以上问题, 本文算法根据城市场景的结构特征与先验, 采用基于连通域检测的方法产生候选平面集, 如算法1所示.
4.1 场景结构特征
根据城市建筑垂直于地平面且以平面结构为主的特征 (如图 4 (c)所示), 空间点在地平面上的投影通常由于较高的聚集度而形成具有一定规则性 (如直线) 的连通区域, 尤其对于场景主平面区域, 此特征更加明显.在如图 4 (d)所示投影图中, 尽管单个投影点对应的空间点数量不尽相同且空间点有所偏差, 但投影点之间却相互聚集成连通区域, 因而可以利用连通域检测方法确定不同连通区域对应的空间点, 进而可通过整体拟合的方式确定相应空间平面.
由于尺寸较小的连通区域对应空间点的分布问题 (如近似位于垂直方向同一直线上) 可能会导致不可靠的空间平面的抽取, 所以, 本文算法首先对尺寸大于指定阈值$\vartheta$ (实验设置为15) 的连通区域进行平面检测, 而对其他连通区域则根据场景结构先验 (参见第4.2节) 检测其中的潜在空间平面.此外, 为了增强连通域检测的可靠性, 本文算法采用了多级投影点阈值的方式对投影图进行过滤处理.如图 4 (e)所示, 采用较高的投影点阈值后, 投影图中的连通区域对应的空间点数量较多, 因而拟合生成的空间平面的可靠性较高 (如图 4 (f)中彼此间隔较小的两个空间平面均可被可靠地抽取).当投影点阈值降低后, 如图 4 (h)所示, 更多连通域可被检测, 因而更多潜在的空间平面可被抽取.在我们的实验中, 将每次投影点阈值$\zeta$ (缺省设置为25) 设置为当前投影图中投影点对应的最大空间点数量的0.05可获得较好的效果.
4.2 场景结构先验
由于空间点分布的不均匀性, 利用其投影特征通常仅能抽取场景中具有明显特征的主平面.在此过程中, 尺寸较小的连通区域虽未被检测, 但其对应的空间点往往位于潜在的场景平面上.对于城市建筑, 其主体结构除以平面为主外, 各个平面之间的夹角通常也是特定 (如$45^\circ $、$90^\circ $等) 的, 此场景结构先验对进一步抽取潜在的空间平面具有较好的指导作用.事实上, 在场景垂直方向已知且部分可靠场景主平面已确定的情况下, 潜在的场景平面更可能位于与当前已抽取的场景主平面具有特定夹角的位置.
在本文算法中, 以当前已抽取的任意一个可靠场景主平面的法向量$n$作为参考, 以场景垂直方向为主轴并以指定角度 (实验采用$15^\circ $) 进行旋转可生成法向量集${n_i}$.显然, 其中的部分法向量相应的空间平面更可能为潜在的空间平面.此外, 考虑到一些特殊倾斜表面 (如与地平面夹角$60^\circ $) 的抽取, 本文算法也将$n$沿场景水平方向在指定可视度量范围内 (如[$0^\circ $, $60^\circ $]) 按指定角度间隔 (如$15^\circ $) 进行了旋转以生成更多可能的法向量,
设小尺寸连通区域的集合为${c_j}$, 则根据法向量$n_i$与连通区域$c_j$对应空间点的重心可确定相应的空间平面$h_{i, j}$.为了验证空间平面$h_{i, j}$的可靠性, 本文算法采用了以下两个度量标准: 1) 剩余空间点 (即不在主平面上的空间点) 到空间平面$h_{i, j}$的距离小于指定阈值的数量$t_1$; 2) 到空间平面$h_{i, j}$的距离小于指定阈值的剩余空间点相关的连通区域数量$t_2$.显然, 如果$t_1$值与$t_2$值越大, 则空间平面$h_{i, j}$的可靠性也越高.在实际中, 由于相同的$t_2$值可能与多个不同的$t_1$值相对应, 因而, 本文算法首先选取$t_2$值大于指定阈值$\omega$的所有空间平面, 然后将其中$t_1$值最大者作为候选平面.由于阈值$\omega$设置过小可能会引入较多的干扰空间平面, 本文实验中将其设置为5.
算法1.基于连通域检测的候选平面抽取
输入.空间点集$P$;
输出.候选空间平面集${\cal H}$;
%初始主平面的抽取
1) 根据$P$生成投影图$M$并根据阈值$\zeta$对其进行过滤处理;
2) 检测连通区域, 如果其尺寸大于指定阈值$\vartheta$, 则拟合相应的空间点并将生成的空间平面保存至$H_1$, 同时从$M$与$P$中分别删除该连通区域与所有被拟合的空间点;
3) 否则, 则将该连通区域添加到集合${c_j}$;
4) 降低阈值$\zeta$并转到步骤2直至检测不到符合条件的连通区域;
%潜在平面的抽取
5) 根据平面$h \in {H_1}$生成场景方向${n_i}$;
6) 根据${n_i}$与$c_j$生成候选平面集$h_{i, j}$;
7) 计算$h_{i, j}$对应的平面可靠性度量$t_1$与$t_2$;
8) 根据$t_1$与$t_2$从$h_{i, j}$中确定候选平面并将其保存至$H_2$;
9) 合并$H_1$与$H_2$为${\cal H}$并从中剔除相似平面后输出.
从算法1中不难发现, 连通域的检测在一定程度上可以全局地对大量空间点 (通常对应多个超像素) 是否属于相同空间平面进行度量与判断, 不但有效地避免了局部对单个超像素对应的空间点进行拟合的不可靠性, 而且也避免了对大量超像素对应的空间点进行拟合的计算复杂度, 整体上具有较高的可靠性与效率.此外, 为了获取场景更细致的结构以避免过拟合情况, 本文算法也在每个空间平面$h \in {\cal H}$附近对与其平行的空间平面进行采样, 并将得到的指定数量 (实验设置为10) 的空间平面也作为候选平面保存至${\cal H}$.
5. 场景结构推断
虽然利用算法1可以抽取场景中充分且可靠的候选平面, 但场景的完整结构仍需要进一步的推断, 其主要原因在于: 1) 由于光照变化、弱纹理等因素的影响, 场景中许多区域并未包含任何空间点, 因而需要对这些区域对应的空间平面进行推断; 2) 从初始空间点中抽取的空间平面中往往也存在少量外点, 因而需要进行全局性的优化以获取更可靠的结果.
针对以上两点问题, 本文采用MRF能量最小化方法进行解决.
5.1 能量函数
设${\cal L}$表示由空间平面集${\cal H}$的序号构成的标记集, ${\cal R}$表示当前图像过分割获得的建筑区域超像素集, 则用于场景完整结构推断的能量函数如下:
$ \begin{align} &E\left( f \right)=\sum\limits_{s\in R}{{{E}_{data}}}\left( s,{{f}_{s}} \right)+{{\lambda }_{smo}}\times \\ &\sum\limits_{t\in N(s)}{{{E}_{smooth}}}\left( {{f}_{s}},{{f}_{t}} \right)+{{\lambda }_{lab}}\cdot \sum\limits_{L\in L}{{{E}_{label}}}\left( f \right) \\ \end{align} $
(1) 其中, $f$为所有超像素对应空间平面的标记组合, $N (s)$为所有与超像素$s$相邻的超像素集合, ${f_s} \in {\cal L}$与${f_t} \in {\cal L}$分别为相邻超像素$s$与$t$对应的空间平面标记, 常数${\lambda _{smo}}$与${\lambda _{lab}}$分别为平滑项${E_{smooth}}\left ({{f_s}, {f_t}} \right)$与标记项${E_{label}}\left (f \right)$相应的权重.在实际中, 较大的${\lambda _{smo}}$有利于增强相邻超像素对应空间平面之间的平滑性, 但设置过大则不利于恢复场景的结构细节 (如两相邻超像素对应空间平面相差较小时会被分配为一个空间平面).类似地, 较大的权重${\lambda _{lab}}$虽然有利于降低场景结构的复杂度, 但过大的取值也会导致场景结构细节的损失.本文实验中分别将${\lambda _{smo}}$与${\lambda _{lab}}$设置为0.6与0.2.
5.1.1 数据项
数据项${E_{data}}\left ({s, {f_s}} \right)$由灰度一致性度量${E_{pho}}\left ({s, {f_s}} \right)$与空间几何约束${E_{geo}}\left ({s, {f_s}} \right)$两部分构成, 即:
$ {E_{data}}\left( {s, {f_s}} \right) = \alpha \cdot {E_{pho}}\left( {s, {f_s}} \right) + \left( {1 - \alpha } \right) \cdot {E_{geo}}\left( {s, {f_s}} \right) $
(2) 其中, 权重常数$\alpha$用于调整灰度一致性度量与空间几何约束的作用力度, 当空间点较少或噪声较大时, 可设置为较大的值以增强灰度一致性的作用力度 (实验中设置为0.6).
5.1.1.1 灰度一致性度量
设当前图像与其相邻图像分别表示为$I_r$与$\left\{ {{N_i}} \right\}\left ({i = 1, \cdots, k} \right)$, 灰度一致性度量${E_{pho}}\left ({s, {f_s}} \right)$定义为:
$ {E_{pho}}\left( {s, {f_s}} \right) = \frac{1}{{k \cdot \left| s \right|}}\mathop \sum \limits_{i = 1}^k \mathop \sum \limits_{p \in s} {C_s}\left( {p, {H_s}, {N_i}} \right) $
(3) 其中, $\left| s \right|$为超像素$s$内部所有像素的总数, 而${C_s}\left ({p, {H_s}, {N_i}} \right)$定义为:
$ \begin{align} &{{C}_{s}}\left( p,{{H}_{s}},{{N}_{i}} \right)= \\ &\left\{ \begin{array}{*{35}{l}} \min \left( \left\| {{I}_{r}}\left( p \right)-{{N}_{i}}\left( {{H}_{s}}(p) \right) \right\|,\delta \right),&{{H}_{s}}\left( p \right)\in M \\ {{\lambda }_{occ}},&\text{其他} \\ \end{array} \right. \\ \end{align} $
(4) 其中, $\left\| {{I_r}\left (p \right)-{N_i}\left ({{H_s}(p)} \right)} \right\|$表示图像${I_r}$中的像素$p$与相邻图像$N_i$中的像素${H_s}(p)$之间的规范化颜色 (即颜色值范围为0 $\sim$ 1) 差异, ${\lambda _{occ}}$为空间可见性冲突惩罚量 (实验设置为2), $\delta$为截断阈值以增强颜色度量的可靠性 (实验设置为0.5).由于${H_s}(p)$可能并非整数位置, 相应的颜色值需要进行插值运算 (本文采用双线性插值).
在式 (4) 中, $M$为相邻图像$N_i$中待推断空间平面的区域, 通常不包含或仅包含较少数的空间点.因而, 如果图像$I_r$中的像素$p \in s$在空间平面$H_s$的诱导下投影在图像$N_i$中的区域$M$ (即${H_s}\left (p \right) \in M$), 则空间平面$H_s$更可能分配至超像素$s$, 其可靠性通过相应的颜色差异进行度量; 否则则可能导致空间点可见性的冲突, 因而需给予较大的惩罚量.需要注意的是, 此处将空间点遮挡也视为可见性冲突情况处理的主要原因在于: 1) 初始空间点本身存在偏差, 空间点遮挡判断的可靠性较低; 2) 单幅图像的遮挡问题可在多个图像的重建结果进行合并时得以缓解; 3) 降低能量函数的复杂性以提高求解效率与可靠性.
5.1.1.2 空间点的约束
在实际中, 如果超像素$s$对应的空间面片包含一定数量的空间点, 则距离这些空间点较近的空间平面更可能成为超像素$s$对应的空间平面.因而, 空间点的几何约束项${E_{geo}}\left ({s, {f_s}} \right)$可定义如下:
$ {E_{geo}}\left( {s, {f_s}} \right) = \left\{ {\begin{array}{ll} {{\lambda _{dis}}},&{\left| {{P_s}} \right| = 0} \\ \displaystyle {\frac{1}{{1 + {{\rm e}^{ - d\left( {{P_s}, {H_s}} \right)}}}}},&{\left| {{P_s}} \right| > 0} \\ \end{array}} \right. $
(5) 其中, $P_s$为超像素$s$对应的空间点集, $d\left ({{P_s}, {H_s}} \right)$为集合$P_s$中的空间点到空间平面$H_s$的平均距离, ${\lambda _{dis}}$为距离惩罚量, 本文实验中根据式 (5) 中的距离度量将其设置为2.
5.1.2 平滑项
平滑项${E_{smooth}}\left ({{f_s}, {f_t}} \right)$采用Potts模型[3], 即:
$ {E_{smooth}}\left( {{f_s}, {f_t}} \right) = {\omega _{st}} \cdot \delta \left( {{f_s} \ne {f_t}} \right) $
(6) 其中, $\delta \left (x \right)$为指示函数, 当$x$为真时取值为1, 否则为0. ${\omega _{st}}$为相邻超像素$s$与$t$对应空间平面不相似性惩罚量.
为了鼓励相邻超像素具有相同的空间平面标记或者空间平面参数应当在颜色相近的超像素之间平滑变化, 式 (6) 中的${\omega _{st}}$定义为:
$ {\omega _{st}} = {b_{st}} \cdot (1 - \left\| {c\left( s \right) - c\left( t \right)} \right\|) \cdot \left\| {n\left( s \right) - n\left( t \right)} \right\| $
(7) 其中, $c (s)$为超像素规范化平均颜色, $n (s)$为空间平面$H_s$ (空间平面标记为$f_s$) 的单位法向量. $\left\| \cdot \right\|$为$L_2$范数度量, $b_{st}$为超像素$s$与$t$之间规范化的共享边界长度 (即共享边界长度除以超像素$s$与$t$中最小周长).
式 (7) 表明, 如果两超像素之间的颜色越相似, 共享边界越长, 则相应的平滑力度越强, 当两者被分配不同的空间平面时所给予的惩罚力度也越大.
5.1.3 标记项
不同于平滑项, 标记项${E_{label}}\left (f \right)$用于约束最终解$f$中不同空间平面标记的数量, 使得位置不相邻而对应空间平面相同的超像素趋于取相同的空间平面标记, 整体上可获取能表达完整场景结构的最小空间平面集, 其定义为:
$ {E_{label}}\left( f \right) = \mathop \sum \limits_{L \in {\cal L}} {{\rm e}^{ - {\lambda _0} \cdot \left| L \right|}} \cdot {\delta _L}\left( f \right) $
(8) 其中, $\left| L \right|$为分配给标记$L$的超像素的数量, ${\lambda _0}$为经验常数 (实验设置为50), 函数${\delta _L}\left (\cdot \right)$定义为:
$ {\delta _L}\left( f \right) = \left\{ {\begin{array}{*{20}{l}} 1, ~~~ {\exists s:{f_s} = L, {f_s} \in f} \\ 0, ~~~ \mbox{其他} \\ \end{array}} \right. $
(9) 通常情况下, 式 (1) 所示的能量函数的求解属于NP-hard问题, 本文算法采用Graph-cuts方法获取其近似解.在实际中, 由于能量函数有效地融合了灰度一致性、空间几何与可见性等度量与约束, 因而其求解可靠性较高.如图 5所示的场景区域 (即矩形区域内部), 尽管由于距离摄像机较远而导致初始空间点偏差较大, 但通过场景结构推断后其对应的平面结构仍得以可靠的恢复.
5.2 外点的剔除
为了检测并剔除场景结构推断结果中的不可靠空间平面 (如非刚体物体对应的空间平面), 对于当前图像$I_r$中的超像素$s$已分配的空间平面$H_s$, 本文采用以下标准度量其可靠性:
$ T\left( {{H_s}} \right) = \sum\limits_{i = 1}^k {\delta \left( {{d_m}\left( {{P_{{H_s}}}, {H_{{N_i}}}} \right) \le \mu } \right)} $
(10) 其中, ${P_{{H_s}}}$为超像素$s$中的所有像素在空间平面$H_s$上的反投影空间点, ${H_{{N_i}}}$为相邻图像$N_i$通过空间平面推断后获得空间平面集, ${d_m}\left ({{P_{{H_s}}}, {H_{{N_i}}}} \right)$为${P_{{H_s}}}$到${H_{{N_i}}}$中的空间平面平均距离中的最小者; $\delta \left (\cdot \right)$则为式 (6) 中的指示函数, $\mu$为距离阈值 (实验设置为0.05), $k$为相邻图像的数量.
式 (10) 表明, 对于空间平面$H_s$, 较高的$T (H_s)$值意味着在多幅图像的平面推断结果中存在与其相近的空间平面, 因而其可靠性也就越高.
6. 实验结果与分析
为了验证本文算法的可行性与有效性, 如图 6所示, 本文利用标准数据集中以平面结构为主的建筑场景[17] (图像分辨率为3 072像素$\times$ 2 048像素的Herz-Jesu与Castle场景) 与图 1所示采集设备获取的类似结构的城市建筑场景数据集 (图像分辨率为1 224像素$\times$ 1 848像素) 分别对其进行测试.其中, 相对于标准数据集, 真实数据集对应的场景深度较大, 而且存在较大光照变化的干扰, 因而利用SfM方法获取的初始空间点的精度较低, 在此基础上的场景分段平面重建的鲁棒性与效率将面临更大的挑战.
 图 6 数据集例图 (上:标准数据; 下:真实数据)Fig. 6 Sample images (Up: standard data; Down: real-world data)
图 6 数据集例图 (上:标准数据; 下:真实数据)Fig. 6 Sample images (Up: standard data; Down: real-world data)此外, 在场景结构推断时, 对于标准数据集, 本文选择当前图像的左、右相邻图像对相应的场景结构进行推断; 而对于真实数据集, 本文主要对2号摄像机获取的图像对应的场景结构进行推断, 其相邻车的前后位置所拍摄的图像; 2) 序号为1的摄像机在当前位置所拍摄的图像.当然, 当考虑更多相邻图像时, 算法的可靠性可得以增强, 但其效率往往也将受到较大的影响.
本文实验环境为64位Win 7系统, 处理器为Intel 3.2 GHz双核CPU、内存为16 GB, 算法采用C++实现.
6.1 评价标准
为了较好地评价本文算法的性能以及与其他算法之间的差异, 本文仅对建筑区域进行重建, 同时采用$T\left ({{H_s}} \right) > 2$时的空间平面数量度量场景分段平面结构推断的可靠性; 此外, 对于存在真值的标准数据集, 本文采用文献[18]中的相对深度差异度量相应的空间点精度 (相关阈值设置为0.02).对于真实数据集, 由于缺少真值, 本文采用文献[19]中的场景重建精度度量标准对相应的空间点精度进行度量.该度量标准通过对在多幅视图中的相对深度偏差均小于指定阈值 (本文中设置为0.02) 的空间点所占百分比进行统计, 可以较好地衡量场景重建精度或完整性.
6.2 结果分析
对于标准数据集, 如图 7 (a)所示, 由于场景中弱纹理、倾斜区域的存在, 利用传统SfM方法获取的初始空间点尽管精度较高, 但整体上较为稀疏且分布不均匀. 表 1列出了初始空间点数量以及过分割后的超像素数量.
表 1 在标准数据集上的算法性能比较Table 1 Performance comparisons on standard data sets图像 初始空间点数量 本文算法 文献[12] 超像素数量 平面数量 重建精度 时间 (s) 超像素数量 平面数量 重建精度 时间 (s) 抽取 推断 合计 抽取 推断 合计 Herz-Jesu 29 541 49 326 12 0.8043 73.15 138.81 211.96 3 096 7 0.3296 136.72 124.50 258.22 Castle 12 337 26 825 9 0.7452 57.96 218.06 276.01 4 127 5 0.2701 107.40 196.80 304.21 从图 7与表 1所示的实验结果可以发现, 尽管标准数据集初始空间点较为稀疏, 但根据建筑结构特征与先验, 其在地平面的投影仍呈现出具有一定规则性 (如直线) 的连通区域 (如图 7 (b)所示).在此基础上, 采用连通域检测算法可以有效地抽取较为完备的候选平面集 (参见第4.2节), 进而使得场景结构推断的可靠性得以极大地增强.需要注意的是, 候选平面集的完备性是场景结构推断可靠性的基础, 这也是本文算法可以恢复更多场景结构细节 (如Herz-Jesu场景台阶) 与完整场景结构的主要原因.另一方面, 本文算法中的场景结构推断模型由于融合了空间几何约束与灰度一致性度量, 因而可以对场景中不包括或包括较少空间点的弱纹理、倾斜表面等区域对应的空间平面进行有效的推断, 这则是获取完整场景结构的关键.
相对地, 文献[12]由于需要拟合超像素对应空间点以获取用于空间平面全局优化的候选平面集, 因而采用了大尺寸的超像素以包含足够的空间点, 这在分段平面假设不可靠的区域 (如超像素对应的空间面片存大较大的深度变化) 往往会产生错误的结果.此外, 由于初始空间点分布的不均匀性, 弱纹理区域对应的超像素通常难以包含足够的空间点, 而文献[12]中的空间平面优化模型为了提高整体优化效率而未采用灰度一致度量, 因而难以对这些超像素对应的空间平面进行推断 (如Castle场景存在大量未被重建的区域).
在算法效率上, 如表 1所示, 相对于文献[12], 尽管本文算法在场景结构推断中计算灰度一致性度量耗时较多, 但在生成候选平面阶段耗时较少, 因而, 整体上仍表现出相对较高的效率.
对于真实数据集, 利用传统SfM方法获得的初始空间点更加稀疏, 本文虽然采用PMVS算法对其进行了扩散处理 (如图 8 (a)所示), 但效果并不理想, 而且空间点精度也较低.
从图 8可以发现, 本文算法可以可靠地去除天空、地平面等非重建区域的干扰, 有效地恢复建筑区域完整的平面结构, 尤其对于一些结构细节 (如图#1、#2中的矩形区域), 仍然表现出较好的性能.相对地, 文献[12]为了保证每个超像素可以包含足够的空间点以拟合相应的候选平面而采用了大尺寸的超像素, 这往往会强制地将实际不能近似为空间平面的空间面片视为空间平面处理, 从而导致空间平面拟合或推断的错误.实际中, 对于图像中对比度较低且纹理单一的区域, 采用大尺度的过分割参数通常会导致相应的超像素与多个空间平面相对应.如图#2中对应多个空间平面的窄矩形区域被分配了一个空间平面, 进而根据$T (H_s)$值而被滤除.此外, 对于不包含空间点或包含较少空间点的超像素, 由于文献[12]未在空间平面推断模型中考虑灰度一致性度量, 因而也难以对相应的空间平面进行可靠的推断 (如图#3中的矩形区域).
 图 8 真实数据集实验结果 (图像从上而下为: #1, #2, #3和#4)Fig. 8 Results for real-world data sets (Images from top to bottom are #1, #2, #3 and #4.)
图 8 真实数据集实验结果 (图像从上而下为: #1, #2, #3和#4)Fig. 8 Results for real-world data sets (Images from top to bottom are #1, #2, #3 and #4.)在本文算法中, 通过融入场景结构先验并采用连通域检测方法获取候选平面集, 不但可有效提高对带噪空间点进行空间平面拟合的可靠性, 而且具有较高的效率; 而对于不包括空间点的超像素对应空间平面的推断, 由于综合考虑了空间几何约束与灰度一致性度量, 因而可以获得较好的结果.需要注意的是, 对于图#2中的宽矩形区域, 本文算法与文献[12]重建出了不同的结果, 其主要原因是由该区域中两个空间平面相距较近而$T (H_s)$中的阈值$\mu$设置相对偏大所致, 这在一定程度上也反映出本文算法在获取候选平面集与场景完整结构推断的可靠性.
表 2给出了两种算法的重建结果与效率.从表 2中不难发现, 相对于文献[12], 本文算法不但在重建可靠性表现出了较好的性能, 而且也具有较高的效率.事实上, 尽管文献[12]为了提高效率而未在空间平面优化阶段考虑灰度一致性度量, 但在获取候选平面集时却消耗了大量的时间, 因而效率相对较低.需要注意的是, 表 2中两种算法的运算时间均为对建筑区域的重建时间.此外, 文献[12]尽管在一些情况下也获得了较多的可靠空间平面 (如图#3), 但其未对弱纹理、倾斜表面等区域进行可靠的重建.
表 2 在真实数据集上的算法性能比较Table 2 Performance comparisons on real-world data sets图像序号 初始空间点 本文算法 文献[12] 超像素 平面 精度 时间 (s) 超像素 平面 精度 时间 (s) #1 16 520 13 907 6 0.7554 58.22 1 996 4 0.3187 78.13 #2 20 468 9 562 7 0.7852 49.36 1 768 6 0.4165 60.98 #3 13 710 23 955 6 0.6486 70.01 2 341 6 0.3547 76.39 #4 10 694 18 933 7 0.5713 64.52 3 011 5 0.2310 72.67 图 9为本文算法对多幅图像重建后的分段平面结果.由于单幅图像对应的结果具有较高的可靠性, 合并后场景模型整体上也是完整、可靠的.
 图 9 多幅图像对应的初始空间点与本文算法重建结果(左:场景#1;右:场景#2)Fig. 9 Initial 3D points and reconstruction results of multiple images (Left: scene #1; Right: scene #2)
图 9 多幅图像对应的初始空间点与本文算法重建结果(左:场景#1;右:场景#2)Fig. 9 Initial 3D points and reconstruction results of multiple images (Left: scene #1; Right: scene #2)总体上, 本文算法通过基于连通域检测的空间平面拟合方法获取可靠的候选平面集与融合多种度量与约束的场景结构推断, 可以较好地克服场景中诸多干扰因素的影响, 进而可以快速、可靠地恢复场景完整的结构.
7. 结论
本文提出一种快速、鲁棒的城市场景分段平面重建算法.根据城市场景结构特征, 本文算法利用基于空间点投影的连通域检测方法可以快速从初始带噪空间点中抽取充分且可靠的候选空间平面, 克服了传统相关算法复杂度高与易于遗漏空间平面的缺点.在此基础上, 本文算法进一步在融合灰度一致性度量、空间几何与可见性约束的MRF能量最小化框架下对场景的完整结构进行了推断, 有效地解决了弱纹理、倾斜表面等区域的重建问题.目前, 本文算法的主要缺点在于: 1) 过于稀疏的初始空间点 (如几十个) 不利于抽取足够多的候选平面与构造较强的约束条件, 进而会影响场景完整性推断的可靠性; 2) 算法所依赖的分段平面假设不利于场景中曲面结构 (如柱面) 的重建, 可能会导致较大的重建偏差.在实际中, 此两方面的缺点可通过采用空间点扩散的方式稠密化初始空间点以及在重建过程中融合更丰富的场景先验进行解决, 这也是本文下一步的研究工作.
-
[1] Wang C, Yang W M, Liao Q M. A space carving based reconstruction method using discrete viewing. In:Proceedings of the 7th International Conference on Image and Graphics. Qingdao, China:IEEE, 2013. 607-611 [2] Liu Guang-Shuai, Li Bai-Lin, He Chao-Ming. Convex optimization of continuous energy model in multiview 3D reconstruction. Computer Engineering and Applications, 2013, 49(1):19-22(刘光帅, 李柏林, 何朝明. 多视三维重构中连续能量模型的凸优化. 计算机工程与应用, 2013, 49(1):19-22) [3] [3] Yemez Y, Sahillioglu Y. Shape from silhouette using topology-adaptive mesh deformation. Pattern Recognition Letters, 2009, 30(13):1198-1207 [4] [4] Dyer C R. Volumetric scene reconstruction from multiple views. Foundations of Image Understanding, 2001, 628:469-489 [5] [5] Lorensen W E, Cline H E. Marching cubes:a high resolution 3d surface reconstruction algorithm. ACM Computer Graphics, 1987, 21(4):163-169 [6] [6] Seitz S M, Dyer C R. Photorealistic scene reconstruction by voxel coloring. International Journal of Computer Vision, 1999, 35(2):151-173 [7] [7] Kutulakos K N, Seitz S M. A theory of shape by space carving. International Journal of Computer Vision, 2000, 38(3):1999-2218 [8] [8] Rankin J R, Boyapati M. Visual hull construction from semitransparent coloured silhouettes. International Journal of Computer Graphics Animation, 2013, 3(4):57-63 [9] [9] Hernandez Esteban C, Schmitt F. Multi-stereo 3D object reconstruction. In:Proceedings of the 1st International Symposium on 3D Data Processing Visualization and Transmission. Padova, Italy:IEEE, 2002. 159-166 [10] Mulayim A Y, Yilmaz U, Atalay V. Silhouette-based 3-D model reconstruction from multiple images. IEEE Transactions on Systems, Man, and Cybernetics, 2003, 33(4):582-591 [11] Wu C L, Wilburn B, Matsushita Y, Theobalt C. High-quality shape from multi-view stereo and shading under general illumination. In:Proceedings of the 2011 Conference on Computer Vision and Pattern Recognition Workshops. Colorado, USA:IEEE, 2011. 969-976 [12] Cremers D, Kolev K. Multiview stereo and silhouette consistency via convex functionals over convex domains. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(6):1161-1174 [13] Ladikos A, Benhimane S, Navab N. Efficient visual hull computation for real-time 3D reconstruction using CUDA. In:Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Anchorage, AK, USA:IEEE, 2008. 1-8 [14] Chang B, Woo S, Ihm I. GPU-based parallel construction of compact visual hull meshes. The Visual Computer, 2014, 30(2):201-211 [15] Huang C H, Lu D M, Diao C Y. Accelerated visual hulls of complex objects using contribution weights. In:Proceedings of the 7th International Conference on Image and Graphics. Qingdao, China:IEEE, 2013. 685-689 [16] Hours J H, Schorsch S, Jones C N. Parametric polytope reconstruction an application to crystal shape estimation. IEEE Transactions on Image Process, 2013, 30(2):201-211 [17] Franco J, Boyer E. Efficient polyhedral modeling from silhouettes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(3):414-427 [18] Matsumoto Y, Terasaki H, Sugimoto K, Arakawa T. A portable three-dimensional digitizer. In:Proceedings of the 1997 International Conference on Recent Advances in 3-D Digital Imaging and Modeling. Ottawa, Ont., Canada:IEEE, 1997. 197-204 [19] Niem W. Automatic reconstruction of 3D objects using a mobile camera. Image and Vision Computing, 1999, 17(2):125-134 [20] Schmitt F, Yemez Y. 3D color object reconstruction from 2D image sequences. In:Proceedings of the 1999 International Conference on Image Processing. Kobe, Japan:IEEE, 1999. 65-69 [21] Slabaugh G, Schafer R, Hans M. Image-based photo hulls. In:Proceedings of the 1st International Symposium on 3D Data Processing Visualization and Transmission. Padova, Italy:IEEE, 2002. 704-862 [22] Montani C, Scateni R, Scopigno R. Discretized marching cubes. In:Proceedings of the 1994 IEEE Conference on Visualization'94. Washington, D.C., USA:IEEE, 1994. 281-287 [23] Cheung K, Baker S, Kanade T. Shape-from-silhouette of articulated objects and its use for human body kinematics estimation and motion capture. Computer Vision and Pattern Recognition, 2003, 1:77-84 [24] Zhang Jian-Qing, Su Guo-Zhong, Zheng Shun-Yi, Zhong Liang. High accurate outline detection algorithm based on line diffusion function model. Geomatics and Information Science of Wuhan University, 2006, 31(2):95-104(张剑清, 苏国中, 郑顺义, 钟良. 基于线扩散函数的高精度轮廓特征提取算法. 武汉大学学报(信息科学版), 2006, 31(2):95-104) [25] Li Cai-Lin, Guo Bao-Yun, Li Chang. The high-accurate extraction of line features of object contour. Acta Geodaetica et Cartographica Sinica, 2011, 40(1):66-70(李彩林, 郭宝云, 李畅. 目标轮廓直线特征的高精度提取. 测绘学报, 2011, 40(1):66-70) [26] Zheng S Y, Li C L, Su G Z, Zhang J Q. High-accurate line feature extraction algorithm based on line diffusion function model. In:Proceedings of the 2007 International Symposium on Multispectral Image Processing and Pattern Recognition. Wuhan, China:SPIE, 2007. 678-683 [27] Xu Ying-Xin, Li Xing-Fei, Zhu Jia. Application of telecentric lens in rotary workpiece measurement system. Transducer and Microsystem Technologies, 2010, 29(1):111-113(徐颖欣, 李醒飞, 朱嘉. 远心镜头在回转体测量系统中的应用. 传感器与微系统, 2010, 29(1):111-113) [28] Fremont V, Chellali R. Turntable-based 3D object reconstruction. In:Proceedings of the 2004 IEEE Conference on Cybernetics and Intelligent Systems. Singapore:IEEE, 2004. 1277-1282 [29] Beardsley P A, Torr P H S, Zisserman A. 3D model acquisition from extended image sequences. In:Proceedings of the 4th European Conference on Computer Vision-ECCV'96. Berlin Heidelberg:Springer-Verlag, 1996. 683-695 [30] Fitzgibbon A W, Cross G, Zisserman A. Automatic 3D model construction for turn-table sequences. In:Proceedings of the 1998 the European Workshop on 3D Structure from Multiple Images of Large-Scale Environments. Berlin Heidelberg:Springer-Verlag, 1998. 155-170 [31] Eisert P, Steinbach E, Girod B. Automatic reconstruction of stationary 3-D objects from multiple uncalibrated camera views. IEEE Transactions on Circuits and Systems for Video Technology, 2000, 10(2):261-277 [32] Gardner R J, Paolo G, Thorsten T. Determining a rotation of a tetrahedron from a projection. Discrete Computational Geometry, 2012, 48(3):749-765 [33] Presles B, Debayle J, Pinoli J C. Size and shape estimation of 3-D convex objects from their 2-D projections:application to crystallization processes. Journal of Microscopy, 2012, 248(2):140-155 [34] Lin T H, Chang H T, Hu S J. 3D reconstruction of intricate objects using planar cast shadows. In:Proceedings of the 2013 ACM SIGGRAPH 2013 Posters. New York, NY, USA:ACM, 2013. 78-88 [35] Servin M, Garnica G, Estrada J C, Padilla J M. High-resolution low-noise 360-degree digital solid reconstruction using phase-stepping profilometry. Optics Express, 2014, 22(9):10914-10922 [36] Xiong Bang-Shu, Yu Liang, Ou Qiao-Feng, Du Jing. An image-based quality detection method of syringe needles. Chinese Journal of Biomedical Engineering, 2010, 29(4):627-631(熊邦书, 余亮, 欧巧凤, 杜静. 注射器针头合格性图像检测方法. 中国生物医学工程学报, 2010, 29(4):627-631) 期刊类型引用(4)
1. 郁钱,路金晓,柏基权,范洪辉. 基于深度学习的三维物体重建方法研究综述. 江苏理工学院学报. 2022(04): 31-41 .  百度学术
百度学术2. 陈占军,林姚宇,龚咏喜,王耀武,顾照鹏. 古建筑视觉三维重建系统设计与实现. 计算机应用与软件. 2021(08): 17-22+32 . 百度学术3. 薛俊诗,易辉,吴止锾,陈向宁. 一种基于场景图分割的混合式多视图三维重建方法. 自动化学报. 2020(04): 782-795 . 本站查看4. 陈加,张玉麒,宋鹏,魏艳涛,王煜. 深度学习在基于单幅图像的物体三维重建中的应用. 自动化学报. 2019(04): 657-668 . 本站查看其他类型引用(4)
-


 下载:
下载:




计量
- 文章访问数: 1652
- HTML全文浏览量: 76
- PDF下载量: 1327
- 被引次数: 8
 下载:
下载:
